


Classification of Ethnicity Using Efficient CNN Models on MORPH and FERET Datasets Based on Face Biometrics

Abstract
:1. Introduction
2. Related Work
2.1. Background
2.2. Existing Methods
2.3. Existing Methods and Novelty
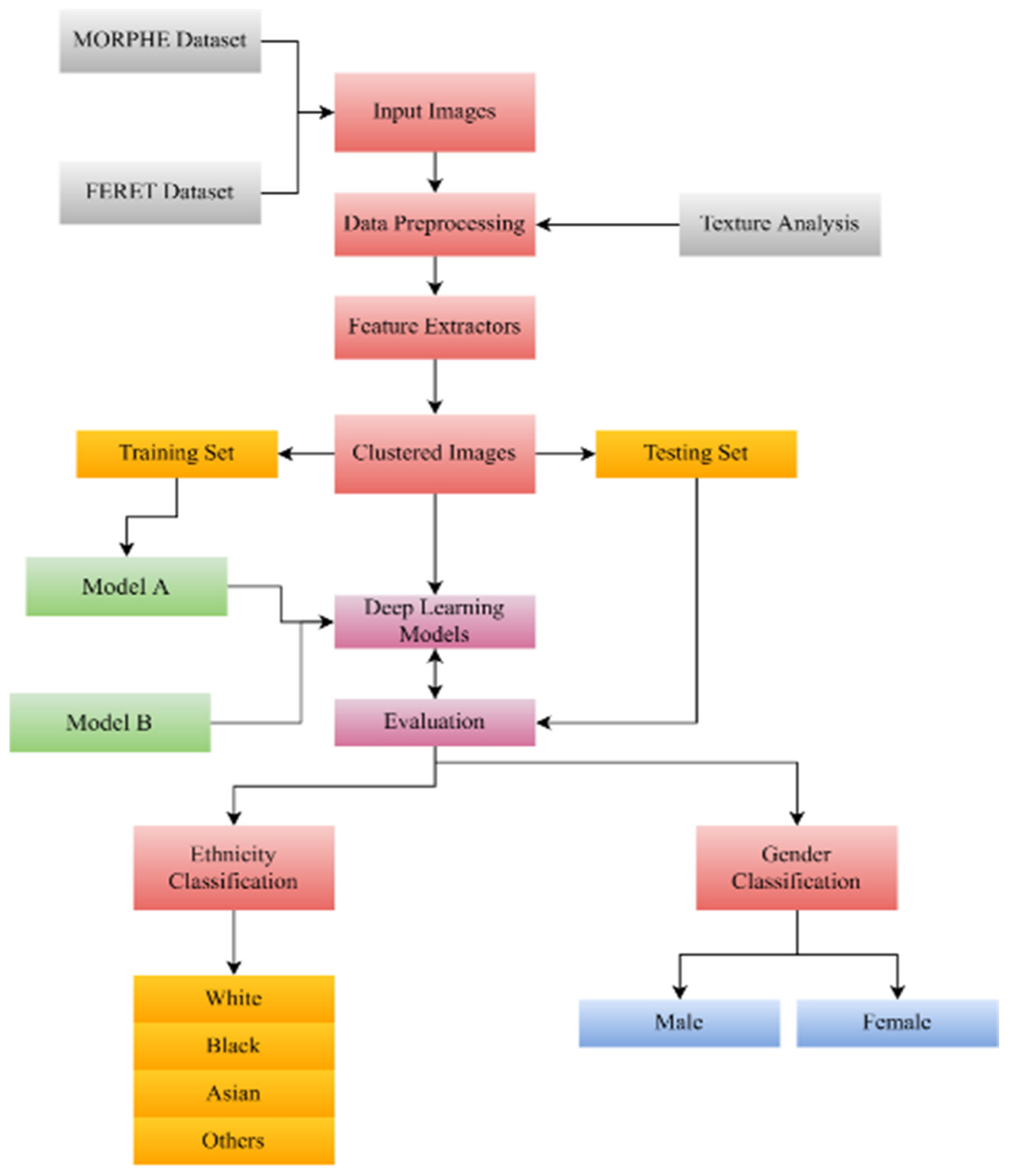
3. Methodology
3.1. Augmentation Strategies
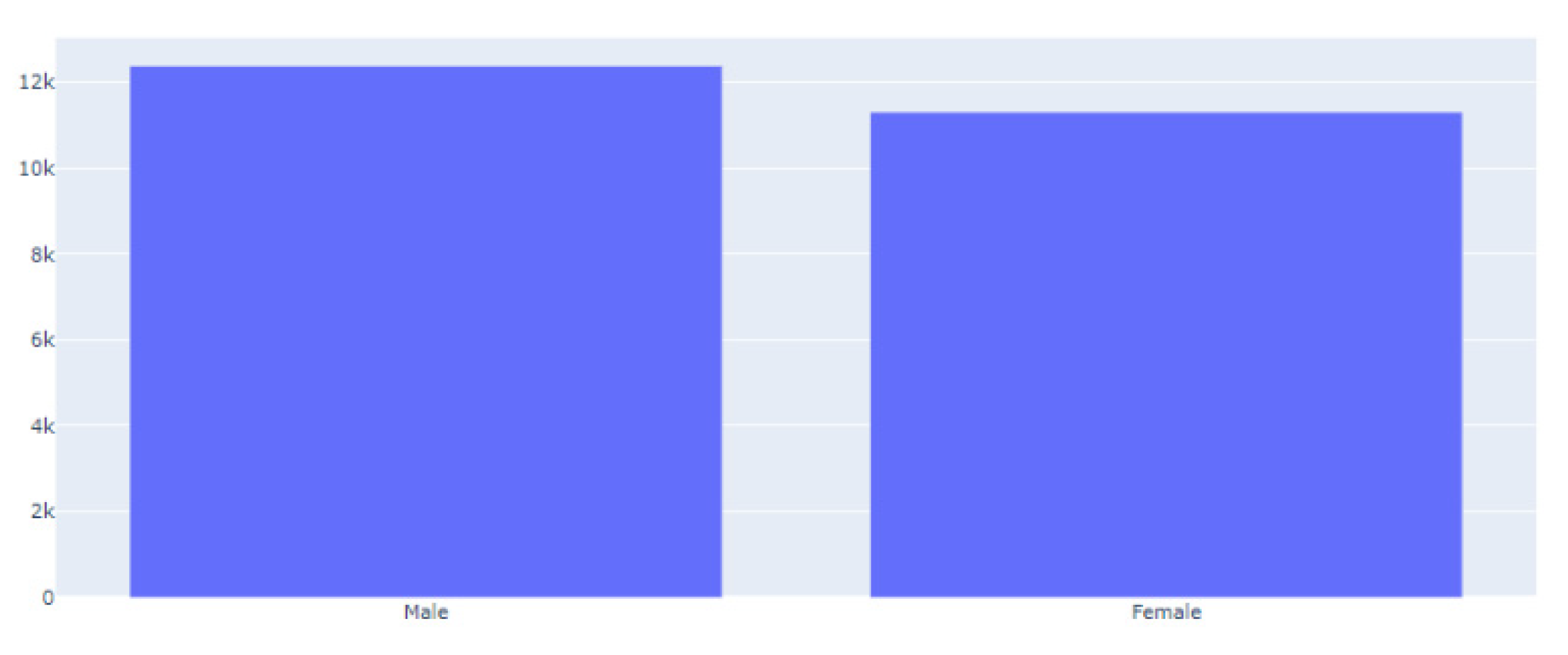
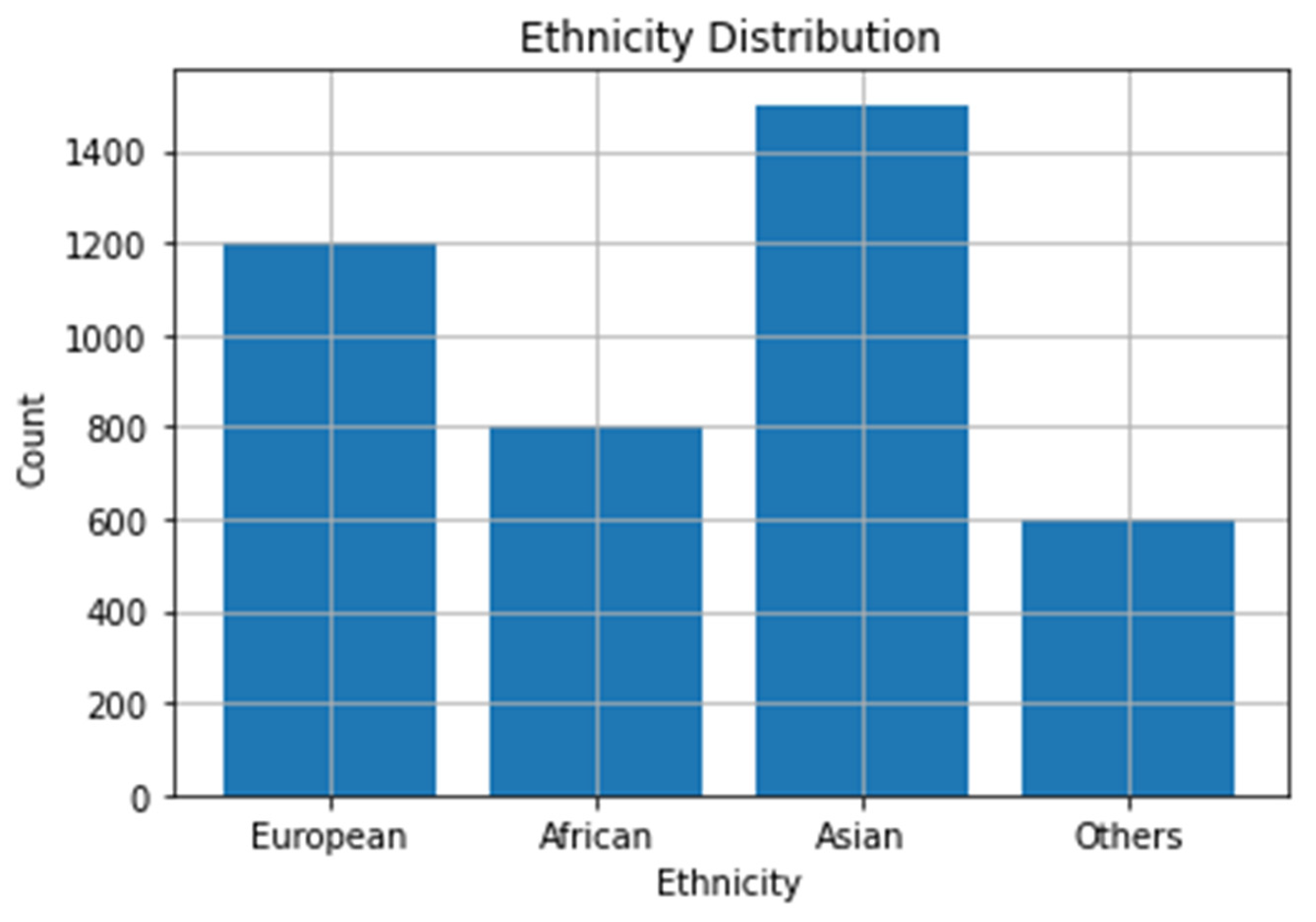
3.2. Dataset Description
3.3. Face Verification Experiments
3.4. Texture Classification
3.5. Feature Extraction
3.6. Deep-Learning Models for Image Classification
Proposed Gender Classification Model
3.7. Model Training
3.8. Proposed Ethnicity Recognition Model
3.9. Normalized Forehead Area Calculation
3.10. Proposed Convolutional Neural Network Model
3.11. Model Training and Testing
3.12. Model Evaluation Parameters
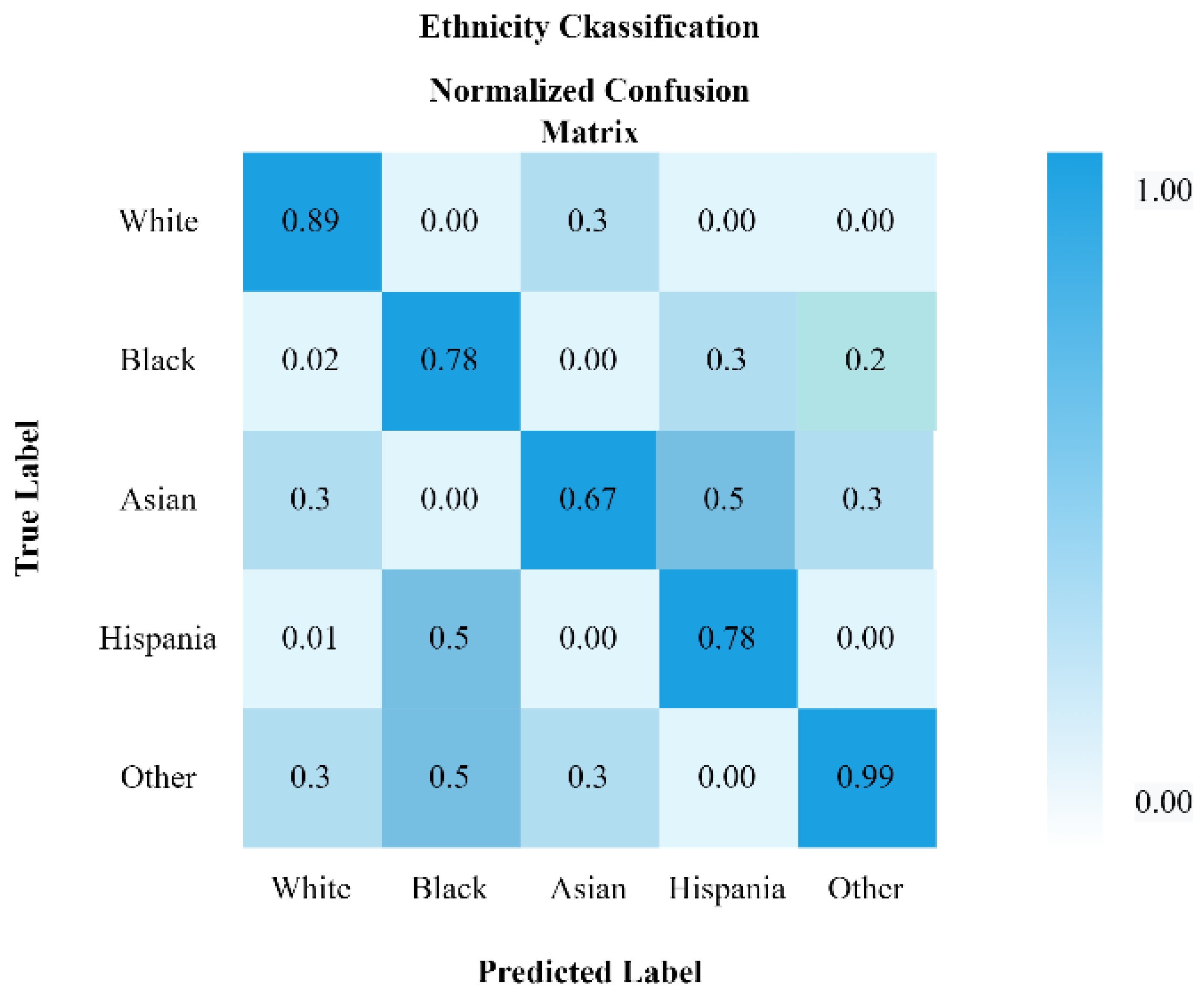
4. Results and Discussion
4.1. Results for Model 1 on Dataset 1
4.2. Results of Model 2 on Dataset 1
4.3. Results of Model 1 on Dataset 2
4.4. Results of Model 2 on Dataset 2
10-Fold Cross-Validation
4.5. Comparative Analysis
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Akbar, M.; Furqan, K.M.Y.; Yaseen, H. Evaluation of Ethnicity and Issues of Political Development in Punjab, Pakistan. Glob. Polit. Rev. 2020, V, 57–64. [Google Scholar] [CrossRef]
- Anwar, I.; Islam, N.U. Learned features are better for ethnicity classification. Cybern. Inf. Technol. 2017, 17, 152–164. [Google Scholar] [CrossRef] [Green Version]
- Belcar, D.; Grd, P.; Tomičić, I. Automatic Ethnicity Classification from Middle Part of the Face Using Convolutional Neural Networks. Informatics 2022, 9, 18. [Google Scholar] [CrossRef]
- Masood, S.; Gupta, S.; Wajid, A.; Gupta, S.; Ahmed, M. Prediction of human ethnicity from facial images using neural networks. Adv. Intell. Syst. Comput. 2018, 542, 217–226. [Google Scholar]
