
ODIN112–AI-Assisted Emergency Services in Romania
 , ,
, ,  , , , , and
, , , , and
Abstract
:1. Introduction
- To our knowledge, the largest high-quality speech dataset of more than 150 h for Romanian available at https://echo.readerbench.com/ (accessed on 1 December 2022);
- An architecture consisting of two central components, namely Automatic Speech Recognition and Emotion Recognition models that achieve state-of-the-art results, integrated with the Romanian emergency system and designed to support the operators take timely decisions.
2. Related Work
2.1. Automatic Speech Recognition
2.1.1. Romanian Datasets
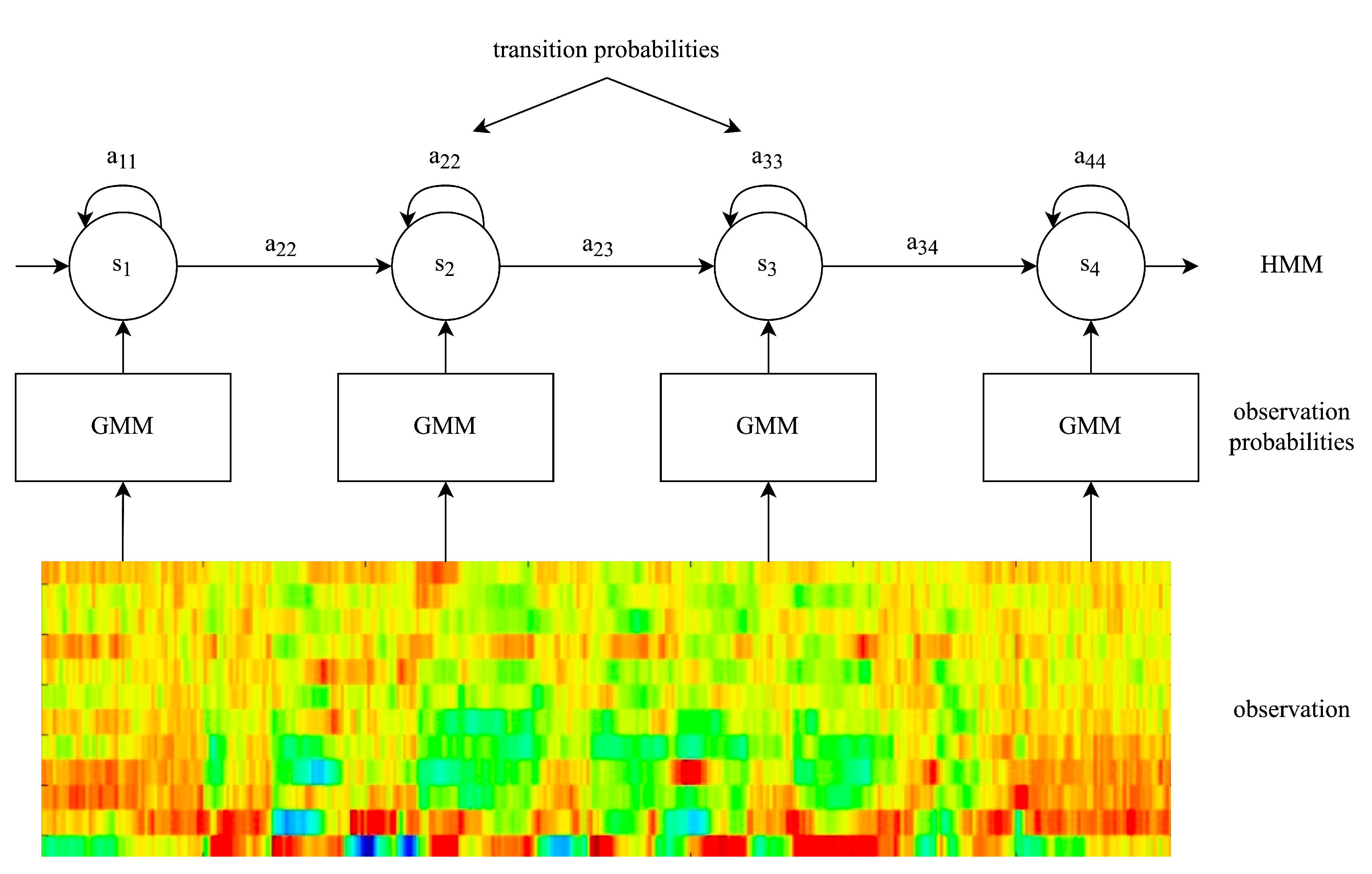
2.1.2. Hidden Markov Model-based Architectures
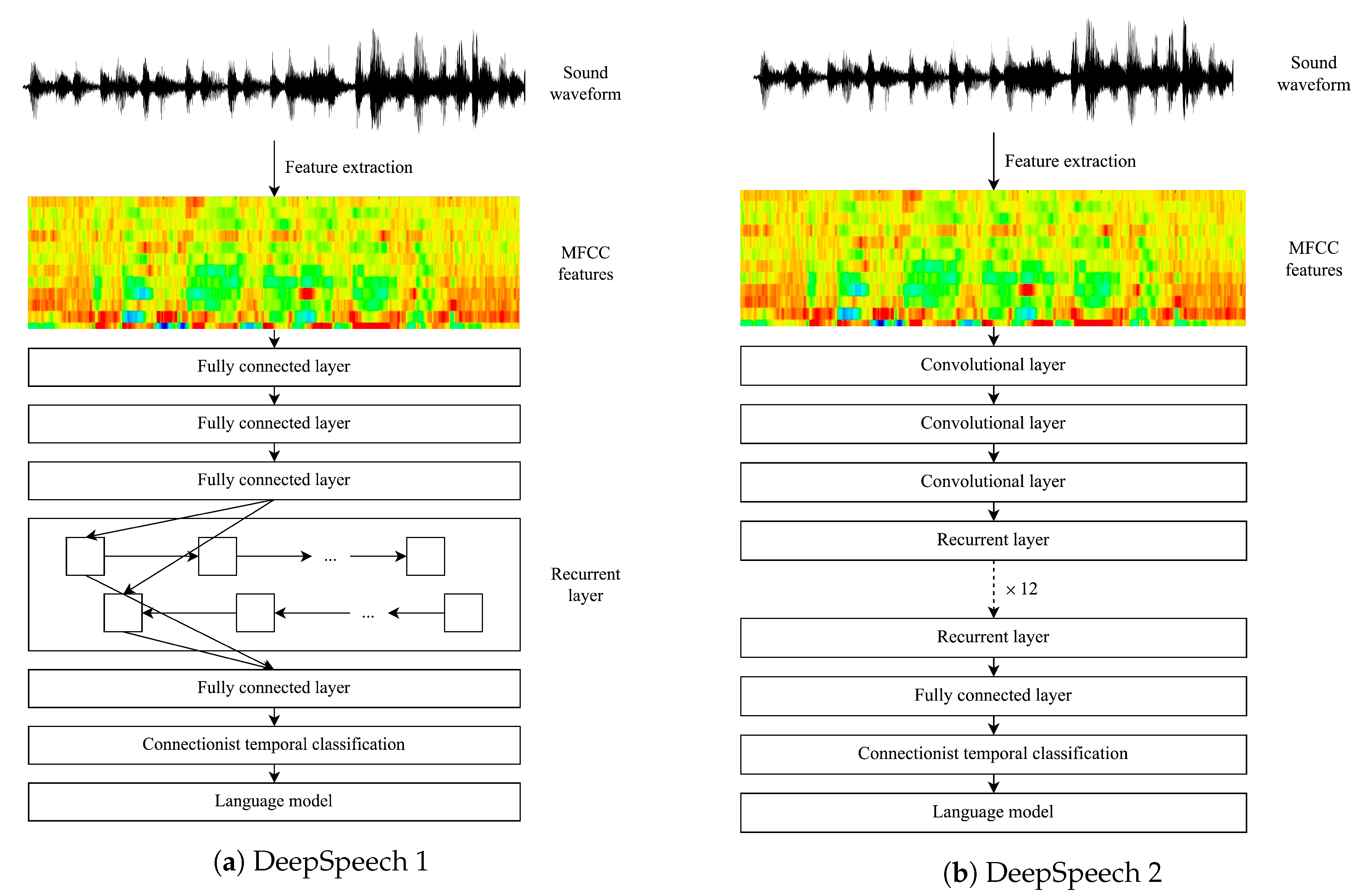
2.1.3. Deep Neural Network-Based Architectures
2.1.4. Hybrid Architectures
2.1.5. Transformer Architectures
2.2. Speech Emotion Recognition
2.2.1. Corpora
2.2.2. Models
3. Method
3.1. Corpus
Data Acquisition
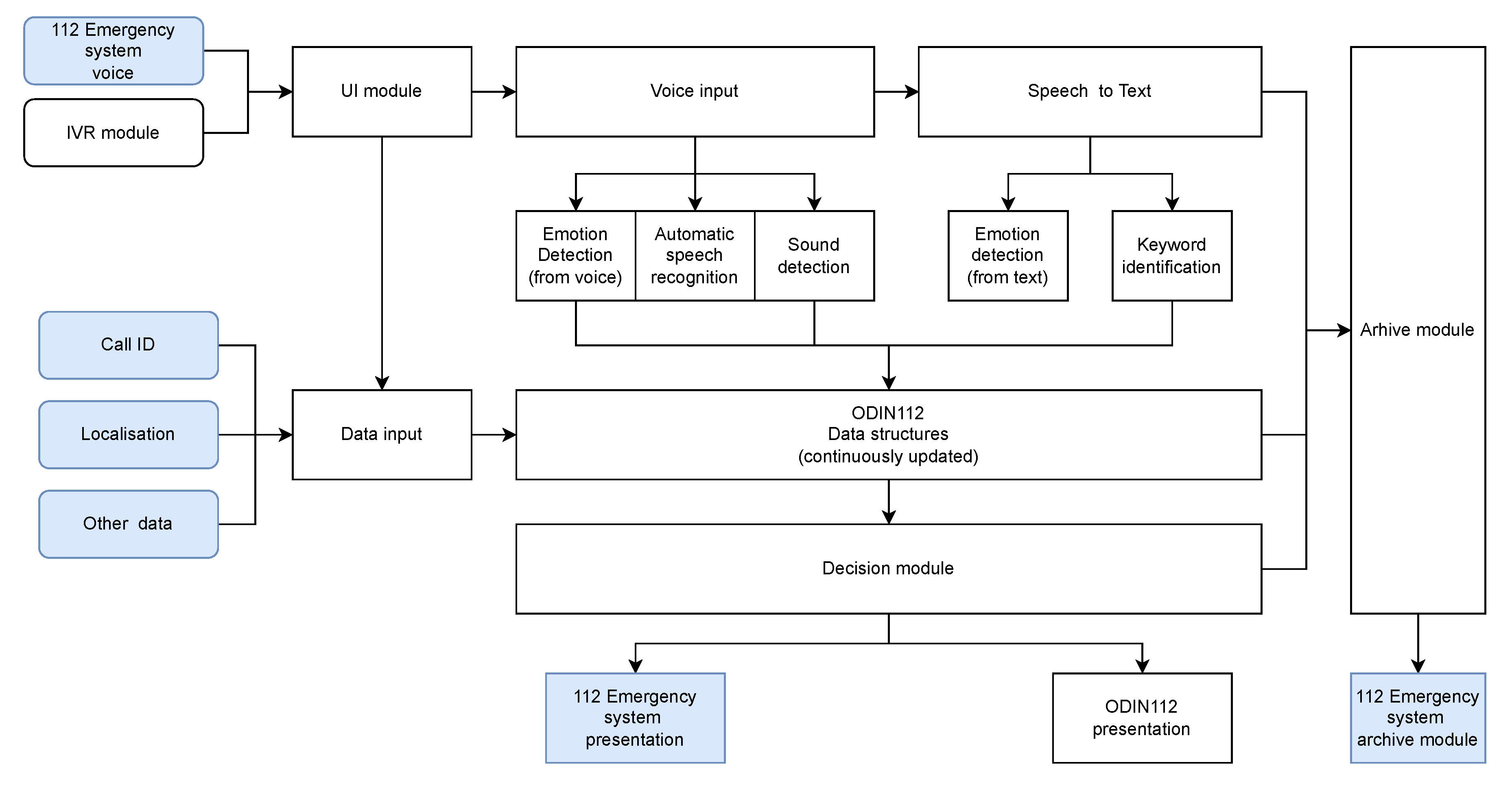
3.2. ODIN112 Architecture
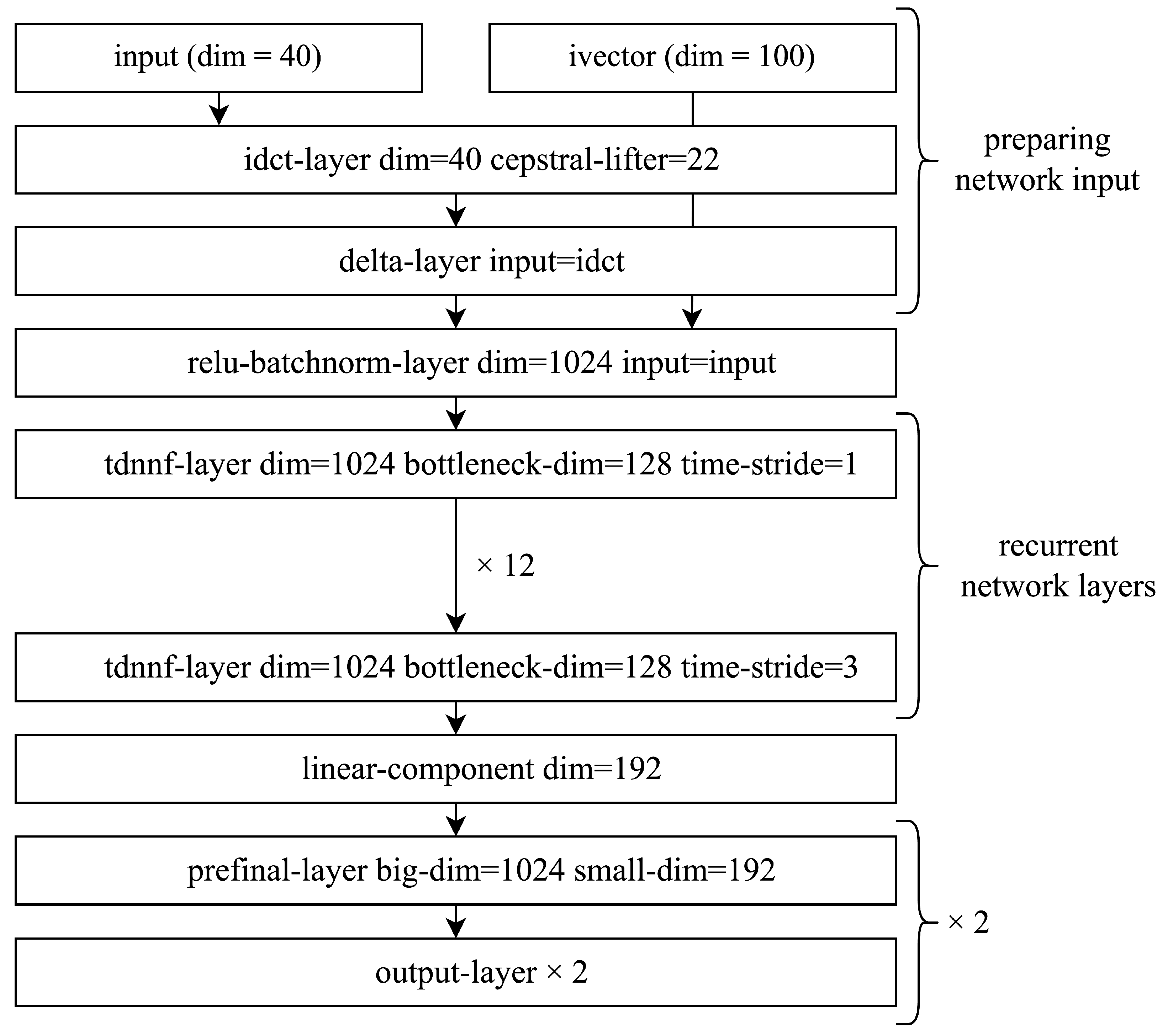
3.3. Automatic Speech Recognition Model
3.4. Speech Emotion Recognition Model
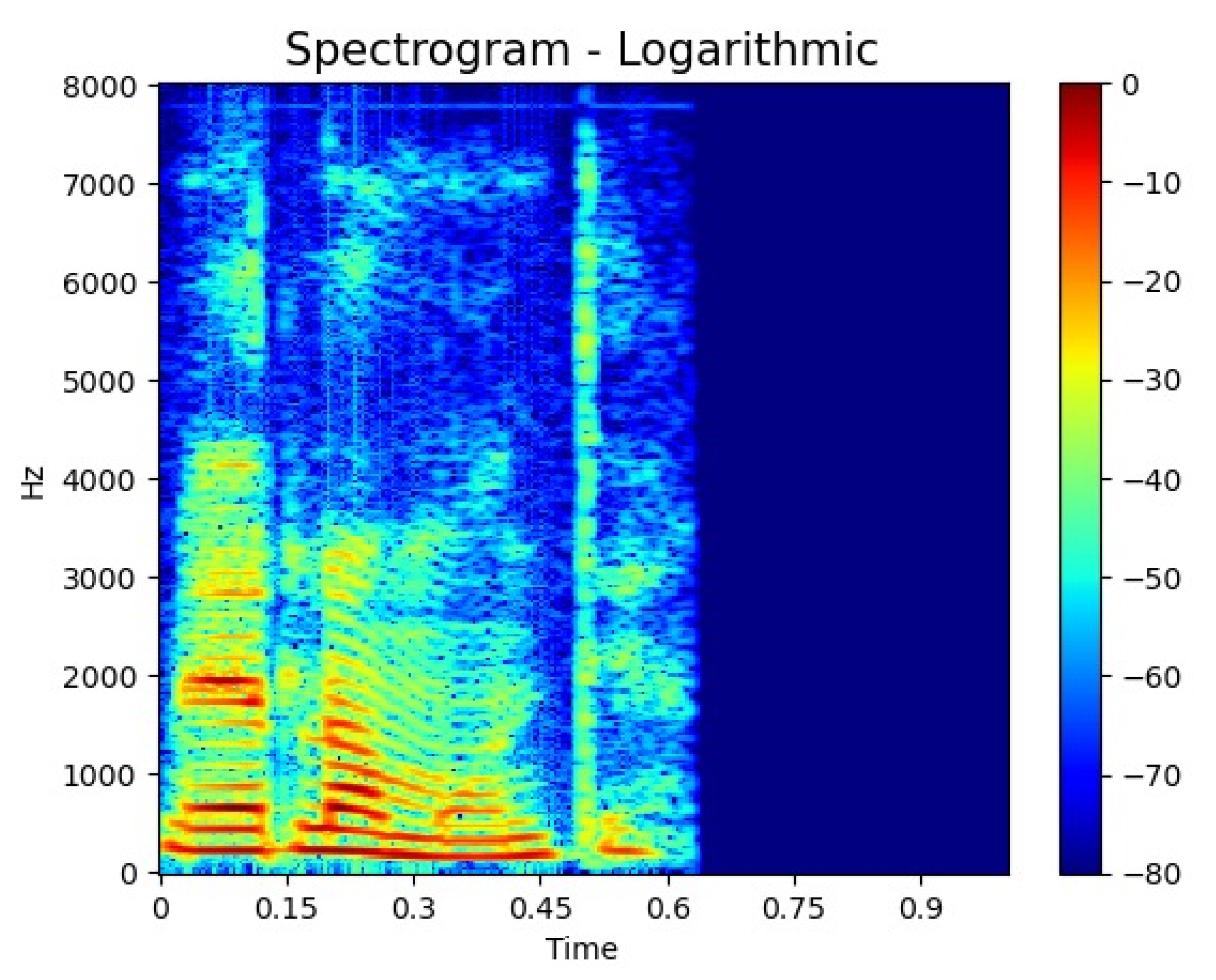
3.4.1. Speech Pre-Processing
3.4.2. Neural Network Architecture
3.5. Deployment
4. Results
4.1. Automatic Speech Recognition
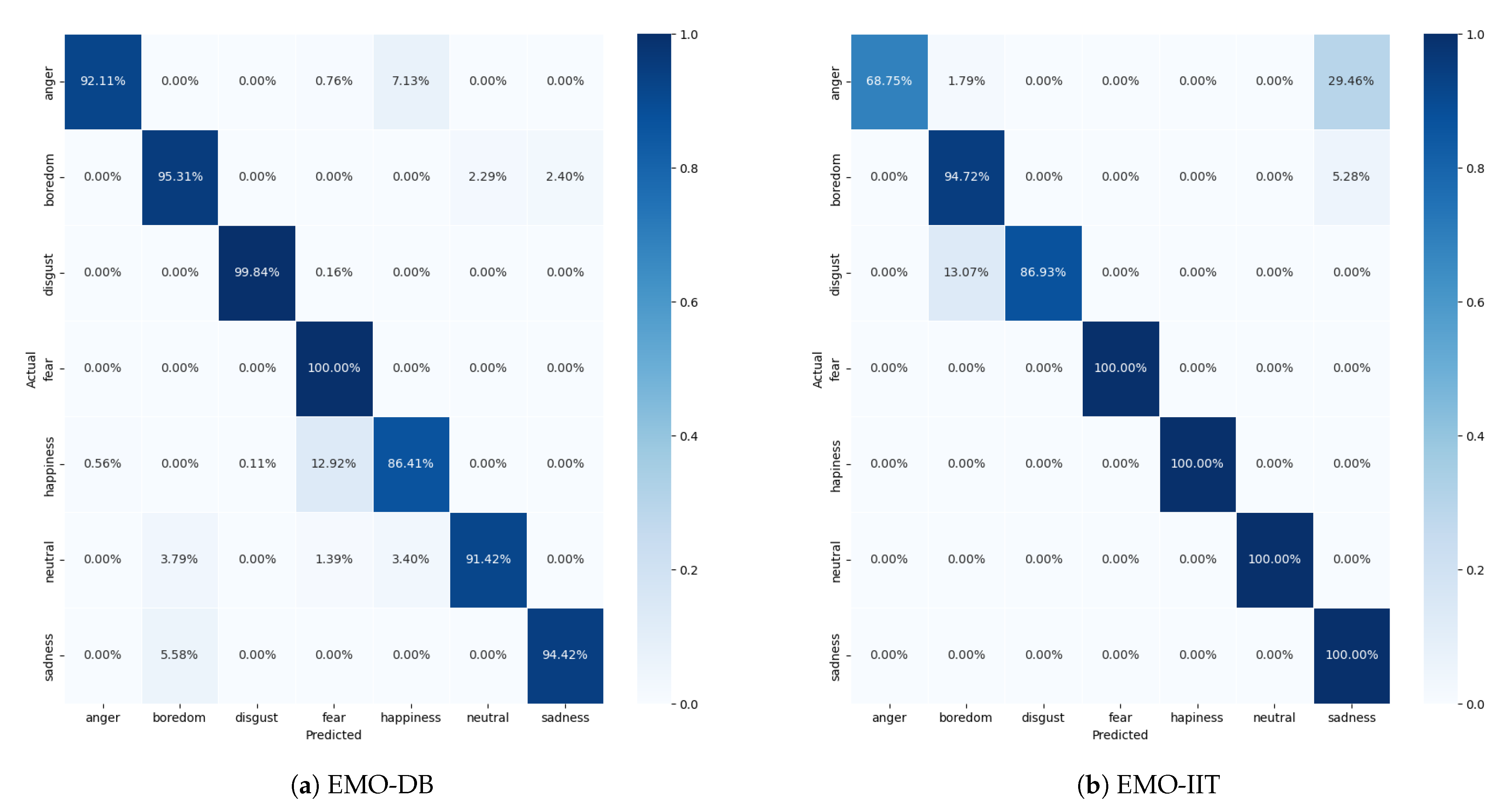
4.2. Speech Emotion Recognition
5. Discussion
5.1. Automatic Speech Recognition
5.2. Speech Emotion Recognition
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ASR | Automatic Speech Recognition |
| CMVN | Cepstral Mean and Variance Normalization |
| DNN | Deep Neural Network |
| DSL | Domain Specific Language |
| fMLLR | Feature space Maximum Likelihood Linear Regression |
| GMM | Gaussian Mixture Model |
| GPU | Graphics Processing Unit |
| GSM | Global System for Mobile communication |
| HMM | Hidden Markov Model |
| LSTM | Long Short-Term Memory |
| MFCC | Mel-Frequency Cepstral Coefficients |
