
Secure Convolution Neural Network Inference Based on Homomorphic Encryption

Abstract
:1. Introduction
1.1. Our Contribution
1.2. Organization
2. Related Works
3. System Model, Encryption Scheme and Design Goals
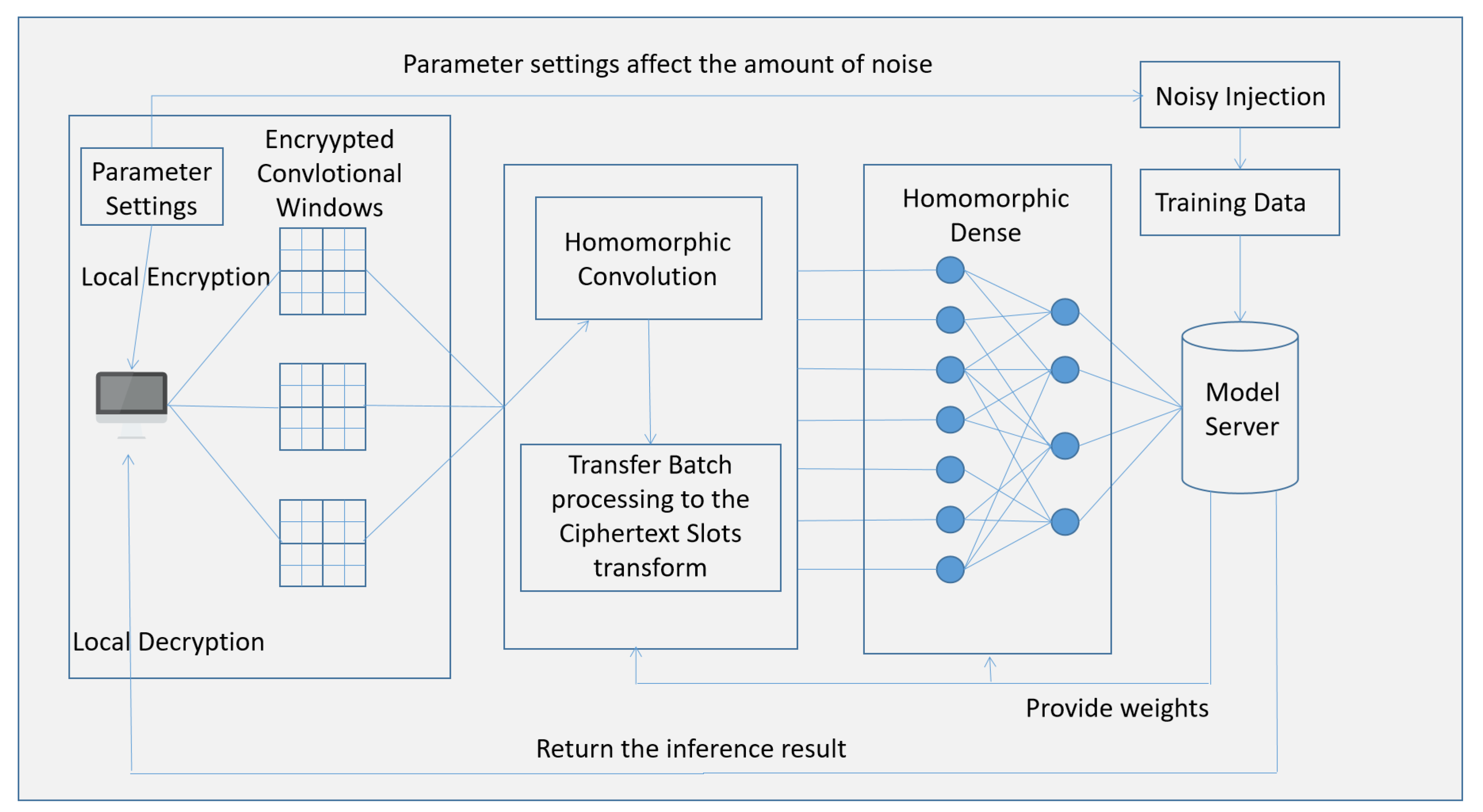
3.1. System Model
3.2. Security Model
3.3. Homomorphic Encryption Scheme
3.4. Formal Definition
- : choose a security parameter λ, generate a secret key , a public key and a key used for evaluation process;
- : for a given polynomial , output a ciphertext . For some small noisy e, the ciphertext c for message m satisfy . A constant denotes an encryption bound, i.e., error polynomial of a fresh ciphertext satisfies || with an overwhelming probability;
- : for a ciphertext c at a level ℓ, output a polynomial ;
- : for the given encrypts of , output an encryption of . An error of output ciphertext is bounded by sum of two errors in input ciphertexts;
- : for a pair of ciphertexts , output a ciphertext satisfies for some polynomial with ||;
- : for a ciphertext at level ℓ and a lower level , output the ciphertext in , i.e., is obtained by scaling to the entries of and rounding the coefficients to the closest integers. We will omit the subscript , when .
