
Accelerating Pattern Matching Using a Novel Multi-Pattern-Matching Algorithm on GPU
Abstract
:1. Introduction
- Identifying GPU programming difficulties, such as memory access overhead, warp divergence, bank conflict, and misaligned or uncoalesced memory accesses to develop high-performance DPI systems;
- Proposing a multi-pattern-matching algorithm that reduces the memory space required in the pattern-matching process and shortens the pattern-matching time compared to existing DPI algorithms;
- Applying the optimization techniques determined to the created DPI system to overcome the memory access overhead difficulty arising from pattern-matching algorithms during the execution of the DPI process on the GPU platform.
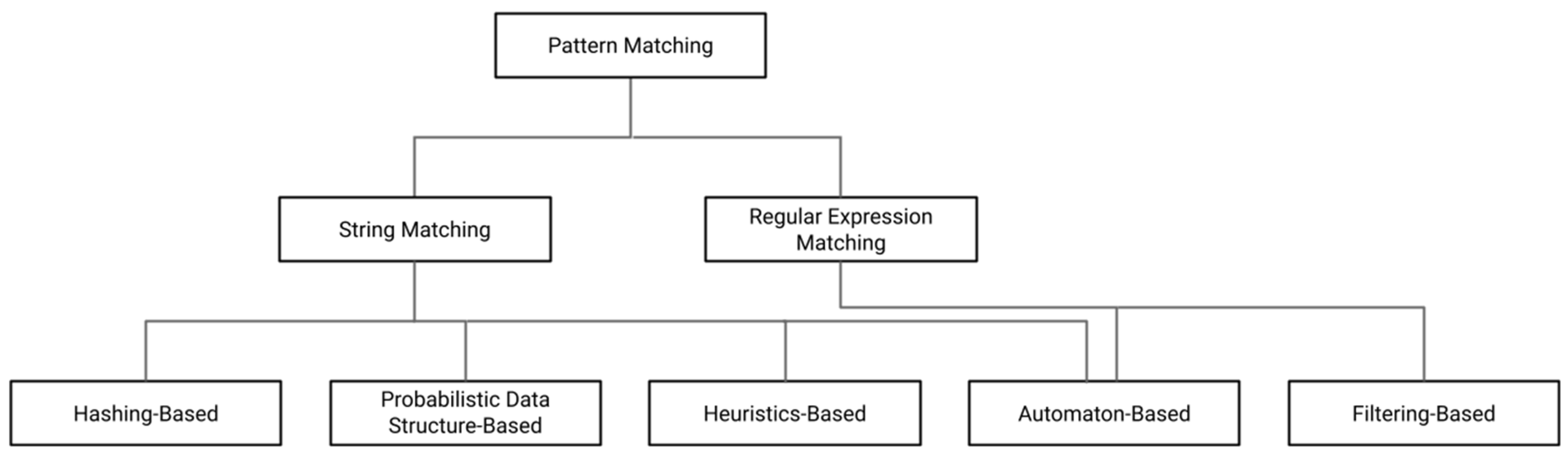
2. Pattern-Matching Algorithms Review
2.1. Hashing-Based Technique
2.2. Probabilistic-Data-Structure-Based Technique
2.3. Heuristics-Based Technique
Wu–Manber Algorithm
- The matching window is placed to cover the first m characters of the packet payload. In this case, the packet payload pointer tp represents the suffix character block of the matching window.
- If the pointer value showing the last element of the packet payload is less than or equal to the value of the tp pointer, the hash value of the suffix character block of the matching window is calculated. Otherwise, the matching process ends in the current packet.
- This hash value is used in the search operation in a SHIFT table. If the shift distance of the character block is 0, it is possible that the matching window can be the first m characters of a pattern, and, in this case, it is possible to go to Step 4 for the prefix hash calculations. Otherwise, the tp value is increased by the shift distance, and the process returns to Step 2.
- The prefix hash values of patterns with the same suffix hash calculation are compared with the hash value of the prefix character block of T in the matching window.
- The pattern and packet payload are compared byte by byte if a correct comparison is detected in Step 4. If any match is found, the match is saved. The tp value is increased by one, and the process returns to Step 2.
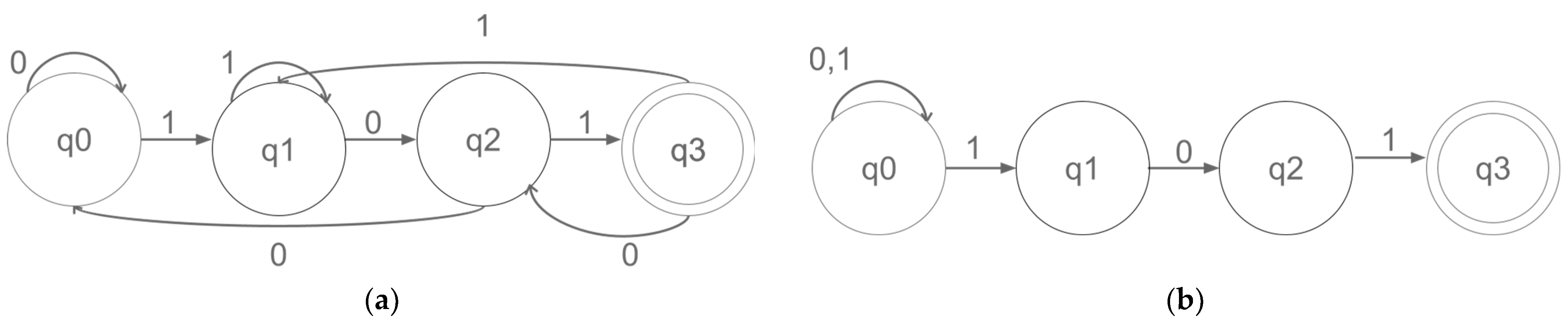
2.4. Automaton-Based Technique
Aho–Corasick Algorithm
2.5. Filtering-Based Technique
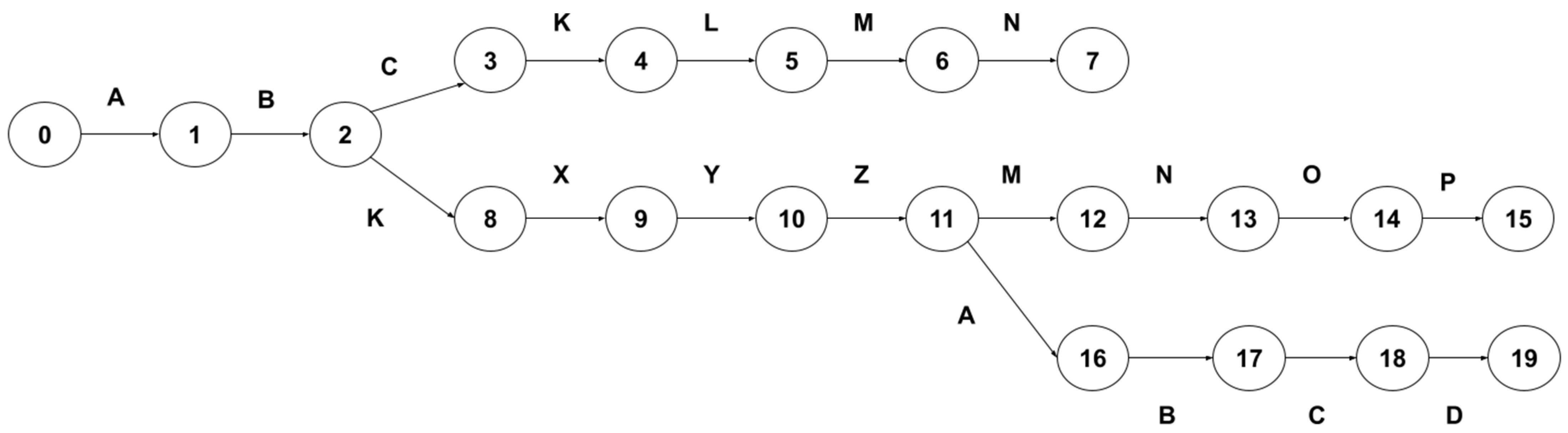
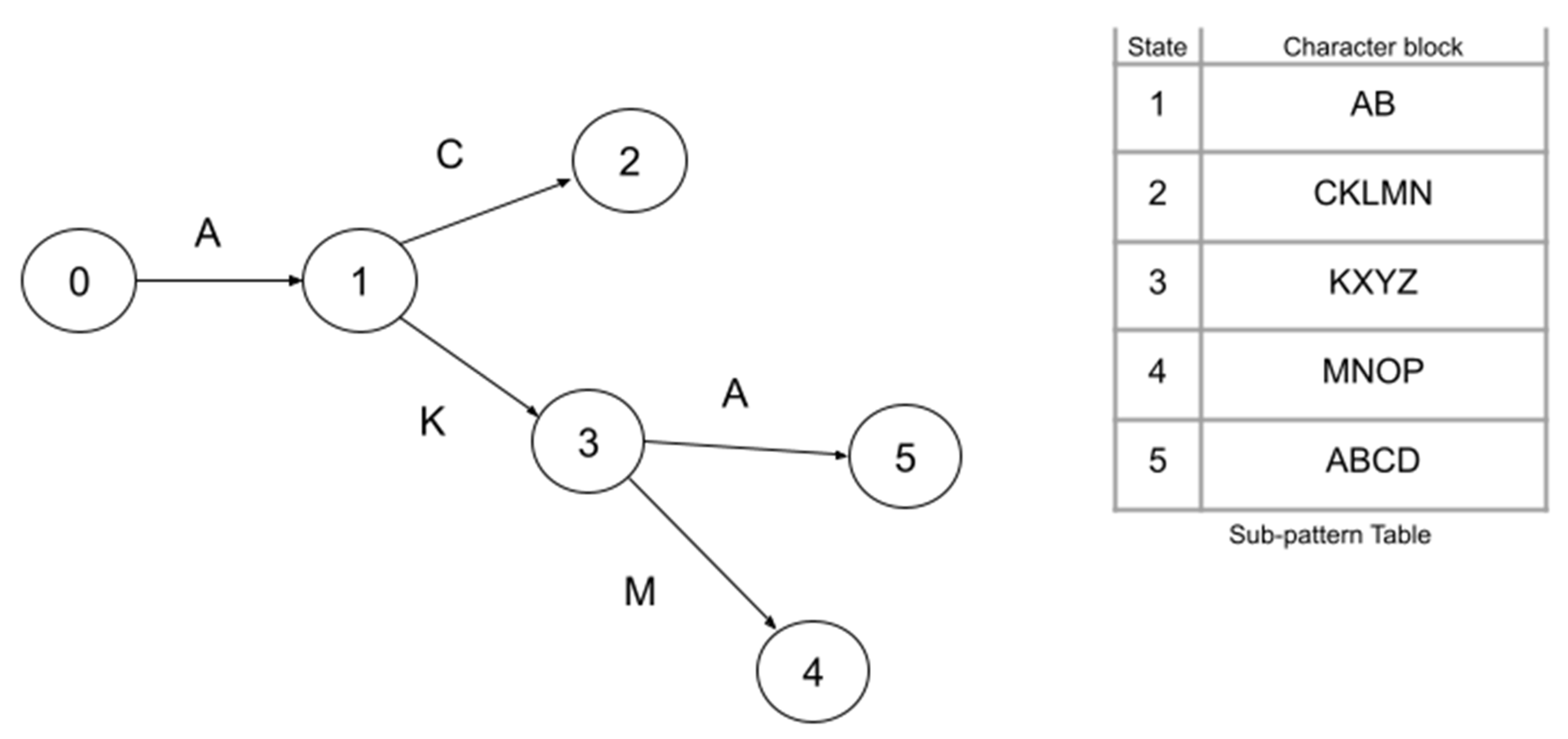
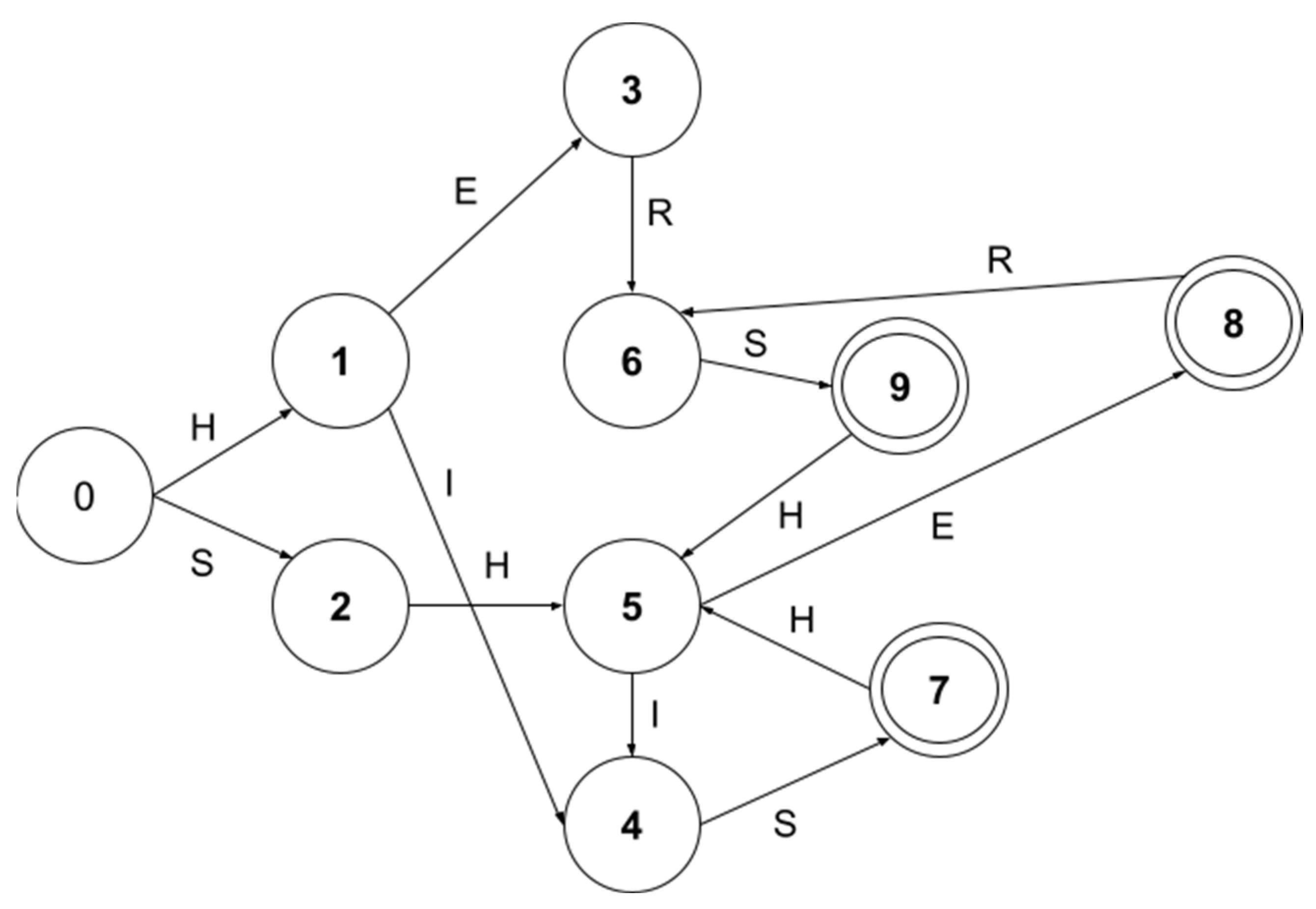
3. A Novel Multi-Pattern-Matching Algorithm
3.1. Problem Definition
3.2. Proposed Algorithm
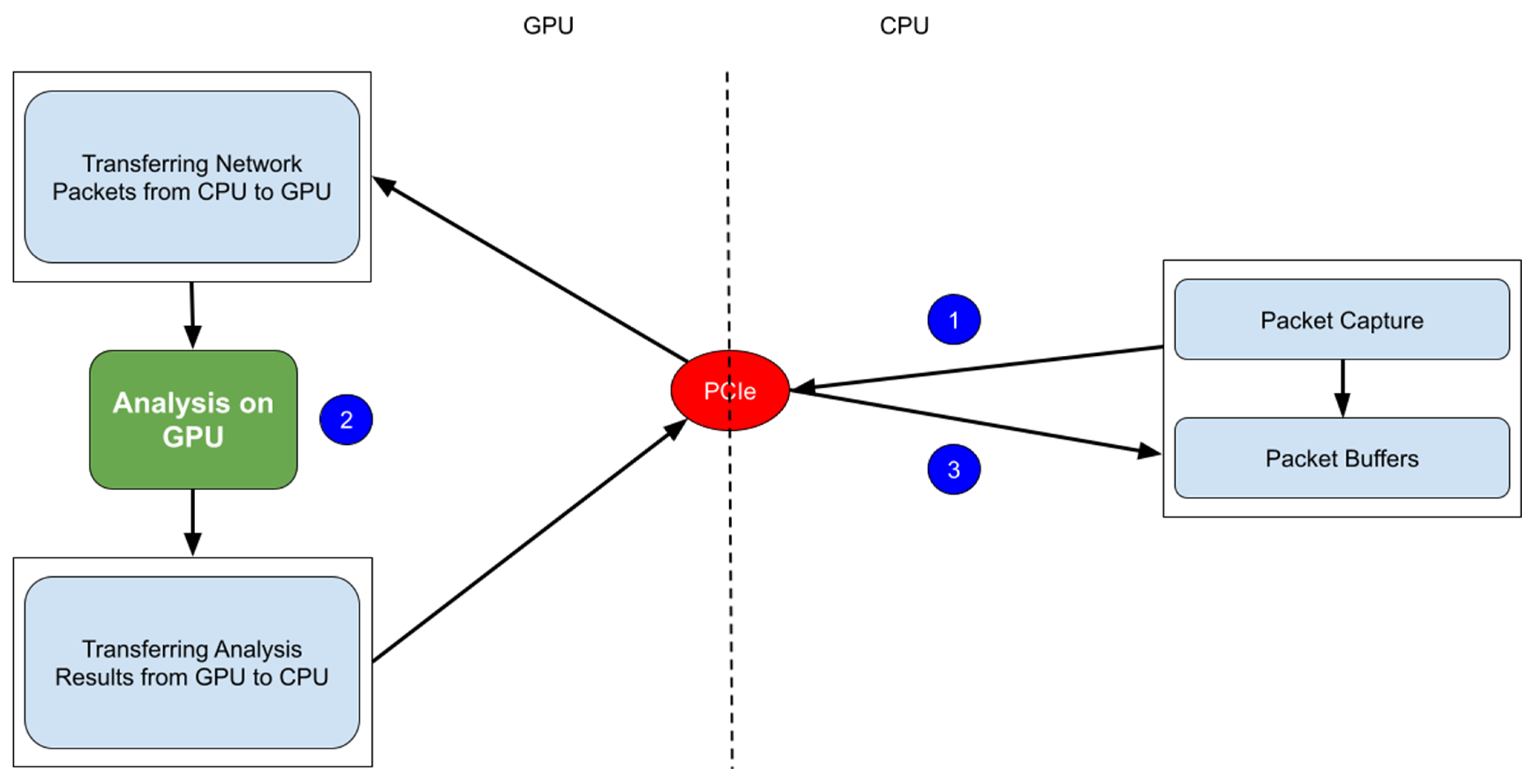
4. GPU Performance Issues
4.1. Memory Access Overhead
4.2. Warp Divergence
4.3. Aligned and Coalesced Memory Access
4.4. Bank Conflict
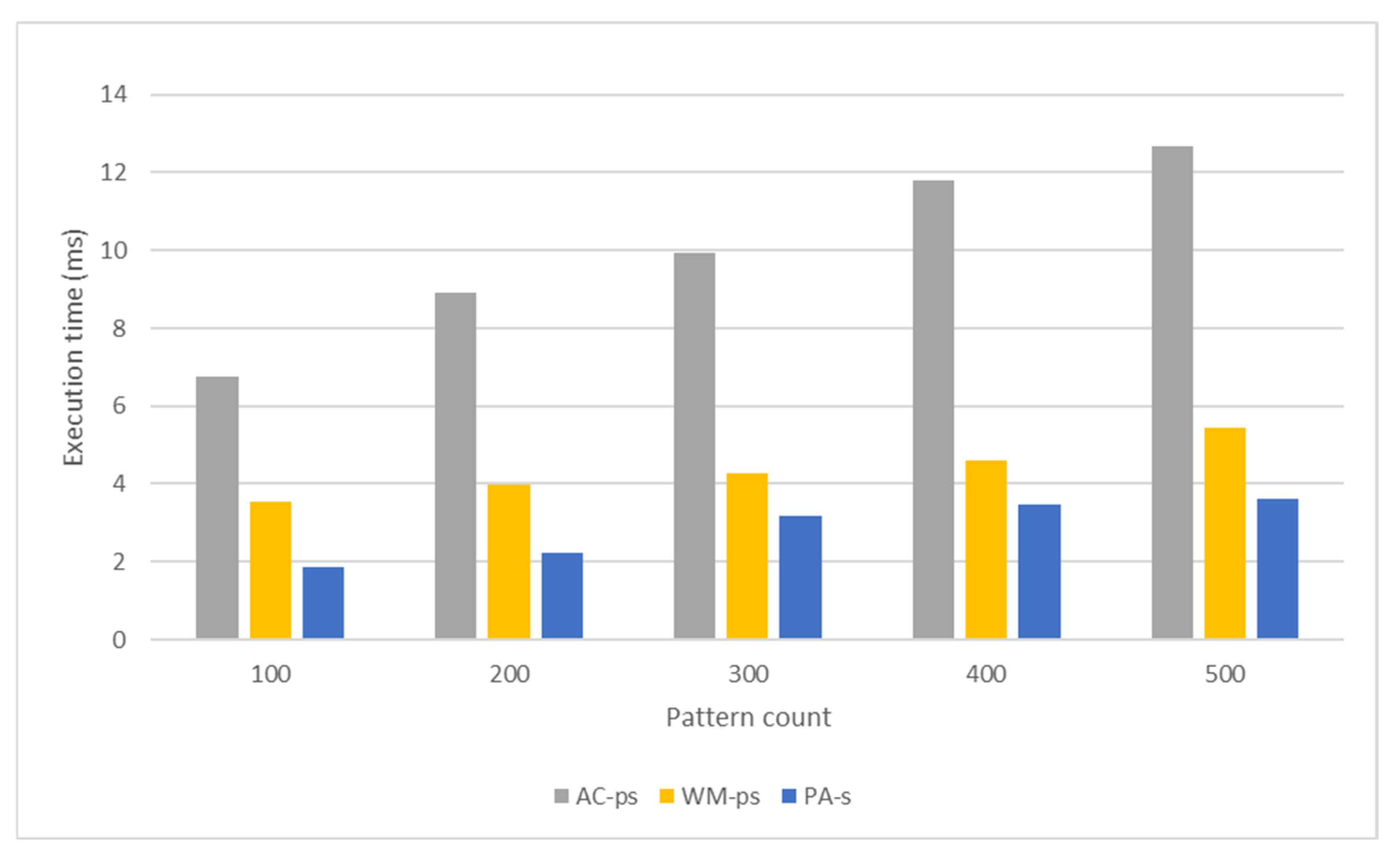
5. Experimental Results
5.1. Experimental Setup
5.2. Memory Analysis
5.2.1. Aho-Corasick Algorithm
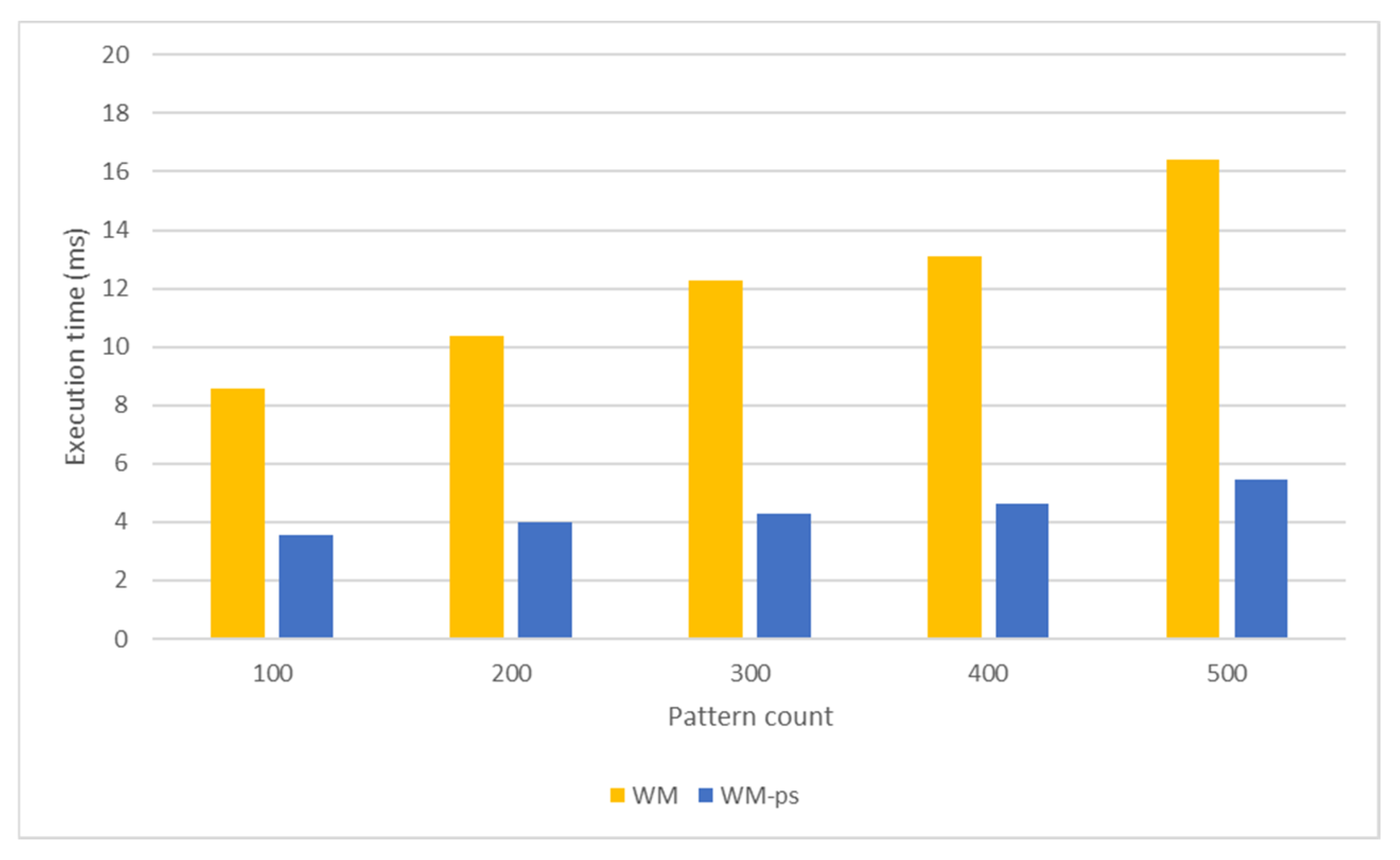
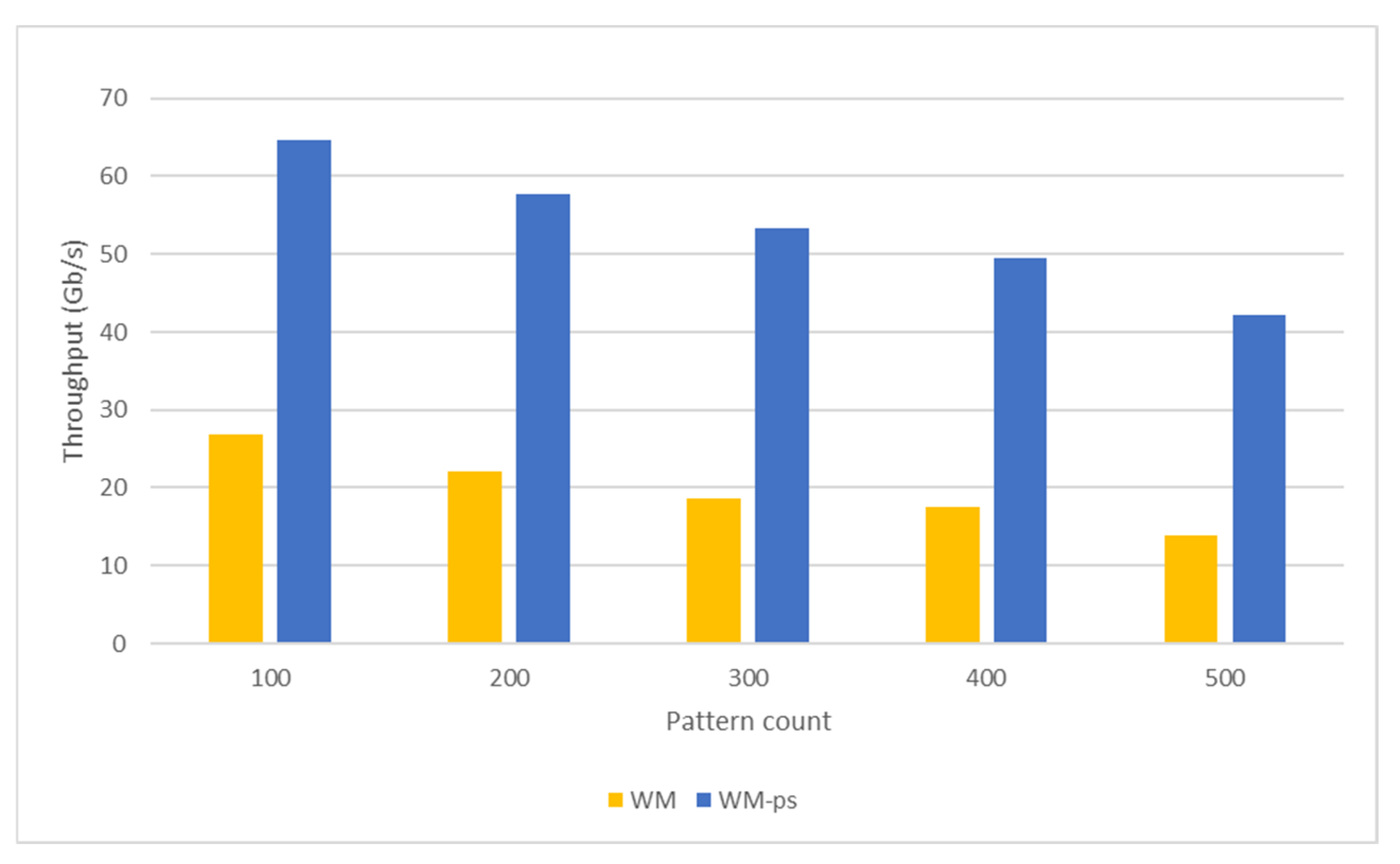
5.2.2. Wu–Manber Algorithm
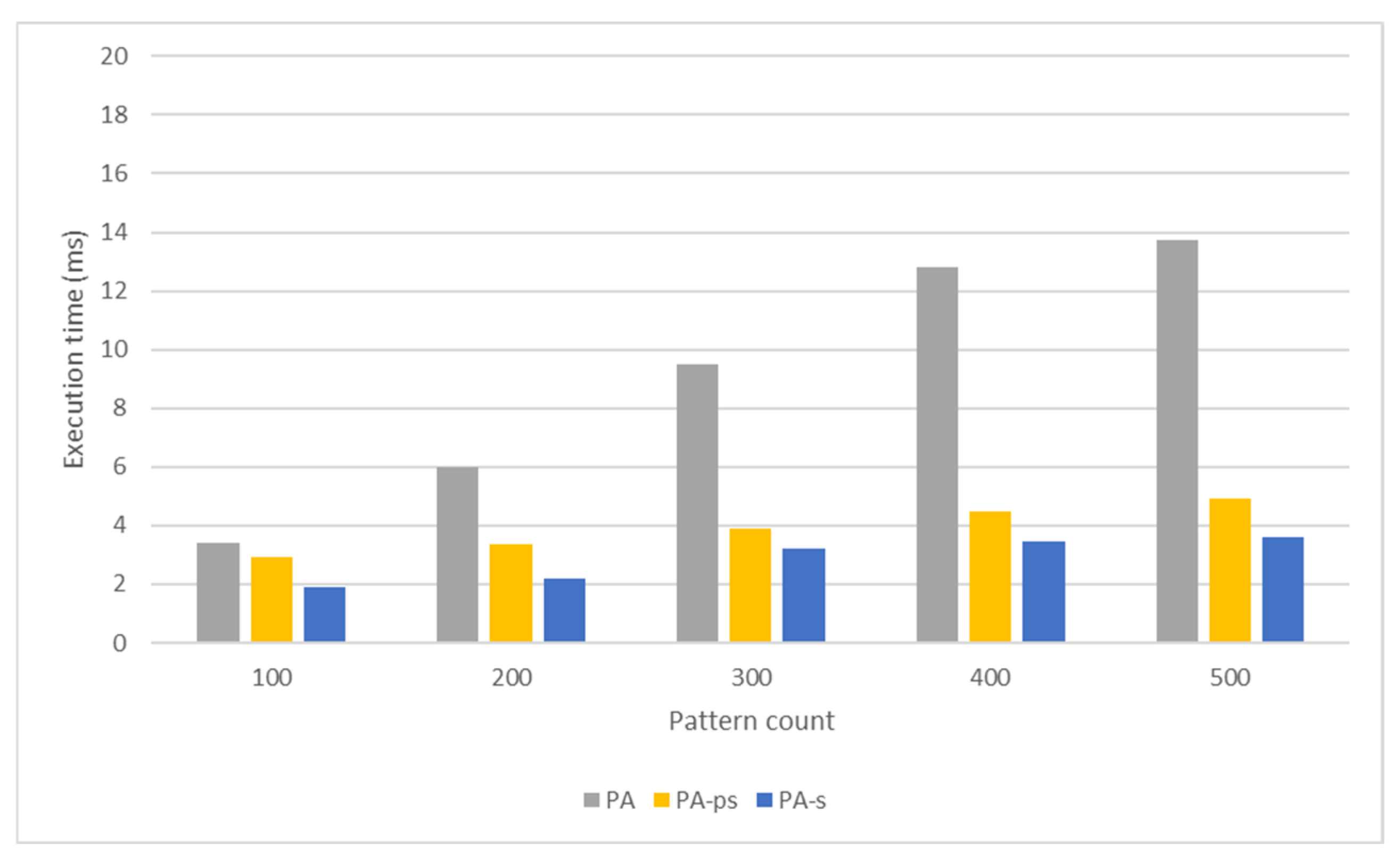
