1. Introduction
Natural language processing (NLP) has become a popular research topic in the last two decades. Its popularity has attracted researchers to examine data, web and text mining, as well as information retrieval [
1]. Opinion mining is one attractive topic, among other topics such as machine translation, customer support boss, text summarization, and speech recognition. Opinion mining is essential in current online interactions, such as e-commerce, e-government, and many online services, for understanding public opinion on specific issues [
2]. Governments worldwide increasingly adopt social media to engage their citizens and understand citizen opinion with respect to public policy [
3].
Opinion mining can mainly be divided into lexicon-based and supervised machine learning approaches. Lexicon-based approaches rely on the sentiment word dictionary. To carry out lexicon-based sentiment analysis, lexicon dictionaries are available for public use, such as wordnet in English, [
4] in Bahasa, and [
5,
6,
7,
8] in Arabic. On the other hand, the supervised approach needs manually labeled corpora to train the classifier. Researchers are working on lexicon-based opinion mining in many languages, such as [
9] for the Indonesian language, [
6,
7,
8,
9,
10] for Arabic, and [
11] for Urdu. The supervised approach has attracted researchers in detecting sentiment levels using SVM, ANN, Naïve Bayes, Decision Tree, Random Forest, and numerous exercises with many different languages and datasets. Currently, researchers are moving forward in implementing deep learning for natural language processing in general, specifically with respect to sentiment polarity classification.
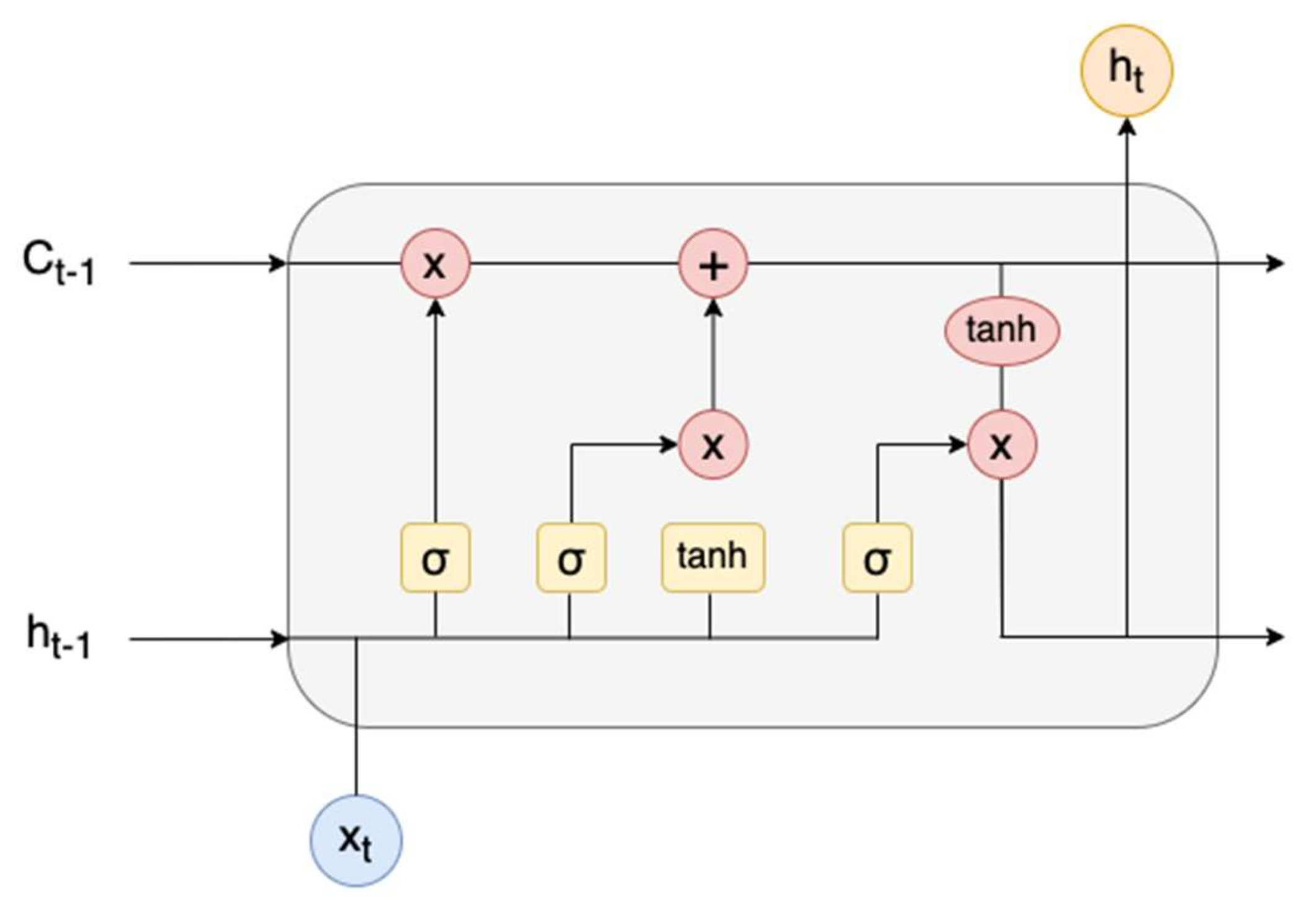
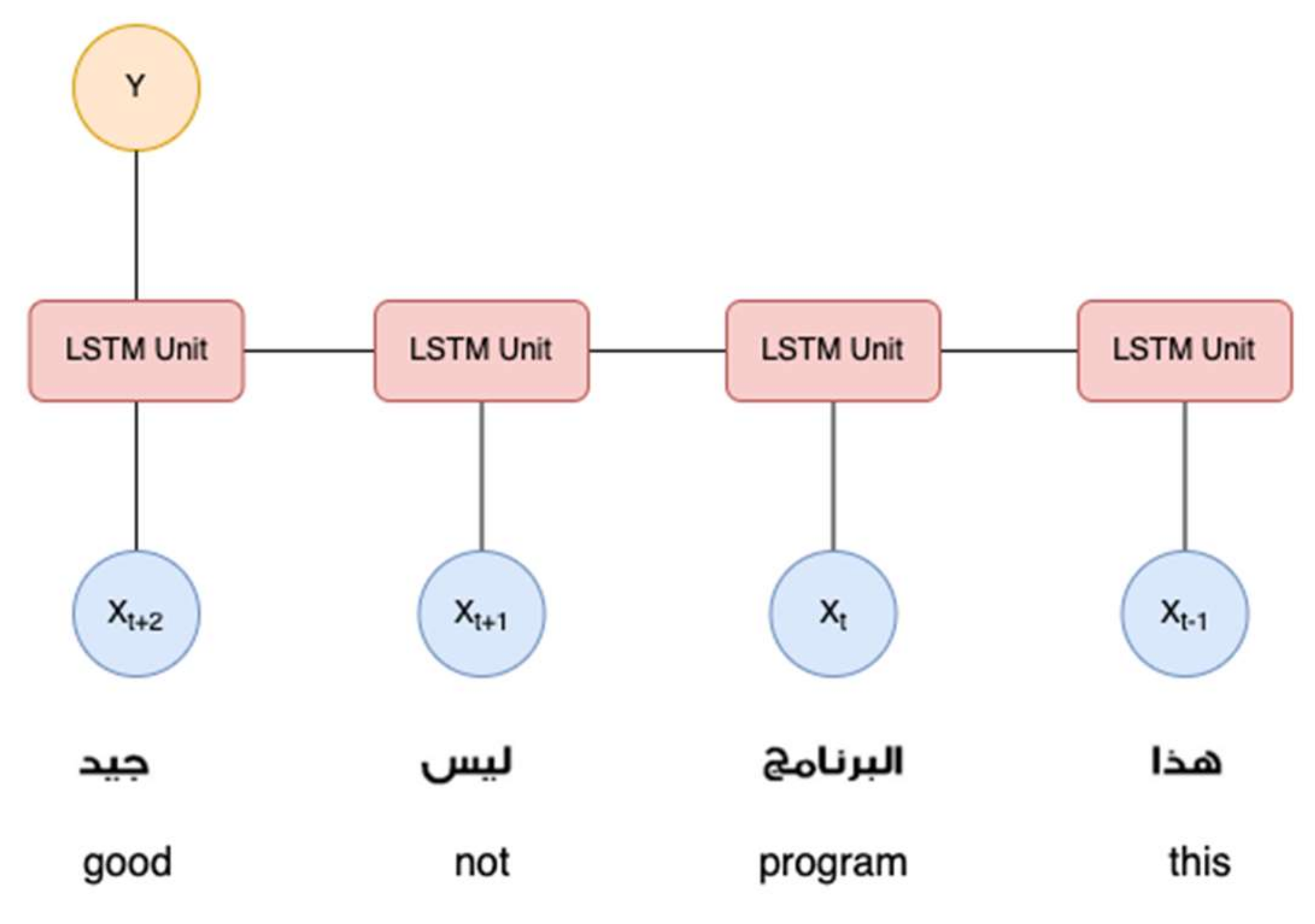
The computing power available in current hardware and cloud services allows researchers to solve problems using heavy computing algorithms. This capability has enabled a massive development in deep learning as an extension of the neural network concept. Deep learning has made a successful breakthrough in many recognition tasks for image, video, and text. In particular, language signals have specific properties regarding time sequence. The early research