3.5. Design Goals
- Correctness: after the user correctly implements our proposed scheme, the prediction result should be correct. The correctness of homomorphic encryption schemes can be understood as follows: encrypting a plaintext, evaluating the ciphertext, and then decrypting the result is equivalent to evaluating the plaintext with the same operation to obtain the same result [4];
- Privacy: after the cloud service provider obtains the ciphertext provided by the user, it cannot obtain any valid information from the ciphertext, and can only perform certain operations on the ciphertext to achieve the user’s expected goal;
- Verifiability: after the user obtains the ciphertext returned by the cloud service provider, there is a way to verify the correctness of the result.
- Efficient: including channel transmission time and inference time, the total time should be much shorter than the user’s own local inference time.
4. Our Scheme
4.1. CNN Private Inference Scheme
4.2. Batch Processing in Inference Stage
| Algorithm 1 Image Divider |
| Input: A image I of the size h ×w(matrix), the size k× k of a kernel, and a stride s of 2 (vertical and horizontal), index of the position of image Output: conv partial of the size 1: f ← (h − k)/strides +1; 2: for i: = 0 to f do 3: for k: = 0 to f do 4: for t: = 0 to k do 5: for j: = 0 to k do 6: p[i × f + k] ← I[s × i + t][s × k + j] 7: end for 8: end for 9: end for 10: end for 11: return conv partial |
| Algorithm 2 Image Padding |
| Input: Image matrix of the size h× w, kernel size 4 (height and width), batch size bs, strides 2 (height and width), each slots of every window to batch operation Output: The k cipertexts for , each cipher stores the same position of convlution window of batch images 1: each slots ← 4 × 4 + the number of dense outputs 2: W← Imagedivider (images, kernel, 0) 3: for i: = 1 to batch size do 4: for k: = 0 to W.rows do 5: for j: = 0 to each slots- do 6: ← 0 7: end for 8: for p: = 0 to do 9: ← Imagedivider(images, kernel, i) 10: end for 11: end for 12: end for 13: for i: = 0 to W. rows do 14: ← 15: ← 16: end for 17: return S |
| Algorithm 3 Homomorphic Convlution |
| Input: A encrypted matrix(c × f) of convolution windows S, padding convlution bias vector(plaintext) B, channel c, padding convlution weights vector(plaintext) P, each row represents a channel, kernel size Output: Encrypted feature map of convlution layer output M 1: for k: = 0 to c do 2: for i: = 0 to f do 3: ← MultP(, ) 4: ← Rescale() 5: end for 6: ← ct.temp 7: end for 8: for t: = 0 to c do 9: for i: = 0 to f do 10: for j: = 0 to do 11: temp ← Rot(, exp2(j)) 12: ← Add(ct., temp) 13: end for 14: ← AddPlain(ct., ct.) 15: end for 16:end for 17: for i: = 0 to f do 18: for j: = 0 to c do 19: ← 20: end for 21: end for 22: return M |
| Algorithm 4 Homomorphic Dense | |
| Input: An activation output ciphertext vector A of the size f, dense weights matrix W of the size d × f, d is the dense layer output size, dense bias vector b of the size d× 1, each image slots s, batch size bs Output: Ciphertexts ct.D of dense output vector | |
| 1: dense weights plain dp ← 0 | ▹ |
|
2: for i: = 0 to f do 3: for j: = 0 to bs do 4: for q: = 0 to d do 5: .() 6: end for 7: for k: = 0 to s-d do 8: .(0) 9: end for 10: end for 11: ← () 12: end for 13: for i: = 0 to bs do | |
| 14: V.([1, 0, 0, …, 0, 0, 0]) | ▹ append a vector that size is bs to V evert round |
|
15: end for 16: V ← Encode(V) | |
