
Low Complexity Deep Learning Framework for Greek Orthodox Church Hymns Classification

 , ,
, ,  , and
, and 
Abstract
:1. Introduction
- Three novel DL models based on convolution operation are designed for Greek Orthodox Church hymns classification. A novel Visual Geometry Group (VGG) approach is presented, namely Micro VGG, which is custom-made for this problem and outperforms the other custom architectures. Micro VGG is lightweight and its fast convergence makes it suitable for mobile applications.
- Five state-of-the-art (SOTA) models are tested on the problem of Greek Orthodox Church hymns classification. A comparison study between the different DL approaches is conducted, both in terms of prediction accuracy and in terms of computational cost.
1.1. Related Work
1.2. Organization of the Article
2. Materials and Methods
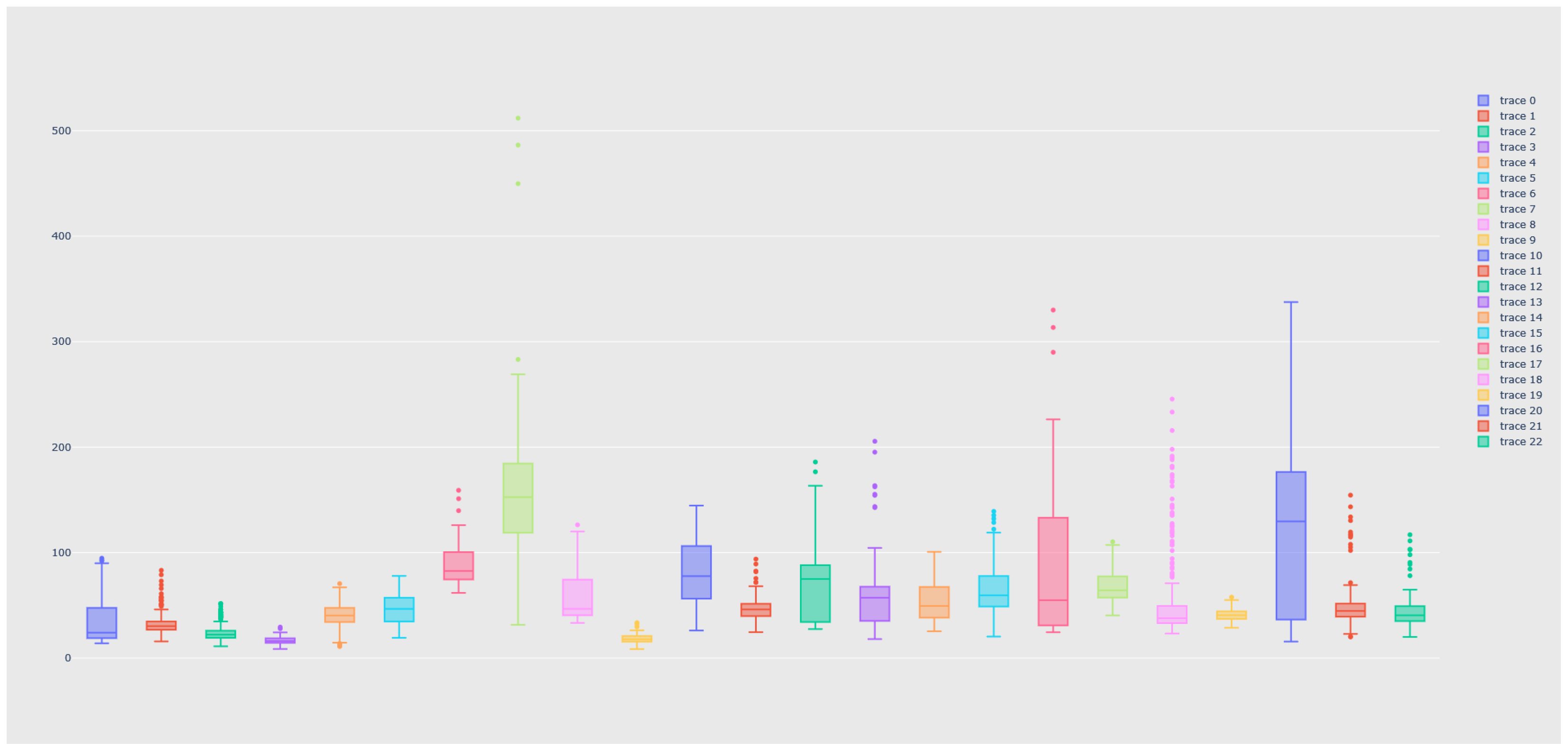
2.1. Data Generation
2.2. Data Processing
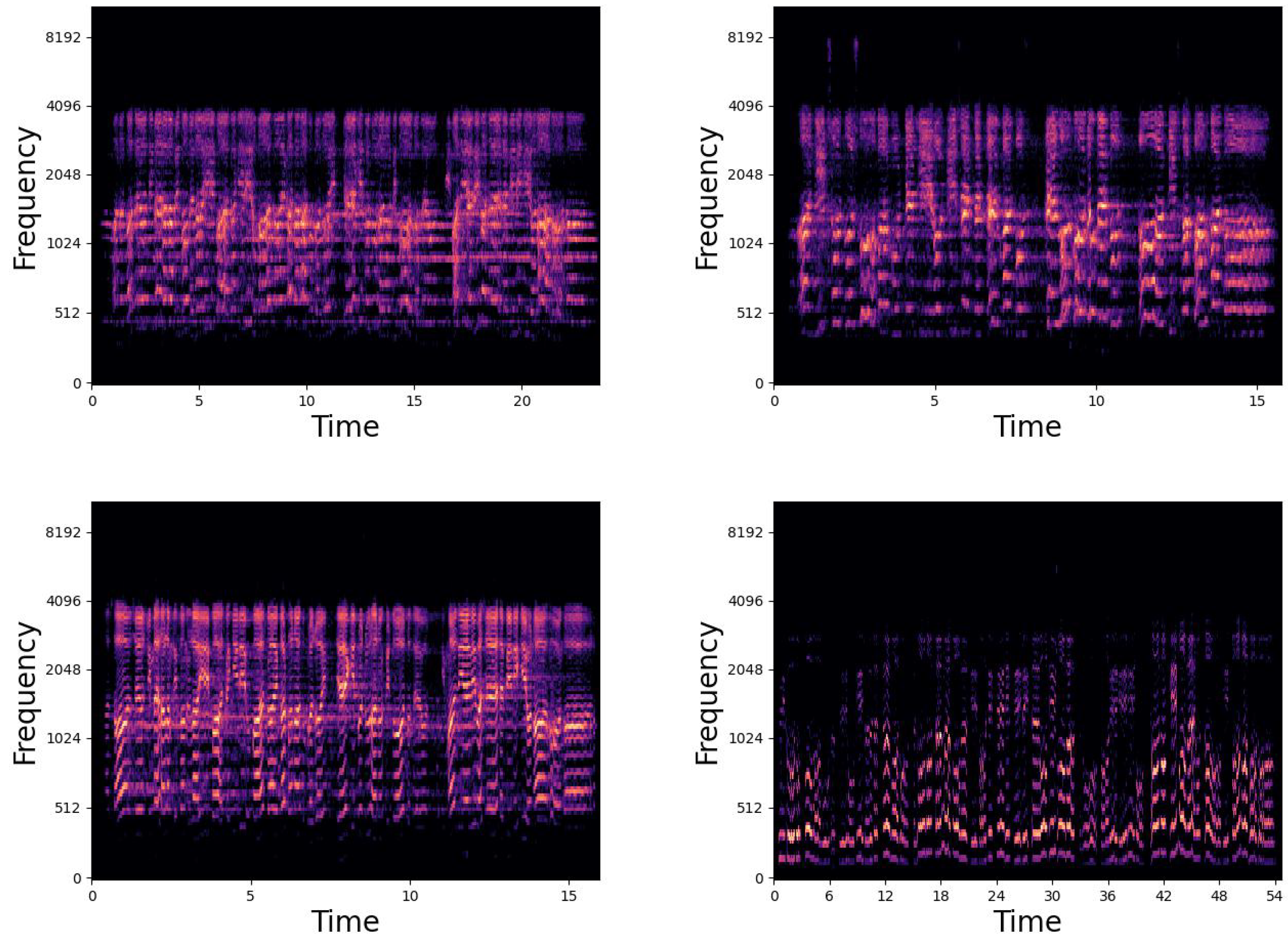
2.2.1. Mel-Spectrograms
2.2.2. Data Processing and Augmentation
| Algorithm 1 TA algorithm |
|
Dataset with M images while do Pick an image Sample augmentation f from Sample a strength value s Return end while |
- Time warping: From a uniform distribution with range , a starting point and a displacement coefficient d are sampled. A linear warping function is defined, such that the point is mapped to the point . Time warping is defined in such a way that the warped features at time t are related to the original features by the following equation:
- Frequency masking: Given a uniform distribution with a range from 0 to , a mask of size f is randomly chosen. Then, a value is chosen from the interval and the consecutive log-Mel frequency channels are masked.
