1. Introduction
Underwater images have broad application value in the marine field, playing an essential role in marine scientific research [
1,
2] and protection and environmental monitoring [
3]. However, underwater image quality is typically limited by the absorption, scattering, and attenuation of light, resulting in the loss of contrast, blurring, and color distortion. With the rapid development of computer vision, many scholars have conducted extensive research on Underwater Image Enhancement (UIE) and have made significant advancements in the field [
4,
5,
6].
According to the Jaffe–McGlamery imaging model [
7,
8], underwater imaging consists of a linear superposition of direct, back-scattered, and forward-scattered components. In general, the effects of forward scattering are negligible; thus, the imaging model can be simplified as:
where
is the observed intensity in the color channel
c of the input image at the pixel
,
represents the radiation of the scene at
,
represents the background light,
is the transmission map, and
c represents the red, green, and blue channels. UIE aims to recover the radiation
of the scene from the observed image
, which is an ill-posed problem. Thus, in one line of traditional UIE methods, physical priors [
9,
10] were utilized to estimate the unknown transmission map and background light. However, these physical priors might not always hold true in complex underwater scenes, resulting in poor performance when physical priors are violated. Another line of traditional methods [
11,
12,
13] directly modifies image pixel values to improve visual quality, regardless of the physical model. These methods usually rely on hand-crafted features, thus exhibiting poor generalization ability. In recent years, UIE methods based on Convolutional Neural Networks (CNNs) have achieved promising results [
14,
15,
16,
17,
18]. For example, Li et al. [
14] presented an underwater image enhancement network via medium transmission-guided multicolor space embedding, called Ucolor. Huo et al. [
15] used wavelet-enhanced learning units to build a UIE framework. However, these methods usually require complex module designs in order to remove mixed degradations directly, resulting in a large number of parameters. Furthermore, these methods often have high computational complexity. For example, it takes the Ucolor [
