1. Introduction
The stylometry is currently the interdisciplinary field combining literary stylistics, statistics, machine learning and computer linguistics to study the style of documents with various purposes. Currently, the stylometry is used to determine the authorship, to describe the features of the author’s style, to detect plagiarism or falsification of various documents, articles, traditional letters, emails and short messages on social networks, and, finally, literary works and their fragments, as well as scientific papers. The stylometry is constantly being improved, although the universal methods leading to a reliable determination of authorship have not yet been developed for most tasks. Nevertheless, in recent years, the methods of stylometry have become actively used in the protection of information, as described in [
1,
2,
3], and criminology [
4].
The modern stylometry is more connected with the analysis of printed texts presented in electronic form, which is due to the active digitalization of society. The need to solve a significant number of problems of stylometry has led to the expansion of the usage of computer methods. Currently, the effectiveness of computational linguistics methods and machine learning methods in the problems of stylometry is already difficult to dispute, these methods are being developed by groups of researchers around the world.
The stylometry in the context of attribution of authorship assumes the identification of features of the author’s style that can be quantified. This work presents the study of the author’s style based on poetic texts in Russian. The task is to determine the features of the author’s style of A.S. Pushkin, as well as poets of the Pushkin era, using machine learning methods. These methods require the data to compare and to identify the features that characterize the author’s style, so the problem was formulated as a binary classification problem, in which two classes were distinguished: the poems by A.S. Pushkin, and poems by other poets of the Pushkin era: K.N. Batyushkov, E.A. Boratynsky, P.A. Vyazemsky, N.I. Gnedich, D.V. Davydov, A.A. Delvig, and V.A. Zhukovsky. It was decided to use only poems as data (the work belonged to this genre on the basis of the formal characteristics given by the compilers of the collected works).
Here, are the main terms used in this article in relation to Russian versification.
A poem is a work written in verse, mostly of a small volume (unlike prose) and mostly lyrical [
5].
A verse is a literary speech, phonetically divided into the separate segments (each of them is also called a verse), which are perceived as comparable and commensurate [
6]. In comparison with prose, the division of verse has two features:
In prose, the division of text is determined only by syntactic pauses; in verse, the articulating pauses may not coincide with syntactic ones;
In prose, the allocation of articulating pauses is largely arbitrary; in verses, it is firmly set.
As noted in [
5], the division into verses is usually marked by the graphic design of the text and is often accompanied by rhyme or other phonetic features. A means to emphasize the comparability and commensurability of verses is the meter—the alternation of strong and weak points within the verse—but it may also be absent, for example in purely tonic or free verse.
The poems as data for classification have a certain specificity: as these are small works, the usage of methods that take into account the frequency of various elements of the verse or compression methods may not give sufficiently accurate results. Therefore, it was decided to abandon the usage of compression methods immediately, but the features describing the frequency of elements form the basis of this work. The metrorhythmic characteristics of a verse can provide additional useful information for classification.
2. Definition of Feature Groups
The attribution tasks and the definition of the author’s style are similar in many ways; they require the determination of the style elements inherent in a particular author, but the attribution tasks are often formulated somewhat differently, for example as described in [
7]. Within the framework of this work, the classification serves as the basis for the analysis of features in order to highlight the characteristics of the author’s style.
From the point of view of philology, the individual (written) style is a complex concept reflecting the socio-historical nature, ethnic, psychological, moral, and ethical characteristics of the author [
8]. The various authors identify the different levels of text analysis [
8,
9] that can be used in stylometry and, upon combining them, we find the following set of levels:
The phonetic level takes into account the peculiarity of intonation and melodica. The melodica describes the number of syllables in words, the repetitions of vowels and consonants to enhance expressive power and euphony. In poetic works, the melodica is aimed at ensuring the rhythm and the harmony.
The punctuation level reveals the peculiarities of the author’s usage of punctuation marks and characteristic errors.
The spelling level reveals the characteristic errors in the spelling of words.
The lexical level describes the author’s vocabulary, the features of the usage of words, phrases and stable expressions, as well as typical repetitive parts of sentences; a tendency to use rare and foreign words, synonyms, antonyms, paronyms, neologisms, as well as words denoting certain concepts.
The syntactic level describes the features of sentence construction, the prevailing types of sentences (affirmative, interrogative, exclamation), the tendency to use complex or incomplete, as well as elliptical sentences, types of syntactic coherence, word order, and sentence length.
