
A Histopathological Image Classification Method Based on Model Fusion in the Weight Space

Abstract
:1. Introduction
- We introduce a weight-based model fusion strategy to solve the problem of histopathological image classification. The strategy significantly reduces the computational complexity of model training and inference.
- We propose the DDWA method to screen the ingredient models, enabling the weight fusion model to achieve a better approximation to the optimal value of the loss function’s error basin, thereby improving the generalization ability of the model.
2. Related Works
3. Model Fusion in the Weight Space for Histopathological Image Classification
3.1. Basic Model Training
A. Ingredient Model Training with Cyclical Learning Rate
B. Ingredient Model Training with Different Training Hyperparameters
C. The Effectiveness of Soup Ingredients
- Let represent the uniform distribution over S, and represent the expected value of L on samples drawn from . Then
- , define , where . Then
- Let . Then
3.2. Soup Strategies
| Algorithm 1: Non-dominated sort. |
| Input: : ranking of M candidate ingredients : ranking of M candidate ingredients H: candidate ingredients Output: : ranking of M candidate ingredients
|
4. Evaluations
4.1. Dataset Description
4.2. Evaluation Environment and Settings
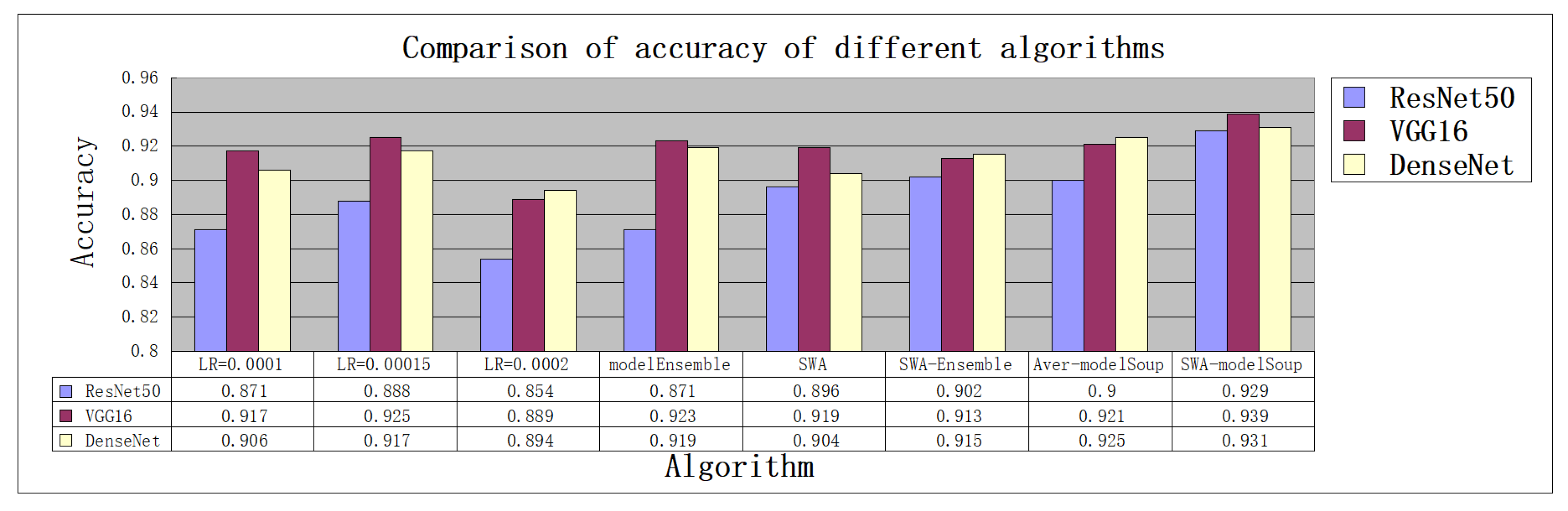
4.3. Evaluation Results
4.4. Model Complexity
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Snead, D.R.; Tsang, Y.W.; Meskiri, A.; Kimani, P.K.; Crossman, R.; Rajpoot, N.M.; Blessing, E.; Chen, K.; Gopalakrishnan, K.; Matthews, P.; et al. Validation of digital pathology imaging for primary histopathological diagnosis. Histopathology 2016, 68, 1063–1072. [Google Scholar] [CrossRef] [Green Version]
- Saltz, J.; Gupta, R.; Hou, L.; Kurc, T.; Singh, P.; Nguyen, V.; Samaras, D.; Shroyer, K.R.; Zhao, T.; Batiste, R.; et al. Spatial organization and molecular correlation of tumor-infiltrating lymphocytes using deep learning on pathology images. Cell Rep. 2018, 23, 181–193. [Google Scholar] [CrossRef] [Green Version]
- Panayides, A.S.; Amini, A.; Filipovic, N.D.; Sharma, A.; Tsaftaris, S.A.; Young, A.; Foran, D.; Do, N.; Golemati, S.; Kurc, T.; et al. AI in medical imaging informatics: Current challenges and future directions. IEEE J. Biomed. Health Inform. 2020, 24, 1837–1857. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A review of machine learning and deep learning applications. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; pp. 1–6. [Google Scholar]
- Li, Y.; Huang, C.; Ding, L.; Li, Z.; Pan, Y.; Gao, X. Deep learning in bioinformatics: Introduction, application, and perspective in the big data era. Methods 2019, 166, 4–21. [Google Scholar] [CrossRef] [Green Version]
