
Advanced Bayesian Network for Task Effort Estimation in Agile Software Development

Abstract
:1. Introduction
- Flexibility of the BN building process (based purely on expert judgment, empirical data, or the combination of both),
- Ability to reflect causal relationships,
- Explicit incorporation of uncertainty as a probability distribution for each variable,
- Graphical representation that makes the model clear,
- Ability of both, forward and backward inferences,
- Ability to run the model with missing data.
2. Related Works
- Suitability for agile development, regardless of used agile methods and/or practices.
- Minimal set of input parameters, provided that the method predicts with at least 75% accuracy.
- Possibility of using the BN model at the start of the project.
- Validation based on larger sample size (not just a few samples).
3. The BN Model
3.1. The Old BN Model
3.2. The New Proposed BN Model
3.2.1. Structure Definition
- The first step defines the types of the selected variables and identifies the values for each variable. Although BN allows the use of both discrete and continuous variables, in this paper we use discrete variables, because the experimental data are discrete, and because the available BN tools require the discretization of the continuous variables.
- All the values are checked for rank and accuracy. In some cases, it is necessary to go back to the first step and redefine the values of the nodes.
- The report is simple if it takes data from a single table in the database. If there are two tables, the report is moderately complex. The report is complex if the data are taken from three or more tables. If more than 10 types of data need to be printed/displayed, the complexity of the report increases by one level, e.g., a simple report becomes moderately complex.
- The user interface of up to 5 elements is simple. With up to 10, it is moderately complex. With more than 10 elements, it is complex. If the elements (controls) are more demanding for programming, and when there are 2 such elements, the interface is moderately complex. It becomes complex when it contains more than 2 such elements.
- The function is simple if it is an existing function, without changes. If minor changes to an existing function are required, the function is moderately complex. The function is complex if it is a completely new function, or if major changes to an existing one are required.
- How understandable is the task?
- Is it complete?
- Is there a possibility of a different interpretation?
- Does the user have a developed idea?
- How are the links to other tasks/modules defined?
- Are there any technological specifics?
3.2.2. Parameter Estimation
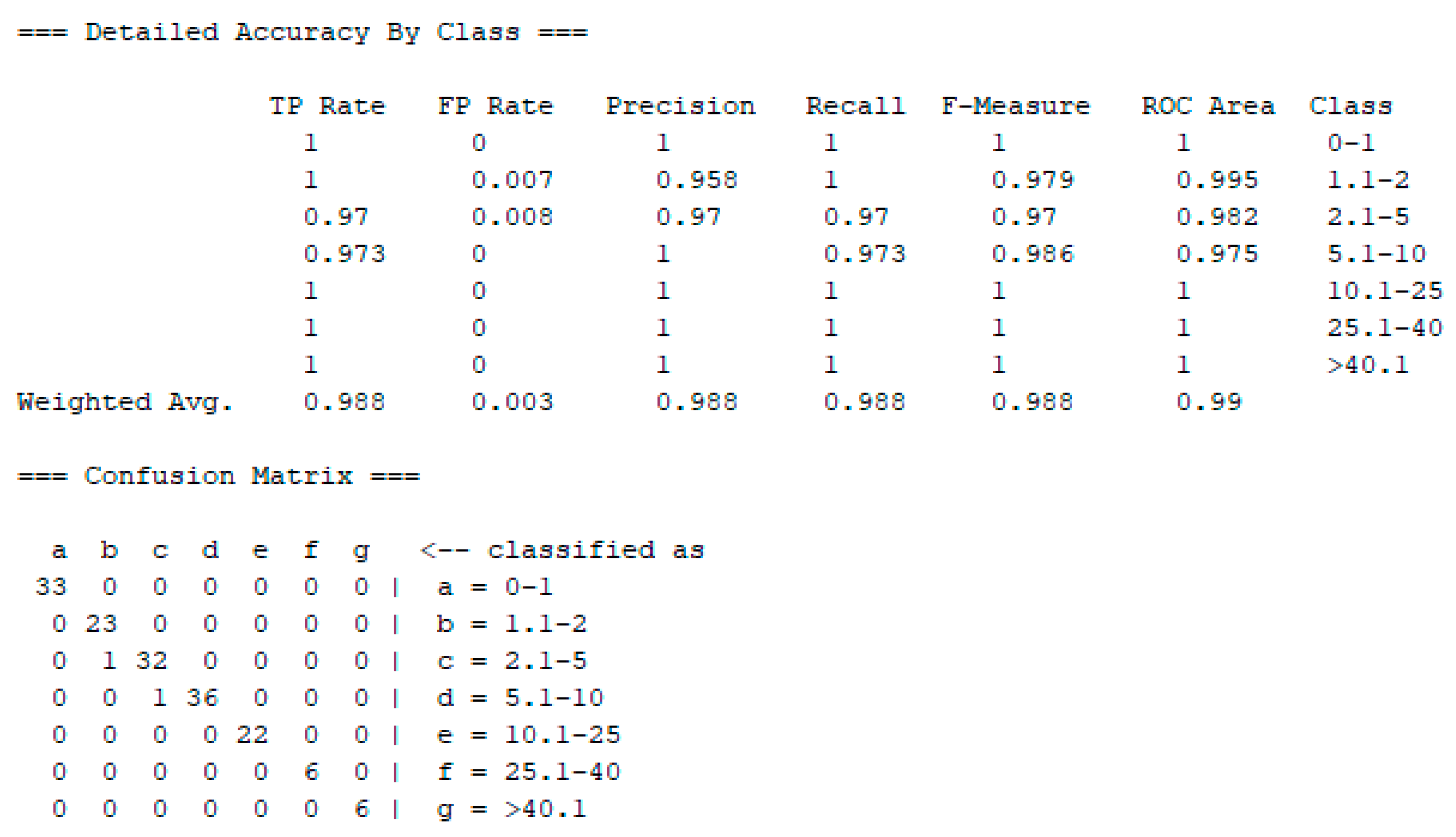
3.2.3. Prediction Accuracy
4. Application of BN Model in Another Company
5. Conclusions and Future Work
- from different companies;
- of different types of software;
- from different areas of work,
- of different technologies;
- from different developers; and
