


Social Media Opinion Analysis Model Based on Fusion of Text and Structural Features

Abstract
:1. Introduction
- Given the special nature of Chinese short texts, a method of extracting features from the comment structure to modify text vectors was adopted in order to achieve more accurate vector mappings. To improve the classification accuracy of sentiment orientation for Chinese short texts, we combined the dynamic comment representation vectors generated by the text vectorization model with features of the comment network structure.
- In response to the heterogeneity of the comment structure network (the sentiment orientation expressed by comments with reply relationships is often opposite), in this paper, we proposed the HGAT model for efficient feature fusion, and we also incorporated an attention mechanism to aid in feature embedding. The proposed model can further improve text features, and even with a relatively simple classifier, it can obtain good prediction results for the sentiment orientation of the comments.
- For the proposed HGAT model, a Toutiao dataset is proposed in this paper, and it is verified on the Toutiao dataset that the model in this paper performs better on the dataset of Toutiao compared to the text-only classification method and the graph embedding method based on isomorphism network.
2. Related Work
2.1. Opinion Tendency Recognition
2.2. Opinion Conflict Detection
2.3. Graph Embedding
3. Proposed HGAT Model
- Word Embedding Layer: The text of the comment is tokenized and fed into a pre-trained text vectorization model using the corresponding phrase table. In this case, The input text is the text from the training set news, and the initial vector representations of all comment phrases and news content are obtained based on the output of the model after secondary training;
- Inputting Layer: The feature vectors of the text obtained from the previous layer are combined with the social media commentary network, and text feature vectors are used as input to node features;
- Encoding Layer: Training is carried out on the structure of each news story. The attention mechanism is used to merge the features of each neighbor node of the comment node at various levels with the node’s own features, and the feature vector of the comment node is changed accordingly;
- Output Layer: Given the output vector of the previous layer, the polarity category of the predicted opinion is obtained via the softmax function.
3.1. Word Embedding Layer
3.2. Input Layer
3.3. Encoding Layer
3.4. Output Layer
4. Experimental Section
4.1. Datasets and Evaluation Metric
4.2. Baseline Method
4.3. Model Parameter Setting
4.4. Comparison of Experimental Results
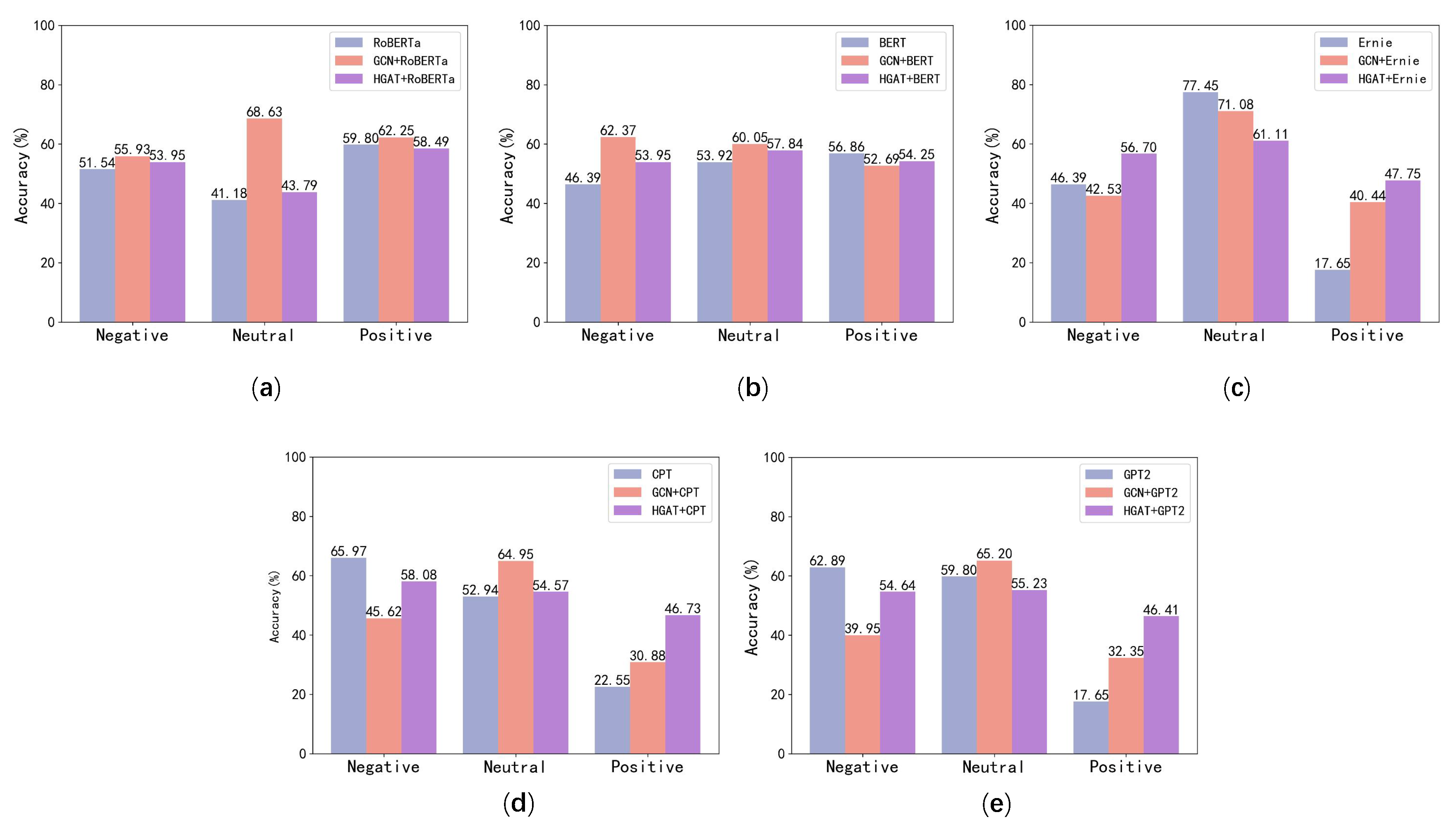
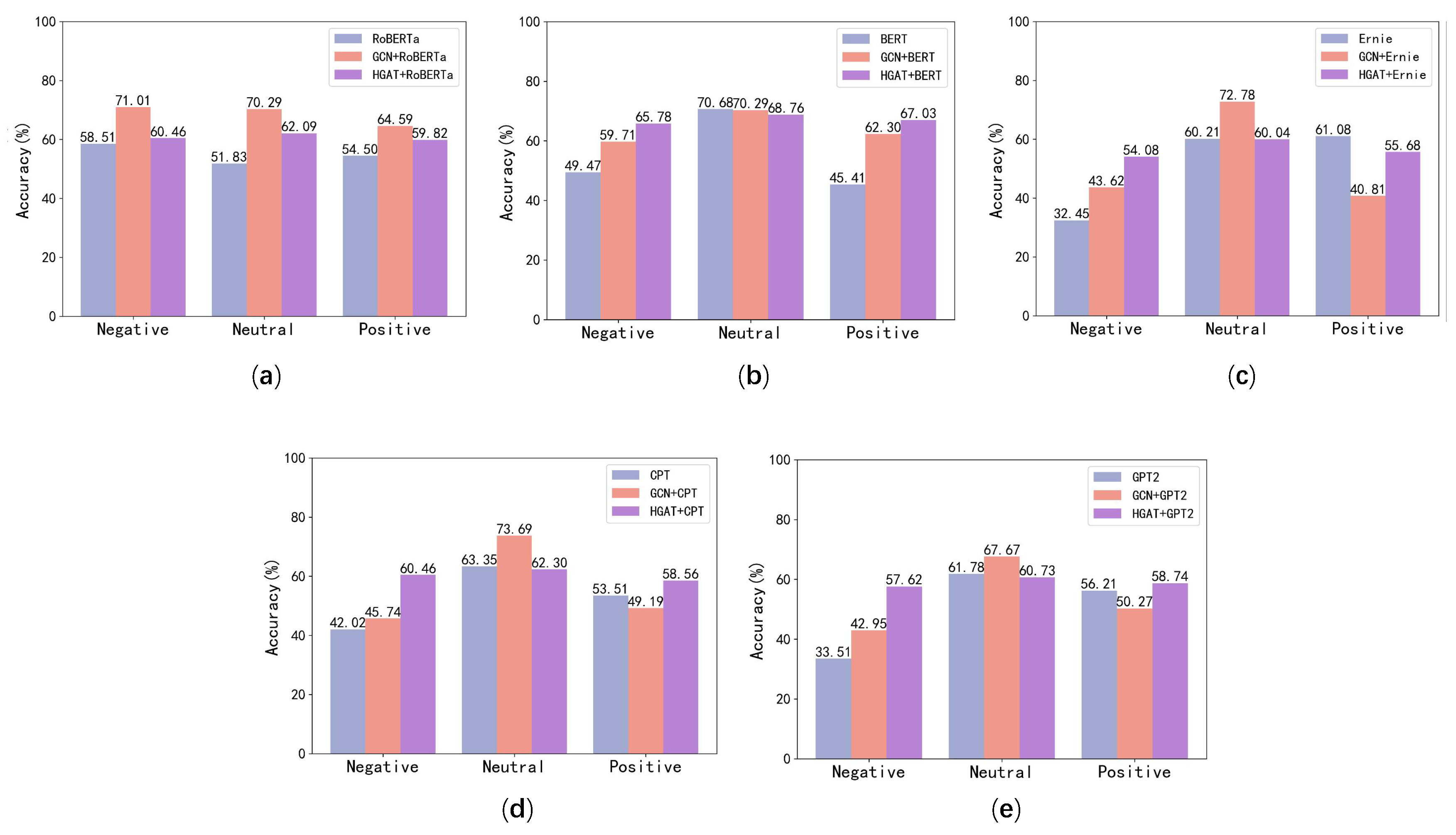
- On both the Toutiao#1 and Toutiao#2 datasets, the text and structural feature combination method proposed in this paper performs better than the original text vectorisation algorithm, which states that the algorithm proposed in this paper, which optimizes and updates the text vectors based on the structural characteristics of the network, has some effect.
- The HGAT + BERT model proposed in this paper outperforms all text vectorization methods as well as all structure-based algorithms on both datasets.
- On the Toutiao#1 dataset, the HGAT proposed in this paper has a slightly weaker effect than the GCN, which could be because there are more neutral comments in the structure of the network. This paper’s model uses graph embeddings of heterogeneous networks to update node vectors, as shown in Figure 4 and Figure 5, but responses to neutral feedback are often still neutral feedback, making prediction of neutral feedback vectors slightly worse for HGAT than for GCN.
- For the most part, the model that combines HGAT and text vectorization has better accuracy in identifying both positive and negative reviews than the model that combines GCN and text vectorization, and also has a larger improvement over the text vectorization methods.
- The combination model of GCN and text vectorisation has an advantage in terms of identifying neutral comments. We believe this is due to the fact that the context of neutral comments often involves neutral comments in response comments, thus, the node homogeneity-based GCN method has an advantage for identifying neutral comments.
