1. Introduction
With the rapid development of internet finance and big data technology, fundamental and technical analysis forecasting schemes are no longer popular today, because the stock market is highly random and volatile. The price of the financial market especially has been influenced by various factors, and the ambiguity of stock data makes the learning-based process more difficult [
1]. To meet investors’ needs, a greater emphasis on data forecasting in recent years has led to many advances in the neural network [
2].
Deep learning originated from artificial neural networks (ANNs), whose basic framework is to build a multi-layer structure and extract features from the input data for combination to obtain a more abstract data structure. Ivakhnenko et al. developed the first working neural network, which was demonstrated in the computer identification system [
3]. However, the information learning process did not use a backpropagation algorithm for training the network in this model. Later, Rumelhart et al. proposed the error backpropagation algorithm [
4], now known as the BP neural network, which collected the errors generated by the system during the cycle and returns them to the outputs. After that, they applied these errors to adjust the weights of every single neuron, resulting in an artificial neural network. The appearance of BP solved the problem of GMDH, which cannot carry out the backpropagation. Currently, the BP neural network model has penetrated into many cutting-edge fields such as pattern recognition [
5], speech processing [
6], image processing, nonlinear optical [
7], financial data forecasting, etc. Huang et al. used the BP neural network for regional logistics demand forecasting (RLDF) [
8], but BP neural networks have very obvious and fatal drawbacks—low learning efficiency, slow convergence, and a tendency to fall into local minima.
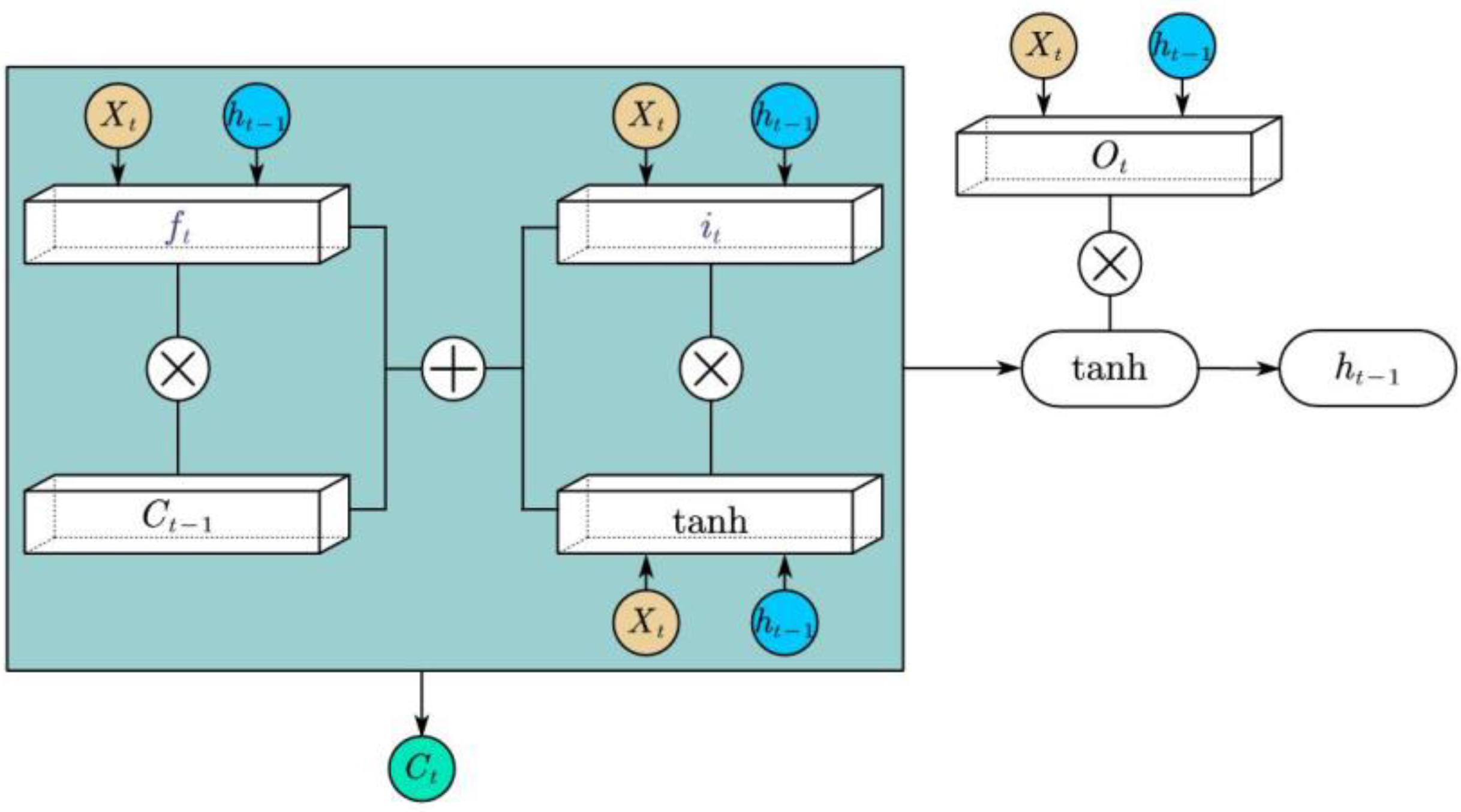
Schmidhuber et al. [
9] elucidated a new recurrent neural network architecture named long short-term memory. This special neural recurrent network could deal with the problem of gradient diffusion and explosion so that it can be used for data modeling of long time series. In 2017, Selvin et al. [
10] compared traditional GARCH models with LSTM to illustrate that LSTM outperforms other previous algorithms. LSTM is a special RNN structure; it is suitable for learning, classifying, processing, and predicting time series from experience, it consists of three gate structures, and each of them can filter the useless information more efficiently to decide which information needs to be used next time or which information needs to be discarded. Both LSTM and gate recurrent unit [
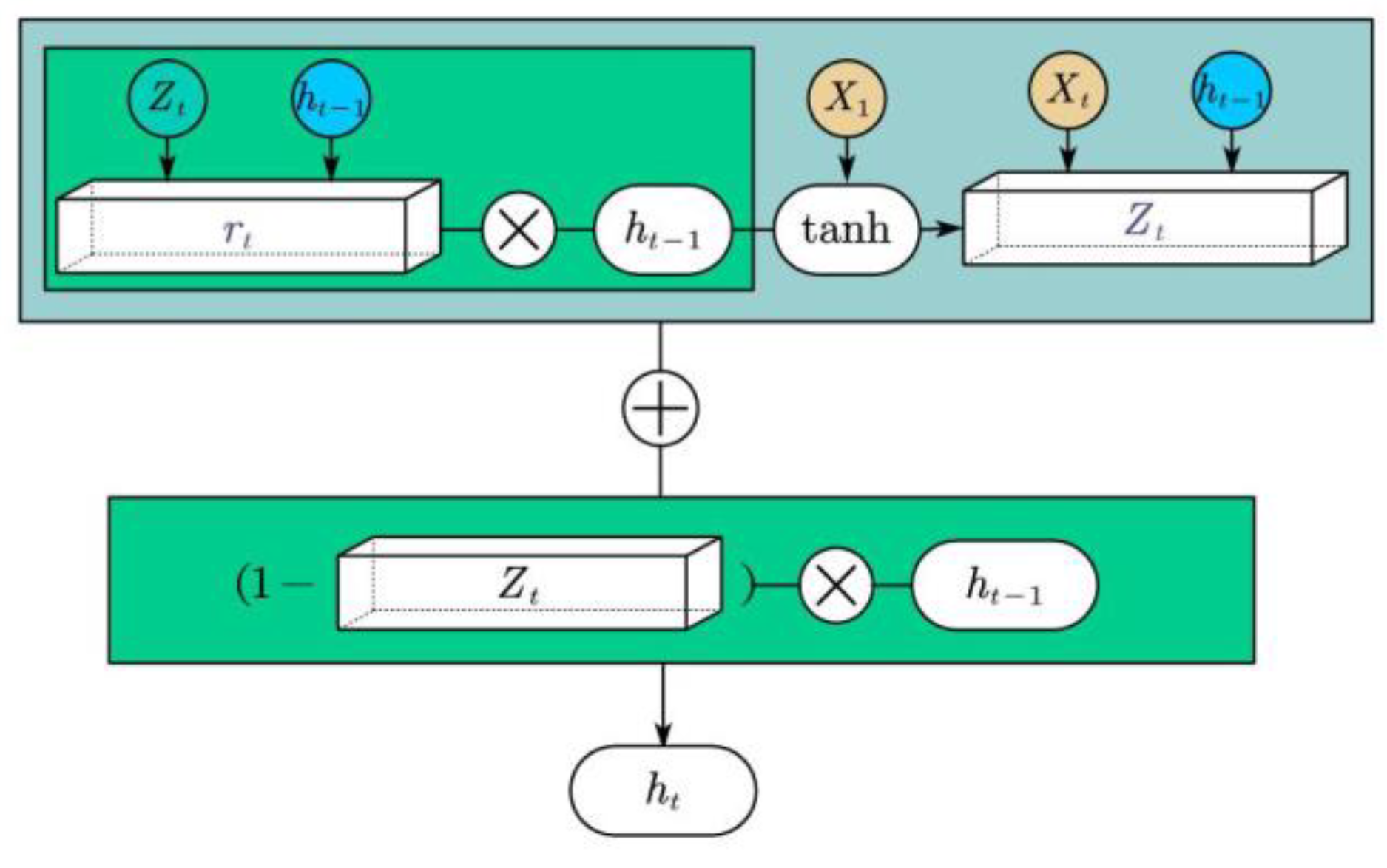
11] (GRU) are variants of RNN, but compared with LSTM, GRU has one less gate structure, fewer parameters, and faster convergence and iteration speed.
