

Risk Propagation Mechanism and Prediction Model for the Highway Merging Area

Abstract
:1. Introduction
1.1. Mechanism of Traffic Accident Risk Propagation
1.2. Study on Traffic Accident Risk Prediction
1.3. Summary
2. Concept of Accident Risk Propagation
2.1. Risk Indicators
2.2. Accident Severity Assessment
2.3. Regional Risk Index
3. Highway Merging Area Accident Impact Range Model
3.1. Gaussian Plume Model
3.2. Parameter Adjustment
- (1)
- Adjustment of the source strength parameter
- (2)
- Adjustment of the average wind speed parameter
- (3)
- Adjustment of the diffusion coefficient parameters
4. Analysis of the Accident Risk Propagation Mechanism in the Highway Merging Area
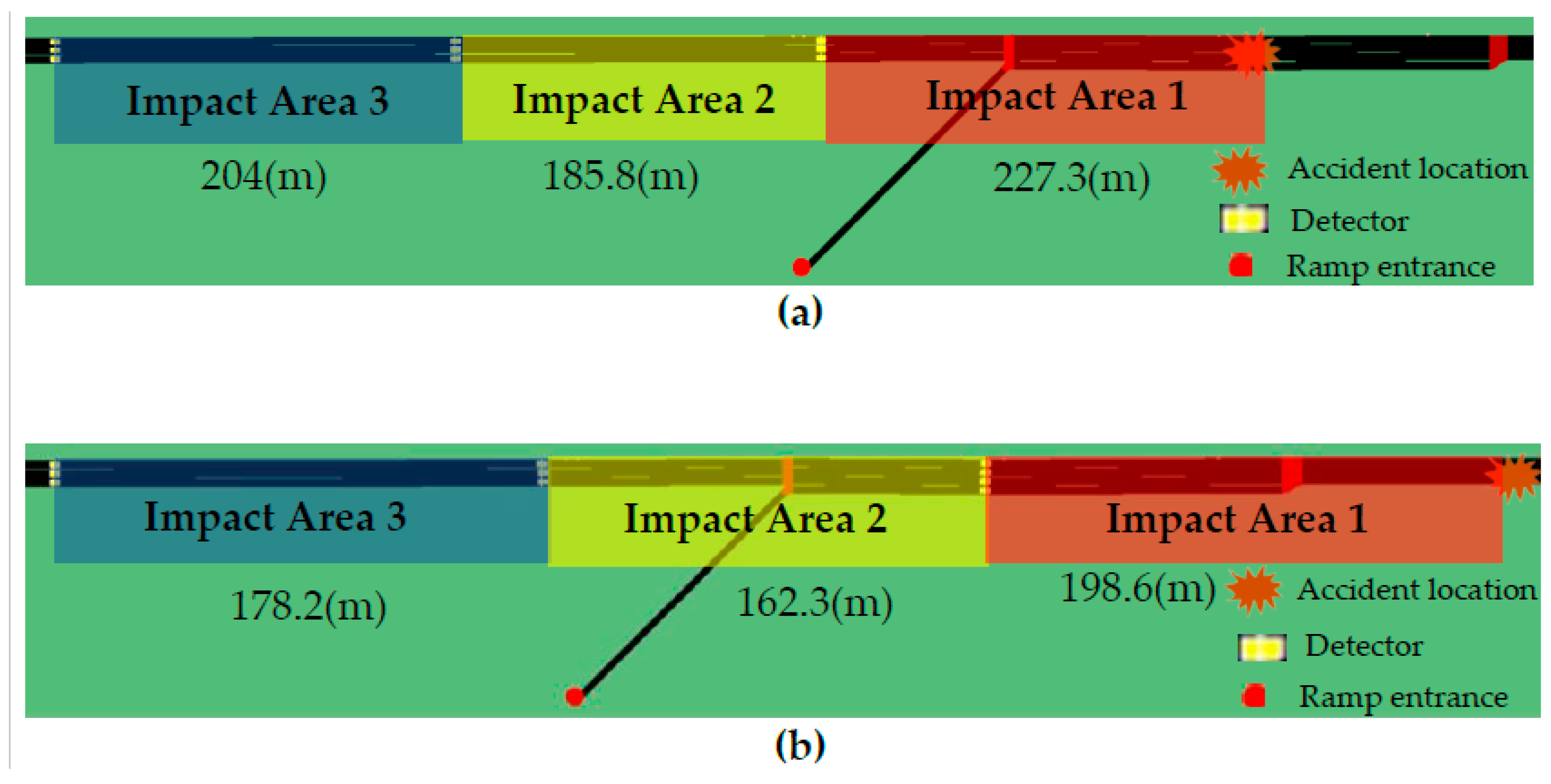
4.1. Simulation Scenario


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Scenario | Accident Location | Accident Type | Lane 1 | Lane 2 | Lane 3 | Lane 4 |
|---|---|---|---|---|---|---|
| 1 | Merging area | Side collision | √ | √ | ||
| 2 | √ | √ | ||||
| 3 | √ | √ | ||||
| 4 | Downstream | Rear-end collision | √ | |||
| 5 | √ |
4.2. Data Collection
4.3. Experimental Results
4.3.1. The Risk Propagation of Side Collision Accidents in the Merging Area
4.3.2. The Risk Propagation of Rear-End Accidents in the Downstream Area
5. Traffic Accident Risk Prediction Model
5.1. Model
5.1.1. LSTM
- (1)
- The input gate controls the input of new information by multiplying the input vector with the weight matrix through sigmoid function to produce a numerical vector between 0 and 1.
