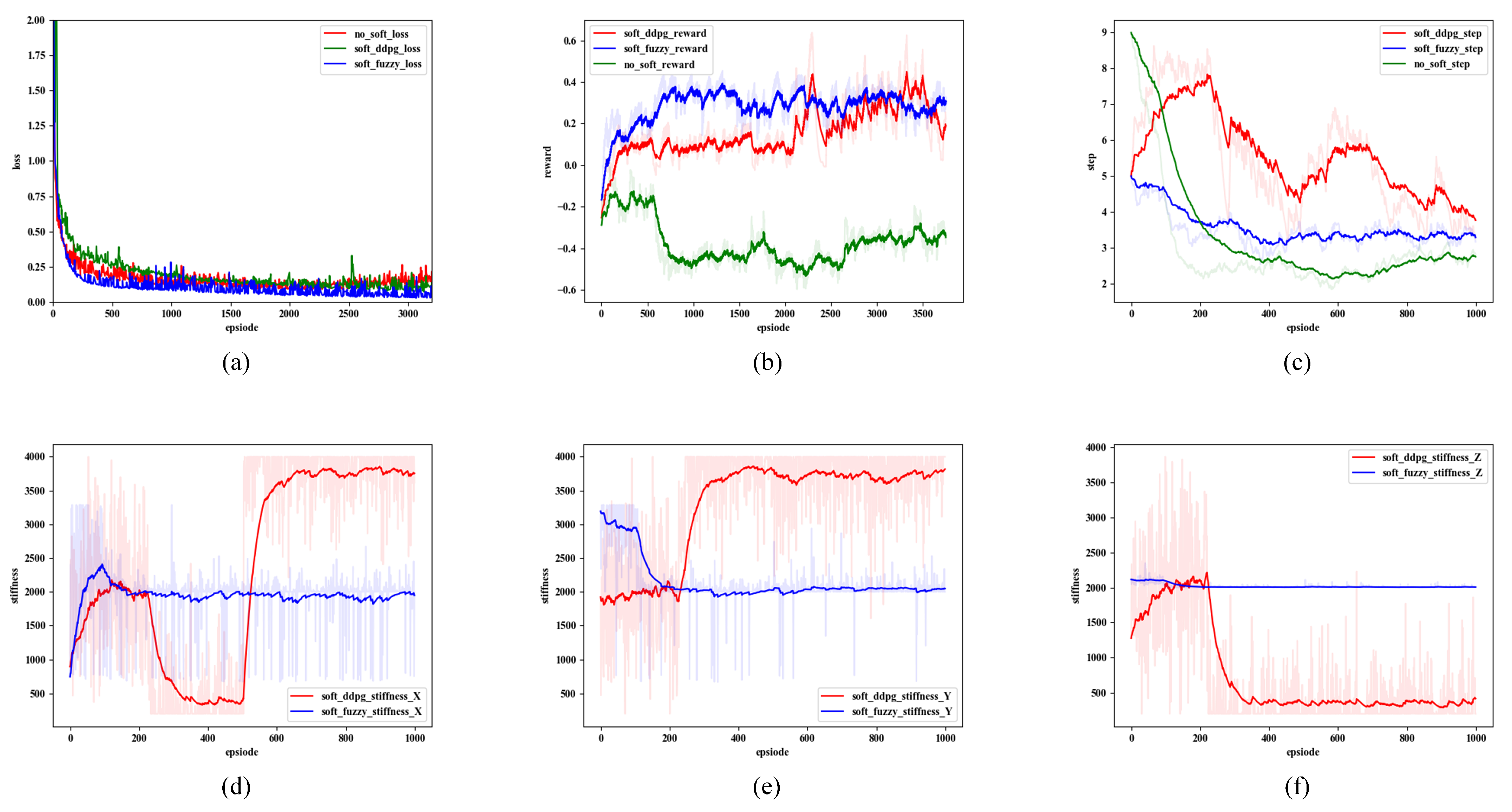
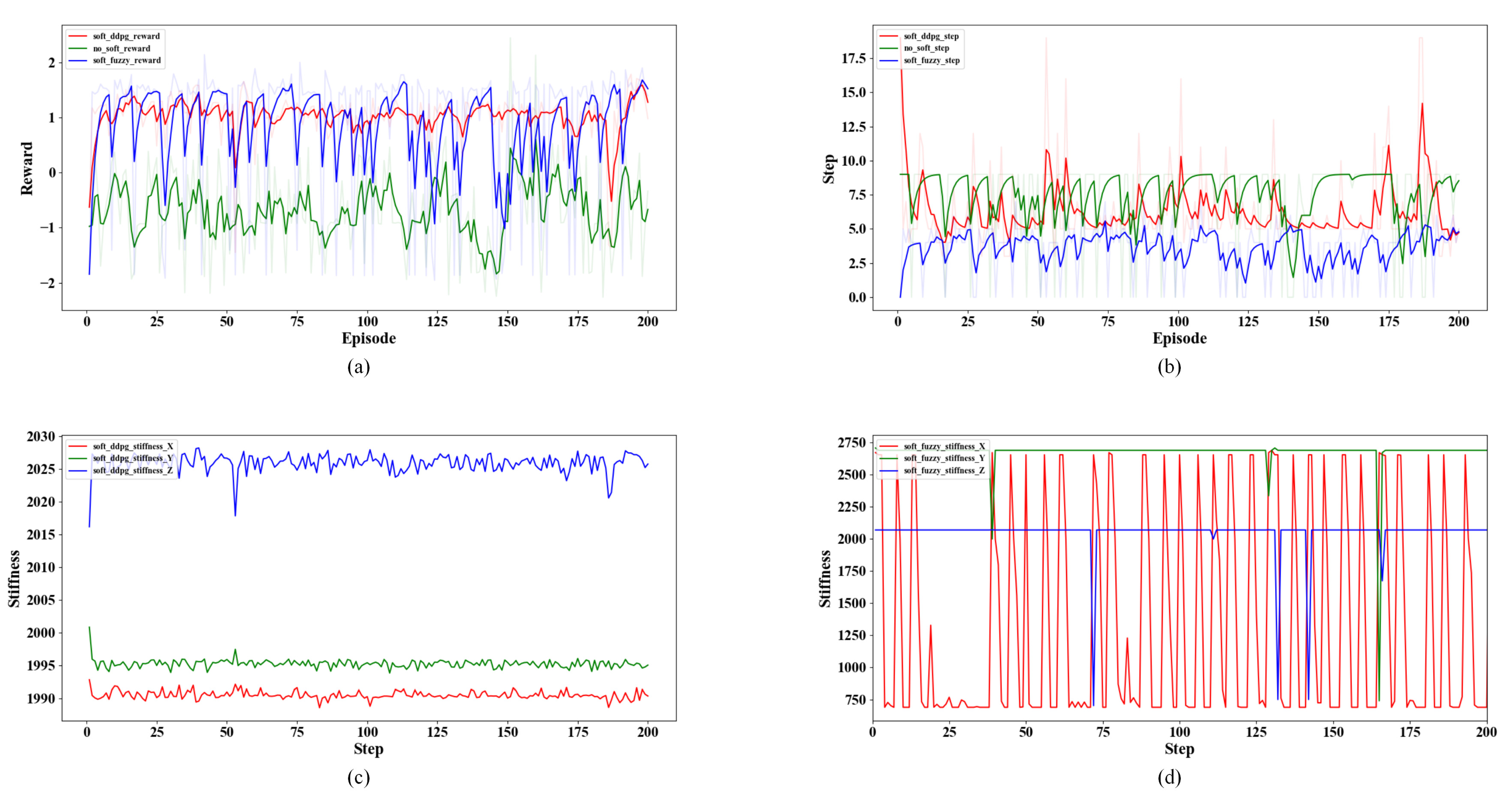
Assembly strategy learning is actually the parameter updating and optimization, which requires a stable and efficient learning algorithm. This paper uses the deep deterministic strategy gradient (DDPG) algorithm to realize the learning of stiffness strategy and trajectory strategy.