However, these neural networks do not take into account the noise of data when making predictions. The initial signal contains noise that is unfavorable to the forecast. To improve the accuracy by continuously optimizing the prediction models, the preprocessing methods of data input are also improved during a series of research. For example, Büyükahin et al. [
12] proved that mode decomposition techniques can reduce signal noise pollution and improve the accuracy of prediction.
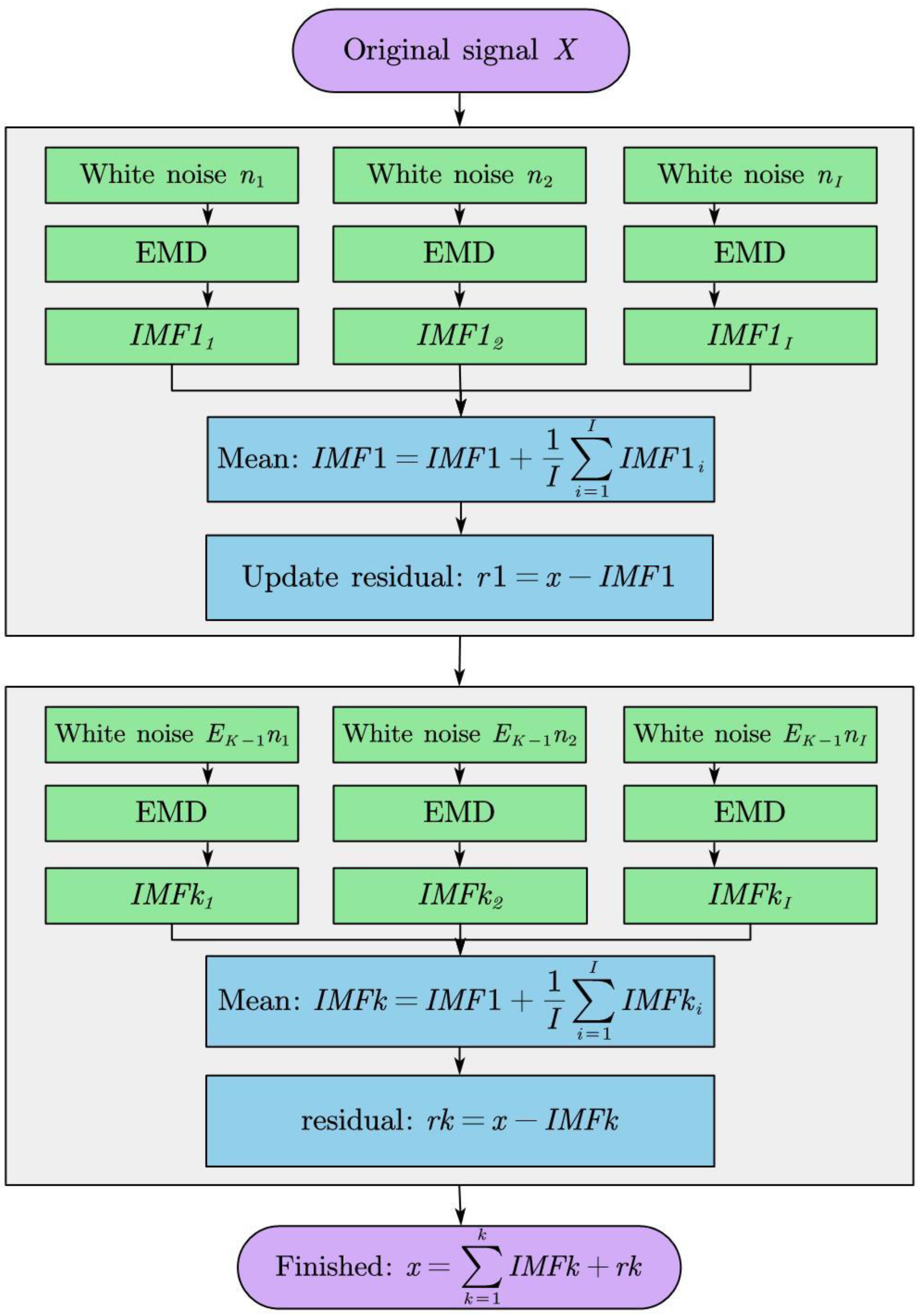
Empirical mode decomposition (EMD) was discovered by Huang et al. [
13] and taken as a new type of adaptive signal time–frequency processing method without requiring any basis functions, which is so different from harmonic function and wavelet basis functions. Theoretically, EMD can be applied to any type of signal decomposition in any field, such as [
14] used to decompose sonar signals in the ocean, and in the medical field, it is used to extract features from electroencephalogram (EEG) signals [
15].