- Time masking: Given a uniform distribution with a range from 0 to , a mask size is randomly chosen. Then, a value is chosen from the interval and the consecutive time steps are masked.
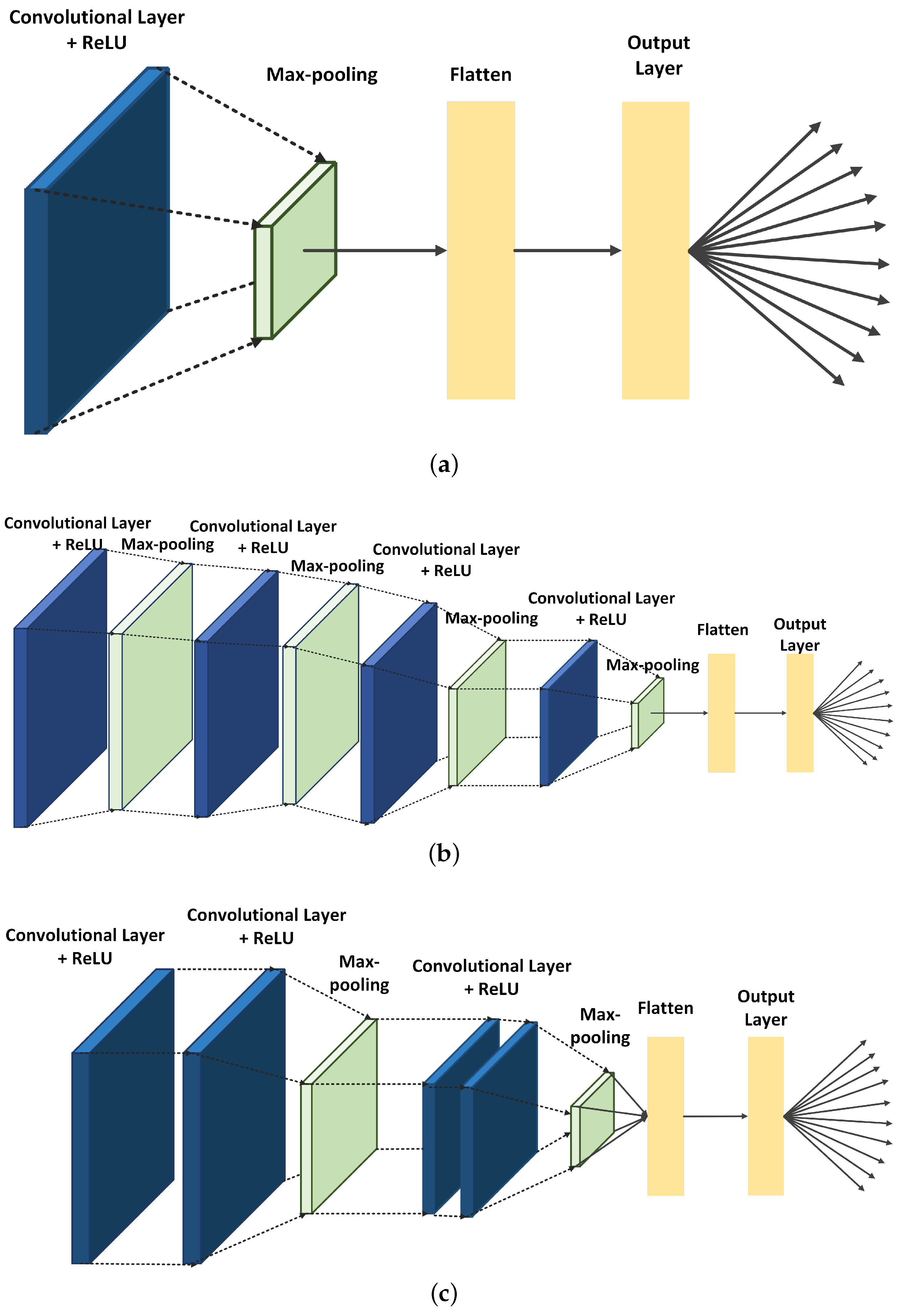
2.3. CNN Architectures
- Input layer: This layer accepts the input data in a form suitable for further processing. Usually, the image data are transformed into multi-dimensional arrays with three color channels.
- Convolution layer: Convolution layers are the building blocks of any CNN architecture. They perform the process of feature extraction. The main difference with a fully connected layer is that convolutional layers are characterized by the neuron’s receptive field. This receptive field indicates that every single unit receives input from only a restricted area of the previous layer.
- Activation function: In the academic literature, the majority of the CNN architectures use as an activation function; either a rectified linear unit (ReLU) function or some kind of a variant. ReLU is mathematically defined as in [6]
- Pooling layer: Their purpose is to reduce the size of the incoming data in a computationally efficient manner.
- Flattening: This layer transforms the data into a 1D vector.
- Output layer: This layer outputs the model’s prediction.
Weights Initialization
2.4. Performance Metrics
- Accuracy is defined as the fraction of correct predictions. It is expressed mathematically asM is the number of test classes, denotes the ML model class predicted label, is the true class label, and represents the indicator function.
- Precision expresses the ratio of correctly predicted positive classes to all predicted positive classes and in multi-class classification problems is defined asL refers to the number of classes, is the number of true positive outcomes, and is the number of false positive outcomes for class label l.
