
Criteria Selection Using Machine Learning (ML) for Communication Technology Solution of Electrical Distribution Substations

 ,
,
Abstract
:1. Introduction
- A list of the potential communication technologies to be applied at the electrical distribution substation, based on extensive literature review.
- The creation of an ML dataset of the potential communication technologies based on the specifications in the literature.
- A thorough investigation on the ML models with the highest performance in selecting the most important criteria for electrical distribution substation communication technology.
- A ranking of the criteria from the most important to the least important, and an evaluation of the criteria that most strongly influence the selection of the best communication technology for the electrical distribution substation.
2. Selection of Communication Technology
3. Criteria and Dataset Specification
- Frequency is defined as the rate of radio signals measured in Hertz (Hz) to transmit and receive communication signals. Each technology has its own operating frequency spectrum, which can be classified into two categories: (1) licensed: assigned solely to operators for independent use; and (2) unlicensed: assigned to each citizen for non-exclusive use subject to regulatory limits such as transmission power restrictions.
- Bandwidth is defined as the range that carries a signal within a band of frequencies. For example, a system that operates on frequencies between 150 MHz and 200 MHz operates with a bandwidth of 50 MHz.
- Data rate is defined as the amount of data transmitted over a network in a certain period of time, commonly expressed in megabit per second (Mbps).
- Distance refers to the coverage offered by a communication technology. Some wireless technologies, such as SATCOM, LoRa, and private LTE, are known to offer long-distance coverage, whereas others offer short-distance coverage (Zigbee, WiFi). Shorter coverage usually leads to higher deployment of a particular technology in the selected areas.
- Terrain factor divides the land into several categories as follows:
- (a)
- City: The city area is known to contain the highest user density, with buildings and existing wireless communication technologies. It is one of the factors affecting the reliability of communication technologies, especially in terms of the line-of-sight (LoS) interference.
- (b)
- Coastal: The coastal area is defined as the interface or transition area between land and sea, including large inland lakes. Because of its large area and low population density, it is assumed to contain no LoS interference.
- (c)
- Plains: The plains are defined as a broad area of relatively flat land. The assumption is that they contain lower user density compared to the city and less or almost no LoS interference due to the wide area and lower vegetation.
- (d)
- Forestry: A forest is defined as an area with more than 0.5 hectares of land, trees taller than 5 m, and a canopy cover of more than 10%, or trees capable of reaching these thresholds in situ. It does not include land that is predominantly used for agricultural or urban land use. The assumption is that it contains the lowest user density. However, the high density of forest affects the communication technology’s reliability, especially for wireless technology.
- (e)
- Mountains: A mountain is a land that is raised above the surrounding landscape. It is usually in the form of a peak with a well-defined summit. The assumption is that mountainous areas contain low density of users and trees. However, due to the topography, it requires higher cost and longer time for cable installation.
- Scalability is defined in this research as the ability of the communication technology to be scaled, measured in terms of percentage. It is dependent on the topology and data rate that each technology can offer, in which the more devices are added to a network, the longer the communication delay on the network. This means that the number of devices added to a network topology needs to be monitored carefully to make sure that the network resources are not stretched beyond their limit. Point-to-point (P2P) topology is not scalable, whereas point-to-multipoint (P2M) and multipoint-to-multipoint (M2M) are considered scalable. The ring topology raises scalability concerns, as the bandwidth is shared by all devices within the network. A star and mesh topology network is considered scalable, as network nodes can be added with minimal disruption.
- Line-of-Sight (LoS) interference, measured in terms of percentage in this research, refers to the setting when the transmit and receive nodes are not in view of each other due to the presence of obstacles between them. A higher percentage is given to the wired technologies than to the wireless technologies due to the latter’s reliability against LoS interference. The reliability of wireless technology is lower than wired technology, taking into consideration the example of Urban (City): high density with buildings, Suburban (Coastal and Plains): higher than Urban and Rural because there are no or few LOS interferences due to the wide area and lower density (buildings, trees), Rural (Forestry): high density of trees and Rural (Mountains): slightly lower considering lower density of trees.
- Interference refers to spectrum interference, measured in percentage in this research. For wired technology, the assumption is that the interference is lower than the wireless technology. To the best of our knowledge, wired technology’s only source of interference is interference from other mediums. Additionally, it is expected that there will be less interference in wired technologies as they are mostly buried underground. The terrain factor affects interference in wireless technology, especially because of the user density in a particular area. For example, in urban areas (cities), the interference is expected to be the highest compared to other areas due to the high density of users.
