1. Introduction
Over the past several years, wide applications of 4G mobile wireless networks have brought us tremendous convenience. For example, through the 4G mobile wireless networks, we can enjoy a large number of online services, including mobile shopping/payment, mobile office, mobile gaming, etc. [
1]. Nowadays, with the wide popularity of various innovative applications, such as Vehicle-to-Everything (V2X), AR, holographic communications, etc. [
2], mobile wireless networks make our daily life more convenient. However, mobile wireless networks also present us with a great challenge while providing tremendous convenience for us. For instance, as a large amount of data including sensitive information is published or shared in mobile wireless networks without privacy preservation, a lot of individual privacy is leaked, which results in many social security problems [
3]. In particular, [
4] points out that data leakage is one of the most frequent mobile security threats. Therefore, it is crucial to pay close attention to individual privacy in mobile wireless networks.
More importantly, there is a large amount of personal privacy information, including identity privacy, semantic attribute privacy, and link privacy, in the graph structure data in mobile wireless networks [
5]. To address the privacy issue in the graph structure data, many graph modification methods have been proposed, which are divided into three categories: edge/node modification, clustering, and uncertain graph [
6]. In the edge/node modification method, the edge randomization method randomly adds or deletes edges in the original graph while retaining the characteristics of an original graph as much as possible [
7]. To overcome the shortcoming of this method, many k-anonymity methods that can resist attacks based on the structure of the graph have been devised, such as (k,l)-anonymity [
8], k2-anonymity [
9] and k-neighborhood sub-graph anonymity [
10]. Clustering-based methods, called generalization methods, usually group nodes and edges into super-nodes and super-edges, which hide the detail of nodes and edges in the graph [
11]. Furthermore, the method combining k-anonymity with node clustering is designed, which can provide sufficient privacy preservation while retaining data utility [
12]. Compared with the two methods mentioned above, the uncertain graph method, which rejects the uncertainty on the edges of a graph to generate an uncertain graph, can get better data utility than them. Although graph modification can preserve the graph structure data, it is not able to resist attacks based on background knowledge.
As a gold-standard notion of privacy that can provide a strict privacy guarantee [
13], differential privacy has been adopted to preserve graph structure data [
14]. For instance, differential privacy has been extensively applied to preserve various statistical values of the graph, such as the degree distribution [
15], frequent graphics patterns [
16], and triangle count [
17]. In addition, it can also be used to generate a synthetic graph to preserve the original graph. In [
18], a synthetic graph is released by using a differential private estimator of the parameters of a special model, which is an exponential family model with the degree sequence as a sufficient statistic. To improve the data utility of a differential private synthetic graph [