- Recall expresses the ratio of correctly predicted positive classes to all existing positive classes. In mathematical terms,L is the number of classes, is the number of true positive, and is the number of false negative for class label l, respectively.
- F1-score aggregates Precision and Recall metrics under the concept of harmonic mean. This is defined as-score can be viewed also as the weighted average between Precision and Recall.
2.5. Proposed Approaches
2.5.1. Shallow CNN
2.5.2. Deep CNN
2.5.3. Micro VGG
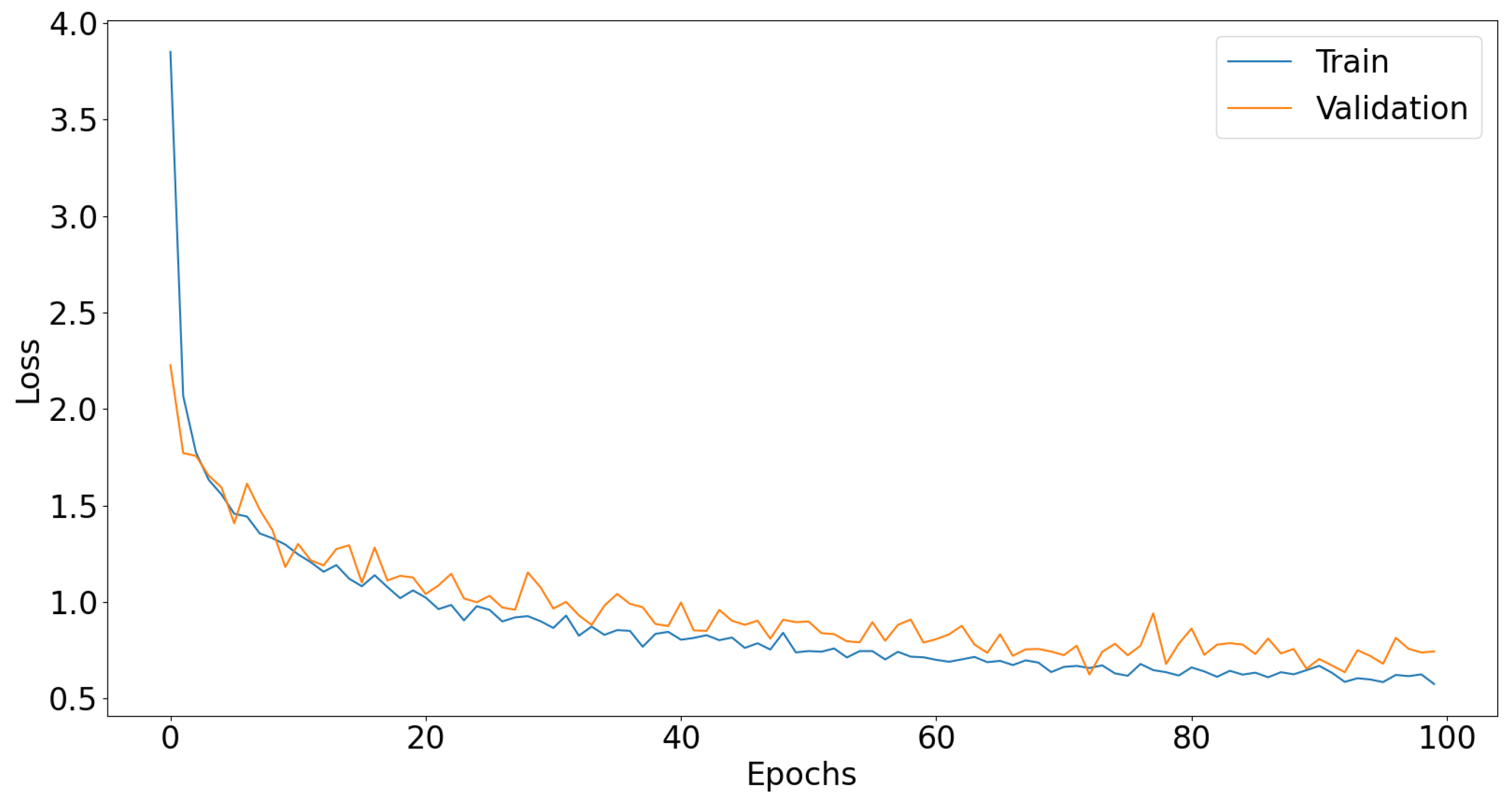
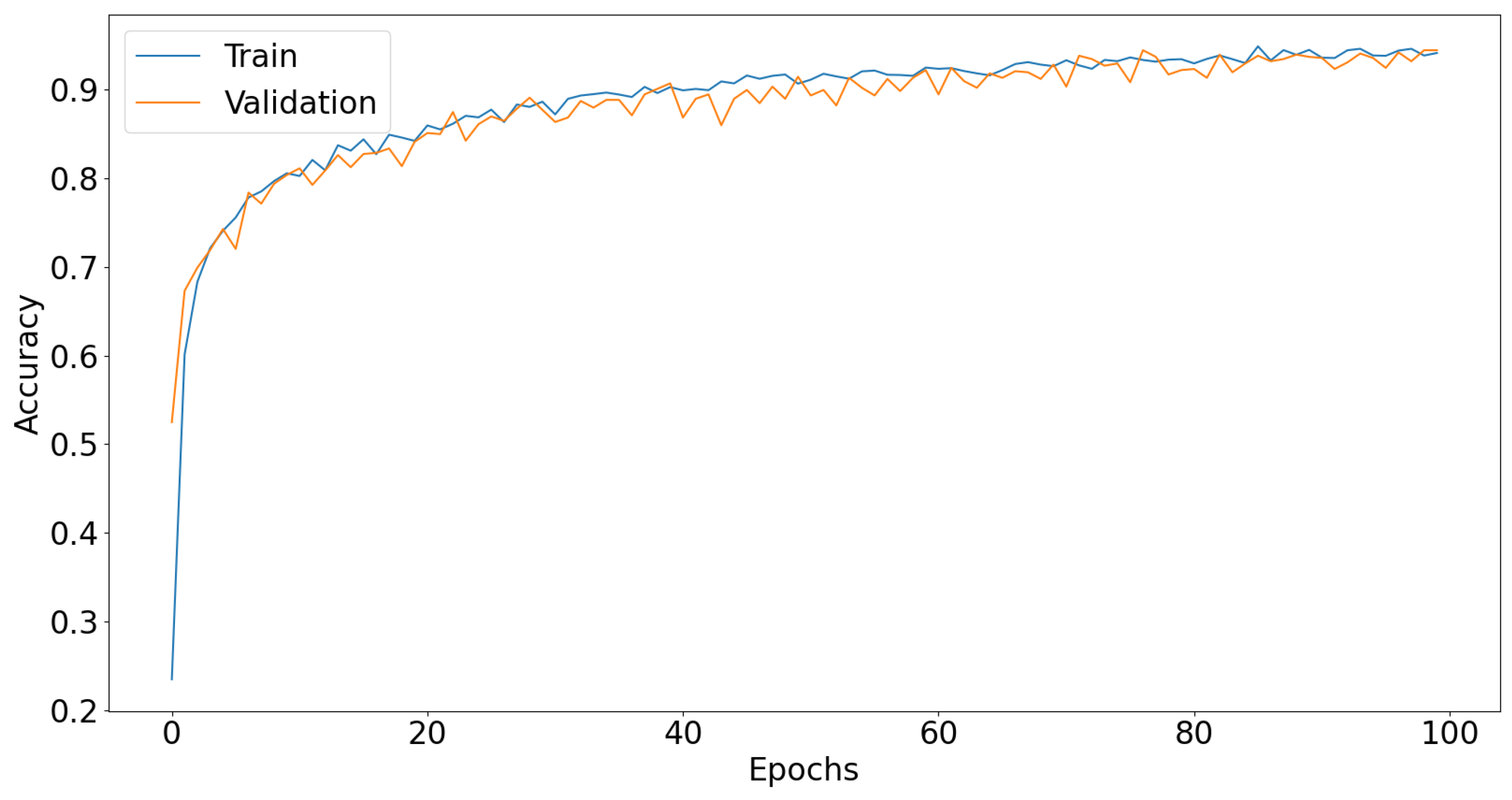
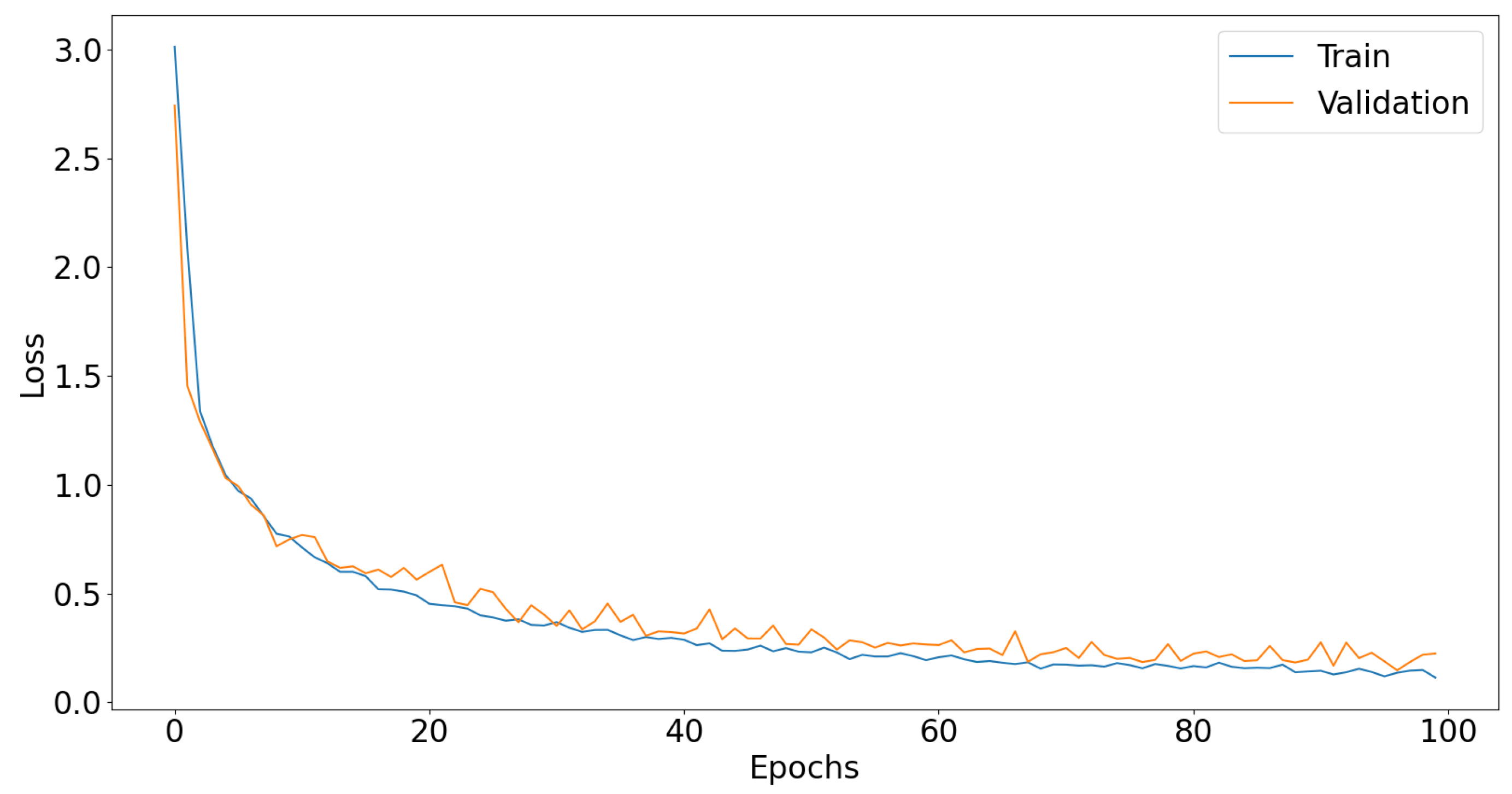
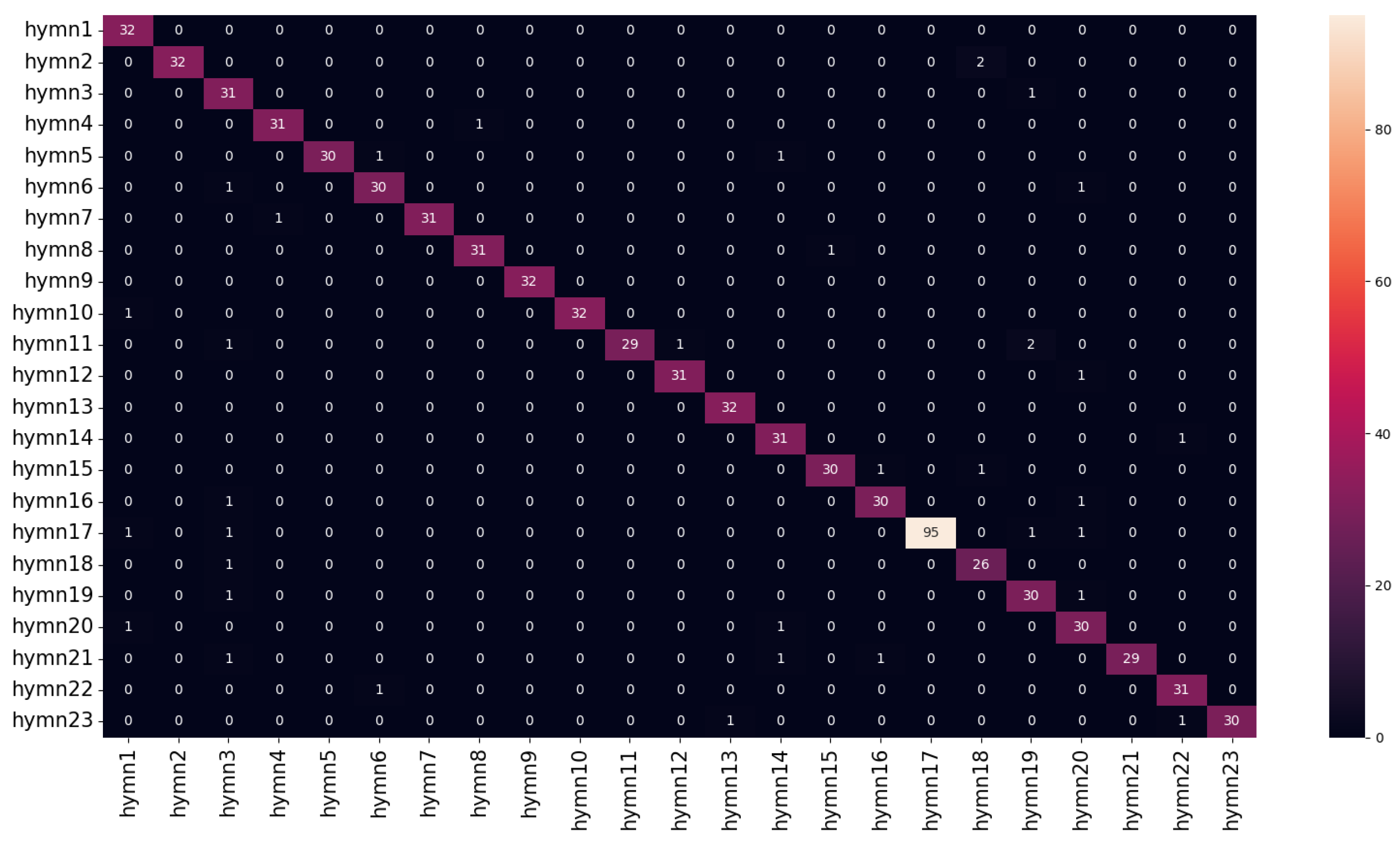
3. Experiments and Results
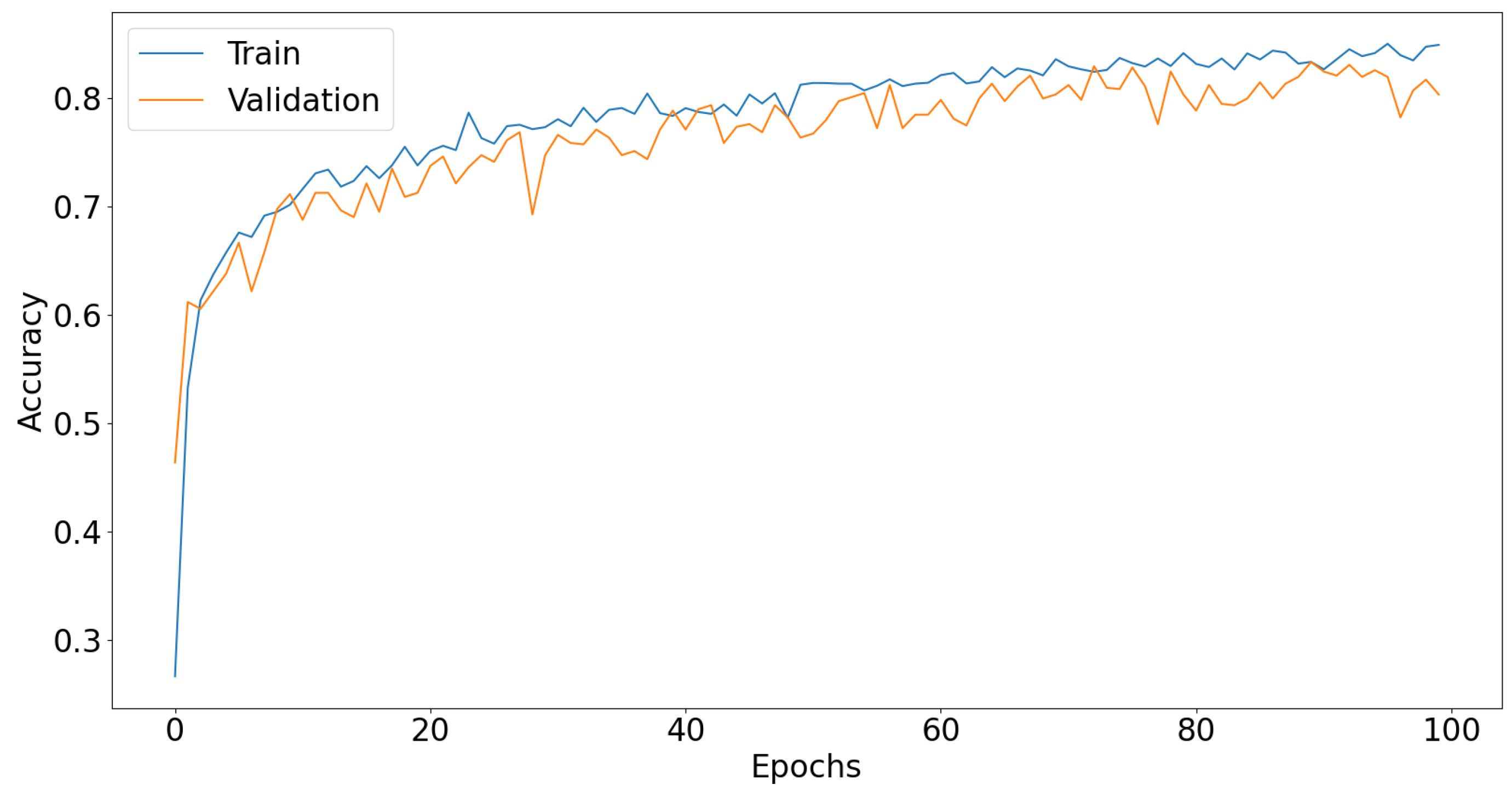
3.1. Dl Models
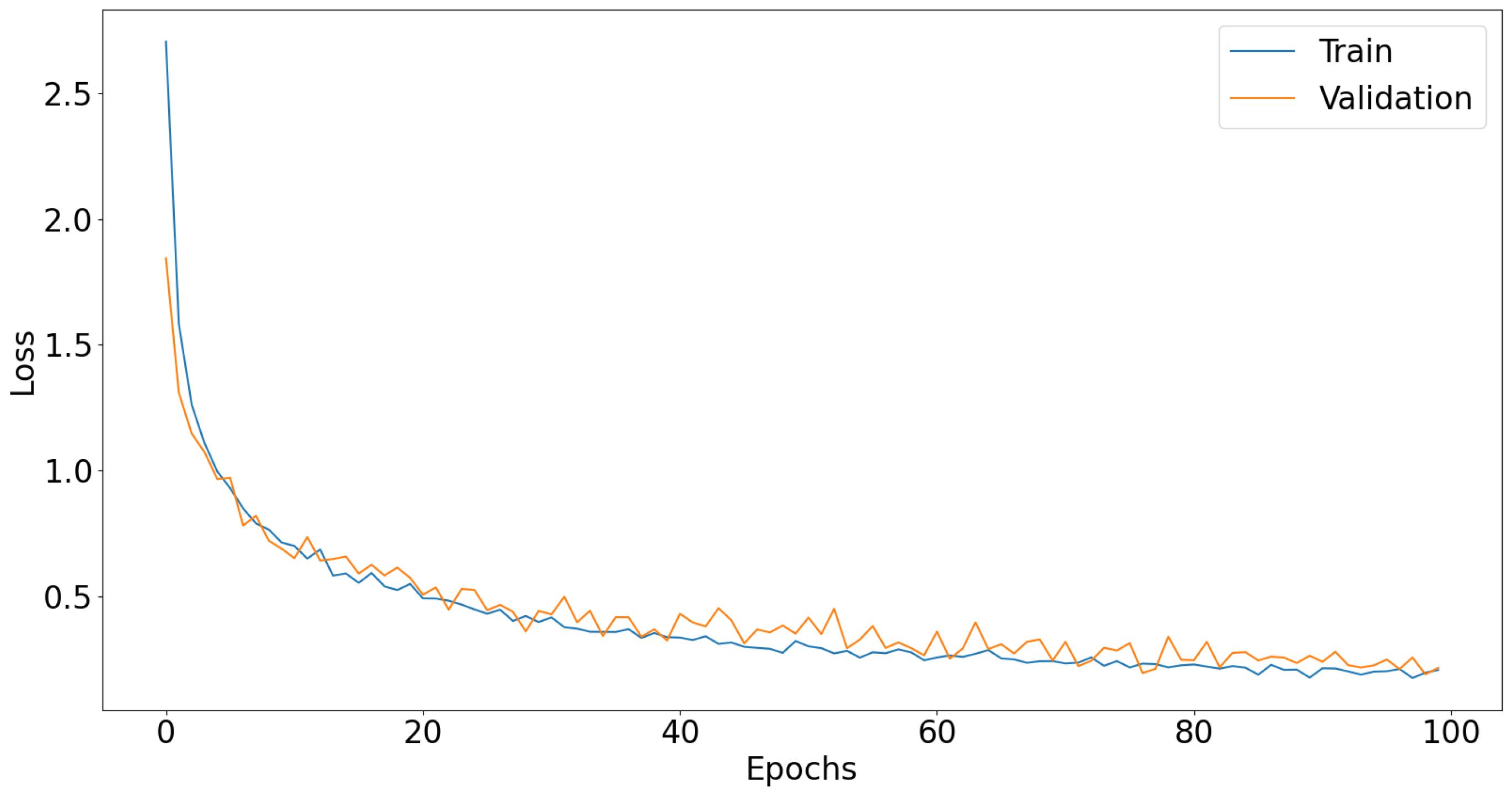
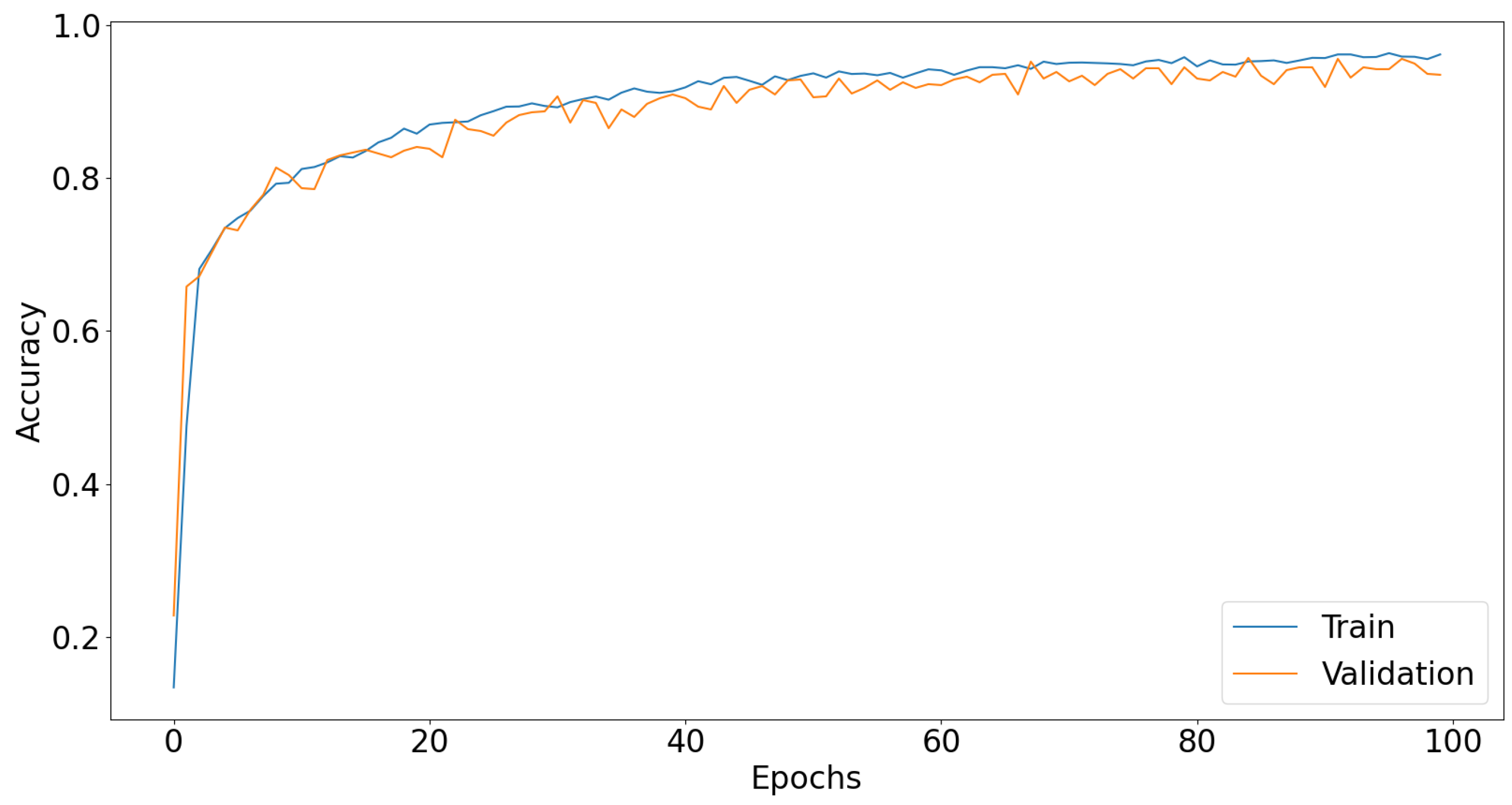
3.2. Transfer Learning—Comparison with SOTA Models
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 1D | one-dimensional |
| 2D | two-dimensional |
| CNNs | convolutional neural networks |
| CV | computer vision |
| DFT | discrete Fourier transform |
| DL | deep learning |
| FFT | fast Fourier transform |
| MG | music generation |
| MIR | music information retrieval |
| ML | machine learning |
| NLP | natural language processing |
| ReLU | rectified linear unit |
| ResNet | residual network |
| RGB | red-green-blue |
| RNNs | recurrent neural networks |
| SGD | stochastic gradient descent |
| SOTA | state of the art |
| TA | TriviaAugment |
| VGG | visual geometry group |
References
- Fiorucci, M.; Khoroshiltseva, M.; Pontil, M.; Traviglia, A.; Del Bue, A.; James, S. Machine Learning for Cultural Heritage: A Survey. Pattern Recognit. Lett. 2020, 133, 102–108. [Google Scholar] [CrossRef]
- Purwins, H.; Li, B.; Virtanen, T.; Schlüter, J.; Chang, S.Y.; Sainath, T. Deep Learning for Audio Signal Processing. IEEE J. Sel. Top. Signal Process. 2019, 13, 206–219. [Google Scholar] [CrossRef] [Green Version]