- The GCN and text vectorization combination models are relatively unstable, and their accuracy is greatly impacted by the text vectorization. Of these, in the Toutiao#1 dataset, based on the CPT vectorisation method, the GCN + CPT model even had an accuracy of around 20% lower in the identification of negative comments when compared to the original method. The proposed HGAT model in this paper has better stability than the GCN model. The reason for the improvement, in our view, is that the HGAT model introduces attention mechanisms, which may better quantify the influence of neighbouring nodes on the current one. Furthermore, the network heterogeneity-based model is best suited to environments with extreme opinion polarization in social networks.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Conover, M.; Ratkiewicz, J.; Francisco, M.; Goncalves, B.; Menczer, F. Political Polarization on Twitter. In Proceedings of the International AAAI Conference on Web and Social Media, Barcelona, Spain, 17–21 July 2011. [Google Scholar]
- Linden, S.; Roozenbeek, J.; Compton, J. Inoculating against fake news about COVID-19. Front. Psychol. 2020, 11, 566790. [Google Scholar] [CrossRef] [PubMed]
- Sharma, K.; Feng, Q.; He, J.; Ruchansky, N.; Liu, Y. Combating Fake News: A Survey on Identification and Mitigation Techniques. ACM Trans. Intell. Syst. Technol. 2019, 10, 1–42. [Google Scholar] [CrossRef]
- Vicario, M.; Vivaldo, G.; Bessi, A.; Zollo, F.; Quattrociocchi, W. Echo Chambers: Emotional Contagion and Group Polarization on Facebook. Sci. Rep. 2016, 6, 37825. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Xu, H.; Su, Z.; Xu, Y. Chinese comments sentiment classification based on word2vec and SVMperf. Expert Syst. Appl. 2015, 42, 1857–1863. [Google Scholar] [CrossRef]
- Qiao, Q.; Bo, T.; Huang, M.; Yang, L.; Zhu, X. Learning Tag Embeddings and Tag-specific Composition Functions in Recursive Neural Network. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; Volume 1: Long Papers. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph Convolution over Pruned Dependency Trees Improves Relation Extraction. arXiv 2018, arXiv:1809.10185. [Google Scholar]
- Bouchlaghem, R.; Elkhelifi, A.; Faiz, R. SVM based approach for opinion classification in Arabic written tweets. In Proceedings of the 2015 IEEE/ACS 12th International Conference of Computer Systems and Applications (AICCSA), Marrakech, Morocco, 17–20 November 2015. [Google Scholar]
- Es-Sabery, F.; Es-Sabery, K.; Qadir, J.; Sainz-De-Abajo, B.; Torre-Diez, I. A MapReduce Opinion Mining for COVID-19-Related Tweets Classification Using Enhanced ID3 Decision Tree Classifier. IEEE Access 2021, 9, 58706–58739. [Google Scholar] [CrossRef]
- Sanjay, K.S.; Danti, A. Detection of fake opinions on online products using Decision Tree and Information Gain. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019. [Google Scholar]
- Wan, W.; Xiao, Z.; Liu, X.; Wei, C.; Wang, T. pkudblab at SemEval-2016 Task 6: A Specific Convolutional Neural Network System for Effective Stance Detection. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016. [Google Scholar]
