
Improved Retinex-Theory-Based Low-Light Image Enhancement Algorithm

Abstract
:1. Introduction
- (1)
- We designed a new decomposition module with the introduction of residual connections, aiming to reduce the loss of detailed information during the decomposition process and obtain more accurate illumination and reflection maps.
- (2)
- An effective method is proposed for low-illumination image enhancement.
- (3)
- By introducing an attention mechanism to improve the network structure and adding a color consistency loss function, the illumination and reflection images can be effectively obtained via the processing.
- (4)
- The proposed method is significantly better than the current techniques for improving low-light images when it comes to visual perception and evaluation indexes.

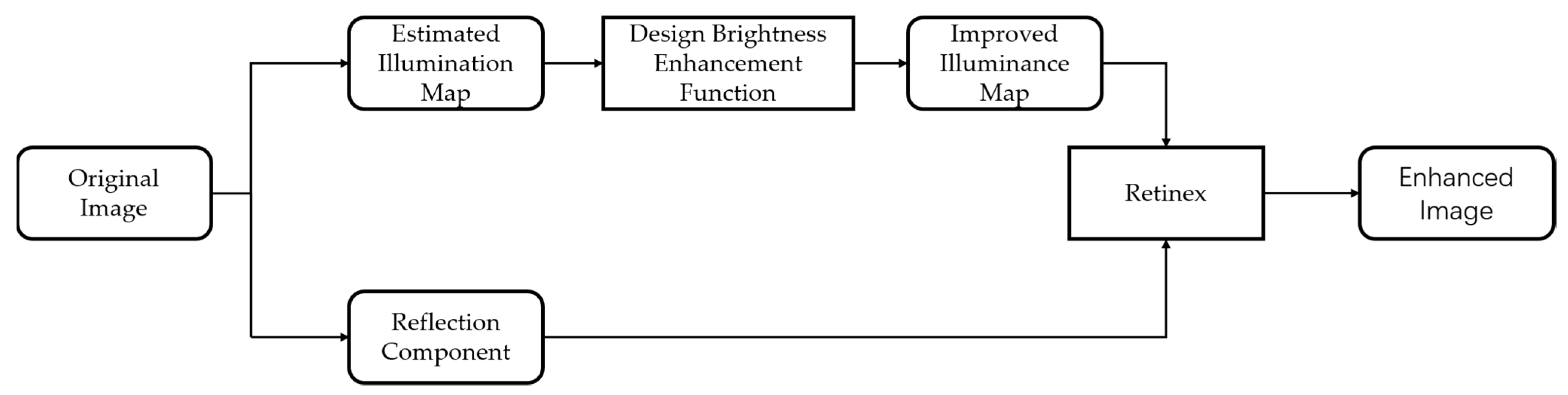
2. Related Work
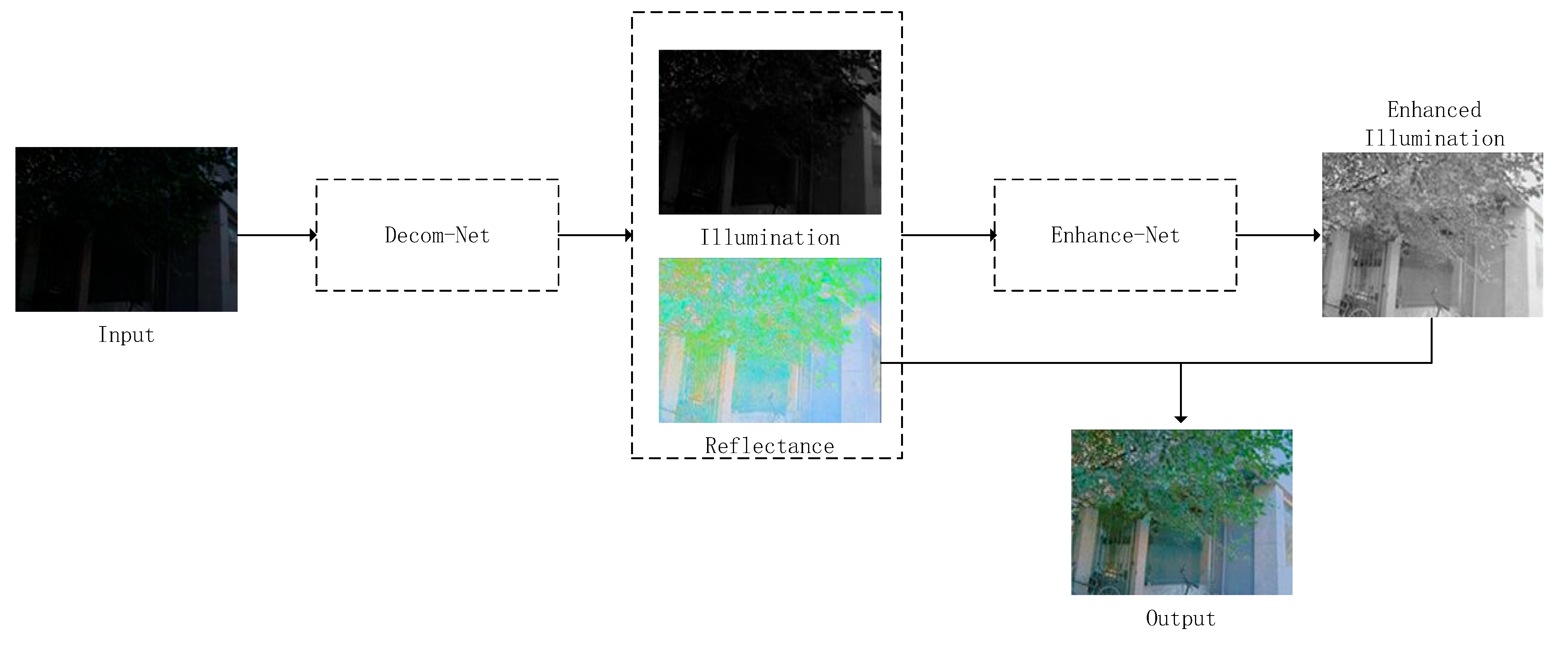
3. Proposed Method
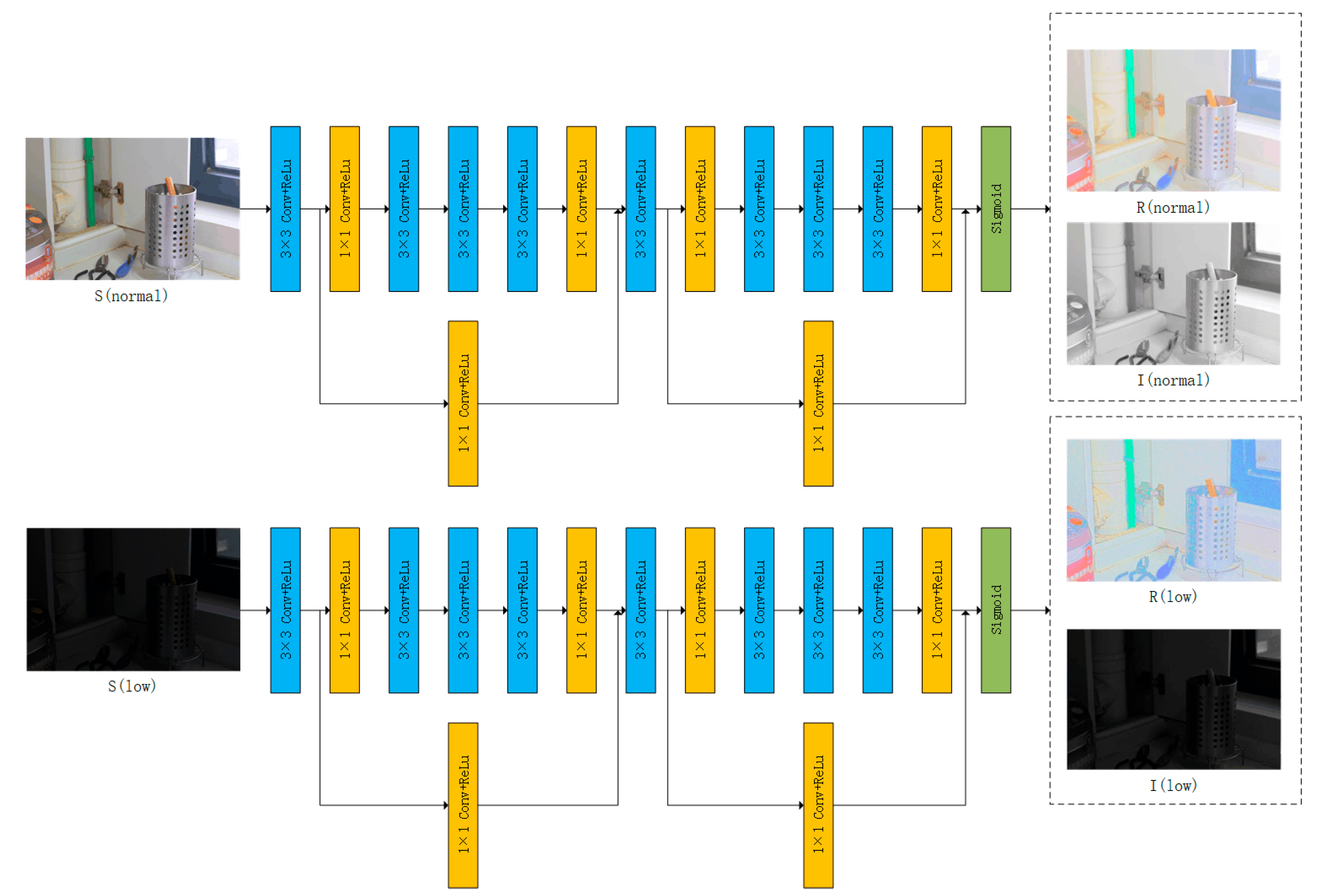
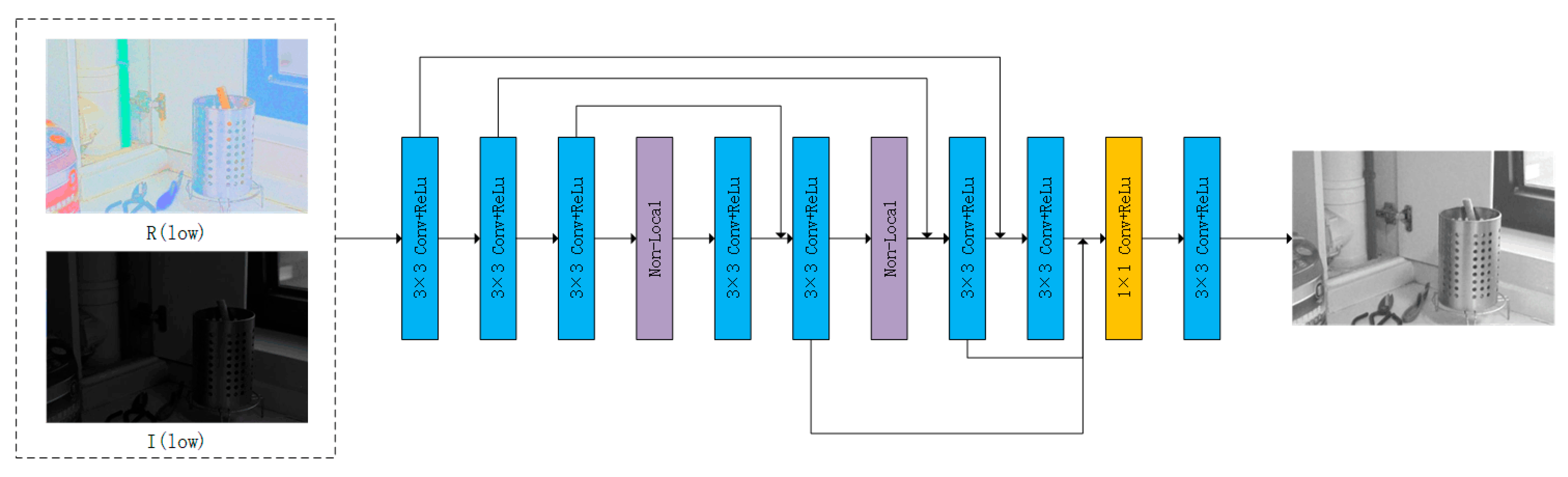
3.1. Decom-Net
3.2. Enhance-Net
3.3. Loss Function
4. Experiments
4.1. Experimental Implementation Details
4.2. Experimental Comparison
4.3. Ablation Study
4.4. Experimental Discussion
5. Limitations and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fang, M.; Li, H.; Lei, L. A review on low light video image enhancement algorithms. J. Chang. Univ. Sci. Technol. 2016, 39, 56–64. [Google Scholar]
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.-M.; Gu, J.; Loy, C.C. Low-light image and video enhancement using deep learning: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 9396–9416. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Xu, D.; Yang, W.; Fan, M.; Huang, H. Benchmarking low-light image enhancement and beyond. Int. J. Comput. Vis. 2021, 129, 1153–1184. [Google Scholar] [CrossRef]
