
Automatic Bug Triaging via Deep Reinforcement Learning


Abstract
:1. Introduction
- A bug triaging model based on RL is presented, in which feature extraction is performed using neural networks, and newly created bug reports can be assigned online in real time.
- A bidirectional RNN that integrates multidimensional features is adopted, and it can capture the information of different levels more comprehensively while rendering the representation of bug reports more robust for bug triaging, compared with the SVM and the method proposed by Yang [20].
- The BT-RL model on real-world datasets (NetBeans, OpenOffice, Mozilla, and Eclipse) is validated. Comprehensive experimental results show that the BT-RL model performs better than state-of-the-art models.
2. Related Works
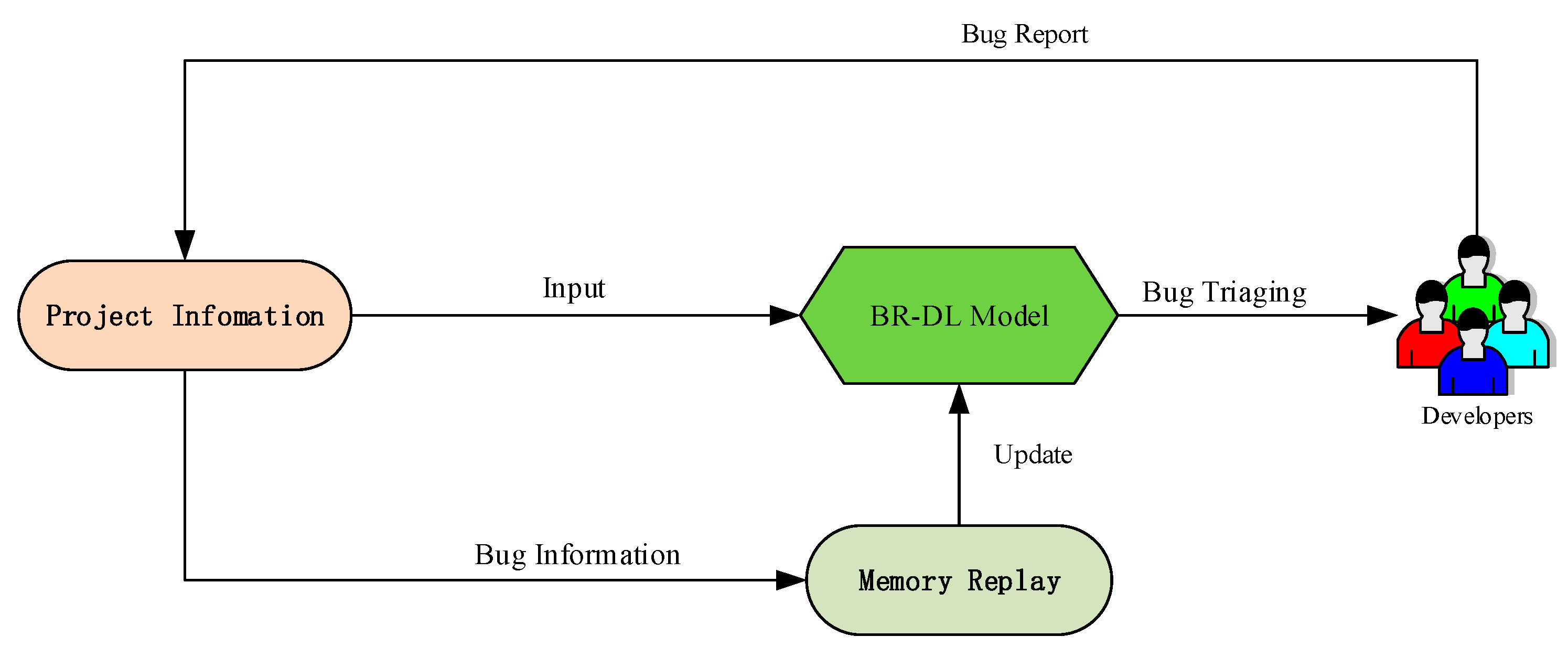
3. Motivation
4. Bug Triaging via Deep Reinforcement (BT-RL) Model
4.1. Overview
| Algorithm 1: BT-RL Algorithm via DQN |
| Input: input D to capacity N, B, C, L Out-put: Top-K developers for each bug task ; ; For episode = 1, M do; ; For t = 1, T do; ; Otherwise select ; in emulator and observe ; and preprocess ; in D; Set ; Perform a gradient descent step; ; End For; End For; |
4.2. DMSF Model
4.3. ODM Model
4.3.1. MDP
- 1.