| MLLT | Maximum Likelihood Linear Transform |
| NLP | Natural Language Processing |
| RNN | Recurrent Neural Network |
| SAT | Speaker Adaptive Training |
| TDNN | Time Delay Neural Network |
| WER | Word Error Rate |
References
- Zicari, R.V.; Brusseau, J.; Blomberg, S.N.; Christensen, H.C.; Coffee, M.; Ganapini, M.B.; Gerke, S.; Gilbert, T.K.; Hickman, E.; Hildt, E.; et al. On Assessing Trustworthy AI in Healthcare. Machine Learning as a Supportive Tool to Recognize Cardiac Arrest in Emergency Calls. Front. Hum. Dyn. 2021, 3. [Google Scholar] [CrossRef]
- Madsen, J.L.; Lauridsen, K.G.; Løfgren, B. In-hospital cardiac arrest call procedures and delays of the cardiac arrest team: A nationwide study. Resusc. Plus 2021, 5, 100087. [Google Scholar] [CrossRef] [PubMed]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Georgescu, A.L.; Cucu, H.; Buzo, A.; Burileanu, C. RSC: A Romanian read speech corpus for automatic speech recognition. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6606–6612. [Google Scholar]
- Rabiner, L.; Juang, B. An introduction to hidden Markov models. IEEE Assp Mag. 1986, 3, 4–16. [Google Scholar] [CrossRef]
- Reynolds, D.A. Gaussian mixture models. Encycl. Biom. 2009, 741, 659–663. [Google Scholar]
- Lamere, P.; Kwok, P.; Gouvea, E.; Raj, B.; Singh, R.; Walker, W.; Warmuth, M.; Wolf, P. The CMU SPHINX-4 speech recognition system. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 2003), Hong Kong, China, 6–10 April 2003; Volume 1, pp. 2–5. [Google Scholar]
- Ungureanu, D.; Badeanu, M.; Marica, G.C.; Dascalu, M.; Tufis, D.I. Establishing a Baseline of Romanian Speech-to-Text Models. In Proceedings of the 2021 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), Bucharest, Romania, 13–15 October 2021; pp. 132–138. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–11. [Google Scholar]