14] method 443.85 GFLOPs to process a 720P image. The considerable number of computational operations and parameters associated with these methods pose challenges for their deployment in underwater equipment with limited power supply, processing capabilities, and memory capacity. Therefore, designing a lightweight and effective underwater image enhancement model has become a challenge.
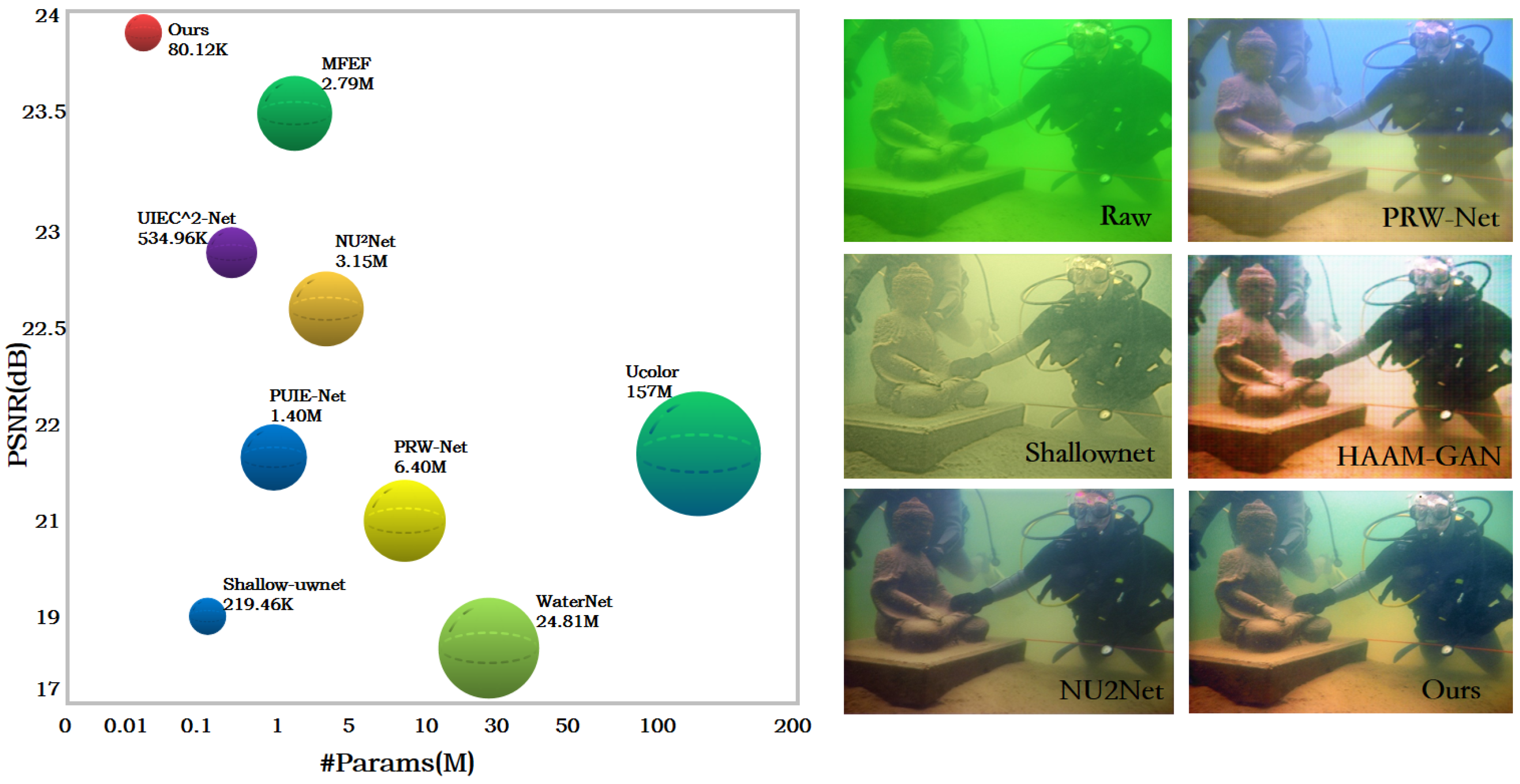
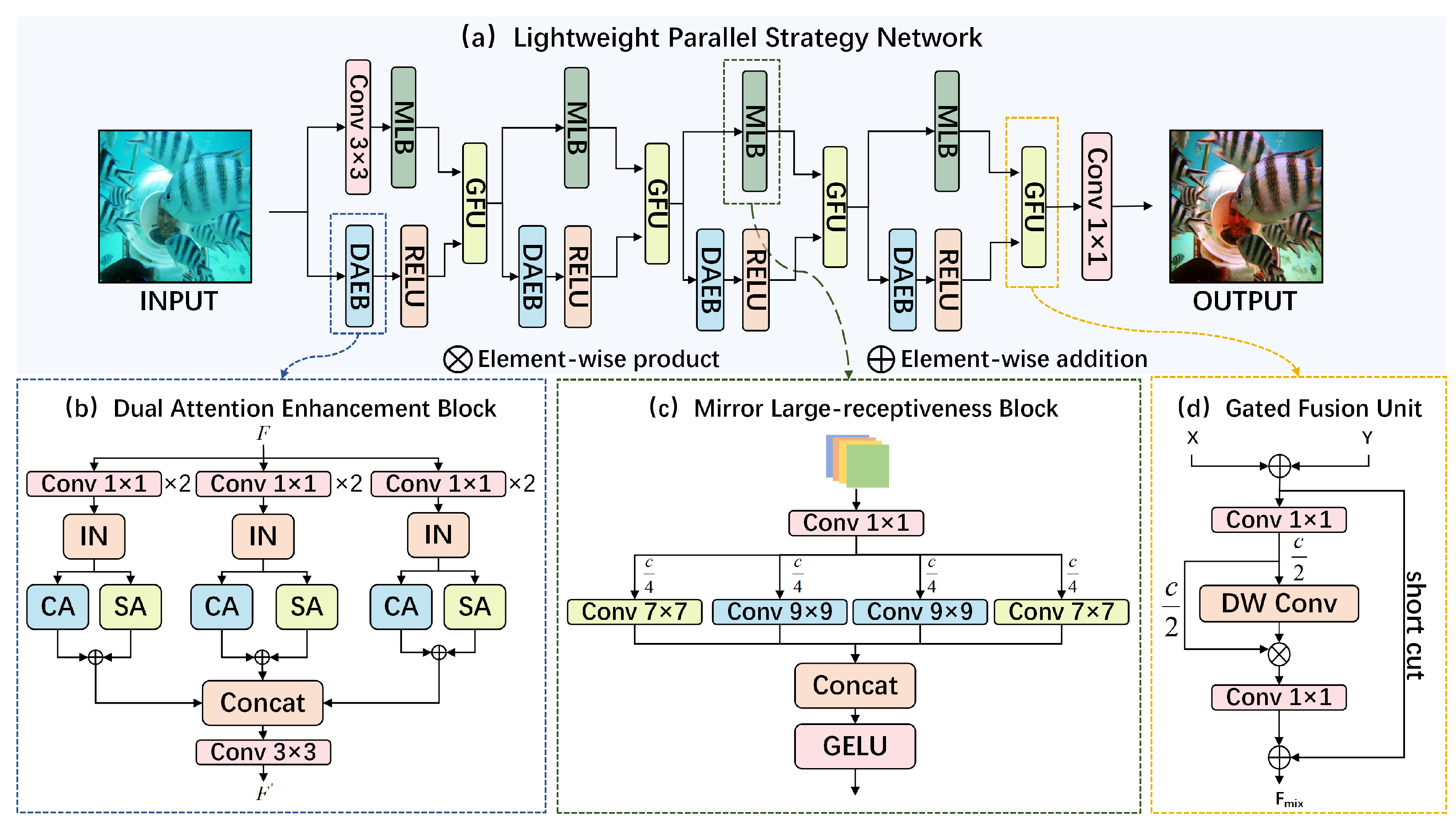
To address the above issues, we propose a Lightweight Parallel Strategy Network (LPS-Net) for underwater image enhancement. As shown in
Figure 1, LPS-Net achieves state-of-the-art underwater image enhancement performance with very few parameters. Specifically, a Dual-Attention Enhancement Block (DAEB) and a Mirror Large Receptiveness Block (MLB) are proposed to, respectively, enhance color and restore detail in degraded images. Problem splitting can avoid the use of complex modules, as well as reduce the amount of computation and parameters. With the aim of achieving remarkable image color and detail rendering, we repeatedly employed these blocks on parallel branches at each stage of LPS-Net and designed a Gated Fusion Unit (GFU) to combine features from different branches.
In water, different wavelengths of light have varying rates of attenuation, with red light attenuating the fastest and blue–green light attenuating the slowest. As a result, there are different degrees of degradation among the three channels of RGB images, but previous methods [
20,
21,
22] have not adequately addressed the hidden visual hazards caused by such differences. To deal with such degradation differences in the R, G, and B channels, the network should capture the distribution of color features across different channels. To this end, the incoming features are divided into three bands in the proposed DAEB. Each band passes through an Instance Normalization (IN) module, which will reduce the differences among different bands. Equipped with subsequent Channel Attention (CA) [
23] and Spatial Attention (SA) [
24], DAEB is bestowed with the ability to enhance the color of different color channels adaptively and separately.