- States (S)
- 2.
- Action (A)
- 3.
- Transition probability ()
- 4.
- Reward Function ()
4.3.2. Policy and Expectation Function
5. Results
5.1. Datasets
- When extracting bug reports, repair status “fixed” is retained.
- Remove bug reports fixed by invalid developers (specifically defined as “unassigned”, “issues”, “needs confirmation”, “nobody”, “webmaster”, “inbox”).
- Remove bug reports fixed by inefficient developers (inefficient developers are those who repair less than n (which equals 20) fixed reports).
- Count and filter high- and low-frequency words to reduce noise.
- Extract the developer engagement information and collect the developer engagement sequence that is the same as the subproject and module information for the current bug report. The maximum number of recorded bug reports is 25 (if the upper limit is exceeded, the closest 25 bug reports are selected). The time interval is three months ahead of the current time node. It is observed that 80% of the developer engagement sequences in 3 months can yield 20 bug reports or more.
5.2. Baselines
5.3. Evaluation Metrics
5.4. Experimental Results
6. Threats to Validity
6.1. Internal Validity
6.2. External Validity
6.3. Construct Validity
7. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Defect Statistics. Apache OpenOffice. Available online: https://www.openoffice.org/stats/defects.html (accessed on 25 February 2022).
- Deng, W.; Zhang, X.X.; Zhou, Y.Q.; Liu, Y.; Zhou, X.B.; Chen, H.L.; Zhao, H.M. An enhanced fast non-dominated solution sorting genetic algorithm for multi-objective problems. Inform. Sci. 2022, 585, 441–453. [Google Scholar] [CrossRef]
- Ran, X.; Zhou, X.; Lei, M.; Tepsan, W.; Deng, W. A novel k-means clustering algorithm with a noise algorithm for capturing urban hotspots. Appl. Sci. 2021, 11, 11202. [Google Scholar] [CrossRef]
- Li, G.; Li, Y.; Chen, H.; Deng, W. Fractional-Order Controller for Course-Keeping of Underactuated Surface Vessels Based on Frequency Domain Specification and Improved Particle Swarm Optimization Algorithm. Appl. Sci. 2022, 12, 3139. [Google Scholar] [CrossRef]
- Wang, X.; Wang, H.Y.; Du, C.Z.; Fan, X.; Cui, L.; Chen, H.; Deng, F.; Tong, Q.; He, M.; Yang, M.; et al. Custom-molded offloading footwear effectively prevents recurrence and amputation, and lowers mortality rates in high-risk diabetic foot patients: A multicenter, prospective observational study. Diabetes Metab. Syndr. Obes. Targets Ther. 2022, 15, 103–109. [Google Scholar]
- Cui, H.; Guan, Y.; Chen, H. Rolling element fault diagnosis based on VMD and sensitivity MCKD. IEEE Access 2021, 9, 120297–120308.52. [Google Scholar] [CrossRef]
