
Lamb Behaviors Analysis Using a Predictive CNN Model and a Single Camera

 , , ,
, , ,  , ,
, ,  ,
,  and
and 
Abstract
:1. Introduction
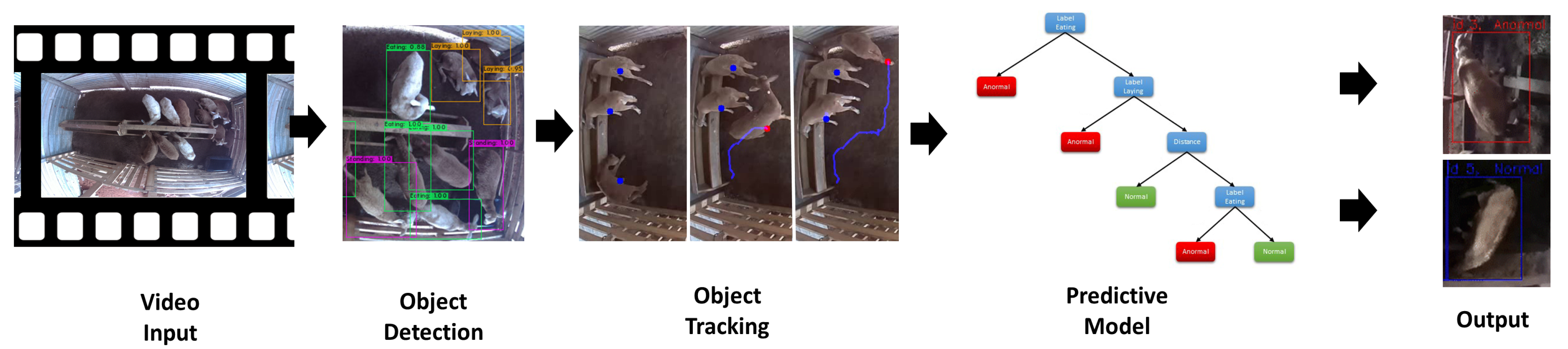
2. Materials and Methods
2.1. Video Input
2.1.1. Animals and Test Facility
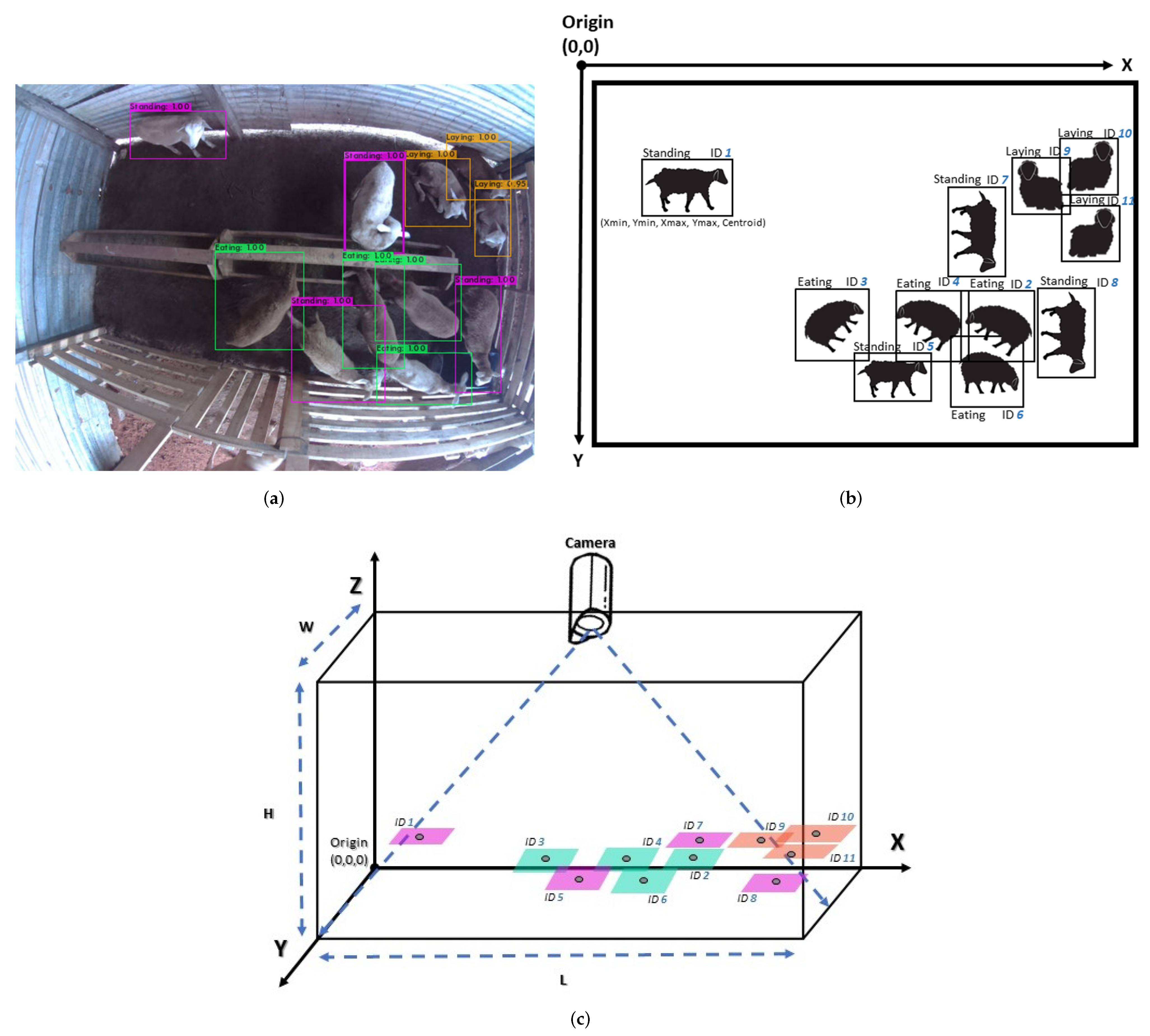
2.1.2. Spatial Distribution of the System and Video Recordings
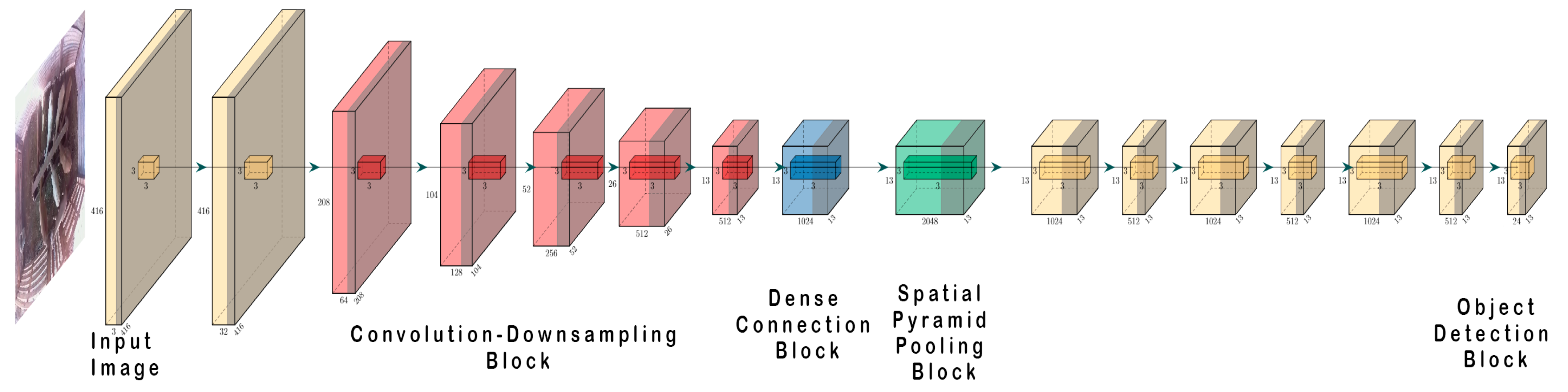
2.2. Object Detection
2.2.1. Automatic Detection of Lambs Activities
2.2.2. Dataset and Labeling Lamb Images
2.2.3. Data Augmentation
2.2.4. Evaluation Procedures and Metrics
- True positive (TP).
- False positive (FP).
- False negative (FN).
- True negative (TN).
- Based on the confidence score, sort all detections.
- Take detections with the highest confidence scores and match them to the ground truth until a recall r higher than the expected r level is reached.
- Calculate precision values based on each level of recall r.
- Interpolate the precision by the maximum precision obtained for a recall level r.