| 17: ct.A ← MultP(ct.A,V) | ▹ Only reserve the first slot of each window |
|
18: for i: = 0 to f do 19: for j: = 0 to do | |
| 20: temp ← (, ) | ▹ Move the first slot value to other slots |
|
21: ← (temp) 22: end for 23: end for 24: for i: = 0 to f do 25: ← () 26: . 27: end for | |
| 28: ct.D ← (A) | ▹ Add f ciphertexts from A together and store into ct.D |
4.3. Dealing with Noise Effects
5. Security Analysis
6. Performance Evaluation
6.1. Numerical Analysis
6.2. Evaluation of Results
7. Discussion
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dwork, C. Differential privacy: A survey of results. In Proceedings of the International Conference on Theory and Applications of Models of Computation, Xi’an, China, 25–29 April 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–19. [Google Scholar]
- Rivest, R.L.; Adleman, L.; Dertouzos, M.L. On data banks and privacy homomorphisms. Found. Secur. Comput. 1978, 4, 169–180. [Google Scholar]
- Yao, A.C. Protocols for secure computations. In Proceedings of the 23rd Annual Symposium on Foundations of Computer Science (SFCS 1982), Chicago, IL, USA, 3–5 November 1982; pp. 160–164. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 201–210. [Google Scholar]
- Chabanne, H.; De Wargny, A.; Milgram, J.; Morel, C.; Prouff, E. Privacy-Preserving Classification on Deep Neural Network. Cryptology ePrint Archive. 2017. Available online: https://eprint.iacr.org/2017/035 (accessed on 15 November 2022).
- Chou, E.; Beal, J.; Levy, D.; Yeung, S.; Haque, A.; Li, F.F. Faster cryptonets: Leveraging sparsity for real-world encrypted inference. arXiv 2018, arXiv:1811.09953. [Google Scholar]
- Bourse, F.; Minelli, M.; Minihold, M.; Paillier, P. Fast homomorphic evaluation of deep discretized neural networks. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 483–512. [Google Scholar]
- Sanyal, A.; Kusner, M.; Gascon, A.; Kanade, V. TAPAS: Tricks to accelerate (encrypted) prediction as a service. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 4490–4499. [Google Scholar]
- Hesamifard, E.; Takabi, H.; Ghasemi, M. Cryptodl: Deep neural networks over encrypted data. arXiv 2017, arXiv:1711.05189. [Google Scholar]
- Brutzkus, A.; Gilad-Bachrach, R.; Elisha, O. Low latency privacy preserving inference. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 812–821. [Google Scholar]
- Ishiyama, T.; Suzuki, T.; Yamana, H. Highly accurate CNN inference using approximate activation functions over homomorphic encryption. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 3989–3995. [Google Scholar]
- Lu, Y.; Lin, J.; Jin, C.; Wang, Z.; Aung, K.M.M.; Li, X. FFConv: Fast factorized neural network inference on encrypted data. arXiv 2021, arXiv:2102.03494. [Google Scholar]
- Lee, J.W.; Kang, H.; Lee, Y.; Choi, W.; Eom, J.; Deryabin, M.; Lee, E.; Lee, J.; Yoo, D.; Kim, Y.S.; et al. Privacy-preserving machine learning with fully homomorphic encryption for deep neural network. IEEE Access 2022, 10, 30039–30054. [Google Scholar] [CrossRef]
- Liu, J.; Juuti, M.; Lu, Y.; Asokan, N. Oblivious neural network predictions via minionn transformations. In Proceedings of the 2017 ACM Sigsac Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 619–631. [Google Scholar]
- Juvekar, C.; Vaikuntanathan, V.; Chandrakasan, A. {GAZELLE}: A low latency framework for secure neural network inference. In Proceedings of the 27th USENIX Security Symposium (USENIX Security 18), Baltimore, MD, USA, 15–17 August 2018; pp. 1651–1669. [Google Scholar]
