
Breaking Alert Fatigue: AI-Assisted SIEM Framework for Effective Incident Response

Abstract
:1. Introduction
- We propose a comprehensive framework to design and implement a next-generation SIEM system, and we demonstrate its effectiveness by prototyping the key components of the framework.
- We formalize a divide-and-conquer strategy to mitigate the alert fatigue problem and introduce practical solutions for each of its component problems, i.e., the filtering and correlation problems. We also present practical solutions to these problems, including the use of the cost-sensitive IWSVM learning method to address the issue of imbalanced learning in the filtering process and an algorithm that leverages the proximity, spatial, and temporal homogeneity of alerts to effectively summarize them into events for more efficient incident handling.
- We present an augmented visualization tool, which we refer to as augmented tile graph (ATG), and demonstrate its ability to improve the performance of data analysis against security alerts.
2. Background and Related Work
2.1. Incident Response with NIDS, SIEM, and SOAR
2.1.1. IDSs
2.1.2. SIEM
2.1.3. SOAR
2.2. Previous Studies on Alert Fatigue
2.2.1. Filtering- and Correlation-Based Approaches
2.2.2. Alert Prioritization
2.3. Feature Engineering
2.3.1. Feature-Based Approach
2.3.2. Featureless Approach
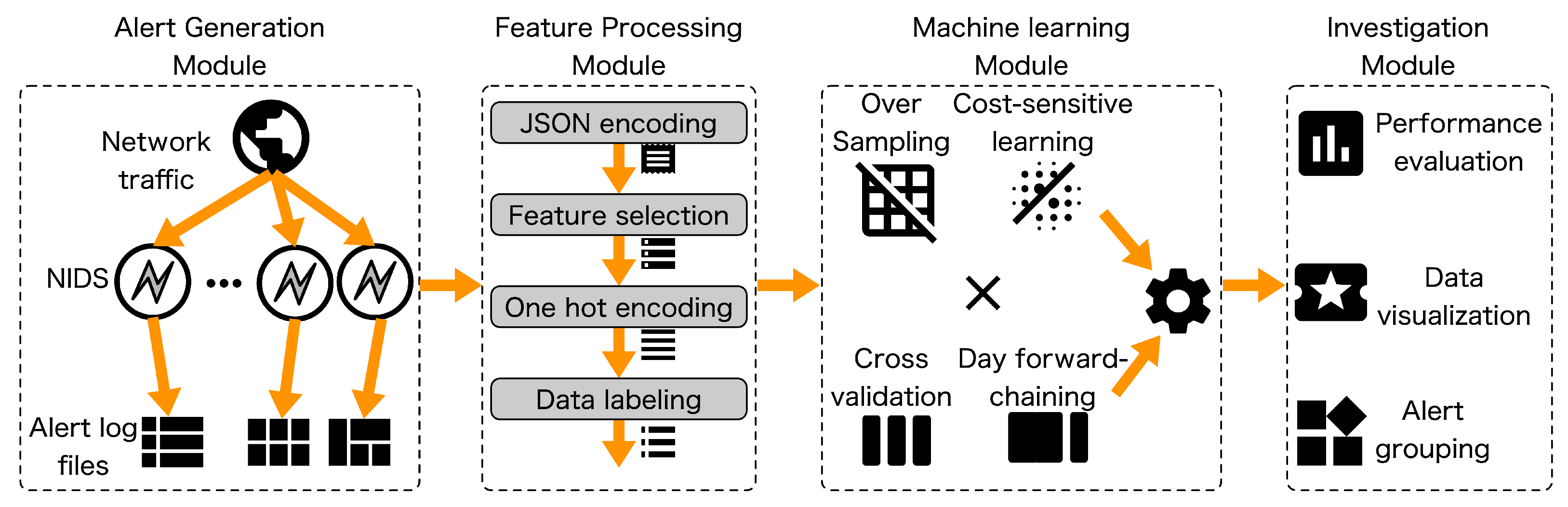
3. Proposed SIEM Framework
- The alert generation module collects alerts from multiple IDS sources.
- The feature processing module standardizes diverse log formats and encodes relevant information as numerical vectors for uniform representation.
- The ML module employs supervised learning algorithms on labeled alerts to develop a prediction model to detect critical alerts.
- The investigation module assesses the performance of the prediction models and enables rapid incident investigation through data visualization and alert correlation, which summarize alerts into high-priority events.
3.1. Alert Generation Module
3.2. Feature Processing Module
3.3. Machine Learning Module
3.3.1. Problem Formulation
3.3.2. Class Imbalance
3.3.3. Baseline Classification Methods
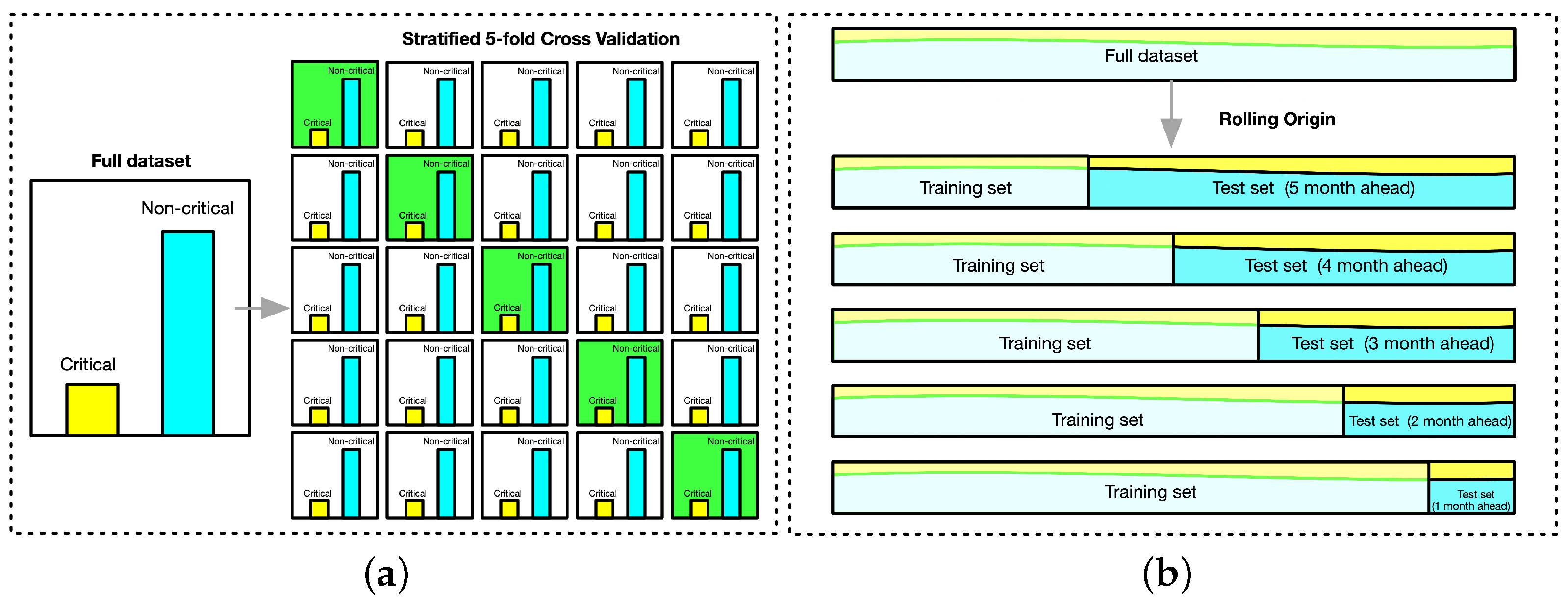
3.3.4. Evaluation Schemes
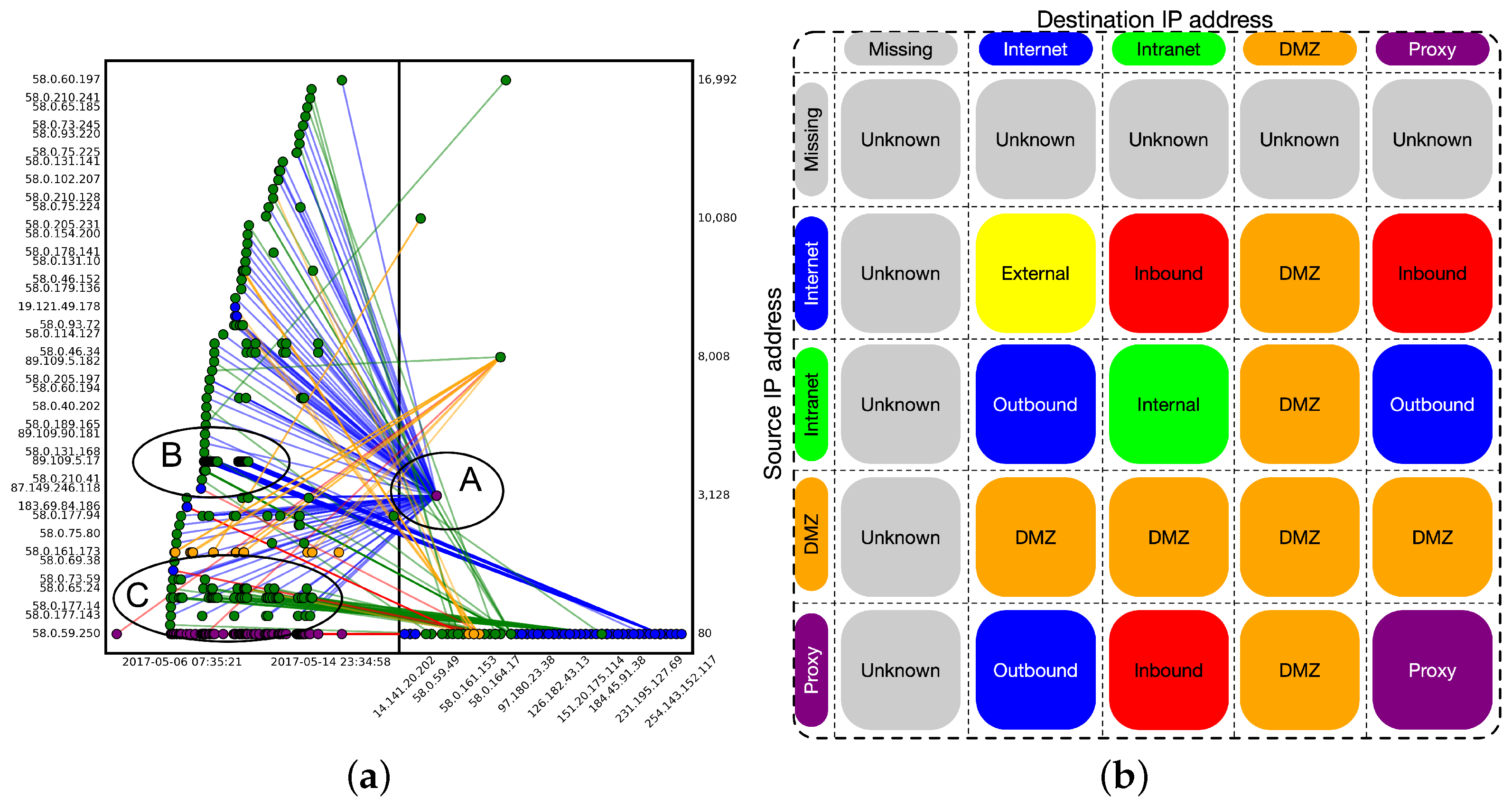