- Nichita, A. A Series-Based Deep Learning Approach to Lung Nodule Image Classification. Cancers 2023, 15, 843. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Dai, Z.; Liu, H.; Le, Q.V.; Tan, M. CoAtNet: Marrying Convolution and Attention for All Data Sizes. arXiv 2021, arXiv:2106.04803. [Google Scholar]
- Hu, L.S.; Yoon, H.; Eschbacher, J.M.; Baxter, L.C.; Dueck, A.C.; Nespodzany, A.; Smith, K.A.; Nakaji, P.; Xu, Y.; Wang, L.; et al. Accurate patient-specific machine learning models of glioblastoma invasion using transfer learning. Am. J. Neuroradiol. 2019, 40, 418–425. [Google Scholar] [CrossRef]
- Sheehan, S.; Mawe, S.; Cianciolo, R.E.; Korstanje, R.; Mahoney, J.M. Detection and classification of novel renal histologic phenotypes using deep neural networks. Am. J. Pathol. 2019, 189, 1786–1796. [Google Scholar] [CrossRef]
- Roster, K.; Connaughton, C.; Rodrigues, F.A. Forecasting new diseases in low-datasettings using transfer learning. arXiv 2022, arXiv:2204.05059. [Google Scholar]
- Han, W.; Johnson, C.; Gaed, M.; Gómez, J.A.; Moussa, M.; Chin, J.L.; Pautler, S.; Bauman, G.S.; Ward, A.D. Histologic tissue components provide major cues for machine learning-based prostate cancer detection and grading on prostatectomy specimens. Sci. Rep. 2020, 10, 9911. [Google Scholar] [CrossRef]
- Hassan, S.A.; Sayed, M.S.; Abdalla, M.I.; Rashwan, M.A. Breast cancer masses classification using deep convolutional neural networks and transfer learning. Multimed. Tools Appl. 2020, 79, 30735–30768. [Google Scholar] [CrossRef]
- Liu, W.; Mo, J.; Zhong, F. Class Imbalanced Medical Image Classification Based on Semi-Supervised Federated Learning. Appl. Sci. 2023, 13, 2109. [Google Scholar] [CrossRef]
- Izmailov, P.; Podoprikhin, D.; Garipov, T.; Vetrov, D.; Wilson, A.G. Averaging weights leads to wider optima and better generalization. arXiv 2018, arXiv:1803.05407. [Google Scholar]
- Wortsman, M.; Ilharco, G.; Gadre, S.Y.; Roelofs, R.; Gontijo-Lopes, R.; Morcos, A.S.; Namkoong, H.; Farhadi, A.; Carmon, Y.; Kornblith, S.; et al. Model soups: Averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. arXiv 2022, arXiv:2203.05482. [Google Scholar]
- Choshen, L.; Venezian, E.; Slonim, N.; Katz, Y. Fusing finetuned models for better pretraining. arXiv 2022, arXiv:2204.03044. [Google Scholar]
- Dansereau, C.; Sobral, M.; Bhogal, M.; Zalai, M. Model soups to increase inference without increasing compute time. arXiv 2023, arXiv:2301.10092. [Google Scholar]
- Draxler, F.; Veschgini, K.; Salmhofer, M.; Hamprecht, F. Essentially no barriers in neural network energy landscape. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Smith, L.N. Cyclical learning rates for training neural networks. In Proceedings of the 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar]