To restore image details, a large receptive field in the UIE network is desired, since increasing the receptive field allows for more contextual information to be obtained. Inspired by the long-range modeling ability of ViTs [
25,
26], we adopted large-kernel convolutions to expand the receptive field for improving model performance, as exemplified by the remarkable ConvNet [
27], which employs 7 × 7 depthwise convolutions. Specifically, the proposed MLB uses four large-kernel convolutions with different kernel sizes. We conduct a series of ablation studies in
Section 5.2 and empirically set the kernel sizes in the MLB as
and
, respectively. Additionally, we constructed parallel branches using the DAEB and MLB as primary components, then applied the GFU to integrate features from different branches. Extensive experiments demonstrated that LPS-Net achieves state-of-the-art UIE performance while using only 80.12 k parameters.
Our main contributions in this paper are summarized as follows:
We propose the DAEB to capture the distribution of color features across the R, G, and B channels. IN can reduce the difference between channels, and by employing CA and SA, the network is able to enhance the color of degraded images at different levels.
We introduce a novel block named the MLB to focus on texture information in degraded images. With the large receptive field of the mirror-designed convolutional kernel, we were able to obtain more contextual information to restore fine details.
Our LPS-Net needs only 80.12 k parameters, making it well-suited for underwater devices with limited memory capacity. Extensive experiments demonstrated that LPS-Net achieves state-of-the-art UIE performance in terms of visual quality and evaluative metrics.
The remaining sections of this paper are organized as follows:
Section 2 reviews the traditional and deep-learning-based UIE methods. Subsequently, in
Section 3, we introduce the proposed LPS-Net.
Section 4 presents comprehensive qualitative and quantitative evaluations, aiming at comparing the efficacy of the proposed method against state-of-the-art approaches.
Section 5 provides ablation studies of each module within the network, while
Section 6 sheds light on the identified limitations and drawbacks. Finally,
Section 7 encompasses a concise summary of our work as well as expounds upon future avenues of research and broader implications.
