As previously depicted, the goal of meta-learning is to train a model that suits a collection of tasks; such a
meta-model works well on any task from this collection. Assume we are given
T tasks for training, and the data are denoted as
. Inputs are denoted as
x and outputs as
y.
can be elaborated as training data
and test data
. According to [
3], we denote the training samples as the
support set and the test samples as the
query set. For each task
,
. We revisit the classical hierarchical variational Bayes probabilistic model in this section, and propose using the amortized Bayesian meta-learning scheme by implementing a function of
as the variational posterior.
3.1. Probabilistic Model
According to the classical hierarchical variational Bayes theory discussed in [
10], the marginal likelihood of a hierarchical Bayes model is written in Equation (
1) as follows:
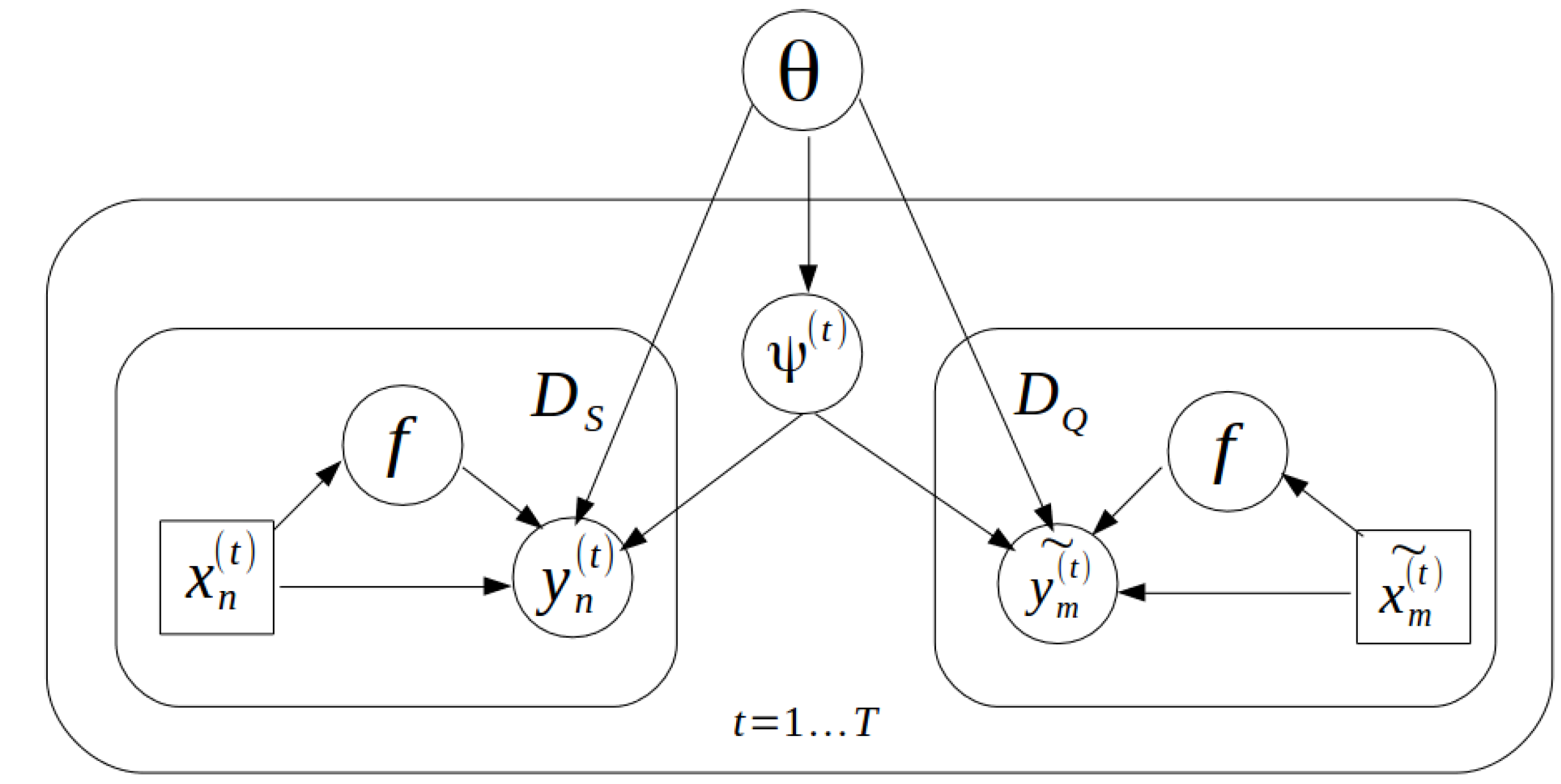
Its generative process is shown as a directed graphical model in
Figure 2, where
is denoted as the global latent variable. For each task
t, a task-specific parameter
is sampled from its priority
. Hierarchical variational inference can be used to estimate the lower bound of the likelihood in Equation (
2) as follows:
where
is denoted as the
evidence lower bound (ELBO) on the log version.