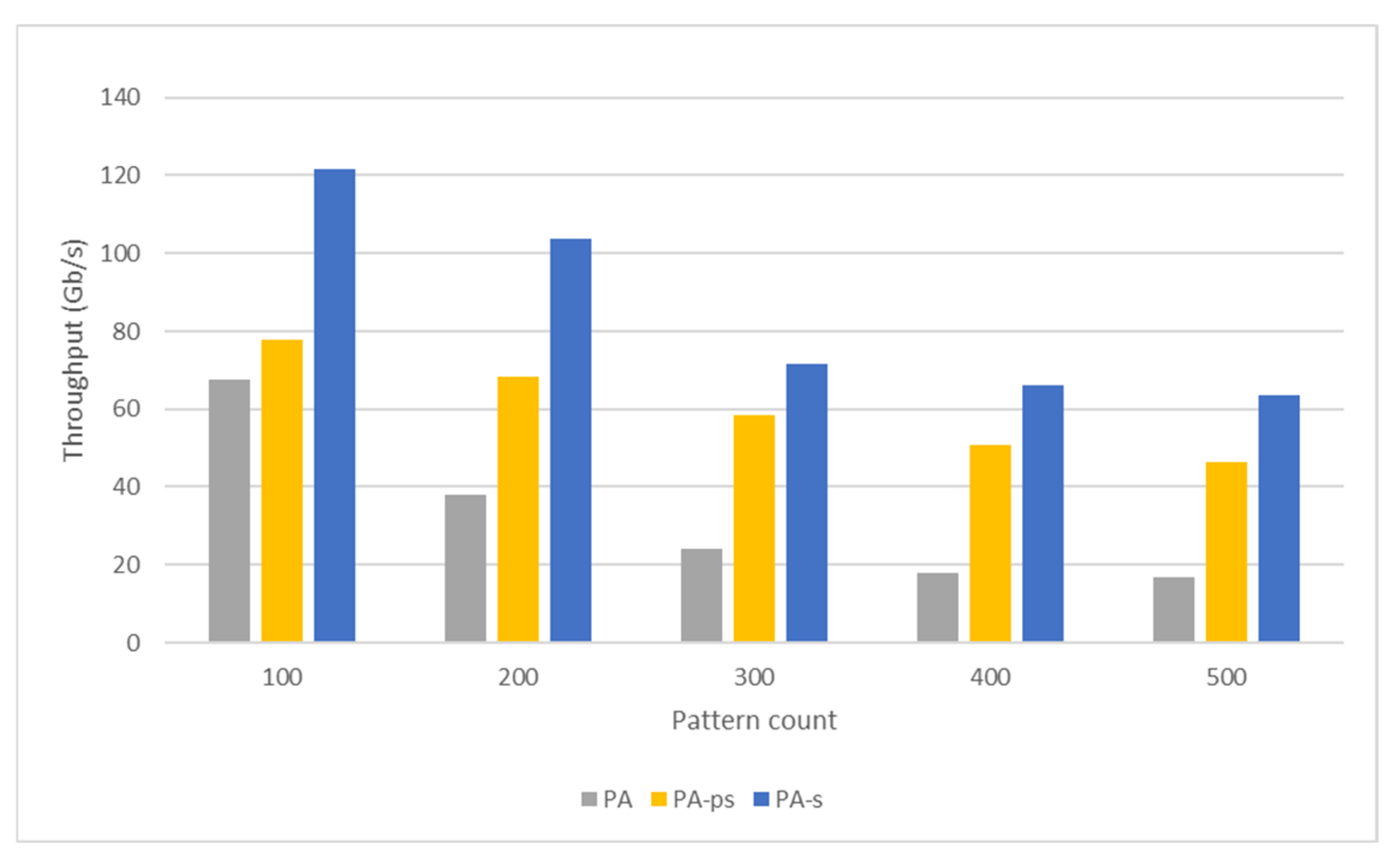
5.2.3. Proposed Algorithm
5.2.4. Comparison
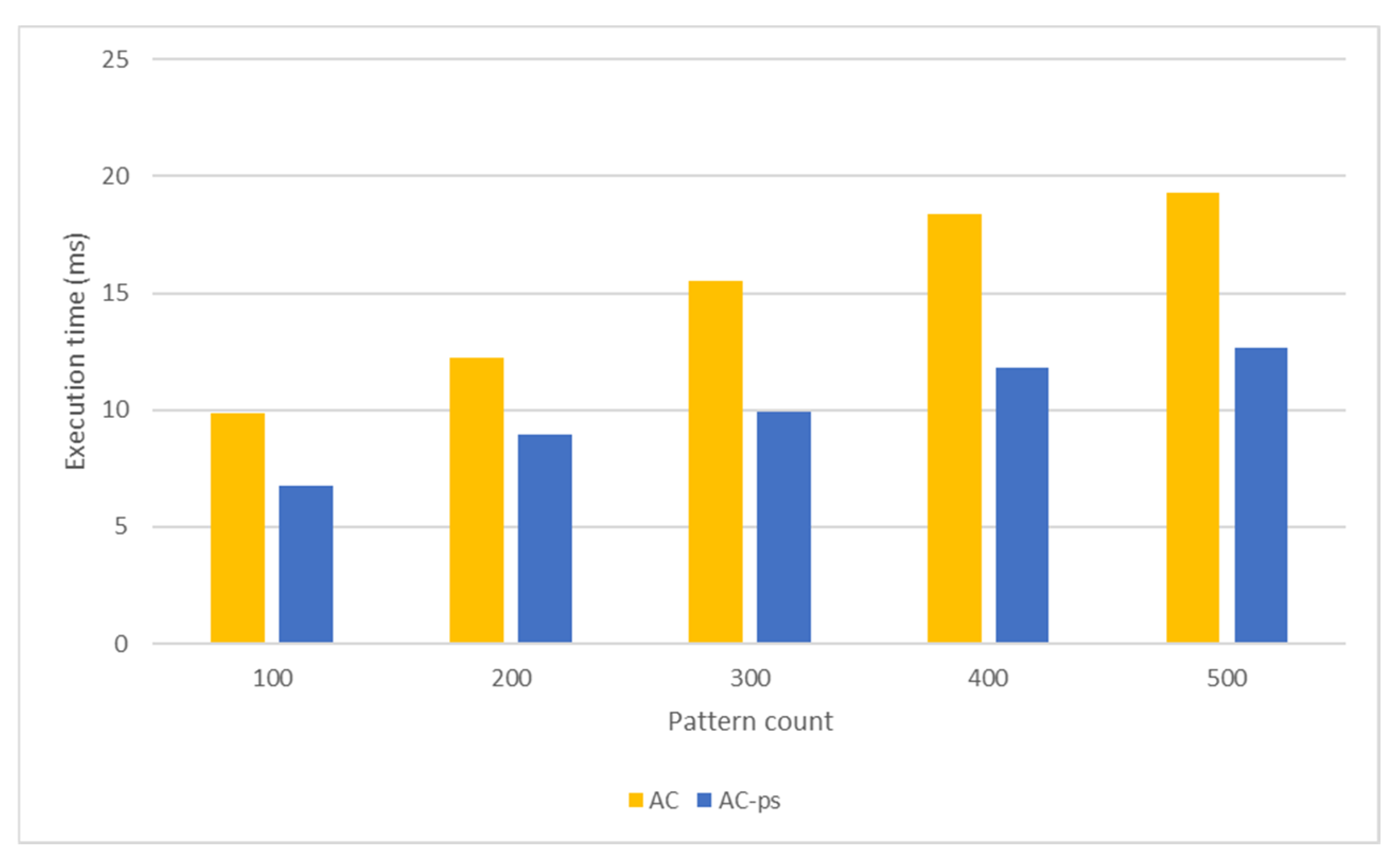
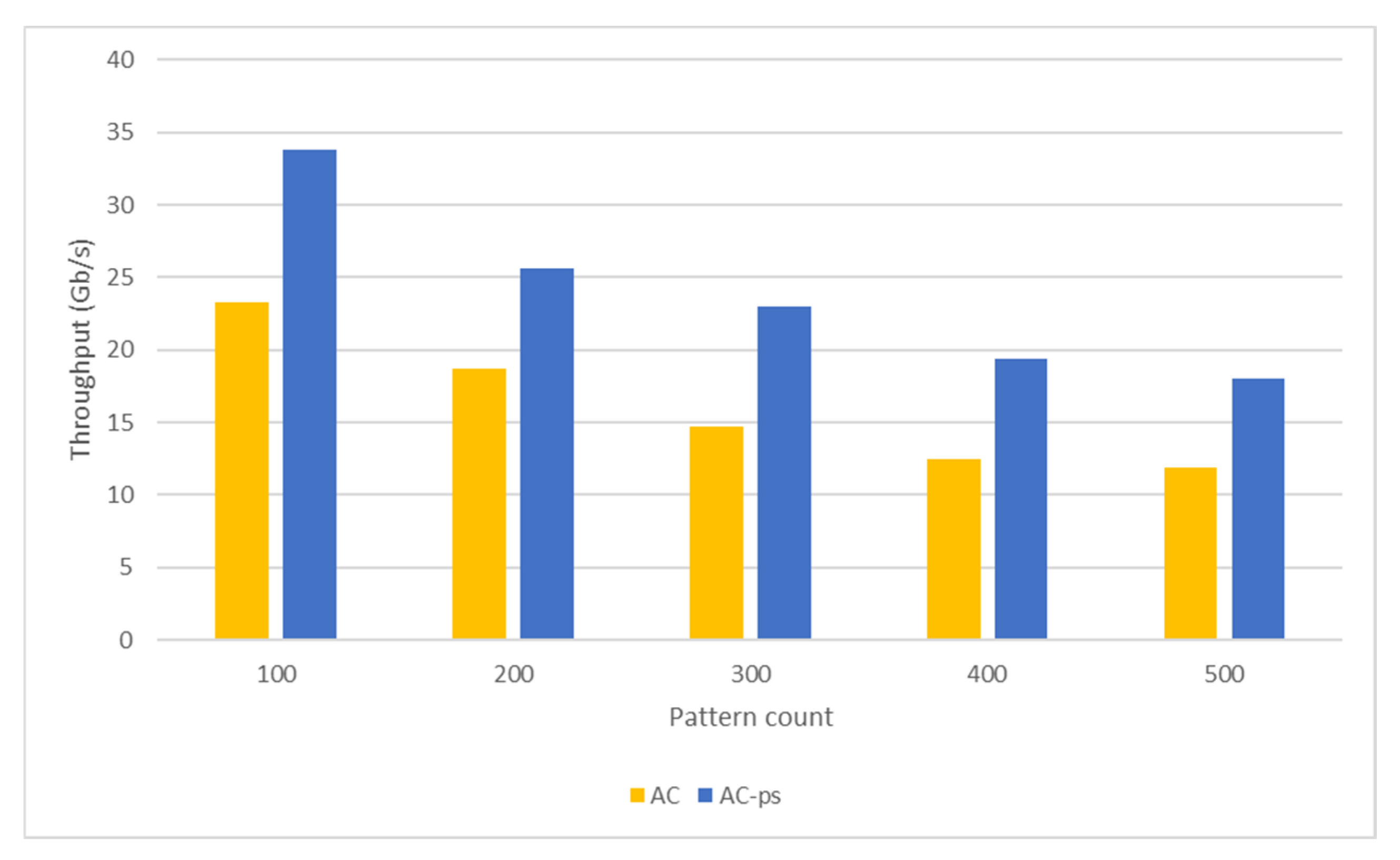
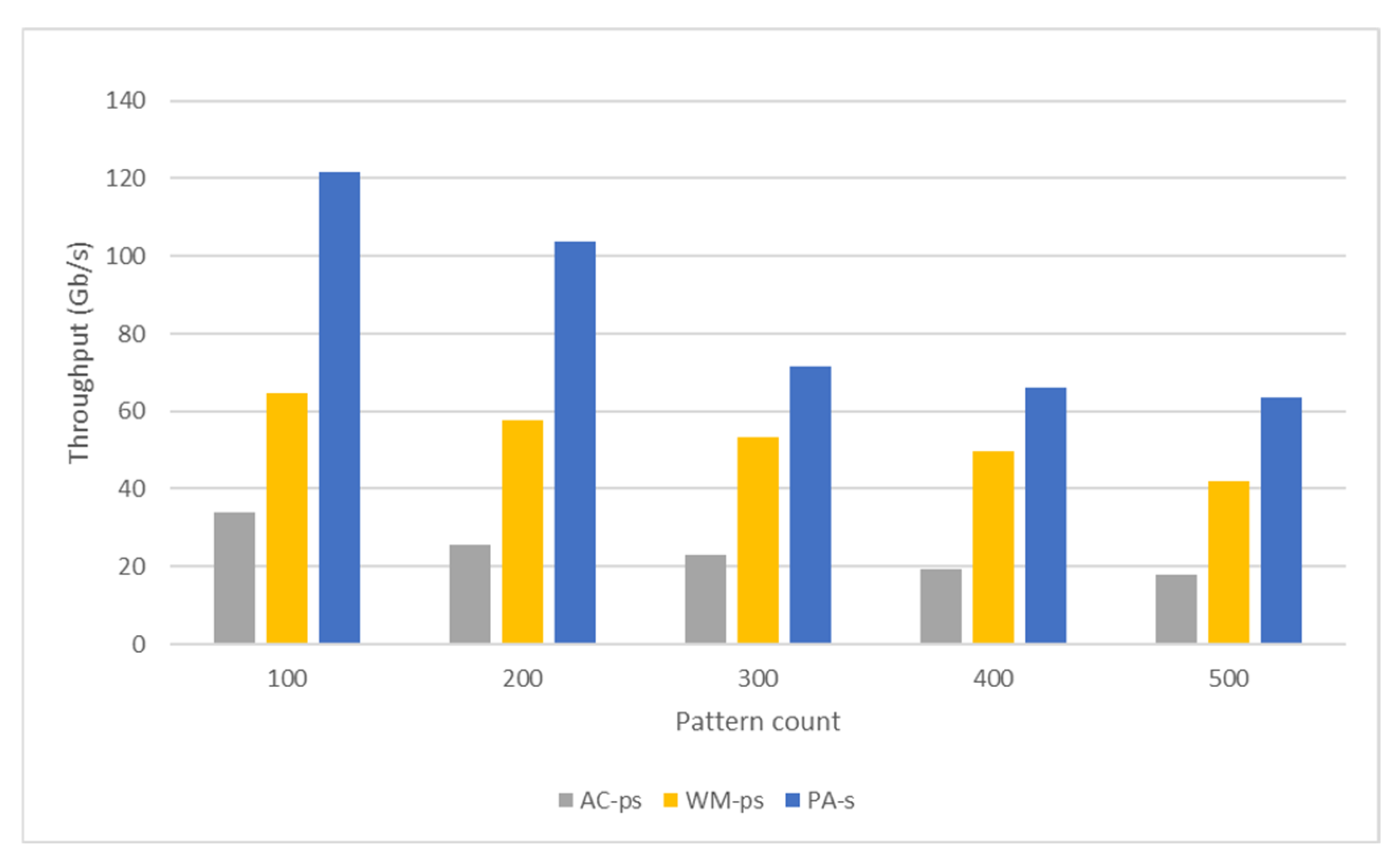
5.3. Throughput Analysis
5.3.1. Aho-Corasick Algorithm
| Algorithm 1 Aho-Corasick algorithm |
| input: InChar, cs, pos |
| while pos is less than 256 do |
| GetNextState(cs, InChar); |
| while cs is equal -1 do |
| GetStateFailure(cs); |
| end while |
| GetNextState(cs, InChar); |
| GetOutputState(cs); |
| if output is greater than 0 then |
| UpdateDetectedPatternCount(); |
| end if |
| end while |
5.3.2. Wu–Manber Algorithm
| Algorithm 2 Wu–Manber algorithm |
| input: pos, m, patSize |
| if pos is greater than m-1 or equal to m-1 then |
| targetTextSuffixHash=ComputeTargetTextSuffixHash(pos); |
| GetShift(targetTextSuffixHash); |
| if shift is equal to 0 then |
| targetTextPrefixHash=ComputeTargetTextPrefixHash(pos,m); |
| GetNumOfPatSameSuffixHashFromPrefixSizeTable(targetTextSuffixHash); |
| for count value from 0 to number of patterns with the same suffix hash calculation do |
| GetPrefixHashFromPrefixValueTable(targetTextSuffixHash,patSize,count); |
| if prefix hash of target text and prefix hash from prefix value table are equal then |
| GetPatIndexFromPrefixIndexTable(targetTextSuffixHash,patSize,count); |
| if Target text and pattern text are equal then |
| UpdateDetectedPatternCount(); |
| end if |
| end if |
| end for |
| end if |
| end if |
5.3.3. Proposed Algorithm
| Algorithm 3 Proposed algorithm |
| input: CC, CO, InChar, cs, pos |
| GetCluster(InChar,CC); |
| if cluster is not equal -1 then |
| GetCharacterSignature(CO); |
| GetStateSignature(CO); |
| GetCharacterSignature(InChar,CC); |
| if Character signatures of CC and CO are equal then |
| UpdateState(cs); |
| while cs is greater than 0 and pos is less than 256 do |
| if cs has state code then |
| if Target text and state text are equal then |
| UpdateInCharPosition(InChar,pos); |
| GetCluster(InChar,CC); |
| GetStateCodeLenght(cs); |
| while State code length is greater than 0 do |
| GetCharacterSignature(CO); |
| GetStateSignature(CO); |
| GetCluster(CO); |
| GetCharacterSignature(InChar,CC); |
| if character signatures of CC and CO are equal then |
| if clusters of CC and CO are equal then |
| UpdateState(cs); |
| end if |
| end if |
| end while |
| end if |
| else |
| if Target text and state text are equal then |
| UpdateDetectedPratternCount(); |
| end if |
| end if |
| end while |
| end if |
| end if |
5.3.4. Comparison
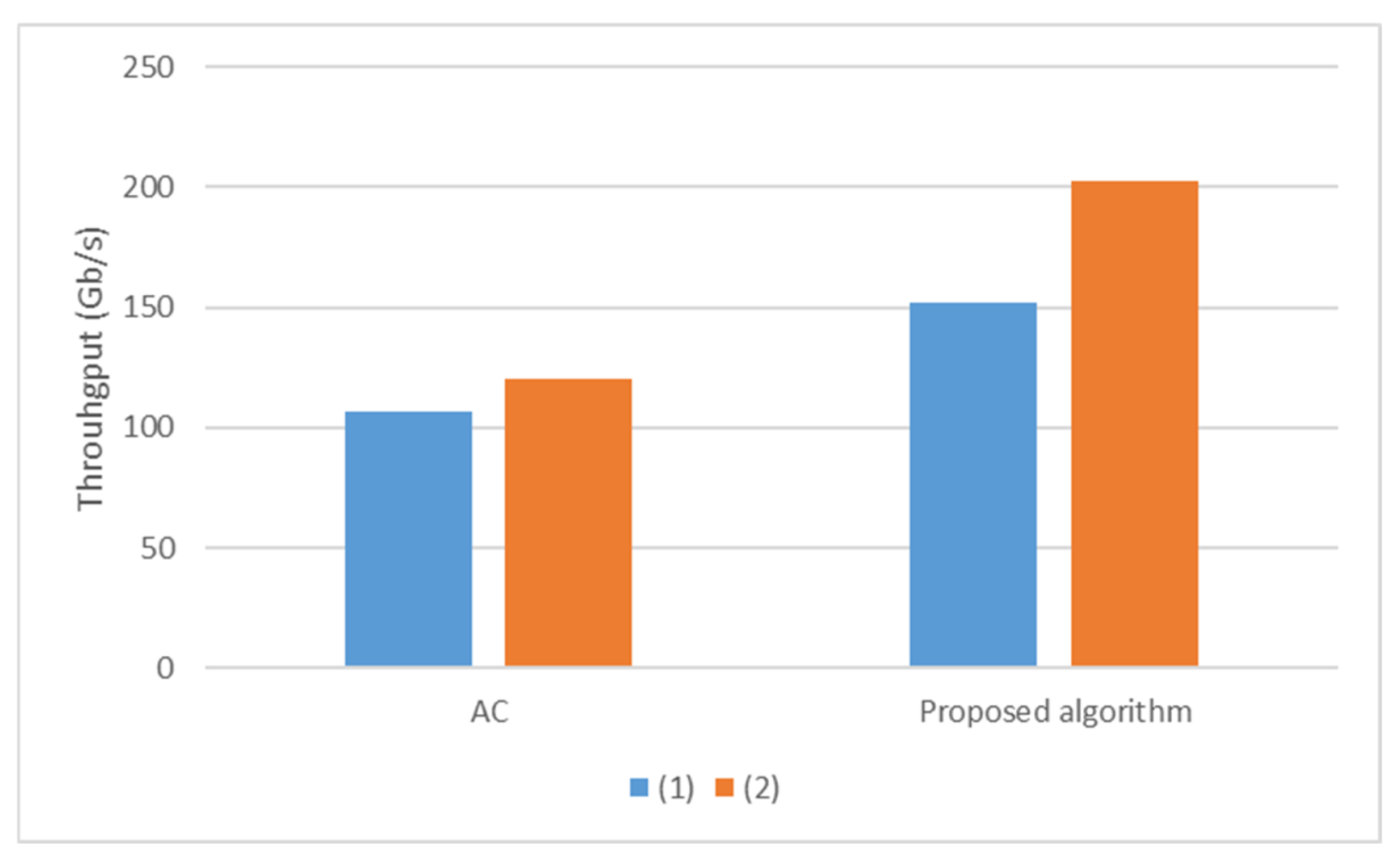
6. Related Work
A Comparison of the Proposed Algorithm with Related Studies
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pimenta Rodrigues, G.A.; de Oliveira Albuquerque, R.; Gomes de Deus, F.E.; de Sousa, R.T., Jr.; de Oliveira Júnior, G.A.; Garcia Villalba, L.J.; Kim, T.H. Cybersecurity and network forensics: Analysis of malicious traffic towards a honeynet with deep packet inspection. Appl. Sci. 2017, 7, 1082. [Google Scholar] [CrossRef] [Green Version]
