
AI and Clinical Decision Making: The Limitations and Risks of Computational Reductionism in Bowel Cancer Screening


{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
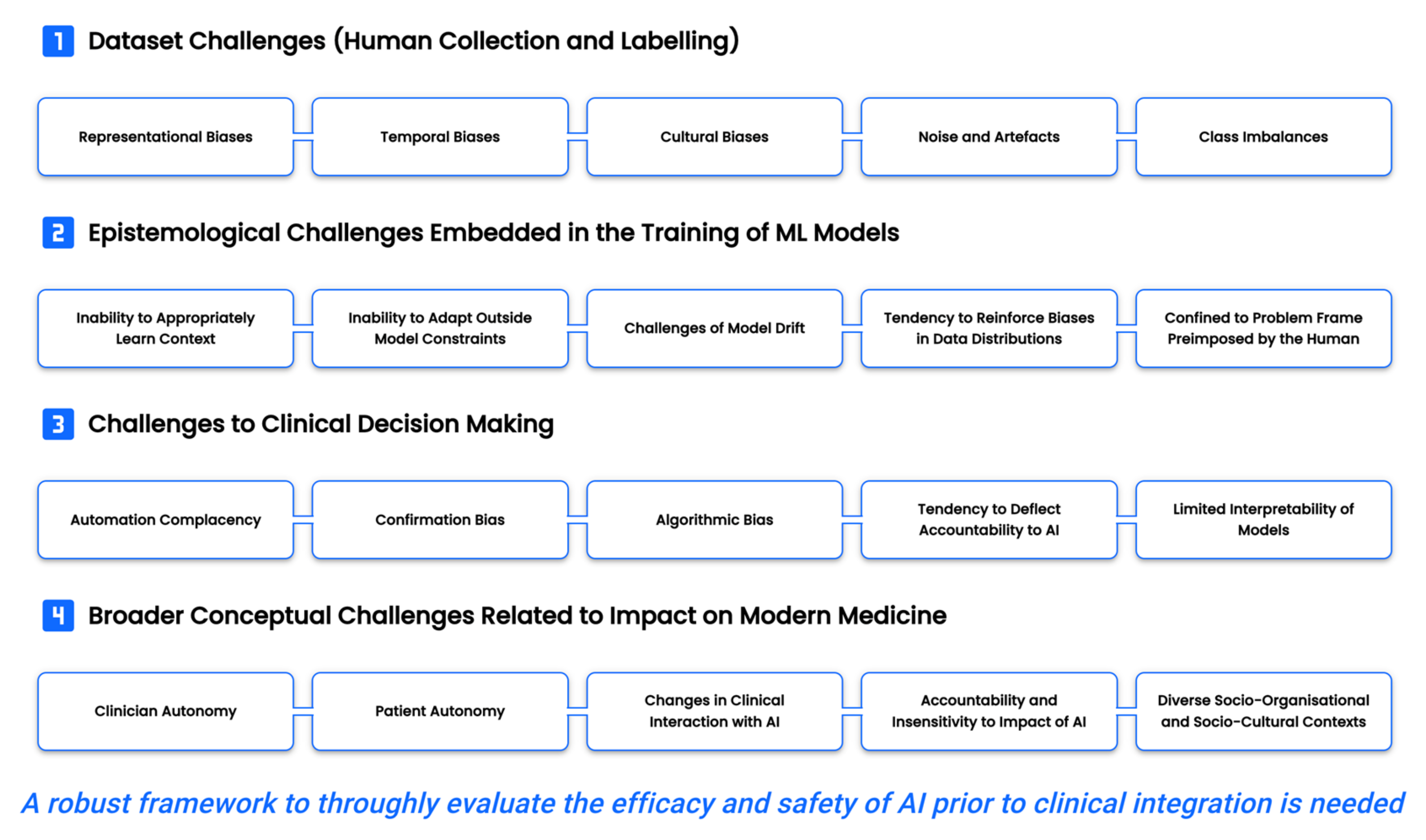
3. AI in Health: Opportunities and Concerns for Clinical Decision Making
4. AI in CRC: Limitations and Risks of Algorithmic Bias in Clinical Decision Making
4.1. CRC, AI and Data
4.1.1. Representational Biases in Data and CRC Risk Stratification Algorithms
4.1.2. Class Imbalance, Heterogeneous Disease States, and Underrepresented Disease
4.2. CRC, AI and Models
4.2.1. Temporal Context
4.2.2. Situational and Operator Context
4.2.3. Interpretability of AI Models
5. Social, Ethical, and Legal Ramifications of AI Mediated Clinical Decision Making
6. Further Risks and Limitations from Marginalising Socio-Technical Factors in CRC
6.1. Interaction between Patient & Healthcare System
6.2. Interaction between Patient & Clinician
6.3. Interaction between Clinician & Healthcare System
7. The Future of AI and Potential Implications for Clinical Decision Making
8. A Way Forward to Enhancing Clinical Decision Making in CRC: A More Nuanced Approach to AI Systems Development, Implementation, and Evaluation
9. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hinton, G. Deep Learning—A Technology with the Potential to Transform Health Care. JAMA 2018, 320, 1101. [Google Scholar] [CrossRef] [PubMed]
- Geoff Hinton: On Radiology. 2016. Available online: https://www.youtube.com/watch?v=2HMPRXstSvQ (accessed on 22 January 2022).
- International Radiology Societies Tackle Radiologist Shortage. Available online: https://www.rsna.org/news/2020/february/international-radiology-societies-and-shortage (accessed on 22 January 2022).
