1. Introduction
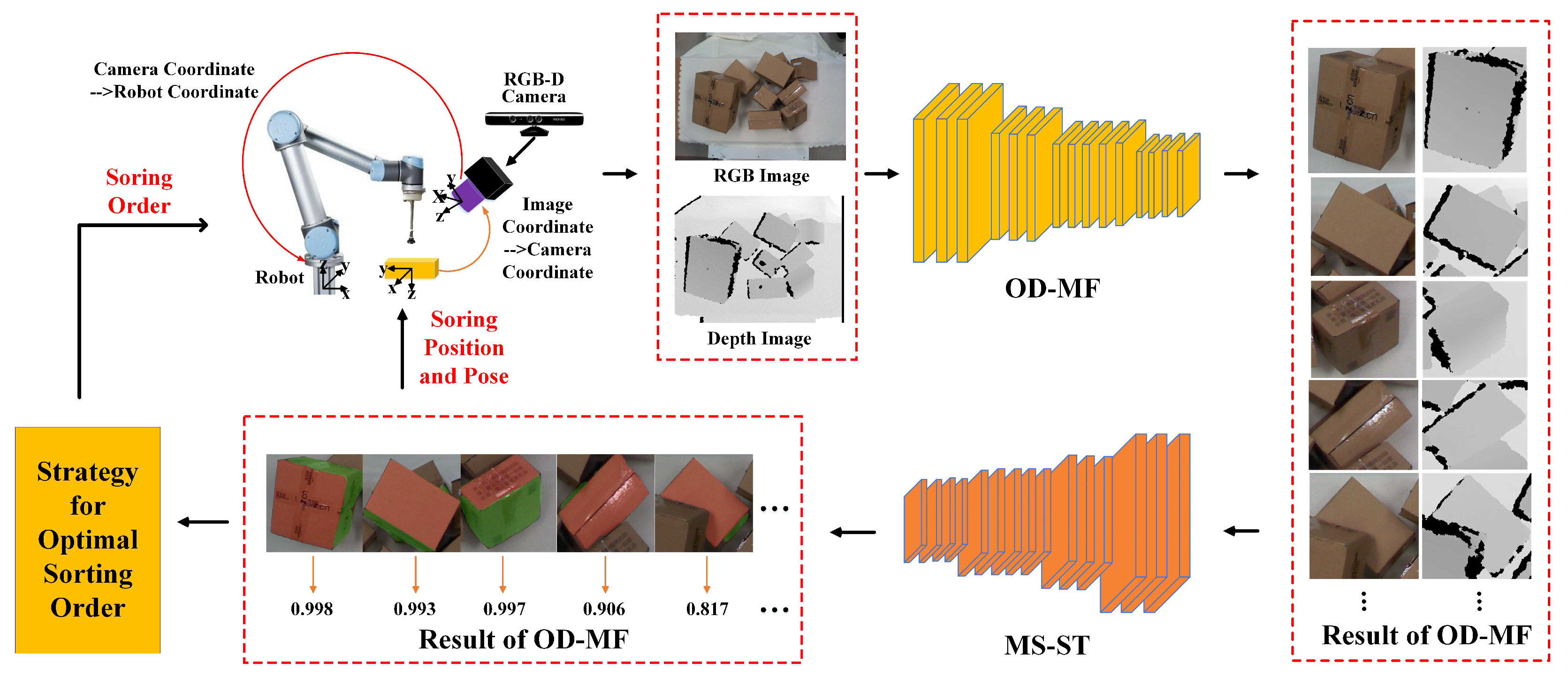
With the vigorous development of e-commerce and the rising labor costs, more and more e-commerce and logistics companies are building automated logistics sorting centers. The degree of automation is getting higher and higher. However, there are still some defects in the automated sorting process where human assistance is required. For example, the disorderly stacking of express parcels requires manual sorting and handling, which greatly limits the efficiency of express sorting and transportation. For such scenarios, industrial robots are used to replace manpower in our solution, and a visual sorting method based on multi-modal information fusion (VS-MF) is proposed. The proposed strategy could realize the detection of the optimal sorting position, pose and order for disorderly stacked express parcels.