- Raza, S.; Wallgren, L.; Voigt, T. SVELTE: Real-time intrusion detection in the Internet of Things. Ad Hoc Netw. 2013, 11, 2661–2674. [Google Scholar] [CrossRef]
- Sedjelmaci, H.; Senouci, S.M.; Al-Bahri, M.A. lightweight anomaly detection technique for low-resource IoT devices: A game-theoretic methodology. In Proceedings of the IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 23–27 May 2016. [Google Scholar]
- Xu, C.; Chen, S.; Su, J.; Yiu, S.M.; Hui, L.C. A survey on regular expression matching for deep packet inspection: Applications, algorithms, and hardware platforms. IEEE Commun. Surv. Tutor. 2016, 18, 2991–3029. [Google Scholar] [CrossRef]
- Antonello, R.; Fernandes, S.; Kamienski, C.; Sadok, D.; Kelner, J.; Godor, I.; Szabo, G.; Westholm, T. Deep packet inspection tools and techniques in commodity platforms: Challenges and trends. J. Netw. Comput. Appl. 2012, 35, 1863–1878. [Google Scholar] [CrossRef]
- Lee, C.L.; Lin, Y.S.; Chen, Y.C. A hybrid CPU/GPU pattern-matching algorithm for deep packet inspection. PLoS ONE 2015, 10, e0139301. [Google Scholar] [CrossRef]
- Hsieh, C.L.; Vespa, L.; Weng, N. A high-throughput DPI engine on GPU via algorithm/implementation co-optimization. J. Parallel Distrib. Comput. 2016, 88, 46–56. [Google Scholar] [CrossRef]
- Vespa, L.; Mathew, M.; Weng, N. P3fsm: Portable predictive pattern matching finite state machine. In Proceedings of the IEEE 20th International Conference on Application-Specific Systems, Architectures and Processors, Boston, MA, USA, 7–9 July 2009. [Google Scholar]
- Aho, A.V.; Corasick, M.J. Efficient string matching: An aid to bibliographic search. Commun. ACM 1975, 18, 333–340. [Google Scholar] [CrossRef]
- Wu, S.; Manber, U. A Fast Algorithm for Multi-Pattern Searching; University of Arizona, Department of Computer Science: Tucson, AZ, USA, 1994; pp. 1–11. [Google Scholar]
- Finsterbusch, M.; Richter, C.; Rocha, E.; Muller, J.A.; Hanssgen, K. A survey of payload-based traffic classification approaches. IEEE Commun. Surv. Tutor. 2013, 16, 1135–1156. [Google Scholar] [CrossRef]
- Karp, R.M.; Rabin, M.O. Efficient randomized pattern-matching algorithms. IBM J. Res. Dev. 1987, 31, 249–260. [Google Scholar] [CrossRef]
- Muth, R.; Manber, U. Approximate Multiple String Search. In Annual Symposium on Combinatorial Pattern Matching; Springer: Berlin/Heidelberg, Germany, 1996. [Google Scholar]
- Gupta, V.; Singh, M.; Bhalla, V.K. Pattern matching algorithms for intrusion detection and prevention system: A comparative analysis. In Proceedings of the IEEE International Conference on Advances in Computing, Communications and Informatics (ICACCI), Delhi, India, 24–27 September 2014. [Google Scholar]
- Shoaib, N.; Shamsi, J.; Mustafa, T.; Zaman, A.; ul Hasan, J.; Gohar, M. GDPI: Signature based deep packet inspection using GPUs. Int. J. Adv. Comput. Sci. Appl. 2017, 8, 081128. [Google Scholar] [CrossRef] [Green Version]