- Wei, L.; Wan, S.; Guo, J.; Wong, K.K. A novel hierarchical selective ensemble classifier with bioinformatics application. Artif. Intell. Med. 2017, 83, 82–90. [Google Scholar] [CrossRef]
- Smith, L.N.; Topin, N. Exploring loss function topology with cyclical learning rates. arXiv 2017, arXiv:1702.04283. [Google Scholar]
- Garipov, T.; Izmailov, P.; Podoprikhin, D.; Vetrov, D.P.; Wilson, A.G. Loss Surfaces, Mode Connectivity, and Fast Ensembling of DNNs. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Jain, P.; Kakade, S.M.; Kidambi, R.; Netrapalli, P.; Sidford, A. Parallelizing Stochastic Gradient Descent for Least Squares Regression: Mini-batching, Averaging, and Model Misspecification. J. Mach. Learn. Res. 2018, 18, 1–42. [Google Scholar]
- Guo, H.; Jin, J.; Liu, B. Stochastic Weight Averaging Revisited. Appl. Sci. 2023, 13, 2935. [Google Scholar] [CrossRef]
- Neyshabur, B.; Sedghi, H.; Zhang, C. What is being transferred in transfer learning? Adv. Neural Inf. Process. Syst. 2020, 33, 512–523. [Google Scholar]
- Hameed, Z.; Zahia, S.; Garcia-Zapirain, B.; Javier Aguirre, J.; María Vanegas, A. Breast cancer histopathology image classification using an ensemble of deep learning models. Sensors 2020, 20, 4373. [Google Scholar] [CrossRef] [PubMed]
- Sohail, A.; Khan, A.; Nisar, H.; Tabassum, S.; Zameer, A. Mitotic nuclei analysis in breast cancer histopathology images using deep ensemble classifier. Med. Image Anal. 2021, 72, 102121. [Google Scholar] [CrossRef]
- Kumar, D.; Batra, U. Classification of Invasive Ductal Carcinoma from histopathology breast cancer images using Stacked Generalized Ensemble. J. Intell. Fuzzy Syst. 2021, 40, 4919–4934. [Google Scholar] [CrossRef]
- Ahuja, S.; Panigrahi, B.K.; Dey, N.; Rajinikanth, V.; Gandhi, T.K. Deep transfer learning-based automated detection of COVID-19 from lung CT scan slices. Appl. Intell. 2021, 51, 571–585. [Google Scholar] [CrossRef] [PubMed]
- Lawton, S.; Viriri, S. Detection of COVID-19 from CT Lung Scans Using Transfer Learning. Comput. Intell. Neurosci. 2021, 2021, 5527923. [Google Scholar] [CrossRef]
- Jangam, E.; Barreto, A.A.D.; Annavarapu, C.S.R. Automatic detection of COVID-19 from chest CT scan and chest X-Rays images using deep learning, transfer learning and stacking. Appl. Intell. 2022, 52, 2243–2259. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densenet: Densely connected convolutional networks. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; Volume 30, pp. 82–84. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 702–703. [Google Scholar]
- Lu, Z.; Wu, X.; Zhu, X.; Bongard, J. Ensemble pruning via individual contribution ordering. In Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 25–28 July 2010; pp. 871–880. [Google Scholar]
- Sahu, A.K.; Sahu, M.; Patro, P.; Sahu, G.; Nayak, S.R. Dual image-based reversible fragile watermarking scheme for tamper detection and localization. Pattern Anal. Appl. 2023, 26, 571–590. [Google Scholar] [CrossRef]