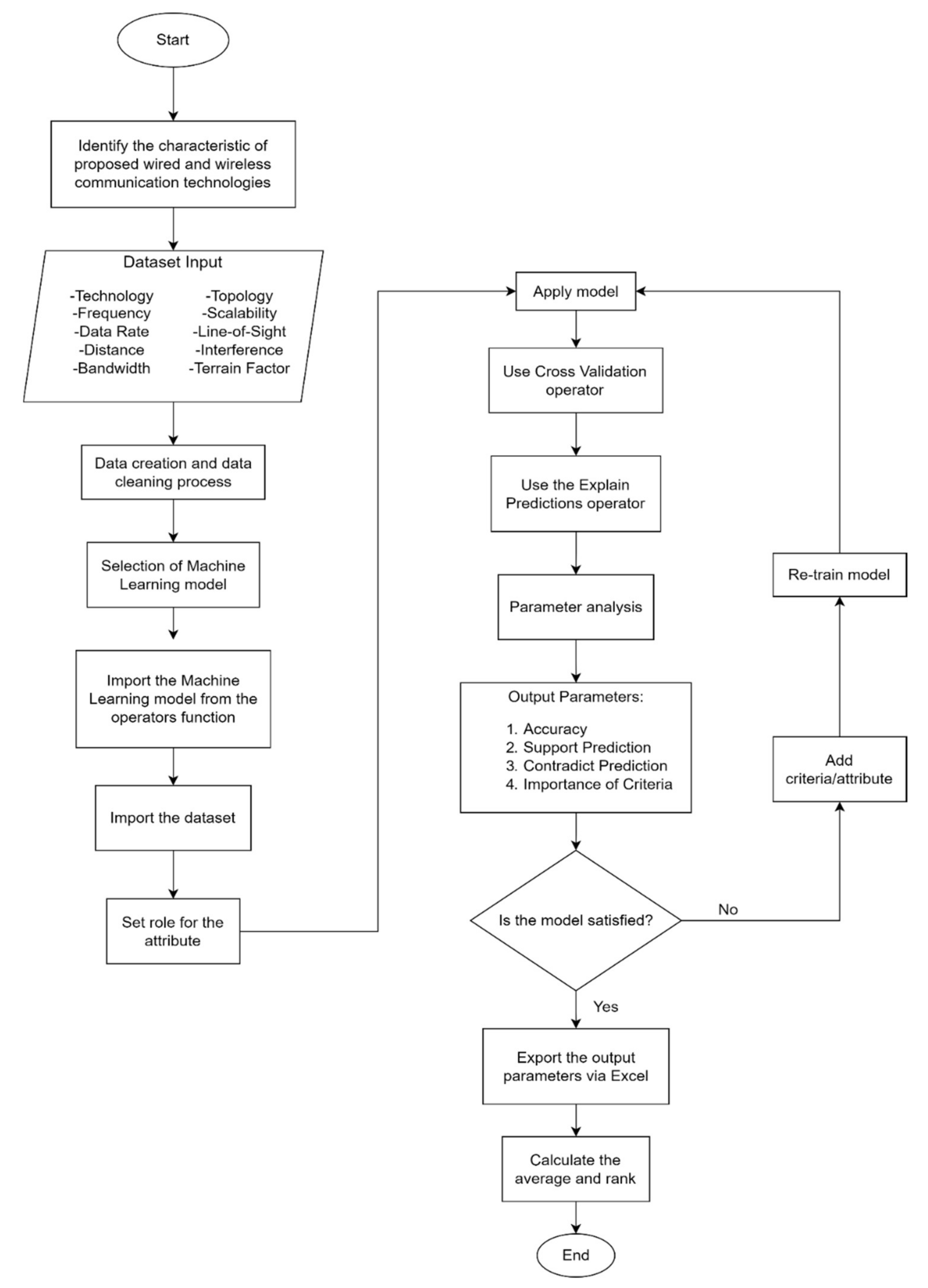
4. Machine Learning (ML)
- It reduced the variability in prediction errors.
- It made the best use of all available data while avoiding overfitting or overlap between test and validation data.
- It avoided testing hypotheses provided by arbitrarily split data.
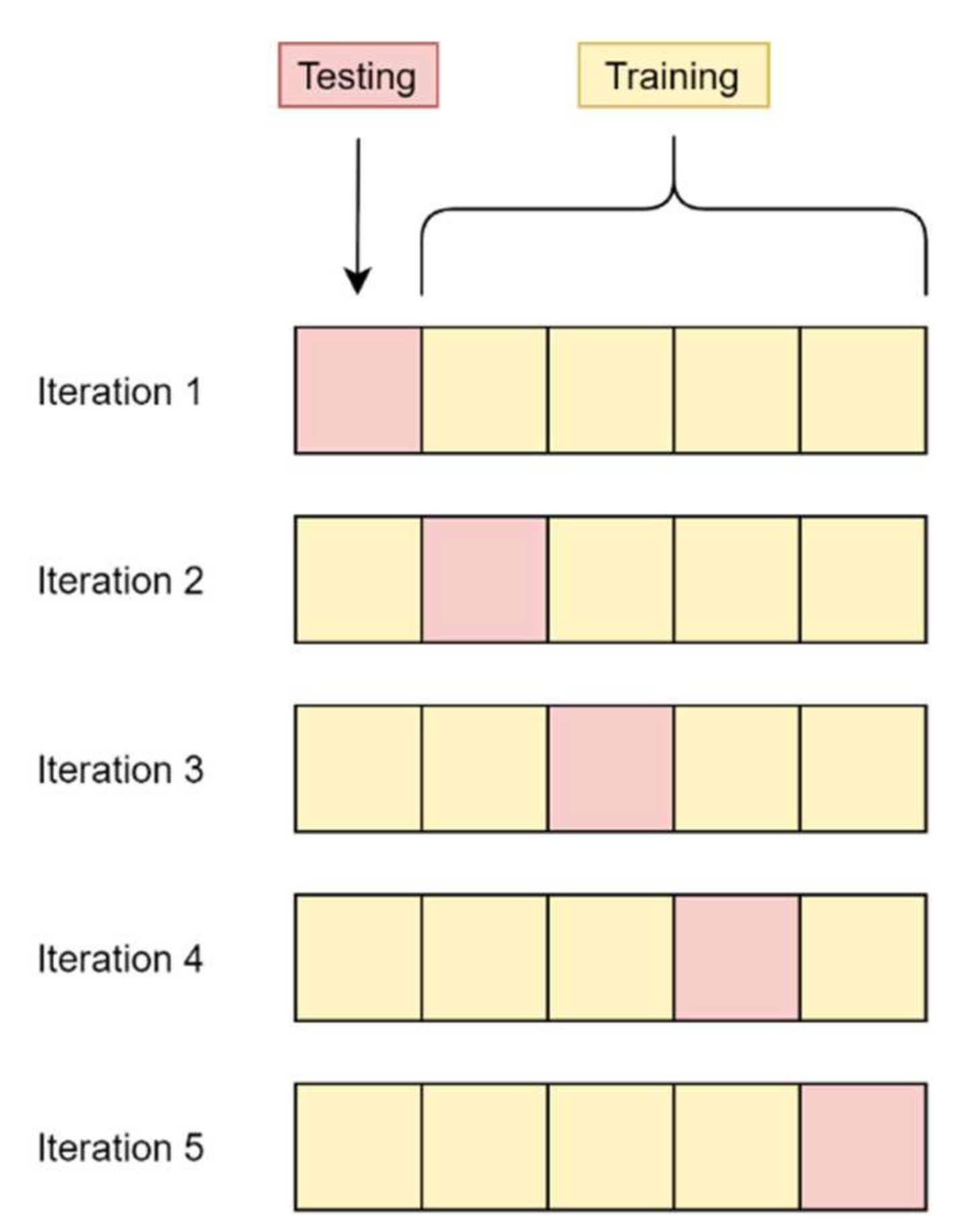
- Pick any number of folds, K. Ideally, it can be from 5 to 10, depending on data sizes.
- The dataset will be divided into K equal subsets, which are also called folds.
- Choose K − 1 folds, which will be the training set. The remaining folds will be the test set.
- Use the cross-validation method to train the ML model and calculate its accuracy
- Evaluate the accuracy using all the K cases of cross validation.
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, R. Chapter 4—Protection and control technologies of connecting to the grid for distributed power resources. In Distributed Power Resources; Li, R., Ed.; Academic Press: Cambridge, MA, USA, 2019; pp. 121–144. [Google Scholar]
- Transmission vs. Distribution. Available online: https://www.osha.gov/etools/electric-power/generation-transmission-distribution/transmission-distribution (accessed on 11 October 2021).
- What Is a Substation—Definition, Types of SubStations. Available online: https://www.elprocus.com/what-is-a-substation-definition-types-of-substations/ (accessed on 11 October 2021).
- Masood, B.; Baig, S. Standardization and deployment scenario of next generation NB-PLC technologies. Renew. Sustain. Energy Rev. 2016, 65, 1033–1047. [Google Scholar] [CrossRef]
- Raza, N.; Akbar, M.Q.; Soofi, A.A.; Akbar, S. Study of Smart Grid Communication Network Architectures and Technologies. J. Comput. Commun. 2019, 7, 19–29. [Google Scholar] [CrossRef] [Green Version]