The stylistic level is responsible for the genre, plot, and general structure of the text, as well as characteristic artistic means.
As only published texts are considered in this work, the presence of spelling and punctuation errors is excluded. In the work [
9], it is noted that the author’s style usually refers to the features of the text at the highest levels, namely syntactic, lexical, and stylistic levels. It should be noted that these levels are widely used in expert analysis, but for formal computational analysis, these groups are quite complex, so most researchers use phonetic, as well as punctuation, lexical, and syntactic levels for analysis.
Within the framework of this work, the groups of features are identified that actively influence the definition of authorship and characterize the author’s style the most. The following groups of features were identified:
the distribution by parts of speech and relationships;
the punctuation mark frequencies;
the words and their n-grams;
the service words;
the letters and other symbols, as well as their n-grams;
the metrorhythmic features.
The distribution of words by parts of speech and relations corresponds to the syntactic level; the frequency of punctuation marks corresponds to the punctuation level. The features describing the words and their n-grams, as well as service words, are related to the lexical level. The features describing the distribution by letters and other symbols, as well as their n-grams, largely reflect the melodica of the text and describe the text at the phonetic level. In addition, the author can consciously control such a distribution to a lesser extent, unlike, for example, the words used. The metrorhythmic features can also be attributed to the phonetic level. Thus, all levels of text description are used in the study, with the exception of stylistic, but it is important to note that the description of the text using the selected set of features is not exhaustive at any level, so further work can be aimed at building the new effective features to improve the quality of text description at various levels.
In this work, the texts of poems in modern orthography were studied. It can be assumed that the study of texts in their original pre-reform orthography would be a little more productive, but it is very difficult to collect a corpus of such texts, with the exception of A.S. Pushkin’s texts. Nevertheless, such a study is of unquestionable interest and may become the subject of further research. The example of such studies of prose works in the original pre-revolutionary orthography is presented in [
10]; they confirm the assumption about the productivity of this approach.
3. Related Works
The works devoted to stylometry analyze a variety of sources: prose and poetic literary works, scientific articles, diploma and term papers, essays, e-mail letters, and messages on social networks. Additionally, although a significant number of works are devoted to the analysis of literary works in prose, the analysis of poems is carried out in a small number of works [
11], while only a few are devoted to the analysis of poems in Russian [
12].
The construction of effective stylometry features of the text largely determines the success of the entire study of both prose and poetic texts, which is why most authors pay considerable attention to this aspect. The researchers tend to believe that the phonetic level represented by symbols and their
n-grams is extremely productive for stylometry, the value of
n is usually a variable parameter and largely depends on the language and features of the studied texts [
8]. In addition, еру symbolic
n-grams are easily extracted, but, nevertheless, the quality of solving problems based on this group of features alone is not enough; therefore, to improve the quality, the different authors used other features describing a wide variety of structural levels of texts.
Therefore, the authors of the work [
13], which was presented within the PAN competition
https://pan.webis.de (accessed on 28 January 2022) by the determination of the coincidence of authorship in pairs of imitations of original texts (fanfics), built a set of classifiers that confirm or disprove an authorship based on the analysis of a number of characteristics of the text: punctuation frequencies, last words in sentences, all categories of service words, abbreviations, verb tenses, as well as adverbs of place and time.
The authors of the work [
14] took into account the syntactic structure of sentences when determining authorship; they built two self-learning subnets that accepted a sequence of words and their parts of speech, respectively. The proposed model was trained on 2662 texts of various genres in English. As a result, the consideration of the syntactic structure showed excellent results: the accuracy was 92.4%.
The paper [
4] describes the approach to classifying the messages in social networks, the various combinations of
n-gram symbols and
n-gram words at the level of parts of speech were investigated. As a result, this approach demonstrated the accuracy of 70%.
The ensemble approach based on three independent classifiers is described in [
15]. The method is based on the
n-gram model of variable length and on the polynomial logistic regression, and is used to select a classifier with better reliability. The constructed method was tested on a set of PAN-CLEF texts in English and Portuguese, but it showed very low accuracy on the texts of songs (52%), so the method was assessed as unsuitable for lyrics.
In [
16], a software product StylometryRy for determining the authorship of controversial texts in Russian is described. The texts in it were presented in the form of bag-of-words. The naive Bayesian classifier, the method
k of the nearest neighbors and the logistic regression were used as classifiers, and the minimum text length for classification was 5500 words.
