
Speed Bump and Pothole Detection Using Deep Neural Network with Images Captured through ZED Camera
 , , ,
, , ,  ,
,  ,
,  and
and 
Abstract
:Featured Application
Abstract
1. Introduction

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Accuracy % | Type of Detection | Sensor | Method |
|---|---|---|---|---|
| [11] | 78.5 | Road anomaly | Accelerometer | Support vector machine |
| [12] | 90 | Pothole | Accelerometer | Z-DIFF |
| [13] | 97 | Pavement distress | Image | Neural network thresholding |
| [14] | 85 | Pedestrian crossing and speed bump | Image and LIDAR | height-difference-based algorithm |
| [15] | 93 | Potholes and bumps | Accelerometer | Energy peak acceleration value |
| [16] | 90–95 | Pothole | Accelerometer | Neural network |
| [17] | 85 | Speed bump | Image | Color image thresholding |
| [18] | 92 | Speed bump | Image | Connected component analysis. |
| [19] | 94.7 | Speed bump | Image | Gaussian mixture model |
| [8] | 97.4 | Speed hump/bump | Image (ZED) | Mobilenet-SSD CNN model |
| [4] | 94–96 | Potholes and bumps | Accelerometer | Wavelet |
| [20] | 80 | Speed bump | Image | Gray-level co-occurrence matrix |
| [5] | 97.14 | Speed bump | Accelerometer | GALGO |