Robotic visual sorting systems [
1,
2,
3] generally use the environmental information collected by 3D vision systems or RGB-D cameras as the original input source. Then, one or more potential sorting positions are predicted by visual algorithms. The grasping posture of the robot is gained according to the object posture or the image features. Finally, the robot achieves the grasping through trajectory planning. The key tasks in the whole process are improving the detection accuracy of sorting position and pose for each parcel, and determining the optimal sorting order of multi-object scene. The completion effect of these two tasks will influence the accuracy safety of the final sorting and the efficiency of the sorting system.
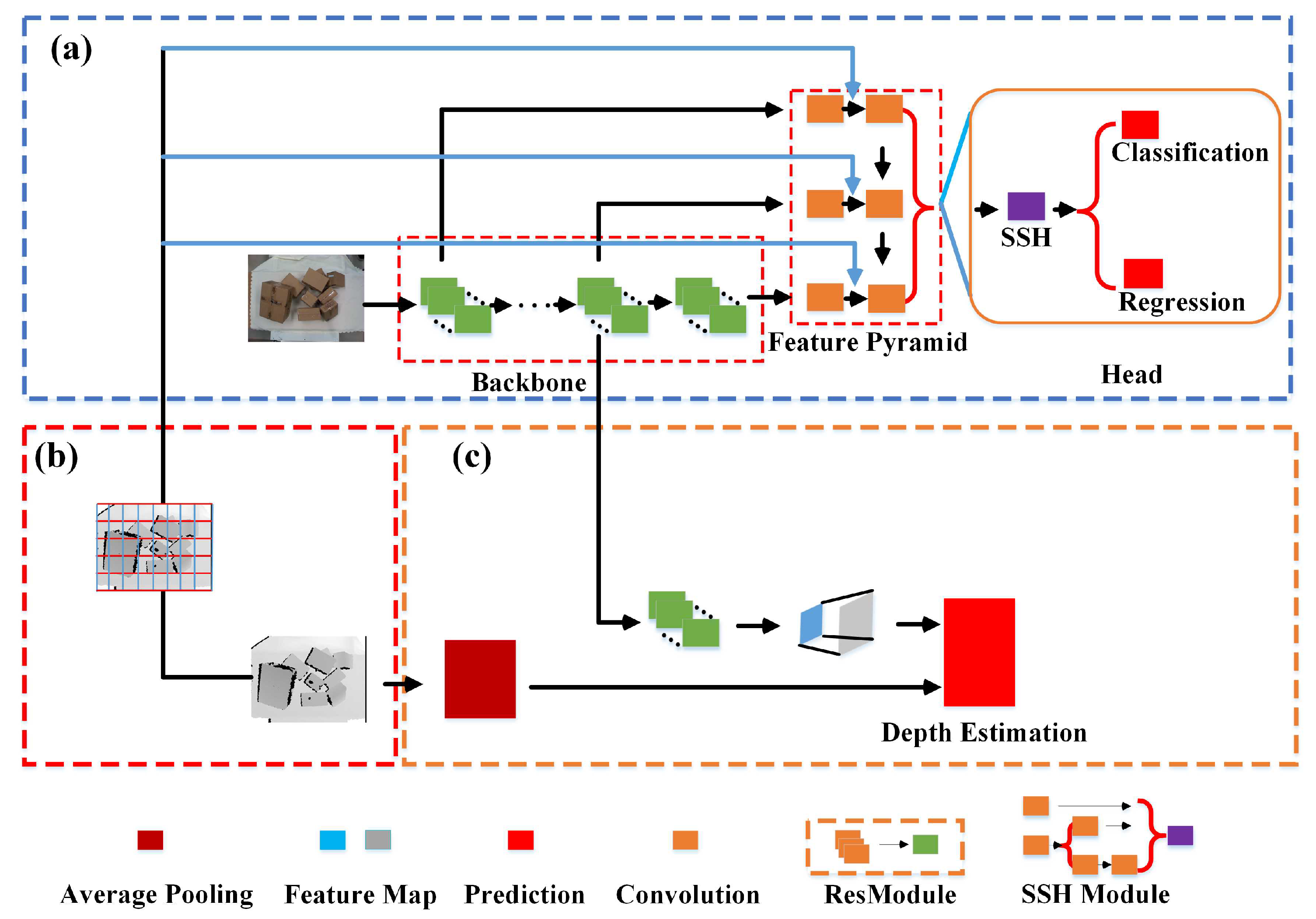
Deep learning methods have achieved great success in various vision tasks. Many researchers have introduced deep learning frameworks into the field of robot sorting, forming methods based on two different types of vision tasks. One is the visual sorting system based on object detection. Ulrich Viereck [
4] used a deep neural network to learn the method of closed-loop controller for machine sorting, and obtained the accurate grasping posture of the object by training the convolutional neural network to learn the distance function, with which a better grasping effect was achieved. Xuedan DU [
5] detected and classified the target objects in the image through a deep learning-based object detection algorithm, and then performed the grasping position detection. The robot grasping position was determined by performing a box searching on each image. In similar work, many scholars have carried out special modeling trained for grasping rectangle detection. Kumra [
6] proposed a multi-modal detection model based on deep learning. Color and depth information are used to detect objects. After being trained and tested on the Cornell dataset, this method achieved an accuracy of 89.21%, while ensuring the real-time performance of the system. Similarly, Zhang Hanbo [