Both the Burrows’ Delta and its modification, the Eder’s Delta, and the author’s invariant, described, for example, in [
17] and defined as a characteristic of the text, calculated as the percentage of the content of service words (conjunctions, prepositions, and particles—55 words in total for the Russian language) in the text, are aimed at building the estimates of the content and the number of service words. The author of [
17] notes that these characteristics are very effective for stylometry, but only within the framework of sufficiently large texts; they should be used for texts from 1000–2000 words.
The aim of the work [
1] is to evaluate the effectiveness of the usage of stylometry as an alternative method of authentication of users of information systems. The authors suggested to use the descriptions of the images from users as a backup authentication system. The users were asked to describe the photos on four topics: ocean, desert, sky, and green landscapes. For the attribution of users, their writing styles are determined, which include vocabulary selection, phrasal pauses, word selection, and other features. All descriptions must be at least 200 words long. If the user forgets the account data, the backup authentication system provides another image containing the same thematic data. The new and previous descriptions are presented using a bag-of-words (BOW), after which the feature vectors are compared using the cosine similarity. If the score is above the threshold level, the author of the text will be authenticated. The model based on the support vector machine method was also built. The control experiment demonstrated an accuracy of about 73%.
The article [
18] examines the approaches to determining the authorship of texts in Russian, as well as the advantages and disadvantages of these approaches. The article describes the attribution of texts, the sizes of which vary from 1000 to 100,000 symbols, using the method of support vectors (SVM) and deep neural networks with long short-term memory (LSTM), the convolutional neural networks (CNN), and transformer networks. The results show that all the considered algorithms are suitable for solving the problem of authorship identification, but SVM shows the best accuracy. The average accuracy of the SVM reaches 96%, while the accuracy increases with increasing text size and decreases with an increasing number of authors under consideration (the number of authors in the sample varied from 2 to 50). The high accuracy is due to the carefully selected parameters of the models and the feature space, which includes statistical and semantic features, among them those which are extracted as a result of the aspect analysis. Deep neural networks are inferior to SVM in accuracy and reach only 93%. The experiments show that SVM-based methods are unstable to deliberate text anonymization.
Some authors suggest to use the pre-trained language models for stylometry. The initialization of word vectors is carried out using the Word2vec model, this approach is a popular method of increasing the productivity in the absence of a large training set of texts. The work [
19] describes a series of experiments with convolutional neural networks (CNN) and trained word vectors based on the Word2vec model for sentence-level classification tasks. The vectors have a dimension of 300 and were trained using the continuous bag-of-words architecture. The words missing from the set of pre-trained words were initialized randomly. The authors show that a relatively simple CNN network with a small adjustment of hyperparameters and with the word vectors based on the pre-trained Word2vec model gives excellent results on a number of tests, for example, for tonality analysis tasks. The authors of [
20] used the Doc2vec model from the GENSIM3 library for cross-thematic attribution of articles by 15 authors from
The Guardian newspaper in English. The description of the texts included
n-grams of symbols,
n-grams of words, and
n-grams of tags of parts of speech; in all cases,
n varied from 1 to 5. After the presentation of the training data in the form of
n-grams, Doc2vec was applied to them to obtain a numerical description of the training documents. The Doc2vec model allows to represent the documents in the form of continuous and dense fixed-length feature vectors. This model generates a vector representation at the document level, it is implemented by processing each document as a special word. Thus, the authors of the work describe both the syntax and the semantics of documents, what ensures the high accuracy in attribution tasks. The logistic regression was used as a classifier. The experimental results show that the proposed model is superior to traditional Doc2vec descriptions based on unigrams of words. However, even here the authors of the work note that the greatest accuracy (at least 90%) is achieved on large texts.
A number of works attempt to explore the rhythmic component of texts. Thus, in [
21], the authors propose to use phonological information about the tones and rhymes of the Chinese language, automatically extracted from unannotated texts, for the attribution of authorship. Support vector machines and algorithms based on random forests were used as classifiers. The article [
22] gives the performance evaluation of the ProseRhythmDetector (PRD), the text rhythm analysis tool, for prose texts in English and Russian. The study was conducted on the basis of 50 English and 50 Russian literary texts written over the last two centuries and consisting of approximately 88,000 words each. The PRD tool was developed for the quantitative analysis of rhythm figures containing the repetition in their structure. The paper evaluates the accuracy of the PRD tool when detecting stylistic features describing the repetitions in sentences. The analysis of rhythmic figures helps to identify the idiolects of the authors and to draw conclusions about the uniqueness of their style and language, which is directly related to the problem of linguistic uniqueness and identification of the authors. The authors of the work note that, in this regard, the tool has shown encouraging results. The paper also discusses the typical errors in the operation of the tool, analyzes the controversial cases, and provides the recommendations for the usage of the tool to identify the author and his idiolect.