is the introduced variational distribution with parameter
. Given
, variational inference solves the following optimization problem:
Note that the optimization process in (
3) results in heavy computational costs since it has to optimize
T-different variational distributions
when
T is large. To overcome this shortcoming, we introduce a
transductive amortization network
that takes
as input, and it outputs the variational distribution
. Here, we use
to represent samples in
for short. The idea of amortized variational inference (AVI) was first introduced in [
26] as a trainable autoencoder that produces variational parameters for each data point, and has been extended to Bayesian variational inferences [
27]. Assume that
follows the Dirac delta distribution (e.g.,
), where
. For the
k-th stochastic gradient descent iterate:
where
denotes the descent step size. By conducting this optimization process up to the
K-th step, such that
, this guarantees that
is a good approximation to its optimal value
. In summary, the optimization process contains the following two steps:
Let
denote the loss function between the ground truth
and the predicted value
for task
t; we provide the gradient decomposition as follows:
Next, replacing each
in (
3), the optimization problem now becomes:
In conclusion, the meta-model is optimized with the feature network f and the hyperparameter from the Bayes formulation, together with the transductive amortization network .
3.2. Fast Transductive Inference with the Synthetic Inference Network
We now introduce the proposed synthetic neural network for fast transductive inference. A side-by-side comparison between MAML and our method is displayed in
Figure 3. In MAML, the global parameter
is given an initialization according to its previous update, and it optimizes for a representation of
that can quickly adapt to new tasks. In our method, we first introduce a transductive neural network
that outputs an initial distribution
for different tasks
t. Next, we propose a trainable synthetic inference network (SIN), which takes features of
as the input and outputs its inferred parameters
for the refined variational distribution
. Then, the refined latent variable