7] proposed a fully convolutional visual grasping detection network based on directed anchor boxes, which realizes real-time detection of grasping. The aforementioned methods not only achieve high accuracy and a high recall rate, but also ensure the real-time performance of the system to a certain extent. However, the mentioned methods are quite difficult to accurately detect the targets when objects are heavily stacked since the semantic understanding of complex scenes is lacking. Thus, they are quite difficult to accurately detect when objects are heavily stacked. Recently, some other methods for robot grasping were proposed based on 3D object detection [
8,
9,
10,
11]. The grasping pose and position of the object can be determined effectively, though the real-time performance cannot be guaranteed. In addition for objects whose shape and texture features are not obvious enough, the estimation of the optimal grasping pose is difficult to train effectively.
In another type of research, segmentation-based deep learning model is used to detect grasping regions. Zeng [
12] proposed a robotic sorting system for known items and novel items in complex environments, which won the first place in the 2017 Amazon Picking Competition. The system uses multiple installed RGB-D cameras as data sources. Additionally, it utilizes deep neural networks based on ResNet-101 [
13] and FCN [
14] to segment pixel-wise grasping candidate regions. Then, the regression scores of the candidate regions are calculated. At last, a series of optimization strategies is proposed to select the best grasping point. The system can achieve 96.7% gripper grasping accuracy and 92.4% suction grasping accuracy, and can sort new items well. Similarly, Nguyen [
15] employs two connected deep neural networks, one as an object detector and one for detection of functional regions of objects. It was proved that combining an object detector and using CRF [
16] for post-optimization can achieve a high detection effect. It was experimentally verified on a full-scale humanoid robot. On this basis, Thanh-Toan Do [
17] proposed AffordanceNet, which borrows the idea of the famous instance segmentation algorithm Mask R-CNN [
18]. An end-to-end network structure is used to implement object classification and the segmentation of functional areas. This type of system more directly determines the grasping point or the segmentation of the candidate grasping area. As these segmentation algorithms mostly adopt a heavy network structure, they often need to balance the accuracy and real-time performance in complex scenes.
