
Relational Graph Convolutional Network for Text-Mining-Based Accident Causal Classification


Abstract
:1. Introduction
- A text-mining-based accident causal classification method based on a R-GCN and pre-trained BERT is proposed.
- The pre-trained BERT was adopted to avoid preprocessing in traditional text mining and ensure efficient text feature extraction.
- The R-GCN was utilized to avoid the expensive retraining of BERT and enable classification of accident investigation reports.
- To eliminate prediction errors that may be caused by domain GAP when embedding text features based on BERT, a gate mechanism was introduced into the R-GCN architecture.
- The proposed method gets rid of preprocessing such as tokenization and stop word removal and can quickly classify accident causes without relying on expert experience.
2. Methodology
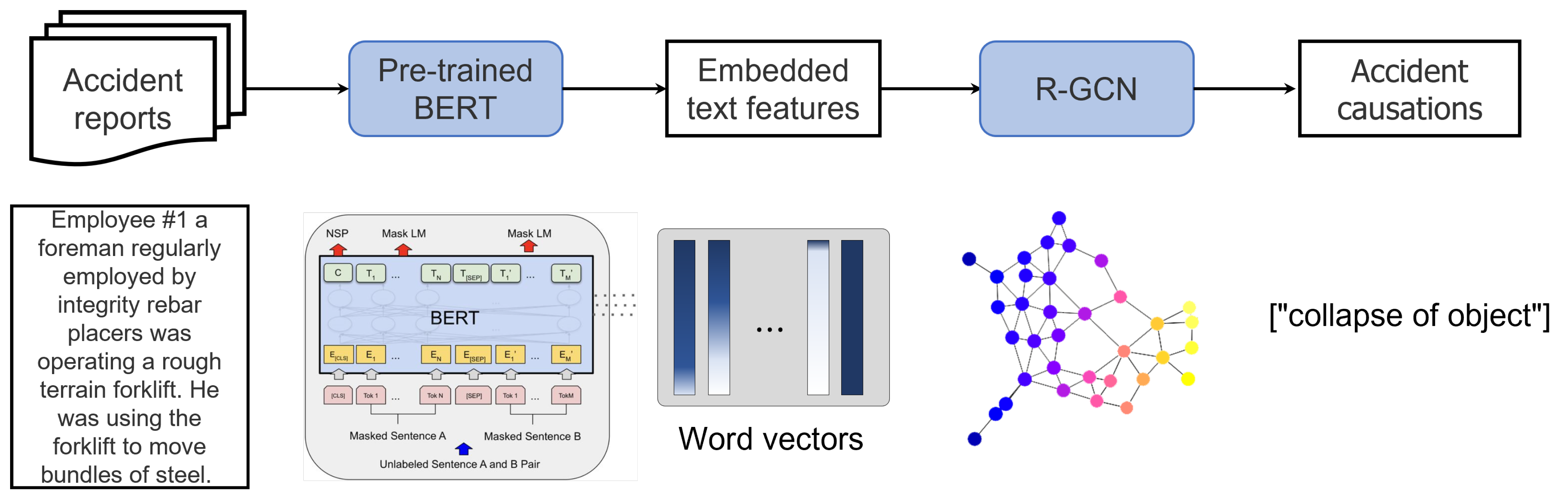
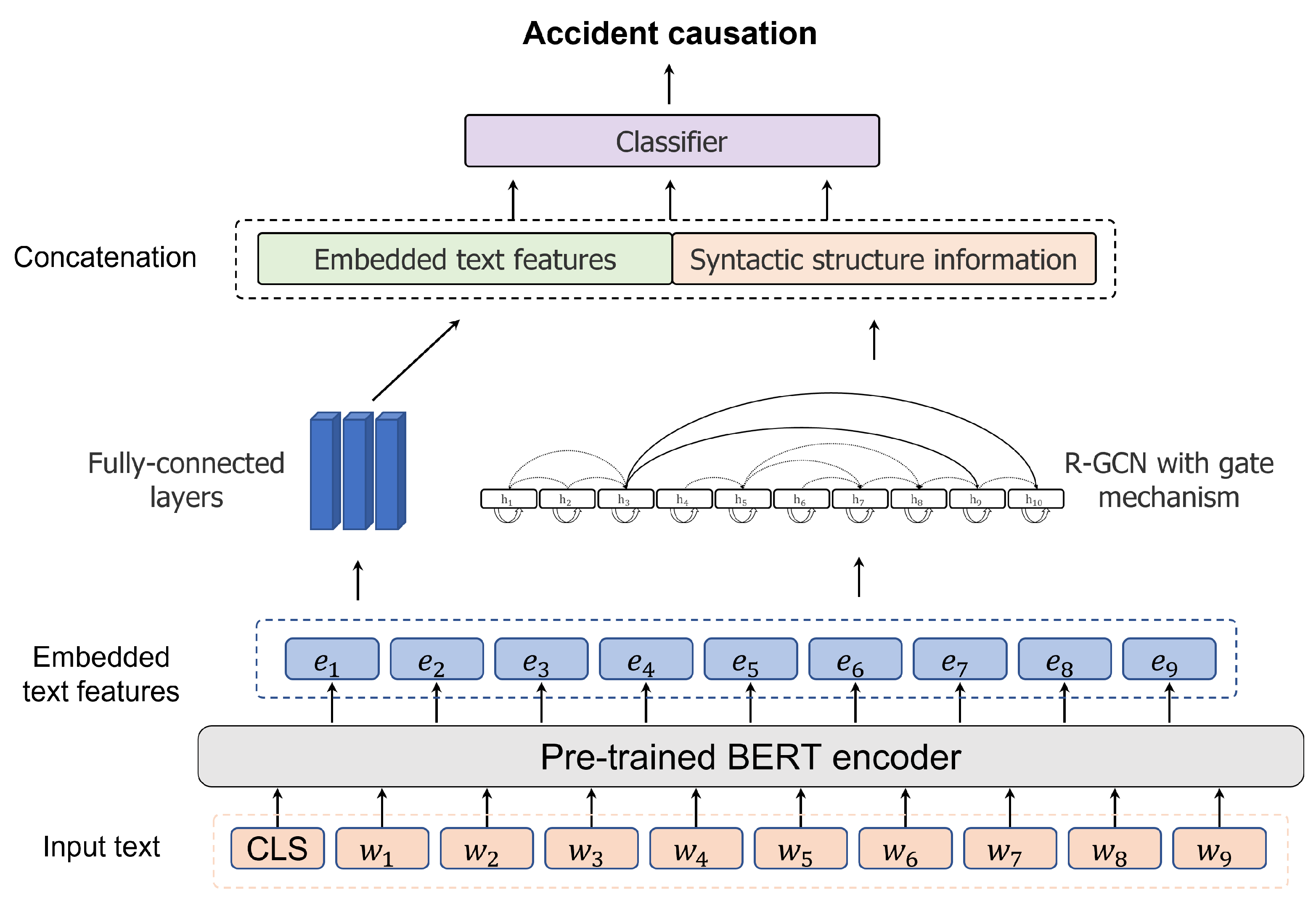
2.1. Overall Scheme of the Proposed Method
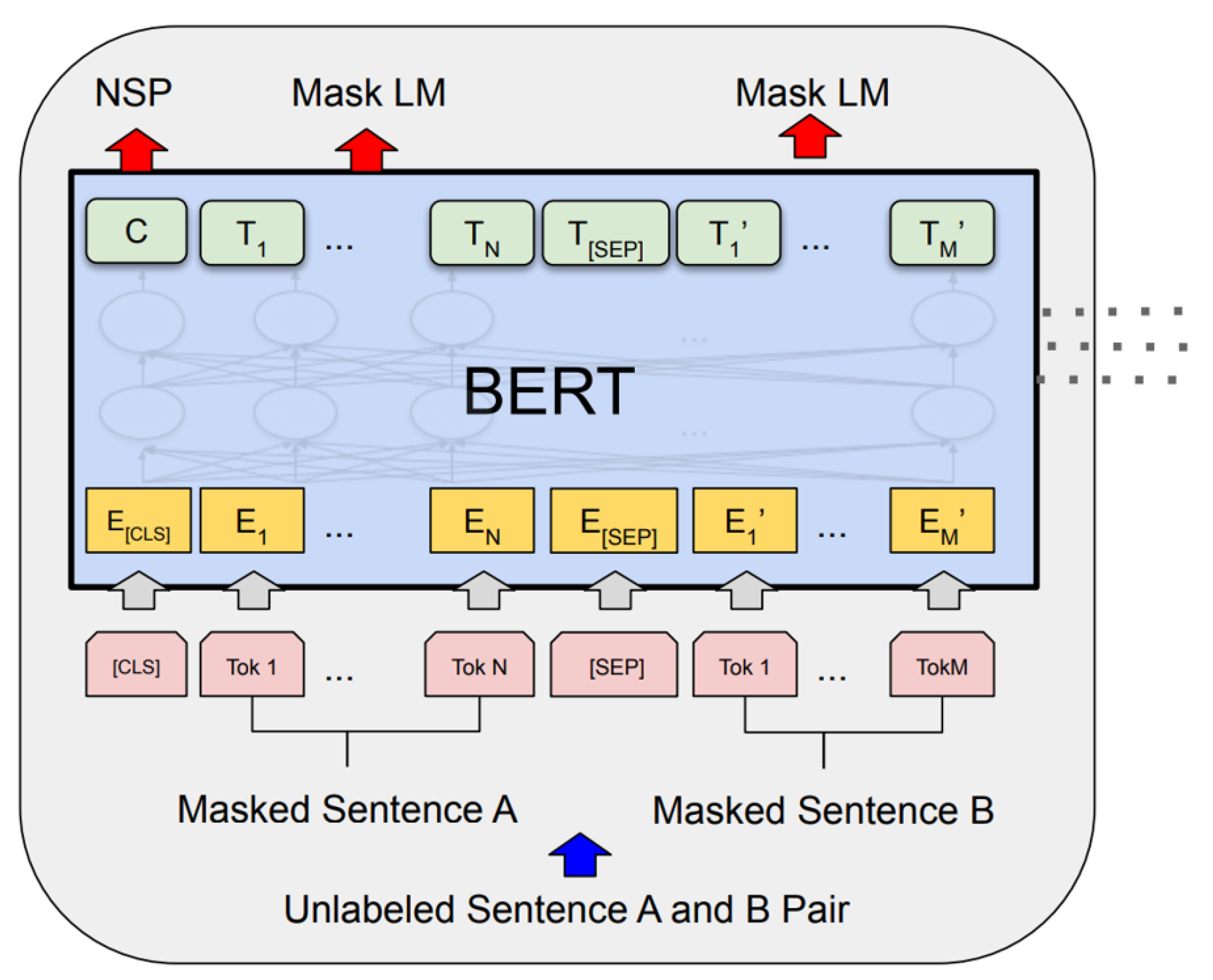
2.2. Pre-Trained BERT
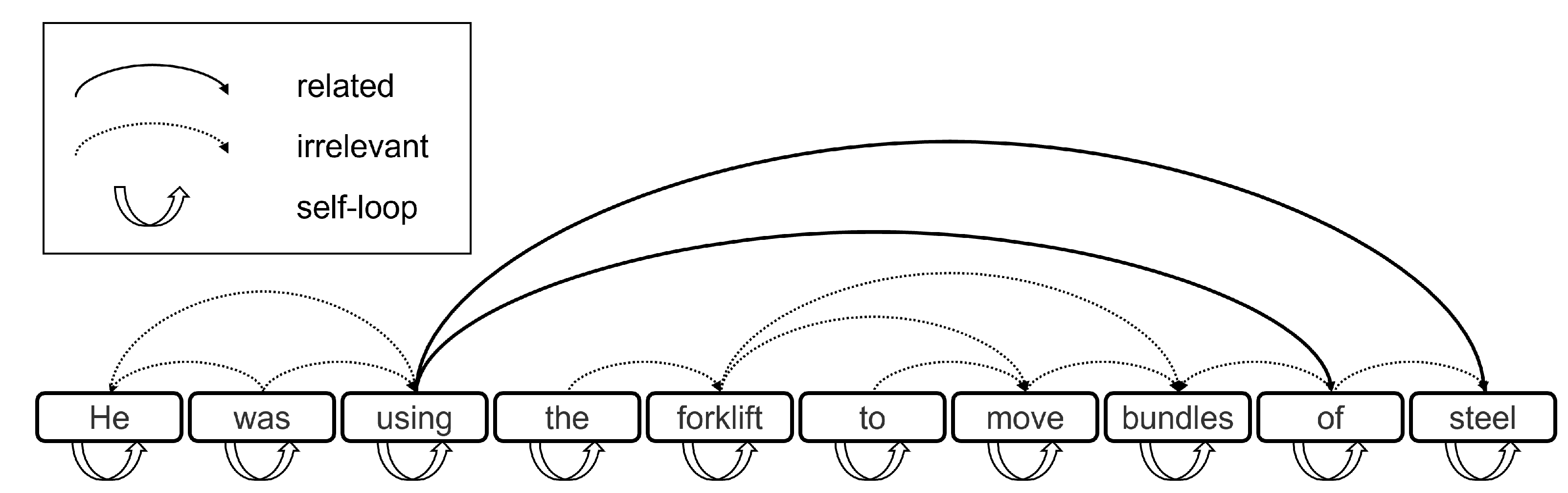
2.3. R-GCN
2.4. Pre-Trained BERT Combined with R-GCN
3. Experimental Details
3.1. Dataset and Pre-Trained Model
3.2. Training Settings
3.3. Evaluation Metrics
3.4. Experimental Platforms
4. Experimental Results
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Williams, H.; Edwards, A.; Hibbert, P.; Rees, P.; Evans, H.P.; Panesar, S.; Carter, B.; Parry, G.; Makeham, M.; Jones, A.; et al. Harms from discharge to primary care: Mixed methods analysis of incident reports. Br. J. Gen. Pract. 2015, 65, e829–e837. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Reason, J. Managing the Risks of Organizational Accidents; Routledge: London, UK, 2016. [Google Scholar]
- Nixon, J.; Braithwaite, G.R. What do aircraft accident investigators do and what makes them good at it? Developing a competency framework for investigators using grounded theory. Saf. Sci. 2018, 103, 153–161. [Google Scholar] [CrossRef]