Before EMD, there existed another method called wavelet transform. The concept of wavelet transform was introduced by Morlet, but, unfortunately, this method was not recognized by mathematicians at that time until Meyer accidentally constructed a real wavelet basis and collaborated with Mallat to establish the multi-resolution analysis (MRA) [
16]; since then, wavelet analysis has been generally accepted and flourished.
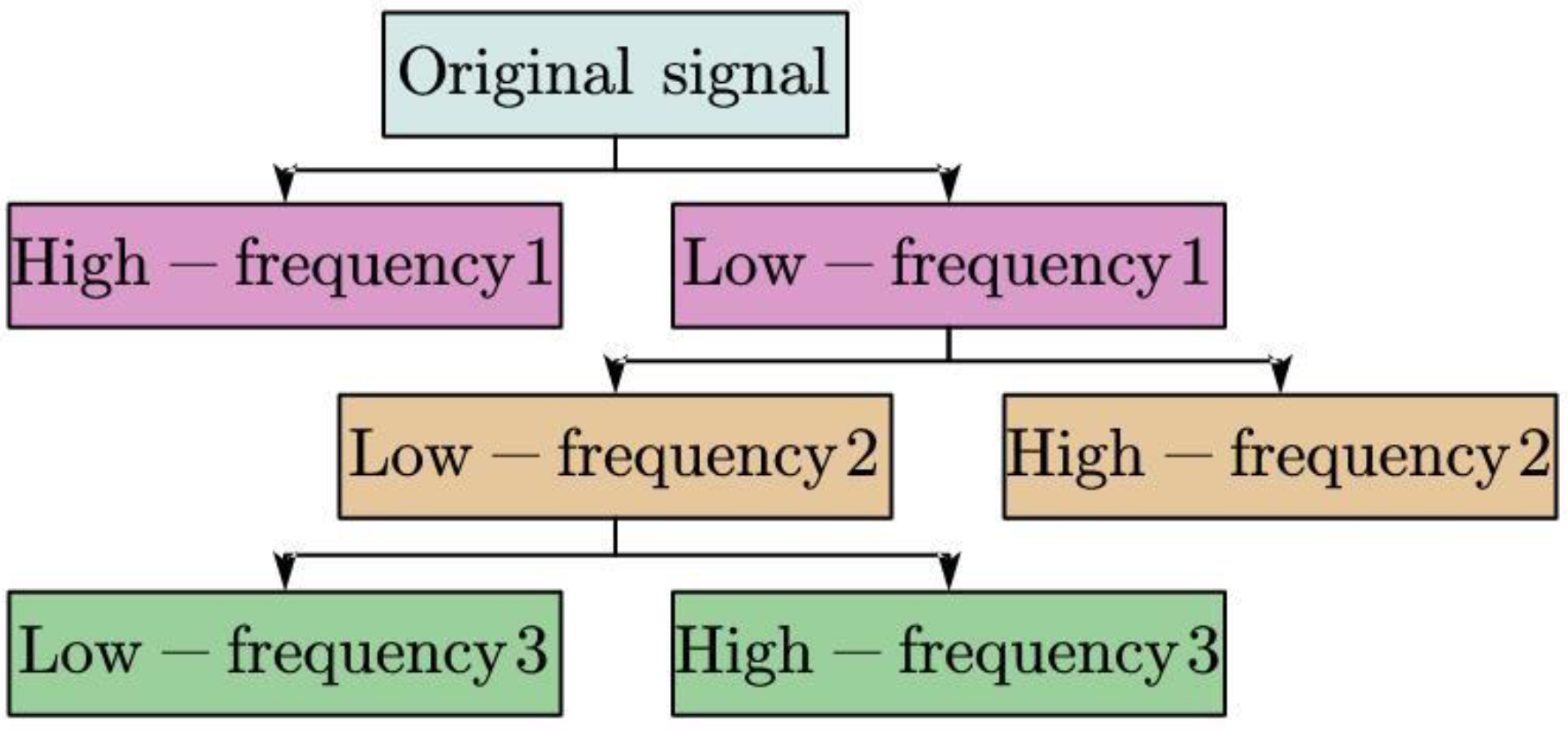
However, the applications of certain single models always have poor forecasting results, such as the ARIMA model, which utilizes only one set of data as input variables. To overcome the limitations of the traditional models, we combine a hybrid model using multi-dimensional variables as input to forecast future data. Firstly, CEEMDAN [
17] is used to decompose the original signal, and then the high-frequency signal is especially denoised by using the wavelet transform function. Finally, the reintegrated signal is put into the GRU neural network for assessment and forecast. The result shows that our framework model has better performance than the extant models.