- Ramesh, M.; Jeon, H. Parallelizing deep packet inspection on GPU. In Proceedings of the IEEE Fourth International Conference on Big Data Computing Service and Applications (BigDataService), Bamberg, Germany, 26–29 March 2018. [Google Scholar]
- Bloom, B.H. Space/time trade-offs in hash coding with allowable errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Fan, L.; Cao, P.; Almeida, J.; Broder, A.Z. Summary cache: A scalable wide-area web cache sharing protocol. IEEE/ACM Trans. Netw. 2000, 8, 281–293. [Google Scholar] [CrossRef]
- Bonomi, F.; Mitzenmacher, M.; Panigrahy, R.; Singh, S.; Varghese, G. An improved construction for counting bloom filters. In European Symposium on Algorithms; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Putze, F.; Sanders, P.; Singler, J. Cache-, hash-and space-efficient bloom filters. In International Workshop on Experimental and Efficient Algorithms; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Knuth, D.E. The Art of Computer Programming: Sorting and Searching; Addison-Wesley: Boston, MA, USA, 1975; p. 723. [Google Scholar]
- Fan, B.; Andersen, D.G.; Kaminsky, M.; Mitzenmacher, M.D. Cuckoo filter: Practically better than bloom. In Proceedings of the 10th ACM International on Conference on Emerging Networking Experiments and Technologies, Sydney, NSW, Australia, 2–5 December 2014. [Google Scholar]
- Al-Hisnawi, M.; Ahmadi, M. Qcf for deep packet inspection. IET Netw. 2017, 7, 346–352. [Google Scholar] [CrossRef]
- Artan, N.S.; Chao, H.J. Multi-packet signature detection using prefix bloom filters. In Proceedings of the IEEE Global Telecommunications Conference, St. Louis, MO, USA, 28 November–2 December 2005. [Google Scholar]
- Kocak, T.; Kaya, I. Low-power bloom filter architecture for deep packet inspection. IEEE Commun. Lett. 2006, 10, 210–212. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Kumar, A.; Xu, J.J. A new design of Bloom filter for packet inspection speedup. In Proceedings of the IEEE Global Telecommunications Conference, Washington, DC, USA, 26–30 November 2007. [Google Scholar]
- Al-Hisnawi, M.; Ahmadi, M. Deep packet inspection using quotient filter. IEEE Commun. Lett. 2016, 20, 2217–2220. [Google Scholar] [CrossRef]
- Al-Hisnawi, M.; Ahmadi, M. Deep packet inspection using cuckoo filter. In Proceedings of the IEEE Annual Conference on New Trends in Information & Communications Technology Applications (NTICT), Baghdad, Iraq, 7–9 March 2017. [Google Scholar]
- Boyer, R.S.; Moore, J.S. A fast string searching algorithm. Commun. ACM 1977, 20, 762–772. [Google Scholar] [CrossRef]
- Padmashani, R.; Sathyadevan, S.; Dath, D. BSnort IPS better snort intrusion detection/prevention system. In Proceedings of the IEEE 12th International Conference on Intelligent Systems Design and Applications (ISDA), Kochi, India, 27–29 November 2012. [Google Scholar]