19], devises a differential private graph generator based on the dK-graph model. Different from graph modification, differential privacy usually employs noise to achieve privacy preservation, which results in insufficient data utility.
However, the methods introduced above mainly concentrate on undirected graphs. As a special graph, directed graphs, such as the who-follows-whom social graph on Twitter, not only possess the relations in graphs but also have the direction information. Therefore, it is hard to adopt these methods to preserve directed graphs when it is published or shared. By considering the direction information of edges, a few k-anonymity methods have been designed in [
20,
21]. But the k-anonymity method is not able to resist attacks based on background knowledge and only withstand some special attacks, these methods cannot provide sufficient privacy preservation for directed graphs. As a result, it is a great challenge to preserve directed graphs.
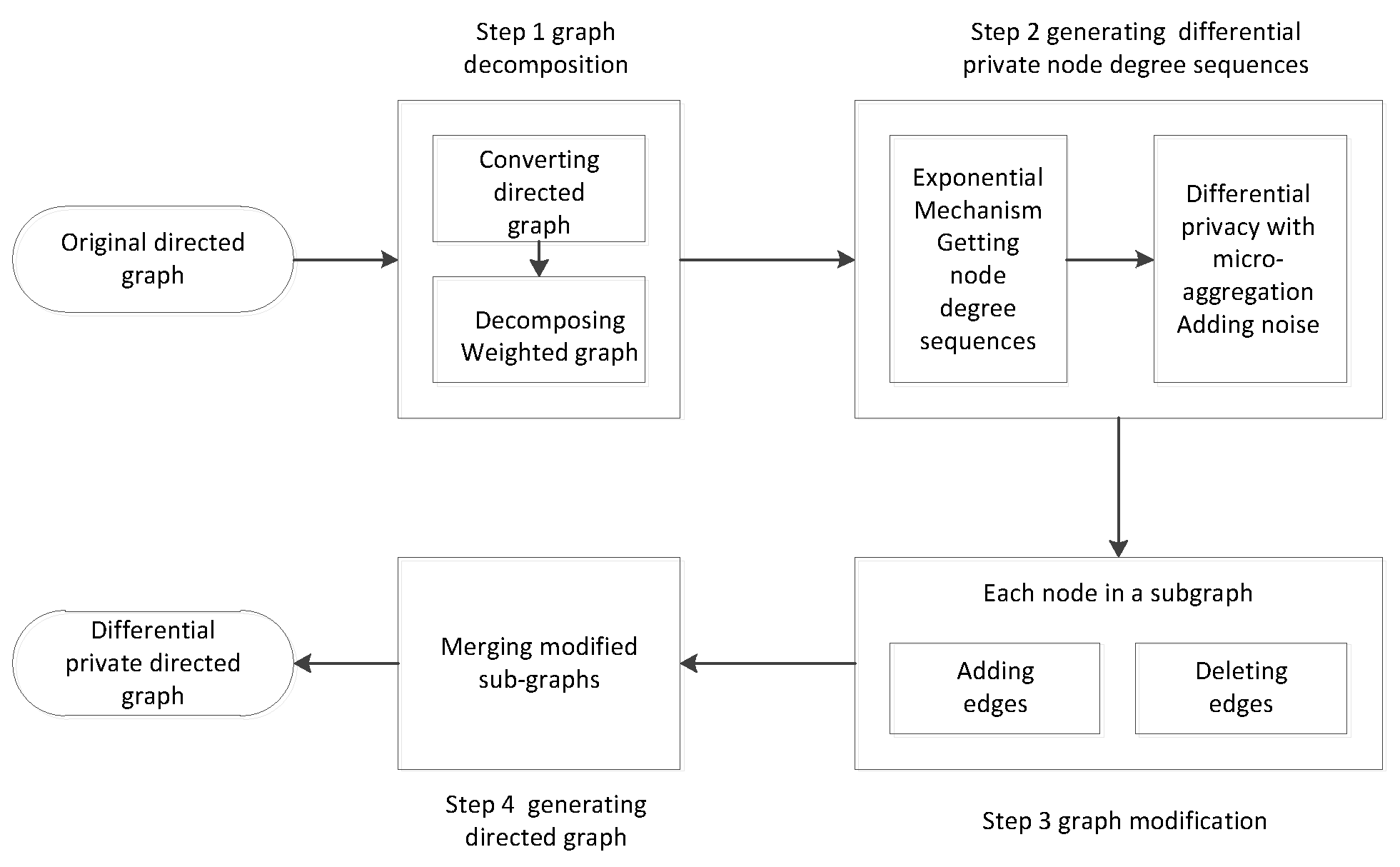
To solve this problem, we propose a useful method that combines differential privacy with graph modification to preserve directed graphs. In particular, compared with edge differential privacy, node differential privacy can provide stronger privacy preservation. Thus, node differential privacy is used to add noise on degree sequences, and edge modification utilizes noised degree sequences to generate a synthetic directed graph, which provides strong privacy preservation for the original directed graph. Additionally, to improve data utility, the original directed graph is divided into many sub-graphs, and the perturbations are only added in each sub-graph, which is useful to maintain the whole graph structure. In particular, the exponent mechanism is adopted to truncate degree sequences, which can ensure that the minimum noise is added to the degree sequences. Moreover, the ranking micro-aggregation effectively reduces the noise added to the degree sequences. According to the noised degree sequences, the relationship between two nodes is utilized to modify the edges of nodes, which can retain the original graph structure. Therefore, the designed method not only provides strong privacy preservation but also maintains the data utility.
In this paper, our contributions can be summarized as follows:
We propose a method based on node differential privacy to preserve directed graphs in wireless mobile networks. Particularly, node differential privacy and edge modification are combined to generate a synthetic directed graph that provides strong privacy preservation for the original directed graph.
We present four algorithms to maintain data utility in the proposed method. First of all, the Louvain algorithm is used to divide the original directed graph into several sub-graphs. Then, the node degree sequences in each sub-graph are generated by the GSEM (generating degree sequence based on exponent mechanism) algorithm and ADPRA (adding noise based on differential privacy with the ranking micro-aggregation) algorithm adds less noise on these node degree sequences. In the end, GGM (generating synthetic graphs based on graph modification) algorithm generates a synthetic directed sub-graph that maintains the properties of an original sub-graph.
