
A White-Box Sociolinguistic Model for Gender Detection


Abstract
:1. Introduction
2. Automatic Gender Detection: From Discriminant Analysis to Deep Learning
2.1. First Stage
2.2. Second Stage
2.3. Third Stage
2.4. Fourth Stage
3. A Sociolinguistic Model for Gender Detection
3.1. PAN-AP-13 Dataset
3.2. Features
3.3. Decision Trees for Gender Detection
4. Results
4.1. Orthography
4.2. Morphology
4.3. Lexicon
4.4. Syntax
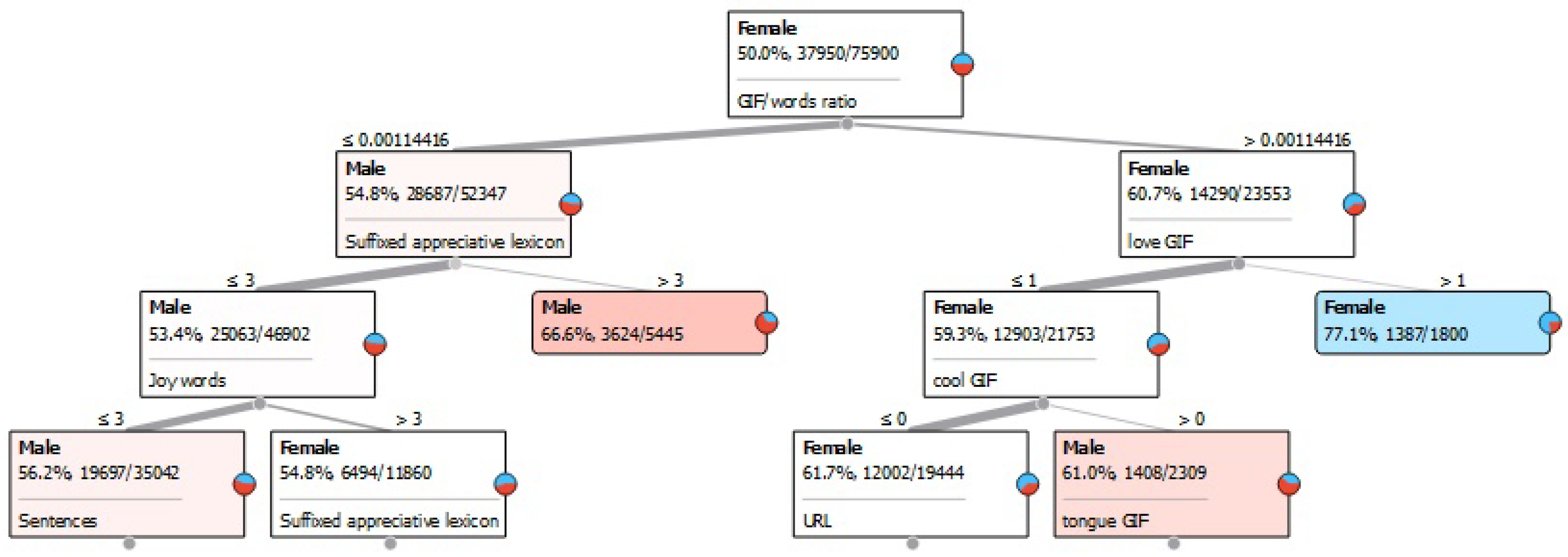
4.5. Digital Features
4.6. Pragmatic and Discourse
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Bruns, A. User-Generated Content. In The International Encyclopedia of Communication Theory and Philosophy; Wiley Online Library: Hoboken, NJ, USA, 2016; pp. 1–5. [Google Scholar]
- Lazer, D.; Pentland, A.; Adamic, L.; Aral, S.; Barabási, A.; Brewer, D.; Christakis, N.; Contractor, N.; Fowler, J.; Gutmann, M.; et al. Computational Social Science. Science 2009, 323, 721–723. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ochoa, X.; Duval, E. Quantitative analysis of user-generated content on the Web. In Proceedings of the WebEvolve2008: Web Science Workshop at WWW2008, Beijing, China, 22 April 2008; pp. 1–8. [Google Scholar]
- Argamon, S.; Koppel, M.; Pennabaker, J.W.; Schler, J. Automatically profiling the author of an anonymous text. Commun. ACM 2009, 52, 119–123. [Google Scholar] [CrossRef]
- Biber, J.K.; Doverskipe, D.; Baznik, D.; Cober, A.; Ritter, B.A. Sexual Harassment in Online Communications: Effects of Gender and Discourse Medium. CyberPsychol. Behav. 2002, 5, 33–42. [Google Scholar] [CrossRef] [PubMed]
- Krysowski, E.; Tremewan, J. Anonimity, Social Norms, and Online Harassment; Universität Wien: Vienna, Austria, 2015. [Google Scholar]
- Bugueño, M.; Mendoza, M. Learning to detect online harassment on Twitter with the transformer. In Machine Learning and Knowledge Discovery in Databases; Springer: Berlin/Heidelberg, Germany, 2020; pp. 1–10. [Google Scholar]
- Mukhopadhyay, D.; Mishra, K.; Mishra, K.; Tiwari, L. Cyber Bullying Detection Based on Twitter Dataset. In Machine Learning for Predictive Analysis; Springer: Singapore, 2020; pp. 87–94. [Google Scholar] [CrossRef]
- Nini, A. Developing forensic authorship profiling. Lang. Law 2018, 5, 38–58. [Google Scholar]
- Shen, A. Recommendations as personalized marketing: Insights from customer experiences. J. Serv. Mark. 2014, 28, 414–427. [Google Scholar] [CrossRef]
- Sun, X.; Wiedenbeck, S.; Chintakovid, T.; Zhang, Q. Gender talk: Differences in interaction style in CMC. In Proceedings of the 11th IFIP TC 13 International Conference on Human-Computer Interaction, Rio de Janeiro, Brazil, 10–14 September 2007; pp. 215–218. [Google Scholar] [CrossRef]
- Aljohani, T.; Cristea, A.I. Learners Demographics Classification on MOOCs During the COVID-19: Author Profiling via Deep Learning Based on Semantic and Syntactic Representations. Front. Res. Metrics Anal. 2021, 6, 1–17. [Google Scholar] [CrossRef]