- Jiao, Z.; Lei, H.; Zong, H.; Cai, Y.; Zhong, Z. Potential Escalator-related Injury Identification and Prevention Based on Multi-module Integrated System for Public Health. arXiv 2021, arXiv:2103.07620. [Google Scholar] [CrossRef]
- Kahfie, I.; Ramadan, M.; Rafi, S.; Perawati, D. The Crash Of Boeing 737 Max 8 And It’s Effect On Costumer Trust: Case On Lion Air Passenger. Adv. Transp. Logist. Res. 2019, 2, 764–769. [Google Scholar]
- Johnston, P.; Harris, R. The Boeing 737 MAX saga: Lessons for software organizations. Softw. Qual. Prof. 2019, 21, 4–12. [Google Scholar]
- Zhang, J.; Wan, C.; He, A.; Zhang, D.; Soares, C.G. A two-stage black-spot identification model for inland waterway transportation. Reliab. Eng. Syst. Saf. 2021, 213, 107677. [Google Scholar] [CrossRef]
- Topuz, K.; Delen, D. A probabilistic Bayesian inference model to investigate injury severity in automobile crashes. Decis. Support Syst. 2021, 150, 113557. [Google Scholar] [CrossRef]
- Goh, Y.M.; Ubeynarayana, C. Construction accident narrative classification: An evaluation of text mining techniques. Accid. Anal. Prev. 2017, 108, 122–130. [Google Scholar] [CrossRef] [PubMed]
- Hotho, A.; Nürnberger, A.; Paaß, G. A brief survey of text mining. In Ldv Forum; Citeseer: Princeton, NJ, USA, 2005; Volume 20, pp. 19–62. [Google Scholar]
- Jiao, Z.; Jia, G.; Cai, Y. A new approach to oil spill detection that combines deep learning with unmanned aerial vehicles. Comput. Ind. Eng. 2019, 135, 1300–1311. [Google Scholar] [CrossRef]
- Cai, Y.; Li, B.; Jiao, Z.; Li, H.; Zeng, X.; Wang, X. Monocular 3D object detection with decoupled structured polygon estimation and height-guided depth estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 10478–10485. [Google Scholar]
- Cai, Y.; Chen, X.; Zhang, C.; Lin, K.Y.; Wang, X.; Li, H. Semantic Scene Completion via Integrating Instances and Scene in-the-Loop. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 324–333. [Google Scholar]