- Li, S.; Xue, K.; Zhu, B.; Ding, C.; Gao, X.; Wei, D.; Wan, T. Falcon: A fourier transform based approach for fast and secure convolutional neural network predictions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8705–8714. [Google Scholar]
- Kumar, N.; Rathee, M.; Chandran, N.; Gupta, D.; Rastogi, A.; Sharma, R. Cryptflow: Secure tensorflow inference. In Proceedings of the 2020 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 18–21 May 2020; pp. 336–353. [Google Scholar]
- Mishra, P.; Lehmkuhl, R.; Srinivasan, A.; Zheng, W.; Popa, R.A. DELPHI: A Cryptographic Inference Service for Neural Networks. In Proceedings of the 29th USENIX Conference on Security Symposium (SEC’20), Vancouver, BC, Canada, 16–18 August 2017. [Google Scholar]
- Ng, L.K.; Chow, S.S. GForce: GPU-Friendly Oblivious and Rapid Neural Network Inference. In Proceedings of the 30th USENIX Security Symposium (USENIX Security 21), Online, 11–13 August 2021; pp. 2147–2164. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Advances in Cryptology, Proceedings of the EUROCRYPT’99: International Conference on the Theory and Application of Cryptographic Techniques Prague, Czech Republic, 2–6 May 1999; Springer: Berlin/Heidelberg, Germany, 1999; Proceedings 18; pp. 223–238. [Google Scholar]
- Fan, J.; Vercauteren, F. Somewhat Practical Fully Homomorphic Encryption. Cryptology ePrint Archive. 2012. Available online: https://eprint.iacr.org/2012/144 (accessed on 2 November 2022).
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. ACM Trans. Comput. Theory (TOCT) 2014, 6, 1–36. [Google Scholar] [CrossRef]
- Ducas, L.; Micciancio, D. FHEW: Bootstrapping homomorphic encryption in less than a second. In Advances in Cryptology, Proceedings of the EUROCRYPT 2015: 34th Annual International Conference on the Theory and Applications of Cryptographic Techniques, Sofia, Bulgaria, 26–30 April 2015; Proceedings, Part I 34; Springer: Berlin/Heidelberg, Germany, 2015; pp. 617–640. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. TFHE: Fast fully homomorphic encryption over the torus. J. Cryptol. 2020, 33, 34–91. [Google Scholar] [CrossRef]
- Cheon, J.H.; Kim, A.; Kim, M.; Song, Y. Homomorphic encryption for arithmetic of approximate numbers. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 409–437. [Google Scholar]
- Jiang, X.; Kim, M.; Lauter, K.; Song, Y. Secure outsourced matrix computation and application to neural networks. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security, Toronto, ON, Canada, 15–19 October 2018; pp. 1209–1222. [Google Scholar]
- CIFAR-10—Canadian Institute For Advanced Research. Available online: https://www.cs.toronto.edu/~kriz/cifar.html (accessed on 1 May 2023).
- Gulli, A.; Pal, S. Deep Learning with Keras; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Microsoft SEAL (Release 4.0); Microsoft Research, Redmond, WA, USA. 2022. Available online: https://github.com/Microsoft/SEAL (accessed on 15 July 2022).
- Halevi, S.; Shoup, V. Algorithms in helib. In Advances in Cryptology, Proceedings of the CRYPTO 2014: 34th Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; Proceedings, Part I 34; Springer: Berlin/Heidelberg, Germany, 2014; pp. 554–571. [Google Scholar]
- Cheon, J.H.; Kim, A.; Yhee, D. Multi-Dimensional Packing for Heaan for Approximate Matrix Arithmetics. Cryptology ePrint Archive. 2018. Available online: https://eprint.iacr.org/2018/1245 (accessed on 15 November 2022).