4.1. Assembly Policy Learning
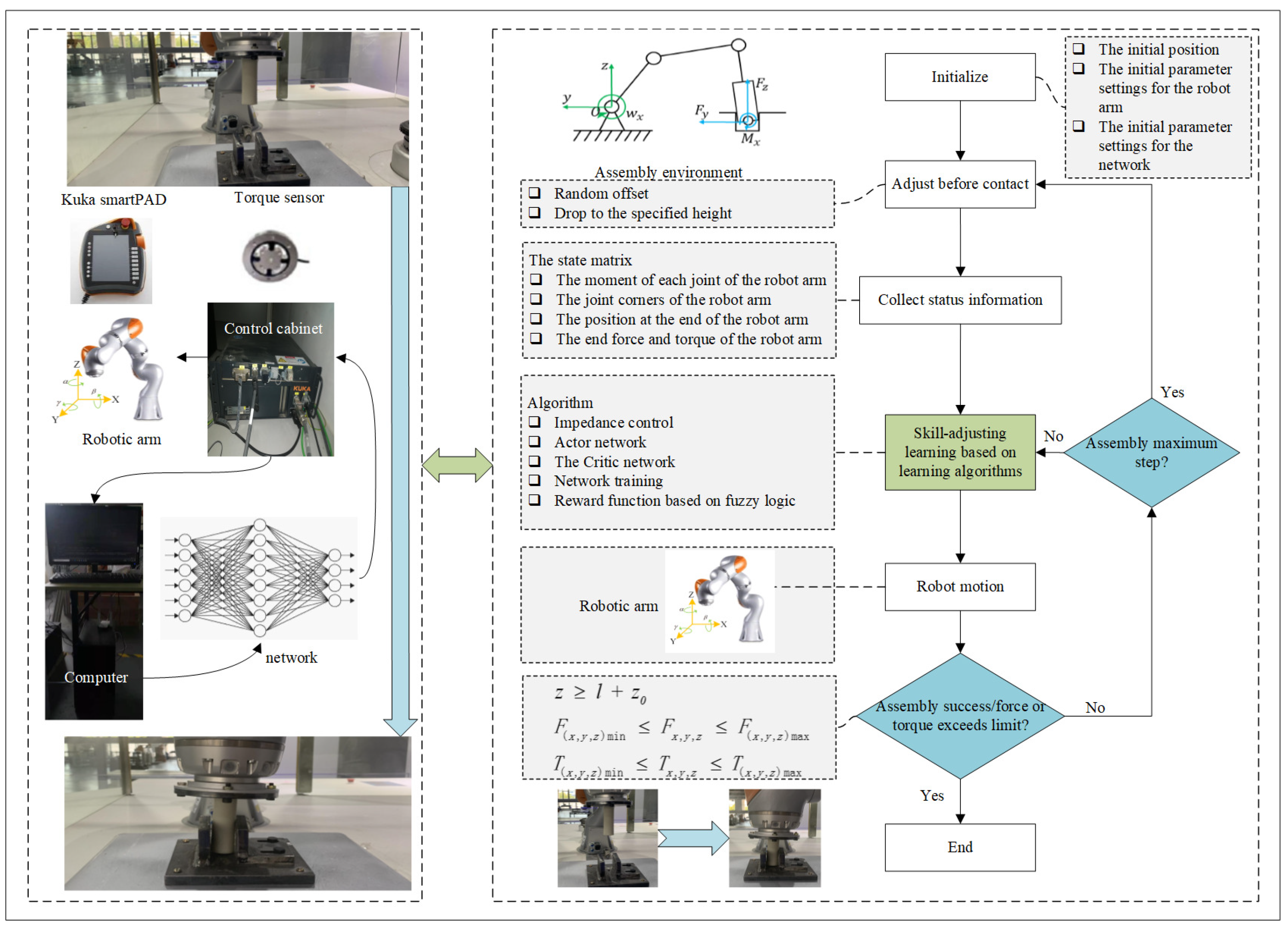
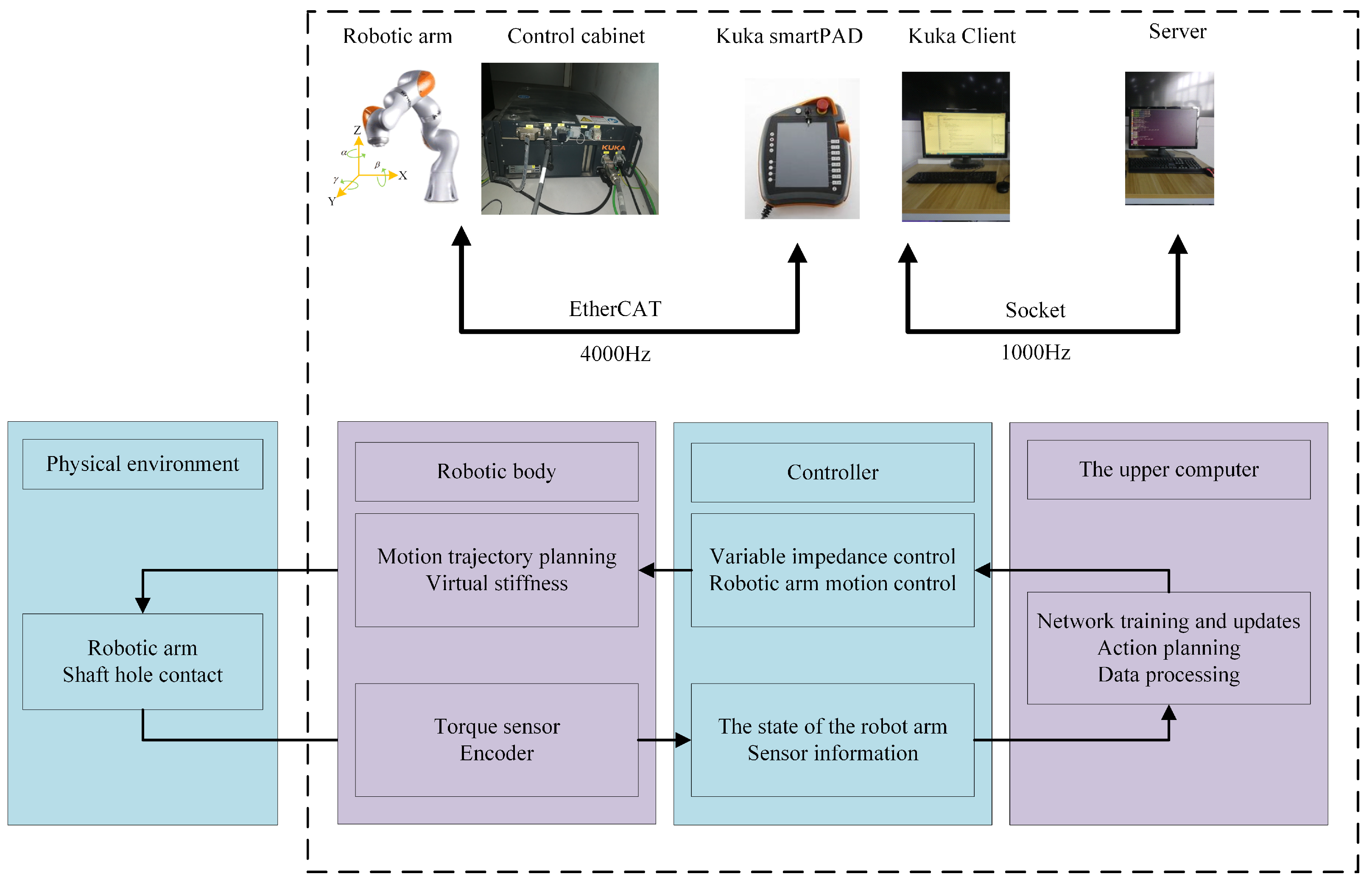
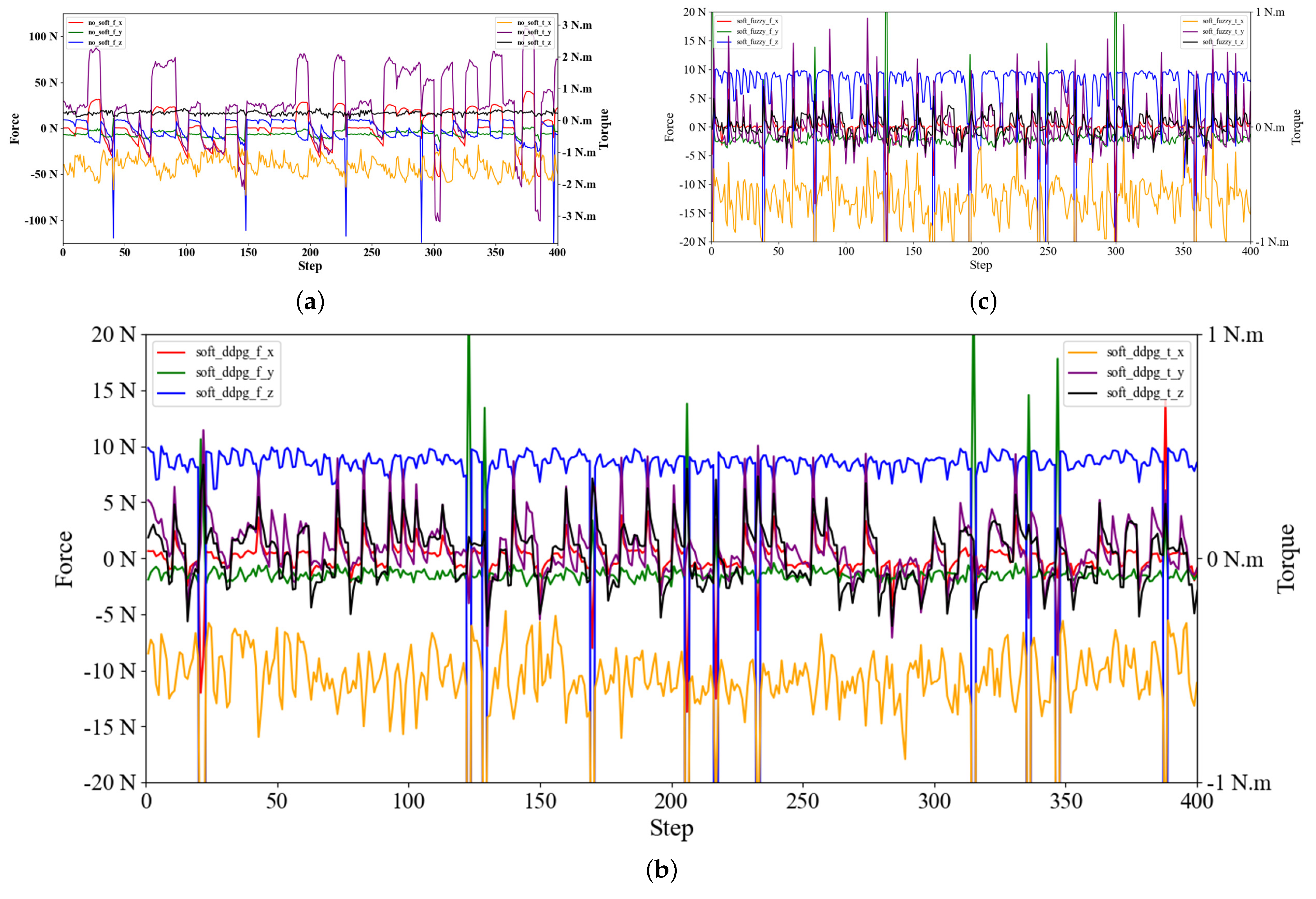
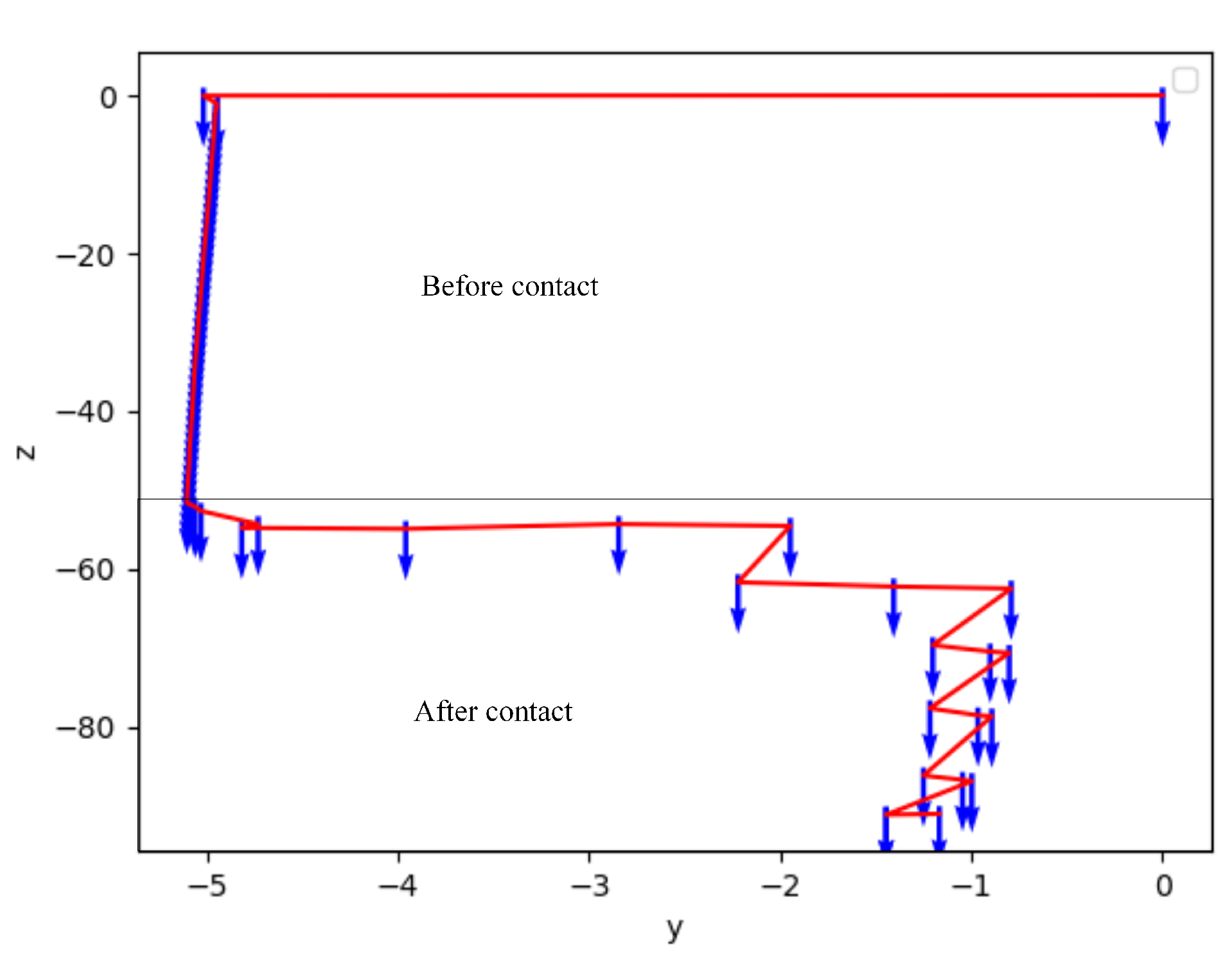
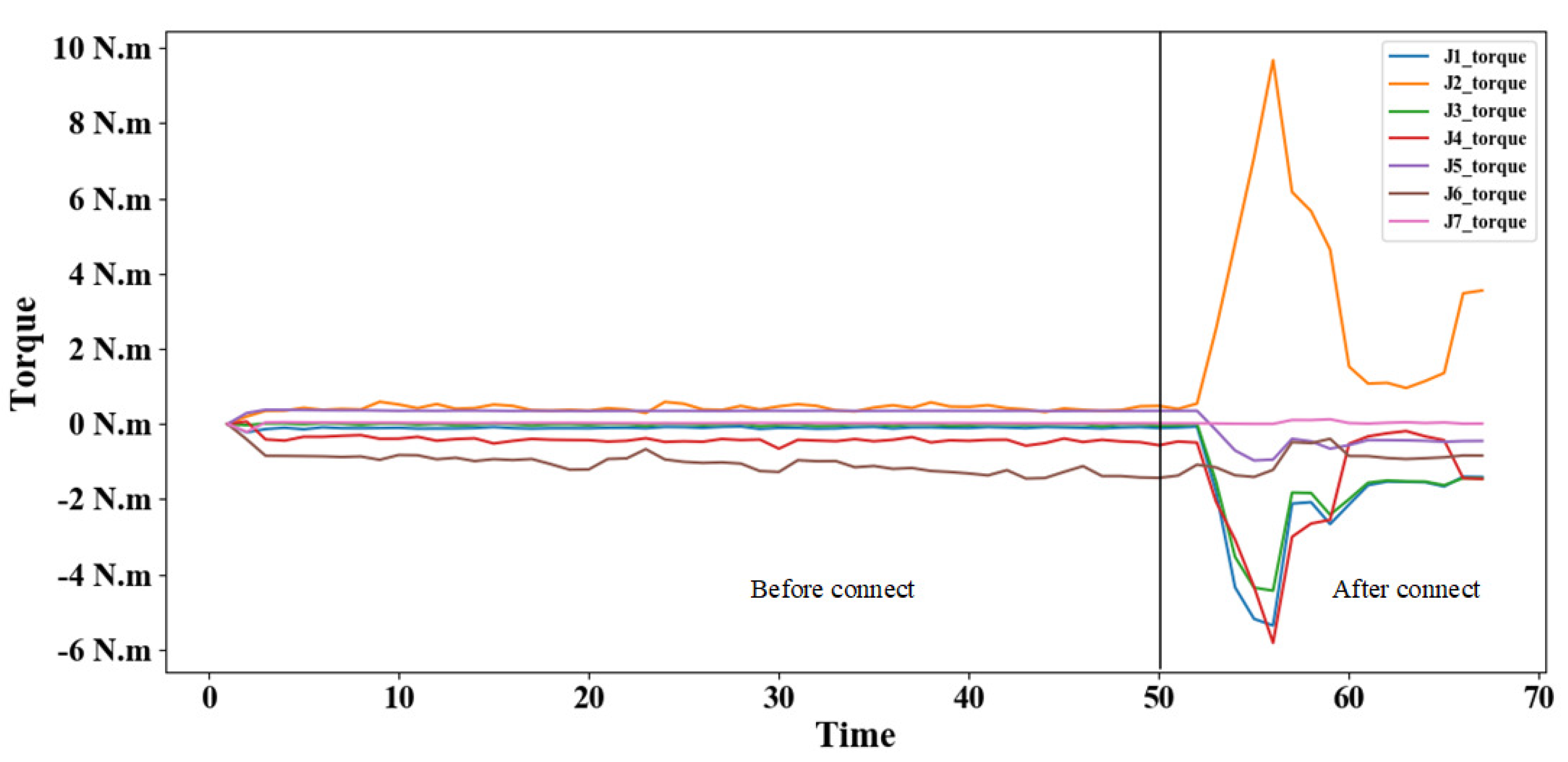
The assembly process is divided into non-contact stage and contact stage. The initial position is often random during the assembly process. In the assembly contact state, there is a corresponding relationship between the robot action and the current state. Then the guidance strategy of the subsequent stage could be carried out