- Kuzlu, M.; Pipattanasomporn, M. Assessment of communication technologies and network requirements for different smart grid applications. In Proceedings of the 2013 IEEE PES Innovative Smart Grid Technologies Conference, Washington, DC, USA, 24–27 February 2013; IEEE: Manhattan, NY, USA, 2013; pp. 1–6. [Google Scholar]
- Kabalci, E.; Kabalci, Y. Introduction to Smart Grid Architecture. In Smart Grids and Their Communication Systems; Kabalci, E., Kabalci, Y., Eds.; Springer: Singapore, 2019; pp. 3–45. [Google Scholar]
- Appasani, B.; Maddikara, J.B.R.; Mohanta, D.K. Standards and Communication Systems in Smart Grid. In Smart Grids and Their Communication Systems; Kabalci, E., Kabalci, Y., Eds.; Springer: Singapore, 2019; pp. 283–327. [Google Scholar]
- Li, Y.; Cheng, X.; Cao, Y.; Wang, D.; Yang, L. Smart choice for the smart grid: Narrowband internet of things (NB-IoT). IEEE Internet Things J. 2018, 5, 1505–1515. [Google Scholar] [CrossRef]
- Mahmood, A.; Javaid, N.; Razzaq, S. A review of wireless communications for smart grid. Renew. Sustain. Energy Rev. 2015, 41, 248–260. [Google Scholar] [CrossRef]
- Li, L.; Hu, X.; Chen, K.; He, K. The applications of WiFi-based Wireless Sensor Network in Internet of Things and Smart Grid. In Proceedings of the 2011 6th IEEE Conference on Industrial Electronics and Applications, Beijing, China, 21–23 June 2011; IEEE: Manhattan, NY, USA, 2011; pp. 789–793. [Google Scholar]
- Lalle, Y.; Fourati, L.C.; Fourati, M.; Barraca, J.P. A Comparative Study of LoRaWAN, SigFox, and NB-IoT for Smart Water Grid. In Proceedings of the 2019 Global Information Infrastructure and Networking Symposium, Paris, France, 18–20 December 2019; IEEE: Manhattan, NY, USA, 2019; pp. 1–6. [Google Scholar]
- Division, E.M. Communication Network Solutions for Transmission and Distribution Grids. 2016. Available online: https://assets.new.siemens.com/siemens/assets/api/uuid:8b4809cf50679ccae32f511471c3eb92d064c814/version:1501223616/cgem-160662-communication-network-solutions-16-seiter-row-lowres-v080rz.pdf (accessed on 11 October 2021).