- Baclic, O.; Tunis, M.; Young, K.; Doan, C.; Swerdfeger, H.; Schonfeld, J. Artificial intelligence in public health: Challenges and opportunities for public health made possible by advances in natural language processing. Can. Commun. Dis. Rep. 2020, 46, 161. [Google Scholar] [CrossRef]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- ZHANG, Y.k.; LI, H.j. Text classification of accident news based on category keyword. J. Comput. Appl. 2008, 28, 139–140. [Google Scholar]
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. (CSUR) 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Kwok, J.T.Y. Automated text categorization using support vector machine. In Proceedings of the International Conference on Neural Information Processing (ICONIP), Kitakyushu, Japan, 21–23 October 1998; Citeseer: Princeton, NJ, USA, 1998. [Google Scholar]
- Caropreso, M.F.; Matwin, S.; Sebastiani, F. Statistical phrases in automated text categorization. Cent. Natl. Rech. Sci. 2000, 47, 1–18. [Google Scholar]
- Zhang, F. A hybrid structured deep neural network with Word2Vec for construction accident causes classification. Int. J. Constr. Manag. 2019, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Brown, D.E. Text mining the contributors to rail accidents. IEEE Trans. Intell. Transp. Syst. 2015, 17, 346–355. [Google Scholar] [CrossRef]
- Zhong, B.; Pan, X.; Love, P.E.; Sun, J.; Tao, C. Hazard analysis: A deep learning and text mining framework for accident prevention. Adv. Eng. Inform. 2020, 46, 101152. [Google Scholar] [CrossRef]
- Soltanzadeh, A.; Mohammadfam, I.; Mahmoudi, S.; Savareh, B.A.; Arani, A.M. Analysis and forecasting the severity of construction accidents using artificial neural network. Saf. Promot. Inj. Prev. 2016, 4, 185–192. [Google Scholar]
- Paul, D.B. Experience with a stack decoder-based hmm csr and back-off n-gram language models. In Proceedings of the Workshop Speech and Natural Language, Pacific Grove, CA, USA, 19–22 February 1991. [Google Scholar]