- Harrison, M.I.; Koppel, R.; Bar-Lev, S. Unintended Consequences of Information Technologies in Health Care—an Interactive Sociotechnical Analysis. J. Am. Med. Inform. Assoc. JAMIA 2007, 14, 542–549. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ash, J.S.; Berg, M.; Coiera, E. Some Unintended Consequences of Information Technology in Health Care: The Nature of Patient Care Information System-Related Errors. J. Am. Med. Inform. Assoc. 2004, 11, 104–112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sung, H.; Ferlay, J.; Siegel, R.L.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global Cancer Statistics 2020: GLOBOCAN Estimates of Incidence and Mortality Worldwide for 36 Cancers in 185 Countries. CA A Cancer J. Clin. 2021, 71, 209–249. [Google Scholar] [CrossRef] [PubMed]
- Yoshida, N.; Inoue, K.; Tomita, Y.; Kobayashi, R.; Hashimoto, H.; Sugino, S.; Hirose, R.; Dohi, O.; Yasuda, H.; Morinaga, Y.; et al. An Analysis about the Function of a New Artificial Intelligence, CAD EYE with the Lesion Recognition and Diagnosis for Colorectal Polyps in Clinical Practice. Int. J. Colorectal Dis. 2021, 36, 2237–2245. [Google Scholar] [CrossRef] [PubMed]
- Barua, I.; Vinsard, D.G.; Jodal, H.C.; Løberg, M.; Kalager, M.; Holme, Ø.; Misawa, M.; Bretthauer, M.; Mori, Y. Artificial Intelligence for Polyp Detection during Colonoscopy: A Systematic Review and Meta-Analysis. Endoscopy 2020, 53, 277–284. [Google Scholar] [CrossRef]
- Hassan, C.; Spadaccini, M.; Iannone, A.; Maselli, R.; Jovani, M.; Chandrasekar, V.T.; Antonelli, G.; Yu, H.; Areia, M.; Dinis-Ribeiro, M.; et al. Performance of Artificial Intelligence in Colonoscopy for Adenoma and Polyp Detection: A Systematic Review and Meta-Analysis. Gastrointest. Endosc. 2021, 93, 77–85. [Google Scholar] [CrossRef]
- Ding, Z.; Shi, H.; Zhang, H.; Meng, L.; Fan, M.; Han, C.; Zhang, K.; Ming, F.; Xie, X.; Liu, H.; et al. Gastroenterologist-Level Identification of Small-Bowel Diseases and Normal Variants by Capsule Endoscopy Using a Deep-Learning Model. Gastroenterology 2019, 157, 1044–1054. [Google Scholar] [CrossRef]
- Wang, K.S.; Yu, G.; Xu, C.; Meng, X.H.; Zhou, J.; Zheng, C.; Deng, Z.; Shang, L.; Liu, R.; Su, S.; et al. Accurate Diagnosis of Colorectal Cancer Based on Histopathology Images Using Artificial Intelligence. BMC Med. 2021, 19, 76. [Google Scholar] [CrossRef]
- Skrede, O.-J.; Raedt, S.D.; Kleppe, A.; Hveem, T.S.; Liestøl, K.; Maddison, J.; Askautrud, H.A.; Pradhan, M.; Nesheim, J.A.; Albregtsen, F.; et al. Deep Learning for Prediction of Colorectal Cancer Outcome: A Discovery and Validation Study. Lancet 2020, 395, 350–360. [Google Scholar] [CrossRef]
- Bychkov, D.; Linder, N.; Turkki, R.; Nordling, S.; Kovanen, P.E.; Verrill, C.; Walliander, M.; Lundin, M.; Haglund, C.; Lundin, J. Deep Learning Based Tissue Analysis Predicts Outcome in Colorectal Cancer. Sci. Rep. 2018, 8, 3395. [Google Scholar] [CrossRef] [PubMed]
- Nartowt, B.J.; Hart, G.R.; Muhammad, W.; Liang, Y.; Stark, G.F.; Deng, J. Robust Machine Learning for Colorectal Cancer Risk Prediction and Stratification. Front. Big Data 2020, 3, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kostopoulou, O.; Arora, K.; Pálfi, B. Using Cancer Risk Algorithms to Improve Risk Estimates and Referral Decisions. Commun. Med. 2022, 2, 2. [Google Scholar] [CrossRef]
- Mori, Y.; Bretthauer, M.; Kalager, M. Hopes and Hypes for Artificial Intelligence in Colorectal Cancer Screening. Gastroenterology 2021, 161, 774–777. [Google Scholar] [CrossRef] [PubMed]
- Abdul Halim, A.A.; Andrew, A.M.; Mohd Yasin, M.N.; Abd Rahman, M.A.; Jusoh, M.; Veeraperumal, V.; Rahim, H.A.; Illahi, U.; Abdul Karim, M.K.; Scavino, E. Existing and Emerging Breast Cancer Detection Technologies and Its Challenges: A Review. Appl. Sci. 2021, 11, 10753. [Google Scholar] [CrossRef]
- Avanzo, M.; Trianni, A.; Botta, F.; Talamonti, C.; Stasi, M.; Iori, M. Artificial Intelligence and the Medical Physicist: Welcome to the Machine. Appl. Sci. 2021, 11, 1691. [Google Scholar] [CrossRef]
- Panch, T.; Szolovits, P.; Atun, R. Artificial Intelligence, Machine Learning and Health Systems. J. Glob. Health 2018, 8, 020303. [Google Scholar] [CrossRef]
- Beam, A.L.; Kohane, I.S. Big Data and Machine Learning in Health Care. JAMA 2018, 319, 1317. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The Mit Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van der Laak, J.A.W.M.; van Ginneken, B.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef] [Green Version]
- Selvikvåg Lundervold, A.; Lundervold, A. An Overview of Deep Learning in Medical Imaging Focusing on MRI. Z. Für Med. Phys. 2018, 29, 102–127. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-Level Classification of Skin Cancer with Deep Neural Networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Nam, J.G.; Park, S.; Hwang, E.J.; Lee, J.H.; Jin, K.-N.; Lim, K.Y.; Vu, T.H.; Sohn, J.H.; Hwang, S.; Goo, J.M.; et al. Development and Validation of Deep Learning–Based Automatic Detection Algorithm for Malignant Pulmonary Nodules on Chest Radiographs. Radiology 2019, 290, 218–228. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nabulsi, Z.; Sellergren, A.; Jamshy, S.; Lau, C.; Santos, E.; Kiraly, A.P.; Ye, W.; Yang, J.; Pilgrim, R.; Kazemzadeh, S.; et al. Deep Learning for Distinguishing Normal versus Abnormal Chest Radiographs and Generalization to Two Unseen Diseases Tuberculosis and COVID-19. Sci. Rep. 2021, 11, 15523. [Google Scholar] [CrossRef]