| [9] | 77 | Pothole | Image | Inception V2 |
| [7] | 88.9 | Potholes and bumps | Image | YOLO |
| [21] | 90 | Speed bump | Image | Otsu thresholding |
| [22] | 90 | Pothole | Image | Tiny-YOLOv4 |
1.1. Related Works Using One-Dimensional Signals
1.2. Related Works Using Multi-Dimensional Signals
1.3. Deep Learning Proposals
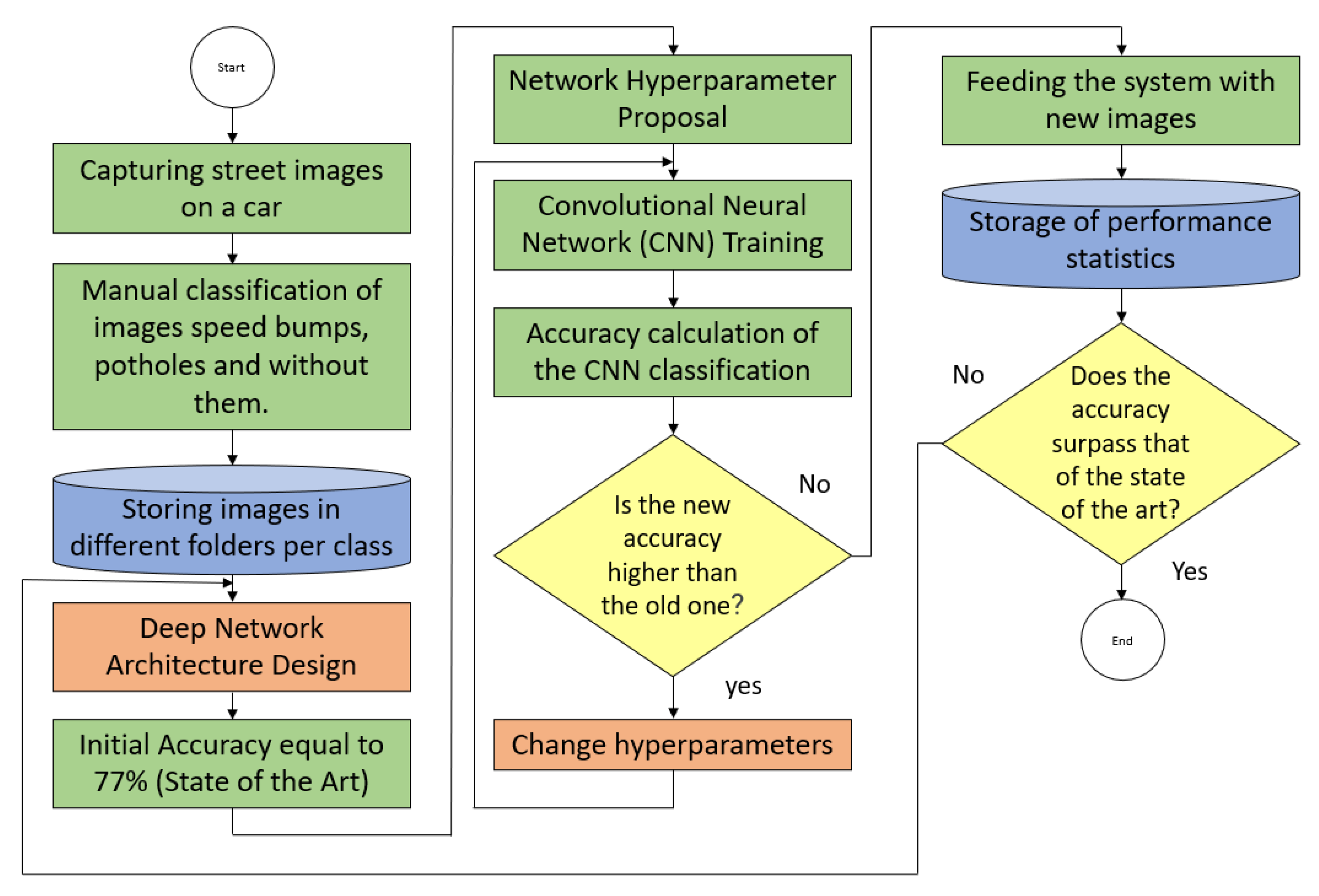
1.4. Our Proposal
2. Materials and Methods
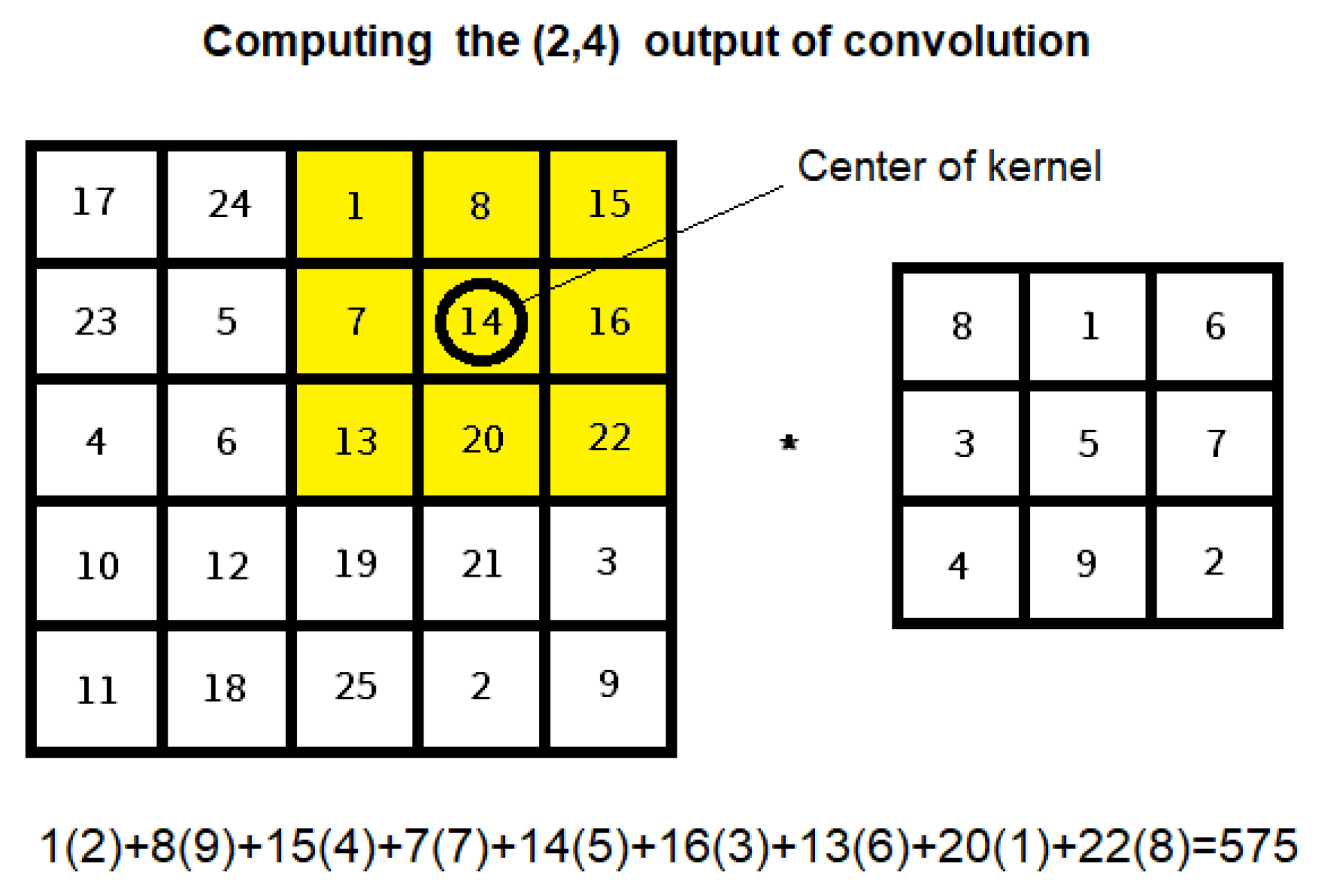
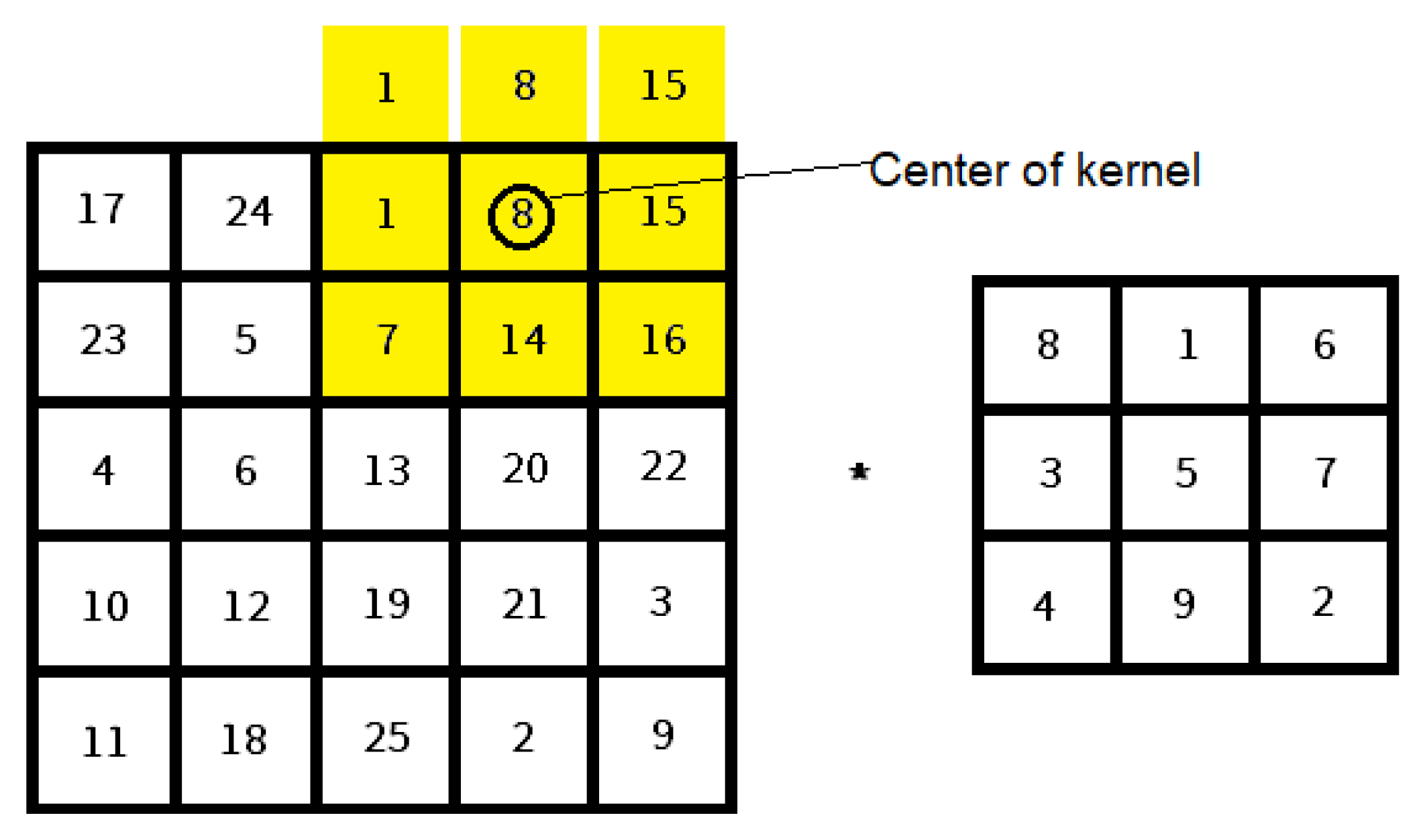
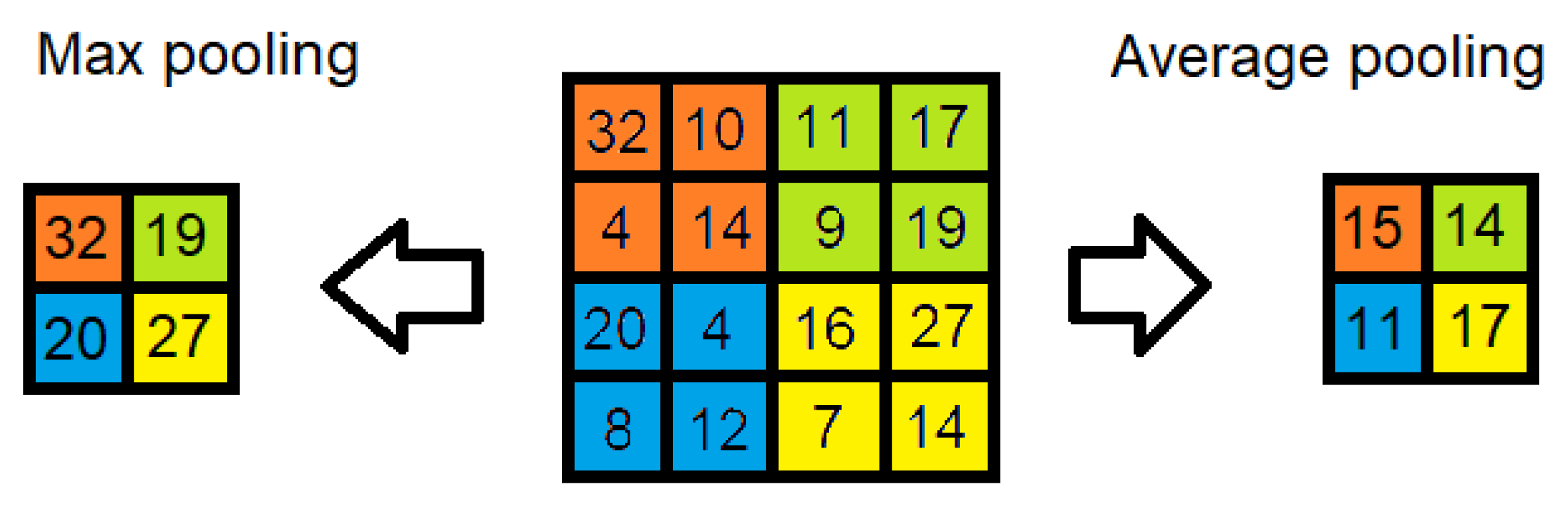
2.1. Basics of Deep Learning in Images
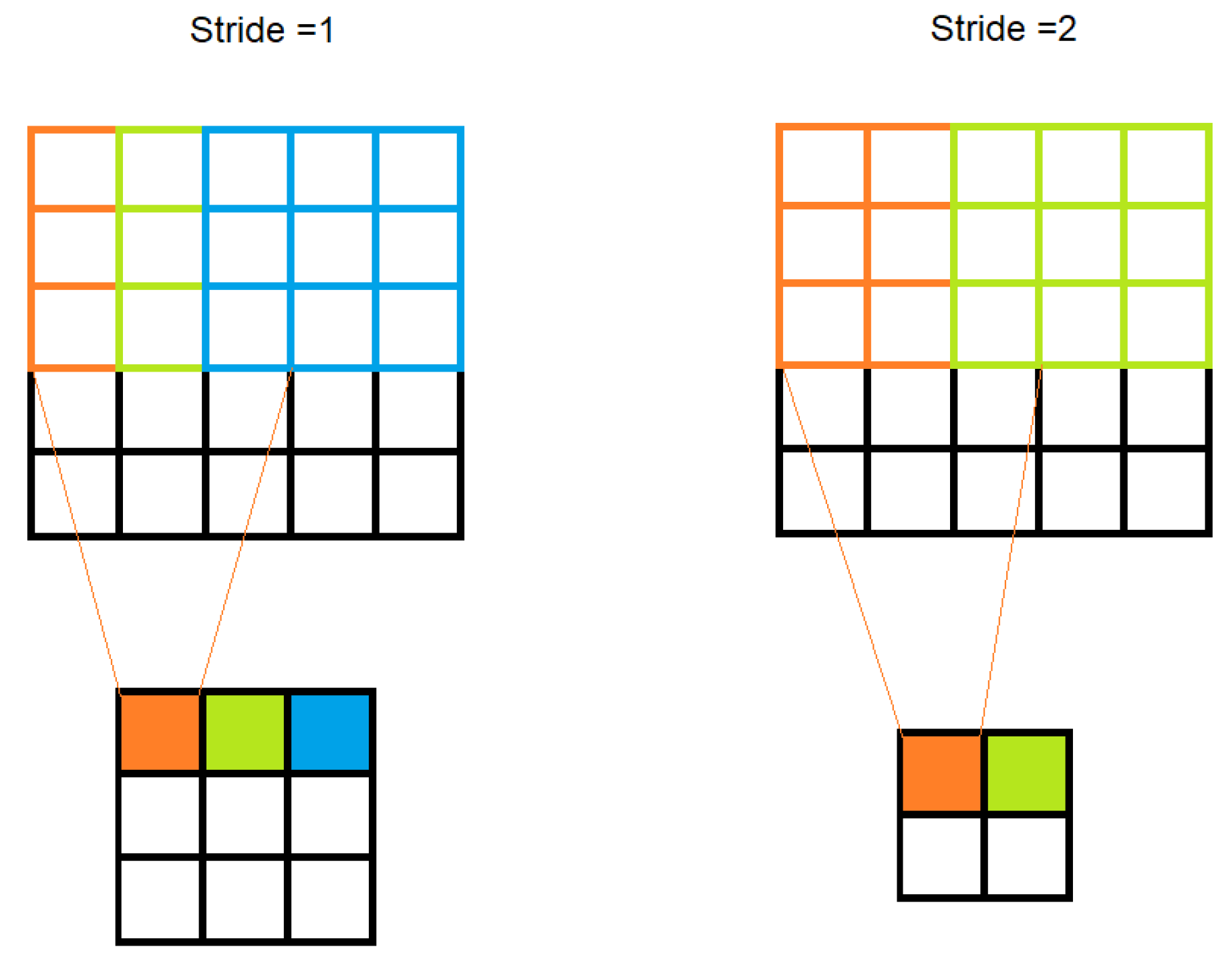
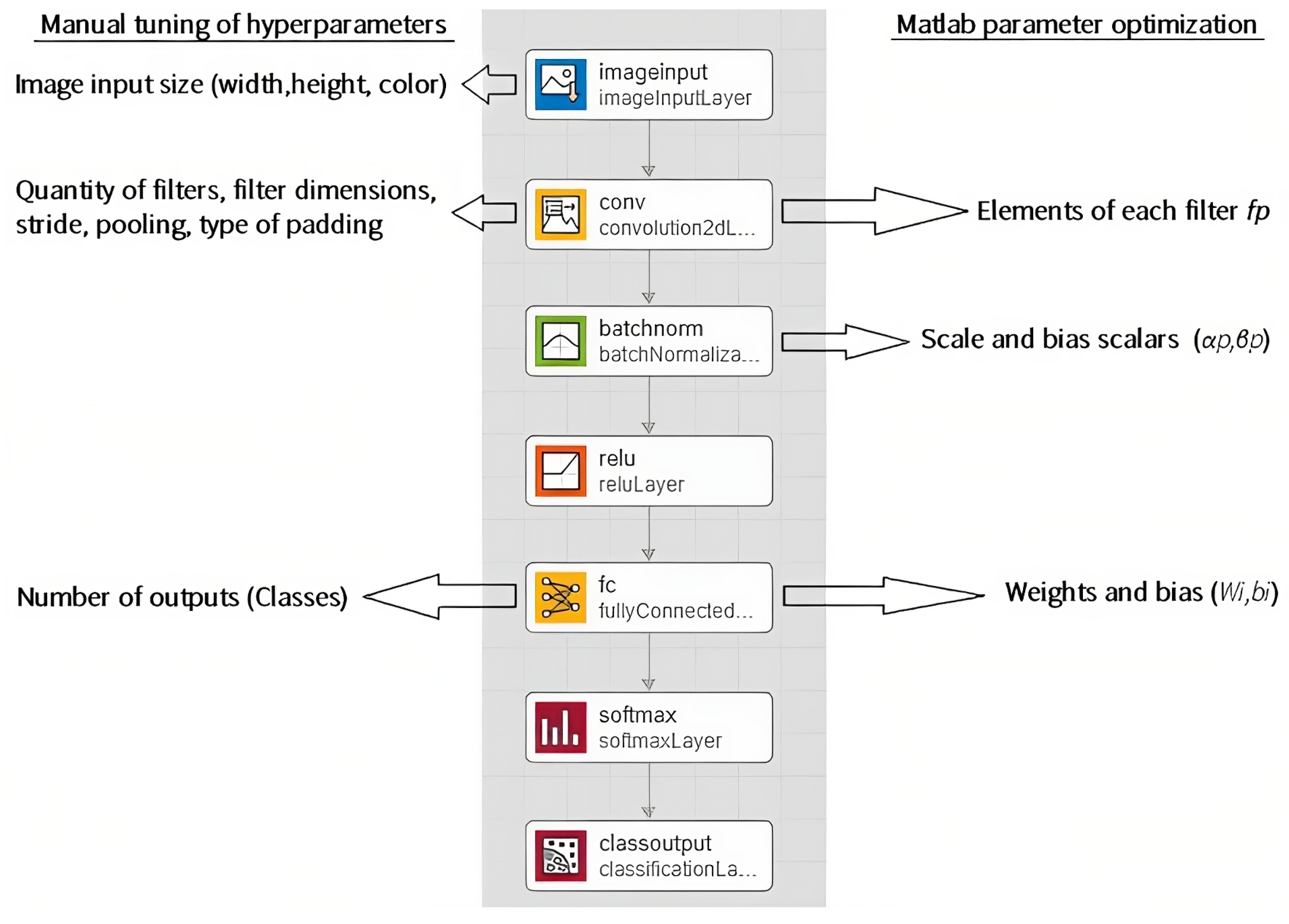
2.2. Convolutional Neural Network Architecture
2.3. Hyperparameter Tuning
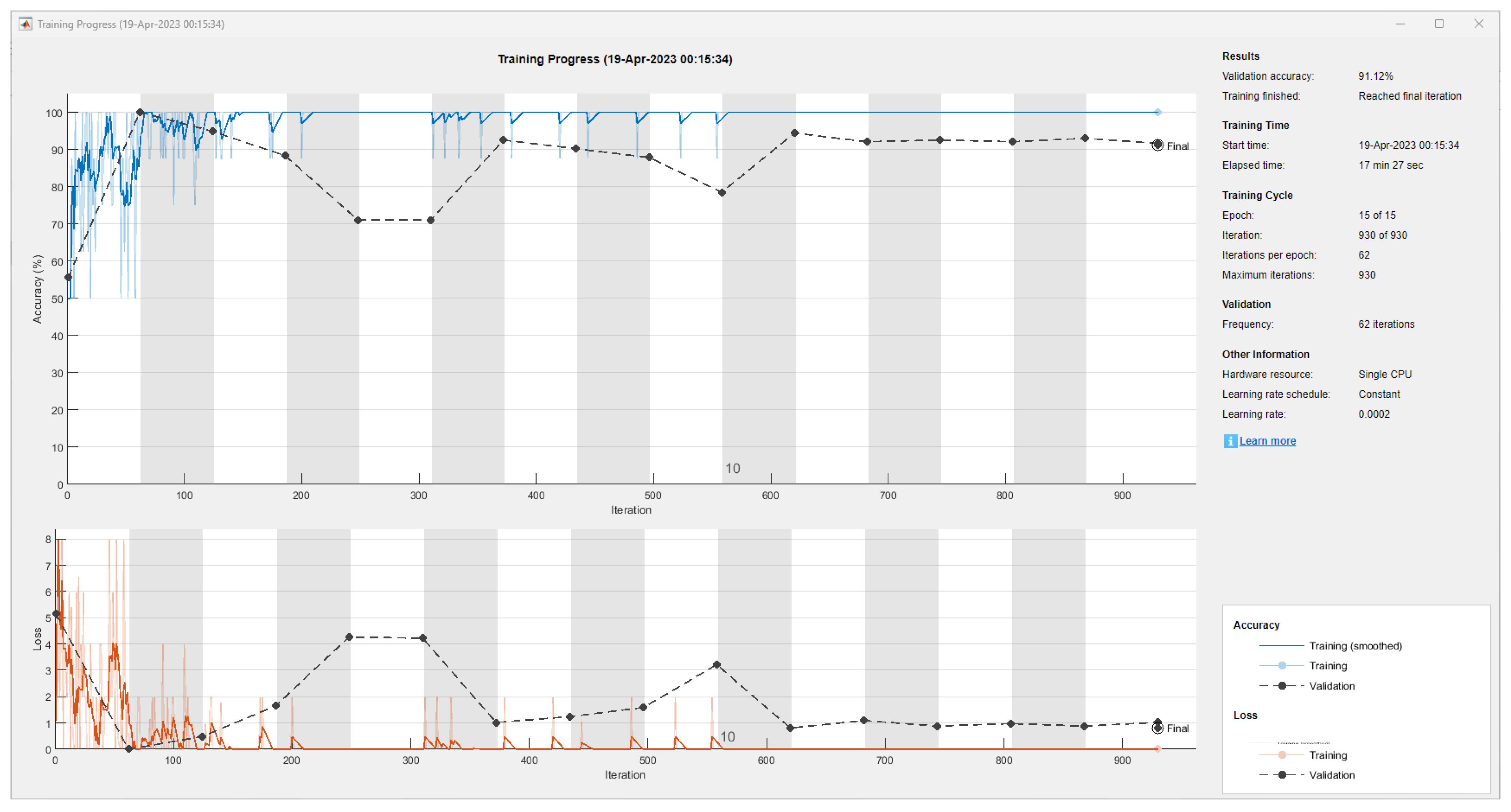
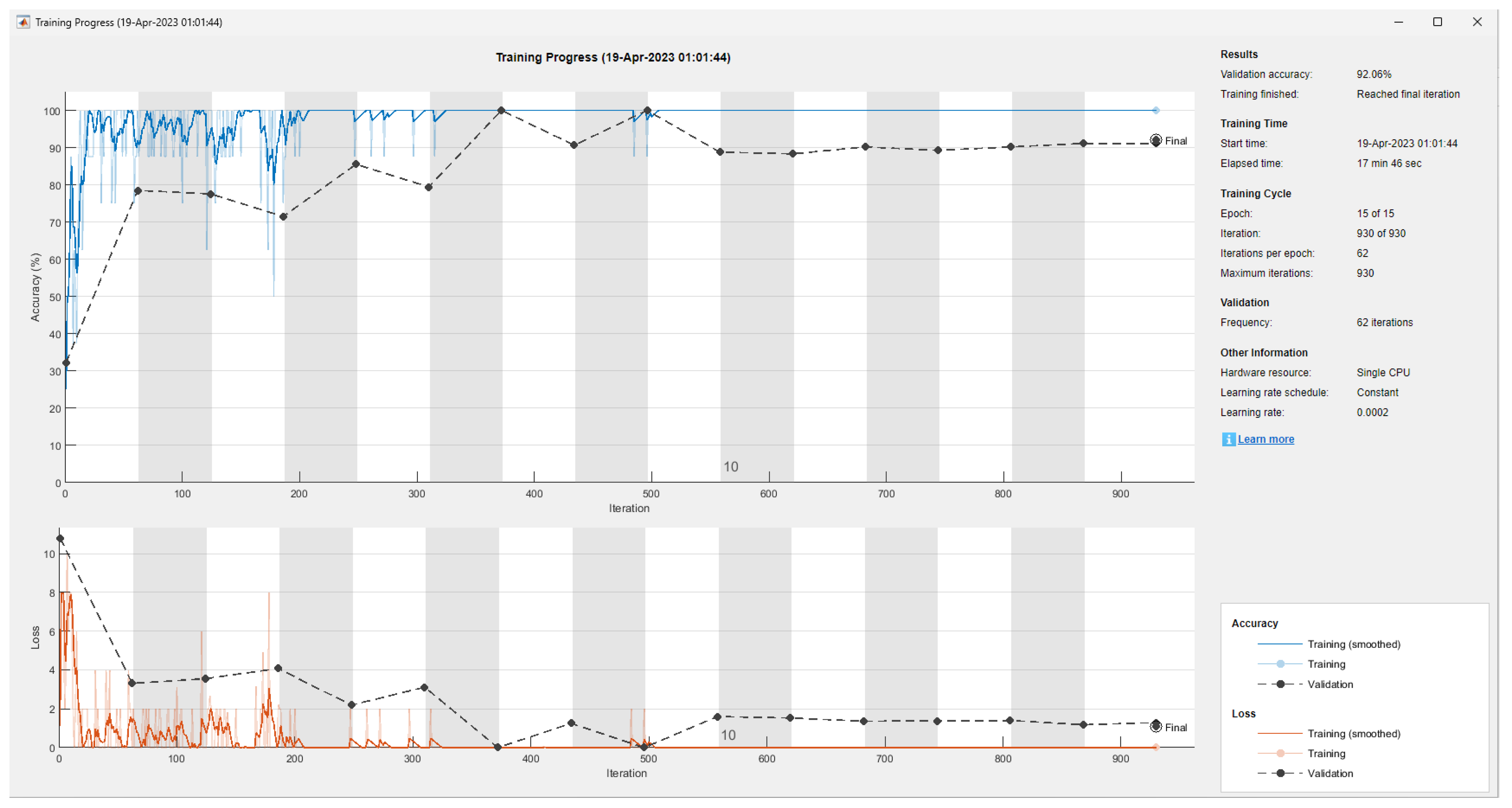
3. Results
Feature Visualization of Convolutional Neural Network
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Secretarĺa de Comunicaciones y Transportes de México. Estadĺstica de Accidentes de Tránsito; Secretarĺa de Comunicaciones y Transportes de México: Mexico City, Mexico, 2020; Available online: https://imt.mx/archivos/Publicaciones/DocumentoTecnico/dt79.pdf (accessed on 4 July 2023).