in turn, which could complete the assembly action smoothly to protect the workpiece from damage. As shown in
Figure 1, the mapping between the contact state and robot action is learned with the framework.
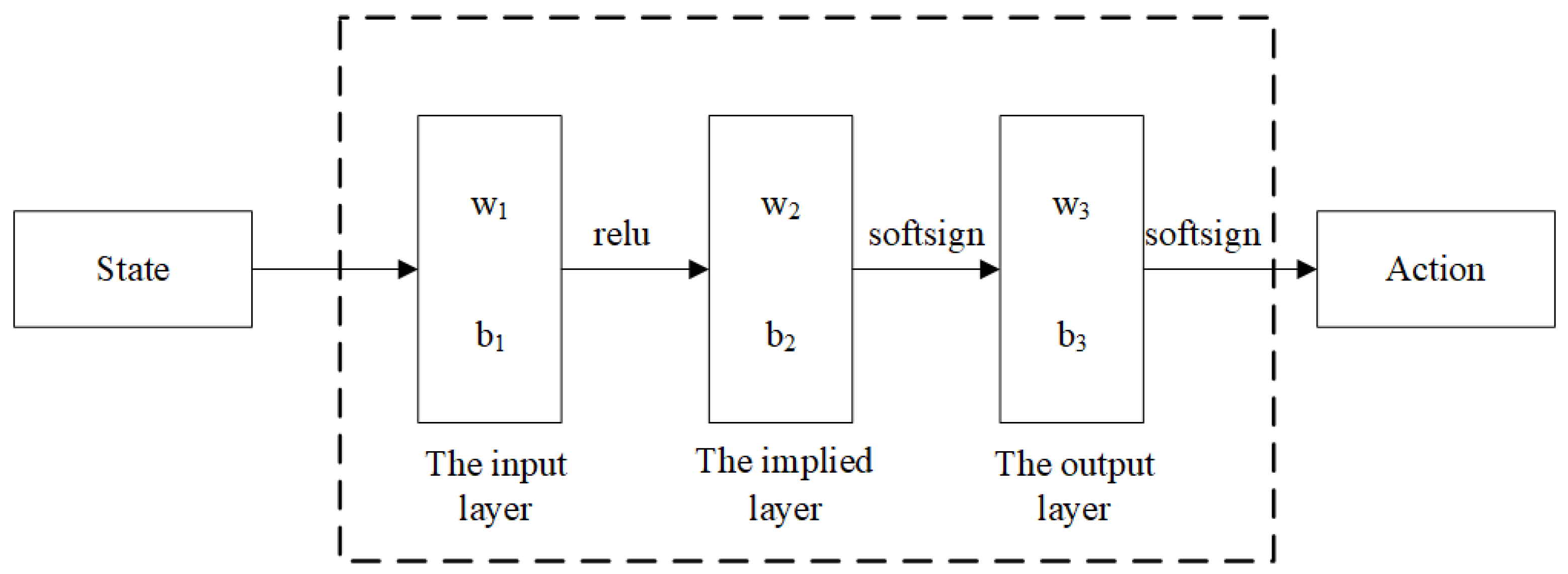
The Actor shows the same network structure as shown in
Figure 2. The hidden layer has three layers: the first layer contains 300 neurons, the second layer and the third layer each contains 200 neurons, the hidden layer and the output layer between the tanh activation function; the output layer gives an adjustment