4. Experiments and Analysis
This section firstly introduces the datasets used in the experiments: Underwater Image Enhancement Benchmark (UIEB) dataset [
5], non-reference underwater image dataset U45 [
48], and Enhancement of Underwater Visual Perception (EUVP) dataset [
43]. Secondly, we describe the experimental setup and implementation details. To demonstrate the feasibility and superiority of the proposed method, we compared LPS-Net with traditional methods [
9,
36,
49] and state-of-the-art deep learning underwater methods [
5,
14,
15,
16,
17,
18,
19,
22,
38,
40,
43,
50]. Finally, we conducted an analysis of the objective data presented in the tables and provide detailed visualizations to demonstrate the advanced and effective nature of our method.
4.1. Datasets
The UIEB dataset contains 890 high-resolution raw underwater images, corresponding high-quality reference images, and 60 challenge images (C60) for which no corresponding reference images were obtained. UIEB covers a variety of underwater scenes, and the image content covers a wide range of areas, such as marine life, divers, submarine corals, and coral reefs. The quality of underwater images is significantly lower. The creators of the dataset devised a method for generating high-quality reference images. Firstly, they applied twelve popular image-enhancement methods to generate enhanced results. Then, fifty volunteers were recruited to evaluate the quality of the enhanced results. The reference image for each original underwater image was determined by majority voting based on pairwise comparisons.
The U45 dataset consists of 45 degraded small images without reference images. Considering that the underwater enhancement task does not have publicly available datasets for a test like the single-image super-resolution task, Li et al. carefully selected 45 authentic underwater images, named U45. It is divided into three subsets of green, blue, and haze, where the subsets correspond to the color cast of underwater degradation, low contrast, and blur effects.
The EUVP dataset contains separate sets of paired and unpaired image samples of poor and good perceptual quality. The creators employed seven distinct camera models, including multiple GoPros, uEye cameras integrated into the Aqua AUV, low-light USB cameras, and high-definition cameras mounted on the Trident ROV, to capture the image data. The data acquisition occurred at diverse locations and under various conditions during marine exploration and robot navigation. In our experiments, two paired sets were used: Underwater Dark (5550 pairs) and Underwater ImageNet (3700 pairs).
4.2. Experimental Setup and Implementation Details
4.2.1. Experiment Details
All experiments were implemented under the Pytorch [
51] framework and accelerated on the NVIDIA RTX A100GPU (40GB). During training, the training epochs were set to 400, and the batch size was 30. We used the ADAM optimizer as the optimization algorithm. The learning rate was set to
first, and the default values of
and
were 0.5 and 0.999, respectively. We used CyclicLR to adjust the learning rate, with an initial momentum of 0.9 and 0.999. Data augmentation included horizontal flipping, random cropping, and randomly rotating the image to
, and
.
Throughout the training process, we standardized the resolution of both the input and output to . From the UIEB dataset, we randomly selected 800 pairs of original images and their corresponding clear images to compose the training set for our model. During the training validation phase, we employed the remaining 90 images from the UIEB dataset (referred to as T90) to evaluate our method’s performance on degraded images. For the formal testing stage, we continued to use the T90 dataset; however, in contrast to the training phase, we refrained from making any alterations to the format and size of the images, aiming to restore the model’s capability to enhance real underwater images. Furthermore, to assess the generalization capacity, we conducted evaluations using the C60 and U45 datasets with various methods. To assess the generalization capability of our model, some comparative experiments were conducted on the EUVP dataset. We used the ImageNet sub-dataset under the EUVP dataset to contain 3700 pairs of images for training and randomly sampled 1000 pairs of images from the Dark sub-dataset for testing.
4.2.2. Evaluation Metrics
For quantitative evaluations, several objective evaluation metrics were employed to assess the performance of the proposed underwater image enhancement method. These metrics served as references for measuring image quality in a comprehensive manner.
The first metric used was the Peak-Signal-to-Noise Ratio (PSNR) [
52], which is a well-established full-reference image quality evaluation metric. It quantifies the errors between corresponding pixels in the enhanced image and the reference image. A higher PSNR score indicates better image quality in terms of minimizing pixelwise errors.
To evaluate the visual quality of the enhanced images, the Structural Similarity Index (SSIM) [
53] was employed. The SSIM measures the similarity between the enhanced image and the reference image in terms of three key features: brightness, contrast, and structure. A higher SSIM value implies a higher perceptual similarity between the enhanced and reference images.