- Corro, I. Joven cae en zanja de Tláhuac con todo y coche; asegura que no habĺa señalización, VIDEO. El Universal, 8 March 2023. [Google Scholar]
- Al-Shargabi, B.; Hassan, M.; Al-Rousan, T. A Novel Approach for the Detection of Road Speed Bumps using Accelerometer Sensor. TEM J. 2020, 9, 469–476. [Google Scholar] [CrossRef]
- Bello-Salau, H.; Aibinu, A.M.; Onumanyi, A.J.; Onwuka, E.N.; Dukiya, J.J.; Ohize, H. New road anomaly detection and characterization algorithm for autonomous vehicles. Appl. Comput. Inform. 2018, 16, 223–239. [Google Scholar] [CrossRef]
- Celaya-Padilla, J.M.; Galván-Tejada, C.E.; López-Monteagudo, F.E.; Alonso-González, O.; Moreno-Báez, A.; Martĺnez-Torteya, A.; Galván-Tejada, J.I.; Arceo-Olague, J.G.; Luna-Garcĺa, H.; Gamboa-Rosales, H. Speed Bump Detection Using Accelerometric Features: A Genetic Algorithm Approach. Sensors 2018, 18, 443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Martinez, F.; Carlos Gonzalez, L.; Ricardo Carlos, M. Identifying Roadway Surface Disruptions Based on Accelerometer Patterns. IEEE Lat. Am. Trans. 2014, 12, 455–461. [Google Scholar] [CrossRef]
- Shah, S.; Deshmukh, C. Pothole and Bump detection using Convolution Neural Networks. In Proceedings of the 2019 IEEE Transportation Electrification Conference (ITEC-India), Bengaluru, India, 17–19 December 2019; pp. 1–4. [Google Scholar]
