1. Introduction
Video-based human action recognition (HAR) is one of the most significant study fields in computer vision, with algorithms becoming more effective by the day. HAR has many applications ranging from surveillance, video tagging, activity/event detection, etc. [
1,
2]. The main goal in human action recognition is to automatically detect the sort of actions that are being performed in the video, e.g., archery, basketball shooting, horse riding, etc. It is a very difficult task owing to the many problems it entails, such as camera motion, varying lighting conditions, backdrop bombardment, various human forms, occlusion, perspective fluctuation, and so on. Such varied changes in the videos make this task challenging and interesting to solve using automated methods. However, the impact of these problems varies depending on the type of action. The four primary kind of action are gestures, interactions, actions, and group activities.
Several researchers have used different modalities for handling HAR, including sensor-based methods [
3] and video streams [
4]. Due to the vast availability of video data, a major portion of researchers concentrate on video processing for HAR, which is the significant topic of work in this paper as well.
Different strategies have been used to extract the motions inside the pictures and videos. In general, recent research on HAR mainly focuses on spatial and temporal models. Sparse segments are used to simulate long-term temporal structure in temporal segment networks (TSNs) [
5]. The utilization of the concept that models learn hierarchical motion patterns within image space has been employed to address diverse temporal modeling challenges in 3D CNN networks [
6,
7]. Tracking characteristics are employed to improve the effectiveness of temporal modeling [
7,
8]. As HAR is a challenging domain, the authors in [
9] provided a thorough literature review of the available datasets. They identified around 68 different datasets, of which 28 are heterogeneous and 40 are for specific human actions.
In [
4], the authors proposed a three-step framework for human activity recognition comprising background subtraction, parameter extraction, and evaluation. In [
10], the authors presented a knowledge representation framework to detect the occurrence of specific events defined as targets in the surveillance scenario. In [
11], the authors presented high-level video event modeling and recognition based on a Petri net. The results shown are encouraging as the event recognition is fully automated. In [
12], the authors presented a framework to jointly learn a view-invariance transfer dictionary, and subsequently a view-invariant classifier. This framework has allowed them to obtain improved performance on the available video datasets.
In [
13,
14,
15], the authors emphasize using convolutional networks (ConvNets) for this task of HAR. Researchers have shown that temporal filters, such as local spatiotemporal filters, can be applied to spatiotemporal objects such as actions, making it possible to use spatial recognition ideas on temporal objects [
14,
15,
16]. This difference between time and space is significant, and different techniques have been examined, such as adding optical flow networks (which simulate motion) [
17] or modeling time sequences in recurrent structures (which represent patterns in nature) [
18,
19,
20].
The two-stream architecture is based on a hypothesis that came out of neuroscience research called the two-stream hypothesis [
13], which states that the visual cortex has two separate pathways: (i) the ventral pathway, which processes information about the visual attributes of objects such as shape and color, and (ii) the dorsal pathway, that responds to transformations in the object, and to spatial relationships as an object of motion. In a typical implementation of a two-stream network, both streams use a different set of inputs to classify actions. One of the streams is trained on stacked RGB images, hence is referred to as ‘the spatial stream’. The second stream, referred as ‘the temporal stream’, uses motion vector-based images as its input to train, which need to be computed beforehand, and thus this can also be time consuming. As both streams use different types of inputs to train their networks, they can take advantage of different methods of feature representation and extraction, combining the strengths of both. Both streams are merged via different techniques to form ‘the two-stream network’, and the classification results are calculated. However, the problem of overfitting exists in both streams as deep learning networks need a large amount of data for stable weight training.
As mentioned earlier, the two-stream network approach made a breakthrough in action recognition as some activities are time oriented (temporal) and others are scene oriented (spatial) in a single dataset. Using any single approach would fail to recognize other types of activity. Hence, we used the two-stream network approach.
The contributions of this paper are as follows:
We demonstrate (using experiments) that using pre-trained models in the spatial stream yields good performance results as compared to training the entire model from scratch and it also saves time. We achieve this by freezing the classification layers of the original two-stream model [
13] and attaching the feature extraction layers of different pre-trained models one by one and then training the fully connected layers only to check which model performs best. After selecting the best model, we fine-tune the whole network to see if the results can be improved.
We present a strategy to deal with the problem of overfitting by using dataset augmentation. The main reason behind overfitting is the limited dataset provided to a deep network to train its model. We incorporate dataset augmentation to increase our dataset size using different augmentation techniques, including horizontal image flipping and rotation.