on textual recognition assumed that the sequence had no significant effect. This assumption led to a lower recognition rate for early sentiment classification using time-series-unaware algorithms such as Artificial Neural Network, Support Vector Machine, and Naïve Bayes. Long Short-Term Memory (LSTM) extends an artificial neural network with a connection between an earlier neuron and the next neuron. Because the neuron in LSTM does not only contain a single operation, it is called an LSTM-cell instead of a neuron. With LSTM architectures, if the sentence in a corpus consists of five words, the first word will come into the first unit, while subsequent words will go to the second through fifth units. To maintain the contribution of the first LSTM unit in the computation of the second unit, the output of the first unit needs to be connected to the second unit. This connection is maintained between subsequent calls. LSTM ensures that word signals in a sentence affect each subsequent word. Therefore, LSTM is suitable for the computation of time series problems, textual and time series prediction analysis, sound, and voice computation. With respect to problem construction, this paper discusses the implementation of LSTM for sentiment analysis.
An extensive dataset is needed in a deep learning environment to enable the necessary training to obtain the pattern of the problem. Deep learning implementation in image and video processing has benefited from the huge datasets available to the public. For instance, the ImageNet (
https://www.image-net.org/index.php, (accessed on 1 February 2022)) dataset for visual recognition and the YouTube 8M (
https://research.google.com/youtube8m/, (accessed on 1 February 2022)) dataset for video understanding have been vital for deep learning algorithms to make perform accurate recognition. Image and video recognition are generally applied for many purposes, regardless of geographical and cultural boundaries. Text datasets, however, cannot be treated generally. For example, a textual dataset for Arabic cannot be used to train English sentiment analysis or vice versa. Therefore, natural language processing research requires many adjustments due to cultural boundaries.