- (2)
- The forget gate controls the forgetting of old information by multiplying the input vector with the weight matrix through sigmoid function to produce a numerical vector between 0 and 1. This vector will be element-wise multiplied with the cell state vector to determine which old information should be forgotten.
- (3)
- The cell state is updated by element-wise multiplying the vector generated by the forget gate with the cell state from the previous time step to obtain the old information that needs to be retained and multiplying the vector generated by the input gate with the new information processed by a function element-wise to obtain the new information that needs to be added. These two vectors are added together to obtain the updated cell state.
- (4)
- The output gate controls the output of the cell state by multiplying the input vector with the weight matrix through sigmoid function to produce a numerical vector between 0 and 1. This vector is then element-wise multiplied with the cell state vector processed by a function to obtain the final output vector.
5.1.2. RNN
5.2. Dataset
5.3. Model Parameters
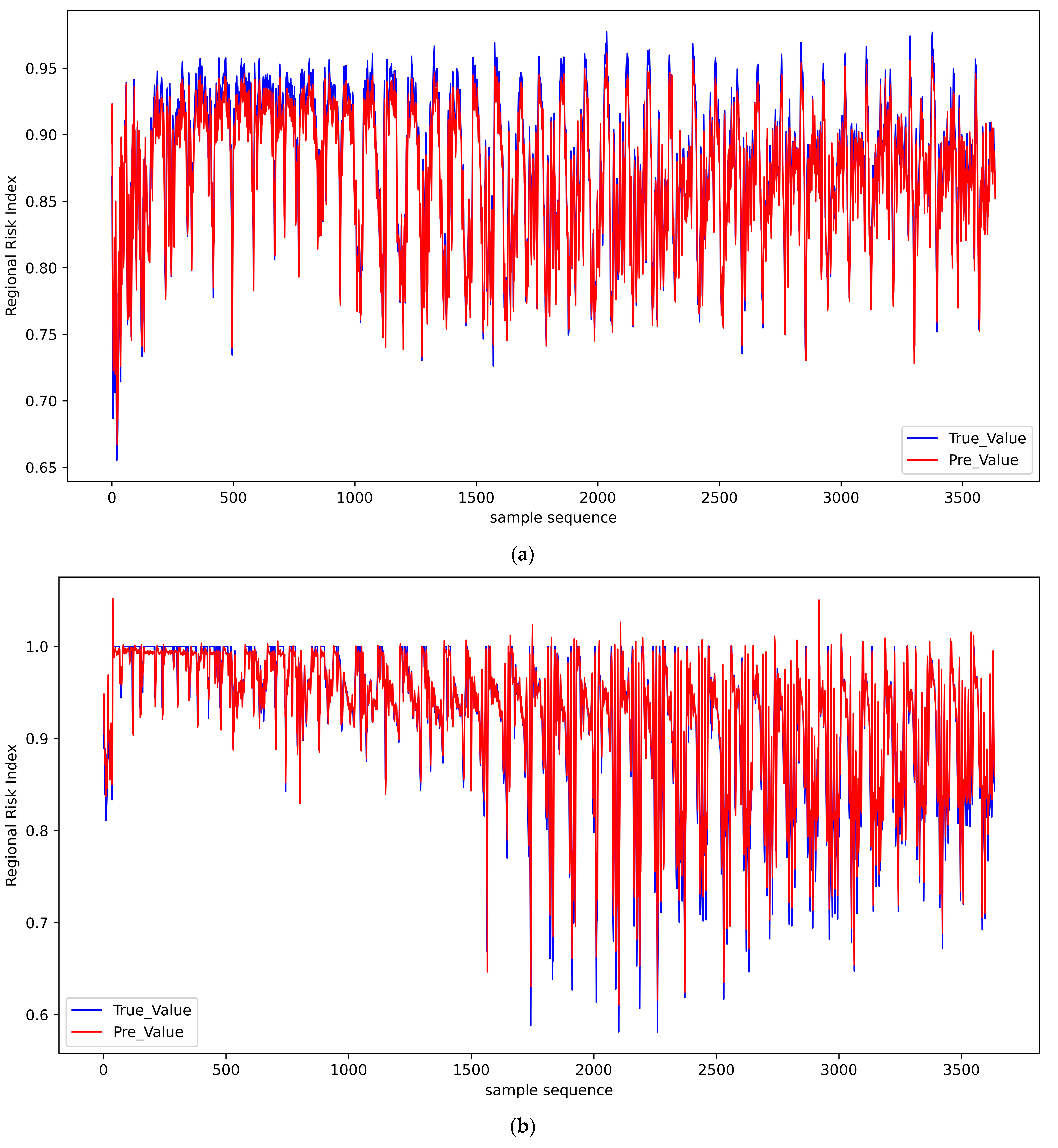
5.4. Model Results
6. Conclusions
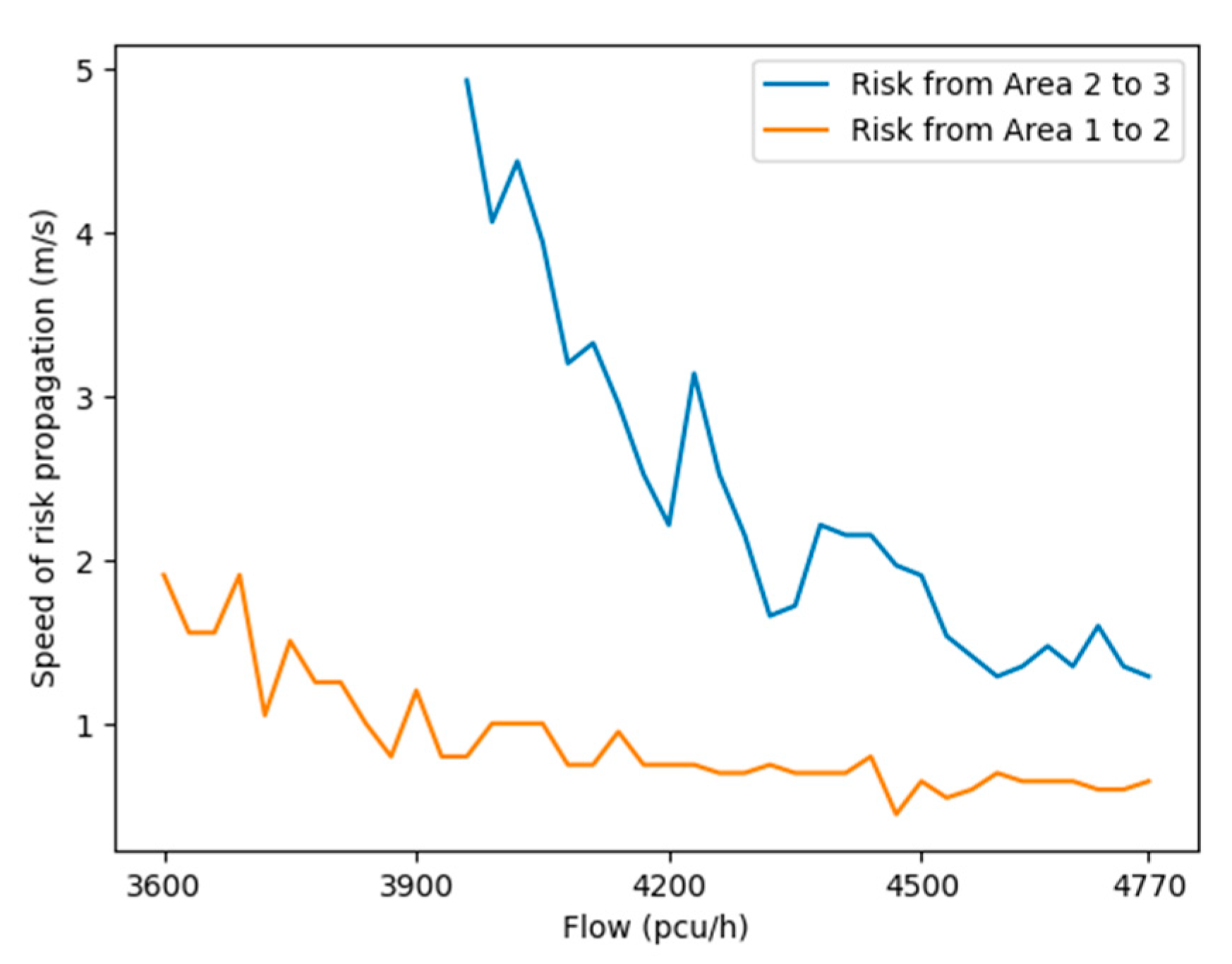
- The simulation results show that the risk of the first impact area remained high throughout the experiment. As the regional risk index in the first impact area decreased, the risk in the second and third impact areas increased. This means that the accident risk spreads from the first impact area to the following areas, which verifies the risk propagation phenomenon of accidents. The risk spreading time from one area to another was affected by traffic flow. Specifically, as traffic flow increases, the risk spread time from the first to second impact areas decreased. This indicates that accidents could spread more quickly in high traffic flow scenarios. The risk spread time from the second to third impact areas also decreased with increasing traffic flow. However, the speed of risk propagation between the second and third impact areas was generally faster than that between the first and second impact areas.
