
Feature Extracted Deep Neural Collaborative Filtering for E-Book Service Recommendations

Abstract
:1. Introduction
- A deep neural CF model with feature extraction for e-book service recommendations was designed by reflecting the user’s and product’s features as much as possible.
- Bayesian optimization was used to optimize the model parameters, and the proposed model for e-book service recommendations was used with the optimized model parameters and activation function.
- A comparative analysis experiment with other CF models was conducted to assess the performance of the proposed model, and the results showed that the proposed model outperformed the comparison models.
2. Related Works
2.1. Recommendation Systems
2.2. Feature Extraction Systems
3. Proposed Model
3.1. Input Layer
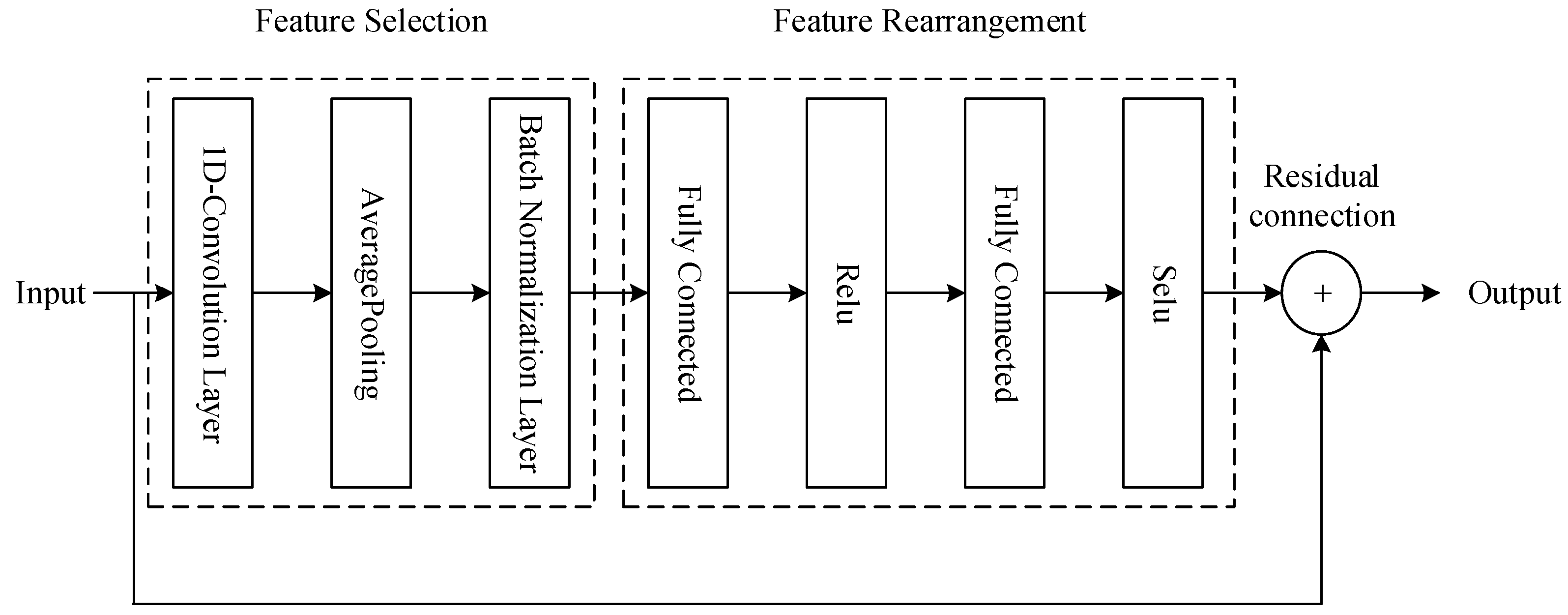
3.2. Feature Extraction Layer
- Feature selection operation
- Feature rearrangement operation
- Residual connection
3.3. Multi-Layer Perceptron
3.4. Output Layer
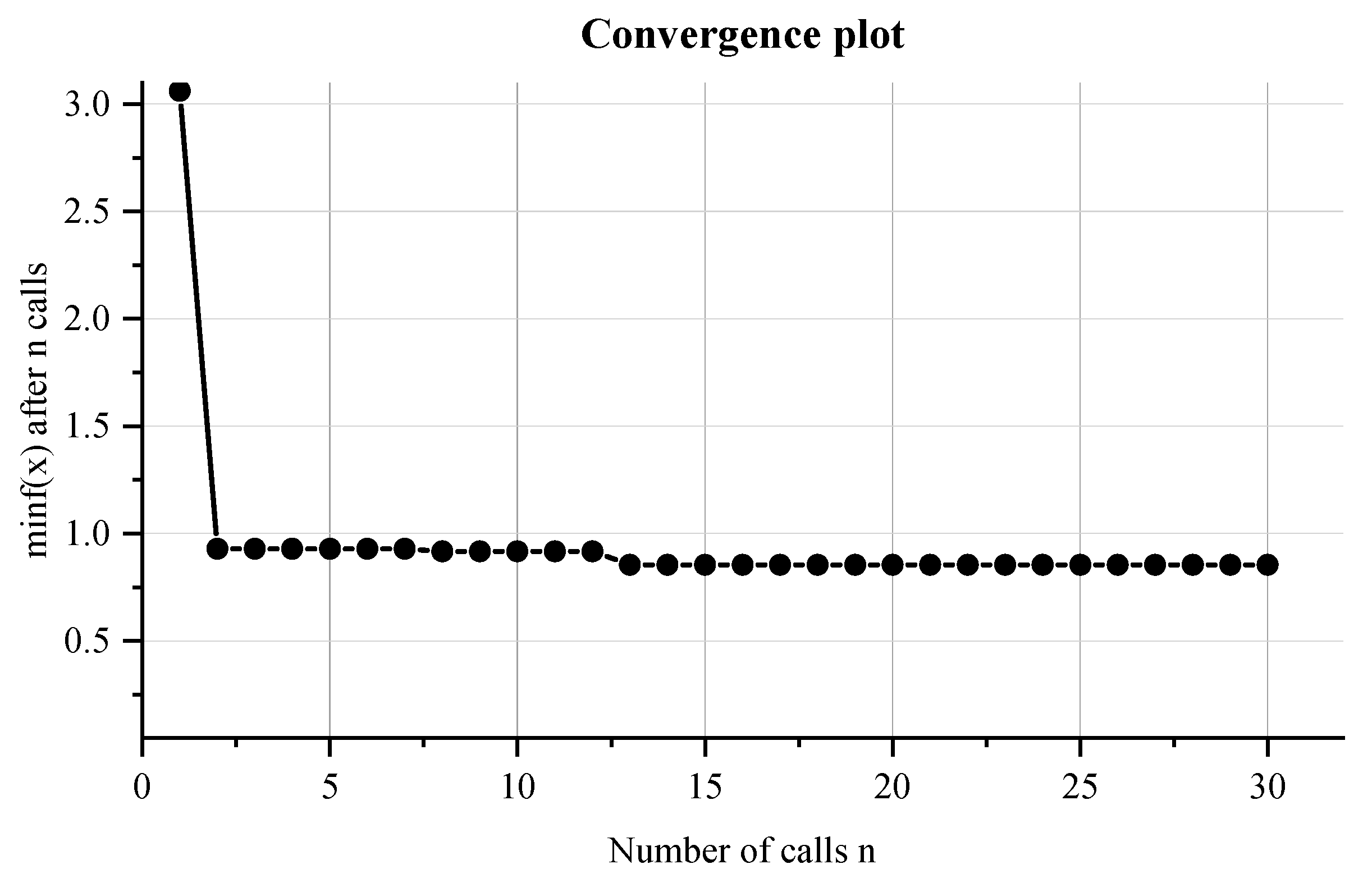
4. Parameter Search Using Bayesian Optimization
4.1. Bayesian Optimization Model
4.2. Optimizer Selection
4.3. Selection of Target Search Parameters
5. Results and Discussion
5.1. Dataset
5.2. Evaluataion Metrics
5.3. Model Performance Comparision
5.4. Selected Parameters of the Model
5.5. Experimental Result and Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Internet Usage Statistics. Available online: https://www.internetworldstats.com/stats.htm (accessed on 5 January 2023).