- Amodei, D.; Ananthanarayanan, S.; Anubhai, R.; Bai, J.; Battenberg, E.; Case, C.; Casper, J.; Catanzaro, B.; Cheng, Q.; Chen, G.; et al. Deep speech 2: End-to-end speech recognition in English and Mandarin. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 19–24 June 2016; pp. 173–182. [Google Scholar]
- Radford, A.; Kim, J.W.; Xu, T.; Brockman, G.; McLeavey, C.; Sutskever, I. Robust Speech Recognition via Large-Scale Weak Supervision. arXiv 2022, arXiv:2212.04356. [Google Scholar]
- Baevski, A.; Zhou, Y.; Mohamed, A.; Auli, M. wav2vec 2.0: A framework for self-supervised learning of speech representations. Adv. Neural Inf. Process. Syst. 2020, 33, 12449–12460. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Heafield, K. KenLM: Faster and smaller language model queries. In Proceedings of the Sixth Workshop on Statistical Machine Translation, Edinburgh, UK, 30–31 July 2011; pp. 187–197. [Google Scholar]
- Eckman, P.; Friesen, V.W.; Ellsworth, P. Emotion in the Human Face Guidelines for Research and an Integration of Findings Volume 11 in Pergamon General Psychology Series; Elsevier Inc.: Amsterdam, The Netherlands, 1972. [Google Scholar]
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.; Weiss, B. A database of German emotional speech. In Proceedings of the 9th European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005; Volume 5, pp. 1517–1520. [Google Scholar] [CrossRef]
- Pichora-Fuller, M.K.; Dupuis, K. Toronto emotional speech set (TESS). In Scholars Portal Dataverse; University of Toronto: Toronto, ON, Canada, 2020. [Google Scholar] [CrossRef]
- Engberg, S.I.; Hansen, A.V.; Andersen, O.; Dalsgaard, P. Design, recording and verification of a danish emotional speech database. In Proceedings of the Eurospeech, Rhodes, Greece, 22–25 September 1997. [Google Scholar]