Tracking Metrics
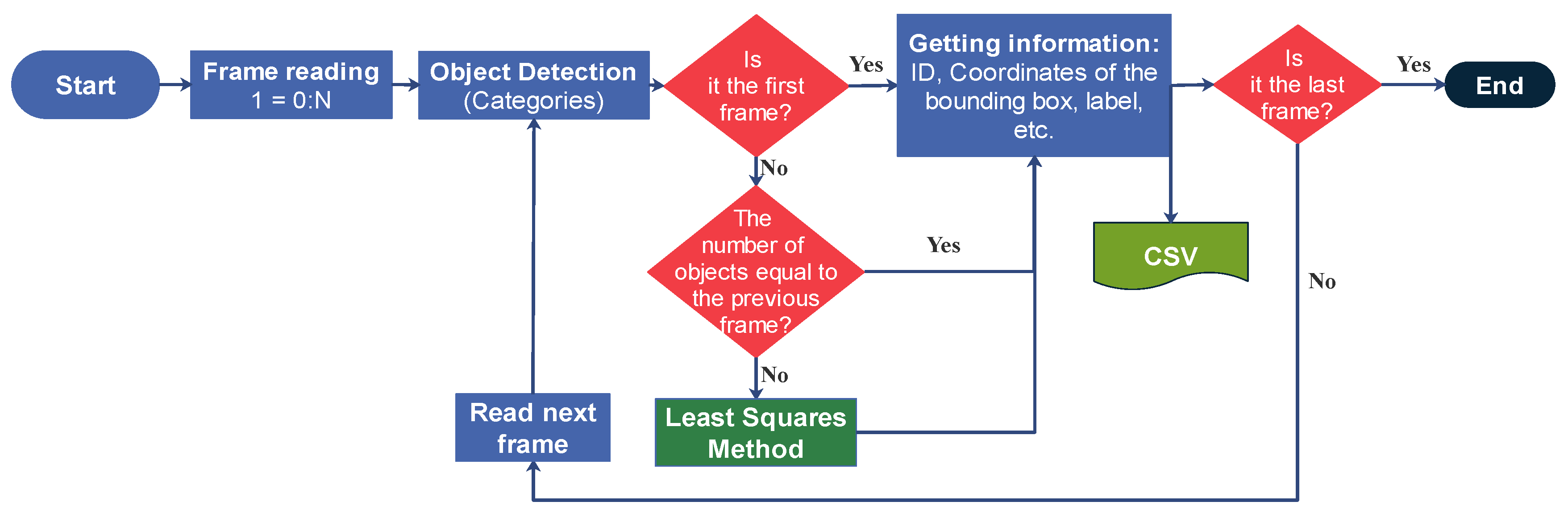
2.3. Object Tracking
Coordinate System
3. Results
3.1. Object Detection Evaluation
Object Detection Performance
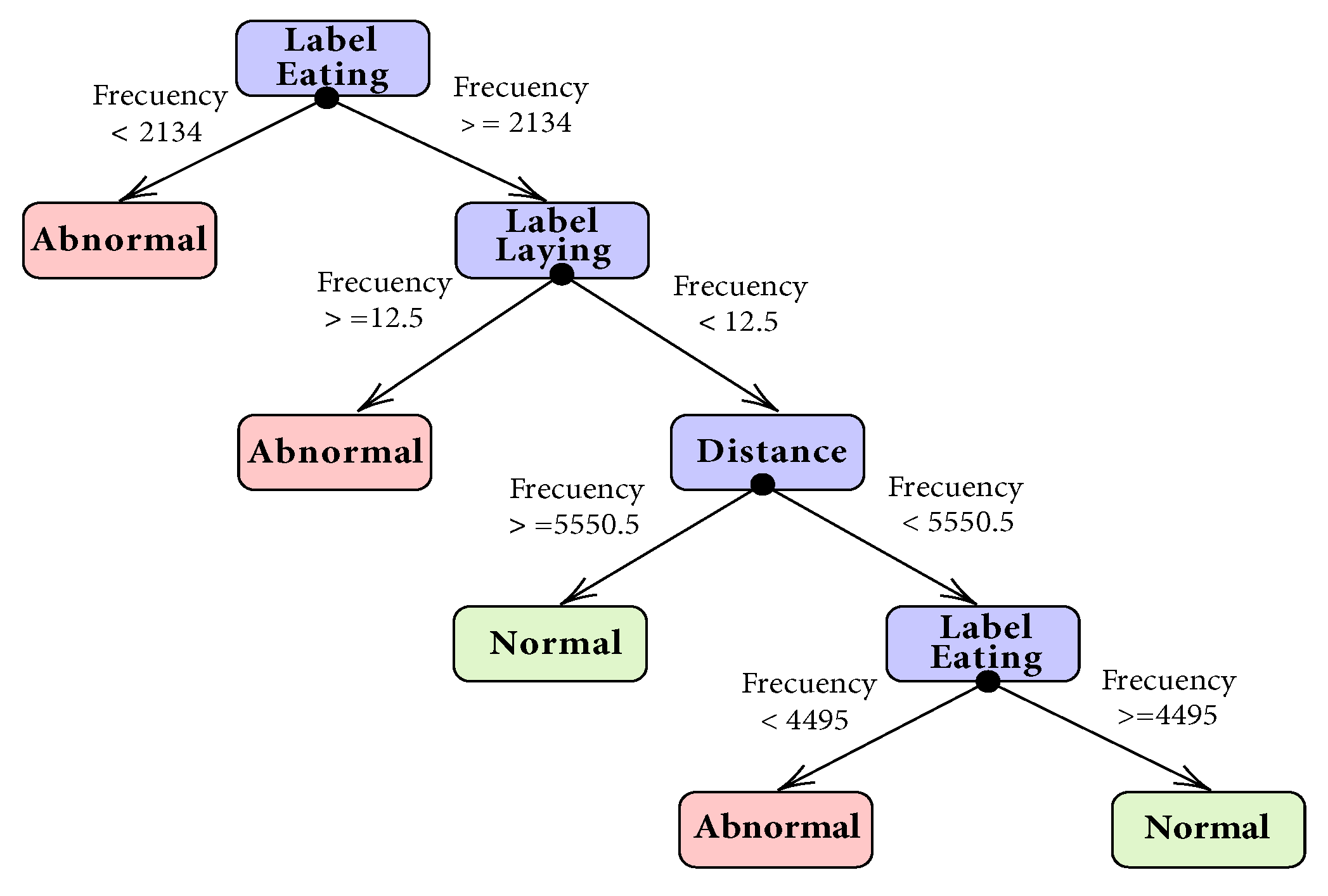
3.2. Predictive Model
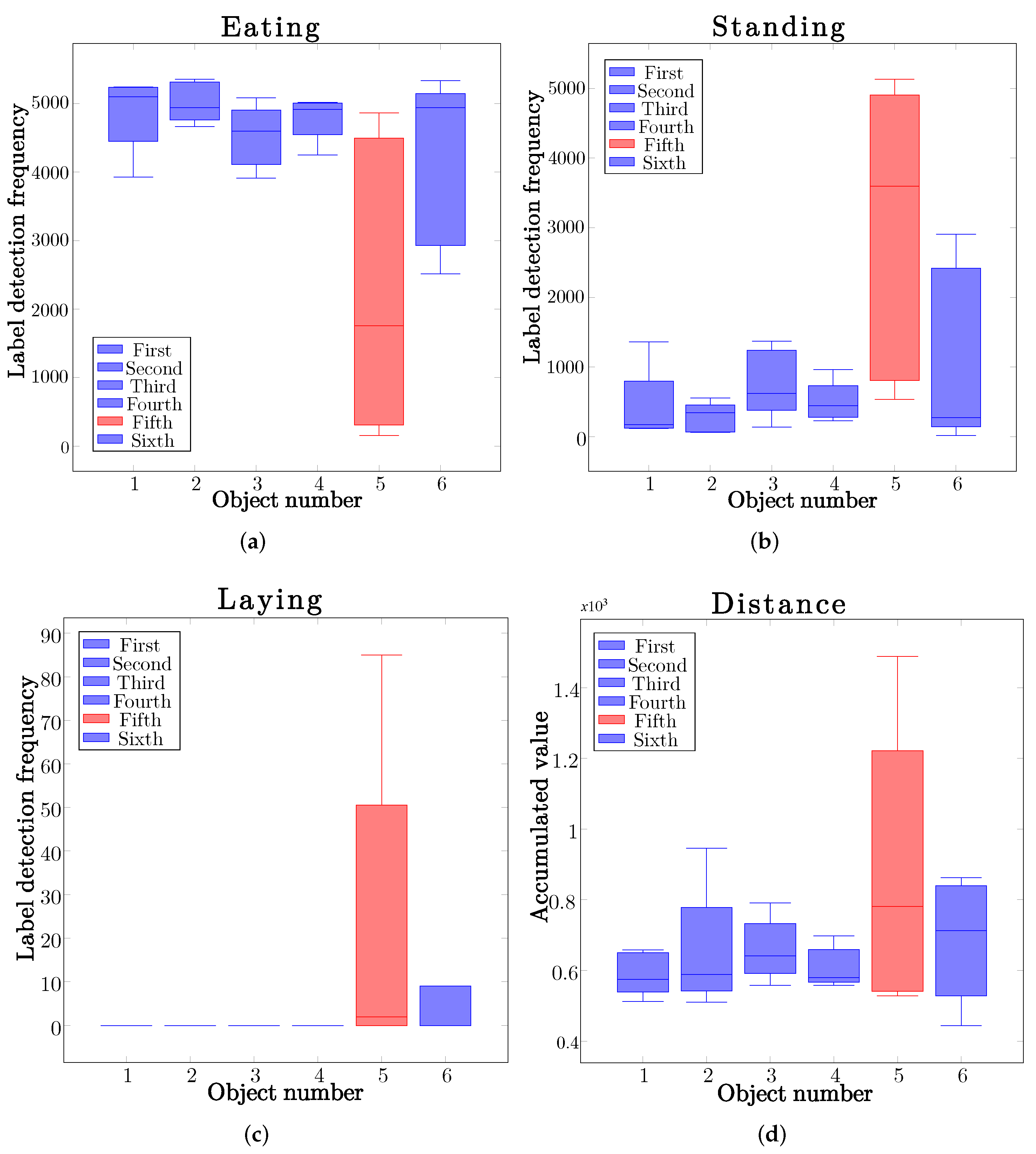
Label Detection Frequency and Cumulative Distance
3.3. Output
4. Discussion
Limitations
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AP | Average precision |
| BB | Bounding box |
| CNN | Convolutional neural networks |
| FN | False negative |
| IoU | Intersection over union |
| mAP | mean average precision |
| TP | True positive |
| YOLO | You only look once |
References
- Poursaberi, A.; Bahr, C.; Pluk, A.; Van Nuffel, A.; Berckmans, D. Real-time automatic lameness detection based on back posture extraction in dairy cattle: Shape analysis of cow with image processing techniques. Comput. Electron. Agric. 2010, 74, 110–119. [Google Scholar] [CrossRef]
- Nasiri, A.; Yoder, J.; Zhao, Y.; Hawkins, S.; Prado, M.; Gan, H. Pose estimation-based lameness recognition in broiler using CNN-LSTM network. Comput. Electron. Agric. 2022, 197, 106931. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Hensel, O.; Edwards, S.A.; Sturm, B. A new approach for categorizing pig lying behaviour based on a Delaunay triangulation method. Animal 2017, 11, 131–139. [Google Scholar] [CrossRef] [Green Version]
- Menchetti, L.; Nanni Costa, L.; Zappaterra, M.; Padalino, B. Effects of Reduced Space Allowance and Heat Stress on Behavior and Eye Temperature in Unweaned Lambs: A Pilot Study. Animals 2021, 11, 3464. [Google Scholar] [CrossRef] [PubMed]
- Jiang, M.; Rao, Y.; Zhang, J.; Shen, Y. Automatic behavior recognition of group-housed goats using deep learning. Comput. Electron. Agric. 2020, 177, 105706. [Google Scholar] [CrossRef]
- Massari, J.M.; de Moura, D.J.; de Alencar Nääs, I.; Pereira, D.F.; Branco, T. Computer-Vision-Based Indexes for Analyzing Broiler Response to Rearing Environment: A Proof of Concept. Animals 2022, 12, 846. [Google Scholar] [CrossRef]
- Adrion, F.; Kapun, A.; Eckert, F.; Holland, E.M.; Staiger, M.; Götz, S.; Gallmann, E. Monitoring trough visits of growing-finishing pigs with UHF-RFID. Comput. Electron. Agric. 2018, 144, 144–153. [Google Scholar] [CrossRef]