- Zech, J.R.; Badgeley, M.A.; Liu, M.; Costa, A.B.; Titano, J.J.; Oermann, E.K. Variable Generalization Performance of a Deep Learning Model to Detect Pneumonia in Chest Radiographs: A Cross-Sectional Study. PLoS Med. 2018, 15, e1002683. [Google Scholar] [CrossRef] [Green Version]
- Yoshida, H.; Shimazu, T.; Kiyuna, T.; Marugame, A.; Yamashita, Y.; Cosatto, E.; Taniguchi, H.; Sekine, S.; Ochiai, A. Automated Histological Classification of Whole-Slide Images of Gastric Biopsy Specimens. Gastric Cancer Off. J. Int. Gastric Cancer Assoc. Jpn. Gastric Cancer Assoc. 2018, 21, 249–257. [Google Scholar] [CrossRef]
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-Level Arrhythmia Detection and Classification in Ambulatory Electrocardiograms Using a Deep Neural Network. Nat. Med. 2019, 25, 65–69. [Google Scholar] [CrossRef]
- Attia, Z.I.; Noseworthy, P.A.; Lopez-Jimenez, F.; Asirvatham, S.J.; Deshmukh, A.J.; Gersh, B.J.; Carter, R.E.; Yao, X.; Rabinstein, A.A.; Erickson, B.J.; et al. An Artificial Intelligence-Enabled ECG Algorithm for the Identification of Patients with Atrial Fibrillation during Sinus Rhythm: A Retrospective Analysis of Outcome Prediction. Lancet 2019, 394, 861–867. [Google Scholar] [CrossRef]
- Al-Zaiti, S.; Besomi, L.; Bouzid, Z.; Faramand, Z.; Frisch, S.; Martin-Gill, C.; Gregg, R.; Saba, S.; Callaway, C.; Sejdić, E. Machine Learning-Based Prediction of Acute Coronary Syndrome Using Only the Pre-Hospital 12-Lead Electrocardiogram. Nat. Commun. 2020, 11, 3966. [Google Scholar] [CrossRef]
- Desautels, T.; Calvert, J.; Hoffman, J.; Jay, M.; Kerem, Y.; Shieh, L.; Shimabukuro, D.; Chettipally, U.; Feldman, M.D.; Barton, C.; et al. Prediction of Sepsis in the Intensive Care Unit with Minimal Electronic Health Record Data: A Machine Learning Approach. JMIR Med. Inform. 2016, 4, e28. [Google Scholar] [CrossRef] [PubMed]
- Kamnitsas, K.; Ferrante, E.; Parisot, S.; Ledig, C.; Nori, A.V.; Criminisi, A.; Rueckert, D.; Glocker, B. DeepMedic for Brain Tumor Segmentation. In Brainlesion: Glioma, Multiple Sclerosis, Stroke and Traumatic Brain Injuries, Proceedings of the Third International Workshop, BrainLes 2017, Quebec City, QC, Canada, 14 September 2017; Springer: Cham, Switzerland, 2016; pp. 138–149. [Google Scholar] [CrossRef]
- Ding, Y.; Sohn, J.H.; Kawczynski, M.G.; Trivedi, H.; Harnish, R.; Jenkins, N.W.; Lituiev, D.; Copeland, T.P.; Aboian, M.S.; Mari Aparici, C.; et al. A Deep Learning Model to Predict a Diagnosis of Alzheimer Disease by Using 18F-FDG PET of the Brain. Radiology 2019, 290, 456–464. [Google Scholar] [CrossRef] [PubMed]
- Chilamkurthy, S.; Ghosh, R.; Tanamala, S.; Biviji, M.; Campeau, N.G.; Venugopal, V.K.; Mahajan, V.; Rao, P.; Warier, P. Deep Learning Algorithms for Detection of Critical Findings in Head CT Scans: A Retrospective Study. Lancet 2018, 392, 2388–2396. [Google Scholar] [CrossRef]
- Poplin, R.; Varadarajan, A.V.; Blumer, K.; Liu, Y.; McConnell, M.V.; Corrado, G.S.; Peng, L.; Webster, D.R. Prediction of Cardiovascular Risk Factors from Retinal Fundus Photographs via Deep Learning. Nat. Biomed. Eng. 2018, 2, 158–164. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.Y.; Jeong, J.; Song, E.M.; Ha, C.; Lee, H.J.; Koo, J.E.; Yang, D.-H.; Kim, N.; Byeon, J.-S. Real-Time Detection of Colon Polyps during Colonoscopy Using Deep Learning: Systematic Validation with Four Independent Datasets. Sci. Rep. 2020, 10, 8379. [Google Scholar] [CrossRef] [PubMed]
- Miotto, R.; Wang, F.; Wang, S.; Jiang, X.; Dudley, J.T. Deep Learning for Healthcare: Review, Opportunities and Challenges. Brief. Bioinform. 2018, 19, 1236–1246. [Google Scholar] [CrossRef]
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.W.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic Accuracy of Deep Learning in Medical Imaging: A Systematic Review and Meta-Analysis. NPJ Digit. Med. 2021, 4, 65. [Google Scholar] [CrossRef]
- Paullada, A.; Raji, I.D.; Bender, E.M.; Denton, E.; Hanna, A. Data and Its (Dis)Contents: A Survey of Dataset Development and Use in Machine Learning Research. Patterns 2021, 2, 100336. [Google Scholar] [CrossRef]
- Sambasivan, N.; Kapania, S.; Highfill, H.; Akrong, D.; Paritosh, P.; Aroyo, L. Everyone Wants to Do the Model Work, Not the Data Work: Data Cascades in High-Stakes AI. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, Yokohama, Japan, 8–13 May 2021. [Google Scholar] [CrossRef]
- Obermeyer, Z.; Powers, B.; Vogeli, C.; Mullainathan, S. Dissecting Racial Bias in an Algorithm Used to Manage the Health of Populations. Science 2019, 366, 447–453. [Google Scholar] [CrossRef] [Green Version]