- Demiar, J.; Schuurmans, D. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tissue | Magnifications | Number of Images |
|---|---|---|
| adrenal | , | 50 |
| gland | , | 50 |
| breast | , | 40 |
| colon | , , | 60 |
| prostate | , | 70 |
| Type | Magnifications | Number of Images |
|---|---|---|
| benign tumor | , , , | 2480 |
| malignant tumor | , , , | 5429 |
| Model | Strategy | SCAN | BreakHis | ||||
|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | Precision | Recall | F1 Score | ||
| ResNet | LR = | ||||||
| LR = | |||||||
| LR = | |||||||
| LR-Ensemble | |||||||
| LR-Aver-Soup | |||||||
| CLR-Aver-Soup(SWA) | |||||||
| CLR-DDWA-Ensemble | |||||||
| CLR-DDWA-Soup | |||||||
| VGG19-BN | LR = | ||||||
| LR = | |||||||
| LR = | |||||||
| LR-Ensemble | |||||||
| LR-Aver-Soup | |||||||
| CLR-Aver-Soup(SWA) | |||||||
| CLR-DDWA-Ensemble | |||||||
| CLR-DDWA-Soup | |||||||
| DenseNet | LR = | ||||||
| LR = | |||||||
| LR = | |||||||
| LR-Ensemble | |||||||
| LR-Aver-Soup | |||||||
| CLR-Aver-Soup(SWA) | |||||||
| CLR-DDWA-Ensemble | |||||||
| CLR-DDWA-Soup | |||||||
| Model | Acc | Div | |||
|---|---|---|---|---|---|
| model_84 | 1 | 1 | 2 | ||
| model_51 | 7 | 3 | 10 | ||
| model_60 | 2 | 8 | 10 | ||
| model_57 | 8 | 5 | 13 | ||
| model_27 | 9 | 6 | 15 | ||
| model_87 | 4 | 11 | 15 | ||
| model_75 | 3 | 12 | 15 | ||
| model_30 | 11 | 7 | 18 |
| Model | Acc | Div | |||
|---|---|---|---|---|---|
| model_39 | 1 | 1 | 2 | ||
| model_42 | 2 | 2 | 4 | ||
| model_18 | 4 | 3 | 7 | ||
| model_15 | 3 | 4 | 7 | ||
| model_27 | 6 | 5 | 11 | ||
| model_57 | 5 | 7 | 12 | ||
| model_54 | 9 | 8 | 17 | ||
| model_24 | 8 | 9 | 17 |
| Model | ResNet | VGG | DenseNet | Average |
|---|---|---|---|---|
| LR = | // | // | // | |
| LR = | // | // | // | |
| LR = | // | // | // | |
| LR-Ensemble | // | // | // | |
| LR-Aver-Soup | // | // | // | |
| CLR-Aver-Soup(SWA) | // | // | // | |
| CLR-DDWA-Ensemble | // | // | // | |
| CLR-DDWA-Soup | // | // | // |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, G.; Lai, Z.-F.; Chen, Y.-Q.; Liu, H.-T.; Sun, W.-J. A Histopathological Image Classification Method Based on Model Fusion in the Weight Space. Appl. Sci. 2023, 13, 7009. https://doi.org/10.3390/app13127009
Zhang G, Lai Z-F, Chen Y-Q, Liu H-T, Sun W-J. A Histopathological Image Classification Method Based on Model Fusion in the Weight Space. Applied Sciences. 2023; 13(12):7009. https://doi.org/10.3390/app13127009
Chicago/Turabian StyleZhang, Gang, Zhi-Fei Lai, Yi-Qun Chen, Hong-Tao Liu, and Wei-Jun Sun. 2023. "A Histopathological Image Classification Method Based on Model Fusion in the Weight Space" Applied Sciences 13, no. 12: 7009. https://doi.org/10.3390/app13127009