- Wang, G.; Muhammad, A.; Liu, C.; Du, L.; Li, D. Automatic Recognition of Fish Behavior with a Fusion of RGB and Optical Flow Data Based on Deep Learning. Animals 2021, 11, 2774. [Google Scholar] [CrossRef]
- Condotta, I.C.; Brown-Brandl, T.M.; Silva-Miranda, K.O.; Stinn, J.P. Evaluation of a depth sensor for mass estimation of growing and finishing pigs. Biosyst. Eng. 2018, 173, 11–18. [Google Scholar] [CrossRef]
- Pezzuolo, A.; Guarino, M.; Sartori, L.; González, L.A.; Marinello, F. On-barn pig weight estimation based on body measurements by a Kinect v1 depth camera. Comput. Electron. Agric. 2018, 148, 29–36. [Google Scholar] [CrossRef]
- Schütz, A.K.; Krause, E.T.; Fischer, M.; Müller, T.; Freuling, C.M.; Conraths, F.J.; Homeier-Bachmann, T.; Lentz, H.H. Computer Vision for Detection of Body Posture and Behavior of Red Foxes. Animals 2022, 12, 233. [Google Scholar] [CrossRef] [PubMed]
- Lee, Y.D.; Lee, H.; Yoon, E.; Park, C.; Osborg, E.S.; Løvall, K. A Comparative Assessment of Mid-Water Trawl and Deep Vision for Investigating Fishery Resources in the Coastal Waters off Jeju Island, Korea. Appl. Sci. 2022, 12, 1835. [Google Scholar] [CrossRef]
- Nasirahmadi, A.; Richter, U.; Hensel, O.; Edwards, S.; Sturm, B. Using machine vision for investigation of changes in pig group lying patterns. Comput. Electron. Agric. 2015, 119, 184–190. [Google Scholar] [CrossRef] [Green Version]
- Khojastehkey, M.; Aslaminejad, A.A.; Shariati, M.M.; Dianat, R. Body size estimation of new born lambs using image processing and its effect on the genetic gain of a simulated population. J. Appl. Anim. Res. 2016, 44, 326–330. [Google Scholar] [CrossRef] [Green Version]
- Burghardt, T.; Calic, J. Analysing animal behaviour in wildlife videos using face detection and tracking. IEE Proc.-Vis. Image Signal Process. 2006, 153, 305–312. [Google Scholar] [CrossRef] [Green Version]
- Stern, U.; He, R.; Yang, C.H. Analyzing animal behavior via classifying each video frame using convolutional neural networks. Sci. Rep. 2015, 5, 1–13. [Google Scholar]
- Zhao, K.; Bewley, J.; He, D.; Jin, X. Automatic lameness detection in dairy cattle based on leg swing analysis with an image processing technique. Comput. Electron. Agric. 2018, 148, 226–236. [Google Scholar] [CrossRef]
- Kang, X.; Zhang, X.; Liu, G. Accurate detection of lameness in dairy cattle with computer vision: A new and individualized detection strategy based on the analysis of the supporting phase. J. Dairy Sci. 2020, 103, 10628–10638. [Google Scholar] [CrossRef]