For the scene of express parcel sorting, Xing [
19] proposed a robot sorting method based on a deep neural network in complex scenes, extracting more detailed candidate regions by fusing shallow feature multi-layer and final feature maps. A keypoint-based cascaded optimal sorting position detection network was proposed to detect parcels in real time. The model based on key point detection in this study was designed in three dimensions. The positions and poses of objects can be estimated through key points, but there is still room for improvement in detection accuracy. Song [
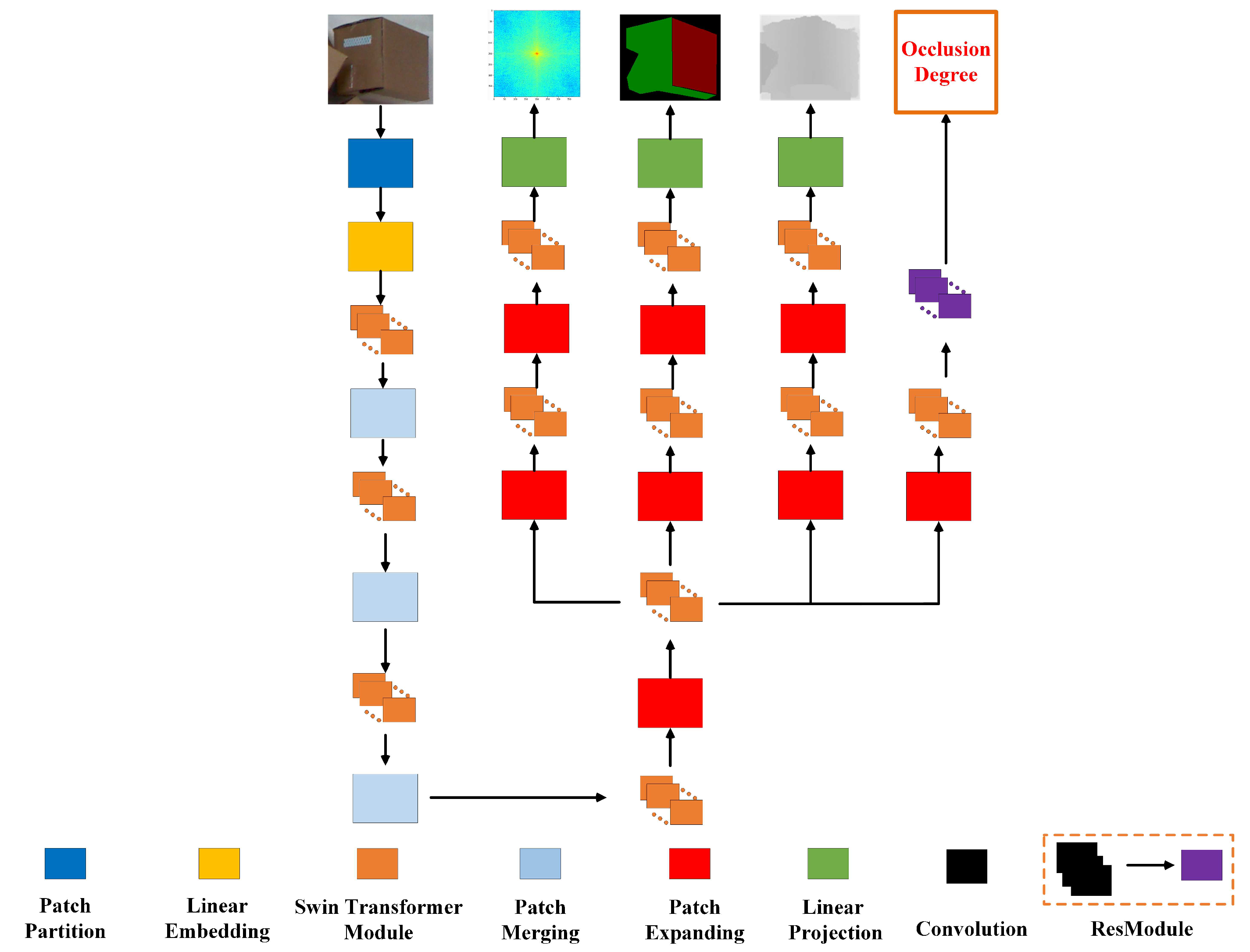
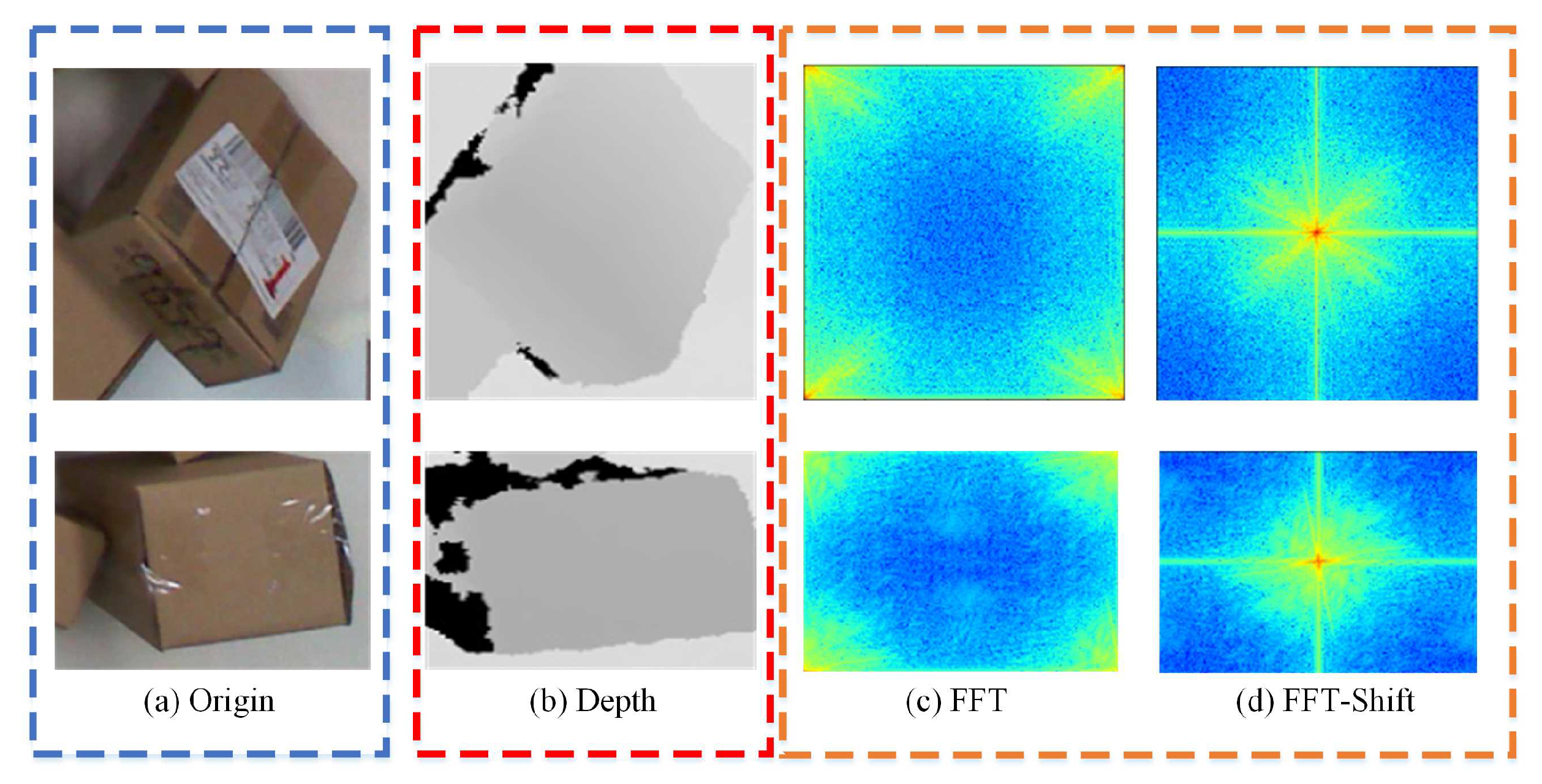
20] used a pruning strategy to propose a new lightweight network model architecture, which can quickly detect the sorting position of stacked parcels in complex scenes without losing accuracy. At the same time, the proposed multi-task network model improves the detection accuracy and gets the sorting pose at the same time. However, though the above-mentioned algorithm for parcels detection obtains the sorting pose by regressing key points, the designed key points are relatively close, and the pose estimated according to the key points will be largely limited by the accuracy of the sensor. Differently from the above methods, this paper propses a multi-modal segmentation network based on the Swin Transformer to obtain the candidate sorting area. Then, the optimal sorting position and pose are accurately estimated according to the point cloud features of the sorting area.