A number of authors successfully use the various graph representations to describe the texts and to extract from them the attributes of the author’s style and attribution, as well as for annotation and semantics analysis. The graphs are also used to describe the universal dependencies. In [
23,
24], the adjacency graphs are used to analyze the text properties and to extract information about language styles. In the work [
24], the prose literary texts in Polish and English are studied. In the adjacency graphs, the text is represented by a set of words and their word combinations; in this context, a language is understood as a complex system of higher levels that cannot be reduced to the sum of the elements involved, as, for example, the meanings of individual words do not necessarily provide the understanding of the entire sentence. Before building an adjacency network, the text undergoes the preliminary processing: annotation and unnecessary spaces are removed, all letters are converted to lowercase, and punctuation marks are replaced with special symbols so that they are then processed in the same way as words due to the fact that, from the point of view of statistical properties, the punctuation marks are no less valuable than the words, and they are the carriers of information about the language sample. In the adjacency networks, each vertex represents a single word, and the edges indicate whether words in the text occur next to each other. In the weighted version of the network, the weights represent the number of words encountered together. In this work, unlike in [
23], the words are not lemmatized when constructing a network, which allows us to take into account the characteristic forms of words. A number of characteristics are calculated for each network: vertex degrees, shortest path lengths, clustering coefficients, as well as associativity and modularity coefficients. After that, the hierarchical clustering and the ensembles of decision trees are used for the studied properties. The accuracy of attribution of authorship using the described approach exceeded 90%, but it should be noted that the work investigated novels, that is, texts of considerable size.
The paper [
25] describes the attribution method based on convolutional neural networks (CNNs) for symbols and their bigrams, supplemented by numerical characteristics describing the features of discourse, in order to improve the accuracy. The complexity of this approach is explained by the difficulties of constructing an adequate numerical description of the features of the discourse. For this purpose, in this work, the object grid model proposed earlier for the ordering of sentences (also called the entity grid model) was used, allowing the authors to track the grammatical relationships of the main entities. For a more productive description, the grammatical relations in this work are replaced by rhetorical structures (RS), which describe already semantic relations between fragments of sentences. The theory of rhetorical structures (RST) is intended to describe texts; it assumes a set of relations that can be observed in texts: antithesis, background, circumstance, concession, condition, and others. The table of relations is presented, for example, in
https://www.sfu.ca/rst/01intro/intro.html (accessed on 28 January 2022), these relations are asymmetric and are represented by arrows of an oriented graph. The nodes of such a graph are the fragments of sentences denoting the subject (nucleus) and object (satellite) of relations. The description of the discourse structure using RST showed the excellent result and allowed the authors to increase the accuracy to 99% for 250 novels written by 50 authors.
A small number of works are devoted to the stylometry of poetic works. The work [
11] describes the experiments on the analysis of poems to determine the authorship of poetic texts in Czech, German, Spanish, and English. The paper considers the Burrows’ Delta, which is based on a pairwise comparison of the frequencies of frequently occurring words, as well as its modifications: Burrows’ Delta, Argamon’s Quadratic Delta, Smith-Aldridge’s Cosine Delta, and also a classifier based on the Support Vector Machine.
The work [
12] is devoted to comparing the structure of reasoning in the poetic texts of three authors: A.K. Tolstoy (two periods of creativity), K.K. Sluchevsky (two periods of creativity), and I.F. Annensky. The paper presents a logical analogue of rhetorical structures, supplemented by some relations, and demonstrates its usage for the analysis of reasoning, as well as the types of constructions and approaches preferred by the authors to the construction of discourse, and their change over time and independence from the genre were identified.
The most studies in the field of stylometry focus on the quantitative indicators for assessing the quality of models [
8], while the interpretation of the results of the study in most cases remains ignored. The explanation of the decision of the classifiers would make it possible to speak with greater certainty about the features of the author’s style. This work is intended to partially compensate for this disadvantage.