- Noor, A.; Zhao, Y.; Koubaa, A.; Wu, L.; Khan, R.; Abdalla, F.Y. Automated sheep facial expression classification using deep transfer learning. Comput. Electron. Agric. 2020, 175, 105528. [Google Scholar] [CrossRef]
- Guo, Y.; He, D.; Chai, L. A machine vision-based method for monitoring scene-interactive behaviors of dairy calf. Animals 2020, 10, 190. [Google Scholar] [CrossRef] [Green Version]
- Jung, D.H.; Kim, N.Y.; Moon, S.H.; Jhin, C.; Kim, H.J.; Yang, J.S.; Kim, H.S.; Lee, T.S.; Lee, J.Y.; Park, S.H. Deep learning-based cattle vocal classification model and real-time livestock monitoring system with noise filtering. Animals 2021, 11, 357. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Li, D.; Huang, J.; Chen, Y. Automated video behavior recognition of pigs using two-stream convolutional networks. Sensors 2020, 20, 1085. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brünger, J.; Traulsen, I.; Koch, R. Model-based detection of pigs in images under sub-optimal conditions. Comput. Electron. Agric. 2018, 152, 59–63. [Google Scholar] [CrossRef]
- D’Eath, R.B.; Jack, M.; Futro, A.; Talbot, D.; Zhu, Q.; Barclay, D.; Baxter, E.M. Automatic early warning of tail biting in pigs: 3D cameras can detect lowered tail posture before an outbreak. PLoS ONE 2018, 13, e0194524. [Google Scholar] [CrossRef] [Green Version]
- Fogarty, E.S.; Swain, D.L.; Cronin, G.M.; Moraes, L.E.; Bailey, D.W.; Trotter, M.G. Potential for autonomous detection of lambing using global navigation satellite system technology. Anim. Prod. Sci. 2020, 60, 1217–1226. [Google Scholar] [CrossRef]
- Viazzi, S.; Ismayilova, G.; Oczak, M.; Sonoda, L.T.; Fels, M.; Guarino, M.; Vranken, E.; Hartung, J.; Bahr, C.; Berckmans, D. Image feature extraction for classification of aggressive interactions among pigs. Comput. Electron. Agric. 2014, 104, 57–62. [Google Scholar] [CrossRef]
- Tassinari, P.; Bovo, M.; Benni, S.; Franzoni, S.; Poggi, M.; Mammi, L.M.E.; Mattoccia, S.; Di Stefano, L.; Bonora, F.; Barbaresi, A.; et al. A computer vision approach based on deep learning for the detection of dairy cows in free stall barn. Comput. Electron. Agric. 2021, 182, 106030. [Google Scholar] [CrossRef]