Our proposed method can avoid training the entire model from scratch, which saves time and avoids the use of high-cost computational resources without compromising the results. The remaining paper is structured as follows:
Section 2 gives the relevant state of the art work performed in this domain of video-based HAR,
Section 3 gives the details of the proposed methodology,
Section 4 gives the implementation details, and this is followed by the experimental results in
Section 5 and conclusions in
Section 6.
2. State of the Art
In [
13], the authors use threefold cross-validation to improve HAR accuracy. Initially, they introduce a concept of two-stream ConvNet that mixes spatial and temporal networks. Secondly, they claim that despite little training data, a ConvNet can be trained on dense optical flow from several consecutive frames and yet achieve outstanding results. They finalize their presentation by demonstrating the potential application of multitask learning, which can effectively amplify the volume of training data and improve performance as a whole. The most important feature is local trajectory pooling, with spatial and temporal tubes that are coordinated across spatiotemporal layers to concentrate on trajectories. Even while the network can detect the optical flow along the trajectories, it ignores trajectories in spatial pooling. However, the designed network still needs to catch up with the current state-of-the-art shallow representation [
21] in terms of the achieved accuracy.
In [
22], spatiotemporal ResNets were used as a combination of these two methods. To begin, residual connections between the appearance and motion channels of a two-stream architecture were injected to allow for spatiotemporal stream interaction. Then, the learned convolutional filters were applied to adjacent feature maps in time to convert pre-trained image ConvNets to spatiotemporal networks.
In their subsequent paper [
23], the same authors have reduced the parameters by merging the spatial and temporal networks at a convolutional layer, with no performance loss. A spatiotemporal architecture was designed for two-stream networks comprising a novel temporal and a convolutional fusion layers, which were connected to the networks. Regarding performance, the innovative design exceeded the top rank on two common benchmark datasets without significantly increasing the number of parameters. According to the findings, it was found that learning correspondence between ConvNet characteristics that are very abstract in both space and time is extremely important.
In [
24], remodeling of the dataset was deployed for initializing model learning by using the augmentation of data, and ResNet101 layer parameters trained on datasets such as ImageNet were used to deal with the overfitting issues caused by having less data. Deeper ConvNet was developed for learning the complexity of action. Using a disorder testing and training method, the model and procedure may provide a substantial boost in action recognition. The experiments showed that the strategy beats current top-ranked methodologies on two advanced datasets, the UCF101 [
25] and the KTH action datasets [
26]. The temporal network with deeper convolutional networks did not perform well compared to the appearance networks on the UCF101 dataset during the experimental evaluation. The following potential alternative might help to overcome this constraint where it was proposed to capture information on motion with a deep temporal structure by adopting deeper recurrent neural networks (RNNs).
A two-stream adaptive graph convolutional network (2S-AGCN) was designed specifically for action recognition in [
27], which uses the skeleton technique. In this technique, graph convolutional networks (GCNs) are used, which model the human body skeleton as spatiotemporal graphs. The backpropagation technique may learn the network architecture either uniformly or individually as it goes along. Making this data-driven technique part of the model increases the model’s flexibility for constructing graphs and increases the model’s generality for varying data samples. To explain both first-order and second-order information, a two-stream framework was developed, and a significant improvement in recognition accuracy was achieved.
In [
28], the authors proposed a motion-attentive transition network for zero-shot video object segmentation. They named this network MATNet; it uses a two-stream encoder network to treat motion and appearance independently in separate streams. The authors tested their network on four challenging public benchmark datasets and showed the effectiveness of their network.
In [
29], residual images were used to feed the temporal stream of the network rather than conventional optical flow images. This reduced the computational requirements, due to less data to process, and increased the accuracy in comparison to the state of the art models. Because residual frames offer minimal information on object appearance, they utilized a 2D convolutional network to extract appearance features and combined them with residual frame findings to build a two-path solution, reporting a marked improvement in the speed of execution and accuracy.
Table 1 shows the state-of-the-art research work on the UCF101 dataset, where we have summarised the work of researchers who have used optical flow.
