

P System Design for Integer Factorization


Abstract
:1. Introduction
2. Foundation
2.1. Cell-like P System
- The system has a global clock to coordinate the synchronized execution of evolutionary rules, and the timing unit is the time slice;
- Non-deterministic. Suppose n rules compete for objects that can only support k (k < n) rules, then the choice of these k rules is uncertain;
- Maximum Parallelism. At any moment, all executable rules must be executed. In other words, all executable rules are executed in parallel in each time slice of the computation;
- The execution of any rule requires and takes only one time slice. In particular, in a time slice when a rule can be repeatedly executed multiple times, the multiple executions of the rule are also completed in one time slice, i.e., the multiple executions of the rule are parallel.
2.2. Integer Factorization
2.3. Extended P System
3. Integer Factorization Algorithm
3.1. Periodic Function
3.2. Parallel Algorithm for Integer Factorization
| Algorithm 1 Prime Factorization Algorithm for Large Numbers (PFLN) |
| Input: N; // An integer N > 4 |
| Output: p, q; // (p×q = N) |
| procedure PFLN (Number N) |
|
| Algorithm 2 FMEP&PF // Finding the minimum even period and the prime factor |
| Input: a, N; |
| Output: p, q; |
|
4. P System Design of Integer Factorization
4.1. Definition of P System for Integer Factorization
- O = {ξN, a, b, c, d, e, f, g, h, i, k, ξ1, ξ2, p, q, q1, q2, r, v, w, w’, y1, y2, y3, y4, z, z1, z2}, where N refers to the size of the number to be decomposed;
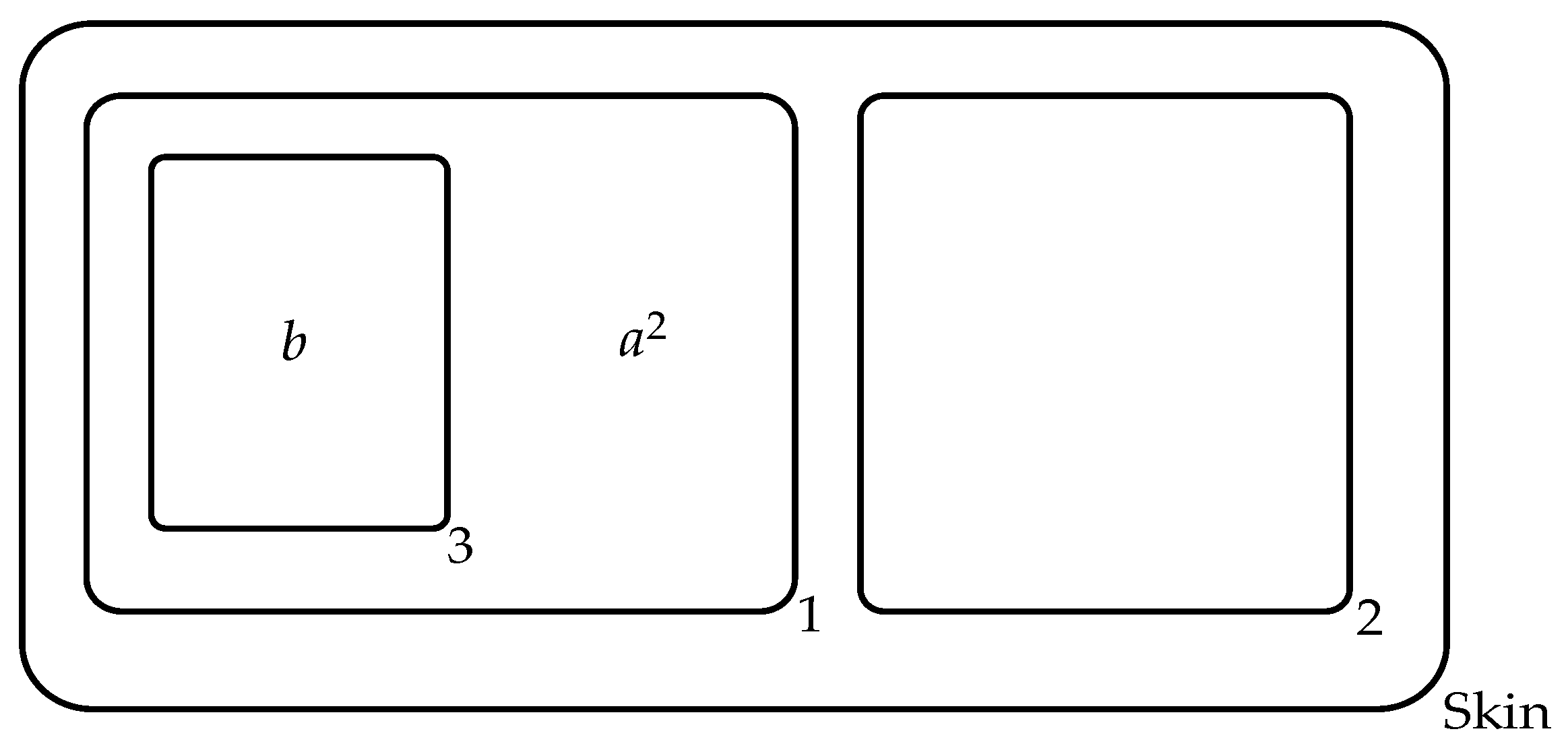
- μ = [[[ ]GCD1 [ ]GCD2]Com]Skin;
- ωSkin = λ, ωCom = { a, d2, ξN }, ωGCD = λ;
- RSkin = λ;RCom = { z → z1 z2|c; c → d; z1 → z z1|z2; d z2 → d; d → e|¬z2; z1 → y y2|e; z → v z2|e; e → c; v c → p f, 1; vn → λ, 2; v → i f, 3; f → z1|i; p → g h|i; y → y1|i; i → λ; z1 → z z1|z2; g z2 → g q1, 1; y1→ y y1|y2; h y2→ h q2, 1; g→ w r2, 2; h→ λ, 2; z→ v|w; q1→ z2|w; z1→ λ|w; q2→ y2|w; y1→ λ|w; w→ c; p→ τ w’(k, out)|¬i; y → y3 y4|⌐v ⌐i; y3→ (in GCD1); y4→ (in GCD2); ξ → ξ1 ξ2; ξ1→ (in GCD1); ξ2→ (in GCD2);}; RGCD = λ;
- The priority of the rules in , …, can be seen in the rules in RCompute, …, RA.
4.2. Rules and Procedures for Integer Factorization of P Systems
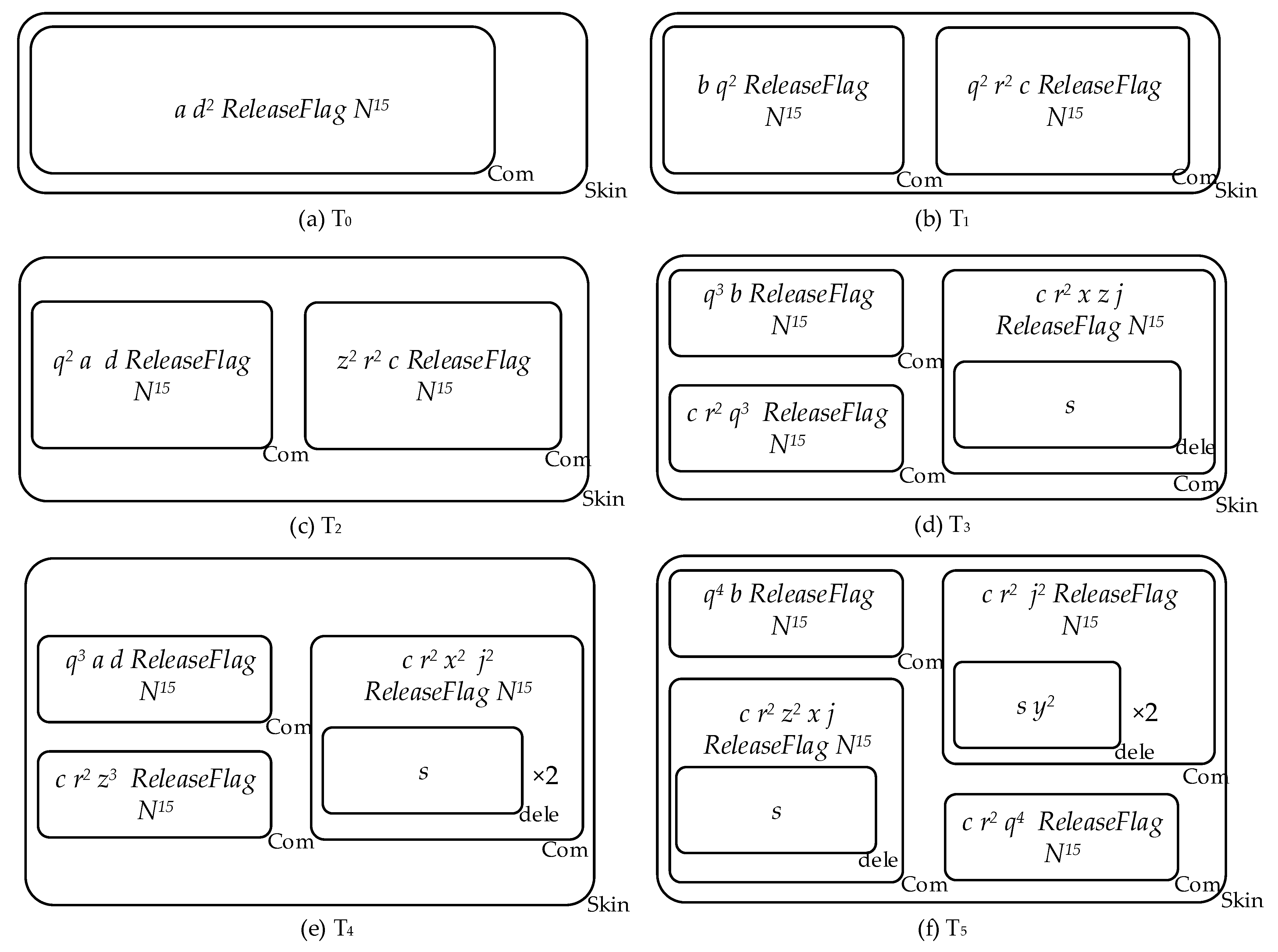
4.2.1. Main Process
4.2.2. Flag Objects and Their Life Cycle
4.2.3. Splitting and Calculation Process
5. Cases and Experiments
5.1. Instance of UPLanguage
5.2. Cases
5.3. Experimental Results
6. Conclusions
- The membrane structure can continue to be optimized, and a dedicated simulator can be established to test on larger data samples;