- The risk propagation speed of different impact levels is related to the accident location. Specifically, when the accident occurs downstream of the merging area, it takes longer for the risk to propagate from the first-level impact area to the second-level impact area compared to the spread time from the second-level impact area to the third-level impact area. However, when an accident occurs in the merging area, the situation is quite the opposite. This is because when the accident occurs downstream, part of the second-level impact area is in the merging area where there are fewer lanes and a higher likelihood of accidents. In contrast, the downstream area of the merging area has more lanes, larger vehicle gaps and lower vehicle speed. This makes it safer to drive. As a result, the risk takes more time to spread from the first-level to the second-level impact area.
- Furthermore, this study proposed a high-speed highway merging risk prediction model based on LSTM. The model performed well in predicting collision risk. It can be used by researchers and practitioners to predict and monitor highway merging risk accurately. Therefore, different control measures can be taken for different impact areas to achieve precise control and reduce the risk of traffic accidents.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Michalopoulos, P.M.; Pisharody, V.B. Derivation of delays based on improved macroscopic traffic models. Transp. Res. Part B 1981, 15, 299–317. [Google Scholar] [CrossRef]
- Sheu, J.; Chou, Y.; Chen, A. Stochastic modeling and real-time prediction of incident effects on surface street traffic congestion. Appl. Math. Model. 2004, 28, 445–468. [Google Scholar] [CrossRef]
- Deo, C.; Boniphace, K.; Gary, O. Impact of Abandoned and Disabled Vehicles on Freeway Incident Duration. J. Transp. Eng. 2014, 140, 40130131. [Google Scholar]
- Lawson, T.W.; Lovell, D.J.; Daganzo, C.F. Using Input-Output Diagram to Determine Spatial and Temporal Extents of a Queue Upstream of a Bottleneck. Transp. Res. Rec. 1996, 1572, 140–147. [Google Scholar] [CrossRef] [Green Version]
- Smid, R.M. The Variability of Traffic in Congestion Forecasting. Master’s Thesis, Delft University of Technology, The Hague, The Netherlands, 2012. [Google Scholar]
- Khattak, A.; Wang, X.; Zhang, H. Incident management integration tool: Dynamically predicting incident durations, secondary incident occurrence and incident delays. Intell. Transp. Syst. IET 2012, 6, 204–214. [Google Scholar] [CrossRef]
- Chung, Y.; Recker, W.W. A Methodological Approach for Estimating Temporal and Spatial Extent of Delays Caused by Freeway Accidents. IEEE Trans. Intell. Transp. Syst. 2012, 13, 1454–1461. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, L.; Dong, X. Forecasting Method of Traffic Accident Impact Sphere of Expressway Network. J. East China Jiaotong Univ. 2017, 34, 85–91. [Google Scholar]