- Castellano, G.; Vessio, G. Deep learning approaches to pattern extraction and recognition in paintings and drawings: An overview. Neural Comput. Appl. 2021, 33, 12263–12282. [Google Scholar] [CrossRef]
- Lin, Q.; Ding, B. Music Score Recognition Method Based on Deep Learning. Intell. Neurosci. 2022, 2022. [Google Scholar] [CrossRef] [PubMed]
- De Vega, F.F.; Alvarado, J.; Cortez, J.V. Optical Music Recognition and Deep Learning: An application to 4-part harmony. In Proceedings of the 2022 IEEE Congress on Evolutionary Computation (CEC), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2016; p. 800. [Google Scholar]
- Nanni, L.; Maguolo, G.; Brahnam, S.; Paci, M. An Ensemble of Convolutional Neural Networks for Audio Classification. Appl. Sci. 2021, 11, 3579. [Google Scholar] [CrossRef]
- Zhao, T.; Xie, Y.; Wang, Y.; Cheng, J.; Guo, X.; Hu, B.; Chen, Y. A Survey of Deep Learning on Mobile Devices: Applications, Optimizations, Challenges, and Research Opportunities. Proc. IEEE 2022, 110, 334–354. [Google Scholar] [CrossRef]
- Baldominos, A.; Cervantes, A.; Saez, Y.; Isasi, P. A Comparison of Machine Learning and Deep Learning Techniques for Activity Recognition using Mobile Devices. Sensors 2019, 19, 521. [Google Scholar] [CrossRef] [Green Version]
- Pérez Arteaga, S.; Sandoval Orozco, A.L.; García Villalba, L.J. Analysis of Machine Learning Techniques for Information Classification in Mobile Applications. Appl. Sci. 2023, 13, 5438. [Google Scholar] [CrossRef]
- Cano, P.; Batle, E.; Kalker, T.; Haitsma, J. A review of algorithms for audio fingerprinting. In Proceedings of the 2002 IEEE Workshop on Multimedia Signal Processing, St. Thomas, VI, USA, 9–11 December 2002; pp. 169–173. [Google Scholar] [CrossRef]
- Wang, A.L. An industrial-strength audio search algorithm. In Proceedings of the ISMIR 2003, 4th Symposium Conference on Music Information Retrieval, Baltimore, MA, USA, 27–30 October 2003; pp. 7–13. [Google Scholar]
- Moysis, L.; Iliadis, L.A.; Sotiroudis, S.P.; Boursianis, A.D.; Papadopoulou, M.S.; Kokkinidis, K.I.D.; Volos, C.; Sarigiannidis, P.; Nikolaidis, S.; Goudos, S.K. Music Deep Learning: Deep Learning Methods for Music Signal Processing—A Review of the State-of-the-Art. IEEE Access 2023, 11, 17031–17052. [Google Scholar] [CrossRef]