is formed by sampling from
. With a few iteration steps,
can reach
, converging to
.
The details of SIN are given below. We let meta-parameter
, where
,
represent the mean and variance, respectively. For
task-specific parameter
, its weight follows the normal distribution in Equation (
7):
and the prior
is written in Equation (
8):
where
follows the Dirichlet distribution with a symmetric prior
.
,
denote the mean and precision matrix for the normal distribution, and
and
represent the scale matrix and its freedom degree for the Wishart distribution. Note that when
, Wishart reduces to the Gamma distribution in Equation (
9):
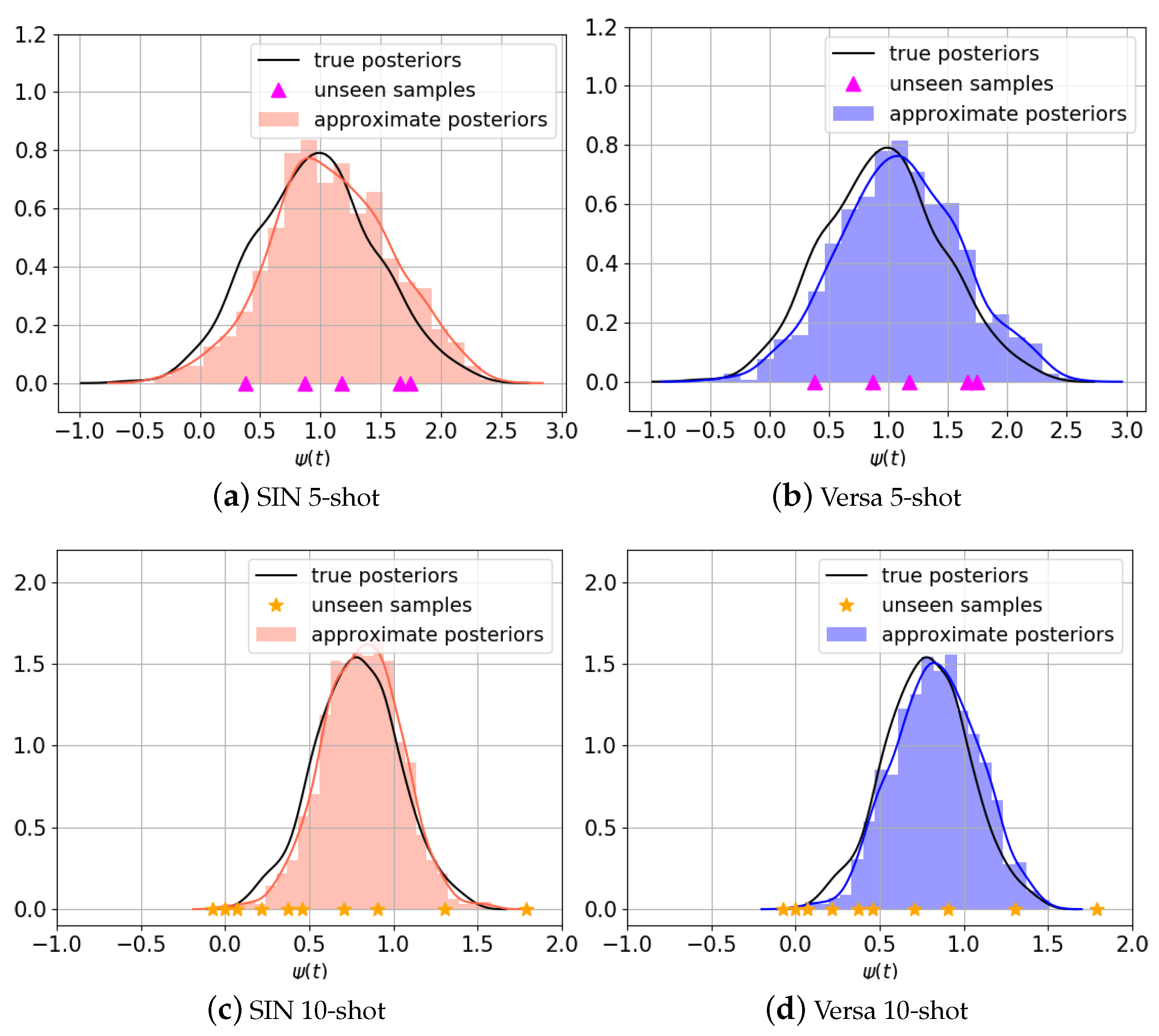
Note that the exact posterior
is a mixture of
T distributions. We use the standard variational Bayes (VB) approximation to the posterior:
Meanwhile, it attempts to maximize the following lower bound:
For a detailed overview of the proposed meta-training with the SIN framework, we show a computational graph in
Figure 1. A teacher–student network architecture is proposed for the fast convergence training of
. SIN is treated as an online trainable neural network with the stochastic gradient descent (SGD) network as its teacher network. Note that the learnable parameter of SIN is the inference parameter
for distribution
, where
denote parameters for the normal and Wishart distributions in (
8). In fact, when
, the Wishart distribution reduces to the Gamma distribution. Hence,
where
and
and
are the alpha and beta parameters for the gamma distribution. Note that
,
, where
.
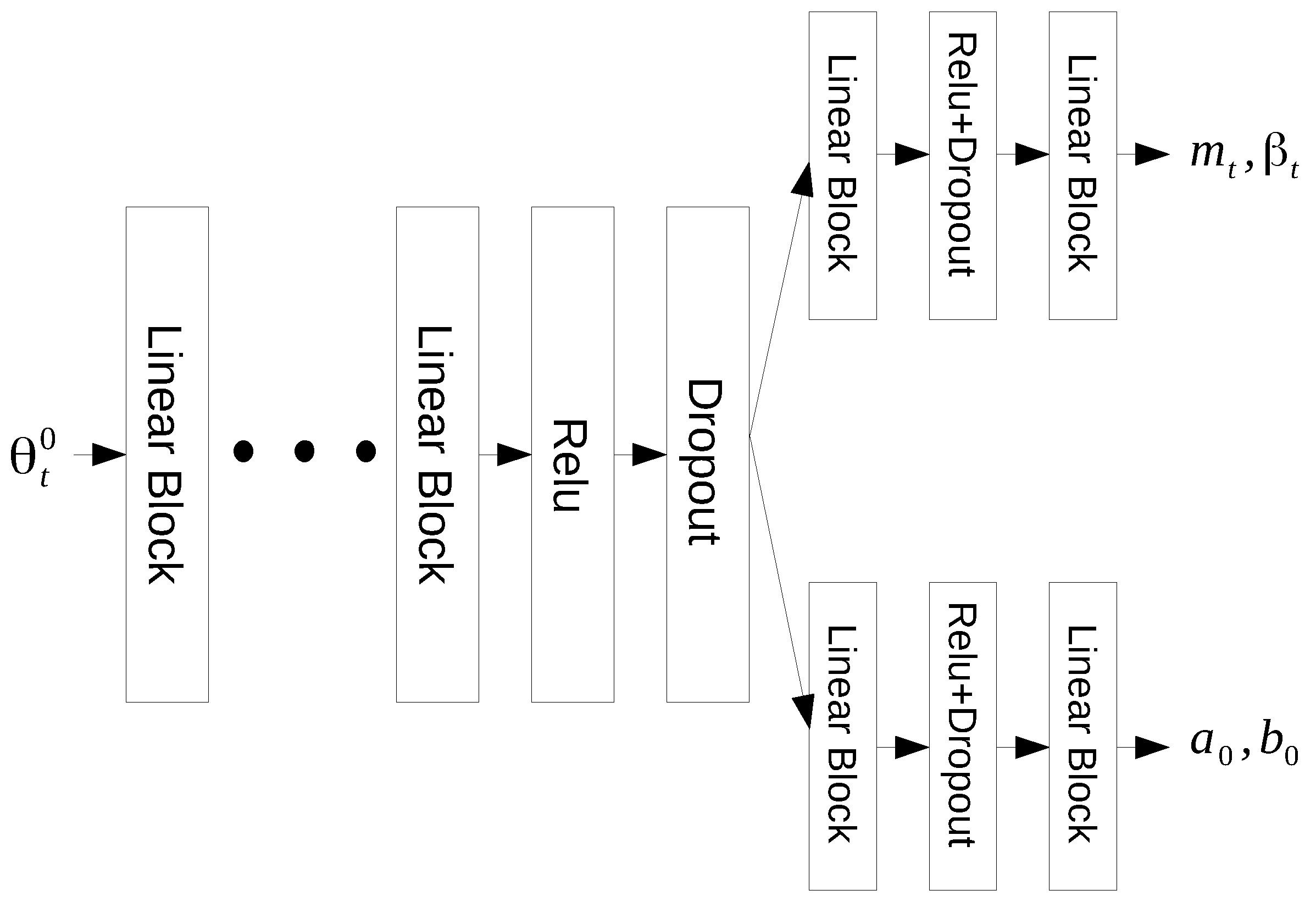
In our work,
represent
T-way meta parameters as learnable initializations. The neural network
takes the feature network output
as input, and
is treated as the weight initialization network. Each task-specific parameter
is passed through SIN to acquire
. The proposed network structure is displayed in
Figure 4 as a brief overview. It follows a multi-task learning structure, where the common network layers are denoted as the shared layers, while the last two separate layers output the two predicted groups of
. Observe that SIN follows the online supervised learning scheme, where its training data