Recently, in order to overcome the limitations of convolution networks on local information interaction, many segmentation networks have borrowed the transformer model [
21]. Robin Strudel [
22] presents the semantic segmentation problem as a sequential to sequential problem. The network makes full use of context information at each stage of the model, which proves that it can produce very competitive results on all kinds of segmentation datasets. The research object of this paper is the parcels with similar color and stacked with each other, and the local information is not conducive to the detection of optimal grasping area and the prediction of occlusion degree. Therefore, this paper introduces the Swin Transformer [
23,
24] model into the robot visual grasping task to make full use of global information and improve the detection accuracy.
Another task of this study was to plan the optimal sorting order for multi-object scenes. In this respect, Panda [
25] tries to learn the contact relationship between objects and derives the contact relationship between the target and surrounding objects through three simple interactions (support from below, support from the side and containment). The objects are sorted in order according to the support relationship. Rosman [
26] proposed a method to learn spatial relationships between objects using segmented point clouds. Such methods can effectively ensure the safety and stability of grasping, but the 3D modeling of each object and the mechanical analysis of the contact surface are extremely time-consuming and cannot meet the real-time requirements of the industry. Zhang Hanbo [
7] proposed a visual manipulation relationship network (VMRN) to perform real-time prediction of manipulation relationships. In the visual manipulation relationship network, object detection and end-to-end training for manipulation relationship prediction are completed. However, for the research scenario of this paper, most express parcels are boxes with similar colors and similar shapes but different sizes. They are stacked and occluded by each other. It was necessary to design a novel network structure to detect the stacking of parcels and formulate a strategy that is more suitable for judging the sorting order of stacked parcels.
In order to realize detection of the optimal sorting position and pose, and gain the sound sorting order of stacked parcels, we propose a visual sorting method based on multi-modal information fusion (VS-MF). In summary, The novelties of the proposed VS-MF are as follows:
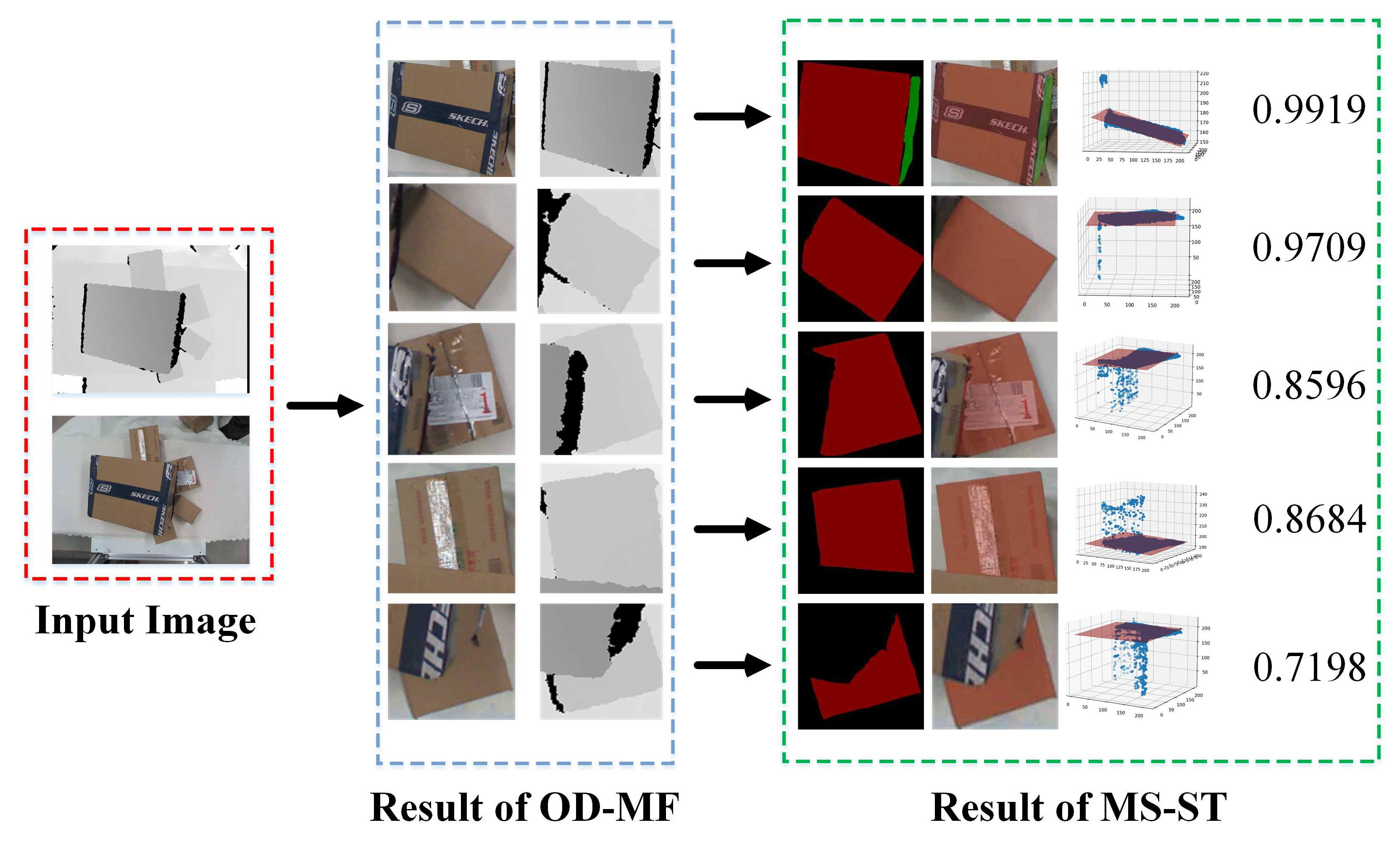
A new object detection network based on multi-modal information fusion (OD-MF) is proposed to detect parcels in stacked scenes, which not only achieves high detection accuracy, but also meets the real-time requirements for robots performing sorting tasks.
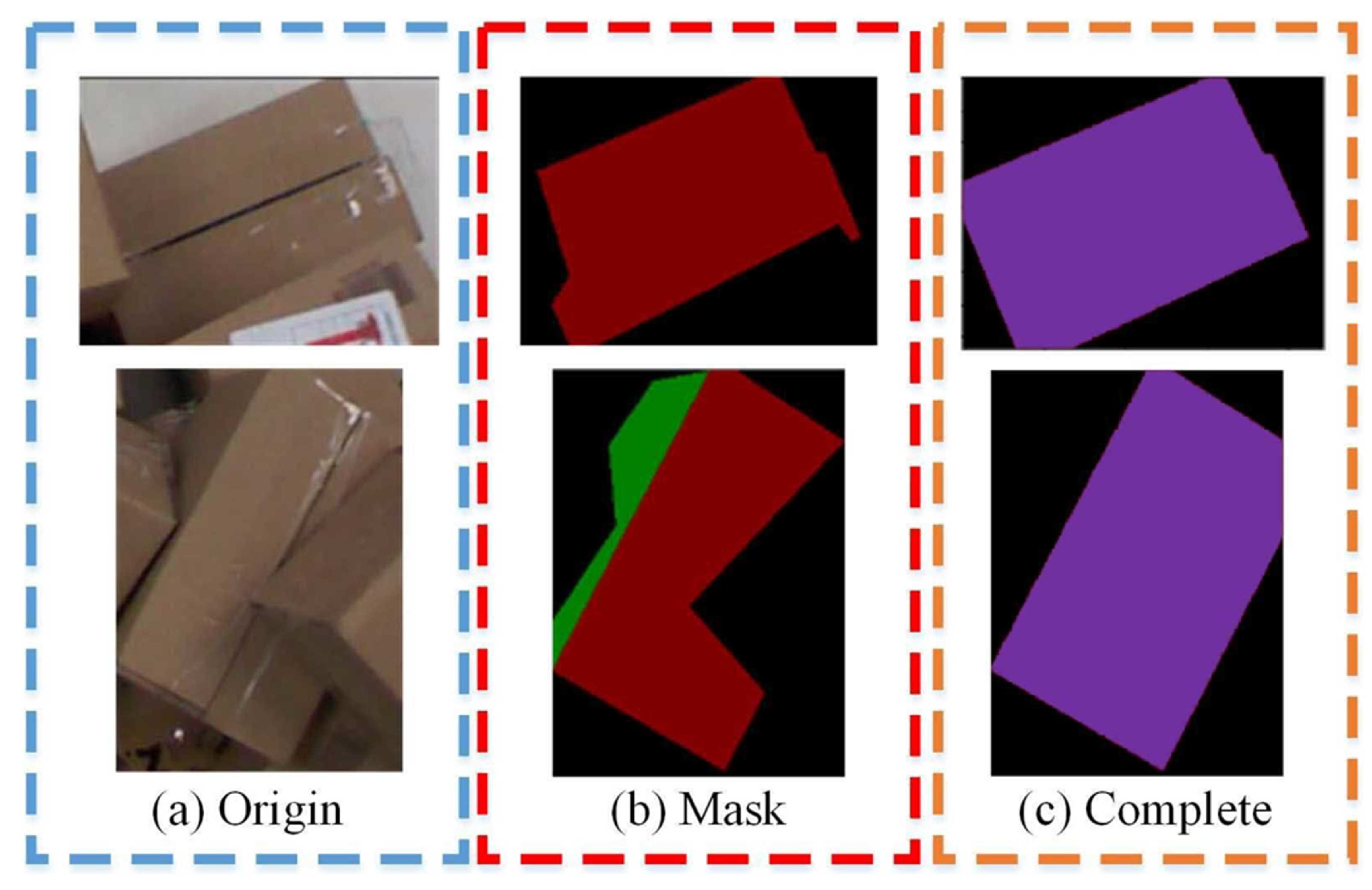
A novel multi-modal segmentation network based on Swin Transformer (MS-ST) is proposed, which obtains the pickable region and the occlusion degree of the parcels. As is known, it is the first network to complete these two tasks at the same time. Then, the optimal sorting position and pose of parcels can be calculated.
A novel strategy for the optimal sorting order of parcels is proposed, which can effectively ensure the stability of robot system during the sorting process.
The subsequent parts of this paper are organized as follows:
Section 2 introduces the entire framework of VS-MF. Then, OD-MF, MS-ST and the strategy for the optimal sorting order are explained in detail.
Section 3 presents experiments to verify the accuracy and effectiveness of the method. The conclusion and future work are presented in
Section 4.
4. Conclusions