- Nguyen, D.; Doğruöz, A.S.; Rosé, C.P.; de Jong, F. Computational Sociolinguistics: A Survey. Comput. Linguist. 2016, 42, 537–593. [Google Scholar] [CrossRef] [Green Version]
- Santosh, K.; Bansal, R.; Shekhar, M.; Varma, V. Author Profiling: Predicting Age and Gender from Blogs—Notebook for PAN at CLEF 2013. In Proceedings of the CLEF 2013 Labs and Workshops, Notebook Papers, CEUR Workshop, Padua, Italy, 22–23 September 2013. [Google Scholar]
- Bamman, D.; Eisenstein, J.; Schnoebelen, T. Gender identity and lexical variation in social media. J. Socioling. 2014, 18, 135–160. [Google Scholar] [CrossRef] [Green Version]
- Thomson, R.; Murachver, T. Predicting gender from electronic discourse. Br. J. Soc. Psychol. 2001, 40, 193–208. [Google Scholar] [CrossRef]
- Singh, S. A Pilot Study on Gender Differences in Conversational Speech on Lexical Richness Measures. Lit. Linguist. Comput. 2001, 16, 251–264. [Google Scholar] [CrossRef] [Green Version]
- Corney, M.; De Vel, O.; Anderson, A.; Mohay, G. Gender-preferential text mining of e-mail discourse. In Proceedings of the 18th Annual Computer Security Applications Conference, Washington, DC, USA, 9–13 December 2002; pp. 282–289. [Google Scholar] [CrossRef] [Green Version]
- Koppel, M.; Argomon, S.; Shimoni, A.R. Automatically categorizing written texts by author gender. Lit. Linguist. Comput. 2002, 17, 401–412. [Google Scholar] [CrossRef]
- Boulis, C.; Ostendorf, M. A quantitative analysis of lexical differences between genders in telephone conversations. In Proceedings of the 43rd Annual Meetings of the Association for Computational Linguistics, Ann Arbor, MI, USA, 25–30 June 2005; pp. 435–442. [Google Scholar] [CrossRef] [Green Version]
- Nowson, J.; Oberlander, J. The identity of bloggers: Openness and gender in personal blogs. In Proceedings of the AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, Stanford, CA, USA, 27–29 March 2006; pp. 163–167. [Google Scholar]
- Schler, J.; Koppel, M.; Argamon, S.; Pennebaker, J.W. Effects of age and gender on blogging. In Proceedings of the AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, Stanford, CA, USA, 27–29 March 2006; pp. 199–205. [Google Scholar]
- Yan, X.; Yan, L. Gender classification of weblog authors. In Proceedings of the AAAI Spring Symposium: Computational Approaches to Analyzing Weblogs, Stanford, CA, USA, 27–29 March 2006; pp. 228–230. [Google Scholar]
- Goswami, S.; Sarkar, S.; Rustagi, M. Stylometric analysis of bloggers’ age and gender. In Proceedings of the 3rd International AAAI Conference, San Jose, CA, USA, 17–20 May 2009; pp. 214–217. [Google Scholar]
- Mukherjee, A.; Liu, B. Improving gender classification of blog authors. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing, Cambridge, MA, USA, 9–11 October 2010; pp. 207–217. [Google Scholar] [CrossRef]