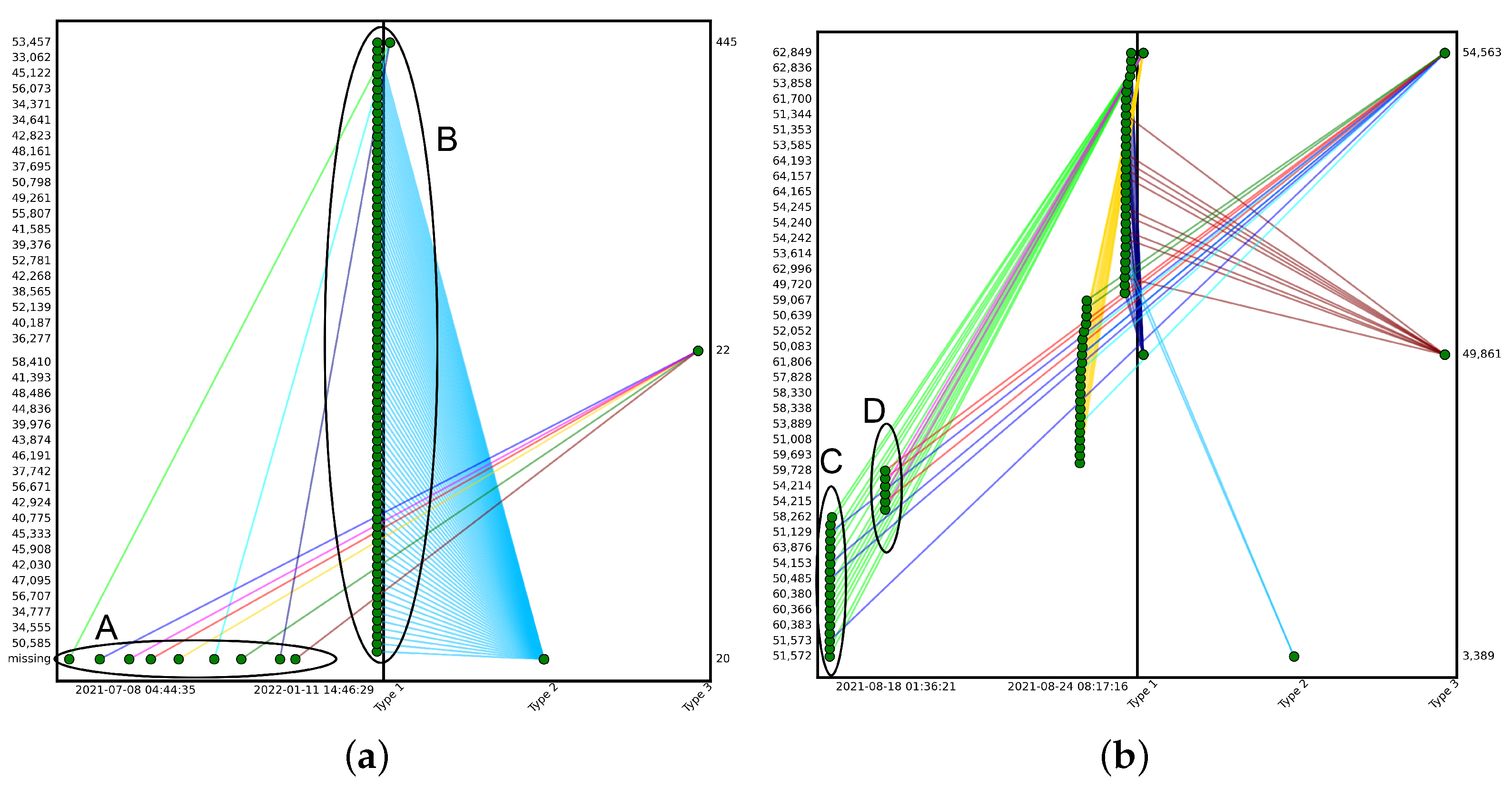
3.4. Investigation Module
4. Methodology
4.1. Filtering Problem
4.1.1. Filtering by Cost-Sensitive Learning
4.2. Correlation Problem
4.2.1. Implementing Alert Correlation
| Algorithm 1 Event Segmenting. |
Require:
|
4.3. Augmented Tile Graph Visualization
5. Experiments
5.1. Data Preparation
5.2. Parameter Tuning
5.3. Evaluation Metrics
5.4. Experiment I
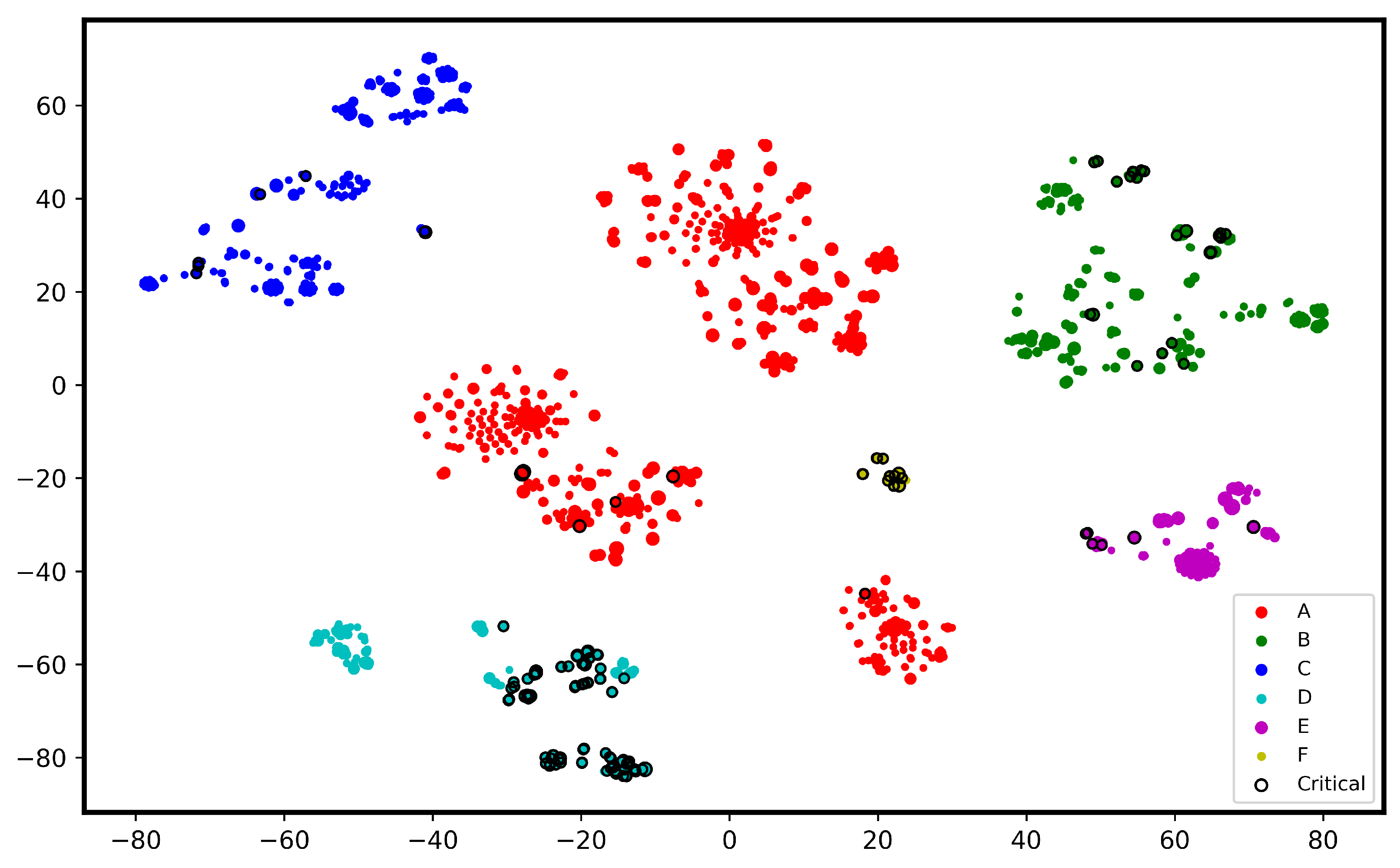
5.4.1. Visualization by t-SNE
5.4.2. Numerical Results
5.5. Experiment II
5.5.1. Filtering Result
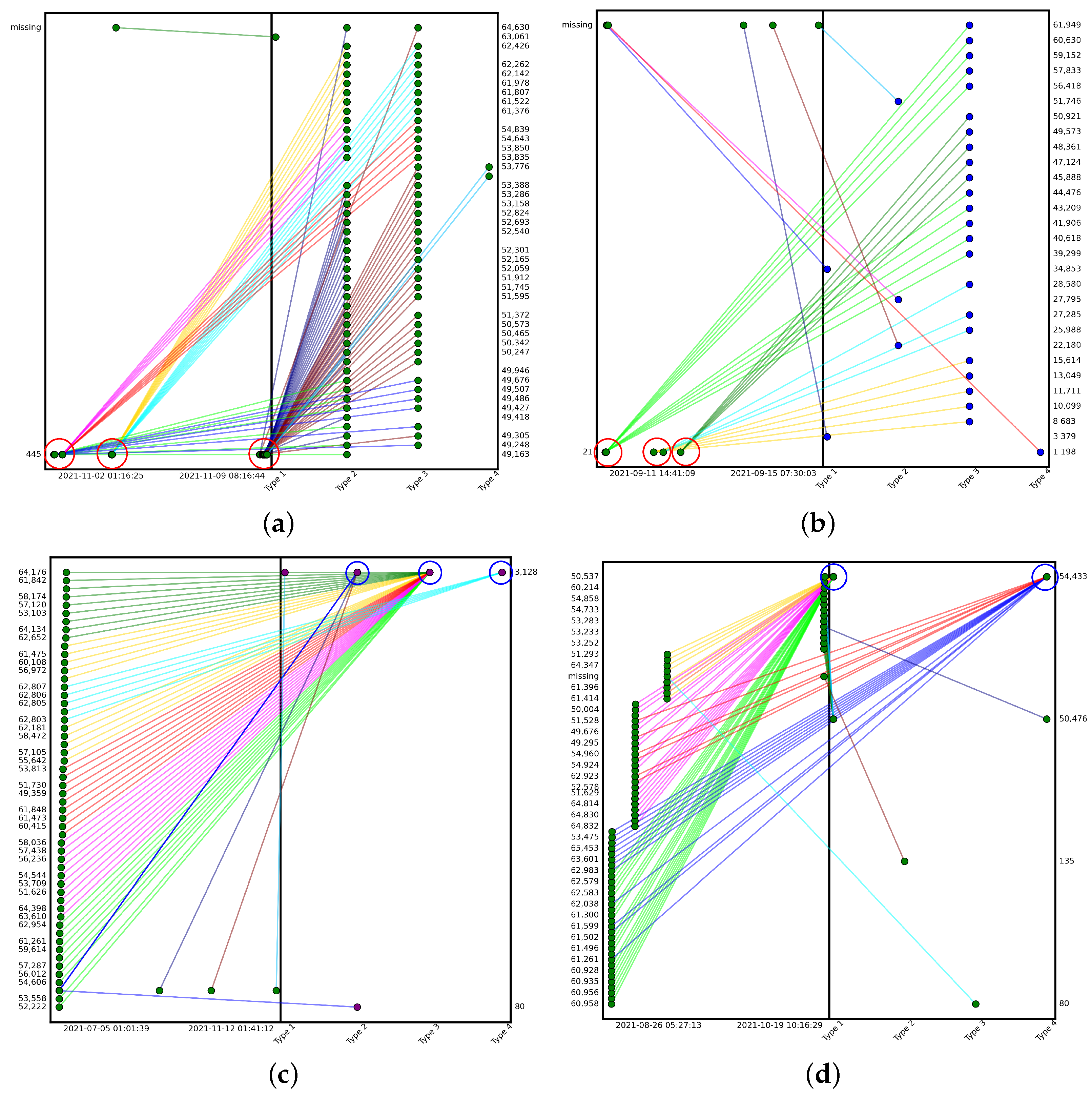
5.5.2. Correlation Result
6. Discussion, Limitations, and Future Work
6.1. Limitation of Scope
6.2. Ethical Implications
- Privacy: Security alerts contain sensitive data, e.g., personal information, usernames, and passwords. Thus, analyzing security alerts can raise privacy concerns if these alerts are stored without appropriate safeguards.
- Data security: NIDS-collected data integrated in the SIEM can be of great value to attackers. Thus, the SIEM must have robust security measures in place to protect the collected data.
- False positives: The proposed SIEM scheme attempts to reduce the number of FPs; however, some may remain. This can result in unnecessary investigations and harm innocent users. To ensure accountability, the proposed visualization technique can summarize the security situation associated with the alert.
- Legal compliance: Similar to NIDSs, the SIEM must comply with applicable laws and regulations, particularly those related to data protection and privacy.
6.3. Technical Limitations
6.3.1. Bias in the Results
6.3.2. Coping with Detection Errors
6.3.3. Emerging Threats and Adversarial Attacks
6.3.4. Guidelines for Model Updating
6.4. Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Example of Security Log in CEF and JSON Format

Appendix A.2. Using Service Port for Effective Alert Correlation

References
- European Union Agency for Cybersecurity. ENISA Threat Landscape. 2021. Available online: https://www.enisa.europa.eu/publications/enisa-threat-landscape-2021 (accessed on 30 January 2023).
- European Union Agency for Cybersecurity. ENISA Threat Landscape. 2022. Available online: https://www.enisa.europa.eu/publications/enisa-threat-landscape-2022 (accessed on 30 January 2023).