- Filho, H.G.S.; Filho, J.P.; Moreli, V.L. The adequacy of LoRaWAN on smart grids: A comparison with RF mesh technology. In Proceedings of the IEEE 2nd International Smart Cities Conference: Improving the Citizens Quality of Life, Trento, Italy, 12–15 September 2016; IEEE: Manhattan, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Meloni, A.; Atzori, L. The Role of Satellite Communications in the Smart Grid. IEEE Wirel. Commun. 2017, 24, 50–56. [Google Scholar] [CrossRef]
- Usman, A.; Shami, S.H. Evolution of communication technologies for smart grid applications. Renew. Sustain. Energy Rev. 2013, 19, 191–199. [Google Scholar] [CrossRef]
- Vegdani, M.; Bahadornejad, M.; Nair, N. Smart Grid Communications Infrastructure: A Discussion on Technologies and Opportunities. 2013. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwj5qM6t6ZT2AhVaxosBHRILADAQFnoECAUQAQ&url=https%3A%2F%2Fwiki.auckland.ac.nz%2Fdownload%2Fattachments%2F88902304%2FGreenGrid_ICT_WhitePaper_2013.pdf%3Fversion%3D1%26modificationDate%3D1415756060000%26api%3Dv2&usg=AOvVaw0vroo1AB6_ZxwkPCXQPHVi (accessed on 11 October 2021).
- Kabalci, Y. A survey on smart metering and smart grid communication. Renew. Sustain. Energy Rev. 2016, 57, 302–318. [Google Scholar] [CrossRef]
- Borovina, D.; Mujcic, A.; Zajc, M.; Suljanovic, N. Investigation of Narrow-Band Power-Line Carrier Communication System Performance in Rural Distribution Grids. Elektron. Elektrotechnika 2018, 24, 61–67. [Google Scholar] [CrossRef] [Green Version]
- Smith, D. What Is the Frequency Range in Optical Fibre Communication? Quora. 2019. Available online: https://www.quora.com/What-is-the-frequency-range-in-optical-fibre-communication (accessed on 5 July 2021).
- Calculating Fiber Loss and Distance Estimates. FOSCO. 2010. Available online: https://www.fiberoptics4sale.com/blogs/archive-posts/95049798-calculating-fiber-loss-and-distance-estimates (accessed on 5 July 2021).
- Aslam, M. Smart Grid Communication Infrastructure, Automation Technologies and Recent Trends. Am. J. Electr. Power Energy Syst. 2018, 7, 25. [Google Scholar] [CrossRef] [Green Version]
- Baimel, D.; Tapuchi, S.; Baimel, N. Smart grid communication technologies- overview, research challenges and opportunities. In Proceedings of the 2016 International Symposium on Power Electronics, Electrical Drives, Automation and Motion, SPEEDAM, Capri, Italy, 22–24 June 2016; Volume 2016, pp. 116–120. [Google Scholar]
- Jain, P.C. Trends in smart power grid communication and networking. In Proceedings of the 2015 International Conference on Signal Processing and Communication, Noida, India, 16–18 March 2015; IEEE: Manhattan, NY, USA, 2013; Volume 14, pp. 374–379. [Google Scholar]
- Pothuganti, K.; Chitneni, A. A comparative study of wireless protocols: Bluetooth, UWB, ZigBee, and Wi-Fi. Adv. Electron. Electr. Eng. 2014, 4, 655–662. [Google Scholar]
- Parikh, P.P.; Kanabar, M.G.; Sidhu, T.S. Opportunities and challenges of wireless communication technologies for smart grid applications. In Proceedings of the IEEE PES General Meeting, Minneapolis, MN, USA, 25–29 July 2010; IEEE: Manhattan, NY, USA, 2010; pp. 1–7. [Google Scholar]
- Ho, Q.D.; Gao, Y.; Le-Ngoc, T. Challenges and research opportunities in wireless communication networks for smart grid. IEEE Wirel. Commun. 2013, 20, 89–95. [Google Scholar]
- Mulla, A.; Baviskar, J.; Khare, S.; Kazi, F. The wireless technologies for smart grid communication: A review. In Proceedings of the 2015 5th International Conference on Communication Systems and Network Technologies, Gwalior, India, 4–6 April 2015; IEEE: Manhattan, NY, USA, 2015; pp. 442–447. [Google Scholar]
- Aravinthan, V.; Karimi, B.; Namboodiri, V.; Jewell, W. Wireless communication for smart grid applications at distribution level—Feasibility and requirements. In Proceedings of the 2011 IEEE Power and Energy Society General Meeting, Detroit, MI, USA, 24–28 July 2011; IEEE: Manhattan, NY, USA, 2011; pp. 1–8. [Google Scholar]
- 4 GHz vs. 5 GHz Wireless Frequency. Internet Broadband Deals, Reviews and Guides. Available online: https://checkmybroadbandspeed.online/2-4-ghz-vs-5-ghz-wireless-frequency/ (accessed on 25 November 2021).