The textual signal naturally consists of non-numeric and unstructured data. Processing unstructured data is a challenge for researchers in NLP, and therefore many researchers have proposed formulas for transforming the unstructured data into a more structured format. A bag of words has been proposed to transform textual data into numerical data by exploiting the frequency of each word in a sentence, resulting in the concepts of Term Frequency and Inverse Document Frequency proposed in [
12]. Word embedding methods have been proposed to obtain more redundant data in order to represent words in consideration of their relationship to other words in many contexts. There are a number of word embedding techniques, such as Word2vec [
13], fastText [
14], and GloVe [
15]. Word embedding requires a massive corpus in order to train the algorithms to calculate the vector values of specific words.
Textual signals may come from a number of unofficial sources, such as social media, e-commerce comments, book reviews, and websites. This condition leads to data problems such as duplicated, unnecessary, meaningless, non-mixing, and stop words. Normalizing data before further processing plays a significant role in achieving high classification accuracy. In many languages, such as in English or Indonesian, the meaning of a word rarely changes with the addition of prefixes or suffixes. Therefore, removing prefixes and suffixes can help reduce the number of specific words (terms) in a corpus, thus reducing the computing complexity. However, in Arabic, words may change their meaning entirely with the addition of a prefix or suffix; therefore, stemming might lead to misinterpretation of the sentence.
The Arabic language is one of the most widely spoken languages today. It is an official language of the United Nations organization, estimated to be used daily by more than 400 million people. Its usage on the web has shown vigorous growth in recent years, where it ranked as the fourth most used language in cyberspace [
16].
The Arabic language can be found in three forms: Classical Arabic (CS), which adheres to strict grammatical and morphological rules and is usually used in literary texts. Second, Modern Standard Arabic (MSA) is commonly used in correspondence and formal speech. Lastly, Dialectical Arabic (DA) refers to oral utterances spoken in daily communication [
17]. Typically, microblogging content will be in MSA or DA or a variant of the two where the Arabic words are written using Latin letters, numbers, and punctuation [
18].
This research observes varied embedding methods and Long Short-Term Memory (LSTM) with single, double and triple layers to recognize sentiment polarity. The authors adopt the Arabic Sentiment Analysis (ASAD) dataset from [
19] to evaluate the proposed frameworks.
2. Literature Review
Several studies have been conducted on sentiment analysis using various algorithms in different languages such as Indonesian [
9], Urdu [
13], Russian [
20], and Arabic [
21]. However, most work has been carried out in English, such as [
22,
23,
24]. The study of natural language processing is interesting for two reasons, firstly due to the algorithm’s variations, and secondly due to language variety. A successful framework for a particular language may need adjustment when it comes to implementation in a different language. Sometimes, even dialect can heavily affect the likely result. In Arabic, for example, the researchers in [
25] divide the variety of languages into three groups: Classical Arabic (CA), Modern Standard Arabic (MSA) and Dialectical Arabic (DA).
Sentiment analysis is a classification task of input text into several classes. The number of classes varies from binary (positive, negative), three classes (binary with neutral) and complex systems of five classes ranging from very positive to very negative. Arabic is one of the most popular languages in the world, with 330 million native speakers, and is one of the official languages of the United Nations (UN) [
26]. There are some public datasets available in the Arabic language of various classes. Some public datasets consist of positive and negative classes such as the Large-Scale Arabic Book Review [
27] and Ar-Twitter, proposed by [
28]. The rest of the available dataset consists of four more classes, such as [
29], which proposed four classes, and ArsenTb, which employs five classes [
10,
30,
31].
The sentiment analysis is mainly divided into lexicon-based and supervised machine learning approaches. Lexicon-based approaches rely on the sentiment word dictionary. Some researchers have claimed promising results using lexicon-based approaches, such as [
32,
33]. Supervised approaches rely on machine learning algorithms and are based on a labeled corpus; therefore, they are also referred to as corpus approaches. The machine learning algorithms are basically trained by the labeled corpus to build a model. There are many researchers who have employed a variety of languages and algorithms.
The lexicon approach was quite popular at the beginning of sentiment analysis study. It is powerful and can be performed using simpler algorithms. However, it is mainly based on the availability of lexicon dictionaries. A pre-defined dictionary provides a set of words in each sentiment polarity. A document is classified into a particular polarity on the basis of the word frequencies of each polarity side from the dictionary. Ref. [
34] compared six sentiment opinion lexicons, and proposed a new general-purpose sentiment lexicon that they claimed was able to achieve 69% accuracy when determining the sentiment of news headline. In sentiment analysis in the Arabic language, ref. [
32] proposed a sentiment lexicon with a size of 16,800 words. Their experiment claimed that the integrated lexicon achieved better results, at 74% accuracy, than manual and dictionary-based sentiment analysis. Later on, ref. [
33] proposed a sentiment lexicon consisting of 120,000 Arabic terms. They claimed an even better accuracy of 86.89%. The lexicon approach generally achieves better performance when the sentiment lexicon is complete. However, as a language is not static knowledge, this approach needs to be continuously updating the data all the time. Therefore, researchers have tried to find a better way of overcoming the language dynamics. Corpus-based methods rely on real-time data such as reviews, social media, and the web. By annotating the real-time data, data researchers train the machine to recognize the patterns of each sentiment polarity.