- Ubeynarayana, C.; Goh, Y. An Ensemble Approach for Classification of Accident Narratives. In Computing in Civil Engineering 2017; The American Society of Civil Engineers: Reston, VA, USA, 2017; pp. 409–416. [Google Scholar]
- Zhang, F.; Fleyeh, H.; Wang, X.; Lu, M. Construction site accident analysis using text mining and natural language processing techniques. Autom. Constr. 2019, 99, 238–248. [Google Scholar] [CrossRef]
- Chen, L.; Vallmuur, K.; Nayak, R. Injury narrative text classification using factorization model. BMC Med. Inform. Decis. Mak. 2015, 15, S5. [Google Scholar] [CrossRef] [Green Version]
- Heidarysafa, M.; Kowsari, K.; Barnes, L.; Brown, D. Analysis of Railway Accidents’ Narratives Using Deep Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1446–1453. [Google Scholar]
- Cheng, X.; Khomtchouk, B.; Matloff, N.; Mohanty, P. Polynomial regression as an alternative to neural nets. arXiv 2018, arXiv:1806.06850. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, L.K. Bert: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Rajput, A. Natural language processing, sentiment analysis, and clinical analytics. In Innovation in Health Informatics; Elsevier: Amsterdam, The Netherlands, 2020; pp. 79–97. [Google Scholar]
- Xiong, G.; Zhang, J.; Yuan, X.; Shi, D.; He, Y. Application of symbiotic organisms search algorithm for parameter extraction of solar cell models. Appl. Sci. 2018, 8, 2155. [Google Scholar] [CrossRef] [Green Version]
- Karatzoglou, A.; Jablonski, A.; Beigl, M. A Seq2Seq learning approach for modeling semantic trajectories and predicting the next location. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 6–9 November 2018; pp. 528–531. [Google Scholar]
- Zulqarnain, M.; Ghazali, R.; Ghouse, M.G.; Mushtaq, M.F. Efficient processing of GRU based on word embedding for text classification. JOIV Int. J. Inform. Vis. 2019, 3, 377–383. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2017; pp. 5998–6008. [Google Scholar]