- Namiot, D. On Mobile Mesh Networks. Int. J. Open Inf. Technol. 2015, 3, 38–41. [Google Scholar]
- Da Gama Schroder Filho, H.; Filho, J.P.; Moreli, V.L. The search for a convergent option to deploy smart grids on iot scenario. Adv. Sci. Technol. Eng. Syst. 2017, 2, 569–577. [Google Scholar] [CrossRef] [Green Version]
- What Frequency Spectrum Will 5G Technology Use and How Does This Compare to 4G? 2019. Available online: https://www.arrow.com/en/research-and-events/articles/what-frequency-spectrum-will-5g-technology-use-and-how-does-this-compare-to-4g (accessed on 12 November 2021).
- Triggs, R. What Is LTE? Everything You Need to Know. Android Authority. 2021. Available online: https://www.androidauthority.com/what-is-lte-283296/ (accessed on 13 November 2021).
- Parvin, J.R. An Overview of Wireless Mesh Networks. In Wireless Mesh Networks—Security, Architectures and Protocols; IntechOpen: London, UK, 2019. [Google Scholar]
- Malaysian Communications and Multimedia Commission. Press Release: Final Report on Allocation of Spectrum Bands for Mobile Broadband Service in Malaysia. Cyberjaya. 2020. Available online: https://www.mcmc.gov.my/en/media/press-releases/final-report-on-allocation-of-spectrum-bands-for-m (accessed on 11 October 2021).
- Minoli, D.; Occhiogrosso, B. Practical Aspects for the Integration of 5G Networks and IoT Applications in Smart Cities Environments. Wirel. Commun. Mob. Comput. 2019, 2019, 5710834. [Google Scholar] [CrossRef] [Green Version]
- Hui, H.; Ding, Y.; Shi, Q.; Li, F.; Song, Y.; Yan, J. 5G network-based Internet of Things for demand response in smart grid: A survey on application potential. Appl. Energy 2020, 257, 113972. [Google Scholar] [CrossRef]
- Tao, J.; Umair, M.; Ali, M.; Zhou, J. The impact of internet of things supported by emerging 5G in power systems: A review. CSEE J. Power Energy Syst. 2020, 6, 344–352. [Google Scholar]
- Gaurav, G.; Semra, B.; Christine, C. 5G Powered Utility Transformation. 2020. Available online: https://www.infosys.com/iki/insights/5g-powered-utility.html (accessed on 17 November 2021).
- Qualcomm. Everything You Need to Know about 5G. Available online: https://www.qualcomm.com/5g/what-is-5g (accessed on 20 November 2021).
- Malaysian Communications and Multimedia Commission. Requirements for Mobile Cellular Services Operating in the Frequency Band from 452.000 MHz to 456.475 MHz and 462.000 MHz to 466.475 MHz. 2006. Available online: https://www.mcmc.gov.my/skmmgovmy/files/attachments/SRSP541MCS.pdf (accessed on 17 November 2021).
- Mekki, K.; Bajic, E.; Chaxel, F.; Meyer, F. A comparative study of LPWAN technologies for large-scale IoT deployment. ICT Express 2019, 5, 1–7. [Google Scholar] [CrossRef]
- Ahmad, K.A.; Salleh, M.S.; Segaran, J.D.; Hashim, F.R. Impact of foliage on LoRa 433MHz propagation in tropical environment. AIP Conf. Proc. 2018, 1930, 1–7. [Google Scholar]
- EMBS LoRa 433 Benefits. 2019. Available online: https://openrb.com/wp-content/uploads/2019/02/EMBS-LoRa-433-benefits_security.pdf (accessed on 25 November 2021).
- LoRa® Alliance. A Technical Overview of LoRa® and LoRaWANTM. San Ramon. 2015. Available online: https://www.tuv.com/content-media-files/master-content/services/products/1555-tuv-rheinland-lora-alliance-certification/tuv-rheinland-lora-alliance-certification-overview-lora-and-lorawan-en.pdf (accessed on 25 November 2021).
- Cotrim, J.R.; Kleinschmidt, J.H. LoRaWAN Mesh Networks: A Review and Classification of Multihop Communication. Sensors 2020, 20, 4273. [Google Scholar] [CrossRef]
- Malaysian Communications and Multimedia Commission. Satellite Industry Developments. 2008. Available online: https://www.mcmc.gov.my/skmmgovmy/media/General/pdf/Satellite_Industry_Developments_compressed.pdf (accessed on 10 June 2021).
- European Telecommunications Standards Institute. ETSI TR 103 401 V1.1.1 (2016-11) Smart Grid Systems and Other Radio Systems Suitable for Utility Operations, and Their Long-Term Spectrum Requirements. 2019. Available online: https://www.etsi.org/deliver/etsi_tr/103400_103499/103401/01.01.01_60/tr_103401v010101p.pdf (accessed on 10 June 2021).