- Otterbacher, J. Inferring gender of movie reviewers: Exploiting writing style, content and metadata. In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 369–378. [Google Scholar] [CrossRef]
- Rao, D.; Yarowsky, D.; Shreevats, A.; Gupta, M. Classifying latent user attributes in Twitter. In Proceedings of the 2nd International Workshop on Search and Mining User-Generated Contents, Toronto, ON, Canada, 30 October 2010; pp. 37–44. [Google Scholar] [CrossRef]
- Burger, J.D.; Henderson, J.; Kim, G.; Zarrella, G. Discriminating gender on Twitter. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 1301–1309. [Google Scholar]
- Fink, C.; Kopecky, K.; Morawski, M. Inferring gender from the content of tweets: A region specific example. In Proceedings of the 6th International AAAI Conference on Web and Social Media, Dublin, Ireland, 4–7 June 2012; Volume 6, pp. 459–462. [Google Scholar]
- Ciot, M.; Sonderegger, M.; Ruths, D. Gender inference of Twitter users in non-English contexts. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1136–1145. [Google Scholar]
- Alrifai, K.; Rebdawi, G.; Ghneim, N. Arabic Tweeps Gender and Dialect Prediction—Notebook for PAN at CLEF 2017. In Proceedings of the CLEF 2017 Labs and Workshops, Notebook Papers, CEUR Workshop, Dublin, Ireland, 11–14 September 2017. [Google Scholar]
- Manna, R.; Pascucci, A.; Monti, J. Gender detection and stylistic differences and similarities between males and females in a dream tales blog. In Proceedings of the 6th Italian Conference on Computational Linguistics (CLiC-it 2019), Bari, Italy, 13–15 November 2019. [Google Scholar]
- Park, S.; Woo, J. Gender Classification Using Sentiment Analysis and Deep Learning in a Health Web Forum. Appl. Sci. 2019, 9, 1249. [Google Scholar] [CrossRef] [Green Version]
- Safara, F.; Mohammed, A.S.; Yousif Potrus, M.; Ali, S.; Tho, Q.T.; Souri, A.; Janenia, F.; Hosseinzadeh, M. An Author Gender Detection Method Using Whale Optimization Algorithm and Artificial Neural Network. IEEE Access 2020, 8, 48428–48437. [Google Scholar] [CrossRef]
- Kowsari, K.; Heidarysafa, M.; Odukoya, T.; Potter, P.; Barnes, L.E.; Brown, D.E. Gender detection on social networks using ensemble Deep Learning. In Proceedings of the Future Technologies Conference (FTC), San Francisco, CA, USA, 5–6 November 2020; pp. 346–358. [Google Scholar] [CrossRef]
- Sharma, D.J.; Dutta, S.; Bora, D.J. REGA: Real-time emotion, gender, age detection using CNN—A review. In Proceedings of the 2020 International Conference on Research in Management & Technovation (ACSIS, 2020), Nagpur, India, 5–6 December 2020; pp. 115–118. [Google Scholar] [CrossRef]
- Sumi, T.A.; Hossain, M.S.; Islam, R.U.; Andersson, K. Human Gender Detection from Facial Images Using Convolution Neural Network. In Applied Intelligence and Informatics; Springer International Publishing: Cham, Switzerland, 2021; pp. 188–203. [Google Scholar]