- Mishra, P.; Varadharajan, V.; Tupakula, U.; Pilli, E.S. A Detailed Investigation and Analysis of Using Machine Learning Techniques for Intrusion Detection. IEEE Commun. Surv. Tutorials 2019, 21, 686–728. [Google Scholar] [CrossRef]
- Mohammadpour, L.; Ling, T.C.; Liew, C.S.; Aryanfar, A. A Survey of CNN-Based Network Intrusion Detection. Appl. Sci. 2022, 12, 8162. [Google Scholar] [CrossRef]
- Gu, G.; Zhang, J.; Lee, W. BotSniffer: Detecting Botnet Command and Control Channels in Network Traffic. In Proceedings of the 2008 Network and Distributed System Security Symposium, NDSS, The Internet Society, San Diego, CA, USA, 10–13 February 2008. [Google Scholar]
- O’Kane, P.; Sezer, S.; McLaughlin, K. Obfuscation: The Hidden Malware. IEEE Secur. Priv. 2011, 9, 41–47. [Google Scholar] [CrossRef]
- Roesch, M. Snort: Lightweight intrusion detection for networks. In Proceedings of the LISA, Seattle, WA, USA, 7–12 November 1999; pp. 229–238. [Google Scholar]
- Paxson, V. Bro: A system for detecting network intruders in real-time. Comput. Netw. 1999, 31, 2435–2463. [Google Scholar] [CrossRef]
- Julien, V. Suricata IDS. 2015. Available online: https://suricata.io/ (accessed on 30 January 2023).
- VMware. Advanced Threat Prevention with VMware NSX Distributed Firewall. 2021. Available online: https://business-iq.net/assets/8079-advanced-threat-prevention-with-vmware-nsx-distributed-firewall (accessed on 30 January 2023).
- Fireeye2022. FireEye Network Security: Effective Protection against Cyber Breaches for Midsize to Large Organizations. 2022. Available online: https://docplayer.net/81314407-Fireeye-network-security.html (accessed on 30 January 2023).
- TrendMicro. Machine Learning and Next-Generation Intrusion Prevention System (NGIPS). 2022. Available online: https://documents.trendmicro.com/assets/wp/WP01_Machine_Learning_170608US.pdf (accessed on 30 January 2023).
- Vaarandi, R.; Podins, K. Network IDS alert classification with frequent itemset mining and data clustering. In Proceedings of the International Conference on Network and Service Management, Niagara Falls, ON, Canada, 25–29 October 2010; pp. 451–456. [Google Scholar]
- McAfee. Alert Fatigue: 31.9% of IT Security Professionals Ignore Alerts. 2017. Available online: https://www.mcafee.com/blogs/enterprise/cloud-security/alert-fatigue-31-9-of-it-security-professionals-ignore-alerts/ (accessed on 30 January 2023).
- González-Granadillo, G.; González-Zarzosa, S.; Diaz, R. Security Information and Event Management (SIEM): Analysis, Trends, and Usage in Critical Infrastructures. Sensors 2021, 21, 4759. [Google Scholar] [CrossRef]
- Kidmose, E.; Stevanovic, M.; Brandbyge, S.; Pedersen, J. Featureless Discovery of Correlated and False Intrusion Alerts. IEEE Access 2020, 8, 108748–108765. [Google Scholar] [CrossRef]
- Bijone, M. A Survey on Secure Network: Intrusion Detection & Prevention Approaches. Am. J. Inf. Syst. 2016, 4, 69–88. [Google Scholar]
- Walling, S.; Lodh, S. A Survey on Intrusion Detection Systems: Types, Datasets, Machine Learning methods for NIDS and Challenges. In Proceedings of the 2022 13th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 3–5 October 2022; pp. 1–7. [Google Scholar] [CrossRef]
- Liu, C.; Gu, Z.; Wang, J. A Hybrid Intrusion Detection System Based on Scalable K-Means+ Random Forest and Deep Learning. IEEE Access 2021, 9, 75729–75740. [Google Scholar] [CrossRef]
- Donkol, A.A.E.B.; Hafez, A.G.; Hussein, A.I.; Mabrook, M.M. Optimization of Intrusion Detection Using Likely Point PSO and Enhanced LSTM-RNN Hybrid Technique in Communication Networks. IEEE Access 2023, 11, 9469–9482. [Google Scholar] [CrossRef]
- Jayalaxmi, P.L.S.; Saha, R.; Kumar, G.; Conti, M.; Kim, T.H. Machine and Deep Learning Solutions for Intrusion Detection and Prevention in IoTs: A Survey. IEEE Access 2022, 10, 121173–121192. [Google Scholar] [CrossRef]
- Ali, I.; Enezi, S.; Ali, F.; Kehar, A.; Fatima, K.; Uddin, M.; Karuppayah, S. Detection of Real-Time Malicious Intrusions and Attacks in IoT Empowered Cybersecurity Infrastructures. IEEE Access 2023, 11, 9136–9148. [Google Scholar] [CrossRef]
- Okey, O.D.; Melgarejo, D.C.; Saadi, M.; Rosa, R.L.; Kleinschmidt, J.H.; Rodríguez, D.Z. Transfer Learning Approach to IDS on Cloud IoT Devices Using Optimized CNN. IEEE Access 2023, 11, 1023–1038. [Google Scholar] [CrossRef]
- Alohali, M.A.; Elsadig, M.; Al-Wesabi, F.N.; Al Duhayyim, M.; Mustafa Hilal, A.; Motwakel, A. Enhanced Chimp Optimization-Based Feature Selection with Fuzzy Logic-Based Intrusion Detection System in Cloud Environment. Appl. Sci. 2023, 13, 2580. [Google Scholar] [CrossRef]
- Bour, H.; Abolhasan, M.; Jafarizadeh, S.; Lipman, J.; Makhdoom, I. A multi-layered intrusion detection system for software defined networking. Comput. Electr. Eng. 2022, 101, 108042. [Google Scholar] [CrossRef]
- Awotunde, J.B.; Folorunso, S.O.; Imoize, A.L.; Odunuga, J.O.; Lee, C.C.; Li, C.T.; Do, D.T. An Ensemble Tree-Based Model for Intrusion Detection in Industrial Internet of Things Networks. Appl. Sci. 2023, 13, 2479. [Google Scholar] [CrossRef]
- Swift, D. A Practical Application of SIM/SEM/SIEM, Automating Threat Identification. 2006. Available online: https://www.sans.org/white-papers/1781/ (accessed on 30 January 2023).
- Tian, Z.; Luo, C.; Lu, H.; Su, S.; Sun, Y.; Zhang, M. User and Entity Behavior Analysis under Urban Big Data. ACM/IMS Trans. Data Sci. 2020, 1, 1–19. [Google Scholar] [CrossRef]
- Podzins, O.; Romanovs, A. Why SIEM is Irreplaceable in a Secure IT Environment? In Proceedings of the 2019 Open Conference of Electrical, Electronic and Information Sciences (eStream), Vilnius, Lithuania, 25 April 2019; pp. 1–5. [Google Scholar] [CrossRef]
- Shea, S. SOAR (Security Orchestration, Automation and Response). 2019. Available online: https://www.techtarget.com/searchsecurity/definition/SOAR (accessed on 30 January 2023).