- from different assessors/managers.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hamid, M.; Zeshan, F.; Ahmad, A.; Aimeur, E. Factors Contributing in Failures of Software Projects. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2019, 19, 62–77. [Google Scholar]
- Teslyuk, V.; Batyuk, A.; Voityshyn, V. Method of Software Development Project Duration Estimation for Scrum Teams with Differentiated Specializations. Systems 2022, 10, 123. [Google Scholar] [CrossRef]
- Borade, J.G.; Khalkar, V.R. Software Project Effort and Cost Estimation Techniques. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 730–739. [Google Scholar]
- Perkusich, M.; e Silva, L.C.; Costa, A.; Ramos, F.; Saraiva, R.; Freire, A.; Dilorenzo, E.; Dantas, E.; Santos, D.; Gorgônio, K.; et al. Intelligent Software Engineering in the Context of Agile Software Development: A Systematic Literature Review. Inf. Softw. Technol. 2020, 119, 106241. [Google Scholar] [CrossRef]
- Saeed, A.; Butt, W.H.; Kazmi, F.; Arif, M. Survey of Software Development Effort Estimation Techniques. In Proceedings of the 2018 7th International Conference on Software and Computer Applications (ICSCA 2018), Kuantan, Malaysia, 8–10 February 2018; pp. 82–86. [Google Scholar]
- Bashaera, A.; Kawtherb, S. Data-driven effort estimation techniques of agile user stories: A systematic literature review. Artif. Intell. Rev. 2022, 55, 5485–5516. [Google Scholar]
- Rodríguez Sánchez, E.; Vázquez Santacruz, E.F.; Cervantes Maceda, H. Effort and Cost Estimation Using Decision Tree Techniques and Story Points in Agile Software Development. Mathematics 2023, 11, 1477. [Google Scholar] [CrossRef]
- BaniMustafa, A. Predicting Software Effort Estimation Using Machine Learning Techniques. In Proceedings of the 2018 8th International Conference on Computer Science and Information Technology (CSIT), Amman, Jordan, 11–12 July 2018; pp. 249–256. [Google Scholar]
- Cabral, J.T.H.; Oliveira, A.L.I. Ensemble Effort Estimation using dynamic selection. J. Syst. Softw. 2021, 175, 110904. [Google Scholar] [CrossRef]
- Fenton, N.; Hearty, P.; Neil, M.; Radliński, Ł. Software Project and Quality Modelling Using Bayesian Networks. In Artificial Intelligence Applications for Improved Software Engineering Development: New Prospects, Information Science Reference; Meziane, F., Vadera, S., Eds.; IGI Publishing: Hershey, PA, USA, 2008; pp. 1–25. [Google Scholar]
- Fenton, N.; Neil, M. A Critique of Software Defect Prediction Models. IEEE Trans. Softw. Eng. 1999, 25, 675–689. [Google Scholar] [CrossRef]
- Celar, S.; Vickovic, L.; Mudnic, E. Evolutionary Measurement-Estimation Method for Micro, Small and Medium-Sized Enterprises Based on Estimation Objects. Adv. Prod. Eng. Manag. 2012, 7, 81–92. [Google Scholar] [CrossRef]
- Jorgensen, M. What We Do and Don’t Know about Software Development Effort Estimation. IEEE Softw. 2014, 31, 37–40. [Google Scholar] [CrossRef]
- Jorgensen, M. Selection of Strategies in Judgment-based Effort Estimation. J. Syst. Softw. 2010, 83, 1039–1050. [Google Scholar] [CrossRef]