The supervised approach relies on machine learning algorithms such as support vector machines, decision trees, logistic regression, and many more. Ref. [
35] compared the Support Vector Machine (SVM) and Artificial Neural Network (ANN) for detecting sentiment on 3000 sentences from the Movie Review dataset and 3000 customer reviews on Amazon for particular products. According to their experiments, ANN performed significantly better than SVM on sentiment classification. Ref. [
24] carried out a study on the scalability of the Naïve Bayes classifier for big data, and found the Naïve Bayes classifier to be capable of analyzing millions of movie reviews with 82% accuracy using a vast dataset. Although Arabic is a less-researched area with respect to sentiment mining, there have been some reports. Ref. [
36] compared the performance of five classifiers: Support Vector Machine, Random Foes, Gaussian Naïve Bayes, Logistic Regression, and Stochastic Gradient Descent. They also compared the Skip-Gram model and Continuous Bag of Words (CBOW) by fastText as vectorization methods. They found that fastText Skip-Gram performed better for all classifiers. Ref. [
37] examined Hierarchical Classifier, SVM, Decision Tree (DT), Naïve Bayes, K-Nearest Neighbor (KNN) on an extensive book review dataset. They found that their Hierarchical Classifier achieved 57.8% accuracy. Ref. [
38] compared Convolutional Neural network (CNN), Naïve Bayes, Logistic Regression and Support Vector Machine (SVM) for sentiment classification on a health dataset. According to their experiments, SVM gave the best results. However, there was no common agreement among researchers regarding high-performance algorithms dealing with sentiment analysis on the basis of those experiments. Some algorithms may work very well under certain conditions, but fail on the problem set.
The aforementioned supervised classifier fails to capture word order sequences in the text. Most machine learning algorithms cannot distinguish differences in word order, such as between “the dog kills a mouse” and “the mouse kills a dog”. A machine learning architecture is needed that is aware of time sequences. Recurrent Neural Network (RNN) has connections between previous, current and future signals, and therefore it is fit to represent time-series signals, including text. Ref. [
39] proposed an implementation of RNN called LSTM (Long Short-Term Memory) in order to retain the long-term memory effect.
Some researchers have implemented RNN and LSTM in many languages, including Arabic, as shown in
Table 1. Ref. [
9] proposed an Indonesian sentiment corpus and classification engine using word2vec and LSTM. In Ref. [
40], proposed Hybrid CNN-LSTM Model outperformed traditional deep learning and machine learning techniques in precision, recall, f-measure, and accuracy. Hybrid CNN-LSTM was tested on the IMDB sentiment dataset and achieved an improved accuracy of 91%. Ref. [
41] explored the performance of a deep learning framework for an Arabic corpus of around 40,000 tweets using Word2vec and several architectures. According to their experiments, LSTM with data augmentation to balance the dataset overperformed compared to LSTM without data augmentation, and the CNN and RCNN models. Ref. [
42] implemented CNN for feature extraction and LSTM to capture long-term word dependency. They achieved 64% accuracy on three-class sentiment prediction. Ref. [
41] focused on a health services sentiment dataset. They used the English dataset translated into Arabic, carried out the classification using RCNN, and achieved 94% prediction accuracy. Ref. [
30] implemented LSTM on a small corpus with five classes in two Arabic dialects: Emirati and Egyptian. They achieved accuracies of 70% on Egyptian dialects and 63.7% on Emirati dialects. Ref. [
43] performed an exercise using multiple datasets, word embedding methods, various classic machine learning methods, and a deep learning framework. They relied on fastText word embedding for deep learning using CNN, LSTM, and bidirectional LSTM. Ref. [
21] explored the Recursive Neural Tensor Networks (RNTN) model using the word2vec word embedding method. Ref. [
44] explored CNN and two-layer LSTM. Their best achievement was recorded at an accuracy of 90.75% on the fastText Skip-Gram CNN-LSTM framework. Among those deep learning approaches mentioned above, there are many aspects, such as pre-processing, word embedding methods, deep learning architectures, and dataset composition. There is no silver bullet approach that solves all problems, and therefore deeper exploration using a variety of datasets, pre-processing methods, architectures and word embedding methods remains chellenging.
Table 1 lists several studies on Arabic sentiment analysis, the algorithms used, and their achieved accuracy.