- Sari, S.Y.; Rahim, F.R.; Sundari, P.D.; Aulia, F. The importance of e-books in improving students’ skills in physics learning in the 21st century: A literature review. J. Phys. Conf. Ser. 2022, 2309, 012061. [Google Scholar] [CrossRef]
- Mobasher, B.; Burke, R.; Bhaumik, R.; Williams, C. Toward trustworthy recommender systems: An analysis of attack models and algorithm robustness. ACM Trans. 2007, 7, 23-es. [Google Scholar] [CrossRef]
- Zhen, L.; Huang, G.Q.; Jiang, Z. An inner-enterprise knowledge recommender system. Expert Syst. Appl. 2010, 37, 1703–1712. [Google Scholar] [CrossRef]
- Guy, I.; Carmel, D. Social recommender systems. In Proceedings of the WWW ‘11: 20th International World Wide Web Conference, Hyderabad, India, 28 March–1 April 2011; pp. 283–384. [Google Scholar] [CrossRef]
- Verma, C.; Hart, M.; Bhatkar, S.; Parker-Wood, A.; Dey, S. Improving scalability of personalized recommendation systems for enterprise knowledge workers. IEEE Access 2016, 4, 204–215. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems: Introduction and Challenge; Springer: Berlin/Heidelberg, Germany, 2015; pp. 1–34. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Reidl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web (WWW), Hong Kong, China, 1–5 May 2001. [Google Scholar] [CrossRef] [Green Version]
- Zhao, A.D.; Shang, M.S. User-based collaborative-filtering recommendation algorithms on Hadoop. In Proceedings of the 3rd International Conference on Knowledge Discovery and Data Mining, Phuket, Thailand, 9–10 January 2010. [Google Scholar] [CrossRef]
- Hu, R.; Pu, P. Enhancing collaborative filtering systems with personality information. In Proceedings of the RecSys ‘11: Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011. [Google Scholar] [CrossRef]
- Elahi, M.; Ricci, F.; Rubens, N. A survey of active learning in collaborative recommender systems. Comput. Sci. Rev. 2016, 20, 29–50. [Google Scholar] [CrossRef]
- Zhang, Q.; Yang, L.T.; Chen, Z.; Li, P. A survey on deep learning for big data. Inf. Fusion 2018, 42, 146–157. [Google Scholar] [CrossRef]
- Barkan, O.; Koenigstein, N. ITEM2VEC: Neural item embedding for collaborative filtering. In Proceedings of the 2016 IEEE 26th International Workshop on Machine Learning for Signal Processing, Vietri sul Mare, Italy, 13–16 September 2016. [Google Scholar] [CrossRef] [Green Version]
- Zheng, L. A Survey and Critique of Deep Learning on Recommender Systems. 2016. Available online: https://bdsc.lab.uic.edu/docs/survey-critique-deep.pdf (accessed on 6 January 2023).
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. arXiv 2017, arXiv:1708.05031. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Outer product-based neural collaborative filtering. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence (IJCAI-18), Stockholm, Sweden, 9–19 July 2018. [Google Scholar]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference, Boston, MA, USA, 15–19 September 2016. [Google Scholar] [CrossRef]
- Cheng, H.T. Wide & deep learning for recommender systems. arXiv 2016, arXiv:1606.07792. [Google Scholar] [CrossRef]
- Xiong, R.; Wang, J.; Li, Z.; Li, B.; Hung, P.C.K. Personalized LSTM based matrix factorization for online QoS prediction. In Proceedings of the 2018 IEEE International Conference on Web Services (ICWS), San Francisco, CA, USA, 2–7 July 2018. [Google Scholar] [CrossRef]
- Taud, H.; Mas, J. Multilayer perceptron (MLP). In Geomatic Approaches for Modeling Land Change Scenarios, Lecture Notes in Geoinformation and Cartography; Springer: Berlin/Heidelberg, Germany, 2018; pp. 451–455. [Google Scholar] [CrossRef]
- Xiong, R.; Wang, J.; Zhang, N.; Ma, Y. Deep hybrid collaborative filtering for Web service recommendation. Expert Syst. Appl. 2018, 110, 191–205. [Google Scholar] [CrossRef]
- Ullah, F.; Zhang, B.; Khan, R.U. Image-based service recommendation system: A JPEG-coefficient RFs approach. IEEE Access 2020, 8, 3308–3318. [Google Scholar] [CrossRef]