- Costantini, G.; Iaderola, I.; Paoloni, A.; Todisco, M. EMOVO Corpus: An Italian Emotional Speech Database. In Proceedings of the Ninth International Conference on Language Resources and Evaluation (LREC’14), Reykjavik, Iceland, 26–31 May 2014; European Language Resources Association (ELRA): Reykjavik, Iceland, 2014; pp. 3501–3504. [Google Scholar]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 Audio-Visual Emotion Database. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Washington, DC, USA, 3–7 April 2006. [Google Scholar]
- Kossaifi, J.; Tzimiropoulos, G.; Todorovic, S.; Pantic, M. AFEW-VA database for valence and arousal estimation in-the-wild. Image Vis. Comput. 2017, 65, 23–36. [Google Scholar] [CrossRef]
- Feraru, M.; Zbancioc, M.D. Emotion Recognition Results using Deep Learning Neural Networks for the Romanian and German Language. In Proceedings of the 2020 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 29–30 October 2020; pp. 1–4. [Google Scholar] [CrossRef]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A Comprehensive Review of Speech Emotion Recognition Systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Badshah, A.M.; Ahmad, J.; Rahim, N.; Baik, S.W. Speech emotion recognition from spectrograms with deep convolutional neural network. In Proceedings of the 2017 International Conference on Platform Technology and Service (PlatCon), Busan, Republic of Korea, 13–15 February 2017. [Google Scholar]
- Mirsamadi, S.; Barsoum, E.; Zhang, C. Automatic speech emotion recognition using recurrent neural networks with local attention. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017. [Google Scholar]
- Zbancioc, M.D.; Feraru, S.M. Emotion Recognition for Romanian Language Using MFSC Images with Deep-Learning Neural Networks. In Proceedings of the 2021 International Conference on e-Health and Bioengineering (EHB), Iasi, Romania, 18–19 November 2021; pp. 1–4. [Google Scholar] [CrossRef]
- Rudd, D.H.; Huo, H.; Xu, G. Leveraged Mel Spectrograms Using Harmonic and Percussive Components in Speech Emotion Recognition. In Advances in Knowledge Discovery and Data Mining; Gama, J., Li, T., Yu, Y., Chen, E., Zheng, Y., Teng, F., Eds.; Springer International Publishing: Cham, Switzerland, 2022; pp. 392–404. [Google Scholar]