- Gartner. Gartner: 2022 Market Guide for Security Orchestration, Automation and Response Solutions. 2022. Available online: https://swimlane.com/resources/gartner-soar-market-guide-2022 (accessed on 30 January 2023).
- Johnson Kinyua, L.A. AI/ML in Security Orchestration, Automation and Response: Future Research Directions. Intell. Autom. Soft Comput. 2021, 28, 527–545. [Google Scholar] [CrossRef]
- Gupta, N.; Traore, I.; de Quinan, P.M.F. Automated Event Prioritization for Security Operation Center using Deep Learning. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5864–5872. [Google Scholar] [CrossRef]
- Tjhai, G.C.; Furnell, S.M.; Papadaki, M.; Clarke, N.L. A preliminary two-stage alarm correlation and filtering system using SOM neural network and K-means algorithm. Comput. Secur. 2010, 29, 712–723. [Google Scholar] [CrossRef]
- Shittu, R.; Healing, A.; Ghanea-Hercock, R.; Bloomfield, R.; Muttukrishnan, R. OutMet: A new metric for prioritising intrusion alerts using correlation and outlier analysis. In Proceedings of the 39th Annual IEEE Conference on Local Computer Networks, Edmonton, AL, Canada, 8–11 September 2014; pp. 322–330. [Google Scholar]
- Valeur, F.; Vigna, G.; Kruegel, C.; Kemmerer, R.A. Comprehensive approach to intrusion detection alert correlation. IEEE Trans. Depend. Secur. Comput. 2004, 1, 146–169. [Google Scholar] [CrossRef]
- Hassan, W.U.; Guo, S.; Li, D.; Chen, Z.; Jee, K.; Li, Z.; Bates, A. NODOZE: Combatting Threat Alert Fatigue with Automated Provenance Triage. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium, San Diego, CA, USA, 24–27 February 2019. [Google Scholar]
- Sun, L.; Versteeg, S.; Boztas, S.; Rao, A. Detecting Anomalous User Behavior Using an Extended Isolation Forest Algorithm: An Enterprise Case Study. arXiv 2016, arXiv:1609.06676. [Google Scholar]
- Chakir, E.M.; Moughit, M.; Idrissi Khamlichi, Y. An efficient method for evaluating alerts of Intrusion Detection Systems. In Proceedings of the 2017 International Conference on Wireless Technologies, Embedded and Intelligent Systems (WITS), Fez, Morocco, 19–20 April 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Aminanto, M.E.; Zhu, L.; Ban, T.; Isawa, R.; Takahashi, T.; Inoue, D. Combating Threat-Alert Fatigue with Online Anomaly Detection Using Isolation Forest. In Proceedings of the Lecture Notes in Computer Science, Neural Information Processing (ICONIP) 2019; Springer: Cham, Switzerland, 2019; pp. 756–765. [Google Scholar]
- Aminanto, M.E.; Ban, T.; Isawa, R.; Takahashi, T.; Inoue, D. Threat Alert Prioritization Using Isolation Forest and Stacked Auto Encoder With Day-Forward-Chaining Analysis. IEEE Access 2020, 8, 217977–217986. [Google Scholar] [CrossRef]
- Madani, A.; Rezayi, S.; Gharaee, H. Log management comprehensive architecture in Security Operation Center (SOC). In Proceedings of the IEEE 2011 International Conference on Computational Aspects of Social Networks (CASoN), Salamanca, Spain, 19–21 October 2011; pp. 284–289. [Google Scholar]
- IBM. Log Event Extended Format (LEEF). 2016. Available online: https://www.ibm.com/support/knowledgecenter/SS42VS_DSM/b_Leef_format_guide.pdf (accessed on 9 May 2019).
- McAfee. McAfee Enterprise Security Manager 10.2.0 Product Guide (Unmanaged). 2017. Available online: https://docs.mcafee.com/bundle/enterprise-security-manager-10.2.0-product-guide-unmanaged/page/GUID-984F5DA6-8D84-4549-855B-C77D53CF96B9.html (accessed on 30 September 2020).
- Debar, H.; Curry, D.; Feinstein, B. The intrusion detection message exchange format (IDMEF). 2007. Available online: https://www.ietf.org/rfc/rfc4765.txt (accessed on 30 January 2023).
- MITRE. Common Event Expression—CEE, a Unified Event Language for Interoperability. Available online: http://makingsecuritymeasurable.mitre.org/docs/cee-intro-handout.pdf (accessed on 30 January 2023).