Compared with traditional methods, deep models have been widely used to predict time series with the following advantages: data-driven, adaptive, as well as a higher ability to analyze inaccurate and noisy data. Deep models can be trained with large amounts of nonlinear data, capturing more abstract nonlinear relationships between data; thus, it was used to solve nonlinear problems more satisfactorily than traditional machine learning algorithms. In recent work of deep models on the field of stock price prediction, Swathi et al. [
18] present a new novel teaching and learning-based optimization (TLBO) model with long short-term memory (LSTM)-based sentiment analysis for stock price prediction using Twitter data. The proposed method produced a greater accuracy. Zhao et al. [
19] proposed a novel hybrid model SA-DLSTM to predict the stock market and simulation trading by combining an emotion-enhanced convolutional neural network, the denoising autoencoder, and LSTM models. SA-DLSTM has a good performance both in return and risk. It can help investors make wise decisions.
As mentioned above, neural computing methods are used in various fields, including data mining, stock prediction, image feature extraction, and so on. However, many scholars use only single historical data for forecasting, resulting in the intrinsic structure and variability of the stock market not being fully considered. Meanwhile, the inappropriate denoising process has caused a part of information loss. Hence, in this paper, we propose a new network architecture based on GRU and CEEMDAN to predict market direction, which collects multidimensional variables and decomposes high-frequency components using the wavelet function to improve prediction accuracy while maximizing information integrity.