- Hu, X.; Wang, W. Determination impact of traffic accident. J. Southeast Univ. 2007, 5, 198–201. [Google Scholar]
- Li, X. Determination Impact of Traffic Accident. Master’s Thesis, Chongqing Jiaotong University, Chongqing, China, 2015. [Google Scholar]
- Yu, B.; Lu, J. Method to Determine the Influence Area of Street Accidents. Urban Transp. 2008, 3, 82–86. [Google Scholar]
- Li, M.; Zhu, Y. Coverage Analysis and Simulation Study for Traffic Flow afterTraffic Accidents on Expressways. J. Highw. Transp. Res. Dev. 2012, 6, 109–111. [Google Scholar]
- Ma, A. Study on the Freeway Traffic Accident Duration and Influence Range. Master’s Thesis, Chang’an University, Chang’an, China, 2013. [Google Scholar]
- Lin, H. Study on Key Problems of Freeway Traffic Emergency Disposal. Master’s Thesis, Chang’an University, Chang’an, China, 2018. [Google Scholar]
- Jin, S.; Wang, W. Traffic accident affected zone division and traffic guidance under regional highway network. J. Chang’an Univ. 2017, 37, 89–98. [Google Scholar]
- Hossain, M.; Muromachi, Y. A Bayesian network based framework for real-time crash prediction on the basic freeway segments of urban expressways. Accid. Anal. Prev. 2012, 45, 373–381. [Google Scholar] [CrossRef]
- Zhai, B.; Lu, J.; Wang, Y. Real-time prediction of crash risk on freeways under fog conditions. Int. J. Transp. Sci. Technol. 2020, 9, 287–298. [Google Scholar] [CrossRef]
- Sun, J.; Sun, J. A dynamic Bayesian network model for real-time crash prediction using traffic speed conditions data. Transp. Res. Part C Emerg. Technol. 2015, 54, 176–186. [Google Scholar] [CrossRef]
- Chen, X.; Wang, Z.; Hua, Q.; Shang, W. AI-Empowered Speed Extraction via Port-Like Videos for Vehicular Trajectory Analysis. IEEE Trans. Intell. Transp. Syst. 2023, 24, 4541–4552. [Google Scholar] [CrossRef]
- Yang, K.; Zhao, W.; Antoniou, C. Utilizing Import Vector Machines to Identify Dangerous Pro-active Traffic Conditions. In Proceedings of the International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 1–6 September 2020. [Google Scholar]
- Zhang, J.; Hu, Z.; Zhu, X. Real-time traffic accident prediction based on AdaBoost classifier. J. Comput. Appl. 2017, 37, 284–288. [Google Scholar] [CrossRef]
- Qu, X.; Wang, W.; Wang, W. Real-time rear-end crash potential prediction on freeways. J. Cent. South Univ. 2017, 24, 2664–2673. [Google Scholar] [CrossRef]
- Fu, C.; Wang, J. A real-time accident risk model on freeways based on monitoring data. J. Transp. Inf. Saf. 2017, 35, 11–17. [Google Scholar]