- Lech, M.; Stolar, M.; Best, C.; Bolia, R. Real-Time Speech Emotion Recognition Using a Pre-trained Image Classification Network: Effects of Bandwidth Reduction and Companding. Front. Comput. Sci. 2020, 2, 14. [Google Scholar] [CrossRef]
- Sun, L.; Fu, S.; Wang, F. Decision tree SVM model with Fisher feature selection for speech emotion recognition. EURASIP J. Audio Speech Music. Process. 2019, 2019, 2. [Google Scholar] [CrossRef] [Green Version]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition. arXiv 2019, arXiv:1904.08779. [Google Scholar]
- Mocanu, B.C.; Filip, I.D.; Ungureanu, R.D.; Negru, C.; Dascalu, M.; Toma, S.A.; Balan, T.C.; Bica, I.; Pop, F. ODIN IVR-Interactive Solution for Emergency Calls Handling. Appl. Sci. 2022, 12, 10844. [Google Scholar] [CrossRef]
- Masala, M.; Ruseti, S.; Dascalu, M. Robert–a romanian bert model. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain, 8–13 December 2020; pp. 6626–6637. [Google Scholar]
- Mermelstein, P. Distance measures for speech recognition, psychological and instrumental. Pattern Recognit. Artif. Intell. 1976, 116, 374–388. [Google Scholar]
- Dehak, N.; Kenny, P.J.; Dehak, R.; Dumouchel, P.; Ouellet, P. Front-end factor analysis for speaker verification. IEEE Trans. Audio Speech Lang. Process. 2010, 19, 788–798. [Google Scholar] [CrossRef]
- Snyder, D.; Garcia-Romero, D.; Povey, D. Time delay deep neural network-based universal background models for speaker recognition. In Proceedings of the 2015 IEEE Workshop on Automatic Speech Recognition and Understanding (ASRU), Scottsdale, AZ, USA, 13–17 December 2015; pp. 92–97. [Google Scholar]
- Povey, D.; Zhang, X.; Khudanpur, S. Parallel training of DNNs with natural gradient and parameter averaging. arXiv 2014, arXiv:1410.7455. [Google Scholar]