- Azodi, A.; Jaeger, D.; Cheng, F.; Meinel, C. A new approach to building a multi-tier direct access knowledgebase for ids/siem systems. In Proceedings of the 2013 IEEE 11th International Conference on Dependable, Autonomic and Secure Computing, Chengdu, China, 21–22 December 2013; pp. 118–123. [Google Scholar]
- Sapegin, A.; Jaeger, D.; Azodi, A.; Gawron, M.; Cheng, F.; Meinel, C. Hierarchical object log format for normalisation of security events. In Proceedings of the IEEE 2013 9th International Conference on Information Assurance and Security (IAS), Gammarth, Tunisia, 4–6 December 2013; pp. 25–30. [Google Scholar]
- Anderson, M.; Antenucci, D.; Bittorf, V.; Burgess, M.; Cafarella, M.; Kumar, A.; Niu, F.; Park, Y.; Ré, C.; Zhang, C. Brainwash: A data system for feature engineering. Proc. CIDR 2013, 2013, 1–4. [Google Scholar]
- Khurana, U.; Turaga, D.; Samulowitz, H.; Parthasrathy, S. Cognito: Automated feature engineering for supervised learning. In Proceedings of the IEEE 16th International Conference on Data Mining Workshops (ICDMW), Barcelona, Spain, 12–15 December 2016; pp. 1304–1307. [Google Scholar]
- Li, D.; Kotani, D.; Okabe, Y. Improving Attack Detection Performance in NIDS Using GAN. In Proceedings of the 2020 IEEE 44th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 13–17 July 2020; pp. 817–825. [Google Scholar] [CrossRef]
- Pezoa, F.; Reutter, J.L.; Suarez, F.; Ugarte, M.; Vrgoč, D. Foundations of JSON schema. In Proceedings of the 25th International Conference on World Wide Web. International World Wide Web Conferences Steering Committee, Montreal, QC, Canada, 11–15 April 2016; pp. 263–273. [Google Scholar]
- Joloudari, J.H.; Marefat, A.; Nematollahi, M.A.; Oyelere, S.S.; Hussain, S. Effective Class-Imbalance Learning Based on SMOTE and Convolutional Neural Networks. Appl. Sci. 2023, 13, 4006. [Google Scholar] [CrossRef]
- Oliveira, N.; Praça, I.; Maia, E.; Sousa, O. Intelligent Cyber Attack Detection and Classification for Network-Based Intrusion Detection Systems. Appl. Sci. 2021, 11, 1674. [Google Scholar] [CrossRef]
- Jadhav, A.; Mostafa, S.M.; Elmannai, H.; Karim, F. An Empirical Assessment of Performance of Data Balancing Techniques in Classification Task. Appl. Sci. 2022, 12, 3928. [Google Scholar] [CrossRef]
- Liu, C.; Cao, L.; Yu, P.S. A hybrid coupled k-nearest neighbor algorithm on imbalance data. In Proceedings of the IEEE 2014 International Joint Conference on Neural Networks (IJCNN), Beijing, China, 6–11 July 2014; pp. 2011–2018. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Nguyen, H.M.; Cooper, E.W.; Kamei, K. Borderline over-sampling for imbalanced data classification. Int. J. Knowl. Eng. Soft Data Paradig. 2011, 3, 4–21. [Google Scholar] [CrossRef]
- Ndichu, S.; Ban, T.; Takahashi, T.; Inoue, D. AI-Assisted Security Alert Data Analysis with Imbalanced Learning Methods. Appl. Sci. 2023, 13, 1977. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. 2011, 2, 1–27. Available online: http://www.csie.ntu.edu.tw/~cjlin/libsvm (accessed on 30 January 2023). [CrossRef]
- Ban, T.; Samuel, N.; Takahashi, T.; Inoue, D. Combat Security Alert Fatigue with AI-Assisted Techniques. In Proceedings of the 2021 Cyber Security Experimentation and Test Workshop, CSET, New York, NY, USA, 9 August 2021; pp. 9–16. [Google Scholar] [CrossRef]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification, 2nd ed.; Wiley-Interscience: New York, NY, USA, 2000. [Google Scholar]
- Sammut, C.; Webb, G.I. Stratified Cross Validation. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; p. 928. [Google Scholar] [CrossRef]
- Tashman, L.J. Out-of-sample tests of forecasting accuracy: An analysis and review. Int. J. Forecast. 2000, 16, 437–450. [Google Scholar] [CrossRef]
- Svetunkov, I.; Petropoulos, F. Old dog, new tricks: A modelling view of simple moving averages. Int. J. Prod. Res. 2018, 56, 6034–6047. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Lapin, M.; Hein, M.; Schiele, B. Learning using privileged information: SVM+ and weighted SVM. Neural Netw. 2014, 53, 95–108. [Google Scholar] [CrossRef]
- Cimpanu, C. Emotet, tOday’S Most Dangerous Botnet, Comes Back to Life. 2019. Available online: https://www.zdnet.com/article/emotet-todays-most-dangerous-botnet-comes-back-to-life/ (accessed on 30 January 2023).
- Pathria, R.K.; Beale, P.D. Statistical Mechanics, 3rd ed.; Academic Press: Cambridge, MA, USA, 2011. [Google Scholar]
- Ndichu, S.; Ban, T.; Takahashi, T.; Inoue, D. A Machine Learning Approach to Detection of Critical Alerts from Imbalanced Multi-Appliance Threat Alert Logs. In Proceedings of the 2021 IEEE International Conference on Big Data (Big Data), Orlando, FL, USA, 15–18 December 2021; pp. 2119–2127. [Google Scholar] [CrossRef]
- Mathworks. Hyperparameter Optimization in Classification Learner App. 2023. Available online: https://www.mathworks.com/help/stats/hyperparameter-optimization-in-classification-learner-app.html (accessed on 30 January 2023).
- Powers, D.M.W. Evaluation: From Precision, Recall and F-measure to ROC, Informedness, Markedness & Correlation. Int. J. Mach. Learn. Technol. 2011, 2, 37–63. [Google Scholar]
- van der Maaten, L.; Hinton, G. Visualizing Data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Petrila, J.; Cohn, B.; Pritchett, W.; Stiles, P.; Stodden, V.V.; Humowiecki, M.; Rozario, N. Legal Issues for IDS Use: Finding a Way Forward. 2017. Available online: https://aisp.upenn.edu/wp-content/uploads/2016/07/Legal-Issues.pdf (accessed on 30 January 2023).