4. Results and Discussion
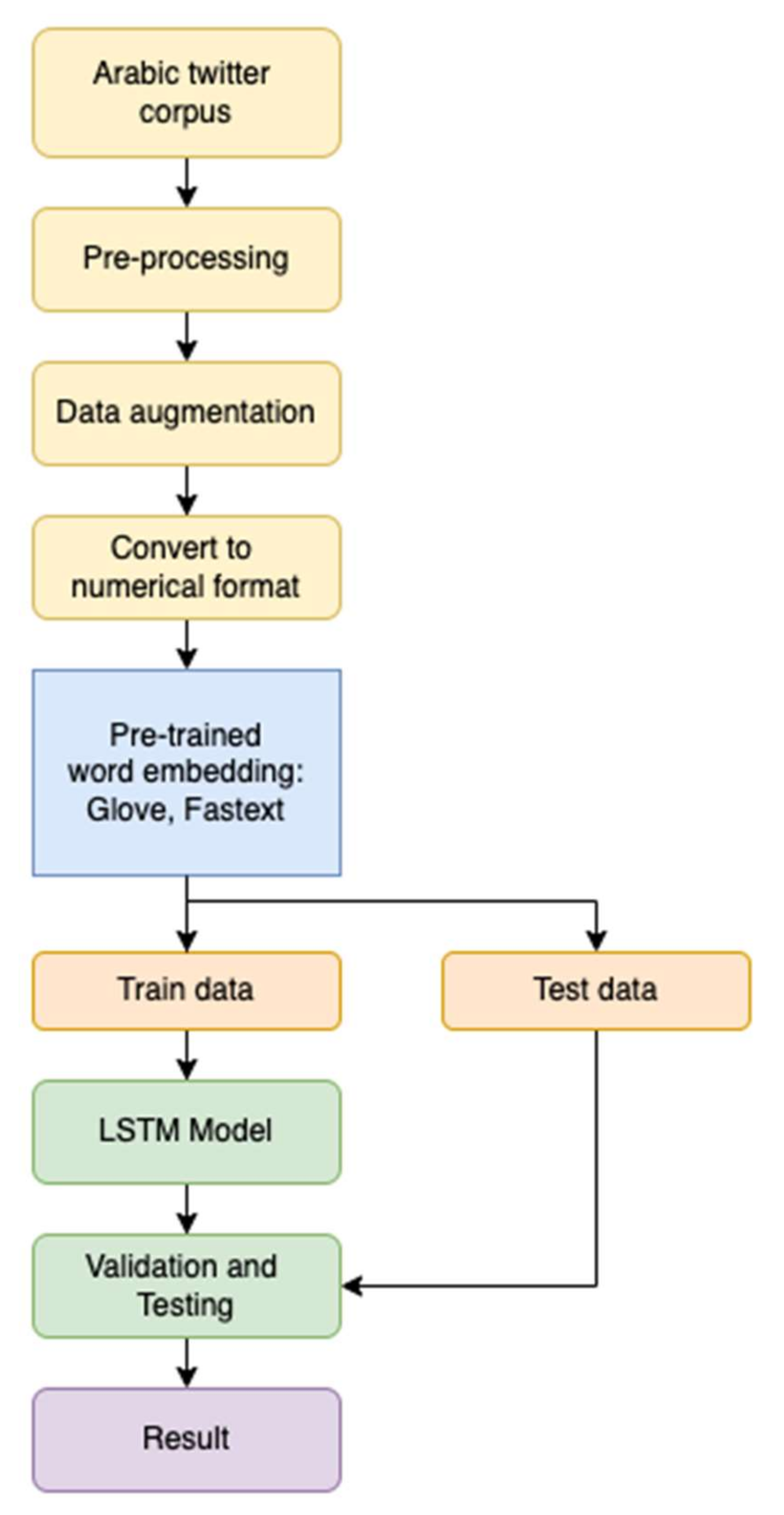
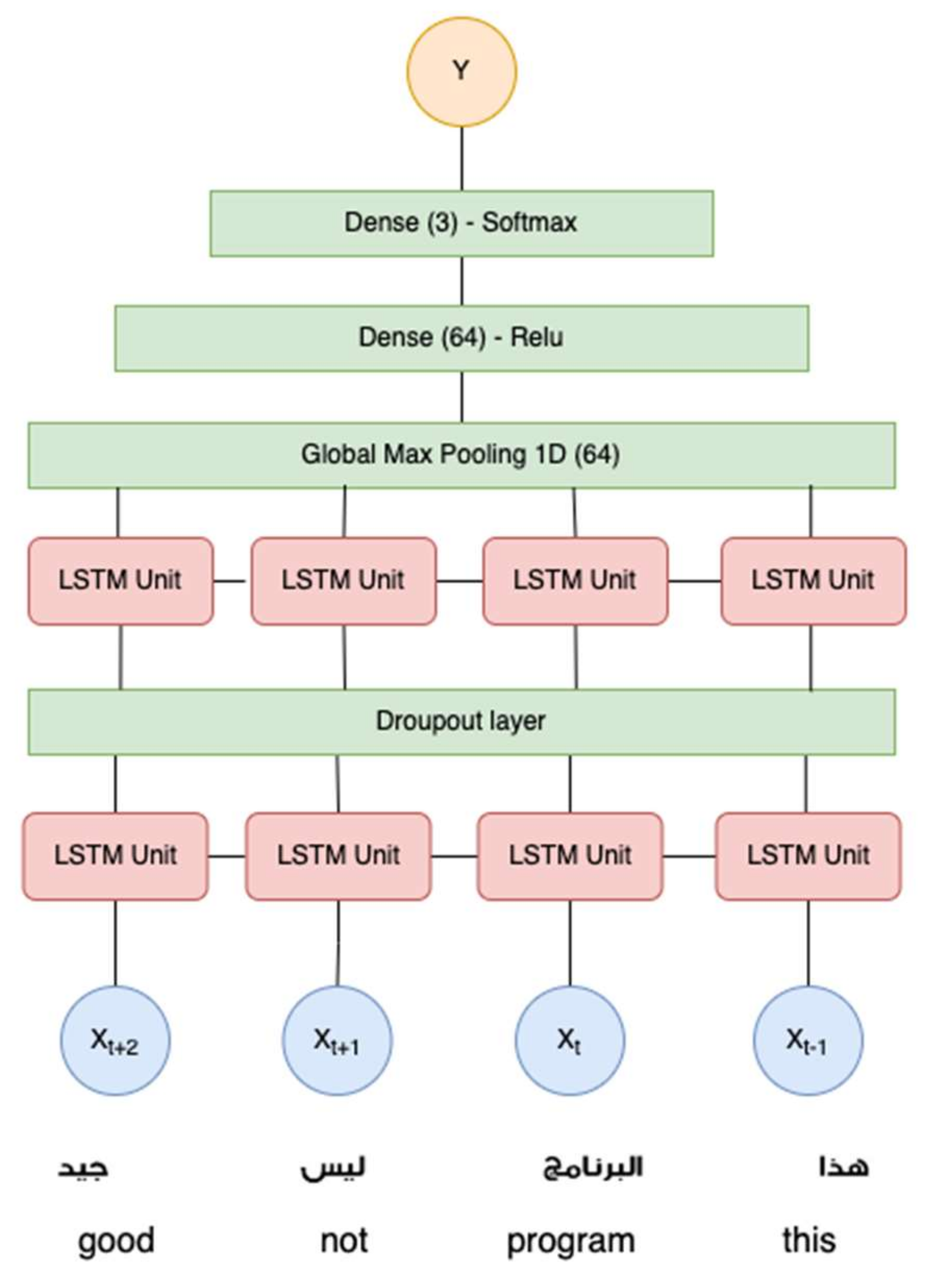
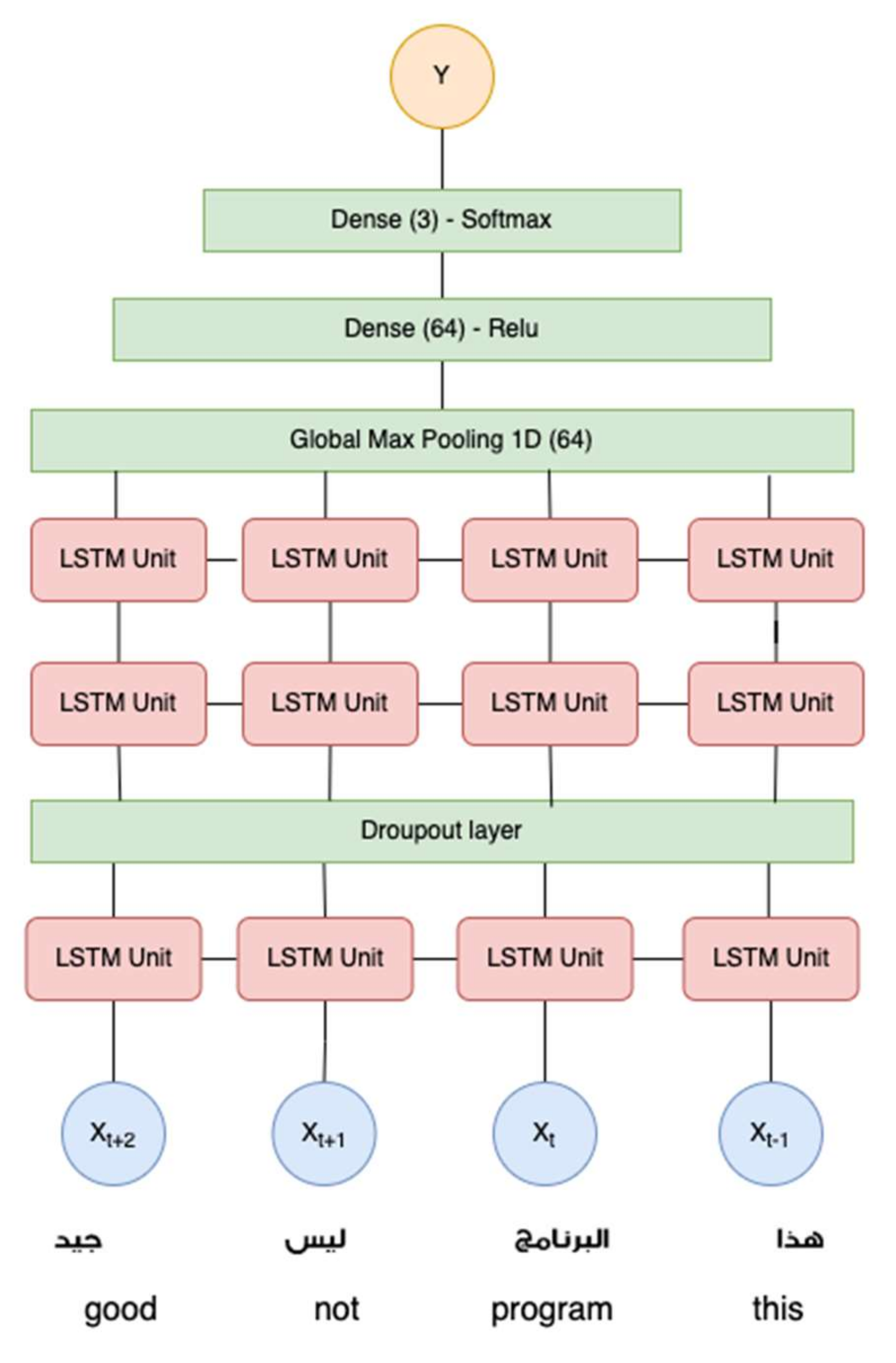
This research aims to find the optimum word embedding method and the best LSTM architectures. Two embedding methods were evaluated for transforming the cleaned text into numerical vectors. LSTM is a recurrent neural network (RNN) variant with a more complex forget gate computation, allowing it to accommodate the influence of time-series signals from the immediate node and to retain the influence of a more extended sequence. In this research, we investigated three LSTM architectures: single layer, double layer, and triple layer, as shown in
Figure 8 and
Figure 9. Training was carried out in 200 epochs to build the models.