- Gupta, S. Efficient malicious domain detection using word segmentation and BM pattern matching. In Proceedings of the IEEE International Conference on Recent Advances and Innovations in Engineering (ICRAIE), Jaipur, India, 23–25 December 2016. [Google Scholar]
- Rahman, T.F.A.; Buja, A.G.; Abd, K.; Ali, F.M. SQL Injection Attack Scanner Using Boyer-Moore String Matching Algorithm. J. Comput. 2017, 12, 183–189. [Google Scholar] [CrossRef]
- Otoum, Y.; Nayak, A. As-ids: Anomaly and signature based ids for the internet of things. J. Netw. Syst. Manag. 2021, 29, 23. [Google Scholar] [CrossRef]
- Wang, Y.; Kobayashi, H. An improved technology for content matching intrusion detection system. In Proceedings of the IEEE International Conference on Software in Telecommunications and Computer Networks, Split, Croatia, 29 September–1 October 2006. [Google Scholar]
- Hasan, A.A.; Rashid, N.A.A. Hash-Boyer-Moore-Horspool string matching algorithm for intrusion detection system. In Proceedings of the IPCSIT International Conference on Computer Networks and Communication Systems, Kuala Lumpur, Malaysia, 7–8 April 2012. [Google Scholar]
- Sharma, S.; Dixit, M. Single Digit Hash Boyer Moore Horspool Pattern Matching Algorithm for Intrusion Detection System. Int. J. Future Gener. Commun. Netw. 2016, 9, 169–180. [Google Scholar] [CrossRef]
- Zheng, Q. An improved multiple patterns matching algorithm for intrusion detection. In Proceedings of the IEEE International Conference on Intelligent Computing and Intelligent Systems, Xiamen, China, 29–31 October 2010. [Google Scholar]
- Ke-Qin, C.D.; Lin, H.W. An improved multi-pattern matching algorithms in intrusion detection. In Proceedings of the IEEE Fifth International Conference on Measuring Technology and Mechatronics Automation, Hong Kong, China, 16–17 January 2013. [Google Scholar]
- Aldwairi, M.; Al-Khamaiseh, K.; Alharbi, F.; Shah, B. Bloom filters optimized Wu-Manber for intrusion detection. J. Digit. Forensics Secur. Law 2016, 11, 5. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Sun, Y.; Meng, F.; Fu, Y.; Jia, B.; Wu, Z. XWM: A high-speed matching algorithm for large-scale URL rules in wireless surveillance applications. Multimed. Tools Appl. 2020, 79, 16245–16263. [Google Scholar] [CrossRef] [Green Version]
- Karcıoğlu, A.A.; Bulut, H. Q-gram hash comparison based multiple exact string matching algorithm for DNA sequences. J. Fac. Eng. Archit. Gazi Univ. 2023, 38, 875–888. [Google Scholar]
- Zhang, B.; Chen, X.; Pan, X.; Wu, Z. High concurrence Wu-Manber multiple patterns matching algorithm. In International Symposium on Information Processing (ISIP 2009); Citeseer: Princeton, NJ, USA, 2009. [Google Scholar]
- Luchaup, D.; De Carli, L.; Jha, S.; Bach, E. Deep packet inspection with DFA-trees and parametrized language overapproximation. In Proceedings of the IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar]