- Schedl, M. Deep Learning in Music Recommendation Systems. Front. Appl. Math. Stat. 2019, 5. [Google Scholar] [CrossRef] [Green Version]
- Hernandez-Olivan, C.; Beltrán, J.R. Music Composition with Deep Learning: A Review. In Advances in Speech and Music Technology: Computational Aspects and Applications; Springer International Publishing: Cham, Switzerland, 2023; pp. 25–50. [Google Scholar] [CrossRef]
- Khamparia, A.; Gupta, D.; Nguyen, N.G.; Khanna, A.; Pandey, B.; Tiwari, P. Sound Classification Using Convolutional Neural Network and Tensor Deep Stacking Network. IEEE Access 2019, 7, 7717–7727. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems; Pereira, F., Burges, C., Bottou, L., Weinberger, K., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; Volume 25. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
- Hershey, S.; Chaudhuri, S.; Ellis, D.P.W.; Gemmeke, J.F.; Jansen, A.; Moore, R.C.; Plakal, M.; Platt, D.; Saurous, R.A.; Seybold, B.; et al. CNN architectures for large-scale audio classification. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 131–135. [Google Scholar] [CrossRef] [Green Version]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Tsalera, E.; Papadakis, A.; Samarakou, M. Comparison of Pre-Trained CNNs for Audio Classification Using Transfer Learning. J. Sens. Actuator Netw. 2021, 10, 72. [Google Scholar] [CrossRef]
- Gemmeke, J.F.; Ellis, D.P.W.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio Set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar] [CrossRef]
- Green, M.; Murphy, D. Environmental sound monitoring using machine learning on mobile devices. Appl. Acoust. 2020, 159, 107041. [Google Scholar] [CrossRef]
- Ryumin, D.; Ivanko, D.; Ryumina, E. Audio-Visual Speech and Gesture Recognition by Sensors of Mobile Devices. Sensors 2023, 23, 2284. [Google Scholar] [CrossRef]