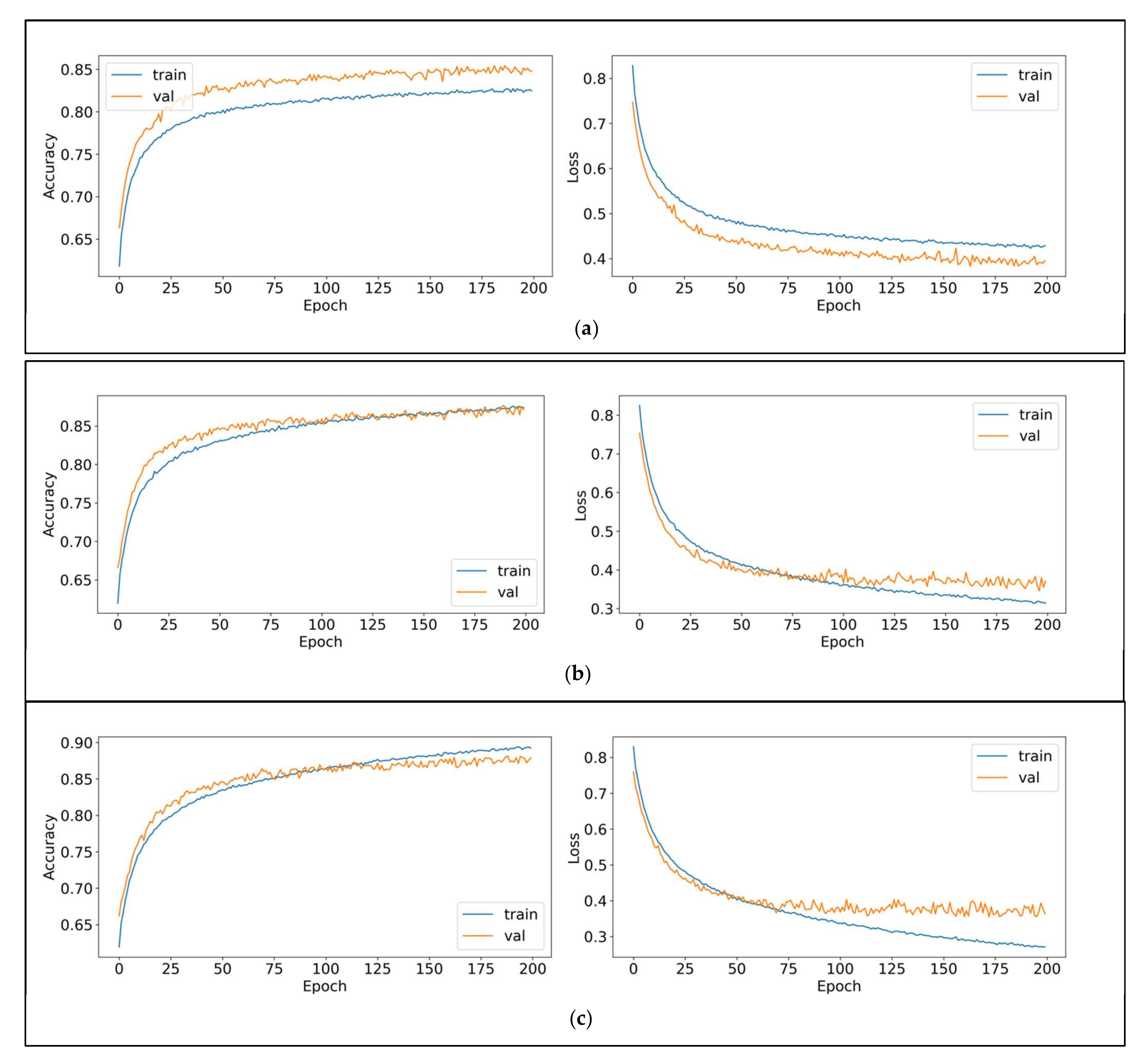
Figure 8 shows the single-, double- and triple-layer LSTM on the balanced dataset with GloVe embedding. Training accuracy and loss are plotted with the blue line, while yellow represents validation accuracy and loss. As can be seen, the single-layer LSTM shows a vast distance between the training and validation accuracy. In contrast, the double- and triple-layer LSTM architectures show a smaller distance between the training and validation accuracy.
Figure 8 demonstrates the effect of a thicker LSTM achieving convergency in earlier training iteration.