- Cohn, M. Agile Estimating and Planning, 1st ed.; Pearson: New York, NY, USA, 2005; ISBN 9780131479418. [Google Scholar]
- Stephen, H.K. Metrics and Models in Software Quality Engineering, 2nd ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 2002; ISBN 0201729156. [Google Scholar]
- Jones, C. Applied Software Measurement—Global Analysis Of Productivity and Quality, 3rd ed.; McGraw-Hill Companies: New York, NY, USA, 2008; ISBN 0-07-150244-0. [Google Scholar]
- McConnell, S. Software Estimation: Demystifying the Black Art; Microsoft Press: Redmond, WA, USA, 2006; ISBN 0735605351. [Google Scholar]
- Jorgensen, M.; Shepperd, M. A Systematic Review of Software Development Cost Estimation Studies. IEEE Trans. Softw. Eng. 2007, 33, 33–53. [Google Scholar] [CrossRef]
- Zarour, A.; Zein, S. Software Development Estimation Techniques in Industrial Contexts: An Exploratory Multiple Case-Study. Int. J. Technol. Educ. Sci. 2019, 3, 72–84. [Google Scholar]
- Dragicevic, S.; Celar, S.; Turic, M. Bayesian Network Model for Task Effort Estimation in Agile Software Development. J. Syst. Softw. 2017, 127, 109–119. [Google Scholar] [CrossRef]
- Ardiansyah, A.; Ferdiana, R.; Permanasari, A.E. MUCPSO: A Modified Chaotic Particle Swarm Optimization with Uniform Initialization for Optimizing Software Effort Estimation. Appl. Sci. 2022, 12, 1081. [Google Scholar] [CrossRef]
- Rankovic, N.; Rankovic, D.; Ivanovic, M.; Lazic, L. A Novel UCP Model Based on Artificial Neural Networks and Orthogonal Arrays. Appl. Sci. 2021, 11, 8799. [Google Scholar] [CrossRef]
- Perkusich, M.; Gorgonio, K.C.; Almeida, H.; Perkusich, A. Assisting the Continuous Improvement of Scrum Projects using Metrics and Bayesian Networks. J. Softw. Evol. Process 2017, 29, e1835. [Google Scholar] [CrossRef]
- Radu, L. Effort Prediction in Agile Software Development with Bayesian Networks. In Proceedings of the 14th International Conference on Software Technologies (ICSOFT 2019), Prague, Czech Republic, 26–28 July 2019; pp. 238–245. [Google Scholar]
- Malgonde, O.; Chari, K. An ensemble-based model for predicting agile software development effort. Empir. Softw. Eng. 2019, 24, 1017–1055. [Google Scholar] [CrossRef]
- Durán, M.; Juárez-Ramírez, R.; Jiménez, S.; Tona, C. User Story Estimation Based on the Complexity Decomposition Using Bayesian Networks. Program Comput. Softw. 2020, 46, 569–583. [Google Scholar] [CrossRef]
- Ratke, C.; Hoffmann, H.H.; Gaspar, T.; Floriani, P.E. Effort Estimation using Bayesian Networks for Agile Development. In Proceedings of the ICCAIS’ 2019 2nd International Conference on Computer Applications & Information Security, Riyadh, Saudi Arabia, 1–3 May 2019; pp. 1–4. [Google Scholar]
- López-Martínez, J.; Ramírez-Noriega, A.; Juárez-Ramírez, R.; Licea, G.; Jiménez, S. User stories complexity estimation using Bayesian networks for inexperienced developers. Clust. Comput. 2018, 21, 715–728. [Google Scholar] [CrossRef]
- Hearty, P.; Fenton, N.; Marquez, D.; Neil, M. Predicting Project Velocity in XP Using a Learning Dynamic Bayesian Network Model. IEEE Trans. Softw. Eng. 2009, 35, 124–137. [Google Scholar] [CrossRef]