- Deng, W.; Li, Z.; Li, X.; Chen, H.; Zhao, H. Compound fault diagnosis using optimized MCKD and sparse representation for rolling bearings. IEEE Trans. Instrum. Meas. 2022, 71, 3508509. [Google Scholar] [CrossRef]
- Anvik, J.; Hiew, L.; Murphy, G.C. Coping with an open bug repository. In Proceedings of the 2005 OOPSLA Workshop on Eclipse Technology eXchange, San Diego, CA, USA, 16–17 October 2005; pp. 35–39. [Google Scholar]
- Gu, Z.; Barr, E.T.; Hamilton, D.J.; Su, Z. Has the bug really been fixed? In Proceedings of the 32th ACM/IEEE International Conference on Software Engineering, Cape Town, South Africa, 2–8 May 2010; pp. 55–64. [Google Scholar]
- Collofello, J.S.; Woodfield, S.N. Evaluating the effectiveness of reliability-assurance techniques. J. Syst. Softw. 1989, 9, 191–195. [Google Scholar] [CrossRef]
- Wu, W.; Zhang, W.; Yang, Y.; Wang, Q. Time series analysis for bug number prediction. In Proceedings of the 2th International Software Engineering and Data Mining, Chengdu, China, 23–25 June 2010; pp. 589–596. [Google Scholar]
- Kawakami, K. Supervised Sequence Labelling with Recurrent Neural Networks. Ph.D. Thesis, Technical University of Munich, München, Germany, 2008. [Google Scholar]
- Tamrawi, A.; Nguyen, T.T.; Al-Kofahi, J.M.; Nguyen, T.N. Fuzzy set and cache-based approach for bug triaging. In Proceedings of the 19th ACM and the 13th on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; pp. 365–375. [Google Scholar]
- Naguib, H.; Narayan, N.; Brgge, B.; Helal, D. Bug report assignee recommendation using activity profiles. In Proceedings of the 10th Mining Software Repositories, San Francisco, CA, USA, 18–19 May 2013; pp. 22–30. [Google Scholar]
- Nigam, K.; Mccallum, A.K.; Thrun, S.; Mitchell, T. Text classfication from labeled and unlabeled documents using EM. Mach. Learn. 2000, 39, 103–134. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Wang, S.; Wang, Q. KSAP: An approach to bug report triaging using KNN search and heterogeneous proximity. Inf. Softw. Technol. 2016, 70, 68–84. [Google Scholar] [CrossRef]
- Anvik, J.; Lyndon, H.; Murphy, G.C. Who should fix this bug? In Proceedings of the 28th International Software Engineering, Shanghai, China, 20–28 May 2006; pp. 361–370. [Google Scholar]
- Syed, N.A.; Javed, F.; Franz, W. Automatic Software Bug Triaging System (BTS) Based on Latent Semantic Indexing and Support Vector Machine. In Proceedings of the 2009 Fourth International Conference on Software Engineering Advances, Porto, Portugal, 20–25 September 2009; pp. 216–221. [Google Scholar]