- The P system has variants of various biological mechanisms. How to introduce these variants into the current model to improve its performance is worth considering.
- Whether the hit rate of the periodic function has a mathematical law is still a question that can be discussed, which is related to the size of the space when the P system is executed. In this way, it can be determined whether a stable space complexity can be found when performing the integer factorization problem.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Păun, G. Computing with Membranes. J. Comput. Syst. Sci. 2000, 61, 108–143. [Google Scholar] [CrossRef] [Green Version]
- Wu, T.; Zhang, Z.; Păun, G.; Pan, L. Cell-like Spiking Neural P Systems. Theor. Comput. Sci. 2016, 623, 180–189. [Google Scholar] [CrossRef]
- Păun, G. Introduction to Membrane Computing. In Applications of Membrane Computing; Ciobanu, G., Păun, G., Pérez-Jiménez, M.J., Eds.; Natural Computing Series; Springer: Berlin, Heidelberg, 2005; pp. 1–42. ISBN 978-3-540-25017-3. [Google Scholar]
- Martín-Vide, C.; Păun, G.; Pazos, J.; Rodríguez-Patón, A. Tissue P Systems. Theor. Comput. Sci. 2003, 296, 295–326. [Google Scholar] [CrossRef] [Green Version]
- Ionescu, M.; Păun, G.; Yokomori, T. Spiking Neural P Systems. Fundam. Informaticae 2006, 71, 279–308. Available online: https://content.iospress.com/articles/fundamenta-informaticae/fi71-2-3-08 (accessed on 26 December 2022).