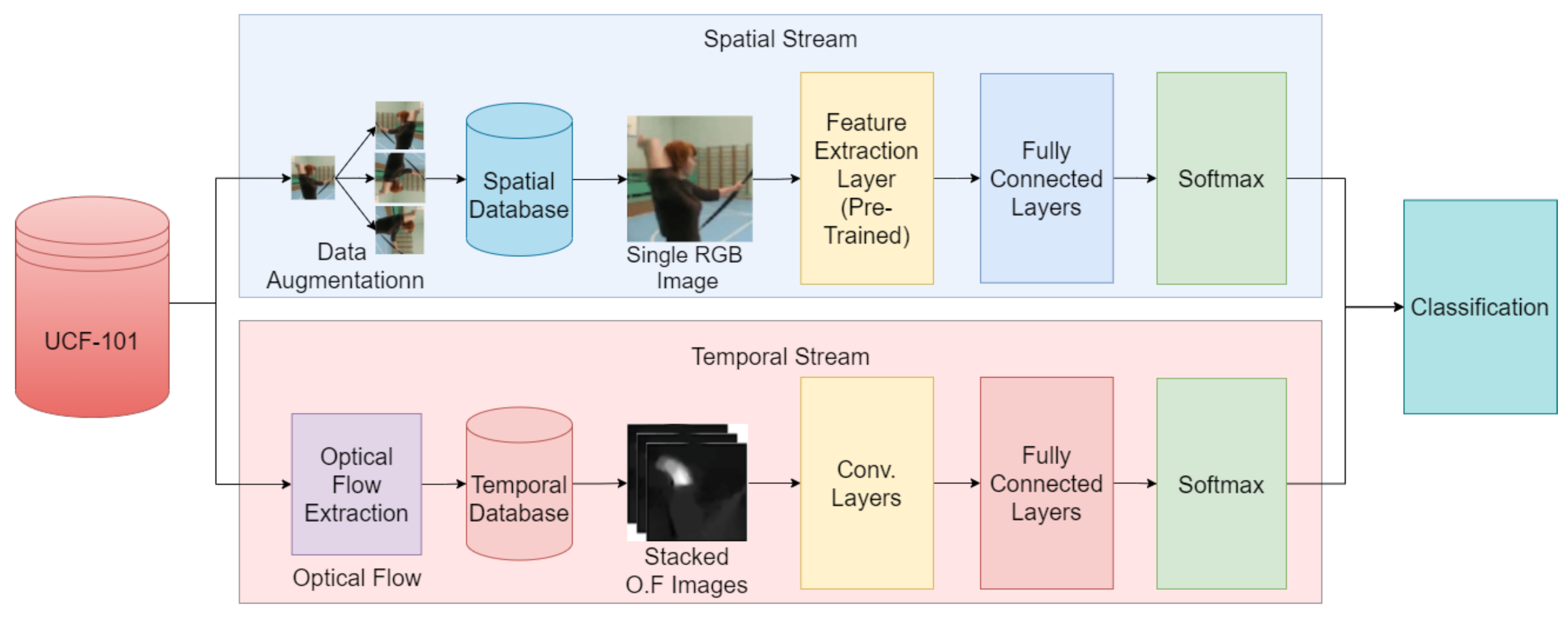
3. Proposed Methodology
The block diagram of the proposed deep two-stream convolutional network is shown in
Figure 1 with its respective spatial and temporal streams. The spatial stream uses each video frame as a single image for feature extraction and processing. It uses a pre-trained ImageNet model [
30] as the feature extraction part. For the temporal stream architecture, we use a stack of optical flow fields as input to the architectures. Doing so achieves two goals: firstly, the data being processed reduces as there are less data in optical flow fields as compared to RGB images; secondly, the optical flow will capture the moving regions in an image, thus making it easier to identify the HAR. The details of each stream architecture are given in
Section 3.2 and
Section 3.3.
3.1. Dataset
The UCF101 dataset contains a total of 13,320 videos from 101 human action classes extracted from videos in the wild. It has the widest variety in terms of actions, and it is the most complex dataset to date in this domain, with substantial differences in camera motion, object look and position, object size, perspective, cluttered backdrop, light conditions, and so on. This is a supplement to UCF50 dataset, that contains 50 activities. Because most accessible action recognition datasets are unrealistic and produced by actors, UCF101 intends to inspire future action recognition research by learning and exploring new realistic action categories. The videos are divided into 25 action groups, where each group may contain 4–7 clips. The details of the dataset are given in
Table 2.