This paper is organized as follows.
Section 2 introduces the preliminary work of neural network prediction.
Section 3 describes the design of the GRU neural network based on the CEEMDAN–wavelet.
Section 4 presents the experiment setup and test process, and the results are obtained by comparative experiments.
Section 5 shows the discussion in detail. In
Section 6, the conclusion and future work directions are given.
4. Results
4.1. Experiment Design
To investigate the availability of the proposed methodology on stock market data, the historical data came from the CSI 300 which is a great indicator of stock price movements in Chinese stock price, and the S&P500, which records 500 listed companies’ stocks price indices in the U.S. from 2018 to 2021, are chosen to conduct experiments and predict future closing prices.
Before denoising the stock time series data, because of the large amount of data used and multivariate values divergence, we use normalization to preprocess data to simplify the calculation. The formula is
The choice of threshold is an important factor that directly affects the denoising effect. In this section, after comparing a series of thresholds such as sqtwolog, heursure, and minimax, we choose two different thresholds for the CSI300 and S&P500. The minimax threshold with the best effect is chosen for the CSI300 and the sawlog fixed threshold for the S&P500.
The input data has four variables: opening price, closing price, highest price, and lowest price. The training part contains 80% of the whole history data, and the rest of the 20% data is set as a test part. The maximum number of training rounds is set to 500, and the data are processed using a segmented learning rate strategy.