- El Khiyari, H.; Wechsler, H. Face Verification Subject to Varying (Age, Ethnicity, and Gender) Demographics Using Deep Learning. J. Biom. Biostat. 2016, 7, 11. [Google Scholar] [CrossRef]
- Sulaiman, M.A.; Kocher, I.S. A systematic review on Evaluation of Driver Fatigue Monitoring Systems based on Existing Face/Eyes Detection Algorithms. Acad. J. Nawroz Univ. (AJNU) 2022, 11, 57–72. [Google Scholar] [CrossRef]
- Ghani, M.U.; Alam, T.M.; Jaskani, F.H. Comparison of Classification Models for Early Prediction of Breast Cancer. In Proceedings of the 2019 International Conference on Innovative Computing (ICIC), Lahore, Pakistan, 1–2 November 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, W.; He, F.; Zhao, Q. Facial ethnicity classification with deep convolutional neural networks. In Proceedings of the 11th Chinese Conference, CCBR 2016, Chengdu, China, 14–16 October 2016; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 176–185. [Google Scholar]
- Chirco, P.; Buchanan, T.M. Dark faces in white spaces: The effects of skin tone, race, ethnicity, and intergroup preferences on interpersonal judgments and voting behavior. Anal. Soc. Issues Public Policy 2022, 22, 427–447. [Google Scholar] [CrossRef]
- Greco, A.; Percannella, G.; Vento, M.; Vigilante, V. Benchmarking deep network architectures for ethnicity recognition using a new large face dataset. Mach. Vis. Appl. 2020, 31, 67. [Google Scholar] [CrossRef]
- SteelFisher, G.K.; Findling, M.G.; Bleich, S.N.; Casey, L.S.; Blendon, R.J.; Benson, J.M.; Sayde, J.M.; Miller, C. Gender discrimination in the United States: Experiences of women. Health Serv. Res. 2019, 54, 1442–1453. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Deshpande, K.V.; Pan, S.; Foulds, J.R. Mitigating Demographic Bias in AI-based Resume Filtering. In Proceedings of the Adjunct Publication of the 28th ACM Conference on User Modeling, Adaptation and Personalization, Genoa, Italy, 14–17 July 2020; pp. 268–275. [Google Scholar]