- Vasantharajan, C.; Thayasivam, U. Towards Offensive Language Identification for Tamil Code-Mixed YouTube Comments and Posts. SN Comput. Sci. 2022, 3, 1–13. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Jiao, Z.; Jia, G.; Cai, Y. Ensuring Computers Understand Manual Operations in Production: Deep-Learning-Based Action Recognition in Industrial Workflows. Appl. Sci. 2020, 10, 966. [Google Scholar] [CrossRef] [Green Version]
- Lin, Y.; Meng, Y.; Sun, X.; Han, Q.; Kuang, K.; Li, J.; Wu, F. BertGCN: Transductive Text Classification by Combining GCN and BERT. arXiv 2021, arXiv:2105.05727. [Google Scholar]
- Cao, R.; Chen, L.; Chen, Z.; Zhao, Y.; Zhu, S.; Yu, K. LGESQL: Line Graph Enhanced Text-to-SQL Model with Mixed Local and Non-Local Relations. arXiv 2021, arXiv:2106.01093. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Berg, R.V.D.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the European Semantic Web Conference, Heraklion, Greece, 3–7 June 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]
- Xu, Y.; Yang, J. Look again at the syntax: Relational graph convolutional network for gendered ambiguous pronoun resolution. arXiv 2019, arXiv:1905.08868. [Google Scholar]
- Ryu, S.; Lim, J.; Hong, S.H.; Kim, W.Y. Deeply learning molecular structure-property relationships using attention-and gate-augmented graph convolutional network. arXiv 2018, arXiv:1805.10988. [Google Scholar]
- Du, C.; Wang, J.; Sun, H.; Qi, Q.; Liao, J. Syntax-type-aware graph convolutional networks for natural language understanding. Appl. Soft Comput. 2021, 102, 107080. [Google Scholar] [CrossRef]
- Marcheggiani, D.; Titov, I. Encoding sentences with graph convolutional networks for semantic role labeling. arXiv 2017, arXiv:1703.04826. [Google Scholar]
- Li, Q.; Han, Z.; Wu, X.M. Deeper insights into graph convolutional networks for semi-supervised learning. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Occupational Safety and Health Administration. Fatality and Catastrophe Investigation Summaries; Occupational Safety and Health Administration: Washington, DC, USA, 2016. [Google Scholar]