- Krishna, S.N. Universality Results for P Systems Based on Brane Calculi Operations. Theor. Comput. Sci. 2007, 371, 83–105. [Google Scholar] [CrossRef] [Green Version]
- Ibarra, O.H.; Paun, G. Membrane Computing: A General View. Ann Eur Acad Sci. EAS 2006, 83–101. Available online: https://citeseerx.ist.psu.edu/document?repid=rep1&type=pdf&doi=9095c58d493590de047aa4af8f4ceeba8043dca2 (accessed on 3 January 2023).
- Muniyandi, R.C.; Mohd Zin, A. Modeling Framework for Membrane Computing in Biological Systems: Evaluation with a Case Study. J. Comput. Sci. 2014, 5, 137–143. [Google Scholar] [CrossRef]
- Singh, G.; Deep, K. A New Membrane Algorithm Using the Rules of Particle Swarm Optimization Incorporated within the Framework of Cell-like P Systems to Solve Sudoku. Appl. Soft Comput. 2016, 45, 27–39. [Google Scholar] [CrossRef]
- Rivest, R.L.; Shamir, A.; Adleman, L. A Method for Obtaining Digital Signatures and Public-Key Cryptosystems. Commun. ACM 1978, 21, 120–126. [Google Scholar] [CrossRef] [Green Version]
- Briggs, M.E. An Introduction to the General Number Field Sieve. Ph.D. Thesis, Virginia Tech, Blacksburg, VA, USA, 1998. Available online: http://hdl.handle.net/10919/36618 (accessed on 14 February 2023).
- Gupta, S.; Paul, G. Revisiting Fermat’s Factorization for the RSA Modulus. arXiv 2009, arXiv:0910.4179. [Google Scholar]
- Leporati, A.; Zandron, C.; Mauri, G. Solving the Factorization Problem with P Systems. Prog. Nat. Sci. 2007, 17, 471–478. [Google Scholar] [CrossRef]
- Murakawa, T.; Fujiwara, A. Arithmetic Operations and Factorization Using Asynchronous P Systems. IJNC 2012, 2, 217–233. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Obtułowicz, A. On P Systems with Active Membranes Solving the Integer Factorization Problem in a Polynomial Time. In Proceedings of the Multiset Processing; Calude, C.S., Păun, G., Rozenberg, G., Salomaa, A., Eds.; Springer: Berlin, Heidelberg, 2001; pp. 267–285. [Google Scholar]
- Zhang, X.; Niu, Y.; Pan, L.; Pérez-Jiménez, M.J. Linear Time Solution to Prime Factorization by Tissue P Systems with Cell Division. Nat. Comput. Simul. Knowl. Discov. 2014, 207–220. [Google Scholar]
- Liu, X.; Li, Z.; Suo, J.; Liu, J.; Min, X. A Uniform Solution to Integer Factorization Using Time-Free Spiking Neural P System. Neural Comput. Appl. 2015, 26, 1241–1247. [Google Scholar] [CrossRef]
- Shor, P.W. Algorithms for Quantum Computation: Discrete Logarithms and Factoring. In Proceedings of the 35th Annual Symposium on Foundations of Computer Science, Santa Fe, NM, USA, 20–22 November 1994; pp. 124–134. [Google Scholar]
- Păun, G. Computing with Membranes (P Systems): A Variant. Int. J. Found. Comput. Sci. 2000, 11, 167–181. [Google Scholar] [CrossRef]
- Bottoni, P.; Martín-Vide, C.; Păun, G.; Rozenberg, G. Membrane Systems with Promoters/Inhibitors. Acta Inform. 2002, 38, 695–720. [Google Scholar] [CrossRef]