- Manrai, A.K.; Funke, B.H.; Rehm, H.L.; Olesen, M.S.; Maron, B.A.; Szolovits, P.; Margulies, D.M.; Loscalzo, J.; Kohane, I.S. Genetic Misdiagnoses and the Potential for Health Disparities. New Engl. J. Med. 2016, 375, 655–665. [Google Scholar] [CrossRef]
- Shaw, R.J.; Corpas, M. A Collection of 2280 Public Domain (CC0) Curated Human Genotypes. bioRxiv 2017. [Google Scholar] [CrossRef]
- Fry, A.; Littlejohns, T.J.; Sudlow, C.; Doherty, N.; Adamska, L.; Sprosen, T.; Collins, R.; Allen, N.E. Comparison of Sociodemographic and Health-Related Characteristics of UK Biobank Participants with Those of the General Population. Am. J. Epidemiol. 2017, 186, 1026–1034. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhou, Y.; Zhao, L.; Zhou, N.; Zhao, Y.; Marino, S.; Wang, T.; Sun, H.; Toga, A.W.; Dinov, I.D. Predictive Big Data Analytics Using the UK Biobank Data. Sci. Rep. 2019, 9, 6012. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abbasi, J. 23andMe, Big Data, and the Genetics of Depression. JAMA 2017, 317, 14. [Google Scholar] [CrossRef]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A Systematic Review on Imbalanced Data Challenges in Machine Learning. ACM Comput. Surv. 2019, 52, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Nalepa, J.; Marcinkiewicz, M.; Kawulok, M. Data Augmentation for Brain-Tumor Segmentation: A Review. Front. Comput. Neurosci. 2019, 13, 83. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Yin, L.; Bai, W.; Mao, K. An Appraisal of Incremental Learning Methods. Entropy 2020, 22, 1190. [Google Scholar] [CrossRef]
- Ahmad, Z.; Rahim, S.; Zubair, M.; Abdul-Ghafar, J. Artificial Intelligence (AI) in Medicine, Current Applications and Future Role with Special Emphasis on Its Potential and Promise in Pathology: Present and Future Impact, Obstacles Including Costs and Acceptance among Pathologists, Practical and Philosophical Considerations. A Comprehensive Review. Diagn. Pathol. 2021, 16, 24. [Google Scholar] [CrossRef]
- Liu, Y.; Geipel, M.M.; Tietz, C.; Buettner, F. TIMELY: Improving Labelling Consistency in Medical Imaging for Cell Type Classification. arXiv 2020, arXiv:2007.05307. [Google Scholar]
- Yu, K.-H.; Kohane, I.S. Framing the Challenges of Artificial Intelligence in Medicine. BMJ Qual. Saf. 2018, 28, 238–241. [Google Scholar] [CrossRef]
- Dike, H.U.; Zhou, Y.; Deveerasetty, K.K.; Wu, Q. Unsupervised Learning Based on Artificial Neural Network: A Review. In Proceedings of the 2018 IEEE International Conference on Cyborg and Bionic Systems (CBS), Shenzhen, China, 25–27 October 2018. [Google Scholar] [CrossRef]
- Montague, P.R. Reinforcement Learning: An Introduction, by Sutton, RS and Barto, AG. Trends Cogn. Sci. 1999, 3, 360. [Google Scholar] [CrossRef]
- Liu, S.; See, K.C.; Ngiam, K.Y.; Celi, L.A.; Sun, X.; Feng, M. Reinforcement Learning for Clinical Decision Support in Critical Care: Comprehensive Review. J. Med. Internet Res. 2020, 22, e18477. [Google Scholar] [CrossRef] [PubMed]
- Plassard, A.J.; Davis, L.T.; Newton, A.T.; Resnick, S.M.; Landman, B.A.; Bermudez, C. Learning Implicit Brain MRI Manifolds with Deep Learning. In Proceedings of the Medical Imaging 2018: Image Processing, Houston, TX, USA, 10–15 February 2018. [Google Scholar] [CrossRef]
- Miotto, R.; Li, L.; Kidd, B.A.; Dudley, J.T. Deep Patient: An Unsupervised Representation to Predict the Future of Patients from the Electronic Health Records. Sci. Rep. 2016, 6, 26094. [Google Scholar] [CrossRef]
- Prasad, N.; Cheng, L.-F.; Chivers, C.; Draugelis, M.; Engelhardt, B.E. A Reinforcement Learning Approach to Weaning of Mechanical Ventilation in Intensive Care Units. arXiv 2017, arXiv:1704.06300. [Google Scholar]
- Raghu, A.; Komorowski, M.; Ahmed, I.; Celi, L.; Szolovits, P.; Ghassemi, M. Deep Reinforcement Learning for Sepsis Treatment. arXiv 2017, arXiv:1711.09602. [Google Scholar]
- Palacio-Niño, J.-O.; Berzal, F. Evaluation Metrics for Unsupervised Learning Algorithms. arXiv 2019, arXiv:1905.05667. [Google Scholar]
- Kleinberg, J. An Impossibility Theorem for Clustering. In Proceedings of the 15th International Conference on Neural Information Processing Systems, Cambridge, MA, USA, 1 January 2002; MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Wu, E.; Wu, K.; Daneshjou, R.; Ouyang, D.; Ho, D.E.; Zou, J. How Medical AI Devices are Evaluated: Limitations and Recommendations from an Analysis of FDA Approvals. Nat. Med. 2021, 27, 582–584. [Google Scholar] [CrossRef]
- Kim, D.W.; Jang, H.Y.; Kim, K.W.; Shin, Y.; Park, S.H. Design Characteristics of Studies Reporting the Performance of Artificial Intelligence Algorithms for Diagnostic Analysis of Medical Images: Results from Recently Published Papers. Korean J. Radiol. 2019, 20, 405. [Google Scholar] [CrossRef]
- Kelly, C.J.; Karthikesalingam, A.; Suleyman, M.; Corrado, G.; King, D. Key Challenges for Delivering Clinical Impact with Artificial Intelligence. BMC Med. 2019, 17, 195. [Google Scholar] [CrossRef] [Green Version]
- Macrae, F.A. Colorectal Cancer: Epidemiology, Risk Factors, and Protective Factors. UpToDate. 2022. Available online: https://www.uptodate.com/contents/colorectal-cancer-epidemiology-risk-factors-and-protective-factors (accessed on 24 January 2022).