- Tan, K.; Zhang, X.; Wang, D. Deep Learning Based Real-Time Speech Enhancement for Dual-Microphone Mobile Phones. IEEE/ACM Trans. Audio Speech, Lang. Process. 2021, 29, 1853–1863. [Google Scholar] [CrossRef]
- Farajzadeh, N.; Sadeghzadeh, N.; Hashemzadeh, M. PMG-Net: Persian music genre classification using deep neural networks. Entertain. Comput. 2023, 44, 100518. [Google Scholar] [CrossRef]
- Sharma, D.; Taran, S.; Pandey, A. A fusion way of feature extraction for automatic categorization of music genres. Multimed. Tools Appl. 2023. [Google Scholar] [CrossRef]
- Müller, S.G.; Hutter, F. TrivialAugment: Tuning-Free Yet State-of-the-Art Data Augmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Virtual, 1–17 October 2021; pp. 774–782. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond Empirical Risk Minimization. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. Interspeech 2019. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How Does Batch Normalization Help Optimization? In Proceedings of the Advances in Neural Information Processing Systems; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31. [Google Scholar]
- Yang, G.; Pennington, J.; Rao, V.; Sohl-Dickstein, J.; Schoenholz, S.S. A Mean Field Theory of Batch Normalization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 249–256. [Google Scholar]
- Hand, D.; Till, R. A Simple Generalisation of the Area Under the ROC Curve for Multiple Class Classification Problems. Mach. Learn. 2001, 45, 171–186. [Google Scholar] [CrossRef]
- Grandini, M.; Bagli, E.; Visani, G. Metrics for Multi-Class Classification: An Overview. arXiv 2020, arXiv:2008.05756. [Google Scholar] [CrossRef]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the 3rd International Conference on Learning Representations—ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Howard, A.G.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Gimeno, P.; Viñals, I.; Ortega, A.; Miguel, A.; Lleida, E. Multiclass audio segmentation based on recurrent neural networks for broadcast domain data. EURASIP J. Audio, Speech, Music Process. 2020, 2020. [Google Scholar] [CrossRef] [Green Version]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef]