- Quality, N.; Commission, S. NDIS Code of Conduct. 2019. Available online: https://www.ndiscommission.gov.au/about/ndis-code-conduct (accessed on 30 January 2023).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Classifiers | Physical Meaning | Grid Values |
|---|---|---|---|
| W | WSVM, IWSVM | Weight for positive class | {1, 10, 100, 1000, 10,000} |
| SVM, WSVM, IWSVM | Width parameter for SVM with RBF kernels | {0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1} | |
| C | SVM, WSVM, IWSVM | Penalty parameter for prediction error | {10, 100,1000, 10,000} |
| Appliance | #Total | #Daily Average | #Subsampled | Sampling Ratio (%) | #Positive | Positive Ratio (%) |
|---|---|---|---|---|---|---|
| A | 36.68 M | 39,005 | 226,784 | 0.618 | 1286 | 0.567 |
| B | 0.56 M | 1857 | 5944 | 1.053 | 617 | 10.380 |
| C | 11.86 M | 39,005 | 30,837 | 0.260 | 169 | 0.548 |
| D | 15.80 M | 51,953 | 36,145 | 0.229 | 20 | 0.055 |
| E | 66.21 M | 217,804 | 372,161 | 0.562 | 53 | 0.014 |
| F | 6498 | 21 | 129 | 1.985 | 94 | 72.868 |
| Total | 137.77 M | 452,958 | 672,000 | 0.488 | 2239 | 0.333 |
| Category | Algorithm | Accuracy (%) | Recall (%) | Precision (%) | FPR (%) | TNR (%) | F1 (%) | BCR (%) |
|---|---|---|---|---|---|---|---|---|
| Unsupervised | IF [40] | 90.705 | 100.000 | 0.551 | 9.300 | 90.700 | 1.097 | 95.350 |
| learning | IF + DC [41] | 94.141 | 95.876 | 0.837 | 5.860 | 94.140 | 1.659 | 95.008 |
| Supervised | KNN | 99.955 | 98.749 | 89.046 | 0.041 | 99.959 | 93.647 | 99.354 |
| learning | NB | 89.741 | 93.390 | 2.950 | 10.271 | 89.729 | 5.719 | 91.559 |
| LDA | 99.983 | 99.732 | 95.387 | 0.016 | 99.984 | 97.511 | 99.858 | |
| DT | 99.916 | 99.285 | 80.137 | 0.082 | 99.918 | 88.689 | 99.602 | |
| AdaBoost | 99.997 | 99.732 | 99.466 | 0.002 | 99.998 | 99.599 | 99.865 | |
| SVM | 99.992 | 97.901 | 99.682 | 0.001 | 99.999 | 98.783 | 98.950 | |
| Over- | RF-SMOTE [70] | 99.914 | 99.048 | 95.632 | 0.072 | 99.928 | 97.310 | 99.488 |
| sampling | DT-SMOTE [70] | 99.573 | 99.286 | 78.977 | 0.422 | 99.578 | 87.975 | 99.432 |
| RF-SVMSMOTE [70] | 99.925 | 98.571 | 96.729 | 0.053 | 99.947 | 97.642 | 99.259 | |
| DT-SVMSMOTE [70] | 99.562 | 99.286 | 78.531 | 0.443 | 99.567 | 87.697 | 99.426 | |
| XGBoost-MAS-OSS [59] | 99.875 | 99.519 | 93.034 | 0.119 | 99.881 | 96.167 | 99.700 | |
| Cost-sensitive | WSVM | 99.998 | 99.598 | 99.687 | 0.001 | 99.999 | 99.643 | 99.799 |
| learning | IWSVM | 99.998 | 99.643 | 99.687 | 0.001 | 99.999 | 99.665 | 99.821 |
| Training Set | Testing Set | #Escalated | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Setting | Interval | #All | #Positive | #Negative | Interval | #All | #Positive | #Negative | #All |
| 1 | June 2021–June 2022 | 5.112 M | 56,530 | 5.056 M | July 2022–November 2022 | 2.213 M | 25,591 | 2.187 M | 4165 |
| 2 | June 2021–July 2022 | 5.648 M | 61,250 | 5.587 M | August 2022–November 2022 | 1.677 M | 20,871 | 1.656 M | 3428 |
| 3 | June 2021–August 2022 | 6.130 M | 67,116 | 6.063 M | September 2022–November 2022 | 1.195 M | 15,005 | 1.180 M | 2935 |
| 4 | June 2021–September 2022 | 6.546 M | 71,758 | 6.475 M | October 2022–November 2022 | 0.779 M | 10,363 | 0.768 M | 2567 |
| 5 | June 2021–October 2022 | 6.989 M | 77,692 | 6.912 M | November 2022 | 0.336 M | 4429 | 0.331 M | 693 |
| Setting | Interval | Accuracy (%) | Recall (%) | Precision (%) | FPR (%) | TNR (%) | F1 (%) | BCR (%) |
|---|---|---|---|---|---|---|---|---|
| 1 | 5 months | 99.986 | 98.945 | 99.822 | 0.002 | 100.000 | 99.381 | 99.472 |
| 2 | 4 months | 99.995 | 99.731 | 99.846 | 0.002 | 100.000 | 99.788 | 99.865 |
| 3 | 3 months | 99.994 | 99.732 | 99.812 | 0.002 | 99.998 | 99.772 | 99.865 |
| 4 | 2 months | 99.991 | 99.611 | 99.728 | 0.004 | 99.996 | 99.669 | 99.804 |
| 5 | 1 month | 99.999 | 99.932 | 99.977 | 0.000 | 100.000 | 99.954 | 99.966 |
| Random Shuffle | - | 100.000 | 1.000 | 99.996 | 0.000 | 100.000 | 99.998 | 50.500 |
| Setting | Interval | Accuracy (%) | Recall (%) | Precision (%) | FPR (%) | TNR (%) | F1 (%) | BCR (%) | ARR |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 months | 98.079 | 97.561 | 98.940 | 1.284 | 98.716 | 98.246 | 98.138 | 45.850 |
| 2 | 4 months | 97.987 | 97.109 | 99.314 | 0.872 | 99.128 | 98.199 | 98.119 | 45.010 |
| 3 | 3 months | 98.331 | 97.361 | 99.394 | 0.634 | 99.366 | 98.367 | 98.364 | 49.400 |
| 4 | 2 months | 98.091 | 96.928 | 99.292 | 0.712 | 99.289 | 98.096 | 98.108 | 50.490 |
| 5 | 1 month | 99.423 | 99.180 | 99.725 | 0.306 | 99.694 | 99.452 | 99.437 | 47.470 |
| Setting | Interval | #Event | Accuracy (%) | Recall (%) | Precision (%) | FPR (%) | TNR (%) | F1 (%) | BCR (%) | GARR (%) |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5 months | 1512 | 96.958 | 97.171 | 98.611 | 3.606 | 96.394 | 97.886 | 96.783 | 74.070 |
| 2 | 4 months | 1173 | 96.249 | 96.261 | 98.397 | 3.779 | 96.221 | 97.317 | 96.241 | 76.340 |
| 3 | 3 months | 888 | 97.072 | 97.152 | 98.472 | 3.093 | 96.907 | 97.808 | 97.030 | 79.930 |
| 4 | 2 months | 718 | 96.379 | 96.288 | 98.000 | 3.462 | 96.538 | 97.137 | 96.413 | 82.470 |
| 5 | 1 month | 206 | 99.029 | 99.099 | 99.099 | 1.053 | 98.947 | 99.099 | 99.023 | 83.980 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ban, T.; Takahashi, T.; Ndichu, S.; Inoue, D. Breaking Alert Fatigue: AI-Assisted SIEM Framework for Effective Incident Response. Appl. Sci. 2023, 13, 6610. https://doi.org/10.3390/app13116610
Ban T, Takahashi T, Ndichu S, Inoue D. Breaking Alert Fatigue: AI-Assisted SIEM Framework for Effective Incident Response. Applied Sciences. 2023; 13(11):6610. https://doi.org/10.3390/app13116610
Chicago/Turabian StyleBan, Tao, Takeshi Takahashi, Samuel Ndichu, and Daisuke Inoue. 2023. "Breaking Alert Fatigue: AI-Assisted SIEM Framework for Effective Incident Response" Applied Sciences 13, no. 11: 6610. https://doi.org/10.3390/app13116610