- Vary, P.; Hellwig, K.; Hofmann, R.; Sluyter, R.; Galand, C.; Rosso, M. Speech codec for the European mobile radio system. In Proceedings of the ICASSP-88, International Conference on Acoustics, Speech, and Signal Processing, New York, NY, USA, 11–14 April 1988; Volume 1, pp. 227–230. [Google Scholar] [CrossRef]
- Holma, H.; Melero, J.; Vainio, J.; Halonen, T.; Makinen, J. Performance of adaptive multirate (AMR) voice in GSM and WCDMA. In Proceedings of the The 57th IEEE Semiannual Vehicular Technology Conference, 2003. VTC 2003-Spring., Jeju, Republic of Korea, 22–25 April 2003; Volume 4, pp. 2177–2181. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- Stan, A.; Dinescu, F.; Ţiple, C.; Meza, Ş.; Orza, B.; Chirilă, M.; Giurgiu, M. The SWARA speech corpus: A large parallel Romanian read speech dataset. In Proceedings of the 2017 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), Bucharest, Romania, 6–9 July 2017; pp. 1–6. [Google Scholar]
- Georgescu, A.L.; Cucu, H.; Burileanu, C. Kaldi-based DNN Architectures for Speech Recognition in Romanian. In Proceedings of the 2019 International Conference on Speech Technology and Human-Computer Dialogue (SpeD), Timisoara, Romania, 10–12 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Popova, A.S.; Rassadin, A.G.; Ponomarenko, A. Emotion Recognition in Sound; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Zhao, J.; Mao, X.; Chen, L. Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomed. Signal Process. Control. 2019, 47, 312–323. [Google Scholar]
- Issa, D.; Demirci, M.F.; Yazıcı, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | Duration | Recordings | Unique Transcripts | Unique Word Count | Speakers |
|---|---|---|---|---|---|
| Chamber of Deputies (eval) | 4 h | 296 | 296 | 7084 | N/A |
| IIT | 18 h | 8877 | 8619 | 30,327 | 98 |
| RACAI | 11 h | 3404 | 2646 | 15,877 | 3 |
| RADOR | 50 h | 16,180 | 15,530 | 50,782 | N/A |
| RASC | 4 h | 2976 | 2972 | 14,113 | N/A |
| Robin | 1 h | 400 | 194 | 2165 | 4 |