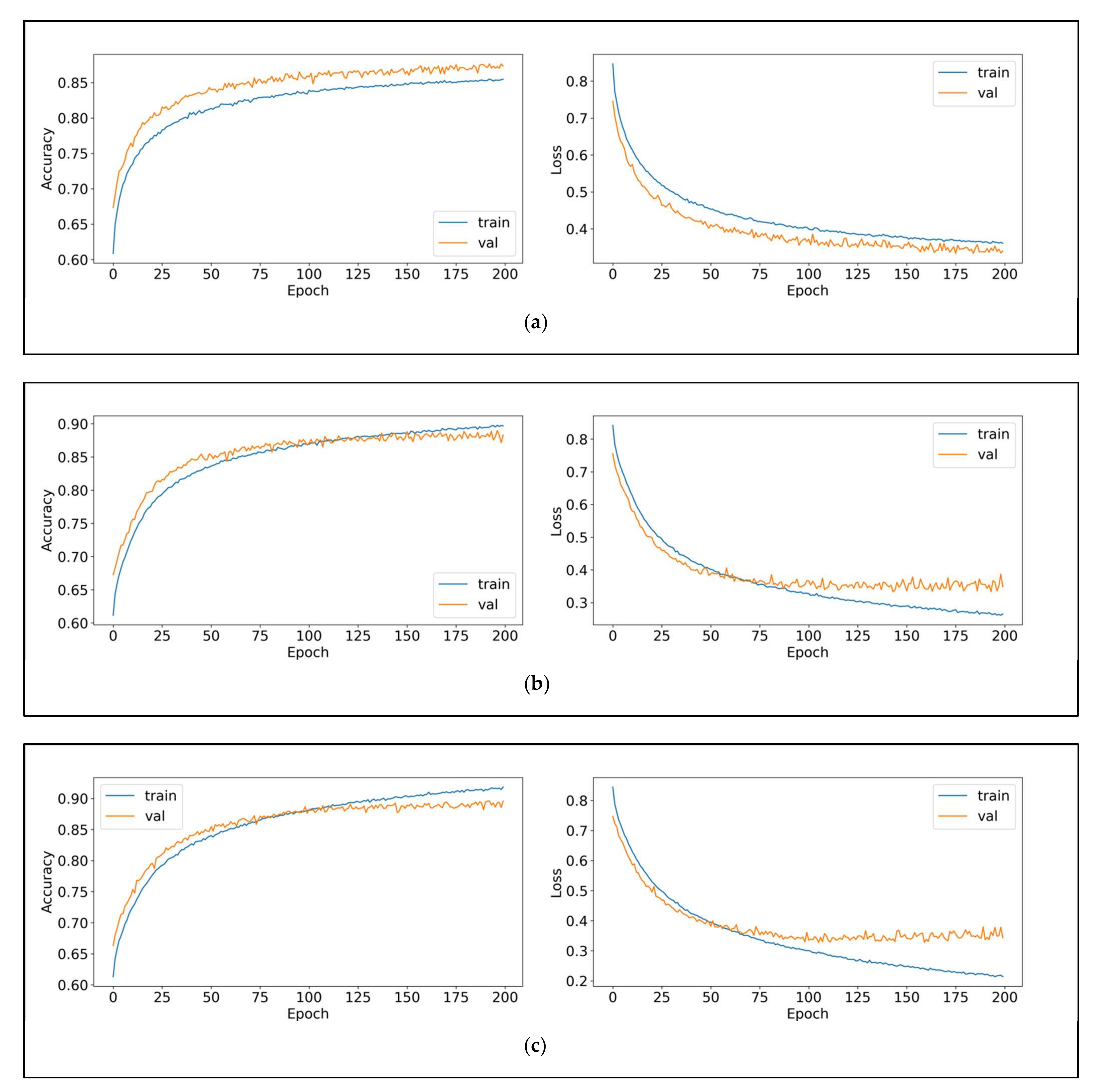
Figure 9 shows the training progress on the next experiment scenario using fastText word embeeding.
Figure 9 shows the single-, double-, and triple-layer LSTM on the balanced dataset with fastText embedding. As can be seen, the single-layer LSTM results show a vast distance between training and validation accuracy. In contrast, the double- and triple-layer LSTM show a smaller distance between training and validation accuracy. As can be seen in double and triple layer of LSTM, the validation accuracy cross the training accuracy at earlier epoch of training. It is indicated that the model reached convergency earlier. This fact lead us to implement early stopping technique in evaluation using the 5 fold cross validation.
Table 7 presents the accuracy achieved by those architectures.
In general, all of the accuracies achieved with fastText word embedding outperformed those achieved when using GloVe. Stacking more layers of LSTM led to higher accuracy in both training and testing. Triple-layer LSTM achieved better performance either double- or single-layer LSTM. This achievement, however, must be achieved at the expense of processing speed, as shown in
Table 7. In this experiment, we used a CUDA GPU Titan V with a total memory of 12 GB.
Table 8 compares the trainable parameters, training time, and testing time required for each LSTM design.
Our results are in line with those of previous studies such as [
28,
41,
42]. Although evaluations were performed on different datasets in previous works, the general trend shows the positive impact of LSTM. Regarding the embedding methods, fastText [
14] demonstrates superiority compared to GloVe [
15]. Our results confirm the findings reported by [
41], where they demonstrated that Skip-Gram fastText performed better than Word2vec [
13] and AraVec. In our experiment, fastText word embedding performed better than GloVe.
A greater number of trainable parameters leads to longer computation times, and the correlation among the trainable parameters and training time can be seen in
Table 8. Training produces a model, which is compiled in the H5 file format. Testing uses the compiled model in a forward pass on the testing data. The elapsed time for each testing set consistently increases with the thickness of the implemented layers. Therefore, the triple-layer LSTM required a longer time than the other architectures. For the best achieved accuracy, with triple-layer LSTM using FastText word embedding, the training time of 1 h 25 min was recorded for the training dataset, with 6.91 µs testing time. In the implementation scenario, the input data consist of a single sentence, and therefore the required processing time is around 6.91 µs divided by 21,650. There will be no issue with the processing speed when implemented with server computer specifications.
We also tested the model using consumer personal computer (PC) with lower computer specifications in order to test its real implementation possibilities. The hardware specifications were: intel I5 with 8 GB memory. The testing time for 21,650 sentences was 16.4 s to achieve the best accuracy with fastText with triple-layer LSTM. Therefore, every individual sentence required 0.75 milliseconds on average. According to those testing results and testing times, we consider that all of the observed architectures can be feasibly implemented.


 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}