action, the output dynamic as the joint angle of the 7 axes and the stiffness of the three directions at the end of the robot arm
The logical relationships between layers are as follows:
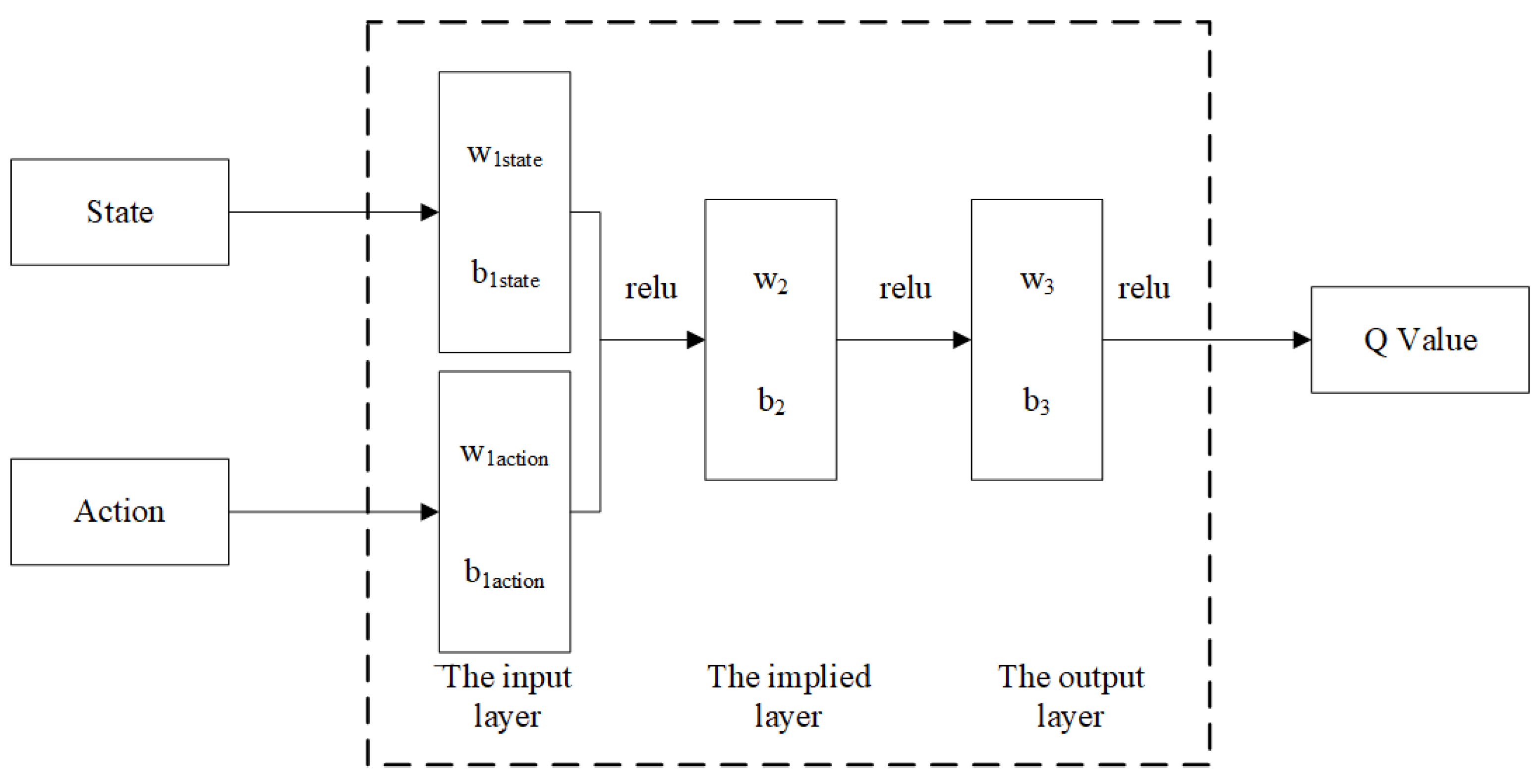
The Critic network structure is shown in
Figure 3. According to the current contact state, the assembly action in the Actor network obtains the
Q value, evaluates the assembly strategy, and then guides the actor network to make strategic adjustments. The input layer obtains the contact state information and the assembly action given by the Actor network, passes through the