4. Data Preparation and Machine Learning Models
The task is characterized by a small amount of data, which includes a poem by A.S. Pushkin outside the lyceum period. Even taking into account this nuance, the number of poems by A.S. Pushkin in the data set was more than 34%. The poems of the other poets are presented as complete collections from the sites
http://feb-web.ru/ (accessed on 28 January 2022) and
https://rvb.ru/ (accessed on 28 January 2022). The description of the authors and the number of their poems in the dataset are presented in
Table 1. In total, the data set consisted of 1966 poems. The works consisting of less than four lines were excluded from the set, as well as the quatrains with punctuations that are not located at the end of the poem, and with a significant number of foreign words, as this prevented the calculation of metrorhythmic characteristics.
Figure 1a shows the distribution of poems by the number of words (up to 300 words), 85% of such poems in the sample, and
Figure 1b shows the same by the distribution of symbols (up to 1000); such poems in the sample are slightly more than 70%. This avenue of study will allow us to assess the effect of the size of poems on the quality of classification.
Obviously, the small size of the verse limits the possibility of its accurate numerical description and makes the classification difficult, so an additional data set was built which included only poems consisting of at least 16 lines, assuming that such a data set would show better classification accuracy; the description of this set is presented in
Table 2, and A. S. Pushkin’s poems make up 27% of it. This set consists of only 1162 poems.
To describe the structure of the sentences, the universal dependencies were used, which were extracted using the UDpipe2 package
https://ufal.mff.cuni.cz/udpipe/2 (accessed on 28 January 2022), accessible via REST IP. Universal Dependencies (UD) is a structure for the graphical representation (agreed annotation) of grammar, including a description of parts of speech, morphological features, and syntactic dependencies, in different natural languages [
26]. The dependency is a binary asymmetric relation, which is represented in diagrams by an arrow from the main to the dependent word, also to the main word of the dependent expression, if it itself is a multiword element. The sentences are represented as trees whose edges are relations, with the predicate root as the root. The dependencies are described using grammatical relationship labels.
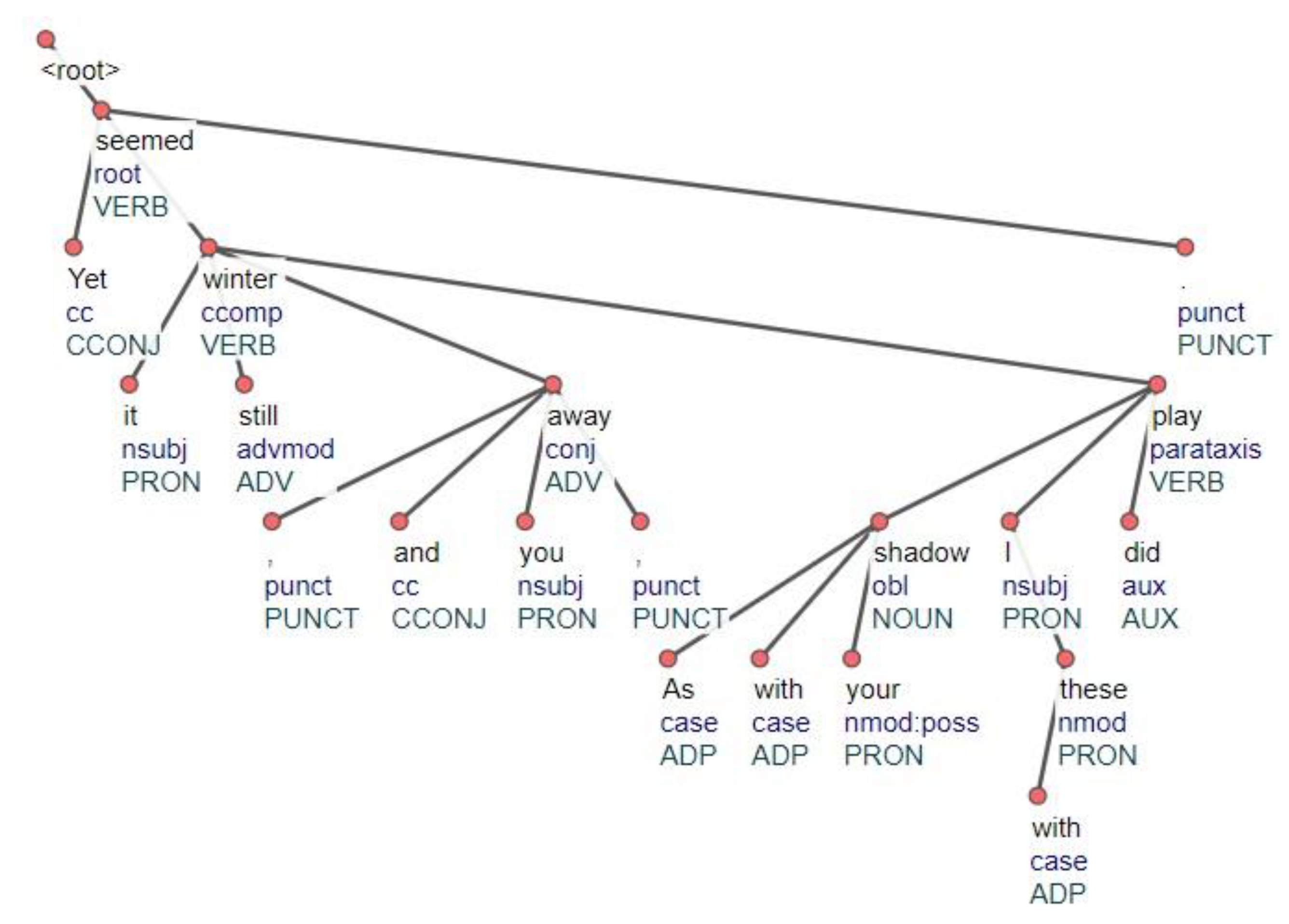
Figure 2 shows the parsing tree for the last sentence of Shakespeare’s sonnet 98, obtained using the english-ewt-ud-2.6-200830 model of the UDpipe2 package. In this Figure, the relationships are signed with blue words in lowercase, and the parts of speech are green in uppercase. The root node is the main word of the phrase; it is usually a predicate and is represented by a verb, but it can also be an adjective, an adverb, etc. The display of grammatical relations between words is a distinctive feature of UD. In our work, the model russian-gsd-ud-2.6-200830 for the Russian language was used, words in initial forms, parts of speech, and relations were extracted.