- Cheng, W.; Shen, Y.; Huang, L.; Zu, Y. Dual-embedding based deep latent factor models for recommendation. ACM Trans. Knowl. Discov. Data 2021, 15, 85. [Google Scholar] [CrossRef]
- Lin, Y.; Du, S.; Zhang, Y.; Duan, K.; Huang, Q.; An, P. A recommendation strategy integrating higher-order feature interactions with knowledge graphs. IEEE Access 2022, 10, 119290–119300. [Google Scholar] [CrossRef]
- Maneechote, N.; Maneeroj, S. Explainable recommendation via personalized features on dynamic preference interactions. IEEE Access 2022, 10, 116326–116343. [Google Scholar] [CrossRef]
- Chen, S.; Tian, J.; Tian, X.; Liu, S. Fusing user reviews into heterogeneous information network recommendation model. IEEE Access 2022, 10, 63672–63683. [Google Scholar] [CrossRef]
- Zeng, W.; Qin, J.; Wei, C. Neural collaborative autoencoder for recommendation with co-occurrence embedding. IEEE Access 2021, 9, 163316–163324. [Google Scholar] [CrossRef]
- Wang, H.; Hong, M.; Hong, Z. Research on BP neural network recommendation model fusing user reviews and ratings. IEEE Access 2021, 9, 86728–86738. [Google Scholar] [CrossRef]
- Huang, H.; Luo, S.; Tian, X.; Yang, S.; Zhang, X. Neural explicit factor model based on item features for recommendation systems. IEEE Access 2021, 9, 58448–58454. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, j. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Ha, S.; Choi, S. Convolutional neural networks for human activity recognition using multiple accelerometer and gyroscope sensors. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar] [CrossRef]
- Kasagi, A.; Tabaru, T.; Tamura, H. Fast algorithm using summed area tables with unified layer performing convolution and average pooling. In Proceedings of the IEEE Workshop on Machine Learning for Signal Processing, Tokyo, Japan, 25–28 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep learning using rectified linear units. arXiv 2018, arXiv:1803.08375. [Google Scholar] [CrossRef]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-normalizing neural networks. In Proceedings of the Self-Normalizing Neural Networks, NIPS’17: 31st International Conference on Neural Information Processing Systems, Montreal, ON, Canada, 3–8 September 2018. [Google Scholar] [CrossRef]
- Clevert, D.A.; Unterthiner, T.; Hochreiter, S. Fast and accurate, deep network learning by exponential linear units (ELUs). In Proceedings of the ICLR 2016, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar] [CrossRef]
- Jastrzebski, S.; Arpit, D.; Ballas, N.; Verma, V.; Che, T.; Bentio, Y. Residual connections encourage iterative inference. In Proceedings of the ICLR 2018 Conference, Vancouver, ON, Canada, 16 February 2018. [Google Scholar] [CrossRef]
- Zhou, Y.; Cahya, S.; Combs, T.A.; Nicolaou, C.A.; Wang, J.; Desai, P.V.; Shen, J. Exploring tunable hyperparameters for deep neural networks with industrial ADME data sets. Am. Chem. Soc. 2019, 59, 1005–1016. [Google Scholar] [CrossRef]
- Frazier, P.I. A tutorial on Bayesian optimization. arXiv 2018, arXiv:1807.02811. [Google Scholar] [CrossRef]
- Candelieri, A.; Archetti, I.; Author, F.; Barkalov, K. Turning hyperparameters of a SVM-based water demand forecasting system through parallel global optimization. Comput. Oper. Res. 2019, 106, 202–209. [Google Scholar] [CrossRef]
- Thiede, L.A.; Parlitz, U. Gradient based hyperparameter optimization in Echo State Networks. Neural Netw. 2019, 115, 23–29. [Google Scholar] [CrossRef] [PubMed]
- Shahriari, B.; Swersky, K.; Wang, Z.; Adams, R.P.; Freitas, N.D. Taking the human out of the loop: A review of Bayesian optimization. Proc. IEEE 2016, 104, 148–175. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]
- Goodbooks-10k. Available online: https://github.com/zygmuntz/goodbooks-10k (accessed on 5 January 2023).