- Li, G.; Hui, X.; Chen, Z.; Chesser, G.D., Jr.; Zhao, Y. Development and evaluation of a method to detect broilers continuously walking around feeder as an indication of restricted feeding behaviors. Comput. Electron. Agric. 2021, 181, 105982. [Google Scholar] [CrossRef]
- Riekert, M.; Klein, A.; Adrion, F.; Hoffmann, C.; Gallmann, E. Automatically detecting pig position and posture by 2D camera imaging and deep learning. Comput. Electron. Agric. 2020, 174, 105391. [Google Scholar] [CrossRef]
- Fuentes, S.; Viejo, C.G.; Chauhan, S.S.; Joy, A.; Tongson, E.; Dunshea, F.R. Computer Vision Algorithms and Machine Learning Modeling Using Integrated Visible/Infrared Thermal Cameras. Sensors 2020, 20, 6334. [Google Scholar] [CrossRef]
- Bhujel, A.; Arulmozhi, E.; Moon, B.E.; Kim, H.T. Deep-Learning-Based Automatic Monitoring of Pigs’ Physico-Temporal Activities at Different Greenhouse Gas Concentrations. Animals 2021, 11, 3089. [Google Scholar] [CrossRef] [PubMed]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Farhadi, A. YOLOv3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- González-Baldizón, Y.; Pérez-Patricio, M.; Magadán, A.; Morales-Reyes, A.; Escobar-Gómez, E.N.; Rodríguez-Elías, O.M.; Vázquez-Delgado, H.D.; Fragoso-Mandujano, A. Recognition of Common Postures in Lambs (ICV-TxLamb); IEEE: Piscataway Township, NJ, USA, 2020. [Google Scholar] [CrossRef]
- Manning, C.; Schutze, H. Foundations of Statistical Natural Language Processing; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Wu, D.; Lv, S.; Jiang, M.; Song, H. Using channel pruning-based YOLO v4 deep learning algorithm for the real-time and accurate detection of apple flowers in natural environments. Comput. Electron. Agric. 2020, 178, 105742. [Google Scholar] [CrossRef]
- Zheng, C.; Zhu, X.; Yang, X.; Wang, L.; Tu, S.; Xue, Y. Automatic recognition of lactating sow postures from depth images by deep learning detector. Comput. Electron. Agric. 2018, 147, 51–63. [Google Scholar] [CrossRef]
- NOM-001-SAG/GAN-2015; NORMA Oficial Mexicana NOM-001-SAG/GAN-2015. Sistema Nacional de Identificación Animal para Bovinos y Colmenas: Mexico City, Mexico, 2015.
- NOM-042-ZOO-1995; NORMA Oficial Mexicana NOM-042-ZOO-1995. Características y Especificaciones Zoosanitarias Para Las Instalaciones, Equipo y Operación de Unidades de Regularización Zoosanitaria Para Ganado Bovino, Equino, Ovino y Caprino: Mexico City, Mexico, 1995.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Model | Precision |