- Khan, K.; Khan, R.U.; Ali, J.; Uddin, I.; Khan, S.; Roh, B.H. Race classification using deep learning. Comput. Mater. Contin. 2021, 68, 3483–3498. [Google Scholar] [CrossRef]
- Vicente-Samper, J.M.; Vila-Navarro, E.; Sabater-Navarro, J.M. Data acquisition devices towards a system for monitoring sensory processing disorders. IEEE Access 2020, 8, 183596–183605. [Google Scholar] [CrossRef]
- Rawan, B.; Bibi, N. Construction of Advertisements in Pakistan: How far Television Commercials Conform to Social Values and Professional Code of Conduct? Glob. Reg. Rev. 2019, IV, 22–31. [Google Scholar] [CrossRef]
- Chitale, V.S.; Sciences, M. A Novel Indexing Method Using Hierarchical Classification for Face-Image. Doctoral Dissertation, Auckland University of Technology, Auckland, New Zealand, 2020. [Google Scholar]
- Sajid, M.; Shafique, T.; Manzoor, S.; Iqbal, F.; Talal, H.; Samad Qureshi, U.; Riaz, I. Demographic-assisted age-invariant face recognition and retrieval. Symmetry 2018, 10, 148. [Google Scholar] [CrossRef] [Green Version]
- Fuad, M.T.H.; Fime, A.A.; Sikder, D.; Iftee, M.A.R.; Rabbi, J.; Al-Rakhami, M.S.; Gumaei, A.; Sen, O.; Fuad, M.; Islam, M.N. Recent advances in deep learning techniques for face recognition. IEEE Access 2021, 9, 99112–99142. [Google Scholar] [CrossRef]
- Saragih, R.E.; To, Q.H. A Survey of Face Recognition based on Convolutional Neural Network. Indones. J. Inf. Syst. 2022, 4, 122–139. [Google Scholar]
- Albdairi, A.J.A.; Xiao, Z.; Alghaili, M.; Huang, C. Identifying Ethnics of People through Face Recognition: A Deep CNN Approach. Sci. Program. 2020, 2020, 6385281. [Google Scholar] [CrossRef]