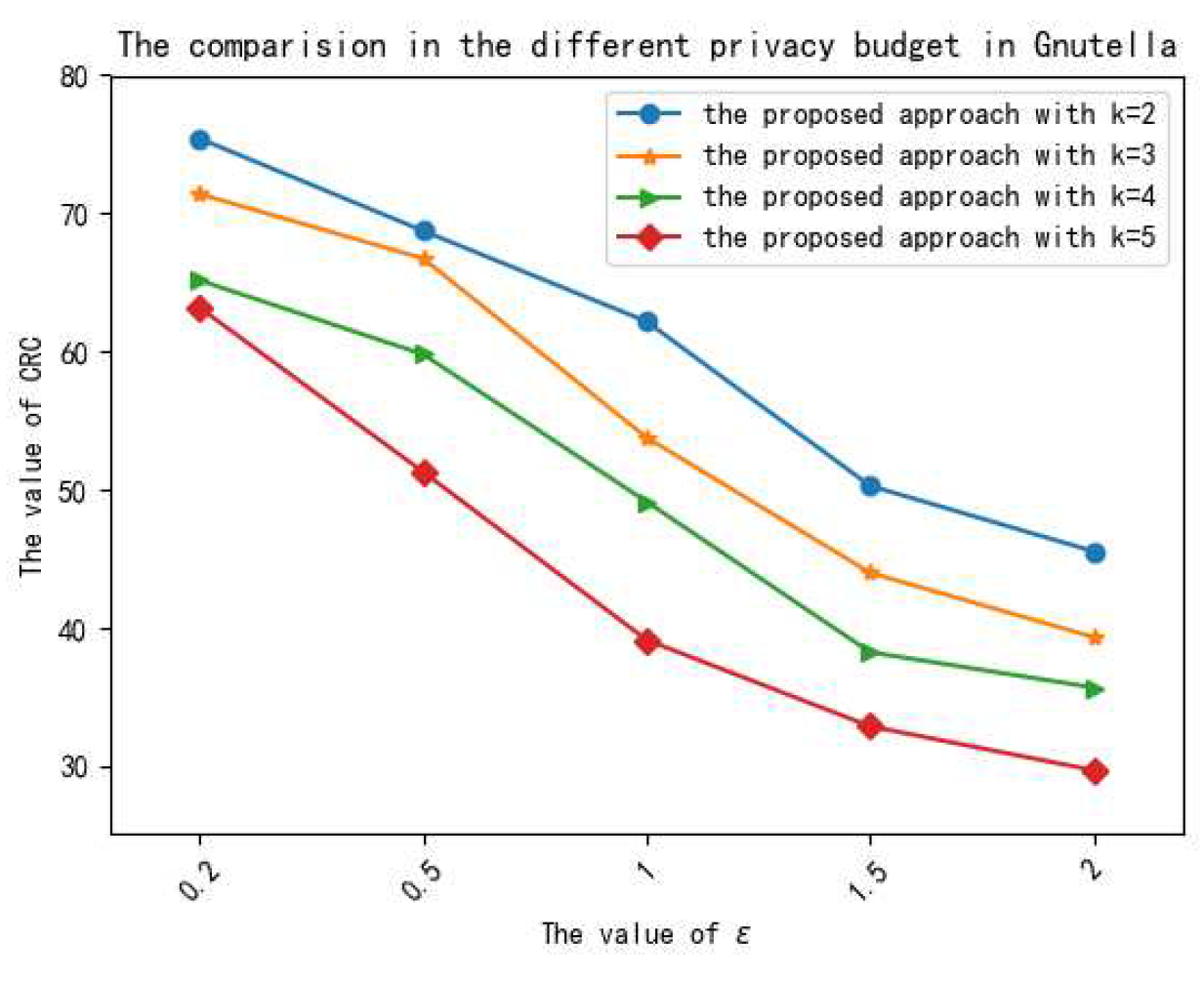
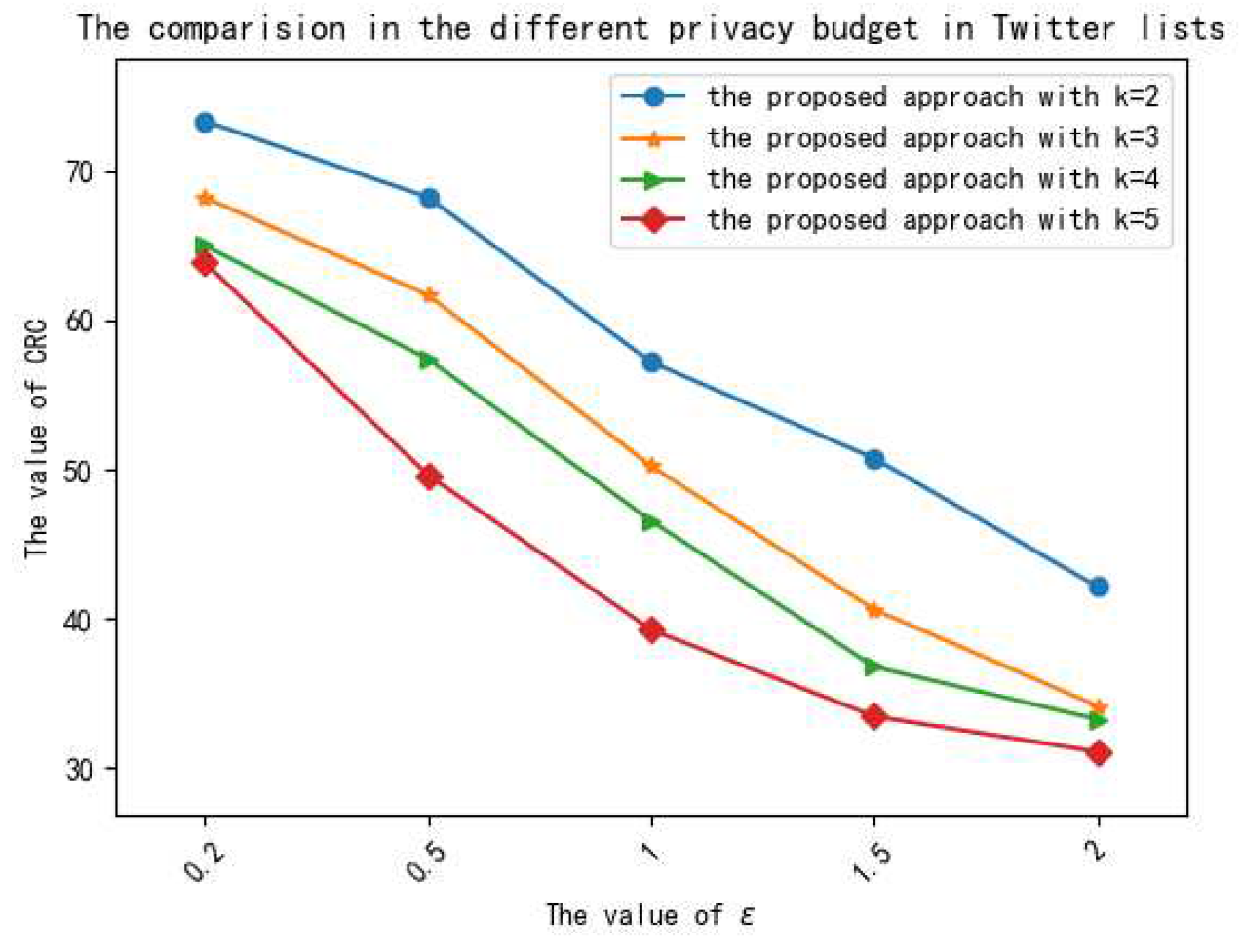
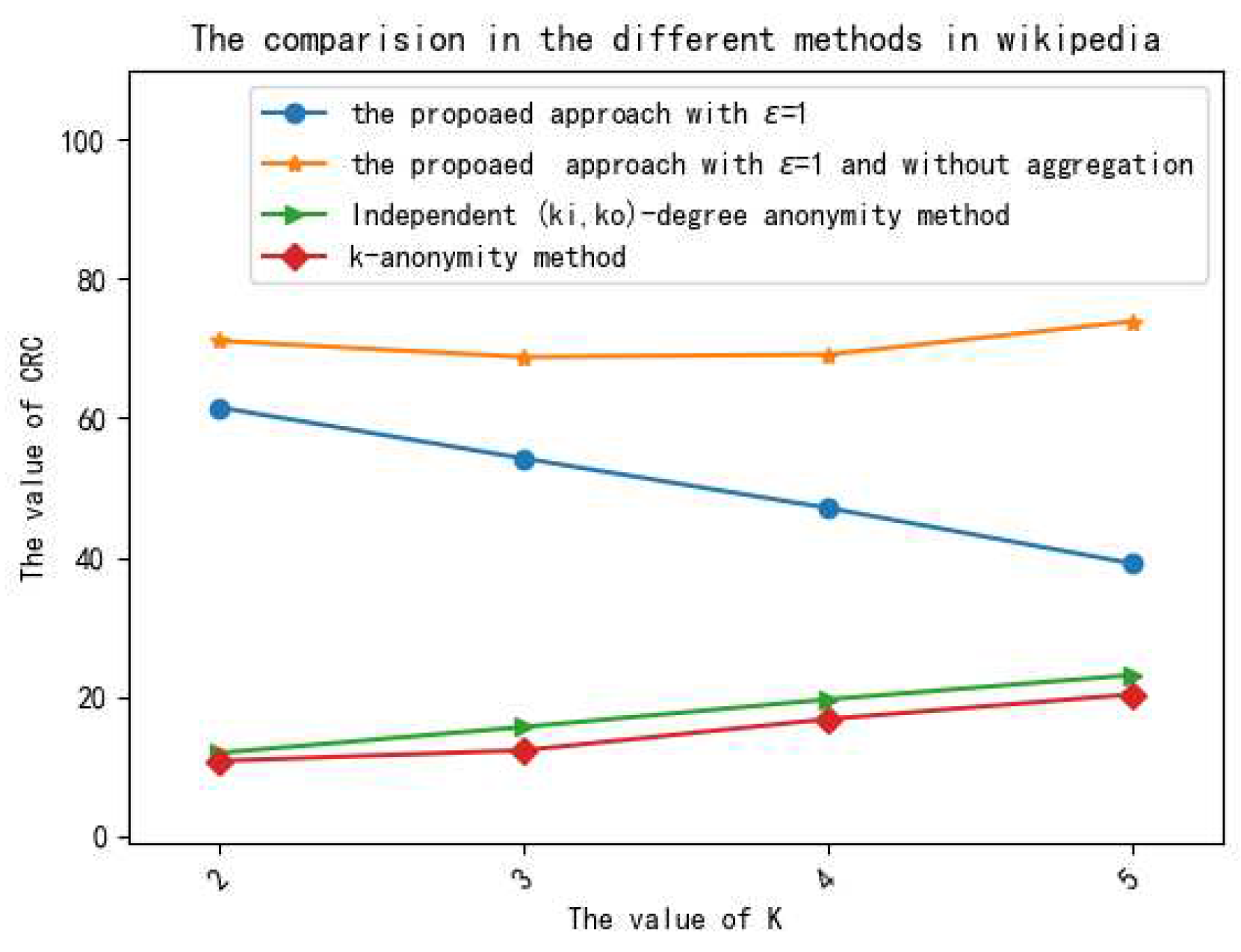
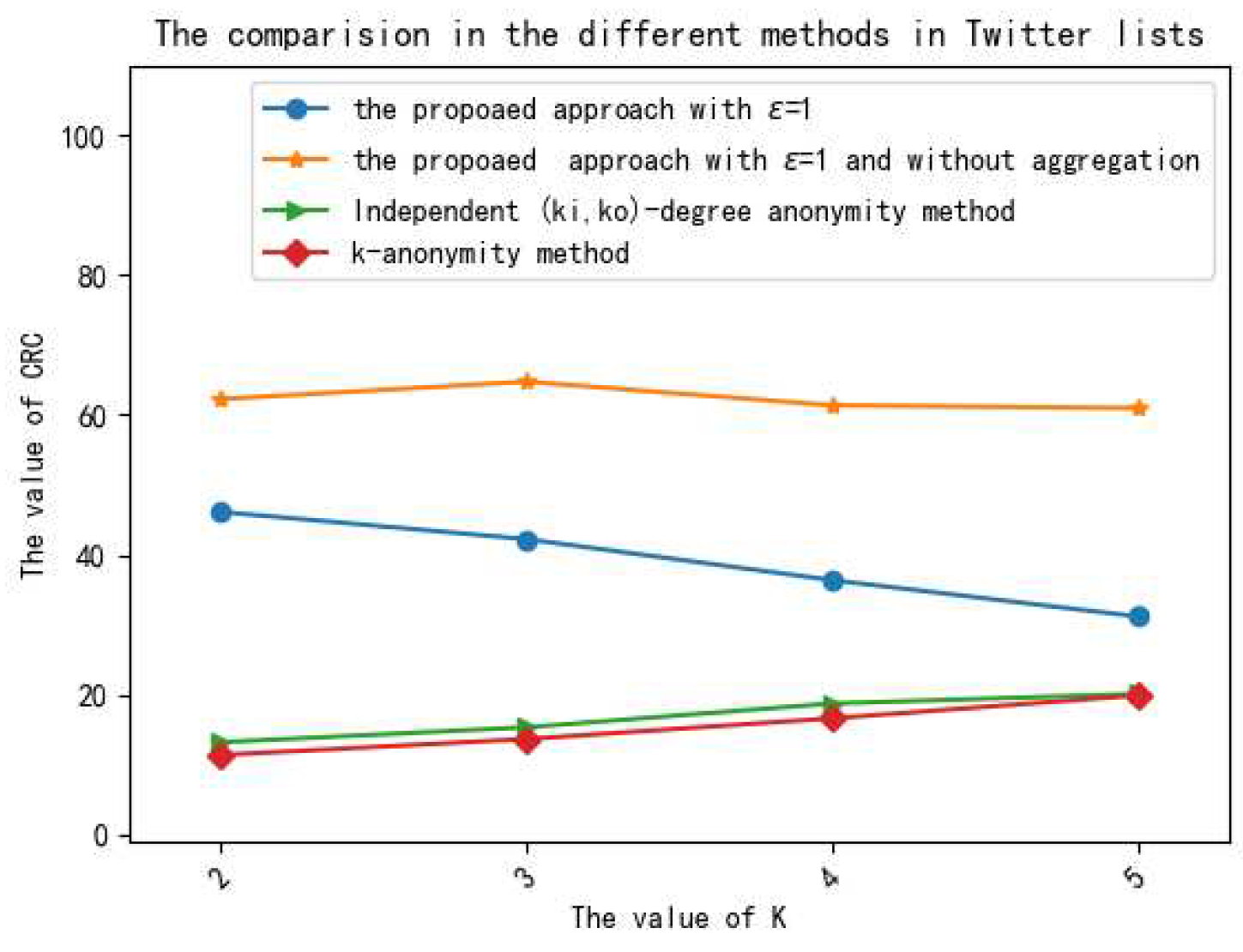
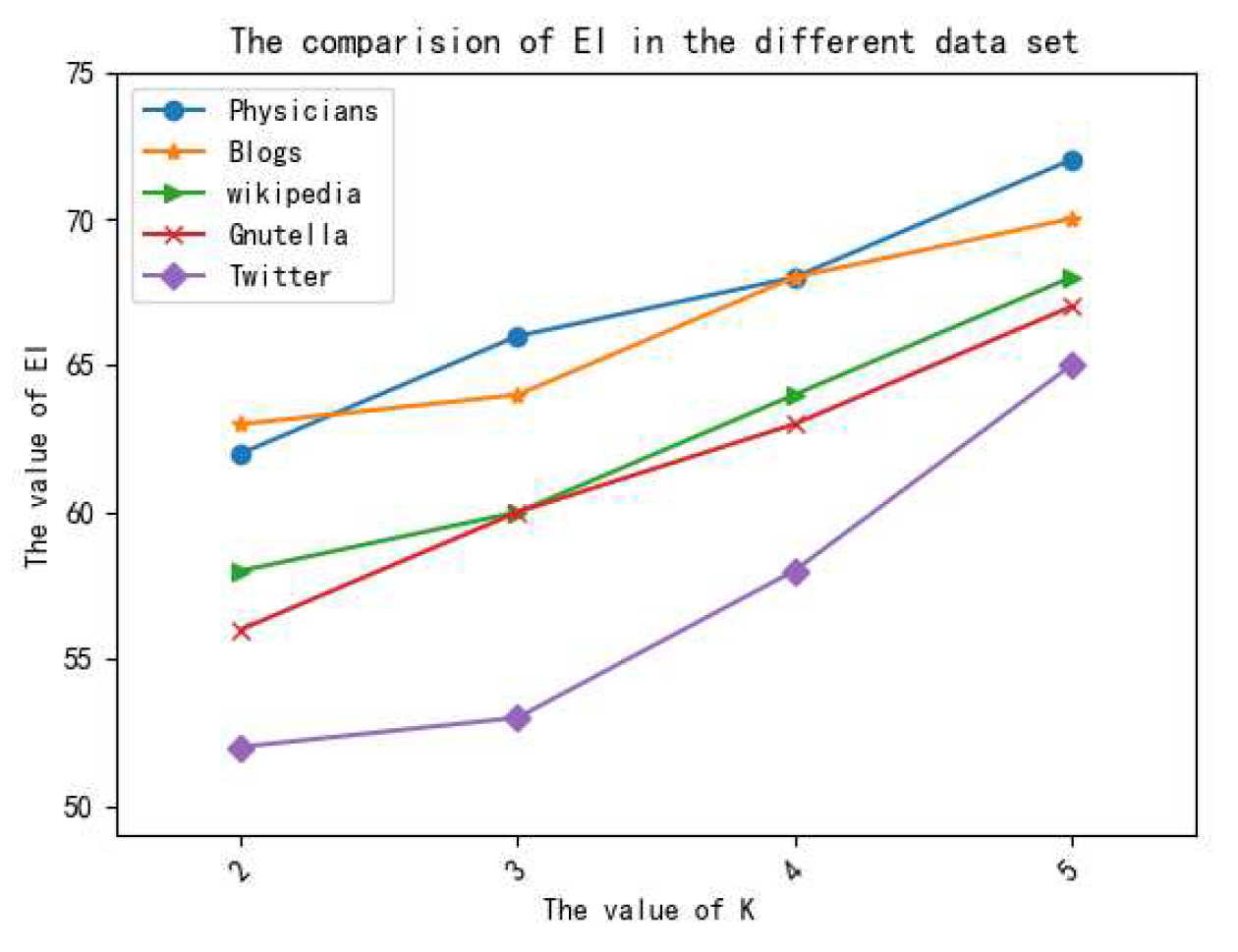
We demonstrate the performances of the proposed method on several different real data sets, and the experimental results show that the proposed method is effective in privacy preservation and data utility.
The rest of this paper is organized as follows.
Section 2 reviews the related methods to preserve the graph structure data. In
Section 3, the preliminaries are introduced. Then, the proposed method is described in detail in
Section 4.
Section 5 demonstrates the performance of the proposed method in privacy preservation and data utility. In
Section 6, the existing challenges and promising future directions are discussed.