- Adams, T. SCADA Systems Intermediate Overview. Arlington. 2004. Available online: https://www.cedengineering.com/userfiles/SCADA%20Systems.pdf (accessed on 10 June 2021).
- Machine Learning. IBM Cloud Education. 2020. Available online: https://www.ibm.com/my-en/cloud/learn/machine-learning (accessed on 10 June 2021).
- Anisimova, A. Types of Machine Learning Out There. IDAP. Available online: https://idapgroup.com/blog/types-of-machine-learning-out-there/ (accessed on 10 June 2021).
- Dhall, D.; Kaur, R.; Juneja, M. Machine Learning: A Review of the Algorithms and Its Applications. In Proceedings of the ICRIC 2019, Jammu, India, 8–9 March 2019; Springer: Cham, Switzerland, 2020; pp. 47–63. [Google Scholar]
- Wu, X.; Wu, J. Criteria evaluation and selection in non-native language MBA students admission based on machine learning methods. J. Ambient Intell. Humaniz. Comput. 2020, 11, 3521–3533. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Machine learning: A review of classification and combining techniques. Artif. Intell. Rev. 2006, 26, 159–190. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Ahmadi, K.; Daneshi, A. Application of Support Vector Machine, Random Forest, and Genetic Algorithm Optimized Random Forest Models in Groundwater Potential Mapping. Water Resour. Manag. 2017, 31, 2761–2775. [Google Scholar] [CrossRef]
- Glen, S. Decision Tree vs. Random Forest vs. Gradient Boosting Machines: Explained Simply. Data Science Central. 2019. Available online: https://www.datasciencecentral.com/profiles/blogs/decision-tree-vs-random-forest-vs-boosted-trees-explained (accessed on 3 November 2021).
- RapidMiner. Gradient Boosted Trees. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/predictive/trees/gradient_boosted_trees.html (accessed on 3 November 2021).
- Sharma, T.; Gupta, P.; Nigam, V.; Goel, M. Customer Churn Prediction in Telecommunications Using Gradient Boosted Trees. In Proceedings of the International Conference on Innovative Computing and Communications, New Delhi, India, 21–23 February 2020; Springer: Singapore, 2020; pp. 235–246. [Google Scholar]
- Li, L.; Yu, Y.; Bai, S.; Hou, Y.; Chen, X. An Effective Two-Step Intrusion Detection Approach Based on Binary Classification and k-NN. IEEE Access 2018, 6, 12060–12073. [Google Scholar] [CrossRef]
- Yu, C.H. Resampling methods: Concepts, applications, and justification. Pract. Assess. Res. Eval. 2002, 8, 1–16. [Google Scholar]
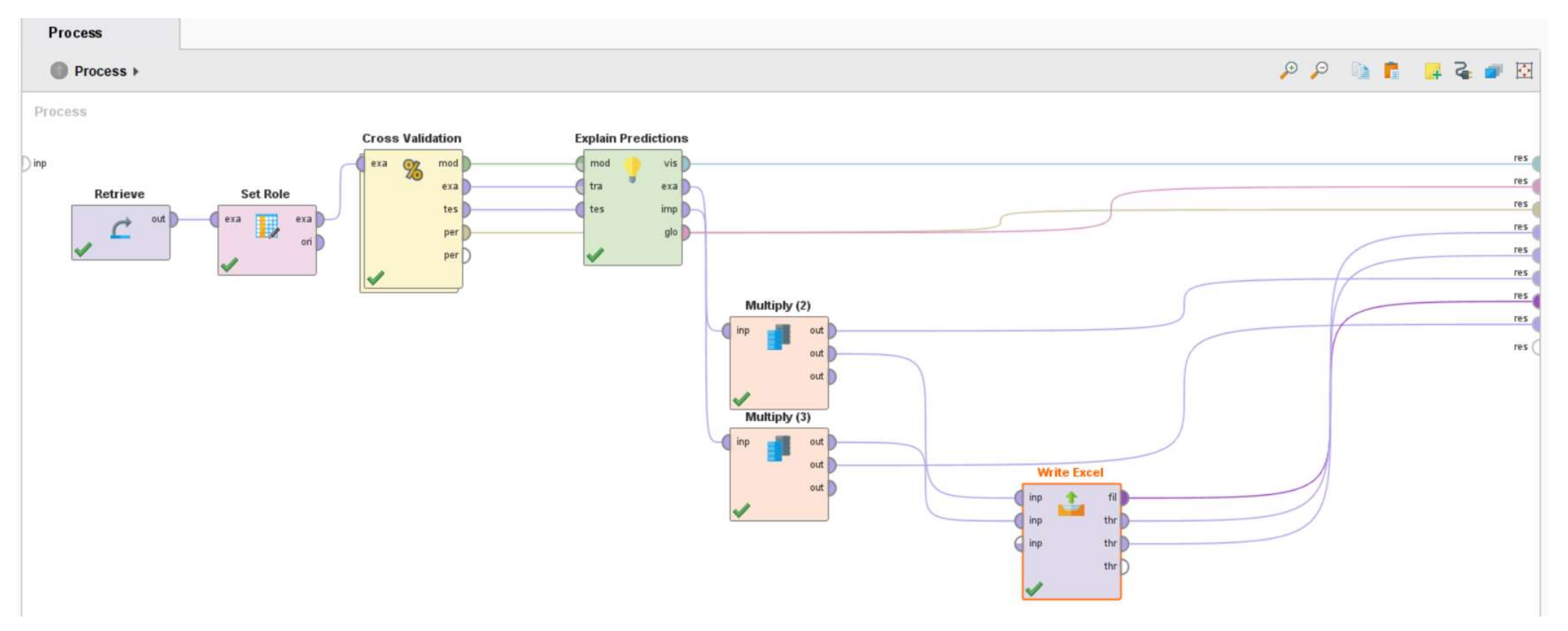
- RapidMiner. Cross Validation. Available online: https://docs.rapidminer.com/latest/studio/operators/validation/cross_validation.html (accessed on 7 November 2021).