- Lotfi-Jam, K.; O’Reilly, C.; Feng, C.; Wakefield, M.; Durkin, S.; Broun, K. Increasing Bowel Cancer Screening Participation: Integrating Population-Wide, Primary Care and More Targeted Approaches. Public Health Res. Pract. 2019, 29, 2921916. [Google Scholar] [CrossRef] [Green Version]
- Brenner, H.; Chen, C. The Colorectal Cancer Epidemic: Challenges and Opportunities for Primary, Secondary and Tertiary Prevention. Br. J. Cancer 2018, 119, 785–792. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting Unreasonable Effectiveness of Data in Deep Learning Era. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Raji, I.D.; Fried, G. About Face: A Survey of Facial Recognition Evaluation. arXiv 2021, arXiv:2102.00813. [Google Scholar]
- Zhao, J.; Wang, T.; Yatskar, M.; Ordonez, V.; Chang, K.-W. Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar] [CrossRef]
- Garg, N.; Schiebinger, L.; Jurafsky, D.; Zou, J. Word Embeddings Quantify 100 Years of Gender and Ethnic Stereotypes. Proc. Natl. Acad. Sci. USA 2018, 115, E3635–E3644. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- van Miltenburg, E. Stereotyping and Bias in the Flickr30K Dataset. arXiv 2016, arXiv:1605.06083. [Google Scholar]
- Hutchinson, B.; Prabhakaran, V.; Denton, E.; Webster, K.; Zhong, Y.; Denuyl, S. Social Biases in NLP Models as Barriers for Persons with Disabilities. arXiv 2020, arXiv:2005.00813. [Google Scholar]
- De, M. Closing the Gap in a Generation: Health Equity through Action on the Social Determinants of Health; WHO Press: Geneva, Switzerland, 2008. [Google Scholar]
- Showell, C.; Turner, P. The PLU Problem: Are We Designing Personal Ehealth for People like Us? Stud. Health Technol. Inform. 2013, 183, 276–280. [Google Scholar]
- Zerilli, J.; Knott, A.; Maclaurin, J.; Gavaghan, C. Algorithmic Decision-Making and the Control Problem. Minds Mach. 2019, 29, 555–578. [Google Scholar] [CrossRef] [Green Version]
- Parasuraman, R.; Manzey, D.H. Complacency and Bias in Human Use of Automation: An Attentional Integration. Hum. Factors J. Hum. Factors Ergon. Soc. 2010, 52, 381–410. [Google Scholar] [CrossRef]
- Navarro, M.; Nicolas, A.; Ferrandez, A.; Lanas, A. Colorectal Cancer Population Screening Programs Worldwide in 2016: An Update. World J. Gastroenterol. 2017, 23, 3632. [Google Scholar] [CrossRef]
- Wan, N.; Weinberg, D.; Liu, T.-Y.; Niehaus, K.; Ariazi, E.A.; Delubac, D.; Kannan, A.; White, B.; Bailey, M.; Bertin, M.; et al. Machine Learning Enables Detection of Early-Stage Colorectal Cancer by Whole-Genome Sequencing of Plasma Cell-Free DNA. BMC Cancer 2019, 19, 832. [Google Scholar] [CrossRef] [Green Version]
- Chan, H.-C.; Chattopadhyay, A.; Chuang, E.Y.; Lu, T.-P. Development of a Gene-Based Prediction Model for Recurrence of Colorectal Cancer Using an Ensemble Learning Algorithm. Front. Oncol. 2021, 11, 631056. [Google Scholar] [CrossRef] [PubMed]
- Challen, R.; Denny, J.; Pitt, M.; Gompels, L.; Edwards, T.; Tsaneva-Atanasova, K. Artificial Intelligence, Bias and Clinical Safety. BMJ Qual. Saf. 2019, 28, 231–237. [Google Scholar] [CrossRef] [PubMed]
- Elston, D.M. Confirmation Bias in Medical Decision-Making. J. Am. Acad. Dermatol. 2020, 82, 572. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dawson, N.V.; Arkes, H.R. Systematic Errors in Medical Decision Making. J. Gen. Intern. Med. 1987, 2, 183–187. [Google Scholar] [CrossRef]
- Bond, R.R.; Novotny, T.; Andrsova, I.; Koc, L.; Sisakova, M.; Finlay, D.; Guldenring, D.; McLaughlin, J.; Peace, A.; McGilligan, V.; et al. Automation Bias in Medicine: The Influence of Automated Diagnoses on Interpreter Accuracy and Uncertainty When Reading Electrocardiograms. J. Electrocardiol. 2018, 51, S6–S11. [Google Scholar] [CrossRef]
- Tsai, T.L.; Fridsma, D.B.; Gatti, G. Computer Decision Support as a Source of Interpretation Error: The Case of Electrocardiograms. J. Am. Med. Inform. Assoc. 2003, 10, 478–483. [Google Scholar] [CrossRef] [Green Version]
- Nestor, B.; McDermott, M.B.A.; Chauhan, G.; Naumann, T.; Hughes, M.C.; Goldenberg, A.; Ghassemi, M. Rethinking Clinical Prediction: Why Machine Learning Must Consider Year of Care and Feature Aggregation. arXiv 2018, arXiv:1811.12583. [Google Scholar]
- Davis, S.E.; Greevy, R.A.; Fonnesbeck, C.; Lasko, T.A.; Walsh, C.G.; Matheny, M.E. A Nonparametric Updating Method to Correct Clinical Prediction Model Drift. J. Am. Med. Inform. Assoc. 2019, 26, 1448–1457. [Google Scholar] [CrossRef]
- Duckworth, C.; Chmiel, F.P.; Burns, D.K.; Zlatev, Z.D.; White, N.M.; Daniels, T.W.V.; Kiuber, M.; Boniface, M.J. Using Explainable Machine Learning to Characterise Data Drift and Detect Emergent Health Risks for Emergency Department Admissions during COVID-19. Sci. Rep. 2021, 11, 23017. [Google Scholar] [CrossRef]
- Davis, S.E.; Lasko, T.A.; Chen, G.; Siew, E.D.; Matheny, M.E. Calibration Drift in Regression and Machine Learning Models for Acute Kidney Injury. J. Am. Med. Inform. Assoc. 2017, 24, 1052–1061. [Google Scholar] [CrossRef]