- Zhou, Z.; Wang, Y.; Xie, X.; Chen, L.; Liu, H. RiskOracle: A Minute-level Citywide Traffic Accident Forecasting Framework. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Yuan, Z.; Zhou, X.; Yang, T. Hetero-ConvLSTM: Hetero-ConvLSTM: A Deep Learning Approach to Traffic Accident Prediction on Heterogeneous Spatio-Temporal Data. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018. [Google Scholar]
- Yu, L.; Du, B.; Hu, X.; Sun, L.; Han, L.; Lv, W. Deep spatio-temporal graph convolutional network for traffic accident prediction. Neurocomputing 2021, 423, 135–147. [Google Scholar] [CrossRef]
- Ren, H.; Song, Y.; Wang, J.; Wang, J.; Lei, J. A Deep Learning Approach to the Citywide Traffic Accident Risk Prediction. In Proceedings of the 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018. [Google Scholar]
- Chen, Q.; Song, H.; Yamada, H.; Shibasaki, R. Learning Deep Representation from Big and Heterogeneous Data for Traffic Accident Inference. In Proceedings of the 30th AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Zhu, S.; Jiang, R. Review of Research on Traffic Conflict Techniques. J. Highw. Transp. 2020, 33, 15–33. [Google Scholar]
- Pasquill, F.; Smith, F.B. The Determination of the Dispersion of Windborne Material. Meteorol. Mag. 1961, 90, 33–49. [Google Scholar]
- Yang, L.; Luo, X.; Zuo, Z.; Zhou, S.; Huang, T.; Luo, S. A novel approach for fine-grained traffic risk characterization and evaluation of urban road intersections. Accid. Anal. Prev. 2023, 181, 106934. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Wang, S.; Long, X.; Li, D.; Ma, C.; Li, P. Ellipse-Like Radiation Range Grading Method of Traffic Accident Influence on Mountain Highways. Sustainability 2022, 14, 13727. [Google Scholar] [CrossRef]
- Yang, F. Accident Prediction and Safety Hazards Digging of Ordinary Arterial Highway in Mountain Area Based on Accident Scenario Classification. Doctor Thesis, Chang’an University, Chang’an, China, 2021. [Google Scholar]
- Greff, K.; Srivastava, R.K.; Koutník, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A search space odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2016, 28, 2222–2232. [Google Scholar] [CrossRef] [Green Version]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the difficulty of training recurrent neural networks. In Proceedings of the 30th International Conference on Machine Learning (ICML-13), Atlanta, GA, USA, 16–21 June 2013. [Google Scholar]
- Chen, X.; Wu, X.; Prasad, D.; Wu, B. Pixel-Wise Ship Identification From Maritime Images via a Semantic Segmentation Model. IEEE Sens. J. 2022, 22, 18180–18191. [Google Scholar] [CrossRef]