- Varma, V.S.K.P.; Adarsh, S.; Ramachandran, K.I.; Nair, B.B. Real Time Detection of Speed Hump/Bump and Distance Estimation with Deep Learning using GPU and ZED Stereo Camera. In Proceedings of the 8th International Conference on Advances in Computing and Communication (ICACC-2018), Kochi, India, 13–15 September 2018; Volume 143, pp. 988–997. [Google Scholar]
- Maeda, H.; Sekimoto, Y.; Seto, T.; Kashiyama, T.; Omata, H. Road Damage Detection Using Deep Neural Networks with Images Captured Through a Smartphone. arXiv 2018, arXiv:1801.09454. [Google Scholar]
- Villaseñor-Aguilar, M.J.; Peralta-López, J.E.; Lázaro-Mata, D.; Garcĺa-Alcalá, C.E.; Padilla-Medina, J.A.; Perez-Pinal, F.J.; Vázquez-López, J.A.; Barranco-Gutiérrez, A.I. Fuzzy Fusion of Stereo Vision, Odometer, and GPS for Tracking Land Vehicles. Mathematics 2022, 10, 2052. [Google Scholar] [CrossRef]
- Tai, Y.-C.; Chan, C.-W.; Yung-Jen, H.J. Automatic Road Anomaly Detection Using Smart Mobile Device. In Proceedings of the 5th Conference on Artificial Intelligence and Applications (TAAI 2010), Hsinchu, Taiwan, 18–20 November 2010. [Google Scholar]