- Du, J.; Xu, R.; He, Y.; Lin, G. Stance Classification with Target-specific Neural Attention. In Proceedings of the 26th International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017. [Google Scholar]
- Zhou, Y.; Cristea, A.I.; Shi, L. Connecting Targets to Tweets: Semantic Attention-Based Model for Target-Specific Stance Detection. In Lecture Notes in Computer Science, Proceedings of the Web Information Systems Engineering—WISE 2017—18th International Conference, Puschino, Russia, 7–11 October 2017, Proceedings, Part I; Bouguettaya, A., Gao, Y., Klimenko, A., Chen, L., Zhang, X., Dzerzhinskiy, F., Jia, W., Klimenko, S.V., Li, Q., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10569, pp. 18–32. [Google Scholar]
- Augenstein, I.; Rocktäschel, T.; Vlachos, A.; Bontcheva, K. Stance Detection with Bidirectional Conditional Encoding. arXiv 2016, arXiv:1606.05464. [Google Scholar]
- Siddiqua, U.A.; Chy, A.N.; Aono, M. Tweet Stance Detection Using an Attention based Neural Ensemble Model. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT 2019), Minneapolis, MO, USA, 2–7 June 2019; Long and Short Papers; Association for Computational Linguistics: Minneapolis, MO, USA, 2019; Volume 1. [Google Scholar]
- Mohtarami, M.; Baly, R.; Glass, J.R.; Nakov, P.; Moschitti, A. Automatic Stance Detection Using End-to-End Memory Networks. arXiv 2018, arXiv:1804.07581. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Ghosh, S.; Singhania, P.; Singh, S.; Rudra, K.; Ghosh, S. Stance Detection in Web and Social Media: A Comparative Study. In Experimental IR Meets Multilinguality, Multimodality, and Interaction: Proceedings of the 10th International Conference of the CLEF Association, CLEF 2019, Lugano, Switzerland, 9–12 September 2019, Proceedings 10; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Li, Y.; Caragea, C. Target-Aware Data Augmentation for Stance Detection. In Proceedings of the Association for Computational Linguistics 2021, Virtual, 1–6 August 2021; pp. 1850–1860. [Google Scholar]
- Xu, G.; Yu, Z.; Yao, H.; Li, F.; Meng, Y.; Wu, X. Chinese Text Sentiment Analysis Based on Extended Sentiment Dictionary. IEEE Access 2019, 7, 43749–43762. [Google Scholar] [CrossRef]
- Li, G.; Zheng, Q.; Zhang, L.; Guo, S.; Niu, L. Sentiment Infomation based Model For Chinese text Sentiment Analysis. In Proceedings of the 2020 IEEE 3rd International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 20–22 November 2020; pp. 366–371. [Google Scholar] [CrossRef]
- Sheng, D.; Yuan, J. An Efficient Long Chinese Text Sentiment Analysis Method Using BERT-Based Models with BiGRU. In Proceedings of the 2021 IEEE 24th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Dalian, China, 5–7 May 2021; pp. 192–197. [Google Scholar] [CrossRef]
- Garimella, K.; Morales, G.D.; Gionis, A.; Mathioudakis, M. Quantifying Controversy on Social Media. ACM Trans. Soc. Comput. 2018, 1, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Coletto, M.; Garimella, K.; Gionis, A.; Lucchese, C. Automatic controversy detection in social media: A content-independent motif-based approach. Online Soc. Netw. Media 2017, 3–4, 22–31. [Google Scholar] [CrossRef]
- Zhong, L.; Cao, J.; Sheng, Q.; Guo, J.; Wang, Z. Integrating Semantic and Structural Information with Graph Convolutional Network for Controversy Detection. arXiv 2020, arXiv:2005.07886. [Google Scholar]