| Accident Type | N × m | Impact Range (m) | ||||
|---|---|---|---|---|---|---|
| Side collision | 0.5 | 1000 | 3e-7 | 1 | (0.05, 0.3,1) | (227.3, 413.1, 617.1) |
| Rear-end collision | 1/3 | (198.6, 360.9, 539.1) |
| Variable Name | Explanation |
|---|---|
| Traffic_flow_all | Initial traffic volume in the simulation scenario |
| Speed_1 | Average speed of vehicles passing through the first impact area |
| Speed_2 | Average speed of vehicles passing through the second impact area |
| Speed_3 | Average speed of vehicles passing through the third impact area |
| Traffic_flow_1 | Number of vehicles passing through the first impact area |
| Traffic_flow_2 | Number of vehicles passing through the second impact area |
| Traffic_flow_3 | Number of vehicles passing through the third impact area |
| RL1 | Regional risk index for the first impact areas |
| RL2 | Regional risk index for the second impact areas |
| RL3 | Regional risk index for the third impact areas |
| Location | Categorical variable, 1 if the accident is in the merging areas, 0 otherwise |
| Lane1 | Categorical variable, 1 if the accident occurred in lane 1, 0 otherwise |
| Lane2 | Categorical variable, 1 if the accident occurred in lane 2, 0 otherwise |
| Lane3 | Categorical variable, 1 if the accident occurred in lane 3, 0 otherwise |
| Lane4 | Categorical variable, 1 if the accident occurred in lane 4, 0 otherwise |
| Number of Neurons. | Optimizer | Activation Function | Learning Rate | Batch Size | Epoch | Dropout |
|---|---|---|---|---|---|---|
| 50 | ADAM | Sigmoid | 0.01 | 120 | 50 | 0.2 |
| Impact Area | Model | RMSE | MSE | MAE |
|---|---|---|---|---|
| 1 | LSTM | 0.0153 | 0.0002 | 0.0122 |
| RNN | 0.0212 | 0.0004 | 0.0189 | |
| 2 | LSTM | 0.0219 | 0.0005 | 0.0136 |
| RNN | 0.0337 | 0.0011 | 0.0215 | |
| 3 | LSTM | 0.0158 | 0.0002 | 0.0146 |
| RNN | 0.0241 | 0.0005 | 0.0198 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ye, Q.; Li, Y.; Niu, B. Risk Propagation Mechanism and Prediction Model for the Highway Merging Area. Appl. Sci. 2023, 13, 8014. https://doi.org/10.3390/app13148014
Ye Q, Li Y, Niu B. Risk Propagation Mechanism and Prediction Model for the Highway Merging Area. Applied Sciences. 2023; 13(14):8014. https://doi.org/10.3390/app13148014
Chicago/Turabian StyleYe, Qing, Yi Li, and Ben Niu. 2023. "Risk Propagation Mechanism and Prediction Model for the Highway Merging Area" Applied Sciences 13, no. 14: 8014. https://doi.org/10.3390/app13148014