- Zheng, S.; Ma, Y.; Pan, J.; Lu, C.; Gupta, G. Low-Light Image and Video Enhancement: A Comprehensive Survey and Beyond. arXiv 2022, arXiv:2212.10772. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Hai, J.; Xuan, Z.; Yang, R.; Hao, Y.; Zou, F.; Lin, F.; Han, S. R2rnet: Low-light image enhancement via real-low to real-normal network. J. Vis. Commun. Image Represent. 2023, 90, 103712. [Google Scholar] [CrossRef]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vis. Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Reza, A.M. Realization of the contrast limited adaptive histogram equalization (CLAHE) for real-time image enhancement. J. VLSI Signal. Process. Syst. Signal. Image Video Technol. 2004, 38, 35–44. [Google Scholar] [CrossRef]
- Rahman, Z.-u.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. In Proceedings of the 3rd IEEE International Conference on Image Processing, Lausanne, Switzerland, 19 September 1996; pp. 1003–1006. [Google Scholar]
- Jobson, D.J.; Rahman, Z.-u.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef] [Green Version]
- Fu, Y.; Hong, Y.; Chen, L.; You, S. LE-GAN: Unsupervised low-light image enhancement network using attention module and identity invariant loss. Knowl.-Based Syst. 2022, 240, 108010. [Google Scholar] [CrossRef]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Toward fast, flexible, and robust low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5637–5646. [Google Scholar]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the BMVC, Newcastle, UK, 3–6 September 2018; p. 4. [Google Scholar]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A convolutional neural network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Lim, S.; Kim, W. DSLR: Deep stacked Laplacian restorer for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Liu, X.; Shen, Y.; Zhang, S.; Zhao, S. Zero-shot restoration of back-lit images using deep internal learning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1623–1631. [Google Scholar]
- Li, C.; Guo, C.; Loy, C.C. Learning to enhance low-light image via zero-reference deep curve estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4225–4238. [Google Scholar] [CrossRef] [PubMed]
- Hore, A.; Ziou, D. Image quality metrics: PSNR vs. SSIM. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2366–2369. [Google Scholar]
- Seshadrinathan, K.; Soundararajan, R.; Bovik, A.C.; Cormack, L.K. Study of subjective and objective quality assessment of video. IEEE Trans. Image Process. 2010, 19, 1427–1441. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Zheng, J.; Hu, H.-M.; Li, B. Naturalness preserved enhancement algorithm for non-uniform illumination images. IEEE Trans. Image Process. 2013, 22, 3538–3548. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.-M.; Gu, J.; Loy, C.C. Lighting the darkness in the deep learning era. arXiv 2021, arXiv:2104.10729. [Google Scholar]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-light image enhancement via illumination map estimation. IEEE Trans. Image Process. 