In this paper, a new visual sorting method based on multi-modal information fusion was proposed for express parcels. First, an object detection method based on multi-modal information fusion was proposed, which improved the detection accuracy of stacked parcels in complex scenes. Secondly, a novel multi-modal segmentation network based on Swin Transformer was proposed, which accurately obtained the pickable regions and the occlusion degrees of the parcels. Finally, a novel strategy for the optimal sorting order of parcels was proposed to ensure the stability of robot system during the sorting process.
The experimental results show that, compared with other existing methods, the proposed method in this paper greatly improves the detection accuracy of parcels’ sorting positions and poses, achieving a 4.6% improvement in success rate of sorting task in the same environment compared to another method. It fully guarantees the stability of the sorting system and the success rate of robot sorting. The whole system using the VS-MF method can significantly reduce the labor cost of the storage center and improve the automation degree of the storage center. Since the proposed method can only guarantee the sorting of square parcels, the sorting methods for other shapes of parcels need further research. We found it will cause some unsuccessful sorting in the experiment when the sorting positions appeared on the tapes or labels of parcels. This is another area for improvement of our method we should focus on in future research. In the future, we will further optimize the proposed method to implement efficient sorting for more types of express parcels. At the same time, we will further improve the detection accuracy and speed of the method, and apply it to an actual logistics sorting center to solve the problem of automatic sorting for stacked parcels.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}