| RoDigits | 37 h | 15,389 | 100 | 10 | 154 |
| Romanian Read-Speech [4] | 99 h | 136,120 | 11,924 | 18,485 | 164 |
| SSC (eval) | 5 h | 3135 | 3008 | 11,291 | N/A |
| SWARA | 21 h | 19,292 | 1803 | 6102 | 17 |
| Various | 32 h | 18,568 | 15,419 | 36,174 | 3444+ |
| Data Set | Duration | Recordings | Unique Transcripts | Unique Word Count | Speakers |
|---|---|---|---|---|---|
| Drama | 6 h | 4146 | 523 | 2724 | 77 |
| Emergencies | 10 h | 6937 | 1309 | 822 | 205 |
| Legal | 13 h | 4101 | 577 | 3079 | 76 |
| Narratives | 23 h | 10,978 | 482 | 7961 | 81 |
| News | 11 h | 4879 | 168 | 4391 | 76 |
| Poetry | 3 h | 917 | 112 | 1836 | 71 |
| Wikipedia | 92 h | 35,754 | 1001 | 7509 | 212 |
| Echo Total | 155 h | 66,795 | 4059 | 22,521 | 215 |
| Age | 19 | 20 | 21 | 22 | 23 | 24 | 25+ | N/A | Total |
|---|---|---|---|---|---|---|---|---|---|
| Count | 3 | 15 | 10 | 37 | 22 | 14 | 8 | 106 | 215 |
| Gender | Male | Female | N/A | Total |
|---|---|---|---|---|
| 41 | 71 | 103 | 215 |
| Parameter | Value |
|---|---|
| Optimization algorithm | SGDM |
| Mini-batch size | 32 |
| Maximum number of epochs | 13 |
| Stochastic gradient descent momentum | 0.9 |
| Initial learning rate | 0.0001% |
| Learning rate decay | 0.0001% |
| Subset | Train [hours] | Test [hours] | Total [hours] | |
|---|---|---|---|---|
| Dataset | ||||
| SWARA | 19 | 2 | 21 | |
| RSC | 92 | 5 | 97 | |
| Echo | 141 | 14 | 155 | |
| All | 394 | 62 | 456 | |
| Corpus | Weighted Accuracy | 5-Fold Cross-Validation Weighted Accuracy |
|---|---|---|
| EMO-DB | 94.46% | 92.28% |
| EMO-IIT | 94.98% | 90.24% |
| EMO-DB GSM | 88.57% | 83.86% |
| EMO-IIT GSM | 93.46% | 91.20% |
| Train Set | SWARA [%WER] | RSC [%WER] | Echo [%WER] | All [%WER] | |
|---|---|---|---|---|---|
| Test Set | |||||
| SWARA | 3.28% | 6.01% | 4.42% | 2.99% | |
| RSC | 13.30% | 4.36% | 4.40% | 3.32% | |
| Echo | 37.21% | 11.90% | 4.97% | 5.29% | |
| All | 35.38% | 13.89% | 4.82% | 5.94% | |