- Mednis, A.; Strazdins, G.; Zviedris, R.; Kanonirs, G.; Selavo, L. Real time pothole detection using Android smartphones with accelerometers. In Proceedings of the 2011 International Conference on Distributed Computing in Sensor Systems and Workshops (DCOSS), Barcelona, Spain, 27–29 June 2011; pp. 1–6. [Google Scholar]
- Salari, E.; Yu, X. Pavement distress detection and classification using a Genetic Algorithm. In Proceedings of the 2011 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 11–13 October 2011; pp. 1–5. [Google Scholar]
- Choi, J.; Lee, J.; Kim, D.; Soprani, G.; Cerri, P.; Broggi, A.; Yi, K. Environment-Detection-and-Mapping Algorithm for Autonomous Driving in Rural or Off-Road Environment. IEEE Trans. Intell. Transp. Syst. 2012, 13, 974–982. [Google Scholar] [CrossRef] [Green Version]
- Astarita, V.; Caruso, M.V.; Danieli, G.; Festa, D.C.; Giofrè, V.P.; Iuele, T.; Vaiana, R. A mobile application for road surface quality control: UNIquALroad. Procedia-Soc. Behav. Sci. 2012, 54, 1135–1144. [Google Scholar] [CrossRef] [Green Version]
- Kulkarni, A.; Mhalgi, N.; Gurnani, S. Pothole Detection System using Machine Learning on Android. Int. J. Emerg. Technol. Adv. Eng. 2014, 4, 360–364. [Google Scholar]