- Ceška, M.; Havlena, V.; Holík, L.; Korenek, J.; Lengál, O.; Matoušek, D.; Matoušek, J.; Semric, J.; Vojnar, T. Deep packet inspection in FPGAs via approximate nondeterministic automata. In Proceedings of the IEEE 27th Annual International Symposium on Field-Programmable Custom Computing Machines (FCCM), San Diego, CA, USA, 28 April–1 May 2019. [Google Scholar]
- Češka, M.; Havlena, V.; Holík, L.; Lengál, O.; Vojnar, T. Approximate reduction of finite automata for high-speed network intrusion detection. Int. J. Softw. Tools Technol. Transf. 2020, 22, 523–539. [Google Scholar] [CrossRef]
- Roesch, M. Snort: Lightweight intrusion detection for networks. Lisa 1991, 99, 229–238. [Google Scholar]
- Sommer, R. Bro: An open source network intrusion detection system. In Security, E-Learning, E-Services, 17. DFN-Arbeitstagung Über; Kommunikationsnetze: Düsseldorf, German, 2003. [Google Scholar]
- Yin, C.; Wang, H.; Yin, X.; Sun, R.; Wang, J. Improved deep packet inspection in data stream detection. J. Supercomput. 2019, 75, 4295–4308. [Google Scholar] [CrossRef]
- Sun, R.; Shi, L.; Yin, C.; Wang, J. An improved method in deep packet inspection based on regular expression. J. Supercomput. 2019, 75, 3317–3333. [Google Scholar] [CrossRef]
- Nagaraju, S.; Shanmugham, B.; Baskaran, K. High throughput token driven FSM based regex pattern matching for network intrusion detection system. Mater. Today Proc. 2021, 47, 139–143. [Google Scholar] [CrossRef]
- Yu, X.; Feng, W.-C.; Yao, D.; Becchi, M. O 3 FA: A scalable finite automata-based pattern-matching engine for out-of-order deep packet inspection. In Proceedings of the ACM/IEEE Symposium on Architectures for Networking and Communications Systems (ANCS), Santa Clara, CA, USA, 17–18 March 2016. [Google Scholar]
- Norton, M. Optimizing Pattern Matching for İntrusion Detection; Sourcefire, Inc.: Columbia, MD, USA, 2004. [Google Scholar]
- Tuck, N.; Sherwood, T.; Calder, B.; Varghese, G. Deterministic memory-efficient string matching algorithms for intrusion detection. In Proceedings of the IEEE INFOCOM 2004, Hong Kong, China, 7–11 March 2004; pp. 2628–2639. [Google Scholar]
- Tan, L.; Sherwood, T. A high throughput string matching architecture for intrusion detection and prevention. In Proceedings of the IEEE 32nd International Symposium on Computer Architecture (ISCA 05), Madison, WI, USA, 4–8 June 2005. [Google Scholar]
- Pao, D.; Lin, W.; Liu, B. A memory-efficient pipelined implementation of the aho-corasick string-matching algorithm. ACM Trans. Archit. Code Optim. 2010, 7, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Lee, T.-H.; Huang, N.-L. A pattern-matching scheme with high throughput performance and low memory requirement. IEEE/ACM Trans. Netw. 2012, 21, 1104–1116. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.-C.; Wang, S.-D. An efficient multicharacter transition string-matching engine based on the aho-corasick algorithm. ACM Trans. Archit. Code Optim. 2013, 10, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Pao, D. Memory-based architecture for multicharacter Aho–Corasick string matching. IEEE Trans. Very Large Scale İntegr. VLSI Syst. 2017, 26, 143–154. [Google Scholar] [CrossRef]