| Works | EMO-IIT Original/GSM | Classifier | Speech Features | Test Set | Result |
|---|---|---|---|---|---|
| Feraru and Zbancioc [24] | original | DL-CNN | Mel spectrograms&MFCCs | CV-10 folds | 84.48% A |
| Zbancioc and Feraru [28] | original | DL-CNN | Mel spectrograms | CV-10 folds | 84.71% A |
| Our model | original | VGG16 | Log spectrograms | CV-5 folds | 90.24% WA |
| GSM | 91.20% WA |
| Works | EMO-IIT Original/GSM | Classifier Type | Speech Features | Test Set | Result |
|---|---|---|---|---|---|
| Popova et al. [44] | original | VGG16 | Mel spectrograms | 70/30 random split | 71.00% A |
| Issa et al. [46] | original | VGG16 | MFCC&chroma& Mel spectrogram& contrast&tonnetz | CV-5 folds | 86.10% A |
| Zhao et al. [45] | original | CNN-LSTM | Mel spectrograms | CV-5 folds | 95.89% A |
| Rudd et al. [29] | original | VGG16-MLP | HP & Mel spectrograms | 80/10/10 random split | 92.79% A |
| Lech et al. [30] | original | AlexNet | Mel spectrograms | CV-10 folds | 80.50% WA |
| GSM | 76.80% WA | ||||
| Our model | original | VGG16 | log Spectrograms | CV-5 folds | 92.28% WA |
| GSM | 83.86% WA |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ungureanu, D.; Toma, S.-A.; Filip, I.-D.; Mocanu, B.-C.; Aciobăniței, I.; Marghescu, B.; Balan, T.; Dascalu, M.; Bica, I.; Pop, F. ODIN112–AI-Assisted Emergency Services in Romania. Appl. Sci. 2023, 13, 639. https://doi.org/10.3390/app13010639
Ungureanu D, Toma S-A, Filip I-D, Mocanu B-C, Aciobăniței I, Marghescu B, Balan T, Dascalu M, Bica I, Pop F. ODIN112–AI-Assisted Emergency Services in Romania. Applied Sciences. 2023; 13(1):639. https://doi.org/10.3390/app13010639
Chicago/Turabian StyleUngureanu, Dan, Stefan-Adrian Toma, Ion-Dorinel Filip, Bogdan-Costel Mocanu, Iulian Aciobăniței, Bogdan Marghescu, Titus Balan, Mihai Dascalu, Ion Bica, and Florin Pop. 2023. "ODIN112–AI-Assisted Emergency Services in Romania" Applied Sciences 13, no. 1: 639. https://doi.org/10.3390/app13010639