- Devapriya, W.; Babu, C.N.K.; Srihari, T. Advance Driver Assistance System (ADAS)-Speed bump detection. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 10–12 December 2015; pp. 1–6. [Google Scholar]
- Devapriya, W.; Babu, C.N.K.; Srihari, T. Real time speed bump detection using Gaussian filtering and connected component approach. Circuits Syst. 2016, 7, 2168–2175. [Google Scholar] [CrossRef] [Green Version]
- Srimongkon, S.; Chiracharit, W. Detection of speed bumps using Gaussian mixture model. In Proceedings of the 2017 14th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology (ECTI-CON), Phuket, Thailand, 27–30 June 2017; pp. 628–631. [Google Scholar]
- Bharathi, M.; Amsaveni, A.; Manikandan, B. Speed Breaker Detection Using GLCM Features. Int. J. Innov. Technol. Explor. Eng. 2018, 8, 384–389. [Google Scholar]
- Babu, K.C.N.; Devapriya, W.; Srihari, T.; Nandakumar, R. Speed-bump Detection using Otsu’s Algorithm and Morphological Operation. Int. J. Emerg. Technol. 2020, 11, 989–994. [Google Scholar]
- Asad, M.H.; Khaliq, S.; Yousaf, M.H.; Ullah, M.O.; Ahmad, A. Pothole Detection Using Deep Learning: A Real-Time and AI-on-the-Edge Perspective. Adv. Civ. Eng. 2022, 2022, 9221211. [Google Scholar] [CrossRef]