- Trivedi, U. An Optimized Aho-Corasick Multi-Pattern Matching Algorithm for Fast Pattern Matching. In Proceedings of the IEEE 17th India Council International Conference (INDICON), New Delhi, India, 10–13 December 2020. [Google Scholar]
- Regéciová, D.; Kolář, D.; Milkovič, M. Pattern Matching in YARA: Improved Aho-Corasick Algorithm. IEEE Access 2021, 9, 62857–62866. [Google Scholar] [CrossRef]
- LIANG, S.L.; Chang, Y.K.; Ke, C.F. Accelerating Aho-Corasick Algorithm Using Odd-Even Sub Patterns to Improve Snort Intrusion Detection System. SSRN 4072552. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4072554 (accessed on 6 July 2023).
- Kim, H. A scalable architecture for reducing power consumption in pipelined deep packet inspection system. Microelectron. J. 2015, 46, 950–955. [Google Scholar] [CrossRef]
- Choi, B.; Chae, J.; Jamshed, M.; Park, K.; Han, D. DFC: Accelerating string pattern matching for network applications. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 16–18 March 2016. [Google Scholar]
- Duan, H.; Yuan, X.; Wang, C. Lightbox: Sgx-assisted secure network functions at near-native speed. arXiv 2017, arXiv:1706.06261. [Google Scholar]
- Han, J.; Kim, S.; Cho, D.; Choi, B.; Ha, J.; Han, D. A secure middlebox framework for enabling visibility over multiple encryption protocols. IEEE/ACM Trans. Netw. 2020, 28, 2727–2740. [Google Scholar] [CrossRef]
- Smith, R.; Goyal, N.; Ormont, J.; Sankaralingam, K.; Estan, C. Evaluating GPUs for network packet signature matching. In Proceedings of the IEEE International Symposium on Performance Analysis of Systems and Software, Boston, MA, USA, 26–28 April 2009. [Google Scholar]
- Costa, L.B.; Al-Kiswany, S.; Ripeanu, M. GPU support for batch oriented workloads. In Proceedings of the IEEE 28th İnternational Performance Computing and Communications Conference, Phoenix, AZ, USA, 14–16 December 2009. [Google Scholar]
- Wang, L.; Chen, S.; Tang, Y.; Su, J. Gregex: Gpu based high speed regular expression matching engine. In Proceedings of the IEEE Fifth International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing, Seoul, Republic of Korea, 30 June–2 July 2011. [Google Scholar]
- Zha, X.; Sahni, S. Multipattern string matching on a GPU. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Corfu, Greece, 28 June–1 July 2011. [Google Scholar]
- Lin, C.H.; Liu, C.H.; Chien, L.S.; Chang, S.-C. Accelerating pattern matching using a novel parallel algorithm on GPUs. IEEE Trans. Comput. 2012, 62, 1906–1916. [Google Scholar] [CrossRef]
- Lin, Y.S.; Lee, C.L.; Chen, Y.C. Length-bounded hybrid CPU/GPU pattern matching algorithm for deep packet inspection. In Proceedings of the Fifth International Conference on Network, Communication and Computing, Kyoto, Japan, 17–21 December 2016. [Google Scholar]