- Perozzi, B.; Al-Rfou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Kai, C.; Corrado, G.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Red Hook, NY, USA, 2013. [Google Scholar]
- Grover, A.; Leskovec, J. node2vec: Scalable Feature Learning for Networks. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 13–17 August 2016. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Li, Q.; Shang, Y.; Qiao, X.; Dai, W. Heterogeneous Dynamic Graph Attention Network. In Proceedings of the 2020 IEEE International Conference on Knowledge Graph (ICKG), Nanjing, China, 9–11 August 2020. [Google Scholar]
- Zhu, J.; Yan, Y.; Zhao, L.; Koutra, D. Beyond Homophily in Graph Neural Networks: Current Limitations and Effective Designs. Adv. Neural Inf. Process. Syst. 2020, 33, 7793–7804. [Google Scholar]
- Fu, C.; Zheng, Y.; Liu, Y.; Xuan, Q.; Chen, G. NES-TL: Network Embedding Similarity-Based Transfer Learning. IEEE Trans. Netw. Sci. Eng. 2020, 7, 1607–1618. [Google Scholar] [CrossRef]
- Datatang|StopWordsSet. Available online: http://www.datatang.com/data/19300 (accessed on 18 March 2021).
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Wu, H. ERNIE: Enhanced Representation through Knowledge Integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Shao, Y.; Geng, Z.; Liu, Y.; Dai, J.; Yang, F.; Zhe, L.; Bao, H.; Qiu, X. CPT: A Pre-Trained Unbalanced Transformer for Both Chinese Language Understanding and Generation. arXiv 2021, arXiv:2109.05729. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Toutiao | Toutiao#1 | Toutiao#2 | |
|---|---|---|---|
| Number of news | 511 | 11 | 11 |
| Number of users | 71,579 | 3496 | 5940 |
| Number of comments | 103,787 | 5570 | 10,580 |
| Positive comments | 54,994 | 2224 | 3622 |
| Neutral comments | 23,236 | 1647 | 4095 |
| Negative comments | 25,557 | 1699 | 2863 |
| Data Set | Toutiao#1 | Toutiao#2 | ||||
|---|---|---|---|---|---|---|
| Positive | Neutral | Negative | Positive | Neutral | Negative | |
| Training set | 904 | 899 | 899 | 1689 | 1689 | 1692 |
| Test set | 97 | 102 | 102 | 188 | 191 | 185 |
| Model | Toutiao#1 | Toutiao#2 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Acc. (%) | Pre. (%) | Rec. (%) | F1 (%) | Acc. (%) | Pre. (%) | Rec. (%) | F1 (%) | ||
| NLP-based | Roberta | 50.83 ± 0.06 | 51.15 ± 0.60 | 50.84 ± 0.07 | 50.55 ± 0.05 | 54.96 ± 0.51 | 54.99 ± 0.44 | 54.98 ± 0.50 | 54.94 ± 0.69 |
| Bert | 52.49 ± 0.20 | 52.77 ± 2.07 | 52.39 ± 0.22 | 52.38 ± 0.99 | 55.32 ± 0.70 | 55.27 ± 1.13 | 55.18 ± 0.71 | 54.72 ± 0.81 | |
| Ernie | 47.17 ± 0.66 | 48.70 ± 0.33 | 47.16 ± 0.60 | 43.83 ± 0.82 | 51.24 ± 0.81 | 52.15 ± 1.07 | 51.25 ± 0.82 | 50.34 ± 1.28 | |
| CPT | 46.51 ± 0.66 | 46.73 ± 1.15 | 46.78 ± 0.62 | 43.80 ± 0.45 | 50.53 ± 0.20 | 50.38 ± 1.63 | 50.50 ± 0.35 | 49.70 ± 1.60 | |
| GPT2 | 46.84 ± 0.60 | 47.77 ± 0.49 | 47.16 ± 0.65 | 44.95 ± 0.79 | 53.01 ± 1.78 | 53.08 ± 1.86 | 52.96 ± 1.14 | 52.63 ± 0.94 | |
| Structure-based | HGAT + ones | 44.43 ± 3.58 | 48.03 ± 7.56 | 44.68 ± 3.65 | 42.07 ± 5.16 | 48.23 ± 1.93 | 48.36 ± 2.00 | 48.28 ± 1.93 | 48.16 ± 1.94 |
| GCN + ones | 53.15 ± 1.16 | 55.18 ± 1.48 | 53.32 ± 1.21 | 52.61 ± 1.28 | 66.49 ± 1.00 | 67.34 ± 0.32 | 66.46 ± 0.91 | 66.32 ± 0.91 | |