4.2. Test Process
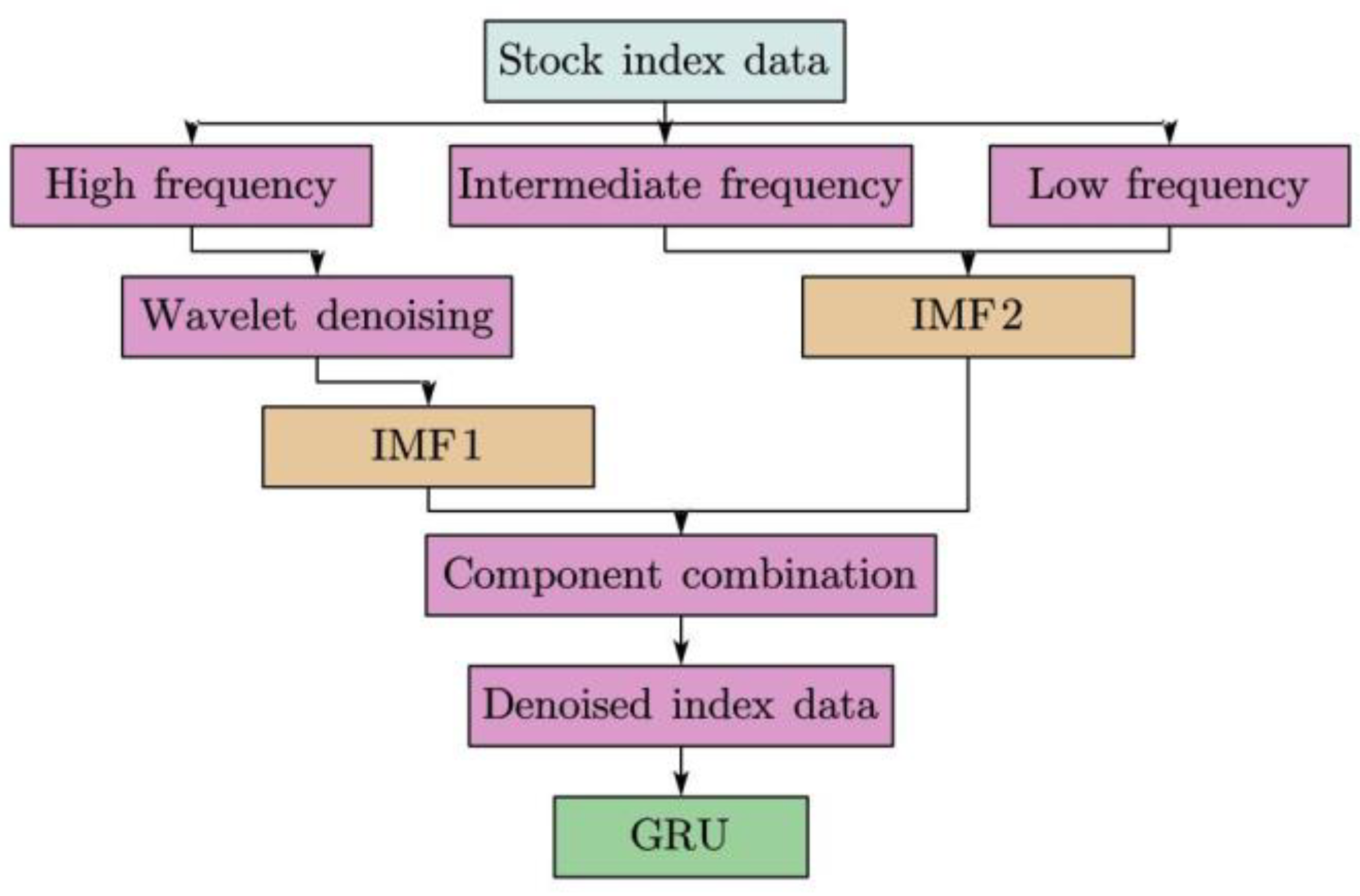
The pre-condition for GRU based on the CEEMDAN–wavelet model is that it has finished its training process. The flow chart is shown in
Figure 6.
The steps are as follows:
Historical data is entered into the model waiting to be used;
Before using data, the input data needs to be standardized according to formula (22);
Noise reduction of data using CEEMDAN, and wavelet threshold denoising method is used for high-frequency components;
The denoised signals are inputted into the trained GRU to get the output value;
Restoring standardized data.
4.3. Comparative Experiments
The aim of this part is to verify the superiority of the proposed model in predicting future data of the stock market. Consequently, a GRU network without wavelet threshold denoising, an LSTM neural network, a traditional ARIMA, a hybrid CNN-BiLSTM, and an ANN model are selected for comparative experiments to highlight the higher prediction accuracy of our framework model.
4.4. Evaluation Method
In order to compare the correctness of each neural network framework structure for prediction results, we choose four common performance measures to evaluate every model’s accuracy objectively, using a data comparison approach to highlight that the proposed model in this paper has higher accuracy.
Root mean square error (
RMSE):
Mean absolute error (
MAE):
Coefficient of determination (
R2):
4.5. Experimental Result and Comparison
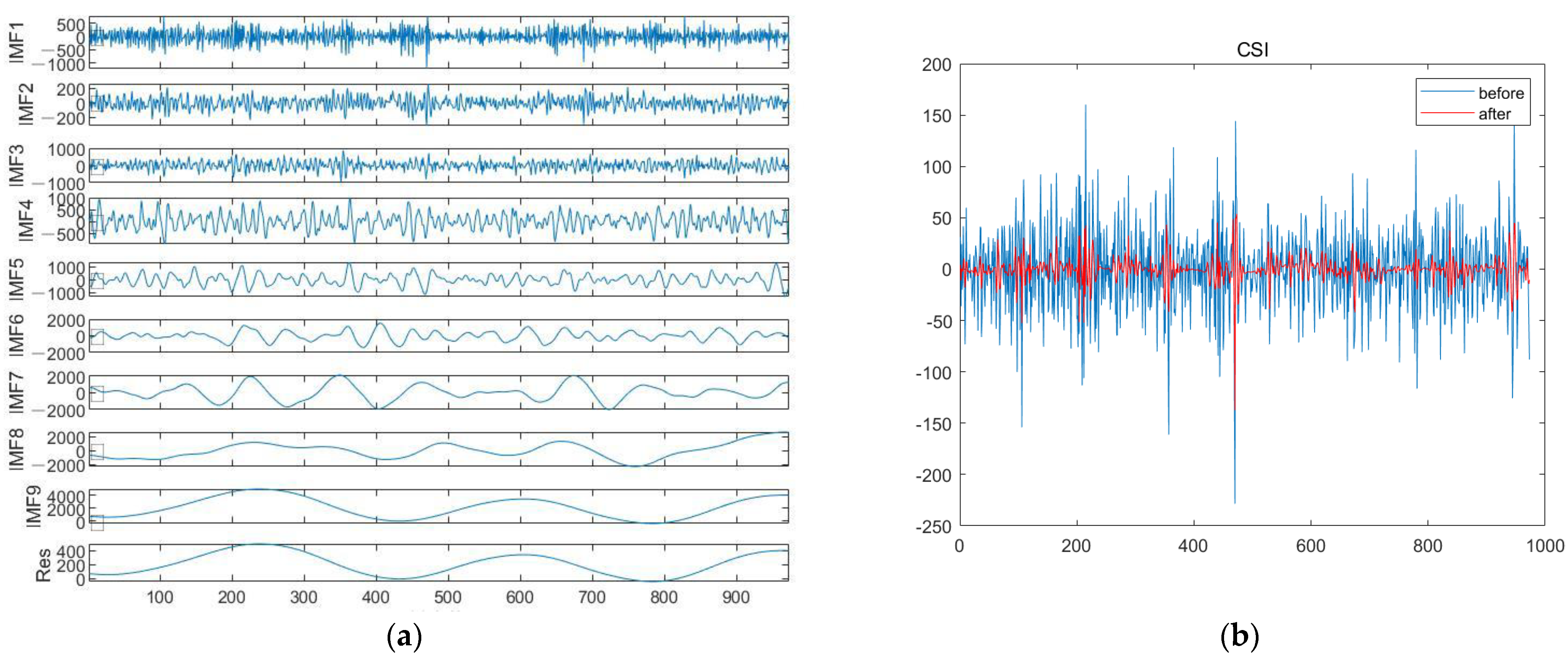
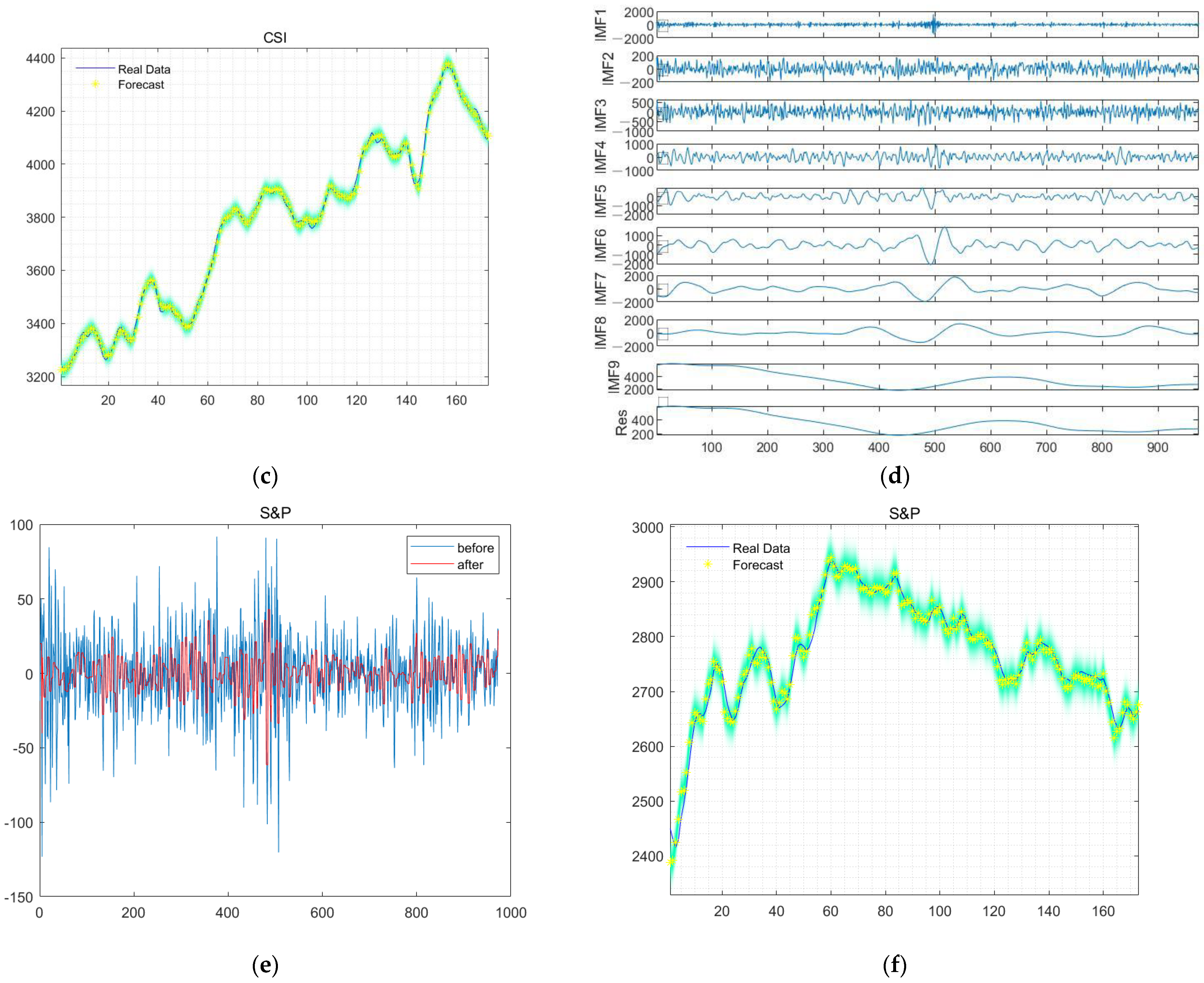
The primary objective was to decompose the data into several sub-signals using CEEMDAN presented in
Figure 7a,d and the denoised signals shown in
Figure 7b,e.