- Van Den Dries, L.; Moschovakis, Y.N. Is the Euclidean Algorithm Optimal Among Its Peers? Bull. Symb. Log. 2004, 10, 390–418. [Google Scholar] [CrossRef] [Green Version]
- Guo, P.; Quan, C.; Ye, L. UPSimulator: A General P System Simulator. Knowl.-Based Syst. 2019, 170, 20–25. [Google Scholar] [CrossRef]
- Li, Z.; Gasarch, W. An Empirical Comparison of the Quadratic Sieve Factoring Algorithm and the Pollard Rho Factoring Algorithm. arXiv 2021, arXiv:2111.02967. [Google Scholar]
- Wang, Q.; Fan, X.; Zang, H.; Wang, Y. The Space Complexity Analysis in the General Number Field Sieve Integer Factorization. Theor. Comput. Sci. 2016, 630, 76–94. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Rounds | Time Slip | Objects in the Membranes | |
|---|---|---|---|
| Round 1 (calculate the case of |z| = 2) | T0 | a d2 | |
| T1 | b d2 | c r2 d2 | |
| T2 | b z2 | c r2 z2 | |
| T3 | a b z2 | c r2 z2 | |
| Round 2 (calculate the case of |z| = 3) | T0 | a b d2 | |
| T1 | b d z2 | c r2 d z2 | |
| T2 | b z3 | c r2 z3 | |
| T3 | a d z3 | c r2 z3 | |
| Round 3 (calculate the case of |z| = 4) | T0 | a d z3 | |
| T1 | b d z3 | c r2 d z3 | |
| T2 | b z4 | c r2 z4 | |
| T3 | a d z4 | c r2 z4 | |
| Rules | a2×1(32) | a1(31) | a2×2(34) | a2(32) |
|---|---|---|---|---|
| c r2 z3 | ||||
| z → z1z2|c; c → d; | d r2z13z23 | |||
| z1 → z z1|z2; d z2 → d; | r2z9z13d | |||
| d → e|¬z2; | r2z9z13e | |||
| z1→ y y2|e; z → v z2|e; e → c | r2c v9z29 | y3 y23 | ||
| v c → p f, 1; | r2p f v8z29 | y3 y23 | r4, p, f, v80, z29 | y9, y23 |
| vn → λ, 2; | r2p f v8z29 | y3 y23 | r4, p, f, v5, z29 | y9, y23 |
| v → i f, 3; | r2p f9i8z29 | y3 y23 | r4, p, f6, i5, z29 | y9, y23 |
| f → z1|i; p → g h|i; y → y1|i; i → λ; | r2g z19z29 | h y13 y23 | r4, g, z16, z29 | h, y19, y23 |
| z1 → z z1|z2; g z2→ g q1, 1; y1→ y y1|y2; h y2→ h q2, 1; | r2g z81z19q19 | h y9y13q23 | r4, g, z54, z16, q19 | h, y27, y19, q23 |
| g→ w r2, 2; h→ λ, 2; | r4w z81z19q19 | y9y13q23 | r6, w, z54, z16, q19 | y27, y19, q23 |
| z→ v|w; q1→ z2|w; z1→ λ|w; q2→ y2|w; y1→ λ|w; w→ c | r4c v81z29 | y9y23 | r6, c, v54, z29 | y27, y23 |
| Algorithm | Time Complexity | Space Complexity |
|---|---|---|
| General Number Field Sieve (GNFS) | -.1 | |
| Shor’s algorithm | O((log n)3loglog n logloglog n) | O(log n) |
| Pollard’s rho algorithm [23] | ) | O(1) |
| ours(PFLN) | O(nlog n) | O(n) 2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nan, H.; Xue, Z.; Li, C.; Zhou, M.; Liu, X. P System Design for Integer Factorization. Appl. Sci. 2023, 13, 8910. https://doi.org/10.3390/app13158910
Nan H, Xue Z, Li C, Zhou M, Liu X. P System Design for Integer Factorization. Applied Sciences. 2023; 13(15):8910. https://doi.org/10.3390/app13158910
Chicago/Turabian StyleNan, Hai, Zhijian Xue, Chaoyue Li, Mingqiang Zhou, and Xiaoyang Liu. 2023. "P System Design for Integer Factorization" Applied Sciences 13, no. 15: 8910. https://doi.org/10.3390/app13158910