- Krishna, D.N.; Amrutha, D.; Sai Sumith, R.; Anudeepa, A.; Prabhu Aashish, G.; Triveni, B.J. Language Independent Gender Identification from Raw Waveform Using Multi-Scale Convolutional Neural Networks. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6559–6563. [Google Scholar] [CrossRef]
- Rangel, F.; Rosso, P.; Koppel, M.; Stamatatos, E.; Inches, G. Overview of the Author Profiling Task at PAN 2013. In Proceedings of the CLEF 2013 Labs and Workshops, Notebook Papers, CEUR Workshop, Valencia, Spain, 23–26 September 2013. [Google Scholar]
- Neal, T.; Sundararajan, K.; Fatima, A.; Yan, Y.; Xiang, Y.; Woodard, D. Surveying Stylometry Techniques and Applications. ACM Comput. Surv. 2017, 50, 1–36. [Google Scholar] [CrossRef]
- Rangel, I.D.; Sidorov, G.; Guerra, S.S. Creation and evaluation of a dictionary tagged with emotions and weighted for Spanish. Onomazein 2014, 29, 31–46. [Google Scholar]
- Loyola-González, O. Black-Box vs. White-Box: Understanding Their Advantages and Weaknesses From a Practical Point of View. IEEE Access 2019, 7, 154096–154113. [Google Scholar] [CrossRef]
- Song, Y.Y.; Lu, Y. Decision tree methods: Applications for classification and prediction. Shanghai Arch. Psychiatry 2015, 27, 130–135. [Google Scholar]
- Almuallim, H.; Kaneda, S.; Akiba, Y. Development and Applications of Decision Trees. Expert Syst. 2002, 1, 53–77. [Google Scholar]
- Verhoeven, B.; Škrjanec, I.; Pollak, S. Gender profiling for Sloven Twitter communication: The influence of gender marking, content and style. In Proceedings of the 6th Workshop on Balto-Slavic Natural Language Processing, Valencia, Spain, 4 April 2017; pp. 119–125. [Google Scholar] [CrossRef]
- Parking, R. Gender and Emotional Expressiveness: An Analysis of Prosodic Features in Emotional Expression. Griffith Work. Pap. Pragmat. Intercult. Commun. 2012, 5, 46–54. [Google Scholar]
- Newman, M.L.; Groom, C.J.; Handelman, L.D.; Pennebaker, J.W. Gender differences in language use: An analysis of 14,000 text samples. Discourse Process. 2008, 45, 211–236. [Google Scholar] [CrossRef]
- Hosseini, M.; Tammimy, Z. Recognizing users gender in social media using linguistic features. Comput. Hum. Behav. 2016, 56, 192–197. [Google Scholar] [CrossRef]
- Rangel, F.; Rosso, P. Use of language and author profiling: Identification of gender and age. In Proceedings of the Nautral Language Processing and Cognitive Science, Marseille, France, 15–16 October 2013; pp. 177–186. [Google Scholar]
- Waseleski, C. Gender and the Use of Exclamation Points in Computer-Mediated Communication: An Analysis of Exclamations Posted to Two Electronic Discussion Lists. J. Comput.-Mediat. Commun. 2006, 11, 1012–1024. [Google Scholar] [CrossRef]
- Zelenkauskaite, A.; Herring, S.C. Gender encoding of typographical elements in Lithuanian and Croatian IRC. In Cultural Attitudes Towards Technology and Communication 2006: Proceedings of the Fifth International Conference on Cultural Attitudes towards Technology and Communication, Tartu, Estonia, 28 June–1 July 2006; Murdoch University Press: Murdoch, Australia, 2006. [Google Scholar]