. In
Figure 1, one can find that
is acquired through the variational Bayes inference with expectation maximization (VBEM). The EM method is introduced to maximize the lower bound of
, where
is obtained from the SGD network with
K-descent steps. As for the loss function, we use the simple MSE loss:
where
and
.
is the weight factor whose value is set to
as default.
A detailed description of the proposed amortized Bayesian meta-training is depicted in Algorithm 1. The algorithm starts with the initializations of some meta-models, such as
,
, and
f. For each task
t, it computes
via fast gradient descent steps, mixing SIN with the SGD network. It first uses the standard SGD network to obtain
. Meanwhile, the SGD network is used as a teacher network for training SIN. When the training process is valid, the output variable
sampled from SIN can reach
through fewer descent steps. After
T training tasks are processed as the epoch, the transductive amortization network
is updated with the feature network
f that has been fine-tuned. Notice that
denotes an online training loss threshold, which indicates that the model can use the learned amortized network output
for fast training. When the training process begins, SIN introduces a teacher–student network architecture for the prediction of
(after
k steps, the gradient descent of SGD). It uses a linear artificial neural network (ANN) to learn the specific latent parameters
related to
. The parameter set
represents parameters for normal and Wishart distributions in Equation (
8). Note that we use these latent parameters to represent the posterior distribution of
, which maximizes the following lower bound given in Equation (
11). We first train both teacher and student networks in
steps (
), after the student network learns the representation of the teacher network, then we use the inference of the student network directly to output
. Note that
is obtained by the VBEM method of
. We generate the new
sampled from
and then assign it to
for a middleware descent output. By applying a modest number of descent steps, where
, the learned latent variable
of the meta-learner can converge to the optimal point.