| Combined | GCN + Bert | 58.31 ± 1.17 1 | 59.39 ± 1.48 1 | 58.37 ± 1.39 1 | 58.38 ± 1.28 1 | 64.14 ± 0.84 | 64.82 ± 0.32 | 64.09 ± 0.90 | 64.00 ± 0.91 |
| HGAT + Bert | 55.82 ± 1.48 | 56.04 ± 1.45 | 55.79 ± 1.46 | 55.84 ± 1.46 | 67.20 ± 0.82 1 | 67.38 ± 0.88 1 | 67.19 ± 0.82 1 | 67.22 ± 0.83 1 | |
| Model | Toutiao#1 | Toutiao#2 | ||||||
|---|---|---|---|---|---|---|---|---|
| Acc. (%) | Pre. (%) | Rec. (%) | F1 (%) | Acc. (%) | Pre. (%) | Rec. (%) | F1 (%) | |
| Bert | 52.49 ± 0.20 | 52.77 ± 2.07 | 52.39 ± 0.22 | 52.38 ± 0.99 | 55.32 ± 0.70 | 55.27 ± 1.13 | 55.18 ± 0.71 | 54.72 ± 0.81 |
| GCN + BERT | 58.31 ± 1.32 1 | 59.39 ± 1.12 1 | 58.37 ± 1.36 1 | 58.38 ± 1.34 1 | 64.14 ± 0.64 | 64.82 ± 0.36 | 64.09 ± 0.68 | 64.00 ± 0.73 |
| HGAT + BERT | 55.82 ± 1.48 | 56.04 ± 1.45 | 55.79 ± 1.46 | 55.84 ± 1.46 | 67.20 ± 0.82 1 | 67.38 ± 0.88 1 | 67.19 ± 0.82 1 | 67.22 ± 0.83 1 |
| Roberta | 50.83 ± 0.06 | 51.15 ± 0.60 | 50.84 ± 0.07 | 50.55 ± 0.05 | 54.96 ± 0.51 | 54.99 ± 0.44 | 54.98 ± 0.50 | 54.94 ± 0.69 |
| GCN + Roberta | 62.37 ± 3.10 1 | 64.67 ± 2.04 1 | 62.27 ± 3.07 1 | 62.44 ± 3.23 1 | 68.66 ± 0.30 1 | 69.23 ± 0.48 1 | 68.63 ± 0.36 1 | 68.58 ± 0.48 1 |
| HGAT + Roberta | 52.41 ± 1.17 | 52.65 ± 1.24 | 52.44 ± 1.19 | 52.24 ± 1.13 | 61.82 ± 0.48 | 61.89 ± 0.56 | 61.79 ± 0.49 | 61.79 ± 0.52 |
| Ernie | 47.17 ± 0.66 | 48.70 ± 0.33 | 47.16 ± 0.60 | 43.83 ± 0.82 | 51.24 ± 0.81 | 52.15 ± 1.07 | 51.25 ± 0.82 | 50.34 ± 1.28 |
| GCN + Ernie | 51.49 ± 0.70 | 52.44 ± 0.93 | 51.35 ± 0.74 | 50.54 ± 0.97 | 52.57 ± 0.54 | 52.84 ± 0.52 | 52.41 ± 0.51 | 51.49 ± 0.51 |
| HGAT + Ernie | 54.41 ± 3.33 1 | 54.34 ± 3.36 1 | 54.43 ± 3.35 1 | 54.23 ± 3.39 1 | 56.62 ± 0.47 1 | 56.60 ± 0.46 1 | 56.60 ± 0.46 1 | 56.59 ± 0.46 1 |
| CPT | 46.51 ± 0.66 | 46.73 ± 1.15 | 46.78 ± 0.62 | 43.80 ± 0.45 | 50.53 ± 0.20 | 50.38 ± 1.63 | 50.50 ± 0.35 | 49.70 ± 1.60 |
| GCN + CPT | 47.17 ± 2.68 | 52.84 ± 2.92 | 47.15 ± 2.81 | 43.56 ± 4.09 | 56.34 ± 0.57 | 56.91 ± 0.55 | 56.21 ± 0.61 | 55.39 ± 0.45 |
| HGAT + CPT | 52.99 ± 1.20 1 | 53.01 ± 1.05 1 | 53.06 ± 1.18 1 | 52.95 ± 1.22 1 | 60.46 ± 0.95 1 | 60.64 ± 0.92 1 | 60.44 ± 0.94 1 | 60.47 ± 0.92 1 |
| GPT2 | 46.84 ± 0.60 | 47.77 ± 0.49 | 47.16 ± 0.65 | 44.95 ± 0.79 | 53.01 ± 1.78 | 53.08 ± 1.86 | 52.96 ± 1.14 | 52.63 ± 0.94 |
| GCN + GPT2 | 45.93 ± 1.23 | 46.39 ± 1.05 | 45.83 ± 1.25 | 44.53 ± 1.47 | 53.72 ± 0.43 | 53.66 ± 0.46 | 53.63 ± 0.42 | 53.16 ± 0.28 |
| HGAT + GPT2 | 51.24 ± 2.21 1 | 51.28 ± 2.20 1 | 51.30 ± 2.19 1 | 51.16 ± 2.25 1 | 59.04 ± 0.78 1 | 59.09 ± 0.80 1 | 59.03 ± 0.79 1 | 59.05 ± 0.79 1 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Long, J.; Li, Z.; Xuan, Q.; Fu, C.; Peng, S.; Min, Y. Social Media Opinion Analysis Model Based on Fusion of Text and Structural Features. Appl. Sci. 2023, 13, 7221. https://doi.org/10.3390/app13127221
Long J, Li Z, Xuan Q, Fu C, Peng S, Min Y. Social Media Opinion Analysis Model Based on Fusion of Text and Structural Features. Applied Sciences. 2023; 13(12):7221. https://doi.org/10.3390/app13127221
Chicago/Turabian StyleLong, Jie, Zihan Li, Qi Xuan, Chenbo Fu, Songtao Peng, and Yong Min. 2023. "Social Media Opinion Analysis Model Based on Fusion of Text and Structural Features" Applied Sciences 13, no. 12: 7221. https://doi.org/10.3390/app13127221