function into the implied layer, and then passes through the identity function into the output layer.
The logical relationships between layers are
4.2. Reward Function
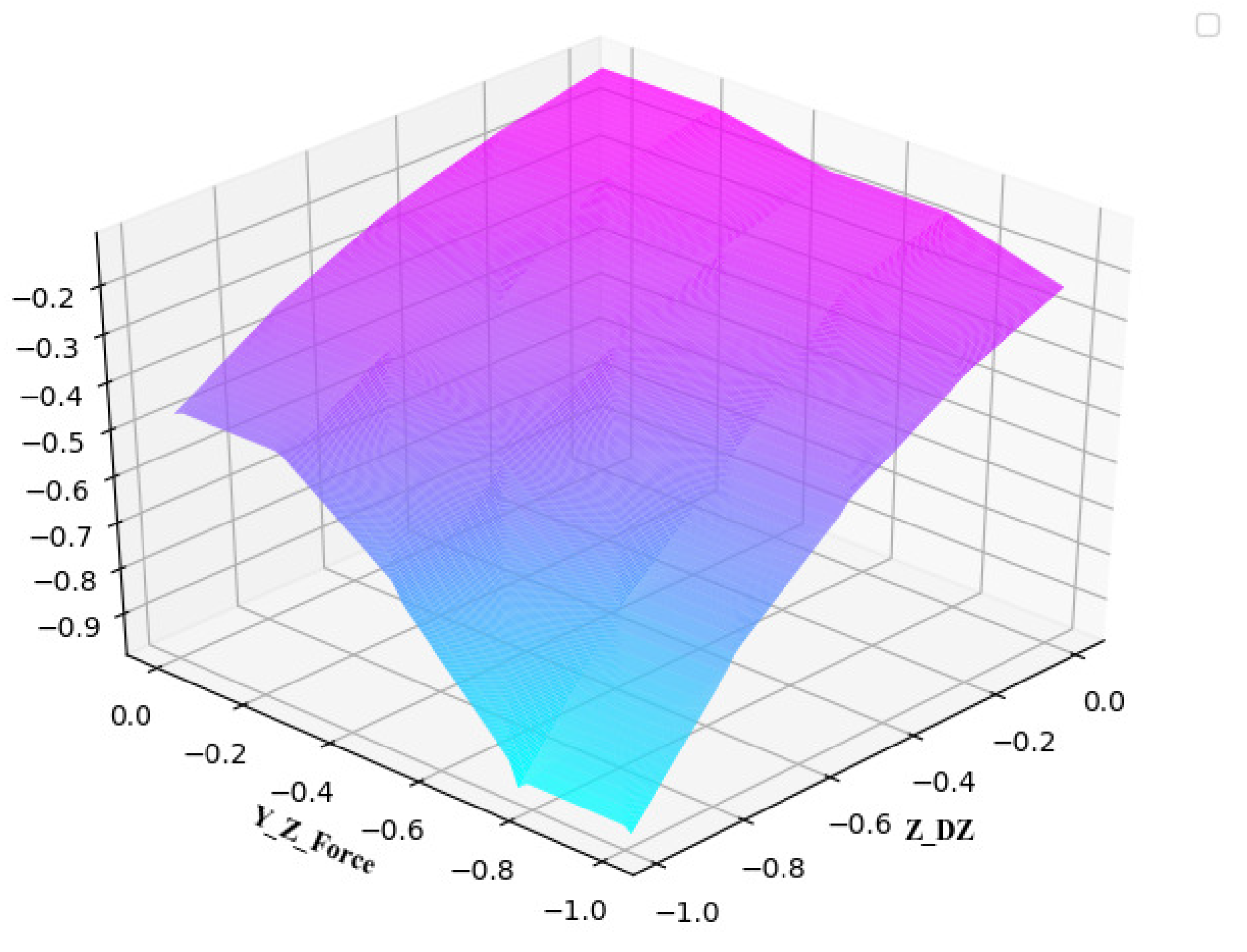
For peg-in-hole assembly, the assembly quality evaluation is one of the most important factors affecting the success rate. The fuzzy logic system could handle multiple parameters, so it could evaluate the quality of the assembly system very well. Therefore, this paper sets up a quality evaluation with fuzzy logic.