- Done, J.Z.; Fang, S.H. Young-Onset Colorectal Cancer: A Review. World J. Gastrointest. Oncol. 2021, 13, 856–866. [Google Scholar] [CrossRef] [PubMed]
- Saad El Din, K.; Loree, J.M.; Sayre, E.C.; Gill, S.; Brown, C.J.; Dau, H.; De Vera, M.A. Trends in the Epidemiology of Young-Onset Colorectal Cancer: A Worldwide Systematic Review. BMC Cancer 2020, 20, 288. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jie, Z.; Zhiying, Z.; Li, L. A Meta-Analysis of Watson for Oncology in Clinical Application. Sci. Rep. 2021, 11, 5792. [Google Scholar] [CrossRef] [PubMed]
- Su, J.; Vargas, D.V.; Sakurai, K. One Pixel Attack for Fooling Deep Neural Networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Li, J.W.; Chia, T.; Fock, K.M.; Chong, K.D.W.; Wong, Y.J.; Ang, T.L. Artificial Intelligence and Polyp Detection in Colonoscopy: Use of a Single Neural Network to Achieve Rapid Polyp Localization for Clinical Use. J. Gastroenterol. Hepatol. 2021, 36, 3298–3307. [Google Scholar] [CrossRef]
- Liu, C.; Liu, X.; Wu, F.; Xie, M.; Feng, Y.; Hu, C. Using Artificial Intelligence (Watson for Oncology) for Treatment Recommendations amongst Chinese Patients with Lung Cancer: Feasibility Study. J. Med. Internet Res. 2018, 20, e11087. [Google Scholar] [CrossRef]
- Strickland, E. IBM Watson, Heal Thyself: How IBM Overpromised and Underdelivered on AI Health Care. IEEE Spectr. 2019, 56, 24–31. [Google Scholar] [CrossRef]
- Holzinger, A.; Biemann, C.; Pattichis, C.S.; Kell, D.B. What Do We Need to Build Explainable AI Systems for the Medical Domain? arXiv 2017, arXiv:1712.09923. [Google Scholar]
- Goodman, B.; Flaxman, S. European Union Regulations on Algorithmic Decision-Making and a Right to Explanation. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef] [Green Version]
- Rajpurkar, P.; Irvin, J.; Ball, R.L.; Zhu, K.; Yang, B.; Mehta, H.; Duan, T.; Ding, D.; Bagul, A.; Langlotz, C.P.; et al. Deep Learning for Chest Radiograph Diagnosis: A Retrospective Comparison of the CheXNeXt Algorithm to Practicing Radiologists. PLoS Med. 2018, 15, e1002686. [Google Scholar] [CrossRef] [PubMed]
- Panwar, H.; Gupta, P.K.; Siddiqui, M.K.; Morales-Menendez, R.; Bhardwaj, P.; Singh, V. A Deep Learning and Grad-CAM Based Color Visualization Approach for Fast Detection of COVID-19 Cases Using Chest X-Ray and CT-Scan Images. Chaos Solitons Fractals 2020, 140, 110190. [Google Scholar] [CrossRef] [PubMed]
- De Fauw, J.; Ledsam, J.R.; Romera-Paredes, B.; Nikolov, S.; Tomasev, N.; Blackwell, S.; Askham, H.; Glorot, X.; O’Donoghue, B.; Visentin, D.; et al. Clinically Applicable Deep Learning for Diagnosis and Referral in Retinal Disease. Nat. Med. 2018, 24, 1342–1350. [Google Scholar] [CrossRef] [PubMed]
- Yosinski, J.; Clune, J.; Nguyen, A.; Fuchs, T.; Lipson, H. Understanding Neural Networks through Deep Visualization. arXiv 2015, arXiv:1506.06579. [Google Scholar]
- Adler, P.; Falk, C.; Friedler, S.A.; Rybeck, G.; Scheidegger, C.; Smith, B.; Venkatasubramanian, S. Auditing Black-Box Models for Indirect Influence. arXiv 2016, arXiv:1602.07043. [Google Scholar]
- Spratt, E.L. Dream Formulations and Deep Neural Networks: Humanistic Themes in the Iconology of the Machine-Learned Image. arXiv 2018, arXiv:1802.01274. [Google Scholar]
- Currie, G.; Hawk, K.E. Ethical and Legal Challenges of Artificial Intelligence in Nuclear Medicine. Semin. Nucl. Med. 2020, 51, 120–125. [Google Scholar] [CrossRef]
- Ma, J.; Sheridan, R.P.; Liaw, A.; Dahl, G.E.; Svetnik, V. Deep Neural Nets as a Method for Quantitative Structure–Activity Relationships. J. Chem. Inf. Modeling 2015, 55, 263–274. [Google Scholar] [CrossRef]
- Alipanahi, B.; Delong, A.; Weirauch, M.T.; Frey, B.J. Predicting the Sequence Specificities of DNA- and RNA-Binding Proteins by Deep Learning. Nat. Biotechnol. 2015, 33, 831–838. [Google Scholar] [CrossRef]
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly Accurate Protein Structure Prediction with AlphaFold. Nature 2021, 596, 583–589. [Google Scholar] [CrossRef]
- Goh, K.H.; Wang, L.; Yeow, A.Y.K.; Poh, H.; Li, K.; Yeow, J.J.L.; Tan, G.Y.H. Artificial Intelligence in Sepsis Early Prediction and Diagnosis Using Unstructured Data in Healthcare. Nat. Commun. 2021, 12, 711. [Google Scholar] [CrossRef]
- Yala, A.; Mikhael, P.G.; Strand, F.; Lin, G.; Satuluru, S.; Kim, T.; Banerjee, I.; Gichoya, J.; Trivedi, H.; Lehman, C.D.; et al. Multi-Institutional Validation of a Mammography-Based Breast Cancer Risk Model. J. Clin. Oncol. 2021, JCO2101337. [Google Scholar] [CrossRef]
- Yu, C.; Helwig, E.J. The Role of AI Technology in Prediction, Diagnosis and Treatment of Colorectal Cancer. Artif. Intell. Rev. 2021, 55, 323–343. [Google Scholar] [CrossRef]
- Kim, N.H.; Jung, Y.S.; Jeong, W.S.; Yang, H.-J.; Park, S.-K.; Choi, K.; Park, D.I. Miss Rate of Colorectal Neoplastic Polyps and Risk Factors for Missed Polyps in Consecutive Colonoscopies. Intest. Res. 2017, 15, 411–418. [Google Scholar] [CrossRef] [Green Version]