- Ling, R. The Sociolinguistics of SMS: An Analysis of SMS use by a random sample of Norwegians. In Mobile Communication and the Recognition of the Social Sphere; Ling, R., Pederson, P., Eds.; Springer: London, UK, 2005; pp. 335–350. [Google Scholar]
- Al Rousan, R.M.; Abd Aziz, N.H.; Christopher, A.A. Gender differences in the typographical features used in the text messaging of young Jordanian undergraduates. In Proceedings of the International Conference on Languages, Literature and Linguistics, Dubai, United Arab Emirates, 28–30 December 2011. [Google Scholar]
- Schwartz, H.A.; Eichstaedt, J.C.; Kern, M.L.; Dziurzynski, L.; Ramones, S.M.; Agrawal, M.; Shah, A.; Kosinski, M.; Stillwell, D.; Seligman, M.E.P.; et al. Personality, gender, and age in the language of social media: The open-vocabulary approach. PLoS ONE 2013, 8, e73791. [Google Scholar] [CrossRef]
- Gianfortoni, P.; Adamson, D.; Rosé, C.P. Modeling of stylistic variation in social media with stretchy patterns. In Proceedings of the 1st Workshop on Algorithms and Resources for Modelling of Dialects and Language Varieties, Edinburgh, UK, 31 July 2011; pp. 49–59. [Google Scholar]
- Argamon, S.; Koppel, M.; Pennebaker, J.W.; Schler, J. Mining the blogosphere: Age, gender and the varieties of self-expression. First Monday 2007, 12. [Google Scholar] [CrossRef]
- Johannsen, A.; Hovy, D.; Søggard, A. Cross-lingual syntactic variation over age and gender. In Proceedings of the 19th Conference on Computational Language Learning, Beijing, China, 30–31 July 2015; pp. 103–112. [Google Scholar] [CrossRef] [Green Version]
- Tannen, D. You Just Don’t Understand: Men and Women in Conversation; Ballantine: New York, NY, USA, 1990. [Google Scholar]
- Lakoff, R. Language and Woman’s Place. Lang. Soc. 1973, 2, 45–80. [Google Scholar] [CrossRef] [Green Version]
- García Mouton, P. Cómo Hablan las Mujeres; Arco Libros: Madrid, Spain, 1999. [Google Scholar]
- García Mouton, P. Así Hablan las Mujeres. Curiosidades y Tópicos del Uso Femenino del Lenguaje; La Esfera de los Libros: Madrid, Spain, 2003. [Google Scholar]
- Silva-Corvalán, C. Sociolingüística: Teoría y Análisis; Editorial Alhambra: Madrid, Spain, 1989. [Google Scholar]
- Soler-Company, J.; Wanner, L. On the role of syntactic dependencies and discourse relations for author gender identification. Pattern Recognit. Lett. 2018, 105, 87–95. [Google Scholar] [CrossRef]
- Witmer, D.F.; Katzman, S.L. On-Line Smiles: Does Gender Make a Differnece in the Use of Graphic Accents? J. Comput.-Mediat. Commun. 1997, 2, JCMC244. [Google Scholar] [CrossRef]
- Chen, Z.; Lu, X.; Ai, W.; Li, H.; Mei, Q.; Liu, X. Through a Gender Lens: Learning Usage Patterns of Emojis from Large-Scale Android Users. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 763–772. [Google Scholar] [CrossRef] [Green Version]