2. Related Works
With individual privacy on MWNs attracting more and more attention, various techniques have been proposed to provide privacy preservation. In this section, we will focus on methods that include two categories: graph modification and differential privacy.
In graph modification, there are three important graph modification methods: edge and node modification methods, generalization or clustering methods, and uncertain graph methods. In edge and node modification methods, to improve data utility, Ying X. [
7] proposed two algorithms to preserve the original graph while keeping the spectral properties of the graph unchanged as much as possible. In [
22], Casas-Roma designed a method to protect the most important edges, which obtained a better trade-off between privacy preservation and data utility. In generalization methods that focus on how to generate so-called super-nodes and super-edges, Yu F. [
23] developed a clustering perturbation algorithm that adopted some perturbations to maintain the whole structure of the social net work and reduce privacy leakages. In uncertain graph methods, Boldi in [
24] designed a (k, )-obfuscation method based on injecting uncertainty to get an uncertain graph, which was similar to the original graph. To prevent link attacks based on background knowledge, Hu J developed an uncertain graph method based on edge-differential privacy, which also had better data utility in [
25].
In addition, k-anonymity [
5] had been widely used to generate anonymous graphs to preserve graph data. Considering the number of mutual friends (NMF) between two users, [
26] developed a k-anonymity method that made use of the mutual friend sequence to ensure the existence of at least k elements holding the same value for better data utility. In [
27], the new (k, l)-degree anonymity algorithm was devised to modify the original networks based on a sequence of edge editing operations. In this algorithm, a location entropy metric was considered to select the important edges so it could achieve minimum edge modification to increase data utility. Meanwhile, to resist insider attacks in collaborative social networks, [
28] developed a k-anonymity method based on the clustering, in which a scalable non-deterministic clustering was utilized to prevent the structure attacks.
In differential privacy methods, many methods based on differential privacy have been presented for graph data since C. Dwork came up with differential privacy, which was classified into two kinds: preserving specific sensitive statistics of graphs and generating differential private graphs. For publishing higher order network statistics, i.e., joint degree distribution, Iftikhar [
29] designed a general framework for releasing dK-distributions under node differential privacy, in which sensitivity was regulated by a graph projection algorithm, which transformed graphs into bounded graphs. To accurately estimate sub-graph counts, [
30] proposed a novel multi-phase framework under DDP (decentralized differential privacy), which was able to control the minimum local noise scale to preserve the sub-graph counts. Furthermore, some statistical data in graph data, such as triangle counts, centrality and shortest paths were preserved by differential privacy before they were released [
31,
32]. Apart from preserving the statistical data, differential privacy is also applied to generate a synthetic graph. In [
33], Vishesh Karwa developed an algorithm to attain a graphical degree partition of a graph preserved by differential privacy, which could also be used to construct synthetic graphs. Ref. [
34] proposed an LDPGen, which could generate a synthetic graph after structurally similar users were clustered together according to optimal parameters.
3. Preliminaries Knowledge