3.2. Spatial Stream
For some actions, a single frame from the whole video can be enough to recognize the actions correctly. This can be true mostly for actions that involve human–object interactions such as playing a guitar, discus throwing, hammering, or basketball. As in these action videos, recognizing an object correctly in a frame can lead to recognizing the associated action successfully. Keeping this hypothesis in mind, the spatial stream can simply be called a modified version of the image classification stream, which takes a single RGB image as input for action recognition.
Enhanced Spatial Stream
As discussed earlier, the spatial stream is in fact an image recognition architecture. Keeping this analysis in mind, we use advanced pretrained models like ImageNet to our advantage and train the classification part only instead of training the original CNN model from scratch. Then, we fine-tune them on our dataset (UCF101) using a transfer learning technique [
31] to form an enhanced spatial stream by adding a fully connected layer at the end and running the training session for a few iterations. The proposed architecture of our enhanced stream is shown in
Figure 2, where the feature extraction part of the pre-trained model is merged with the classification part of the original architecture from a two-stream network [
13].
ImageNet [
30] is a well-known dataset that has been extensively used in computer vision since its publication in 2015. The dataset contains over 100,000 classes and has been made available for educational and non-commercial research purposes. Several research teams, including Google, Nvidia, etc., have trained their models on this dataset and have made their trained models available for research purposes.
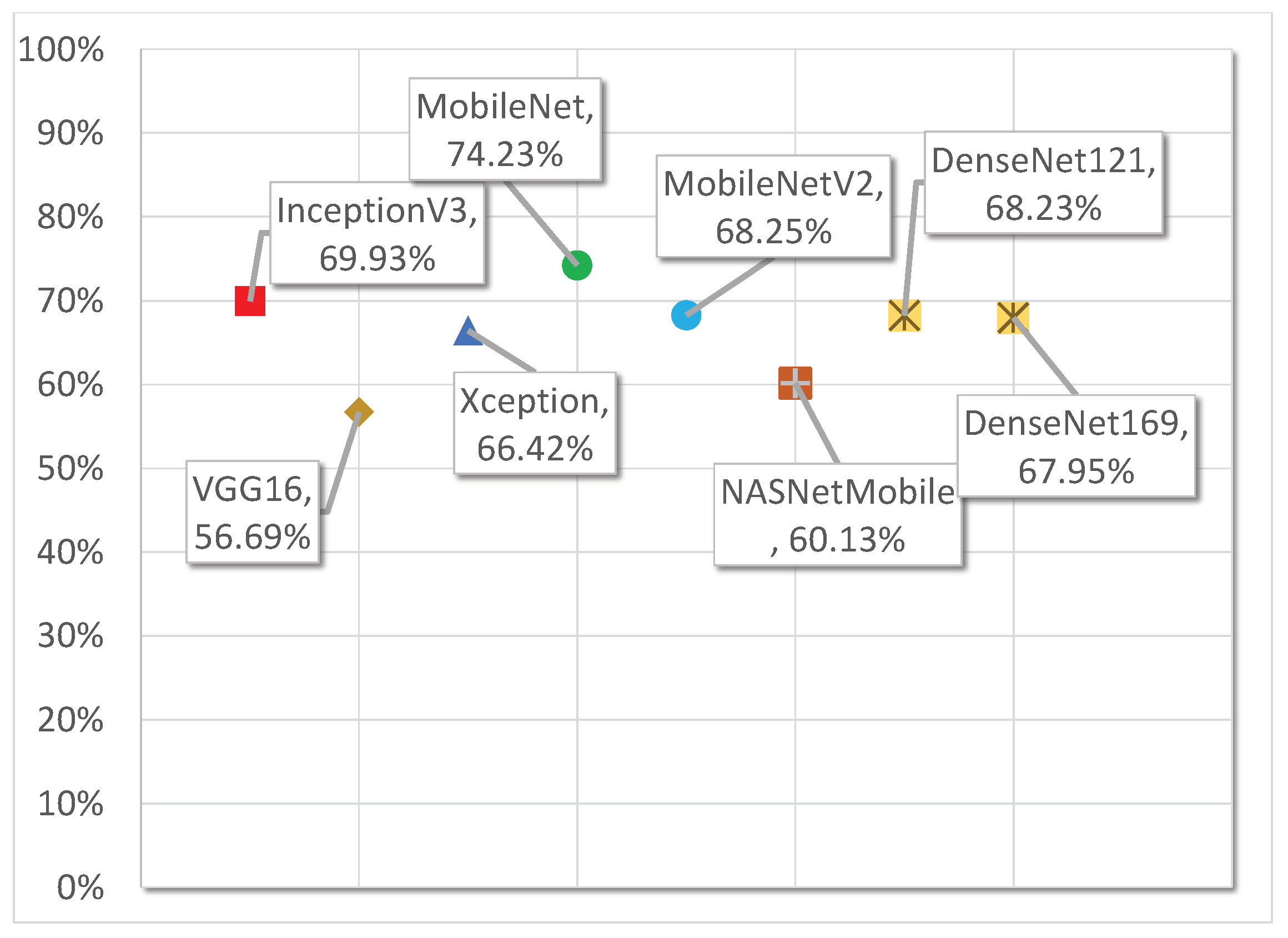
Table 3 contains different models trained on ImageNet with the details of the number of layers in the model and the number of parameters being used in the specific model.