The Mean-Squared Error (MSE) [
54] was another metric used, which calculates the average squared difference between the pixels of the enhanced image and the reference image. A lower MSE value indicates better image quality, as it quantifies the overall distortion in the enhanced image compared to the reference image.
For a comprehensive evaluation of underwater image quality, two additional metrics were employed. The Underwater Color Image Quality Evaluation (UCIQE) [
55] metric primarily measures the degree of detail and color recovery in distorted images. It is considered one of the most-comprehensive image-evaluation standards for underwater images. The Underwater Image Quality Metric (UIQM) [
56] is specifically designed to assess color, sharpness, and contrast in underwater images. By considering both local and global image features, the UIQM offers a holistic evaluation of underwater image quality.
By utilizing these objective evaluation metrics, the proposed method aims to provide a quantitative assessment of its performance in terms of fidelity, perceptual similarity, color reproduction, detail recovery, and overall image quality. These metrics serve as valuable references to measure and compare the effectiveness of the proposed underwater image enhancement technique.
4.3. Compared Methods
We compared LPS-Net with state-of-the-art methods, including traditional methods and deep learning methods. Traditional methods included UDCP [
9], IBLA [
49], and MLLE [
36], and deep learning methods included UWCNN [
22], Water-Net [
5], PRW-Net [
15], Shallownet [
38], Ucolor [
14], UIEC⌃2-Net [
50], PUIE-Net [
16], FUNIE-GAN [
43], UHD-SFNet [
18], HAAM-GAN [
40], MFEF [
19], and the latest NU2Net [
17] for underwater image enhancement.
4.4. Quantitative Comparisons
We firstly performed a quantitative comparison on 90 images from T90, 60 images from C60, and 45 images from U45.
Table 1 gives the quantitative results of different methods. The PSNR, SSIM, and MSE were used as full-reference evaluation metrics and provided only the T90 test set, since T90 has ground-truth images. UCIQE and UIQM were used as non-reference evaluation metrics and provided for all test sets.
From
Table 1, it can be seen that our method achieved the best results in terms of the PSNR and MSE metrics on the T90 test set and the best results in terms of the UCIQE metric on all three test sets. Specifically, on the T90 test set with reference images, the proposed LPS-Net scored the best PSNR and MSE metrics and obtained the second-best SSIM metric, proving that the proposed network has achieved state-of-the-art UIE performance, and its network architecture is able to restore color and recover image details. Compared with the recently developed MFEF method, which roughly ranked second-best, LPS-Net led by 0.553 dB, 0.005, and 0.005 in terms of the PSNR, SSIM, and MSE.
On the other hand, higher UCIQE and UIQM values indicate better performance in terms of sharpness, color correction ability, and contrast in images. Among the evaluated methods, LPS-Net achieved the highest UCIQE values, demonstrating its efficacy in mitigating color shifts and enhancing sharpness. Although FUNIE-GAN and HAAM-GAN slightly outperformed our method in terms of the UIQM, a qualitative comparison revealed that GAN-based approaches suffered from localized exposure issues, leading to significant image distortions. Conversely, the enhanced results obtained by LPS-Net effectively addressed color biases without introducing additional degradation problems.
Apart from enhancement performance, efficiency is also very important for UIE methods.
Table 2 provides comparison results in terms of various efficiency metrics, including the number of computational operations measured in GFLOPs, the number of parameters, and runtime speed. It can be seen that LPS-Net needed only 0.08 M (80.12 k) parameters, substantially fewer than other methods, which is beneficial for deployment in equipment with limited memory capacity. In terms of GFLOPs, LPS-Net ranked the second-best, after UHD-SFNet, whose UIE performance was much worse compared to LPS-Net, as shown in
Table 1. Compared with Shallownet [
38], we reduced the parameters by more than 50% and reduced the time complexity by more than 71%, but the PSNR and SSIM were 5.627 dB and 0.06 higher, which fully proved the superiority and feasibility of our method. Although LPS-Net did not have the best runtime metric, taking into consideration its performance and efficiency overall, it can be concluded that LPS-Net achieved state-of-the-art underwater image enhancement performance while enjoying superior model efficiency.
Additionally, for the EUVP dataset, we employed the PSNR, SSIM, UCIQE, and UIQM as quantitative metrics to assess the recovery outcomes for more-extensive research. Notably, the results in
Table 3 produced by LPS-Net demonstrate excellent performance in terms of the PSNR, SSIM, and UICIQE, yielding the highest scores. This observation highlights the robustness and generalizability of LPS-Net for underwater image enhancement.