- Xuan, J.; Jiang, H.; Ren, Z.; Yan, J.; Luo, Z. Automatic Bug Triaging using Semi-Supervised Text Classification. In Proceedings of the 22nd International Conference on Software Engineering and Knowledge Engineering (SEKE 2010), Redwood City, San Francisco Bay, CA, USA, 1–3 July 2010; pp. 209–214. [Google Scholar]
- Yang, G.; Zhang, T.; Lee, B. Towards semi-automatic bug triaging and severity prediction based on topic model and mul-ti-feature of bug reports. In Proceedings of the 38th Annual Computer Software and Applications Conference, Vasteras, Sweden, 21–25 July 2014; pp. 97–106. [Google Scholar]
- Wu, W.; Zhang, W.; Yang, Y.; Wang, Q. Drex: Developer recommendation with k-nearest neighbor search and expertise ranking. In Proceedings of the 18th Asia-Pacific Software Engineering Conference, Ho Chi Minh City, Vietnam, 5–8 December 2011; pp. 389–396. [Google Scholar]
- Davor, C.; Murphy, G.C. Automatic bug triaging using text categorization. In Proceedings of the Sixteenth International Conference on Software Engineering & Knowledge Engineering, Banff, AB, Canada, 20–24 June 2004; pp. 92–97. [Google Scholar]
- Xie, X.; Zhang, W.; Yang, Y.; Wang, Q. DRETOM: Developer recommendation based on topic models for bug resolution. In Proceedings of the 8th International Conference on Predictive Models in Software Engineering, Lund, Sweden, 21–22 September 2012; pp. 19–28. [Google Scholar]
- Nguyen, T.T.; Nguyen, A.T.; Nguyen, T.N. Topic-based, time-aware bug assignment. ACM SIGSOFT Softw. Eng. Notes 2014, 39, 1–4. [Google Scholar] [CrossRef]
- Zhang, T.; Yang, G.; Lee, B.; Lua, E.K. A novel developer ranking algorithm for automatic bug triaging using topic model and de-veloper relations. In Proceedings of the 21st Asia-Pacific Software Engineering Conference, Jeju, Korea, 1–4 December 2014; Volume 1, pp. 223–230. [Google Scholar]
- Yan, M.; Zhang, X.; Yang, D.; Xu, L.; Kymer, J.D. A component recommender for bug reports using discrim-inative probability latent semantic analysis. Inf. Softw. Technol. 2016, 73, 37–51. [Google Scholar] [CrossRef]
- Xuan, J.; Jiang, H.; Zhang, H.; Ren, Z. Developer recommendation on bug commenting: A ranking approach for the developer crowd. Sci. China Inf. Sci. 2017, 60, 072105. [Google Scholar] [CrossRef]
- Somasundaram, K.; Murphy, G.C. Automatic categorization of bug reports using latent dirichlet allocation. In Proceedings of the 5th India Software Engineering Conference, Kanpur, India, 22–25 February 2012; pp. 125–130. [Google Scholar]
- Yin, Y.; Dong, X.; Xu, T. Rapid and Efficient Bug Triaging Using ELM for IOT Software. IEEE Access 2018, 6, 52713–52724. [Google Scholar] [CrossRef]