- Torkar, R.; Awan, N.M.; Alvi, A.K.; Afzal, W. Predicting Software Test Effort in Iterative Development Using a Dynamic Bayesian Network. In Proceedings of the 21st IEEE International Symposium on Software Reliability Engineering, San Jose, CA, USA, 1–4 November 2010. [Google Scholar]
- Charniak, E. Bayesian Networks without Tears: Making Bayesian Networks more Accessible to the Probabilistically Unsophisticated. AI Mag. 1991, 12, 50–63. [Google Scholar]
- Basili, V.R.; Caldiera, G.; Rombach, H.D. The Goal Question Metric Approach. In The Encyclopedia of Software Engineering; John Wiley & Sons: Hoboken, NJ, USA, 1994; Volume 1, pp. 469–476. [Google Scholar]
- Differding, C.; Joisl, B.; Lott, C.M. Technology Package for the Goal Question Metric Paradigm; Technical Report 281/96; University of Kaiserslautern: Kaiserslautern, Germany, 1996. [Google Scholar]
- Celar, S.; Turic, M.; Vickovic, L. Method for Personal Capability Assessment in Agile Teams Using Personal Points; 22nd Telecommunications Forum; IEEE: Beograd, Serbia, 2014; pp. 1134–1137. [Google Scholar]
- Huynh Thai, H.; Silhavy, P.; Fajkus, M.; Prokopova, Z.; Silhavy, R. Propose-Specific Information Related to Prediction Level at x and Mean Magnitude of Relative Error: A Case Study of Software Effort Estimation. Mathematics 2022, 10, 4649. [Google Scholar] [CrossRef]
- Picek, S.; Heuser, A.; Jovic, A.; Bhasin, S.; Regazzoni, F. The Curse of Class Imbalance and Conflicting Metrics with Machine Learning for Side-channel Evaluations. IACR Trans. Cryptogr. Hardw. Embed. Syst. 2019, 2019, 209–237. [Google Scholar] [CrossRef]
- Orozco-Arias, S.; Piña, J.S.; Tabares-Soto, R.; Castillo-Ossa, L.F.; Guyot, R.; Isaza, G. Measuring Performance Metrics of Machine Learning Algorithms for Detecting and Classifying Transposable Elements. Processes 2020, 8, 638. [Google Scholar] [CrossRef]
- WEKA. How to Do Proper Testing in Weka and How to Get Desired Results? Available online: https://stackoverflow.com/questions/10053125/how-to-do-proper-testing-in-weka-and-how-to-get-desired-results (accessed on 2 May 2023).
- Radlinski, L. A Survey of Bayesian Net Models for Software Development Effort Prediction. Int. J. Softw. Eng. Comput. 2010, 2, 95–109. [Google Scholar]
- Conte, S.D.; Dunsmore, H.E.; Shen, V.Y. Software Engineering Metrics and Models. Benjamin-Cummings Publishing Co., Inc.: San Francisco, CA, USA, 1986. [Google Scholar]
- Pendharkar, P.C.; Subramanian, G.H.; Rodger, J.A. A Probabilistic Model for Predicting Software Development Effort. IEEE Trans. Softw. Eng. 2005, 31, 615–624. [Google Scholar] [CrossRef]
- Mendes, E. The Use of Bayesian Networks for Web Effort Estimation: Further Investigation. In Proceedings of the Eighth International Conference on Web Engineering, Proceedings of ICWE’08, Washington, DC, USA, 14–18 July 2008; pp. 203–216. [Google Scholar]
- Tierno, I.A.P. Assessment of Data-Driven Bayesian Networks in Software Effort Prediction. 2013. Available online: https://lume.ufrgs.br/handle/10183/71952 (accessed on 3 August 2023).