The forecasting curve in
Figure 7c,f are plotted using the last 173 days of the test data to illustrate the results of CSI300 and S&P500.
5. Discussion
Figure 7c,f show plots of the actual versus predicted values of the model predicting future movements of the CSI and S&p500 data, respectively.
Table 1 and
Table 2 show that the differential value between the denoised GRU and the non-denoised GRU is 0.008 and 0.019 in the
in CSI and S&P, respectively, and both
of denoised GRU reach above 0.99, which indicates that the denoised GRU model has a great advantage in the goodness of fit.
In order to select the optimum model, we did ten experiments for the significance analysis test and obtained ten sets of MSE and MAE of the six models. Since the ten sets of MSE and MAE of ARIMA did not have any variation and the mean values were 769.69 and 19.32, which were significantly larger than GRU based on CEEMDAN–wavelet, we found GRU based on CEEMDAN–wavelet is better than ARIMA.
In our study, GRU based on CEEMDAN–wavelet was used as the treatment group model. The LSTM, GRU, and CNN-BiLSTM are compared with GRU based on CEEMDAN–wavelet in turn in a two-by-two
t-test, using as the experimental group models. We know that the p-value of the
t-test is less than 0.05; in other words, there is a significant difference between the means of the values taken by the two models on this indicator.
Table 3 and
Table 4 selected ten experiments of CSI300 to study the significance analysis of
MSE and
MAE. The mean value of
MSE for GRU based on CEEMDAN–wavelet is 303.10 and the mean value of
MAE is 13.70. From
Table 3 and
Table 4, it is concluded that the
p-values of
t-tests of GRU, CNN-BiLSTM, and ANN on
MSE and
MAE are less than 0.05, i.e., there is a significant difference in the mean values of these three models on
MSE and
MAE. In addition, according to the mean values of
MSE and
MAE obtained by the ten experiments conducted, the mean values of
MSE and
MAE of GRU based on CEEMDAN–wavelet are the smallest; so, we conclude that GRU based on CEEMDAN–wavelet is superior to the other three models. For LSTM, even though its
p-value of the
t-test is larger than 0.05, since its mean values of
MSE and
MAE are larger than those of GRU based on CEEMDAN-wavelet, we conclude that GRU based on CEEMDAN–wavelet is superior to LSTM.
Similarly,
Table 5 and
Table 6 represent the ten experiments of S&P500 to study the significance analysis of
MSE and
MAE. The mean value of
MSE for GRU based on CEEMDAN–wavelet is 162.85 and the mean value of
MAE is 9.18. From
Table 5 and
Table 6, it is concluded that the four models of LSTM, GRU, CNN-BiLSTM, and ANN have significant differences in
MSE and there is a significant difference in the mean values of the values taken on
MAE. The mean values of
MSE and
MAE for GRU based on CEEMDAN–wavelet are the smallest, so we also believe that GRU based on CEEMDAN–wavelet can outperform the other four models.
Overall, by significance analysis, we conclude that GRU based on CEEMDAN–wavelet is optimum in comparison with the other five models.
6. Conclusions
In this paper, we propose a novel framework combining gated recurrent unit (GRU) neural networks and complete ensemble empirical modal decomposition of adaptive noise (CEEMDAN) to predict stock indices with more accuracy, where the wavelet threshold method is specifically used to denoise high-frequency noise in sub-signals in order to exclude interference noise for future data prediction. We first evaluate the proposed GRU-CEEMDAN–wavelet model with selected representative datasets from the S&P 500 and CSI 300 index closing prices. Meanwhile, we compare the improved model with the traditional ARIMA model and several modified neural network models applying different gate structures. After the verification of various evaluation indicators, the results show that the model is indeed better than the traditional model in terms of forecasting results.
However, financial markets are subject to human interference. We only have four-dimensional features for prediction. The personal behavior of any oligarchic firm or star investor may later lead to volatility in the financial market, and this human factor related to sentiment is not predictable by machine models and is completely random. Therefore, subsequent research wants to extract news keywords and sentiment analysis (e.g., a news article that the program can grab in the first place, and perform semantic analysis and sentiment judgments contained therein. If it is positively favorable, it will be added to the neural network prediction we build as a positive sentiment factor. Together, as a hybrid algorithm, it determines the price direction of the financial market.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}