2016, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Lee, C.; Kim, C.-S. Contrast enhancement based on layered difference representation of 2D histograms. IEEE Trans. Image Process. 2013, 22, 5372–5384. [Google Scholar] [CrossRef] [PubMed]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1780–1789. [Google Scholar]










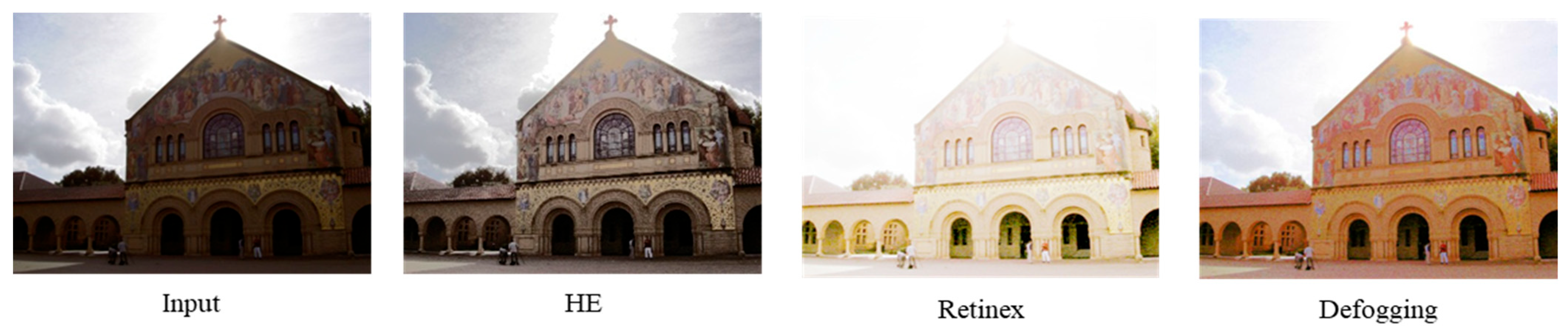{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PSNR | SSIM | MSE | LPIPS | VIF |
|---|---|---|---|---|---|
| Input | 7.773 | 0.121 | 12613.620 | 0.560 | 0.266 |
| LightenNet [16] | 11.965 | 0.632 | 5661.574 | 0.359 | 0.704 |
| MBLLEN [15] | 17.655 | 0.930 | 1515.911 | 0.287 | 0.956 |
| RetinexNet [5] | 17.399 | 0.916 | 1565.746 | 0.363 | 0.963 |
| EnlightenGAN [17] | 17.539 | 0.919 | 1960.018 | 0.326 | 0.938 |
| DSLR [18] | 14.935 | 0.838 | 3679.389 | 0.403 | 0.862 |
| ExCNet [19] | 16.390 | 0.908 | 2159.039 | 0.327 | 0.935 |
| RRDNet [14] | 10.878 | 0.511 | 6966.992 | 0.336 | 0.642 |
| Zero-DCE [27] | 14.861 | 0.827 | 3281.716 | 0.335 | 0.868 |
| Zero-DCE++ [20] | 14.682 | 0.855 | 3207.455 | 0.340 | 0.882 |
| R2RNet [6] | 18.179 | 0.892 | 1498.952 | 0.272 | 0.950 |
| Our method | 18.208 | 0.932 | 1459.655 | 0.318 | 0.959 |
| Method | LIME | VV | DICM | Avg. |
|---|---|---|---|---|
| LightenNet [16] | 4.681 | 3.729 | 3.735 | 4.048 |
| MBLLEN [15] | 4.818 | 4.294 | 3.442 | 4.185 |
| RetinexNet [5] | 4.361 | 3.422 | 4.209 | 3.997 |
| EnlightenGAN [17] | 3.697 | 2.981 | 3.570 | 3.416 |
| DSLR [18] | 4.033 | 3.649 | 3.389 | 3.690 |
| ExCNet [19] | 4.162 | 3.783 | 3.039 | 3.661 |