- Cheng, M.Y.; Kusoemo, D.; Gosno, R.A. Text mining-based construction site accident classification using hybrid supervised machine learning. Autom. Constr. 2020, 118, 103265. [Google Scholar] [CrossRef]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S.R. GLUE: A multi-task benchmark and analysis platform for natural language understanding. arXiv 2018, arXiv:1804.07461. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Cause | Labeled Number |
|---|---|---|
| 1 | Traffic | 63 |
| 2 | Collapse of object | 212 |
| 3 | Falls | 236 |
| 4 | Caught in/between objects | 68 |
| 5 | Struck by moving objects | 134 |
| 6 | Others | 43 |
| 7 | Exposure to chemical substance | 29 |
| 8 | Fires and explosion | 47 |
| 9 | Electrocution | 108 |
| 10 | Struck by falling object | 43 |
| 11 | Exposure to extreme temperatures | 17 |
| Fold 1 | Fold 2 | Fold 3 | Fold 4 | Fold 5 | |
|---|---|---|---|---|---|
| AvgF1-score | 0.69 | 0.64 | 0.72 | 0.77 | 0.75 |
| Prediction | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Ground truth | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | Total | TP | FN | Recall | ||
| 1 | 9 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 12 | 9 | 3 | 0.75 | ||
| 2 | 0 | 34 | 0 | 1 | 4 | 0 | 1 | 0 | 0 | 0 | 0 | 40 | 34 | 6 | 0.85 | ||
| 3 | 1 | 0 | 39 | 0 | 0 | 0 | 1 | 0 | 0 | 8 | 1 | 50 | 39 | 11 | 0.78 | ||
| 4 | 0 | 0 | 1 | 12 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 15 | 12 | 3 | 0.80 | ||
| 5 | 0 | 2 | 0 | 0 | 19 | 0 | 0 | 0 | 0 | 2 | 0 | 23 | 19 | 4 | 0.83 | ||
| 6 | 0 | 1 | 0 | 2 | 0 | 3 | 0 | 1 | 1 | 1 | 0 | 9 | 3 | 6 | 0.33 | ||
| 7 | 0 | 1 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 6 | 5 | 1 | 0.83 | ||
| 8 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 2 | 10 | 7 | 3 | 0.70 | ||
| 9 | 0 | 0 | 0 | 0 | 2 | 2 | 2 | 0 | 15 | 0 | 0 | 21 | 15 | 6 | 0.71 | ||