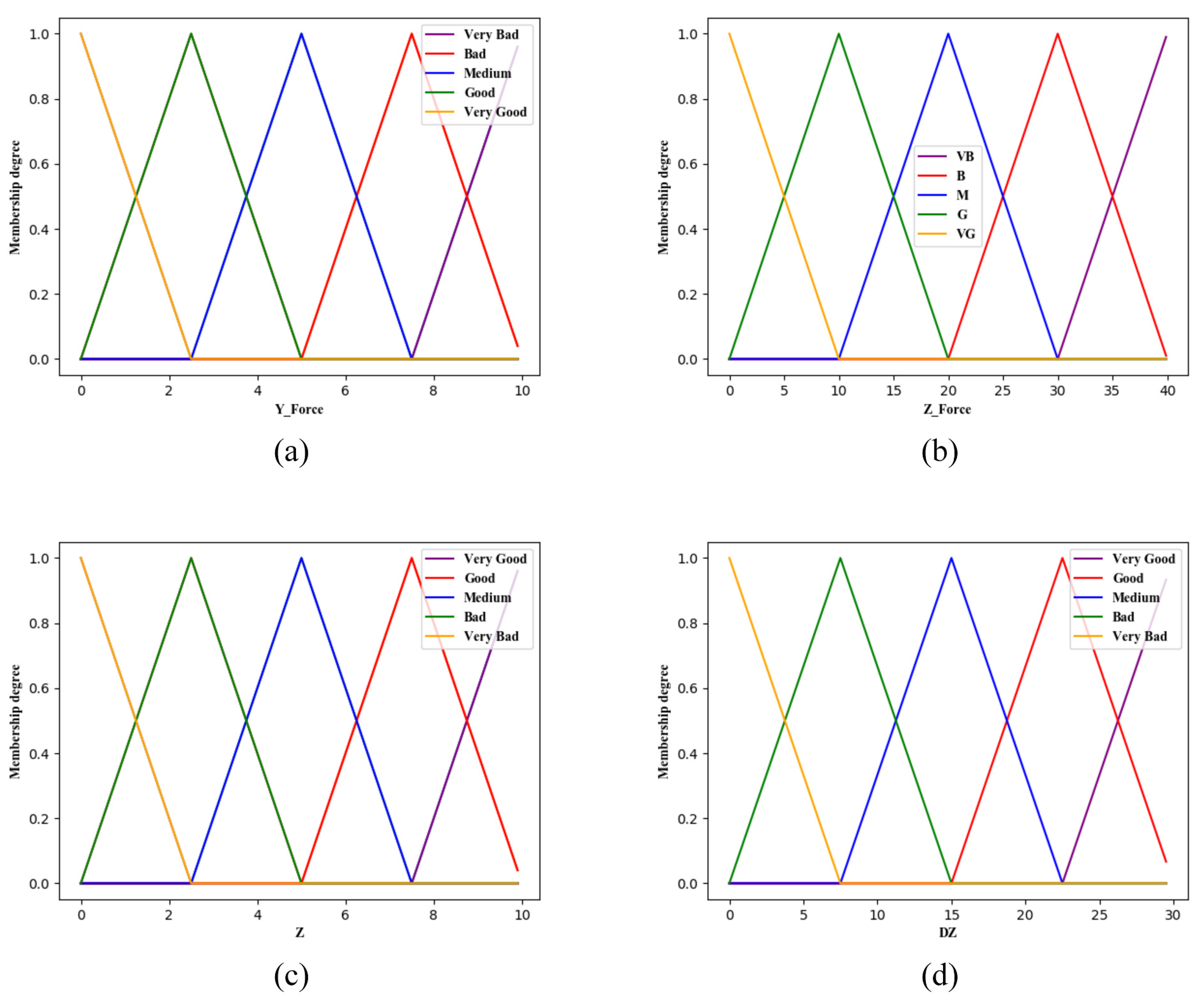
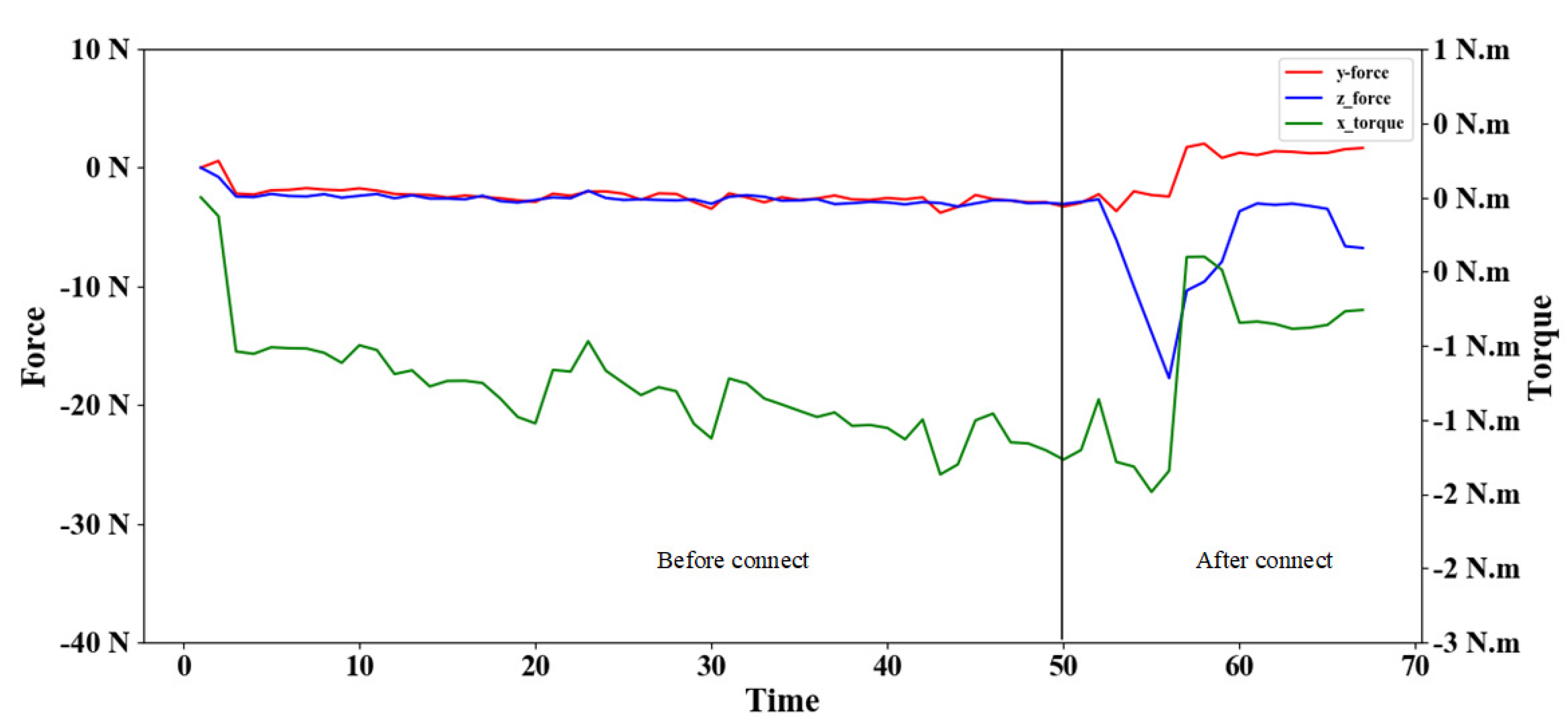
In this paper, four typical parameters are used as the parameters of fuzzy quality evaluation, i.e., contact force
of t-moment y axis, contact force
of z-axis, assembly depth
Z of t-moment shaft and assembly action amount
:
where
is the force of the
z direction,
is the initial force of the
z direction,
is the force of the
y direction,
is the initial force of the
y direction,
is the
Z axis coordinates in the current state of the robot arm, and
d is the
Z axis coordinate value at the bottom of the hole under the same coordinate system as the robot arm.