- Khatun, A.; Sakib, K. A Bug Triaging Approach Combining Expertise and Recency of Both Bug Fixing and Source Commits. In Proceedings of the 13th International Conference on Evaluation of Novel Approaches to Software Engineering, Funchal, Portugal, 23–24 March 2018; pp. 351–358. [Google Scholar] [CrossRef]
- Yadav, A.; Singh, S.K. A novel and improved developer rank algorithm for bug assignment. Int. J. Intell. Syst. Technol. Appl. 2020, 19, 78–101. [Google Scholar]
- Jahanshahi, H.; Chhabra, K.; Cevik, M.; Basar, A. DABT: A Dependency-aware Bug Triaging Method. In Evaluation and Assessment in Software Engineering; ACM: New York, NY, USA, 2021; pp. 221–230. [Google Scholar]
- Su, Y.; Xing, Z.; Peng, X.; Xia, X.; Wang, C.; Xu, X.; Zhu, L. Reducing Bug Triaging Confusion by Learning from Mistakes with a Bug Tossing Knowledge Graph. In Proceedings of the 2021 36th IEEE/ACM International Conference on Automated Software Engineering (ASE), Melbourne, Australia, 15–19 November 2021; pp. 191–202. [Google Scholar]
- Wu, H.; Ma, Y.; Xiang, Z.; Yang, C.; He, K. A Spatial-Temporal Graph Neural Network Framework for Automated Software Bug Triaging. Knowl.-Based Syst. 2022, 241, 108308. [Google Scholar] [CrossRef]
- Guo, S.; Zhang, X.; Yang, X.; Chen, R.; Guo, C.; Li, H.; Li, T. Developer activity motivated bug triaging: Via convolutional neural network. Neural Processing Lett. 2020, 51, 2589–2606. [Google Scholar] [CrossRef]
- Kashiwa, Y.; Ohira, M. A Release-Aware Bug Triaging Method Considering Developers’ Bug-Fixing Loads. IEICE TRANSAC-TIONS Inf. Syst. 2020, 103, 348–362. [Google Scholar] [CrossRef] [Green Version]
- Mani, S.; Sankaran, A.; Aralikatte, R. Deeptriaging: Exploring the effectiveness of deep learning for bug triaging. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data, Kolkata, India, 3–5 January 2019; pp. 171–179. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Project | Period | Bug Reports | Developers | Subprojects | Components | Avg_dev_fix | Avg_mon_bug |
|---|---|---|---|---|---|---|---|
| NetBeans | 1 January 2008 to 11 January 2010 | 22,691 | 226 | 33 | 148 | 85.30 | 961 |
| OpenOffice | 1 March 2007 to 7 April 2013 | 23,491 | 553 | 36 | 116 | 42.48 | 341 |
| Mozilla | 23 June 2009 to 3 June 2010 | 18,793 | 1021 | 12 | 167 | 18.40 | 1705 |
| Eclipse | 1 January 2008 to 23 July 2009 | 41,830 | 772 | 7 | 114 | 54.25 | 2418 |
| Project | Period | Bug Reports | Developers | Token Length | Subprojects | Components |
|---|---|---|---|---|---|---|
| NetBeans | 1 January 2008 to 11 January 2010 | 15,824 | 129 | 6997 | 14 | 134 |
| OpenOffice | 1 March 2007 to 7 April 2013 | 20,516 | 169 | 4637 | 36 | 116 |
| Mozilla | 23 June 2009 to 3 June 2010 | 14,565 | 229 | 5545 | 12 | 167 |