- Ho, T.; Cho, S.J.; Oh, S.R. Parallel multiple pattern matching schemes based on cuckoo filter for deep packet inspection on graphics processing units. IET Inf. Secur. 2018, 12, 381–388. [Google Scholar] [CrossRef]
- Douligeris, C.; Serpanos, D.N. Network Security: Current Status and Future Directions; Wiley-IEEE Press: Hoboken, NJ, USA, 2007. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Character | Group | Char Signature | State Signature |
|---|---|---|---|---|
| C1 | H | G1 | 00 | 01 |
| C1 | H | G5 | 00 | 10 |
| C1 | S | G2 | 01 | 01 |
| C1 | S | G7 | 01 | 10 |
| C1 | S | G9 | 01 | 11 |
| C1 | E | G3 | 10 | 01 |
| C1 | E | G8 | 10 | 10 |
| C1 | R | G6 | 11 | 01 |
| C2 | I | G4 | 0 | 1 |
| State | Group | Code |
|---|---|---|
| S1 | G3, G4 | 100101 |
| S2 | G5 | 001000 |
| S3 | G6 | 110100 |
| S4 | G7 | 011000 |
| S5 | G8, G4 | 101001 |
| S6 | G9 | 011100 |
| S7 | G5 | 001000 |
| S8 | G6 | 110100 |
| S9 | G5 | 001000 |
| Character | Signature | Cluster | Offset | Index |
|---|---|---|---|---|
| H | 00 | 1 | 0 | 1 |
| S | 01 | 1 | 2 | 3 |
| E | 10 | 1 | 5 | 0 |
| R | 11 | 1 | 7 | 0 |
| I | 0 | 2 | 8 | 0 |
| Index | State Code | State |
|---|---|---|
| 1 | 100101 | S1 |
| 2 | 101001 | S5 |
| 3 | 001000 | S2 |
| 4 | 001000 | S7 |
| 5 | 001000 | S9 |
| 6 | 110100 | S3 |
| 7 | 110100 | S8 |
| 8 | 011100 | S6 |
| 9 | 011000 | S4 |
| Processor | Intel Xeon E5-2640 v4 |
| Memory | 32 GB DDR4-2666 4Rx4 ECC RDIMM |
| GPU | RTX 2080 TI 11 G 352 Bit |
| Pattern Count | Average Pattern Length |
|---|---|
| 100 | 30.42 |
| 200 | 29.44 |
| 300 | 29.91 |
| 400 | 29.98 |
| 500 | 30.70 |
| Pattern Count | AC (KB) |
|---|---|
| 100 | 2625.512 |
| 200 | 5181.12 |
| 300 | 7785.044 |
| 400 | 10,515.412 |
| 500 | 13,271.48 |
| Pattern Count | WM (KB) |
|---|---|
| 100 | 4331.49 |
| 200 | 8619.935 |
| 300 | 12,908.622 |
| 400 | 17,197.241 |
| 500 | 21,486.196 |
| Pattern Count | PA (KB) |
|---|---|
| 100 | 8.161 |
| 200 | 14.097 |
| 300 | 19.615 |
| 400 | 25.281 |
| 500 | 31.218 |
| Pattern Count | AC | PA |
|---|---|---|
| 100 | 2554 | 121 |
| 200 | 5040 | 264 |
| 300 | 7573 | 395 |
| 400 | 10,229 | 527 |
| 500 | 12,910 | 667 |
| Pattern Count | AC (KB) | WM (KB) | PA (KB) |
|---|---|---|---|
| 100 | 2625.512 | 4331.49 | 8.161 |
| 200 | 5181.12 | 8619.935 | 14.097 |
| 300 | 7785.044 | 12,908.622 | 19.615 |
| 400 | 10,515.412 | 17,197.241 | 25.281 |
| 500 | 13,271.48 | 21,486.196 | 31.218 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Çelebi, M.; Yavanoğlu, U. Accelerating Pattern Matching Using a Novel Multi-Pattern-Matching Algorithm on GPU. Appl. Sci. 2023, 13, 8104. https://doi.org/10.3390/app13148104
Çelebi M, Yavanoğlu U. Accelerating Pattern Matching Using a Novel Multi-Pattern-Matching Algorithm on GPU. Applied Sciences. 2023; 13(14):8104. https://doi.org/10.3390/app13148104
Chicago/Turabian StyleÇelebi, Merve, and Uraz Yavanoğlu. 2023. "Accelerating Pattern Matching Using a Novel Multi-Pattern-Matching Algorithm on GPU" Applied Sciences 13, no. 14: 8104. https://doi.org/10.3390/app13148104