- Chulani, S.; Boehm, B.; Steece, B. Bayesian analysis of empirical software engineering cost models. IEEE Trans. Softw. Eng. 1999, 25, 573–583. [Google Scholar] [CrossRef]
- Williams, L. Agile Software Development Methodologies and Practices. Adv. Comput. 2010, 80, 1–44. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Goal | Accurate Assessment of the Effort Required to Accomplish the Task | |
|---|---|---|
| Question 1 | What is the difference between the estimated time and actual time? | |
| Measure 1 | Task Completion Time | |
| Question 2 | How much does the task scope affect the required effort? | |
| Measure 2 | User Interface Complexity | |
| Measure 3 | Report Complexity | |
| Measure 4 | Function Complexity | |
| Question 3 | How much does the task complexity affect the effort required? | |
| Measure 2 | User Interface Complexity | |
| Measure 3 | Report Complexity | |
| Measure 4 | Function Complexity | |
| Question 4 | How much does knowledge of the work domain affect the required effort? | |
| Measure 5 | Task Type (New or Change/Update/Correction of Old One) | |
| Question 5 | What is the impact of technology knowledge on the required effort? | |
| Measure 6 | Developer Rating | |
| Report Complexity | |||
|---|---|---|---|
| Input Parameters | Output Value | ||
| High (No) | Medium (No) | Low (No) | Total |
| 0 | 0 | ≤10 | Low |
| 0 | 0 | >10 | Medium |
| 0 | ≤5 | ≤10 | Medium |
| 0 | ≤5 | >10 | High |
| 0 | >5 | x * | High |
| ≥1 | x * | x * | High |
| Node Name | Description | ||
|---|---|---|---|
| Form Complexity | Total rating of user interface (form) complexity | ||
| Function Complexity | Total rating of function complexity | ||
| Report Complexity | Total rating of report complexity | ||
| Specification Quality | Quality of specification | ||
| New Task Type | Type of task (new or familiar one) | ||
| Task Complexity | Overall rating of task complexity | ||
| Developer Skills | Overall rating of developer experience, motivation and skills | ||
| Working Hours | Number of hours spent on the task | ||
| Working Hours Classification | Intervals of spent working hours: | ||
| 0–1 h | very simple task | (33 instances) | |
| 1.1–2 h | simple task | (23 instances) | |
| 2.1–5 h | complex simple task | (33 instances) | |
| 5.1–10 h | simple moderate task | (37 instances) | |
| 10.1–25 h | moderate task | (22 instances) | |
| 25.1–40 h | complex task | (6 instances) | |
| >40.1 h | very complex task | (6 instances) | |
| Task ID | New Task Type | Specification Quality | Form Complexity | Function Complexity | Report Complexity | Task Complexity | Developer Skills | Working Hours | Working Hours Classification |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Yes | 2 | M | M | L | M | 2 | 16.5 | 10.1–25 |
| 2 | Yes | 1 | M | M | H | M | 4 | 9 | 2.1–10 |
| 3 | Yes | 4 | H | H | L | H | 3 | 8.5 | 2.1–10 |
| 4 | No | 4 | L | L | L | L | 2 | 28 | 25.1–40 |
| 5 | Yes | 3 | H | L | H | H | 4 | 46.5 | >40.1 |
| 6 | No | 3 | L | L | L | L | 2 | 1 | 0–2 |
| 7 | No | 2 | L | M | L | L | 3 | 1.5 | 0–2 |
| 8 | Yes | 3 | H | H | L | H | 3 | 9 | 2.1–10 |
| 9 | Yes | 3 | L | L | M | L | 2 | 3.75 | 2.1–10 |
| 10 | No | 4 | L | M | H | M | 2 | 10 | 2.1–10 |
| 11 | No | 2 | M | M | L | M | 3 | 0.5 | 0–2 |
| 12 | Yes | 5 | M | M | L | M | 2 | 15.5 | 10.1–25 |
| BN Model | ||
|---|---|---|
| Old Model | New Model | |
| Number of Tasks | 160 | 160 |
| Accuracy (Correctly classified instances) | 99.375% | 98.75% |
| MAE | 0.026 | 0.037 |
| RMSE | 0.065 | 0.0792 |
| RAE | 9.71% | 15.77% |
| RRSE | 17.81% | 23.13% |
| Pred. (25) % | 40.625% | 27.5% |
| MMRE | 6.21 | 1.27 |
| The Old Model (5 Output Levels) | The New Model (7 Output Levels) | ||
|---|---|---|---|
| Class | Probability | Class | Probability |
| 0–2 | 0.96 | 0–1 | 0.91 |
| 2.1–10 | 0.01 | 1.1–2 | 0.015 |
| 10.1–25 | 0.01 | 2.1–5 | 0.015 |
| 25.1–40 | 0.01 | 5.1–10 | 0.015 |
| >40.1 | 0.01 | 10.1–25 | 0.015 |
| 25.1–40 | 0.015 | ||
| >40.1 | 0.015 | ||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Turic, M.; Celar, S.; Dragicevic, S.; Vickovic, L. Advanced Bayesian Network for Task Effort Estimation in Agile Software Development. Appl. Sci. 2023, 13, 9465. https://doi.org/10.3390/app13169465
Turic M, Celar S, Dragicevic S, Vickovic L. Advanced Bayesian Network for Task Effort Estimation in Agile Software Development. Applied Sciences. 2023; 13(16):9465. https://doi.org/10.3390/app13169465
Chicago/Turabian StyleTuric, Mili, Stipe Celar, Srdjana Dragicevic, and Linda Vickovic. 2023. "Advanced Bayesian Network for Task Effort Estimation in Agile Software Development" Applied Sciences 13, no. 16: 9465. https://doi.org/10.3390/app13169465