- Sanjay, M. Why and how to Cross Validate a Model? 2018. Available online: https://towardsdatascience.com/why-and-how-to-cross-validate-a-model-d6424b45261f (accessed on 5 November 2021).
- Berrar, D. Cross-Validation. In Encyclopedia of Bioinformatics and Computational Biology; Ranganathan, S., Gribskov, M., Nakai, K., Schönbach, C., Eds.; Academic Press: Oxford, UK, 2019; pp. 542–545. [Google Scholar]
- Wu, C.C.; Yeh, W.C.; Hsu, W.D.; Islam, M.M.; Nguyen, P.A.; Poly, T.N.; Wang, Y.C.; Yang, H.C.; Li, Y.C. Prediction of fatty liver disease using machine learning algorithms. Comput. Methods Programs Biomed. 2019, 170, 23–29. [Google Scholar] [CrossRef]
- Brownlee, J. A Gentle Introduction to k-fold Cross-Validation. Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/K-fold-cross-validation/ (accessed on 3 November 2021).
- Kumar, S. Understanding 8 Types of Cross-Validation. 2020. Available online: https://towardsdatascience.com/understanding-8-types-of-cross-validation-80c935a4976d (accessed on 3 November 2021).
- Great Learning Team. What is Cross Validation in Machine Learning? Types of Cross Validation. Great Learning. 2020. Available online: https://www.mygreatlearning.com/blog/cross-validation (accessed on 7 November 2021).
- Tamilarasi, P.; Rani, R.U. Diagnosis of Crime Rate against Women using k-fold Cross Validation through Machine Learning. In Proceedings of the 2020 Fourth International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 11–13 March 2020; IEEE: Manhattan, NY, USA, 2020; pp. 1034–1038. [Google Scholar]
- Lyashenko, V. Cross-Validation in Machine Learning: How to Do It Right. Neptune Blog. 2021. Available online: https://neptune.ai/blog/cross-validation-in-machine-learning-how-to-do-it-right (accessed on 14 November 2021).
- De Rooij, M.; Weeda, W. Cross-Validation: A Method Every Psychologist Should Know. Adv. Methods Pract. Psychol. Sci. 2020, 3, 248–263. [Google Scholar] [CrossRef]
- Kuhn, M.; Johnson, K. Over-Fitting and Model Tuning. In Applied Predictive Modeling; Springer: New York, NY, USA, 2013; pp. 61–92. [Google Scholar]
- RapidMiner. Explain Predictions. Available online: https://docs.rapidminer.com/9.0/studio/operators/scoring/explain_predictions.html (accessed on 10 November 2021).
- How to Decide when to Use Naive Bayes for Classification. Analytics Vidhya. 2015. Available online: https://discuss.analyticsvidhya.com/t/how-to-decide-when-to-use-naive-bayes-for-classification/5720/2 (accessed on 13 November 2021).