| Eclipse | 1 January 2008 to 23 July 2009 | 26,949 | 291 | 9017 | 7 | 114 |
| Project | Top-k | LDA_KL | LDA_SVM | DERTOM | DeepTriaging | BT-RL |
|---|---|---|---|---|---|---|
| NetBeans | Top5 | 0.28 | 0.48 | 0.48 | 0.33 | 0.54 |
| Top4 | 0.26 | 0.48 | 0.44 | 0.33 | 0.52 | |
| Top3 | 0.20 | 0.46 | 0.36 | 0.33 | 0.48 | |
| Top2 | 0.18 | 0.40 | 0.32 | 0.18 | 0.44 | |
| Top1 | 0.10 | 0.26 | 0.10 | 0.04 | 0.34 | |
| Mozilla | Top5 | 0.46 | 0.62 | 0.54 | 0.52 | 0.68 |
| Top4 | 0.42 | 0.60 | 0.52 | 0.52 | 0.66 | |
| Top3 | 0.36 | 0.60 | 0.46 | 0.48 | 0.64 | |
| Top2 | 0.32 | 0.50 | 0.40 | 0.38 | 0.52 | |
| Top1 | 0.16 | 0.20 | 0.16 | 0.20 | 0.28 | |
| Eclipse | Top5 | 0.58 | 0.74 | 0.72 | 0.47 | 0.78 |
| Top4 | 0.50 | 0.70 | 0.62 | 0.37 | 0.72 | |
| Top3 | 0.42 | 0.66 | 0.58 | 0.27 | 0.68 | |
| Top2 | 0.36 | 0.52 | 0.52 | 0.18 | 0.58 | |
| Top1 | 0.16 | 0.40 | 0.32 | 0.12 | 0.46 | |
| OpenOffice | Top5 | 0.44 | 0.50 | 0.46 | 0.20 | 0.52 |
| Top4 | 0.40 | 0.44 | 0.38 | 0.20 | 0.46 | |
| Top3 | 0.32 | 0.42 | 0.36 | 0.20 | 0.42 | |
| Top2 | 0.22 | 0.30 | 0.28 | 0.16 | 0.30 | |
| Top1 | 0.16 | 0.26 | 0.20 | 0.10 | 0.18 |
| Project | Top-k | LDA_KL | LDA_SVM | DERTOM | DeepTriaging | BT-RL |
|---|---|---|---|---|---|---|
| NetBeans | Top5 | 0.48 | 0.70 | 0.62 | 0.44 | 0.76 |
| Top4 | 0.36 | 0.60 | 0.60 | 0.35 | 0.72 | |
| Top3 | 0.28 | 0.58 | 0.54 | 0.35 | 0.64 | |
| Top2 | 0.20 | 0.48 | 0.44 | 0.31 | 0.54 | |
| Top1 | 0.10 | 0.36 | 0.28 | 0.21 | 0.40 | |
| Mozilla | Top5 | 0.36 | 0.52 | 0.52 | 0.38 | 0.52 |
| Top4 | 0.32 | 0.48 | 0.46 | 0.33 | 0.50 | |
| Top3 | 0.26 | 0.38 | 0.42 | 0.33 | 0.44 | |
| Top2 | 0.18 | 0.32 | 0.34 | 0.29 | 0.32 | |
| Top1 | 0.06 | 0.12 | 0.18 | 0.13 | 0.22 | |
| Eclipse | Top5 | 0.42 | 0.52 | 0.44 | 0.40 | 0.64 |
| Top4 | 0.38 | 0.46 | 0.42 | 0.23 | 0.62 | |
| Top3 | 0.24 | 0.44 | 0.42 | 0.19 | 0.56 | |
| Top2 | 0.18 | 0.28 | 0.36 | 0.13 | 0.42 | |
| Top1 | 0.08 | 0.22 | 0.26 | 0.08 | 0.26 | |
| OpenOffice | Top5 | 0.40 | 0.46 | 0.42 | 0.15 | 0.48 |
| Top4 | 0.40 | 0.38 | 0.40 | 0.08 | 0.40 | |
| Top3 | 0.32 | 0.32 | 0.32 | 0.04 | 0.38 | |
| Top2 | 0.22 | 0.28 | 0.30 | 0.04 | 0.28 | |
| Top1 | 0.16 | 0.14 | 0.16 | 0.04 | 0.10 |
| Project | Top-k | LDA_KL | LDA_SVM | DERTOM | DeepTriaging | BT-RL |
|---|---|---|---|---|---|---|
| NetBeans | Top5 | 0.50 | 0.52 | 0.48 | 0.31 | 0.54 |
| Top4 | 0.46 | 0.46 | 0.44 | 0.31 | 0.48 | |
| Top3 | 0.40 | 0.44 | 0.40 | 0.27 | 0.48 | |
| Top2 | 0.36 | 0.40 | 0.38 | 0.25 | 0.46 | |
| Top1 | 0.20 | 0.34 | 0.34 | 0.23 | 0.38 | |
| Mozilla | Top5 | 0.46 | 0.48 | 0.30 | 0.10 | 0.50 |
| Top4 | 0.36 | 0.38 | 0.24 | 0.10 | 0.44 | |
| Top3 | 0.32 | 0.36 | 0.20 | 0.10 | 0.36 | |