- Smart, N.P.; Vercauteren, F. Fully homomorphic SIMD operations. Des. Codes Cryptogr. 2014, 71, 57–81. [Google Scholar] [CrossRef]
- Lyubashevsky, V.; Peikert, C.; Regev, O. On ideal lattices and learning with errors over rings. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, Riviera, France, 30 May–3 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 1–23. [Google Scholar]
- Gentry, C.; Halevi, S.; Smart, N.P. Homomorphic evaluation of the AES circuit. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 850–867. [Google Scholar]
- Lindner, R.; Peikert, C. Better key sizes (and attacks) for LWE-based encryption. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 14–18 February 2011; Springer: Berlin/Heidelberg, Germany, 2011; pp. 319–339. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Generation | Input Data Types | Fast Packing or Batching | Fast Bootstrapping | Applications | Deficiency |
|---|---|---|---|---|---|
| First (Gentry09 [4]) | Binary data | Supported | Unsupported | SIMD | Large ciphertext size |
| Second (BGV [23], BFV [22]) | Integer | Supported | Unsupported | Fast Escalar Multiplication | Slow Bootstrapping |
| Third (FHEW [24], TFHE [25]) | Bitwise | Unsupported | Supported | Efficient Boolean Circuits | No support for Batching |
| Fourth (CKKS [26]) | Real Number | Supported | Unsupported | Fast polynomial approx;SIMD | Slow Bootstrapping |
| Layer | Basic Model | Our Model |
|---|---|---|
| CONV | 64 input images of size , 4 kernels of size (4 channels), stride size of (3, 3) | 64 input images of size , 5 kernels of size (5 channels), stride size of (2, 2) |
| BN | None | outputs |
| ACT-1 | Squaring 256 input valus | |
| FC-1 | Fully connecting with inputs and 64 (neural nodes) outputs | Fully connecting with inputs and 100 outputs |
| BN | None | 100 outputs |
| ACT-2 | Squaring 64 input valus | |
| FC-2 | Fully connecting with 64 inputs and 10 outputs | Fully connecting with 100 inputs and 10 outputs |
| Library | BGV [23] | TFHE [25] | FHEW [24] | BFV [22] | CKKS [26] | Language |
|---|---|---|---|---|---|---|
| SEAL [30] | ✓ | ✗ | ✗ | ✓ | ✓ | C++/C |
| HElib [31] | ✓ | ✗ | ✗ | ✗ | ✓ | C++ |
| FHEW [24] | ✗ | ✗ | ✓ | ✗ | ✗ | C++ |
| TFHE [25] | ✗ | ✓ | ✗ | ✗ | ✗ | C++/C |
| HEAAN [32] | ✗ | ✗ | ✗ | ✗ | ✓ | C++ |
| Operation | Time Consumption(s) | Evaluation Times |
|---|---|---|
| Encryption | 0.43155 | |
| Multiplication(Ciphertext) | 0.00714 | |
| Multiplication(Plaintext) | 0.00198 | |
| Relinearization | 0.07435 | |
| Rescale | 0.01009 | |
| Rotation | 0.01009 | |
| Add | 0.00080 |
| Epochs | Batch Size | Learning Rate | Cosine Similarity (Noisy) | Cosine Similarity (Original) | Promotion Ratio |
|---|---|---|---|---|---|
| 10 | 64 | 10.0167 | 7.0016 | ||
| 10 | 64 | 10.2742 | 4.9816 | ||
| 20 | 64 | 23.3822 | 21.3689 | ||
| 10 | 128 | 21.5057 | 21.3939 | ||
| 15 | 128 | 17.4479 | 17.0862 | ||
| 12 | 64 | 10.0247 | 6.0178 |
| Layer | Evaluation Time (s) | Memory Consumption (mb) |
|---|---|---|
| Local Pretreatment | 0.0875 | 1539 |
| Convlutional Layer | 13.843 | 6018 |
| Activation Layer-1 | 10.65 | 27,922 |
| FC-1 | 2.425 | 2676 |
| Activation Layer-2 | 0.07 | 17 |
| FC-2 | 0.075 | 239 |
| Total | 27.15 | 38,411 |
| Framework | HE Inference Time(s) | Accuracy | Conv-Dense Multiplication |
|---|---|---|---|
| Cryptonets | 249.6 | 98.95% | |
| CryptoDL | 148.9 | 98.1% | |
| FCryptonets | 39.1 | 98.71% | |
| Ours | 27.15 | 99.05% | h |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Song, C.; Huang, R. Secure Convolution Neural Network Inference Based on Homomorphic Encryption. Appl. Sci. 2023, 13, 6117. https://doi.org/10.3390/app13106117
Song C, Huang R. Secure Convolution Neural Network Inference Based on Homomorphic Encryption. Applied Sciences. 2023; 13(10):6117. https://doi.org/10.3390/app13106117
Chicago/Turabian StyleSong, Chen, and Ruwei Huang. 2023. "Secure Convolution Neural Network Inference Based on Homomorphic Encryption" Applied Sciences 13, no. 10: 6117. https://doi.org/10.3390/app13106117