- Mendelson, A.L.; Papacharissi, Z. Look at us: Collective narcissism in college student Facebook photo galleries. In The Networked Self: Identity, Community and Culture on Social Network Site; Papacharissi, Z., Ed.; Taylor & Francis: Hoboken, NJ, USA, 2010; pp. 251–273. [Google Scholar]
- Holmes, J. Women, Men and Politeness; Routledge: London, UK, 1995. [Google Scholar]


{kind=link}
| Author | Year | Dataset | Features | Algorithm | Acc. |
|---|---|---|---|---|---|
| Singh | 2001 | Oral conversations | Lexical richness measures | Discriminant analysis | 90.0 |
| Boulis & Ostendorf | 2005 | Telephone conversations | Word unigrams and bigrams | SVM | 92.5 |
| Nowson & Oberlander | 2006 | Blogs | Dictionary-based and POS n-grams | SVM | 92.5 |
| Goswami, Sarkar & Rustagi | 2009 | Blogs | Non-dictionary words and sentence length | Naïve Bayes | 89.3 |
| Otterbacher | 2010 | Movie reviews | Lexical frequencies and POS tags | Logistic Regression | 73.3 |
| Rao et al. | 2010 | Tokens unigrams and bigrams | SVM | 72.3 | |
| Alrifai, Rebdawi & Ghneim | 2017 | Character n-grams (2, 7) | Sequential Minimal Optimization | 72.25 | |
| Fink, Kipecky & Morawski | 2012 | Word unigrams, hashtags and LIWC categories | Balanced Winno2 | 75.5 | |
| Manna, Pascucci & Monti | 2019 | Blogs | Word unigrams, bigrams, and trigrams | Feed-Forward Neural Network | 77.6 |
| Park & Woo | 2019 | Web forum | NRC and BING dictionaries | CNN | 91 |
| Kowsari et al. | 2020 | TF-IDF and GloVe | CNN | 86.33 |
| Language | Age Group | Gender | Number of Authors | |
|---|---|---|---|---|
| Training | Test | |||
| Spanish | 10 s | M | 1250 | 144 |
| F | 1250 | 144 | ||
| 20 s | M | 21,300 | 2304 | |
| F | 21,300 | 2304 | ||
| 30s | M | 15,400 | 1632 | |
| F | 15,400 | 1632 | ||
| TOTAL | 75,900 | 8160 | ||
| Features | CA |
|---|---|
| D | 56.9 |
| D + L | 58.9 |
| D + L + S | 59.2 |
| D + L + S + M | 59.0 |
| D + L + S + M + P | 59.0 |
| D + L + S + M + P + O | 58.7 |
| Feature | Importance | Female | Male |
|---|---|---|---|
| Ellipsis points | 0.382 | 3.764 | 2.841 |
| Numeric characters | 0.154 | 4.285 | 6.418 |
| Repetition of exclamation marks | 0.145 | 0.318 | 0.195 |
| Dashes | 0.102 | 3.760 | 4.660 |
| Commas | 0.079 | 14.115 | 15.430 |
| Consonants | 0.050 | 584.344 | 645.232 |
| Double quotation marks | 0.023 | 1.073 | 1.336 |
| Upper case | 0.018 | 56.448 | 52.007 |
| Duplication of exclamation marks | 0.014 | 0.138 | 0.080 |
| Parentheses | 0.012 | 1.264 | 1.828 |
| Lower case | 0.011 | 1026.719 | 1139.409 |
| Repetition of vowels | 0.007 | 0.066 | 0.036 |
| Full stops | 0.005 | 6.884 | 7.771 |
| Feature | Importance | Female | Male |
|---|---|---|---|
| Personal pronouns | 0.305 | 7.789 | 6.215 |
| Prepositions | 0.241 | 20.418 | 20.996 |
| Numeral determiners | 0.174 | 1.931 | 2.689 |
| Demonstrative determiners | 0.072 | 1.528 | 1.573 |
| Non-personal verbs | 0.057 | 9.434 | 8.304 |
| Personal verbs | 0.055 | 22.458 | 20.037 |
| Possessive determiners | 0.033 | 5.360 | 4.535 |