The TF-IDF (TF—term frequency, IDF—inverse document frequency) text model was used to obtain the “features-objects” matrix. The ensemble methods based on decision trees used for the classification include extra-trees classifier (ET), random forest classifier (RF), AdaBoost classifier (AB), gradient boosting for classification (GB), CatBoost classifier (CB), multi-layer perceptron classifier (MLP), the support vector classification (SVC), and logistic regression classifier (RF). The result tables show only the best results. The list of methods and classes implementing them are presented in
Table 3. At the first stage, the classification by groups of features was performed separately for each group, then a conclusion was given about the effectiveness of the group. At the second stage, the most effective groups of features were combined, and the classification was carried out according to several groups of features. The task of the second stage was to build the most accurate classification, as well as to identify specific features that most determine the author’s style.
All the given estimates are calculated on the basis of cross-validation for five blocks with the stratification by the answers. The part of the test sample is 25%. The tables show the maximum numbers of features, as well as the significances of the features which are obtained for the entire data set as a whole. It should be noted that at the stages of cross-validation, the smaller quantity of features is possible when classifying by words, service words, and also to a lesser extent by letters and symbols.
6. The Combining of the Groups of Features
After the evaluation of different groups of features, the various combinations of groups were constructed, according to the classification that was carried out. The neural networks gave the best results, so the results are given only for this model. As a result of the selection of hyperparameters, two neural networks were built with two hidden layers in each, trained according to Adam’s algorithm. The results of the cross-validation are presented in
Table 10. The combination of parameters allows us to achieve a better result than for any individual group, but it should be noted that the improvement in the characteristics of the final model in comparison with the classification by symbols and their n-grams is quite small. The group of letters and their n-grams were included in the final set in two versions: 2 and 3 g, as well as 2, 3, and 4 g. Additionally, although the second option gives a little more accuracy, but it requires significantly more computing resources. In all cases, there is a greater value of completeness (about 0.9) and a lower value of accuracy. For a data set with poems with volume from 16 lines, it was not possible to obtain a significant increase in accuracy, the maximum AUC ROC on this set was 0.9240. As a result of the conducted research, the neural network was built that describes the stylistic features of A.S. Pushkin.