|---|---|---|
| 2022 [11] | YOLO | 99.91% |
| 2021 [27] | YOLO | 66.00% |
| 2021 [28] | Faster R-CNN | 93% |
| 2020 [5] | YOLO | 97.49% |
| 2020 [29] | Faster R-CNN | 80.20% |
| FPS | ID | Label | Precision | Xmin | Ymin | Xmax | Ymax | CentroidX | CentroidY | Distance | Time Inference | Date |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 | 3 | Standing | 0.99973434 | 175 | 328 | 164 | 92 | 257 | 374 | 19 | 0.79399347 | 8 March 2021 08:46 |
| 2 | 1 | Eating | 0.9996016 | 176 | 84 | 123 | 121 | 237 | 144 | 0 | 0.79399347 | 8 March 2021 08:46 |
| 2 | 4 | Eating | 0.99948317 | 285 | 71 | 93 | 148 | 331 | 145 | 1 | 0.79399347 | 8 March 2021 08:46 |
| 2 | 2 | Eating | 0.99919647 | 118 | 199 | 127 | 109 | 181 | 253 | 1 | 0.79399347 | 8 March 2021 08:46 |
| 2 | 5 | Laying | 0.99890792 | 226 | 218 | 112 | 124 | 282 | 280 | 1 | 0.79399347 | 8 March 2021 08:46 |
| 2 | 7 | Eating | 0.98845434 | 385 | 64 | 67 | 170 | 418 | 149 | 0 | 0.79399347 | 8 March 2021 08:46 |
| 2 | 6 | Eating | 0.98077255 | 332 | 223 | 91 | 175 | 377 | 310 | 1 | 0.79399347 | 8 March 2021 08:46 |
| 2 | 8 | Eating | 0.91383141 | 114 | 95 | 122 | 105 | 175 | 147 | 3 | 0.79399347 | 8 March 2021 08:46 |
| 3 | 1 | Eating | 0.99960029 | 176 | 84 | 123 | 121 | 237 | 144 | 0 | 0.82321477 | 8 March 2021 08:46 |
| 3 | 3 | Standing | 0.99957621 | 183 | 326 | 160 | 93 | 263 | 372 | 25 | 0.82321477 | 8 March 2021 08:46 |
| Class | Average Precision (AP) | True Positive (TP) | False Positive (FP) |
|---|---|---|---|
| Standing | 99.81% | 1850 | 110 |
| Laying | 99.79% | 1033 | 32 |
| Eating | 99.95% | 4143 | 35 |
| Total Frames | Precision Eating | Precision Standing | Precision Laying | General Precision | |
|---|---|---|---|---|---|
| Video 1 | 5410 | 96.7835 | 89.8188 | 62.8166 | 83.139 |
| Video 2 | 5402 | 99.4638 | 97.9638 | n/a | 98.713 |
| Video 3 | 5418 | 95.343 | 94.4279 | 81.1694 | 90.313 |
| Video 4 | 5397 | 99.7009 | 97.6652 | 85.0948 | 94.153 |
| Video 5 | 5447 | 99.1959 | 97.1366 | 74.3940 | 90.242 |
| Video 6 | 5419 | 99.1337 | 96.6490 | n/a | 97.891 |
| Total Objects | True Positives | False Positives | True Negatives | False Negatives | General Precision | |
|---|---|---|---|---|---|---|
| Video_1 | 4 | 4 | 0 | 0 | 0 | 100 |