- Agbo-Ajala, O.; Viriri, S. Deeply Learned Classifiers for Age and Gender Predictions of Unfiltered Faces. Sci. World J. 2020, 2020, 1289408. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Khan, K.; Attique, M.; Khan, R.U.; Syed, I.; Chung, T.S. A multi-task framework for facial attributes classification through end-to-end face parsing and deep convolutional neural networks. Sensors 2020, 20, 328. [Google Scholar] [CrossRef] [Green Version]
- Angulu, R.; Tapamo, J.R.; Adewumi, A.O. Age estimation via face images: A survey, 2018, no. 1. EURASIP J. Image Video Process. 2018, 2018, 42. [Google Scholar] [CrossRef] [Green Version]
- Ngan, M.; Grother, P. Face Recognition Vendor Test (FRVT)—Performance of Automated Gender Classification Algorithms; US Department of Commerce, National Institute of Standards and Technology: Gaithersburg, MD, USA, 2015. [Google Scholar]
- Atallah, R.R.; Kamsin, A.; Ismail, M.A.; Abdelrahman, S.A.; Zerdoumi, S. Face Recognition and Age Estimation Implications of Changes in Facial Features: A Critical Review Study. IEEE Access 2018, 6, 28290–28304. [Google Scholar] [CrossRef]
- Terhörst, P.; Kolf, J.N.; Damer, N.; Kirchbuchner, F.; Kuijper, A. Post-comparison mitigation of demographic bias in face recognition using fair score normalization. Pattern Recognit. Lett. 2020, 140, 332–338. [Google Scholar] [CrossRef]
- Kärkkäinen, K.; Joo, J. FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age. arXiv 2019, arXiv:1908.04913. [Google Scholar]
- Vo, T.; Nguyen, T.; Le, C.T. Race recognition using deep convolutional neural networks. Symmetry 2018, 10, 564. [Google Scholar] [CrossRef] [Green Version]