In our experiments, we have have found quite a few similarities between the ImageNet and UCF101 datasets. As an example, UCF101 dataset has a class “WalkingWithDog” involving dogs, while the ImageNet also has examples containing dogs, such as “MalteseDog”. Because of the similarities in the types of task between the two datasets, we used pre-trained models on ImageNet for our problem and tailored them to fit our problem by using transfer learning techniques. The different pre-trained models listed in
Table 3 will be evaluated individually by training the classification layers only. The best-performing model will be selected and further fine-tuned to check for any further improvement in the performance.
3.3. Optical Flow Convolutional Networks
Although for certain activities, a single frame can be enough for recognizing object-oriented activities, however, time-oriented activities such as running, jogging, etc., need special input. Here, we describe the input to the ConvNet model for the temporal stream.
Optical flow displacement fields are stacked multiple times to form the input for the temporal stream. Such inputs will explicitly describe the motion between two consecutive frames. As a result, the network is freed of the need to estimate motion and can focus on pattern recognition. We present the details of the proposed optical flow based architecture in
Figure 3.
Stacked Optical Flow
Dense optical flow refers to a collection of displacement vectors, denoted as
, which represent the motion between pairs of consecutive frames in a sequence, where
d is the displacement vector that represents the movement direction between two consecutive frames in frame
t, as in
Figure 4a,b. The displacement vector is a point (
u,
v), at locations
u and
v in a frame
t, which moves to the corresponding point in frame
t + 1, thus, can be denoted by
dt(
u,
v) for the
tth frame. The horizontal component
and vertical component
of the displacement vector and their optical flow representation as an image can be seen in
Figure 4.
In the corresponding image, only the outlined region is being moved during two consecutive frames (an arm of the person).
Figure 4a,b show the movement detection of the arm. Now,
Figure 4c of the image shows the
x component of the vector
d and
Figure 4d shows the
y component of the vector
d. Both the
x and
y components in the images are represented by white and black colors in the respective images. Motion across the consecutive frames is represented by stacking the vertical and horizontal components’ displacement vectors of
L continuous frames to form a total of 2
L input channels. A ConvNet input volume
for a video frame of width
w and height
h, for temporal stream with an arbitrary input
τ, can be denoted as in Equations (
1) and (
2).
3.4. Avoiding Overfitting
Overfitting is mainly caused by having a small amount of data available to train a deep network. To tackle this issue, we adapt some helpful techniques to minimize overfitting in the spatial and temporal streams.
3.4.1. Dataset Augmentation for Spatial Stream
Data augmentation is a technique that allows practitioners to substantially enhance the variety of data available for training models without gathering new data. When training large neural networks, data augmentation methods such as trimming, padding, vertical and horizontal flipping, and rotation are frequently employed. However, data augmentation and its strategies that capture data invariances have received less attention than the neural network designs themselves. These techniques were employed during the training phase on the dataset to increase the number of images. Horizontal flip, horizontal shift, vertical shift, and rotation transformations were used to increase the total number of images from 2,482,325 to 2,693,322 images, resulting in an increase of 8.5% in the overall size of the dataset.
3.4.2. Data Variation for Temporal Stream
Instead of clipping the prominent areas of the picture center, as performed in [
32], we incorporated a method of data variation in our proposed work to enhance the data variety. All frames are cropped from four corners by randomly choosing the height and width for each set, which was to make use of multiple scale representations. After resizing the clipped areas to 224 × 224 and flipping them horizontally, they were presented to the proposed model as input for training the network. This kind of augmentation method significantly increases the variability in inputs during the training process, which helps to minimize the issue of overfitting.