- STEREOLABS. Available online: https://www.stereolabs.com/zed-2/ (accessed on 13 April 2023).
- Ssheshadri, Jetson Nano Developer Kit User Guide. 2788 San Tomas Expressway Santa Clara, CA 95051. 15 January 2020. Available online: https://developer.download.nvidia.com/assets/embedded/secure/jetson/Nano/docs/NV_Jetson_Nano_Developer_Kit_User_Guide.pdf?svGUDWZio7oyFzB5oJu3kMwIBZBEpJ84wuGMfPRRDnmA5gIgeFKtQ987wVYovaAMCJa4UR8deq0CLbvazMUVFAFxBjxIYCZq_Ws9iTdBPmL4HV89ellsIv1IceR5knK2ldDCWXys-t1rENTDFitQTKsDCg8G1cjlQR2_V3D2DgjvFs1u986stSY_XLruS-GJonI=&t=eyJscyI6ImdzZW8iLCJsc2QiOiJodHRwczovL3d3dy5nb29nbGUuY29tLyJ9 (accessed on 4 July 2023).

















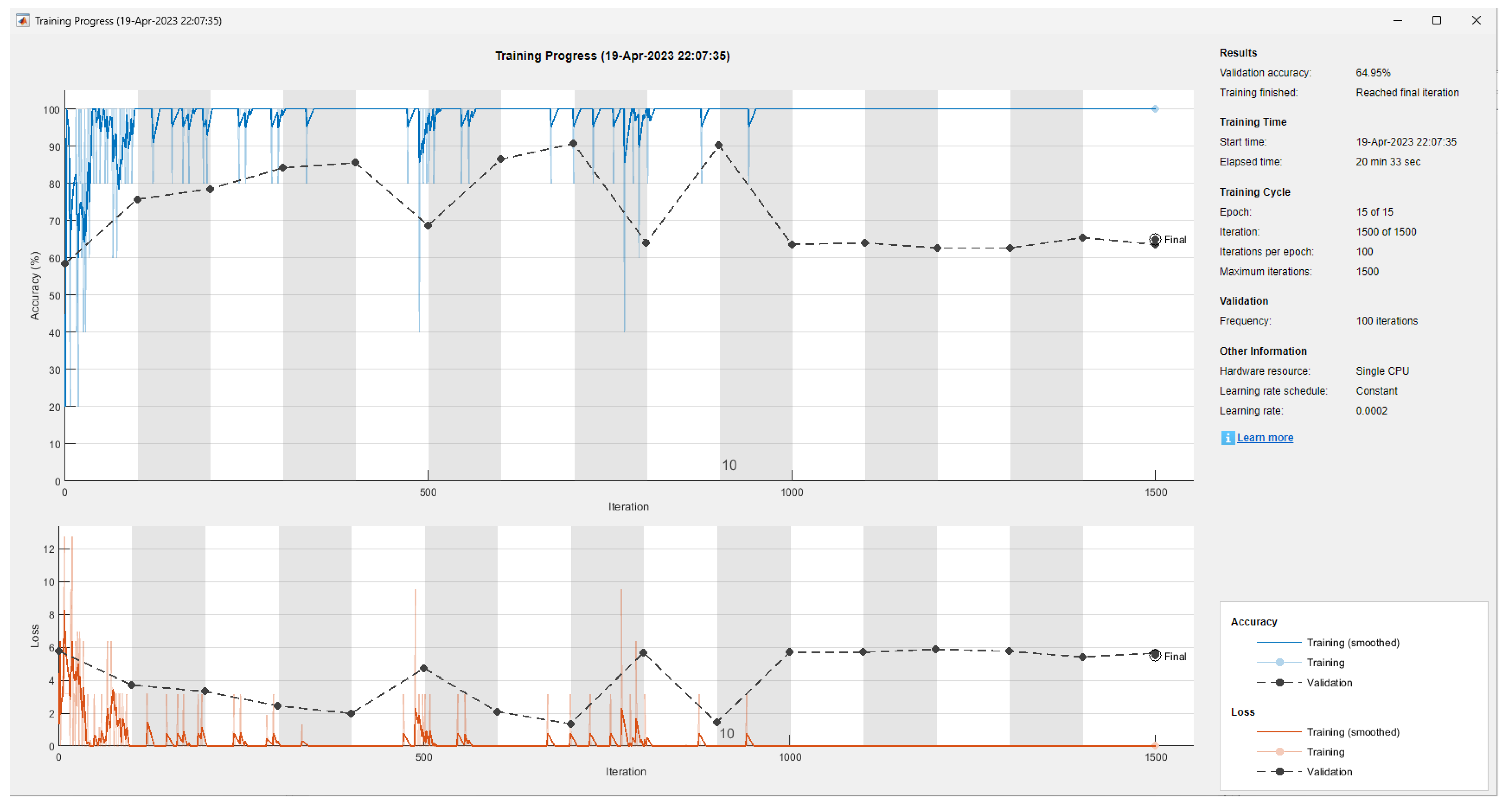
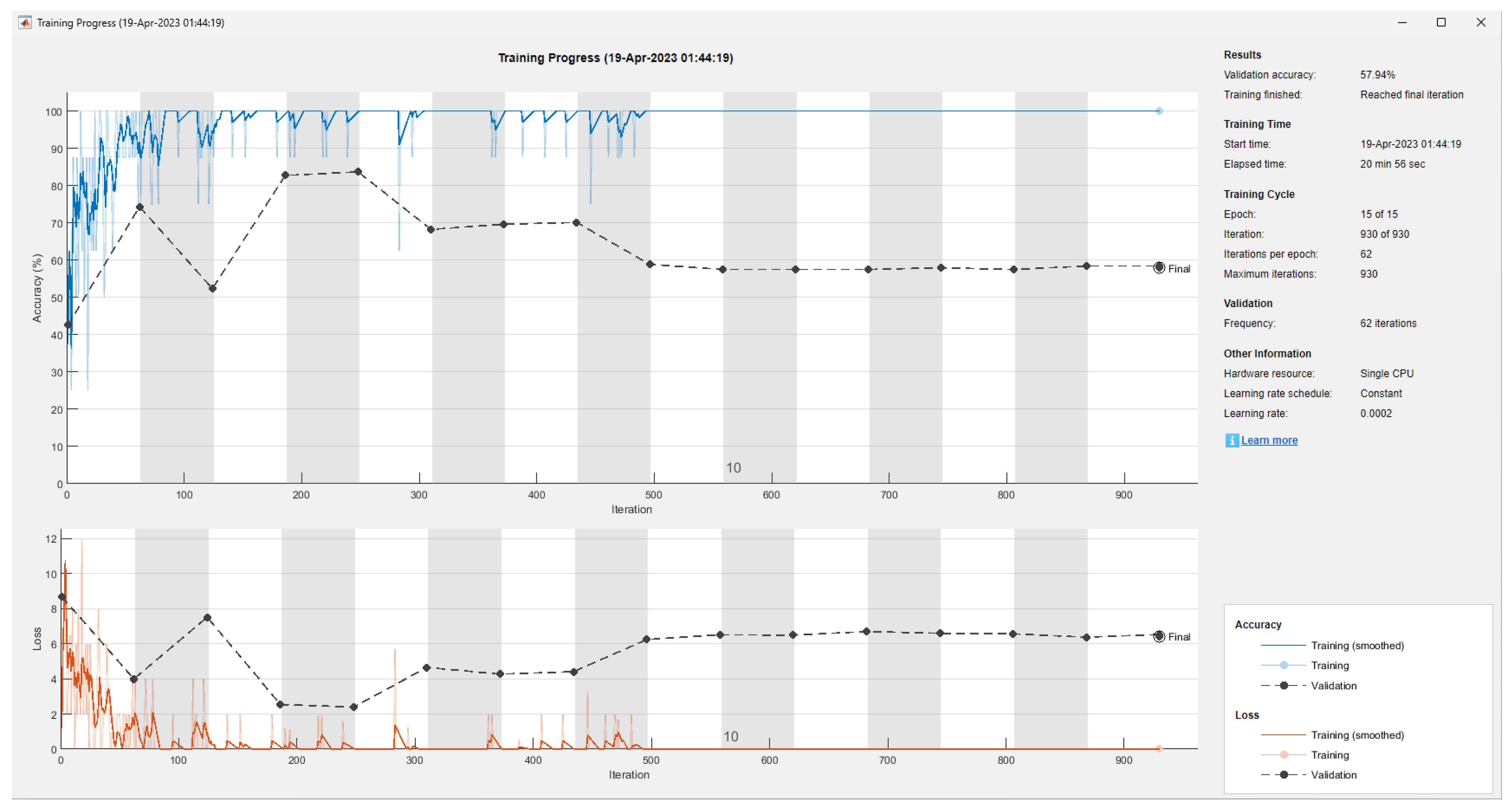
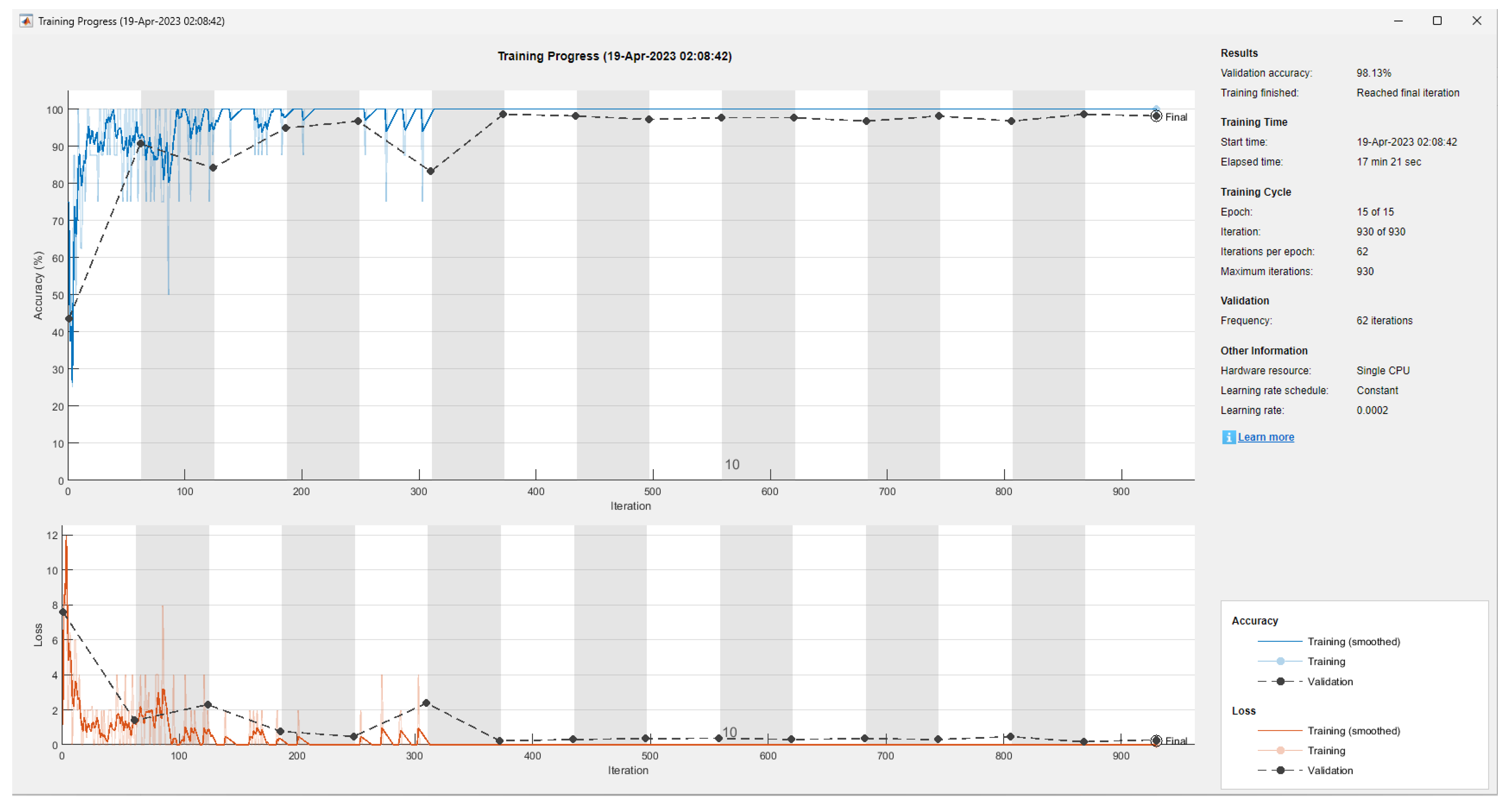
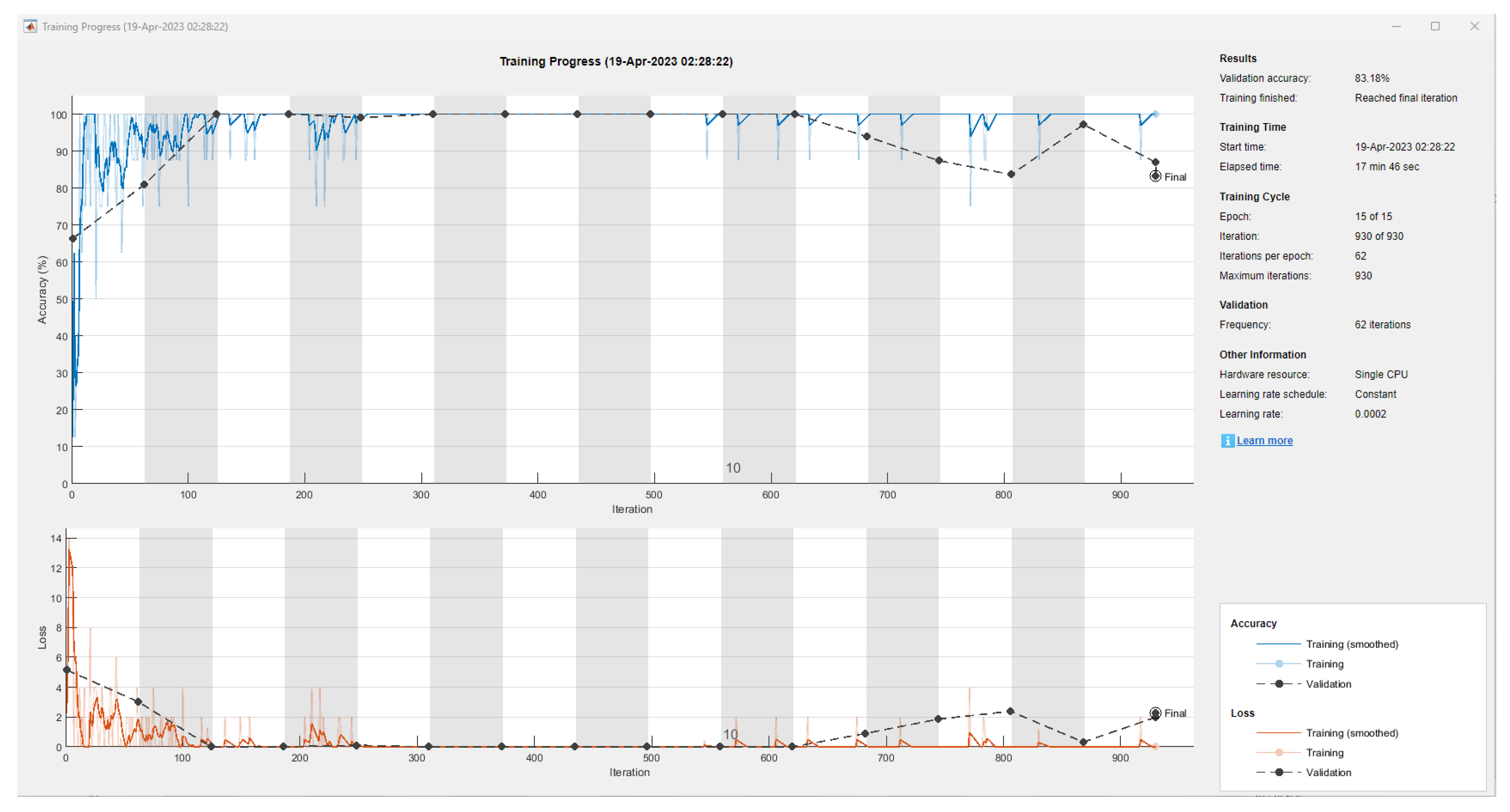
| Model | Filter Size | Filter Quantity | Accuracy | Training and Validation Time |
|---|---|---|---|---|
| 1 | 5 × 5 | 36 | 91.12% | 17 min 27 s |
| 2 | 5 × 5 | 37 | 92.06% | 17 min 46 s |
| 3 | 5 × 5 | 38 | 64.95% | 20 min 33 s |
| 4 | 7 × 7 | 37 | 57.94% | 20 min 56 s |
| 5 | 3 × 3 | 37 | 98.13% | 17 min 21 s |