| Algorithm 1 Amortized Bayesian meta-training with SIN. |
- Require:
the dataset ; learning rate ; iteration number K; number of tasks T. - 1:
Initialize meta-model , ( 8). - 2:
Initialize the transductive amortization network and the pre-trained feature network f. - 3:
Initialize loss function for T tasks of SIN. - 4:
while not converged do - 5:
for t = 1 to T do - 6:
Sample a task t’s data with its related support set and query set . - 7:
Compute , where . - 8:
if then - 9:
Compute sampled from the output of SIN, assign sampled from . - 10:
for do - 11:
Compute via ( 4) with learning rate - 12:
end for - 13:
else - 14:
for do - 15:
Compute via ( 4) with learning rate - 16:
end for - 17:
end if - 18:
Implement the VBEM method for to compute the inferred parameter . - 19:
Update with () iterations, where denotes the weight of SIN. - 20:
end for - 21:
Update . - 22:
Optionally, fine-tune . - 23:
end while
|
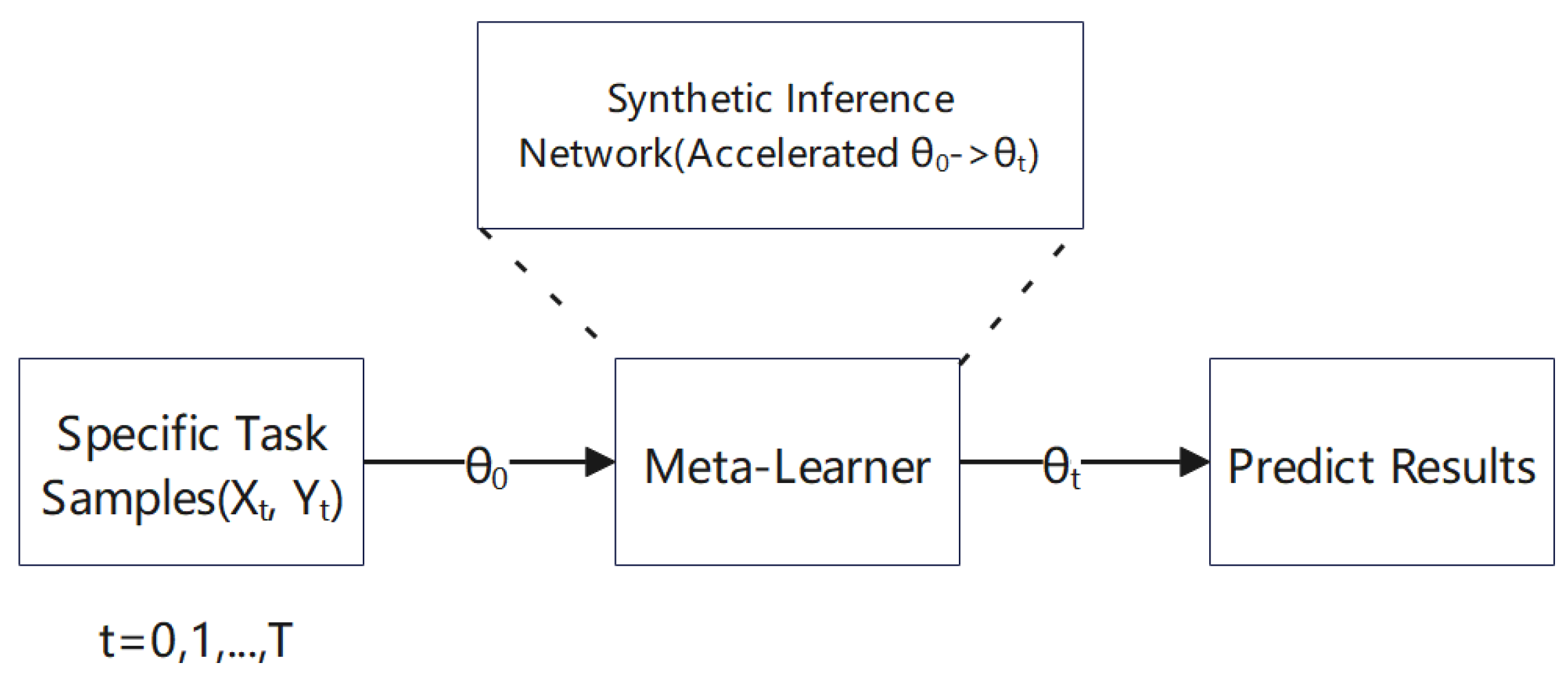
To summarize the architecture of the proposed ABML-SIN model, we provide a clear learning structure of our model, depicted in
Figure 5. We can see that the architecture of ABML-SIN is embedded into the meta-learner module. It helps the meta-learner to quickly infer the learned latent posterior
for task
t based on the prior
. ABML-SIN provides an amortized synthetic inference network (ASIN) to use the pre-trained student network for fast
output. For different task numbers
, the inference network outputs different posterior values
related to the prediction results.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}