{kind=link}
{kind=link}
{kind=link}
| Acronyms | Definition |
|---|---|
| AMI | Advanced Metering Infrastructure |
| EV | Electric Vehicle |
| HAN | Home Area Network |
| IoT | Internet of Things |
| k-NN | k-Nearest Neighbor |
| LoS | Line of Sight |
| LTE | Long-Term Evolution |
| ML | Machine Learning |
| M2M | Multipoint-to-Multipoint |
| NB-IoT | Narrow-Band IoT |
| NBPLC | Narrowband Power Line Communication |
| P2M | Point-to-Multipoint |
| P2P | Point-to-Point |
| PLC | Power Line Communication |
| SATCOM | Satellite communication |
| UHF | Ultra-high frequency |
| WAN | Wide Area Networks |
| Technology | Frequency (MHz) | Data Rate (Mbps) | Distance (km) | Frequency Bandwidth (MHz) | Physical Topology | Scalability (%) | Line-of-Sight (%) | Interference (%) | Terrain Factor |
|---|---|---|---|---|---|---|---|---|---|
| NBPLC | 0.01 | 0.5 | 150 | 0.1 | Point-to-Point | 30 | 70 | 60 | City |
| NBPLC | 0.01 | 0.5 | 150 | 0.1 | Point-to-Multipoint | 45 | 70 | 60 | City |
| NBPLC | 0.1 | 0.5 | 150 | 0.1 | Point-to-Point | 30 | 70 | 60 | City |
| NBPLC | 0.1 | 0.5 | 150 | 0.1 | Point-to-Multipoint | 45 | 70 | 60 | City |
| NBPLC | 0.3 | 0.5 | 150 | 0.1 | Point-to-Point | 30 | 70 | 60 | City |
| NBPLC | 0.3 | 0.5 | 150 | 0.1 | Point-to-Multipoint | 45 | 70 | 60 | City |
| NBPLC | 0.5 | 0.5 | 150 | 0.1 | Point-to-Point | 30 | 70 | 60 | City |
| NBPLC | 0.5 | 0.5 | 150 | 0.1 | Point-to-Multipoint | 45 | 70 | 60 | City |
| Fiber | 193,000,000 | 1000 | 70 | 50,000 | Point-to-Point | 60 | 85 | 60 | City |
| Fiber | 193,000,000 | 1000 | 70 | 50,000 | Point-to-Multipoint | 80 | 85 | 60 | City |
| Fiber | 193,000,000 | 1000 | 70 | 100,000 | Point-to-Point | 60 | 85 | 60 | City |
| Fiber | 193,000,000 | 1000 | 70 | 100,000 | Point-to-Multipoint | 80 | 85 | 60 | City |
| NBPLC | 0.01 | 0.5 | 150 | 0.1 | Point-to-Point | 30 | 70 | 45 | Coastal |
| NBPLC | 0.01 | 0.5 | 150 | 0.1 | Point-to-Multipoint | 45 | 70 | 45 | Coastal |
| Technology | Frequency (MHz) | Data Rate (Mbps) | Distance (km) | Frequency Bandwidth (MHz) | Physical Topology | Terrain Factor | Scalability(%) | LoS (%) | Interference(%) |
|---|---|---|---|---|---|---|---|---|---|
| NBPLC |
|
[16,18] |
|
|
|
|
|
|
|
| Fiber optics |
|
|
|
|
|
|
|
|
|
| Zigbee |
[16,17] [22,23,24,25] |
[17,23,24,25,26,27] |
[23,24,26] |
|
[24,27,28] |
|
|
|
|
| WiFi |
[23,24] [26,28,29] |
[27,30] |
|
|
|
|
|
|
|
| RF Mesh |
|
|
|
|
|
|
|
|
|
| Cellular Network—4G LTE |
|
|
|
|
|
|
|
|
|
| 5G |
|
|
|
|
|
|
|
|
|
| Cellular Network—Private LTE |
|
|
|
|
|
|
|
|
|
| NB-IoT (LTE) |
|
|
|
|
|
|
|
|
|
| LoRa |
|
|
|
|
|
|
|
|
|
| SATCOM |
|
|
|
|
|
|
|
|
|
| UHF |
|
|
|
|
|
|
|
|
|
| ML Model | Advantages | Disadvantages |
|---|---|---|
| Naïve Bayes |
|
|
| Decision Tree |
|
|
| Random Tree Forest |
|
|
| Gradient Boosted Tree |
|
|
| k-Nearest Neighbor |
|
|
| Models | Cross Validation Accuracy | Standard Deviation | Execution Time (Cross Validation) | Execution Time (Explain Prediction) |
|---|---|---|---|---|
| Naïve Bayes | 98.41% | +/− 0.79% | 28–50 ms | 3320–3800 ms |
| Decision Tree | 97.05% | +/− 2.94% | 45–80 ms | 1800–2500 ms |
| Random Forest | 97.95% | +/− 1.29% | 980–2400 ms | 144,000–160,000 ms |
| Gradient Boosted Tree | 98.07% | +/− 1.52% | 3700–9400 ms | 28,000–40,000 ms |
| k-NN | 97.73% | +/− 1.42% | 95–150 ms | 47,000–55,000 ms |
| Criteria | Average |
|---|---|
| Frequency | 0.0127919 |
| Distance | 0.0086610 |
| Scalability | 0.0048568 |
| Data rate | 0.0037547 |
| Reliability | 0.0032249 |
| Physical Topology | 0.0013349 |
| Frequency Bandwidth | 0.0003337 |
| Terrain Factor | −0.0016518 |
| Interference | −0.0067775 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azhar, N.A.; Mohamed Radzi, N.A.; Mohd Azmi, K.H.; Samidi, F.S.; Muhammad Zainal, A. Criteria Selection Using Machine Learning (ML) for Communication Technology Solution of Electrical Distribution Substations. Appl. Sci. 2022, 12, 3878. https://doi.org/10.3390/app12083878
Azhar NA, Mohamed Radzi NA, Mohd Azmi KH, Samidi FS, Muhammad Zainal A. Criteria Selection Using Machine Learning (ML) for Communication Technology Solution of Electrical Distribution Substations. Applied Sciences. 2022; 12(8):3878. https://doi.org/10.3390/app12083878
Chicago/Turabian StyleAzhar, Nayli Adriana, Nurul Asyikin Mohamed Radzi, Kaiyisah Hanis Mohd Azmi, Faris Syahmi Samidi, and Alisadikin Muhammad Zainal. 2022. "Criteria Selection Using Machine Learning (ML) for Communication Technology Solution of Electrical Distribution Substations" Applied Sciences 12, no. 8: 3878. https://doi.org/10.3390/app12083878