4.5. Visual Comparisons
In the case of the T90 dataset, a subset of images from the UIEB dataset was carefully chosen for conducting a visual comparison against seven state-of-the-art methods. These images were meticulously classified into various categories, encompassing yellow-toned, green-toned, blue-toned, low light, shallow-water areas, and deep-water areas.
Figure 3 and
Figure 4 showcase the performance of each method. Shallownet succeeded in enhancing contrast, but fell short in improving the quality of yellow-toned and green-toned underwater images. UWGAN exhibited notable improvements in yellow-toned images; however, oversaturation issues arose in many instances. PRW-Net’s applicability was limited across a wide range of scenarios, as it introduced additional chromatic aberrations or artifacts in deep-water areas and low-light conditions. UIEC⌃2-Net employed a multicolor spatial encoder for natural color processing, but inaccurate transmission map estimation resulted in contrast and saturation degradation. PUIE-Net and NU2Net encountered challenges with overall darkness and low contrast in a majority of the processed images. In contrast, our method effectively combines the strengths of multiple features, resulting in visually pleasing outcomes in terms of contrast, saturation, and detail processing.
Additionally,
Figure 5,
Figure 6 and
Figure 7 verify the generalization performance of LPS-Net, which can be finely enhanced for underwater degraded images of different qualities. Our method exhibited quite compatible color and detail recovery, enhancing the entire degraded image and making its contrast and texture details meet the sensory requirements of the human eyes. That is beneficial from our well-designed DAEB, MLB, and GFU.
Further, we also give an intuitive comparison with two previous SOTA methods on the EUVP dataset. As seen in
Figure 8 and
Figure 9, Shallownet was incapable of sufficiently restoring underwater images due to its straightforward network structure. On the other hand, NU2Net lacked precise color control, hence leading to visible chromatic deviations that can be noticed by the human eye. In contrast, our method was better at removing color casts and handling details.
6. Limitations and Error Cases
Despite demonstrating effectiveness and exceptional performance in underwater image enhancement tasks through experiments on multiple datasets, LPS-Net is still constrained compared to other tasks due to the challenges in collecting underwater datasets, resulting in insufficient dataset sizes and suboptimal model optimization. Specifically, LPS-Net may require further model design and optimization to overcome the overfitting issue caused by small datasets and improve its performance in handling complex underwater image details. For instance, the utilization of unsupervised training methods could eliminate the need for collecting a large number of expensive paired data. Additionally, although the proposed model is expected to exhibit efficiency and flexibility in underwater robotics, further experiments are needed to validate its performance and reliability in practical applications.
Besides, in some uncommon cases, where the degraded images appear to be pink or orange, the DAEB, which was designed to process individual color channels, cannot effectively handle these particular colors, leading to unsatisfactory enhancement results. In the future, we will consider incorporating more color-processing branches to address the challenges posed by complex and diverse color environments.
7. Conclusions and Future Work
This work proposes a Lightweight Parallel Strategy Network for underwater image enhancement. By introducing a Dual-Attention Enhancement Block and a Mirror Large Receptiveness Block, we addressed the mixed degeneracies of color distortion and the loss of detail in underwater raw images. LPS-Net utilizes these components as the building blocks of parallel branches and employs Gated Fusion Units to fuse features from different branches. Extensive experiments demonstrated that LPS-Net achieved state-of-the-art underwater image enhancement performance in terms of visual quality and evaluative metrics, while using only 80.12 k parameters. The success of LPS-Net proves that tackling mixed degradations by dividing them into sub-problems has the potential of avoiding the use of complex modules and reducing the amount of computation and parameters.
Despite the superiority of LPS-Net, there is still room for improvement. Looking ahead, we plan to incorporate frequency domain operations into LPS-Net since processing information in the Fourier space is capable of capturing the global representation in the frequency domain, while normal convolution focuses on learning local representations in the spatial domain. Another direction is to take advantage of both visual transformers and CNNs. It is worth investigating how to bring the merits of transformers while achieving a good balance between UIE performance and model complexity.
The proposed LPS-Net demonstrated impressive performance in real-world underwater image enhancement, making it beneficial for other downstream vision applications, such as underwater photography, underwater archeology, and marine biological survey. We also plan to investigate whether LPS-Net can be adapted to other image-restoration tasks [
58], such as image dehazing and image deraining. Of course, efforts should be made to tackle mixed degradations in these tasks by dividing them into sub-problems that could be effectively addressed.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}