| RRDNet [14] | 4.522 | 3.845 | 3.992 | 4.120 |
| Zero-DCE [27] | 3.928 | 3.217 | 3.716 | 3.620 |
| Zero-DCE++ [20] | 3.843 | 3.341 | 2.835 | 3.339 |
| R2RNet [6] | 3.704 | 3.093 | 3.503 | 3.433 |
| Our method | 3.547 | 3.364 | 3.312 | 3.408 |
| Method | Running Time (s) |
|---|---|
| LightenNet [16] | 0.983 |
| MBLLEN [15] | 3.975 |
| RetinexNet [5] | 0.469 |
| EnlightenGAN [17] | 0.012 |
| DSLR [18] | 0.942 |
| ExCNet [19] | 12.748 |
| RRDNet [14] | 78.386 |
| Zero-DCE [27] | 0.671 |
| Zero-DCE++ [20] | 0.747 |
| R2RNet [6] | 3.704 |
| Our method | 0.633 |
| Method | PSNR | SSIM | MSE | NIQE |
|---|---|---|---|---|
| 0.01 | 17.466 | 0.931 | 1660.814 | 3.404 |
| 0.1 | 17.590 | 0.928 | 1624.519 | 3.560 |
| 0.5 | 17.281 | 0.927 | 1703.411 | 3.282 |
| 0.01 | 17.470 | 0.932 | 1592.601 | 3.184 |
| 0.1 | 17.087 | 0.913 | 1850.028 | 3.931 |
| 0.5 | 17.275 | 0.919 | 1711.196 | 3.752 |
| 0.01 | 17.560 | 0.923 | 1611.588 | 3.461 |
| 0.1 | 16.623 | 0.898 | 1919.451 | 3.930 |
| 0.5 | 17.394 | 0.920 | 1720.743 | 3.406 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wang, H.; Sun, Y.; Yang, J. Improved Retinex-Theory-Based Low-Light Image Enhancement Algorithm. Appl. Sci. 2023, 13, 8148. https://doi.org/10.3390/app13148148
Wang J, Wang H, Sun Y, Yang J. Improved Retinex-Theory-Based Low-Light Image Enhancement Algorithm. Applied Sciences. 2023; 13(14):8148. https://doi.org/10.3390/app13148148
Chicago/Turabian StyleWang, Jiarui, Hanjia Wang, Yu Sun, and Jie Yang. 2023. "Improved Retinex-Theory-Based Low-Light Image Enhancement Algorithm" Applied Sciences 13, no. 14: 8148. https://doi.org/10.3390/app13148148