- Mustapha, M.F.; Mohamad, N.M.; Osman, G.; Hamid, S.H.A. Age group classification using Convolutional Neural Network (CNN). J. Phys. Conf. Ser. 2021, 2084, 012028. [Google Scholar] [CrossRef]
- Ahmed, M.A.; Choudhury, R.D.; Kashyap, K. Race estimation with deep networks. J. King Saud Univ.-Comput. Inf. Sci. 2020, 34, 4579–4591. [Google Scholar] [CrossRef]
- Badrulhisham, N.A.S.; Mangshor, N.N.A. Emotion Recognition Using Convolutional Neural Network (CNN). J. Phys. Conf. Ser. 2021, 1962, 1748–1765. [Google Scholar] [CrossRef]
- Meenakshi, S.; Jothi, M.S.; Murugan, D. Face recognition using deep neural network across variationsin pose and illumination. Int. J. Recent Technol. Eng. 2019, 8, 289–292. [Google Scholar]
- Boussaad, L.; Boucetta, A. An effective component-based age-invariant face recognition using Discriminant Correlation Analysis. J. King Saud Univ.-Comput. Inf. Sci. 2020, 34, 1739–1747. [Google Scholar] [CrossRef]
- Sharmila; Sharma, R.; Kumar, D.; Puranik, V.; Gautham, K. Performance Analysis of Human Face Recognition Techniques. In Proceedings of the 2019 4th International Conference on Internet of Things: Smart Innovation and Usages (IoT-SIU), Ghaziabad, India, 18–19 April 2019; pp. 1–4. [Google Scholar]
- Rubeena; Kavitha, E. Sketch face Recognition using Deep Learning. In Proceedings of the2021 5th International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 2–4 December 2021; Volume 1, pp. 928–930. [Google Scholar]
- Sun, H.; Grishman, R. Lexicalized dependency paths based supervised learning for relation extraction. Comput. Syst. Sci. Eng. 2022, 43, 861–870. [Google Scholar] [CrossRef]
- Sun, H.; Grishman, R. Employing lexicalized dependency paths for active learning of relation extraction. Intell. Autom. Soft Comput. 2022, 34, 1415–1423. [Google Scholar] [CrossRef]