In this paper, a directed network is regarded as a simple, directed graph G = (V, E), where V = (, , ..., ) is the set of nodes, and E is the links table, each link (i, j) denotes a relationship from to .
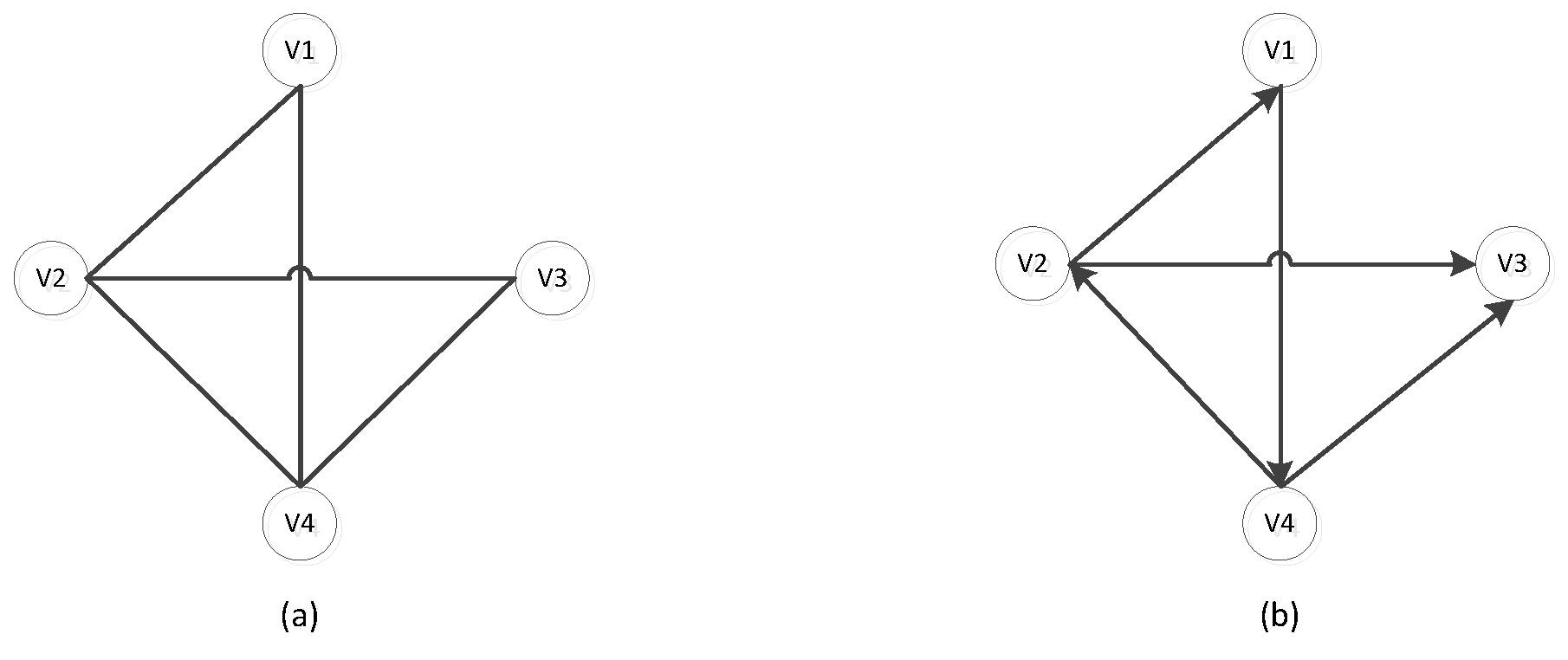
Definition 1 (The undirected graph and the directed graph).
As shown in Figure 1, the Figure 1a is an undirected graph, while the Figure 1b represents a directed graph, where each edge denotes a relationship from one node to another node. In the Figure 1b, the edge (,) denotes a link relation from node to node .
Definition 2 (Neighboring directed graph). For two directed graphs = (,), = (,), if |⊕|+|⊕| = 1, where ⊕ is Exclusive—OR operation, we can say and are neighbors.
Definition 3 (Differential Privacy).
For all outputs S belong to Range(Z), if we can obtain the result as follows:where Ga and Gb are neighbors, ϵ is a privacy preservation level, we can see that the algorithm Z satisfies ϵ-differential privacy.In order to achieve ϵ-differential privacy, we must perturb the outputs of queries in two ways, which include the Laplace mechanism and the exponential mechanism.
Definition 4 (Laplace Mechanism).
For a sequence of queries F: G→G, if the following holds:where μ = 0, b = Δ
f/ε and Lap(Δ
f/ε) represents the Laplace noise, the way that makes an algorithm Z satisfies ε-differential privacy by adding Laplace noise is the Laplace mechanism.In the Laplace mechanism, the Laplace noise distribution is shown in Equation (4).where μ is a position parameter, b denotes a scale parameter, and x is a random variable. Definition 5 (Exponential Mechanism). Given a dataset D, an output range T, a privacy budget ϵ, and a utility function U: (D, t) →R, a mechanism M that selects an output t∈T with probability proportional to exp() satisfies ϵ-differential privacy.
Definition 6 (Parallel composition properties). Given a sequence of algorithms {, , ..., }, and each algorithm satisfies differential privacy, if these algorithms are applied independently on a disjoint subset of the input database D, this data process is called the parallel composition properties of differential privacy, which satisfies max differential privacy.
6. Conclusions
In this paper, to preserve directed graphs in MWNs, the DGNDP method is designed, which combines node differential privacy and graph modification. In this method, as node differential privacy can provide stronger privacy preservation than edge differential privacy and graph modification, it is used to add noise on degree sequences. Then, edge modification utilizes noised degree sequences to generate a synthetic directed graph, which can strongly preserve the original directed graph. Additionally, to improve data utility, the original directed graph is divided into many sub-graphs, and the perturbations are only added in each sub-graph. In particular, the exponent mechanism is adopted to truncate degree sequences, which can ensure that the minimum noise is added to the degree sequences. Moreover, the ranking micro-aggregation effectively reduces the noise added to the degree sequences. According to the noised degree sequences, the relationship between two nodes is utilized to modify the edges of nodes, which can retain the original graph structure. Moreover, the theoretical analysis and the performance of experiments show that the DGNDP method not only satisfies -differential privacy but also retains data utility.
In this paper, we only focus on the simple static directed graph without considering node attributes. However, node attributes play an important role in the directed graphs. Thus, in the future, we will concentrate on the application of node differential privacy in complex attribute graphs. In addition, there is still a demand to achieve privacy preservation for dynamic directed graphs.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}