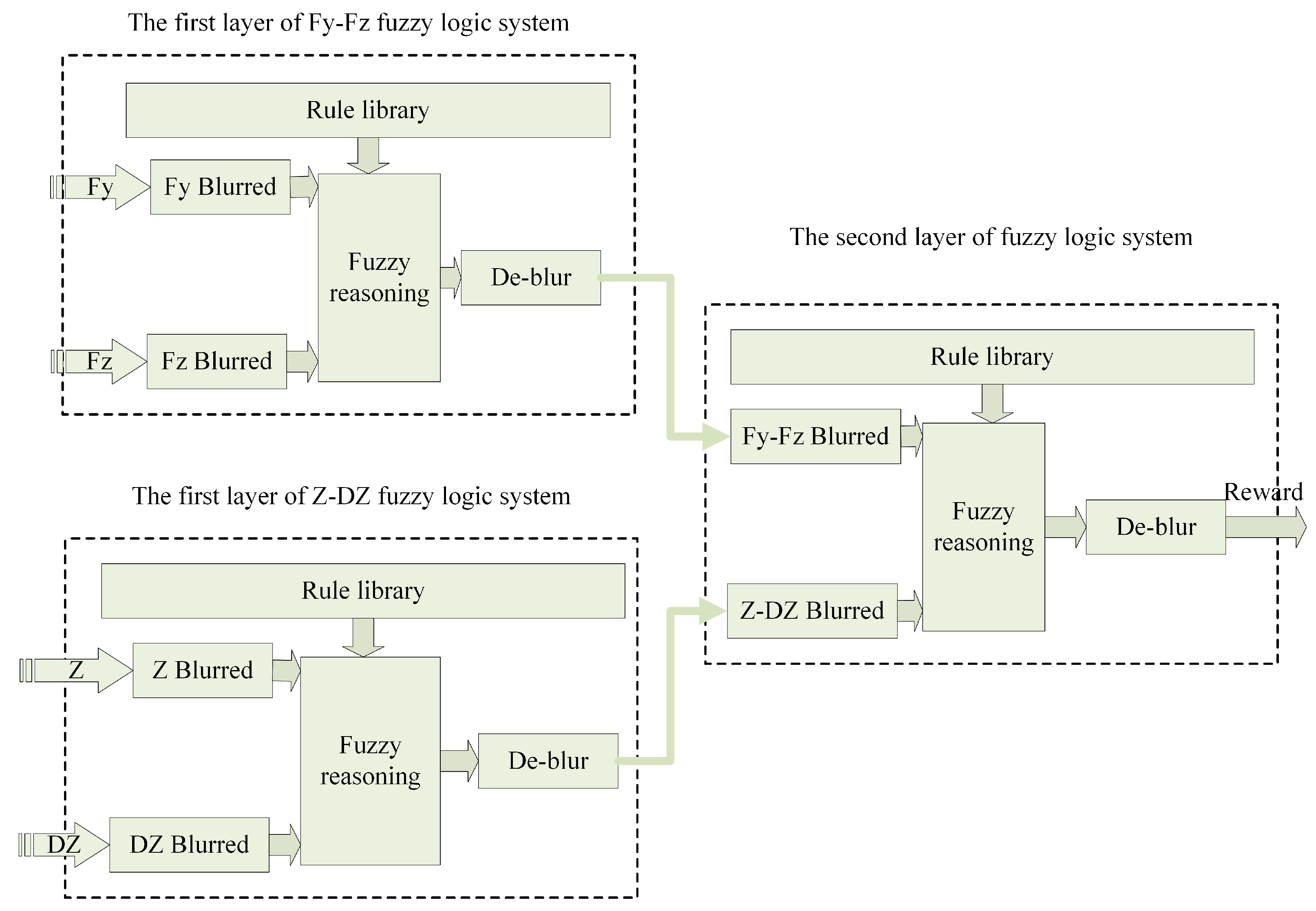
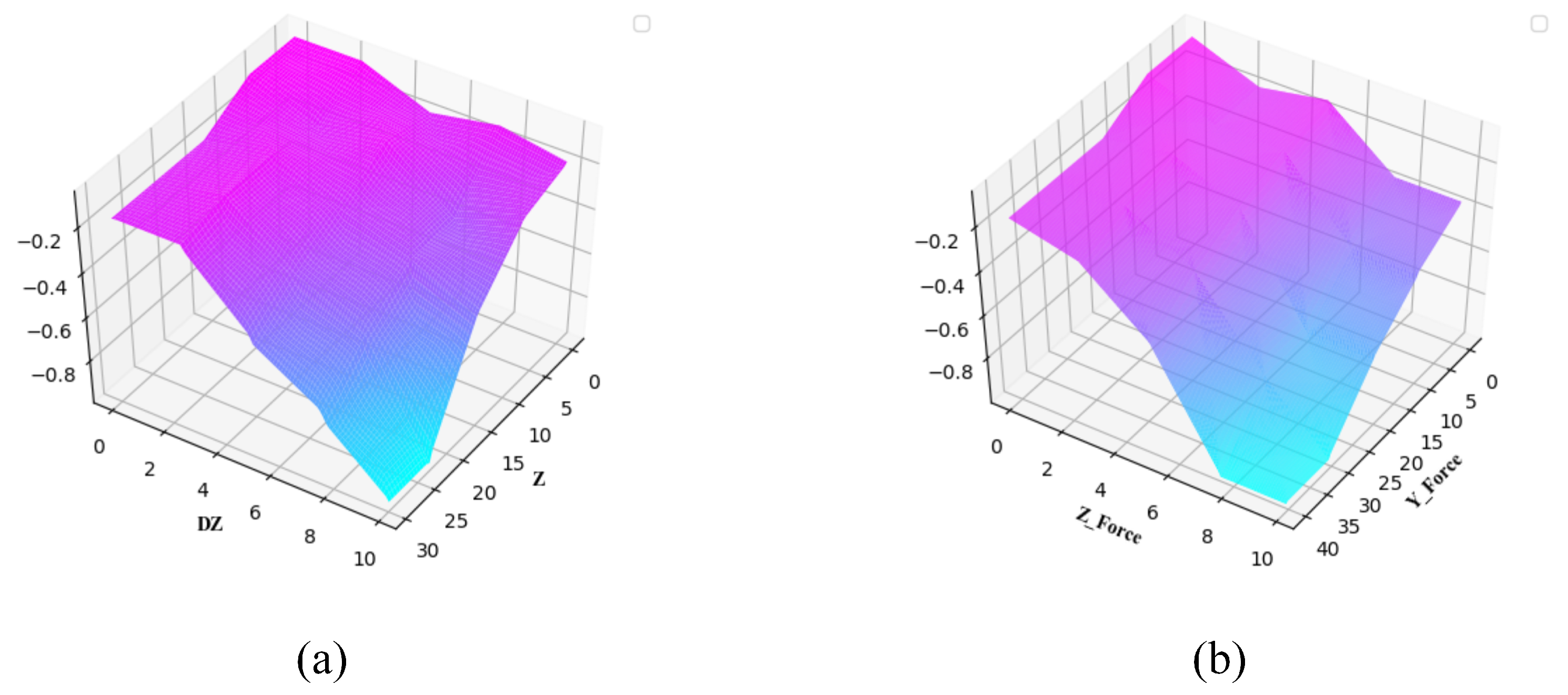
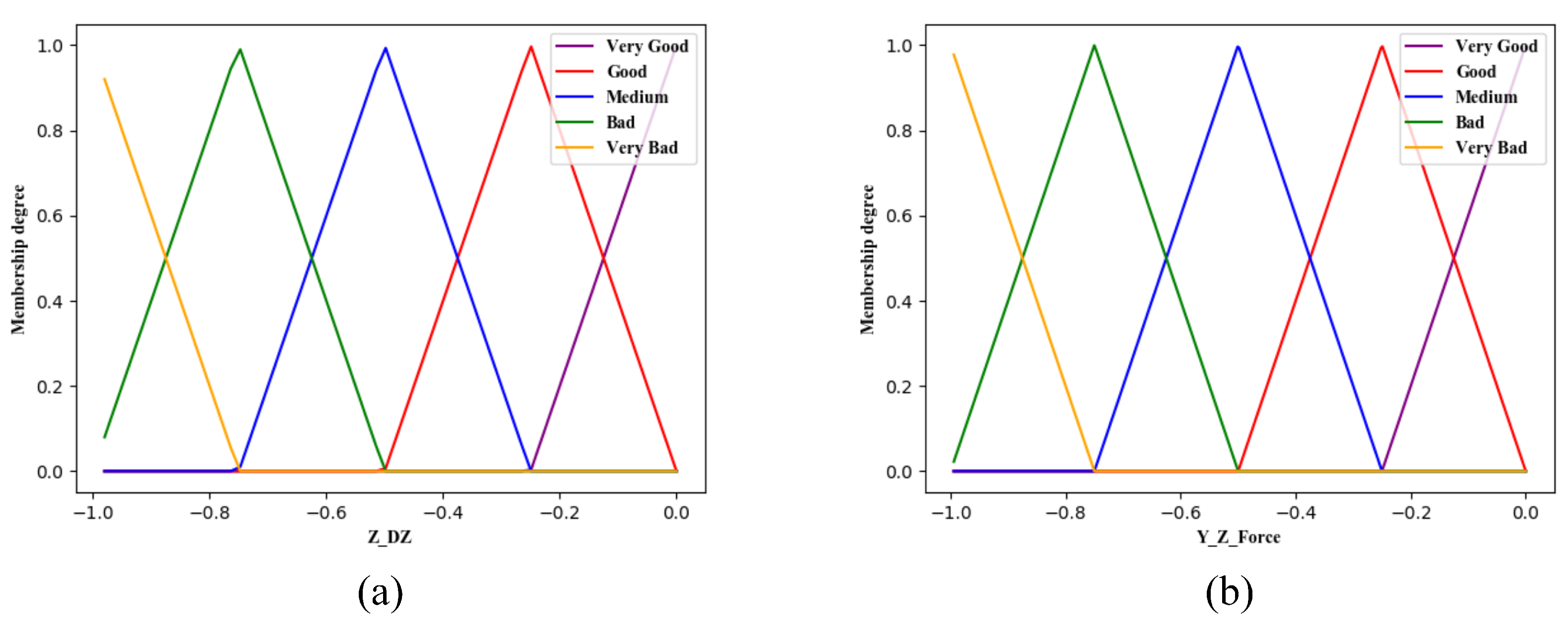
If you blur these four parameters, 625 fuzzy rules are needed if you use only one layer of fuzzy logic system. In order to simplify the design of the reward system, the double-layer fuzzy logic structure of
Figure 4 is adopted, the first layer has two fuzzy logic systems, the
fuzzy logic system takes the contact force
and z-axis contact force
as input, and the
fuzzy logic system takes the assembly depth
Z and assembly action
of the t-moment axis as the input. The output of the two systems serves as input to the second layer of fuzzy logic systems, and finally the value of the reward required is output by the second layer of fuzzy logic systems. Thus 75 fuzzy rules need to be made, greatly reducing the difficulty of fuzzy rules.
For the above parameter input system, using triangular membership function for fuzzy processing, each parameter is blurred into 5 fuzzy values: VG, G, M, B, and VB, respectively, refer to very good, good, medium, bad, and very bad. Each fuzzy value has a membership range of (0, 1).
where
represent the parameter value in the triangular membership function,
determines the width of the membership function, and
b determines the location of the membership function.
After blurring the parameters, fuzzy reasoning is based on the established rule library, and the rule library as shown in
Table 1 is established according to the experience in peg-in-hole assembly. Additionally, use the AND operation for fuzzy reasoning.
where
are fuzzy collections. The AND operation takes the minimum value of the membership of both and determines the membership of the fuzzy value of the output according to the rule library.
Finally, the resulting fuzzy value is clearly processed, that is, the last part of the fuzzy logic system: de-fuzzing. Since there are many fuzzy values obtained after fuzzy reasoning, which cannot be used, the data need to be processed by the de-fuzzing method, and finally the clear value that meets our requirements is obtained.
Discrete fuzzy values are used in this paper. Use the center of gravity method to defuse
where
refers to the clear output after de-blurring,
refers to the fuzzy collection of fuzzy reasoning, and
refers to the weight of each membership.
4.3. Network Training
During network training, the Actor and Critic’s target networks are recorded as
and
, which are used to calculate the target values. These target networks have to be updated with parameters
and
are parameters of the target network, and
is the progressive update rate for the target network.
During algorithm training, the Critic network optimizes parameter
by minimizing the loss function, Loss.
Thereinto, is a discount factor that balances the current and long-term penalties.
State action value function
Q updates Actor on the
gradient:



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}