- Rahim, A.; Zhong, Y.; Ahmad, T. A Deep Learning-Based Intelligent Face Recognition Method in the Internet of Home Things for Security Applications. J. Hunan Univ. (Nat. Sci.) 2022, 49, 10. [Google Scholar] [CrossRef]
- Mohammad, A.S.; Al-Ani, J.A. Towards ethnicity detection using learning based classifiers. In Proceedings of the 2017 9th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 27–29 September 2017; pp. 219–224. [Google Scholar] [CrossRef]
- Mohammad, A.S.; Al-Ani, J.A. Convolutional Neural Network for Ethnicity Classification using Ocular Region in Mobile Environment. In Proceedings of the 2018 10th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 19–21 September 2018; pp. 293–298. [Google Scholar] [CrossRef]


























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Dataset | Techniques | Accuracy |
|---|---|---|---|
| [2] | FERET | CNN | 75% |
| [36] | FERET | Learning-based Classifiers | 88% |
| [37] | FERET | CNN | 82% |
| Experiment no | Training Set (50%) | Validation Set (25%) | Test Set (25%) |
|---|---|---|---|
| 1 | 1355 images | 677 images | 677 images |
| 2 | 4110 images | 2055 images | 2055 images |
| 3 | 171 images | 85 images | 85 images |
| Fold | Training Accuracy | Testing Accuracy |
|---|---|---|
| 1 | 0.82 | 0.80 |
| 2 | 0.84 | 0.81 |
| 3 | 0.81 | 0.79 |
| 4 | 0.83 | 0.82 |
| 5 | 0.85 | 0.83 |
| 6 | 0.82 | 0.80 |
| 7 | 0.80 | 0.78 |
| 8 | 0.83 | 0.82 |
| 9 | 0.85 | 0.83 |
| 10 | 0.81 | 0.79 |
| Average | 0.82 | 0.80 |
| Fold | Training Accuracy | Testing Accuracy |
|---|---|---|
| 1 | 0.75 | 0.72 |
| 2 | 0.74 | 0.71 |
| 3 | 0.72 | 0.70 |
| 4 | 0.73 | 0.70 |
| 5 | 0.75 | 0.72 |
| 6 | 0.73 | 0.70 |
| 7 | 0.71 | 0.68 |
| 8 | 0.74 | 0.71 |
| 9 | 0.76 | 0.73 |
| 10 | 0.72 | 0.69 |
| Average | 0.73 | 0.70 |