- Xu, P.; Zhu, X.; Clifton, D.A. Multimodal Learning With Transformers: A Survey. IEee Trans. Pattern Anal. Mach. Intell. 2023, 1–20. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Samples | Hymn Name (In the Greek Language) |
|---|---|---|
| Hymn1 | 210 | H ΠAΡΘΕΝOΣ ΣHΜΕΡOΝ |
| Hymn2 | 210 | ΕΥΛOΓHΤOΣ ΕΙ ΧΡΙΣΤΕ O ΘΕOΣ |
| Hymn3 | 218 | ΤHΝ ΩΡAΙOΤHΤA |
| Hymn4 | 174 | ΤOΝ ΣΤAΥΡOΝ ΣOΥ ΠΡOΣΚΥΝOΥΜΕ |
| Hymn5 | 210 | AΝOΙΞΩ ΤO ΣΤOΜA ΜOΥ |
| Hymn6 | 210 | ΦΩΣ ΙΛAΡOΝ |
| Hymn7 | 210 | ΜΕΤA ΤΩΝ AΓΙΩΝ AΝAΠAΥΣOΝ |
| Hymn8 | 210 | ΧΡΙΣΤOΣ AΝΕΣΤH |
| Hymn9 | 210 | ΜΕΤA ΠΝΕΥΜAΤΩΝ ΔΙΚAΙΩΝ |
| Hymn10 | 222 | ΕΙΣ ΤHΝ ΚAΤAΠAΥΣΙΝ ΣOΥ ΚΥΡΙΕ |
| Hymn11 | 210 | ΠΡOΣΤAΣΙA ΤΩΝ ΧΡΙΣΤΙAΝΩΝ |
| Hymn12 | 210 | ΔOΞOΛOΓΙA |
| Hymn13 | 210 | AΝAΣΤAΣΕΩΣ HΜΕΡA |
| Hymn14 | 210 | ΤOΝ ΝΥΜΦΩΝA ΣOΥ ΒΛΕΠΩ |
| Hymn15 | 210 | ΤOΥ ΔΕΙΠΝOΥ ΣOΥ ΤOΥ ΜΥΣΤΙΚOΥ |
| Hymn16 | 210 | AΠOΣΤOΛOΙ ΕΚ ΠΕΡAΤΩΝ |
| Hymn17 | 210 | ΘΕOΣ ΚΥΡΙOΣ |
| Hymn18 | 216 | ΘΕOΤOΚΕ ΠAΡΘΕΝΕ |
| Hymn19 | 213 | ΠAΣA ΠΝOH |
| Hymn20 | 207 | ΩΣ ΤΩΝ AΙΧΜAΛΩΤΩΝ |
| Hymn21 | 210 | ΜΕΓAΝ ΕΥΡAΤO |
| Hymn22 | 210 | ΕΚ ΝΕOΤHΤOΣ ΜOΥ |
| Hymn23 | 210 | ΜΕΤA ΠΝΕΥΜAΤΩΝ ΔΙΚAΙΩΝ |
| Model | Parameters Size (MB) | Number of Parameters | Number of Operations |
|---|---|---|---|
| Shallow CNN | 1.36 | 8,391,191 | 15.73 M |
| Deep CNN | 2.3 | 68,660,631 | 6.42 G |
| Micro VGG | 1.96 | 489,687 | 234.6 M |
| Model | Train Accuracy % | Validation Accuracy % | Test Accuracy % |
|---|---|---|---|
| Shallow CNN | 83.33 ± 1.24 | 83.52 ± 0.83 | 82.79 |
| Deep CNN | 95.99 ± 1.28 | 96.10 ± 0.89 | 94.01 |
| Micro VGG | 97.16 ± 1.19 | 97.14 ± 0.74 | 96.38 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| Shallow CNN | 0.83 | 0.82 | 0.83 |
| Deep CNN | 0.95 | 0.96 | 0.95 |
| Micro VGG | 0.97 | 0.97 | 0.97 |
| Model | Training Time (s) | Inference Time (s) |
|---|---|---|
| Shallow CNN | 1937.002 | 3.88 |
| Deep CNN | 3405.890 | 4.79 |
| Micro VGG | 2091.434 | 4.02 |