| 10 | 0 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 0 | 10 | 6 | 4 | 0.60 | ||
| 11 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 4 | 3 | 1 | 0.75 | ||
| Total | 10 | 39 | 45 | 16 | 27 | 5 | 9 | 9 | 16 | 18 | 6 | 200 | |||||
| TP | 9 | 34 | 39 | 12 | 19 | 3 | 5 | 7 | 15 | 6 | 3 | ||||||
| FP | 1 | 5 | 6 | 4 | 8 | 2 | 4 | 2 | 1 | 12 | 3 | ||||||
| Precision | 0.90 | 0.87 | 0.87 | 0.75 | 0.70 | 0.60 | 0.56 | 0.78 | 0.94 | 0.33 | 0.50 | ||||||
| Precision | Recall | F1-Score | Number of Cases | AvgF1-Score | |
|---|---|---|---|---|---|
| 1 | 0.90 | 0.75 | 0.82 | 12 | 0.77 |
| 2 | 0.87 | 0.85 | 0.86 | 40 | |
| 3 | 0.87 | 0.78 | 0.82 | 50 | |
| 4 | 0.75 | 0.80 | 0.77 | 15 | |
| 5 | 0.70 | 0.83 | 0.76 | 23 | |
| 6 | 0.60 | 0.33 | 0.43 | 9 | |
| 7 | 0.56 | 0.83 | 0.67 | 6 | |
| 8 | 0.78 | 0.70 | 0.74 | 10 | |
| 9 | 0.94 | 0.71 | 0.81 | 21 | |
| 10 | 0.33 | 0.60 | 0.43 | 10 | |
| 11 | 0.50 | 0.75 | 0.60 | 4 |
| Average Precision | Average Recall | AvgF1-Score | |
|---|---|---|---|
| Decision trees | 0.48 | 0.55 | 0.51 |
| KNN | 0.49 | 0.52 | 0.50 |
| Naive Bayes | 0.57 | 0.54 | 0.55 |
| Logistic regression | 0.47 | 0.87 | 0.61 |
| LSTM | 0.58 | 0.64 | 0.61 |
| GRU | 0.70 | 0.61 | 0.65 |
| SGRU | 0.73 | 0.69 | 0.71 |
| Ours w/o gate mechanism | 0.74 | 0.72 | 0.73 |
| Ours | 0.79 | 0.76 | 0.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Huang, K.; Wu, L.; Zhong, Z.; Jiao, Z. Relational Graph Convolutional Network for Text-Mining-Based Accident Causal Classification. Appl. Sci. 2022, 12, 2482. https://doi.org/10.3390/app12052482
Chen Z, Huang K, Wu L, Zhong Z, Jiao Z. Relational Graph Convolutional Network for Text-Mining-Based Accident Causal Classification. Applied Sciences. 2022; 12(5):2482. https://doi.org/10.3390/app12052482
Chicago/Turabian StyleChen, Zaili, Kai Huang, Li Wu, Zhenyu Zhong, and Zeyu Jiao. 2022. "Relational Graph Convolutional Network for Text-Mining-Based Accident Causal Classification" Applied Sciences 12, no. 5: 2482. https://doi.org/10.3390/app12052482