- Ghosh, S.; Nahar, N.; Wahab, M.A.; Biswas, M. Recommendation system for e-commerce using alternating leat squares (ALS) on Apache Spark. In Intelligent Computing and Optimization, Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2021. [Google Scholar] [CrossRef]
- Author, M.G.; Margaritis, K.G. Applying SVD on generalized item-based filtering. In Proceedings of the 5th International Conference on Intelligent Systems Design and Applications (ISDA’05), 8–10 September 2005. [Google Scholar]
- Howard, J.; Gugger, S. Fastai: A layered API for deep learning. Information 2020, 11, 108. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. Recommender Systems: The Textbook; Springer: New York, NY, USA, 2016. [Google Scholar]
- Meng, Z.; McCreadie, R.; Macdonald, C.; Ounis, I. Exploring data splitting strategies for the evaluation of recommendation models. In Proceedings of the RecSys ’20: 14th ACM Conference on Recommender Systems, New York, NY, USA, 22–26 September 2020. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
| Kind of Data | Search Space |
|---|---|
| Size of embedding in the input layer | 10–100 |
| Regularization method type in the embedding input layer | L1, L2, L1L2 |
| Number of 1D convolution layer filters of feature extraction layer | 4–258 |
| Size of 1D convolution layer kernel of feature extraction layer | 4–258 |
| Number of neurons in the first fully connected layer of feature extraction layer | 4–258 |
| Activation function type in the second fully connected layer | Sigmoid, SoftMax, ReLU, tanh, SeLU, ELU |
| Number of neurons in the first fully connected layer of the multilayer perceptron | 4–258 |
| Number of neurons in the second fully connected layer of the multilayer perceptron | 4–258 |
| Number of neurons in the third fully connected layer of the multilayer perceptron | 4–258 |
| Number of neurons in the fourth fully connected layer of the multilayer perceptron | 4–258 |
| Type of loss function | Huber, MeanAbsoluteError, MeanSquaredError |
| Value of learning rate | 0.001–0.000001 |
| Attribute | Range |
|---|---|
| User Id | 1–53,424 |
| Book Id | 1–10,000 |
| Rating | 1–5 |
| Kind of Data | Search Space |
|---|---|
| Size of embedding in the input layer | 40 |
| Regularization method type in the embedding input layer | L1 |
| Number of 1D convolution layer filters of feature extraction layer | 108 |
| Size of 1D convolution layer kernel of feature extraction layer | 24 |
| Number of neurons in the first fully connected layer of feature extraction layer | 14 |
| Activation function type in the second fully connected layer | SeLU |
| Number of neurons in the first fully connected layer of the multilayer perceptron | 60 |
| Number of neurons in the second fully connected layer of the multilayer perceptron | 216 |
| Number of neurons in the third fully connected layer of the multilayer perceptron | 258 |
| Number of neurons in the fourth fully connected layer of the multilayer perceptron | 210 |
| Type of loss function | MeanAbsoluteError |
| Value of learning rate | 0.000495 |
| Trial No. | ALS | SVD | Fast AI Embedding Dot Bias | SAR | Feature Extracted Deep Neural CF | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |
| 1 | 0.9641 | 0.7307 | 0.8560 | 0.6683 | 0.9711 | 0.7781 | 1.6783 | 1.4239 | 0.8424 | 0.6593 |
| 2 | 0.9686 | 0.7325 | 0.8555 | 0.6684 | 0.9656 | 0.7722 | 1.6755 | 1.4190 | 0.8418 | 0.6587 |
| 3 | 0.9651 | 0.7309 | 0.8548 | 0.6673 | 0.9652 | 0.7719 | 1.6683 | 1.4138 | 0.8429 | 0.6598 |
| 4 | 0.9685 | 0.7340 | 0.8565 | 0.6689 | 0.9655 | 0.7722 | 1.6657 | 1.4119 | 0.8424 | 0.6594 |
| 5 | 0.9683 | 0.7324 | 0.8558 | 0.6681 | 0.9653 | 0.7720 | 1.6682 | 1.4149 | 0.8428 | 0.6597 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, J.-Y.; Lim, C.-K. Feature Extracted Deep Neural Collaborative Filtering for E-Book Service Recommendations. Appl. Sci. 2023, 13, 6833. https://doi.org/10.3390/app13116833
Kim J-Y, Lim C-K. Feature Extracted Deep Neural Collaborative Filtering for E-Book Service Recommendations. Applied Sciences. 2023; 13(11):6833. https://doi.org/10.3390/app13116833
Chicago/Turabian StyleKim, Ji-Yoon, and Chae-Kwan Lim. 2023. "Feature Extracted Deep Neural Collaborative Filtering for E-Book Service Recommendations" Applied Sciences 13, no. 11: 6833. https://doi.org/10.3390/app13116833