The diagram 5 describing the importance of features for classification into the groups of features using the Shapley method is shown in
Figure 5, the features are supplemented with the prefixes indicating their belonging to groups: punct_—punctuation frequencies, turn_—proportions of relations, metrorhysthm_—metrorhythmic features, letter_—features by n-grams of symbols, and lemma_—features by words in the initial form. In the names of features by n-grams of characters, the spaces are still replaced by underscores, so if there are two underscores after the name of the letter_ group, then the second of them indicates a space in the n-gram. The same applies to the underscores at the end of features in the letter_ group. It is interesting to note that among the first 30 significant features, there are only two features according to words, which concerns the prepositions
в and
с. The main features are still the features describing the authors’ preferences in punctuation marks, according to which Pushkin, unlike other authors, preferred the usage of dots and ellipses rather than exclamation marks, which distinguish the other authors. Considering the result by the words, according to which Pushkin was also not inclined to use the interjection
ах, it can be noted that other poets of the Pushkin era were much more emotional and wrote with a more pronounced enthusiastic syllable. When the important features which describe the relations are analyzed, it should be noted that the statement that the widespread usage of functional words is not characteristic of Pushkin’s work is confirmed here by the values of the features turn_case, as well as lemma_в, lemma_с, and letter__к_.
The case relation is a relation of case and is used for any case marking element represented by a single word; in Russian such relations connect words with prepositions. The large values of the turn_amod feature indicate the usage of modifier relations which was characteristic of A. S. Pushkin, when such relations are used the meaning of a noun or pronoun is supplemented by an adjective located both before and after the noun or pronoun to which it refers. Pushkin’s commitment to the usage of adjectives was also noted when classifying by words. The features describing Pushkin’s preferences in the usage of endings and letter combinations, noted when describing the classification by n-grams of characters, are also present among the important features in the final classification. The meter is also included in the set of significant features; it is represented in green on the diagram because it is categorical, not numerical data, and therefore their numerical values cannot be displayed on the diagram.
In the main data set, the poetic works of A.S. Pushkin, written since 1823, were used. To test the constructed model, retrained on the entire data set, 50 poems by A. S. Pushkin, written in 1821 and 1822, as well as 46 poems by D. V. Venevitinov, were used. As a result, all of Pushkin’s poems were classified correctly, but 13 of Venevitinov’s poems were attributed to Pushkin. Thus, the F1 measure for the validation sample was 0.8849.
For the model trained on poems of at least 16 lines, all 26 of Pushkin’s poems of at least 16 lines were classified correctly, and 7 of Venevitinov’s 39 poems were incorrectly classified. Thus, this model shows greater accuracy, but less completeness, that is, in some cases it can attribute poems by other poets to Pushkin, but the ownership of poems by Pushkin determines almost certainly.
7. Conclusions
In this paper, the importance of groups of features of poetic texts for determining the author’s style was evaluated. The most effective classification according to the considered groups of features was obtained by 2, 3, and 4 g of symbols; the classification only by letters and spaces loses to the classification by symbols by accuracy. In the next place is the classification by words. All the listed classifications showed the AUC ROC more than 0.8, but at the same time the number of classification features in them was in the thousands and tens of thousands. Next in quality was the group of punctuation marks, in which there are only 11 features. It should be noted that the punctuation marks largely reflect the emotional coloring of a poetic work. This fact is also confirmed by the quality of classification by punctuation marks, but to a greater extent by the fact that the punctuation marks (often with spaces surrounding them) have become the most important features of classification by symbols, which is described in the corresponding section.
The lowest quality was demonstrated by the classifications based on relations and metrorhythmic features. It should be noted that the distribution of relations does not fully characterize the peculiar properties of sentences; the author’s preference for certain language constructions does not reflect the changes in the order of words characteristic of poetic works, what is certainly important for describing the author’s style. Our attempts to build the classification features based on the analysis of sentence parsing trees have not yet brought interesting results, but this topic is extremely interesting, and the work in this direction will be continued.
The best of the constructed classifications included all the selected groups of features: 2, 3, and 4 g of symbols, words, punctuation marks, relations, and metrorhythmic features, while it is obvious that there are non-empty pairwise intersections of features in these groups.
In the future, a similar study of stylometric indicators with the usage of phonetic features and also the building of classification models by the authors on the basis of pre-trained models of vector representations of words and texts Word2Vec, Text2Vec, FastText, and neural networks based on the transformers BERT and XLM are planned.
The investigation described in this work will be included in the already existing system of the analysis of poetic texts and will correspond to the general requirements for a system formed with the requirements of philologists (potential users of the system). A separate article is devoted to this question [
27].










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}