| Model | Dataset | Augmentation Strategies | Training Accuracy | Testing Accuracy | Training Loss | Testing Loss |
|---|---|---|---|---|---|---|
| Model 1 | Dataset 1 | Without Augmentation | 0.82 | 0.80 | 0.34 | 0.37 |
| Model 1 | Dataset 1 | With Augmentation | 0.86 | 0.84 | 0.20 | 0.23 |
| Model 2 | Dataset 1 | Without Augmentation | 0.72 | 0.70 | 0.80 | 0.75 |
| Model 2 | Dataset 1 | With Augmentation | 0.74 | 0.72 | 0.68 | 0.71 |
| Model 1 | Dataset 2 | Without Augmentation | 0.72 | 0.75 | 0.20 | 0.40 |
| Model 1 | Dataset 2 | With Augmentation | 0.75 | 0.77 | 0.18 | 0.35 |
| Model 2 | Dataset 2 | Without Augmentation | 0.72 | 0.75 | 0.20 | 0.30 |
| Model 2 | Dataset 2 | With Augmentation | 0.75 | 0.78 | 0.15 | 0.27 |
| References | Techniques | Dataset | Accuracy |
|---|---|---|---|
| [32] | CNN | MORPH | 69% |
| [33] | Deep Neural Network | FERET | 70% |
| [34] | CNN | MORPH | 71.3% |
| [35] | CNN | MORPH | 70.89% |
| [36] | Learning-based Classifiers | FERET | 88% |
| [37] | CNN | FERET | 82% |
| [39] | Learning-based classifiers | FERET | 85% |
| [40] | CNN | FERET | 0.68 gain |
| This proposed model | Model ACNN Model BCNN | MORPH, FERET | 85%, 86% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abdulwahid, A.A. Classification of Ethnicity Using Efficient CNN Models on MORPH and FERET Datasets Based on Face Biometrics. Appl. Sci. 2023, 13, 7288. https://doi.org/10.3390/app13127288
Abdulwahid AA. Classification of Ethnicity Using Efficient CNN Models on MORPH and FERET Datasets Based on Face Biometrics. Applied Sciences. 2023; 13(12):7288. https://doi.org/10.3390/app13127288
Chicago/Turabian StyleAbdulwahid, Abdulwahid Al. 2023. "Classification of Ethnicity Using Efficient CNN Models on MORPH and FERET Datasets Based on Face Biometrics" Applied Sciences 13, no. 12: 7288. https://doi.org/10.3390/app13127288