| Definite articles | 0.024 | 10.318 | 10.860 |
| Coordinating conjunctions | 0.024 | 9.041 | 8.597 |
| Demonstrative pronouns | 0.008 | 0.492 | 0.488 |
| Nouns | 0.007 | 29.551 | 30.151 |
| Feature | Importance | Female | Male |
|---|---|---|---|
| Joy words | 0.449 | 5.585 | 4.923 |
| Suffixed appreciative lexicon | 0.217 | 0.913 | 1.247 |
| Ratio letters/words | 0.172 | 4.317 | 4.367 |
| Derived appreciative lexicon | 0.040 | 4.215 | 5.138 |
| Approximators | 0.026 | 0.062 | 0.092 |
| Words over six characters | 0.024 | 43.957 | 50.317 |
| Sadness words | 0.019 | 2.680 | 2.566 |
| Lexical diversity | 0.007 | 0.742 | 0.758 |
| TTR Lemma | 0.005 | 0.151 | 0.156 |
| Emotive lexicon | 0.004 | 10.918 | 10.194 |
| Mitigating lexicon | 0.004 | 5.385 | 4.994 |
| Feature | Importance | Female | Male |
|---|---|---|---|
| Sentences | 0.354 | 3.854 | 3.408 |
| Nominal modifier | 0.340 | 9.750 | 12.441 |
| Adverbial modifier | 0.170 | 15.101 | 14.673 |
| Sentences length | 0.041 | 71.554 | 74.049 |
| Flat multiword expression | 0.032 | 6.507 | 8.442 |
| Open clausal complement | 0.021 | 5.361 | 5.036 |
| Clausal complement | 0.018 | 4.310 | 4.208 |
| Adjectival modifier | 0.016 | 11.800 | 14.169 |
| Subordination | 0.008 | 29.427 | 29.321 |
| Feature | Importance | Female | Male |
|---|---|---|---|
| GIF/words ratio | 0.530 | 0.023 | 0.015 |
| love GIF | 0.213 | 0.213 | 0.065 |
| cool GIF | 0.128 | 0.034 | 0.063 |
| JPG | 0.031 | 0.097 | 0.065 |
| w00t GIF | 0.029 | 0.045 | 0.051 |
| hug GIF | 0.024 | 0.037 | 0.013 |
| URL | 0.021 | 0.185 | 0.253 |
| tongue GIF | 0.015 | 0.117 | 0.071 |
| GIF | 0.004 | 1.301 | 0.795 |
| inlove GIF | 0.003 | 0.043 | 0.017 |
| Feature | Importance | Female | Male |
|---|---|---|---|
| Exclamative sentences | 0.266 | 1.201 | 0.850 |
| Existential presuppositions proper names | 0.259 | 4.438 | 6.227 |
| Personal deixis | 0.161 | 13.273 | 10.841 |
| Spatial deixis | 0.123 | 3.225 | 3.390 |
| Ex. pr. det. phrases with defined interpretation | 0.058 | 10.428 | 12.064 |
| Temporal deixis | 0.028 | 2.181 | 1.812 |
| Tabulations | 0.027 | 3.823 | 3.152 |
| Line breaks | 0.024 | 18.515 | 16.480 |
| Gratitude expressions | 0.022 | 0.174 | 0.142 |
| Existential presuppositions | 0.018 | 17.642 | 20.967 |
| Lexical presuppositions | 0.014 | 1.958 | 1.744 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Morales Sánchez, D.; Moreno, A.; Jiménez López, M.D. A White-Box Sociolinguistic Model for Gender Detection. Appl. Sci. 2022, 12, 2676. https://doi.org/10.3390/app12052676
Morales Sánchez D, Moreno A, Jiménez López MD. A White-Box Sociolinguistic Model for Gender Detection. Applied Sciences. 2022; 12(5):2676. https://doi.org/10.3390/app12052676
Chicago/Turabian StyleMorales Sánchez, Damián, Antonio Moreno, and María Dolores Jiménez López. 2022. "A White-Box Sociolinguistic Model for Gender Detection" Applied Sciences 12, no. 5: 2676. https://doi.org/10.3390/app12052676