| Top2 | 0.28 | 0.22 | 0.16 | 0.06 | 0.30 | |
| Top1 | 0.14 | 0.10 | 0.04 | 0.04 | 0.22 | |
| Eclipse | Top5 | 0.50 | 0.50 | 0.48 | 0.40 | 0.58 |
| Top4 | 0.40 | 0.50 | 0.42 | 0.35 | 0.54 | |
| Top3 | 0.32 | 0.40 | 0.38 | 0.25 | 0.44 | |
| Top2 | 0.22 | 0.36 | 0.34 | 0.23 | 0.36 | |
| Top1 | 0.12 | 0.32 | 0.28 | 0.21 | 0.22 | |
| OpenOffice | Top5 | 0.34 | 0.46 | 0.38 | 0.27 | 0.50 |
| Top4 | 0.32 | 0.40 | 0.36 | 0.23 | 0.40 | |
| Top3 | 0.28 | 0.34 | 0.30 | 0.23 | 0.40 | |
| Top2 | 0.22 | 0.30 | 0.22 | 0.02 | 0.34 | |
| Top1 | 0.06 | 0.22 | 0.20 | 0.02 | 0.32 |
| Project | Top-k | BT-RL-T | BT-RL-D | BT-RL-TD |
|---|---|---|---|---|
| NetBeans | Top5 | 0.40 | 0.54 | 0.54 |
| Top4 | 0.32 | 0.50 | 0.52 | |
| Top3 | 0.32 | 0.46 | 0.48 | |
| Top2 | 0.28 | 0.44 | 0.44 | |
| Top1 | 0.26 | 0.32 | 0.34 | |
| Mozilla | Top5 | 0.52 | 0.64 | 0.68 |
| Top4 | 0.50 | 0.64 | 0.66 | |
| Top3 | 0.48 | 0.62 | 0.64 | |
| Top2 | 0.44 | 0.52 | 0.52 | |
| Top1 | 0.20 | 0.38 | 0.28 | |
| Eclipse | Top5 | 0.42 | 0.50 | 0.78 |
| Top4 | 0.38 | 0.50 | 0.72 | |
| Top3 | 0.32 | 0.50 | 0.68 | |
| Top2 | 0.26 | 0.46 | 0.58 | |
| Top1 | 0.22 | 0.26 | 0.46 | |
| OpenOffice | Top5 | 0.36 | 0.48 | 0.52 |
| Top4 | 0.34 | 0.42 | 0.46 | |
| Top3 | 0.28 | 0.38 | 0.42 | |
| Top2 | 0.22 | 0.24 | 0.30 | |
| Top1 | 0.14 | 0.20 | 0.18 |
| Project | Top-k | BT-RL-T | BT-RL-D | BT-RL-TD |
|---|---|---|---|---|
| NetBeans | Top5 | 0.50 | 0.46 | 0.54 |
| Top4 | 0.46 | 0.42 | 0.52 | |
| Top3 | 0.44 | 0.40 | 0.48 | |
| Top2 | 0.42 | 0.30 | 0.44 | |
| Top1 | 0.24 | 0.26 | 0.34 | |
| Mozilla | Top5 | 0.56 | 0.50 | 0.68 |
| Top4 | 0.50 | 0.48 | 0.66 | |
| Top3 | 0.40 | 0.38 | 0.64 | |
| Top2 | 0.38 | 0.30 | 0.52 | |
| Top1 | 0.38 | 0.30 | 0.28 | |
| Eclipse | Top5 | 0.60 | 0.56 | 0.78 |
| Top4 | 0.60 | 0.56 | 0.72 | |
| Top3 | 0.56 | 0.50 | 0.68 | |
| Top2 | 0.44 | 0.38 | 0.58 | |
| Top1 | 0.28 | 0.28 | 0.46 | |
| OpenOffice | Top5 | 0.46 | 0.44 | 0.52 |
| Top4 | 0.40 | 0.40 | 0.46 | |
| Top3 | 0.32 | 0.28 | 0.42 | |
| Top2 | 0.32 | 0.28 | 0.30 | |
| Top1 | 0.24 | 0.22 | 0.18 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Qi, X.; Zhang, J.; Li, H.; Ge, X.; Ai, J. Automatic Bug Triaging via Deep Reinforcement Learning. Appl. Sci. 2022, 12, 3565. https://doi.org/10.3390/app12073565
Liu Y, Qi X, Zhang J, Li H, Ge X, Ai J. Automatic Bug Triaging via Deep Reinforcement Learning. Applied Sciences. 2022; 12(7):3565. https://doi.org/10.3390/app12073565
Chicago/Turabian StyleLiu, Yong, Xuexin Qi, Jiali Zhang, Hui Li, Xin Ge, and Jun Ai. 2022. "Automatic Bug Triaging via Deep Reinforcement Learning" Applied Sciences 12, no. 7: 3565. https://doi.org/10.3390/app12073565