- Corley, D.A.; Jensen, C.D.; Marks, A.R.; Zhao, W.K.; Lee, J.K.; Doubeni, C.A.; Zauber, A.G.; de Boer, J.; Fireman, B.H.; Schottinger, J.E.; et al. Adenoma Detection Rate and Risk of Colorectal Cancer and Death. New Engl. J. Med. 2014, 370, 1298–1306. [Google Scholar] [CrossRef] [Green Version]
- Gini, A.; Jansen, E.E.L.; Zielonke, N.; Meester, R.G.S.; Senore, C.; Anttila, A.; Segnan, N.; Mlakar, D.N.; de Koning, H.J.; Lansdorp-Vogelaar, I.; et al. Impact of Colorectal Cancer Screening on Cancer-Specific Mortality in Europe: A Systematic Review. Eur. J. Cancer 2020, 127, 224–235. [Google Scholar] [CrossRef] [Green Version]
- Lew, J.-B.; St John, D.J.B.; Xu, X.-M.; Greuter, M.J.E.; Caruana, M.; Cenin, D.R.; He, E.; Saville, M.; Grogan, P.; Coupé, V.M.H.; et al. Long-Term Evaluation of Benefits, Harms, and Cost-Effectiveness of the National Bowel Cancer Screening Program in Australia: A Modelling Study. Lancet Public Health 2017, 2, e331–e340. [Google Scholar] [CrossRef] [Green Version]
- Li, M.; Olver, I.; Keefe, D.; Holden, C.; Worthley, D.; Price, T.; Karapetis, C.; Miller, C.; Powell, K.; Buranyi-Trevarton, D.; et al. Pre-Diagnostic Colonoscopies Reduce Cancer Mortality—Results from Linked Population-Based Data in South Australia. BMC Cancer 2019, 19, 856. [Google Scholar] [CrossRef] [Green Version]
- Pignone, M.P.; Flitcroft, K.L.; Howard, K.; Trevena, L.J.; Salkeld, G.P.; St John, D.J.B. Costs and Cost-Effectiveness of Full Implementation of a Biennial Faecal Occult Blood Test Screening Program for Bowel Cancer in Australia. Med. J. Aust. 2011, 194, 180–185. [Google Scholar] [CrossRef]
- Cole, S.R.; Tucker, G.R.; Osborne, J.M.; Byrne, S.E.; Bampton, P.A.; Fraser, R.J.L.; Young, G.P. Shift to Earlier Stage at Diagnosis as a Consequence of the National Bowel Cancer Screening Program. Med. J. Aust. 2013, 198, 327–330. [Google Scholar] [CrossRef] [Green Version]
- Ananda, S.S.; McLaughlin, S.J.; Chen, F.; Hayes, I.P.; Hunter, A.A.; Skinner, I.J.; Steel, M.C.A.; Jones, I.T.; Hastie, I.A.; Rieger, N.A.; et al. Initial Impact of Australia’s National Bowel Cancer Screening Program. Med. J. Aust. 2009, 191, 378–381. [Google Scholar] [CrossRef]
- Howe, M. The National Bowel Cancer Screening Program: Time to Achieve Its Potential to Save Lives|PHRP. Available online: https://www.phrp.com.au/issues/july-2019-volume-29-issue-2/the-national-bowel-cancer-screening-program-time-to-achieve-its-potential-to-save-lives/ (accessed on 4 January 2022).
- European Guidelines for Quality Assurance in Colorectal Cancer Screening and Diagnosis: Overview and Introduction to the Full Supplement Publication. Endoscopy 2012, 45, 51–59. [CrossRef] [Green Version]
- National Bowel Cancer Screening Program Monitoring Report 2021. Summary. Available online: https://www.aihw.gov.au/reports/cancer-screening/nbcsp-monitoring-report-2021/summary (accessed on 12 January 2022).
- Rao, S.K.; Schilling, T.F.; Sequist, T.D. Challenges in the Management of Positive Fecal Occult Blood Tests. J. Gen. Intern. Med. 2009, 24, 356–360. [Google Scholar] [CrossRef] [Green Version]
- Levin, B.; Lieberman, D.A.; McFarland, B.; Smith, R.A.; Brooks, D.; Andrews, K.S.; Dash, C.; Giardiello, F.M.; Glick, S.; Levin, T.R.; et al. Screening and Surveillance for the Early Detection of Colorectal Cancer and Adenomatous Polyps, 2008: A Joint Guideline from the American Cancer Society, the US Multi-Society Task Force on Colorectal Cancer, and the American College of Radiology. CA Cancer J. Clin. 2018, 58, 130–160. [Google Scholar] [CrossRef] [Green Version]
- Green, B.B.; Baldwin, L.-M.; West, I.I.; Schwartz, M.; Coronado, G.D. Low Rates of Colonoscopy Follow-up after a Positive Fecal Immunochemical Test in a Medicaid Health Plan Delivered Mailed Colorectal Cancer Screening Program. J. Prim. Care Community Health 2020, 11, 215013272095852. [Google Scholar] [CrossRef]
- Shahidi, N.; Cheung, W.Y. Colorectal Cancer Screening: Opportunities to Improve Uptake, Outcomes, and Disparities. World J. Gastrointest. Endosc. 2016, 8, 733. [Google Scholar] [CrossRef]
- Hurtado, J.L.; Bacigalupe, A.; Calvo, M.; Esnaola, S.; Mendizabal, N.; Portillo, I.; Idigoras, I.; Millán, E.; Arana-Arri, E. Social Inequalities in a Population Based Colorectal Cancer Screening Programme in the Basque Country. BMC Public Health 2015, 15, 1021. [Google Scholar] [CrossRef] [Green Version]
- Plumb, A.A.; Ghanouni, A.; Rainbow, S.; Djedovic, N.; Marshall, S.; Stein, J.; Taylor, S.A.; Halligan, S.; Lyratzopoulos, G.; von Wagner, C. Patient Factors Associated with Non-Attendance at Colonoscopy after a Positive Screening Faecal Occult Blood Test. J. Med. Screen. 2016, 24, 12–19. [Google Scholar] [CrossRef] [Green Version]
- Earl, V.; Beasley, D.; Ye, C.; Halpin, S.N.; Gauthreaux, N.; Escoffery, C.; Chawla, S. Barriers and Facilitators to Colorectal Cancer Screening in African-American Men. Dig. Dis. Sci. 2021, 67, 463–472. [Google Scholar] [CrossRef]