| 6 | 3 × 3 | 38 | 83.18% | 17 min 46 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peralta-López, J.-E.; Morales-Viscaya, J.-A.; Lázaro-Mata, D.; Villaseñor-Aguilar, M.-J.; Prado-Olivarez, J.; Pérez-Pinal, F.-J.; Padilla-Medina, J.-A.; Martínez-Nolasco, J.-J.; Barranco-Gutiérrez, A.-I. Speed Bump and Pothole Detection Using Deep Neural Network with Images Captured through ZED Camera. Appl. Sci. 2023, 13, 8349. https://doi.org/10.3390/app13148349
Peralta-López J-E, Morales-Viscaya J-A, Lázaro-Mata D, Villaseñor-Aguilar M-J, Prado-Olivarez J, Pérez-Pinal F-J, Padilla-Medina J-A, Martínez-Nolasco J-J, Barranco-Gutiérrez A-I. Speed Bump and Pothole Detection Using Deep Neural Network with Images Captured through ZED Camera. Applied Sciences. 2023; 13(14):8349. https://doi.org/10.3390/app13148349
Chicago/Turabian StylePeralta-López, José-Eleazar, Joel-Artemio Morales-Viscaya, David Lázaro-Mata, Marcos-Jesús Villaseñor-Aguilar, Juan Prado-Olivarez, Francisco-Javier Pérez-Pinal, José-Alfredo Padilla-Medina, Juan-José Martínez-Nolasco, and Alejandro-Israel Barranco-Gutiérrez. 2023. "Speed Bump and Pothole Detection Using Deep Neural Network with Images Captured through ZED Camera" Applied Sciences 13, no. 14: 8349. https://doi.org/10.3390/app13148349