6. Conclusions
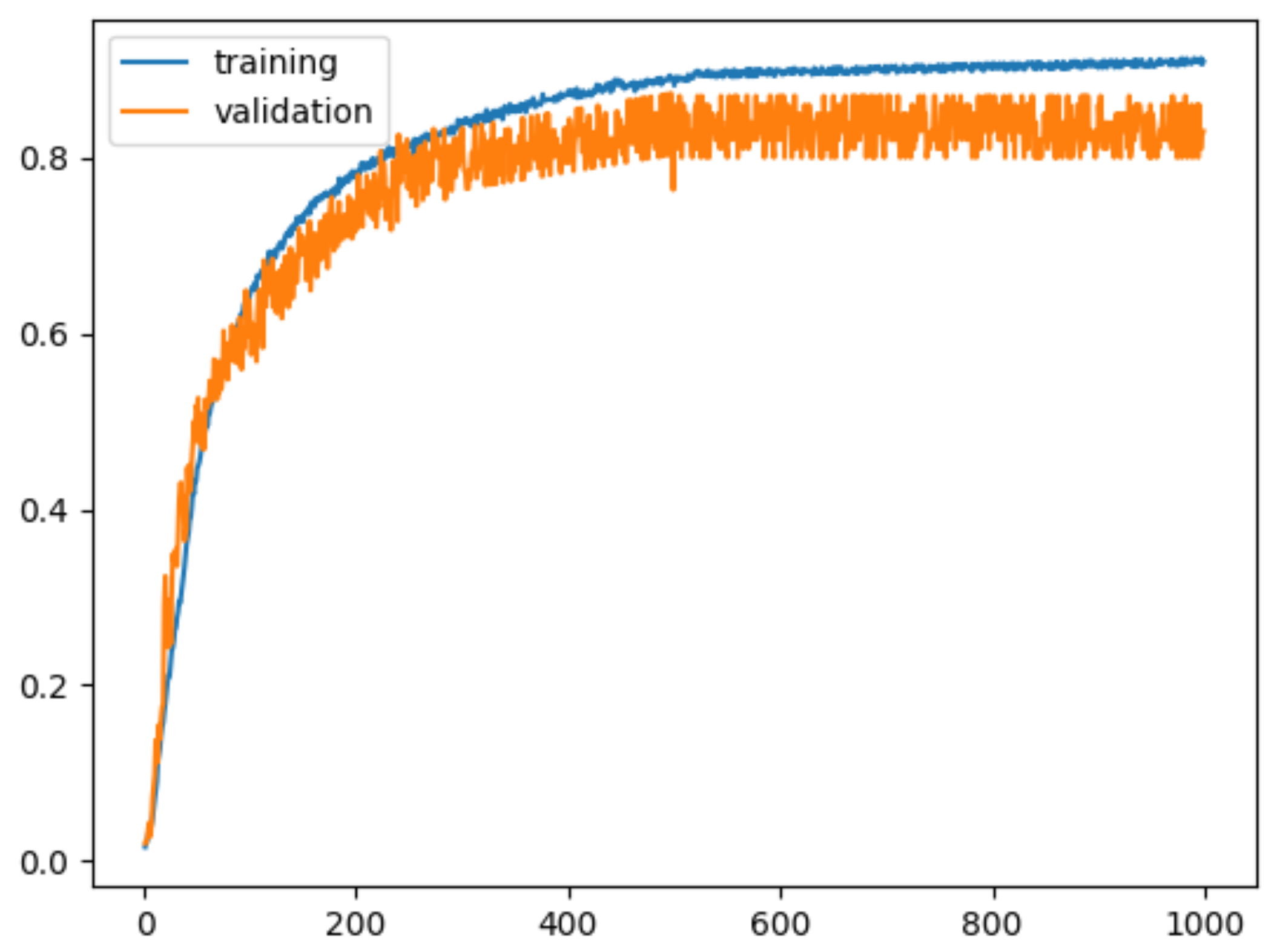
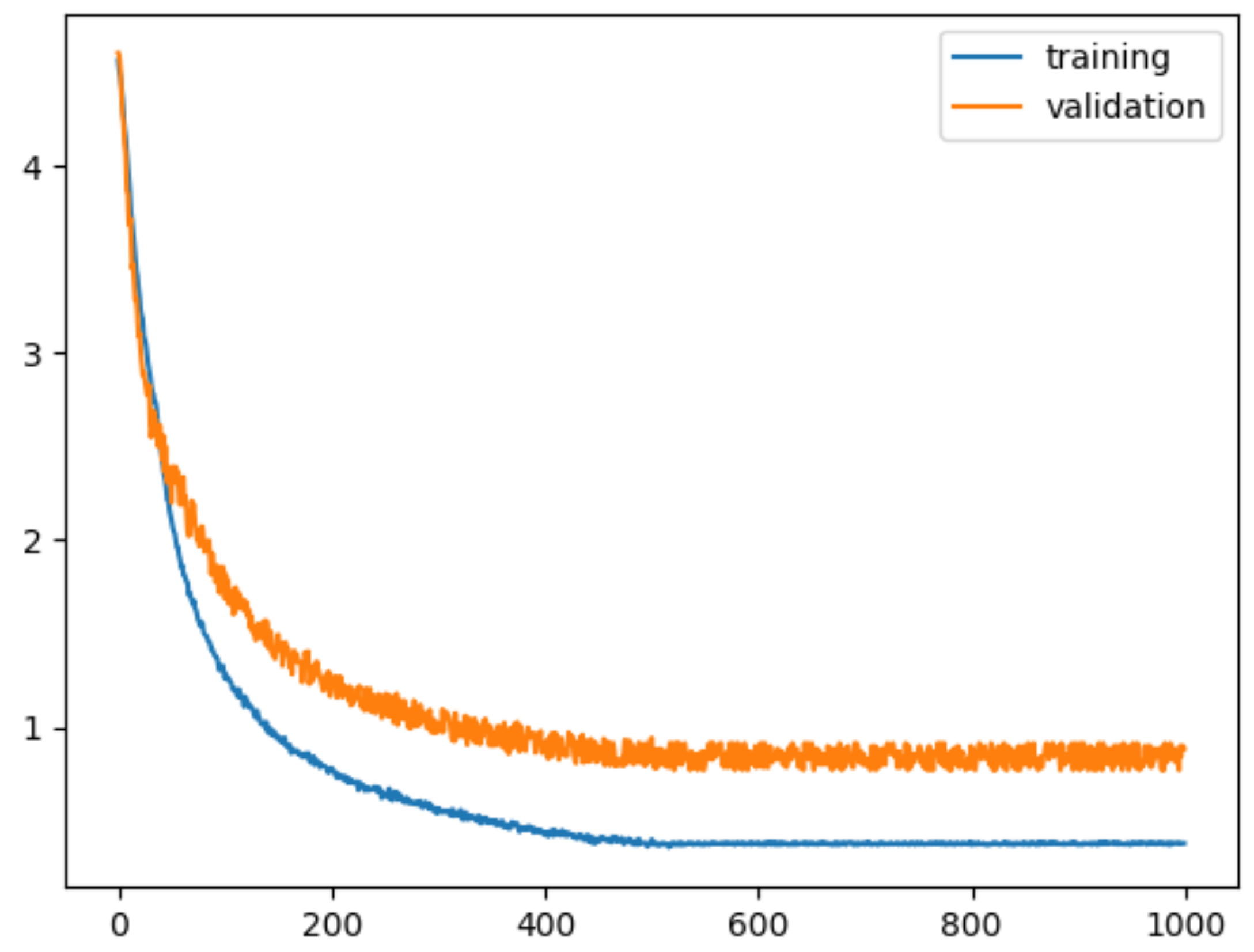
The key goal of our research was to develop a reliable HAR network. Various techniques were discussed in this paper to cope with the problems faced by two-stream networks including overfitting, and their effects were measured. Different configurations of inputs were also considered, and the results were compared with published research. Here, we proposed an enhanced form of the original spatial stream. Several strategies were deployed to reduce the overfitting issue posed by the insufficient datasets. Using data augmentation and transfer learning, a critical improvement in HAR has been attained. The empirical experiments have shown that the proposed architecture’s results are better than the top-ranked model in terms of accuracy, with 91.2% accuracy on the UCF101 dataset.
While the currently applied methodology provides good results for the used dataset, future research into new alternatives for the proposed system may enhance precision. Using transfer learning in the temporal stream can provide good results. Furthermore, by adding more activities to the existing datasets, overfitting can be further minimized. Furthermore, the current study offers foundational principles for future researchers to investigate more configurations in the stated architecture, which will aid in the HAR system’s high achievement level.

 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}