| Video_2 | 4 | 3 | 0 | 1 | 0 | 100 |
| Video_3 | 2 | 1 | 0 | 1 | 0 | 100 |
| Video_4 | 2 | 1 | 0 | 1 | 0 | 100 |
| Video_5 | 1 | 0 | 0 | 1 | 0 | 100 |
| Video_6 | 3 | 2 | 0 | 1 | 0 | 100 |
| Video_7 | 4 | 4 | 0 | 0 | 0 | 100 |
| Video_8 | 1 | 0 | 0 | 1 | 0 | 100 |
| Video_9 | 3 | 2 | 0 | 1 | 0 | 100 |
| Video_10 | 3 | 2 | 0 | 1 | 0 | 100 |
| Video_11 | 3 | 2 | 0 | 1 | 0 | 100 |
| Video_12 | 3 | 2 | 0 | 1 | 0 | 100 |
| Video_13 | 3 | 1 | 0 | 1 | 1 | 66.66 |
| Video_14 | 3 | 0 | 0 | 1 | 2 | 33.33 |
| Video_15 | 5 | 3 | 0 | 1 | 1 | 80 |
| Video_16 | 5 | 0 | 0 | 0 | 5 | 0 |
| Video_17 | 5 | 2 | 0 | 0 | 3 | 40 |
| Model | Objects | Dataset | Precision | Categories | Tracking | Analisis |
|---|---|---|---|---|---|---|
| YOLO | Red foxes [11] | 8913 | 99.91% | Sitting, Lying, Standing | No | Individual |
| YOLO | Lambs (Proposed) | 9652 | 99.85% | Standing, Lying, Eating | Yes | Group |
| YOLO | Goats [5] | 1200 | 97.49% | Drinking, Eating, Inactive, Active | Yes | Group |
| Faster R-CNN | Broilers [29] | 9040 | 93% | Feeder, Eating bird, Bird around feeder | Yes | Group |
| Faster R-CNN | Pigs [29] | 7277 | 80.20% | Pig, Pig lying, Pig not lying | No | Group |
| YOLO | Dairy cows [27] | 11,754 | 66.00% | Xleft, Xright, Vleft, Vright, Oleft, Cright, Ileft, Iright | No | Group |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
González-Baldizón, Y.; Pérez-Patricio, M.; Camas-Anzueto, J.L.; Rodríguez-Elías, O.M.; Escobar-Gómez, E.N.; Vazquez-Delgado, H.D.; Guzman-Rabasa, J.A.; Fragoso-Mandujano, J.A. Lamb Behaviors Analysis Using a Predictive CNN Model and a Single Camera. Appl. Sci. 2022, 12, 4712. https://doi.org/10.3390/app12094712
González-Baldizón Y, Pérez-Patricio M, Camas-Anzueto JL, Rodríguez-Elías OM, Escobar-Gómez EN, Vazquez-Delgado HD, Guzman-Rabasa JA, Fragoso-Mandujano JA. Lamb Behaviors Analysis Using a Predictive CNN Model and a Single Camera. Applied Sciences. 2022; 12(9):4712. https://doi.org/10.3390/app12094712
Chicago/Turabian StyleGonzález-Baldizón, Yair, Madaín Pérez-Patricio, Jorge Luis Camas-Anzueto, Oscar Mario Rodríguez-Elías, Elias Neftali Escobar-Gómez, Hector Daniel Vazquez-Delgado, Julio Alberto Guzman-Rabasa, and José Armando Fragoso-Mandujano. 2022. "Lamb Behaviors Analysis Using a Predictive CNN Model and a Single Camera" Applied Sciences 12, no. 9: 4712. https://doi.org/10.3390/app12094712