- Muthukrishnan, M.; Arnold, L.D.; James, A.S. Patients’ Self-Reported Barriers to Colon Cancer Screening in Federally Qualified Health Center Settings. Prev. Med. Rep. 2019, 15, 100896. [Google Scholar] [CrossRef]
- Turner, B.; Myers, R.E.; Hyslop, T.; Hauck, W.W.; Weinberg, D.; Brigham, T.; Grana, J.; Rothermel, T.; Schlackman, N. Physician and Patient Factors Associated with Ordering a Colon Evaluation after a Positive Fecal Occult Blood Test. J. Gen. Intern. Med. 2003, 18, 357–363. [Google Scholar] [CrossRef] [Green Version]
- Jones, R.M.; Woolf, S.H.; Cunningham, T.D.; Johnson, R.E.; Krist, A.H.; Rothemich, S.F.; Vernon, S.W. The Relative Importance of Patient-Reported Barriers to Colorectal Cancer Screening. Am. J. Prev. Med. 2010, 38, 499–507. [Google Scholar] [CrossRef] [Green Version]
- Wangmar, J.; Wengström, Y.; Jervaeus, A.; Hultcrantz, R.; Fritzell, K. Decision-Making about Participation in Colorectal Cancer Screening in Sweden: Autonomous, Value-Dependent but Uninformed? Patient Educ. Couns. 2020, 104, 919–926. [Google Scholar] [CrossRef]
- Nielsen, J.B.; Berg-Beckhoff, G.; Leppin, A. To Do or Not to Do—A Survey Study on Factors Associated with Participating in the Danish Screening Program for Colorectal Cancer. BMC Health Serv. Res. 2021, 21, 43. [Google Scholar] [CrossRef]
- Clinical Practice Guidelines for the Prevention, Early Detection and Management of Colorectal Cancer—Cancer Guidelines Wiki. Available online: https://wiki.cancer.org.au/australia/Guidelines:Colorectal_cancer (accessed on 12 January 2022).
- Hubbard, R.A.; Johnson, E.; Hsia, R.; Rutter, C.M. The Cumulative Risk of False-Positive Fecal Occult Blood Test after 10 Years of Colorectal Cancer Screening. Cancer Epidemiol. Biomark. Prev. A Publ. Am. Assoc. Cancer Res. Cosponsored Am. Soc. Prev. Oncol. 2013, 22, 1612–1619. [Google Scholar] [CrossRef] [Green Version]
- Meklin, J.; Syrjänen, K.; Eskelinen, M. Fecal Occult Blood Tests in Colorectal Cancer Screening: Systematic Review and Meta-Analysis of Traditional and New-Generation Fecal Immunochemical Tests. Anticancer Res. 2020, 40, 3591–3604. [Google Scholar] [CrossRef]
- Llovet, D.; Serenity, M.; Conn, L.G.; Bravo, C.A.; McCurdy, B.R.; Dubé, C.; Baxter, N.N.; Paszat, L.; Rabeneck, L.; Peters, A.; et al. Reasons for Lack of Follow-up Colonoscopy among Persons with a Positive Fecal Occult Blood Test Result: A Qualitative Study. Am. J. Gastroenterol. 2018, 113, 1872–1880. [Google Scholar] [CrossRef]
- Dawson, G.; Crane, M.; Lyons, C.; Burnham, A.; Bowman, T.; Perez, D.; Travaglia, J. General Practitioners’ Perceptions of Population Based Bowel Screening and Their Influence on Practice: A Qualitative Study. BMC Fam. Pract. 2017, 18, 36. [Google Scholar] [CrossRef] [Green Version]
- Hanks, H.; Veitch, C.; Harris, M. Colorectal Cancer Management—The Role of the GP. Aust. Fam. Physician 2008, 37, 259–261. [Google Scholar]
- Baus, A.; Wright, L.E.; Kennedy-Rea, S.; Conn, M.E.; Eason, S.; Boatman, D.; Pollard, C.; Calkins, A.; Gadde, D. Leveraging Electronic Health Records Data for Enhanced Colorectal Cancer Screening Efforts. J. Appalach. Health 2020, 2, 53–63. [Google Scholar]
- Knight, W. The Dark Secret at the Heart of AI. Available online: https://www.technologyreview.com/2017/04/11/5113/the-dark-secret-at-the-heart-of-ai/ (accessed on 16 January 2022).
- Cui, L.; Lu, Y.; Sun, J.; Fu, Q.; Xu, X.; Wu, H.; Chen, J. RFLMDA: A Novel Reinforcement Learning-Based Computational Model for Human MicroRNA-Disease Association Prediction. Biomolecules 2021, 11, 1835. [Google Scholar] [CrossRef]
- Middleton, B.; Bloomrosen, M.; Dente, M.A.; Hashmat, B.; Koppel, R.; Overhage, J.M.; Payne, T.H.; Rosenbloom, S.T.; Weaver, C.; Zhang, J. Enhancing Patient Safety and Quality of Care by Improving the Usability of Electronic Health Record Systems: Recommendations from AMIA. J. Am. Med. Inform. Assoc. 2013, 20, e2–e8. [Google Scholar] [CrossRef]
- ML Evaluation Standards. Available online: https://ml-eval.github.io (accessed on 31 January 2022).

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ameen, S.; Wong, M.-C.; Yee, K.-C.; Turner, P. AI and Clinical Decision Making: The Limitations and Risks of Computational Reductionism in Bowel Cancer Screening. Appl. Sci. 2022, 12, 3341. https://doi.org/10.3390/app12073341
Ameen S, Wong M-C, Yee K-C, Turner P. AI and Clinical Decision Making: The Limitations and Risks of Computational Reductionism in Bowel Cancer Screening. Applied Sciences. 2022; 12(7):3341. https://doi.org/10.3390/app12073341
Chicago/Turabian StyleAmeen, Saleem, Ming-Chao Wong, Kwang-Chien Yee, and Paul Turner. 2022. "AI and Clinical Decision Making: The Limitations and Risks of Computational Reductionism in Bowel Cancer Screening" Applied Sciences 12, no. 7: 3341. https://doi.org/10.3390/app12073341