| Model | Parameters Size (MB) | Number of Parameters | Number of Operations |
|---|---|---|---|
| VGGish | 220.48 | 55,119,447 | 28.45 G |
| ResNet18 | 44.75 | 11,188,311 | 148.07 M |
| MobileNetV3 | 6.14 | 1,542,765 | 240.93 M |
| SqueezeNet | 4.37 | 734,295 | 17.26 M |
| EfficientNet | 4.74 | 4,037,011 | 7 M |
| Model | Train Accuracy % | Validation Accuracy % | Test Accuracy % |
|---|---|---|---|
| VGGish | 100 ± 0 | 98.03 ± 1.16 | 95.42 |
| ResNet18 | 96.18 ± 1.21 | 97.27 ± 1.08 | 96.11 |
| MobileNetV3 | 94.87 ± 1.22 | 98.18 ± 1.03 | 95.76 |
| SqueezeNet | 90.08 ± 1.26 | 91.04 ± 0.99 | 88.78 |
| EfficientNet | 95.99 ± 1.19 | 97.14 ± 0.91 | 96.13 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| VGGish | 0.94 | 0.94 | 0.94 |
| ResNet18 | 0.97 | 0.98 | 0.97 |
| MobileNetV3 | 0.96 | 0.95 | 0.95 |
| SqueezeNet | 0.89 | 0.89 | 0.89 |
| EfficientNet | 0.96 | 0.96 | 0.96 |
| Model | Training Time (s) | Inference Time (s) |
|---|---|---|
| VGGish | 3054.258 | 4.73 |
| ResNet18 | 2811.133 | 4.11 |
| MobileNetV3 | 7813.502 | 5.89 |
| SqueezeNet | 2821.533 | 4.23 |
| EfficientNet | 3018.431 | 4.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iliadis, L.A.; Sotiroudis, S.P.; Tsakatanis, N.; Boursianis, A.D.; Kokkinidis, K.-I.D.; Karagiannidis, G.K.; Goudos, S.K. Low Complexity Deep Learning Framework for Greek Orthodox Church Hymns Classification. Appl. Sci. 2023, 13, 8638. https://doi.org/10.3390/app13158638
Iliadis LA, Sotiroudis SP, Tsakatanis N, Boursianis AD, Kokkinidis K-ID, Karagiannidis GK, Goudos SK. Low Complexity Deep Learning Framework for Greek Orthodox Church Hymns Classification. Applied Sciences. 2023; 13(15):8638. https://doi.org/10.3390/app13158638
Chicago/Turabian StyleIliadis, Lazaros Alexios, Sotirios P. Sotiroudis, Nikolaos Tsakatanis, Achilles D. Boursianis, Konstantinos-Iraklis D. Kokkinidis, George K. Karagiannidis, and Sotirios K. Goudos. 2023. "Low Complexity Deep Learning Framework for Greek Orthodox Church Hymns Classification" Applied Sciences 13, no. 15: 8638. https://doi.org/10.3390/app13158638