
A Novel Pathological Voice Identification Technique through Simulated Cochlear Implant Processing Systems



Abstract
:1. Introduction
- It develops a novel, non-invasive pathological voice detection algorithm based on speech signal processing that mimics the biological process of speech perception and a deep learning approach.
- It extracts audio information using gammatone filters and conventional bandpass filters to examine their efficacy for pathological voice identification.
- It eliminates the necessity of choosing the suitable features from speech samples to aid the classification mechanism.
- It achieves a reasonably high classification accuracy without overwhelming the computation burden on the system.
- It provides a detailed performance analysis of the proposed system in terms of accuracy, precision, recall, NPV, and F1 score.
- It compares the performances of the proposed system with other related works to demonstrate its effectiveness.
2. Related Works
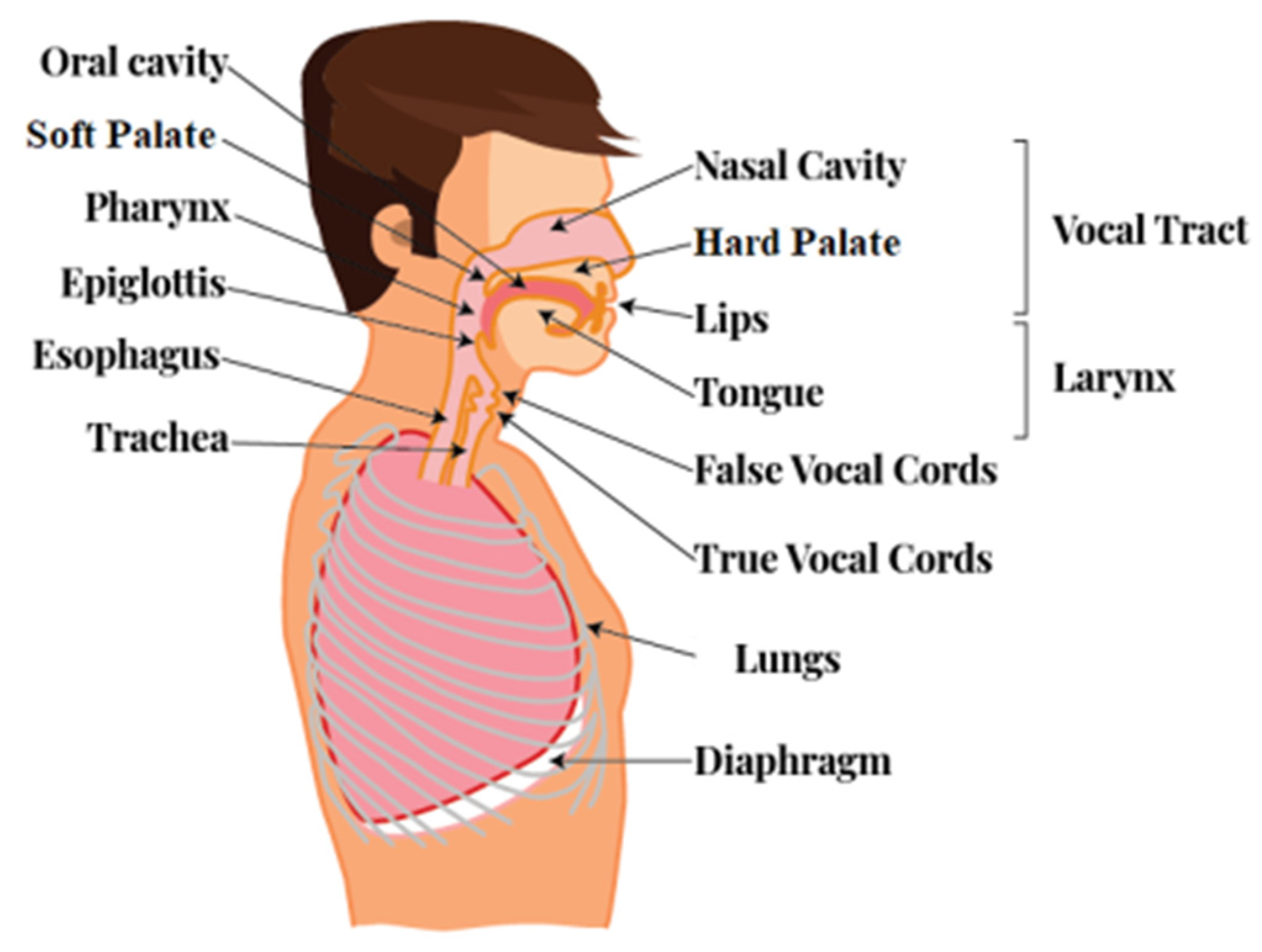
3. Materials and Methods
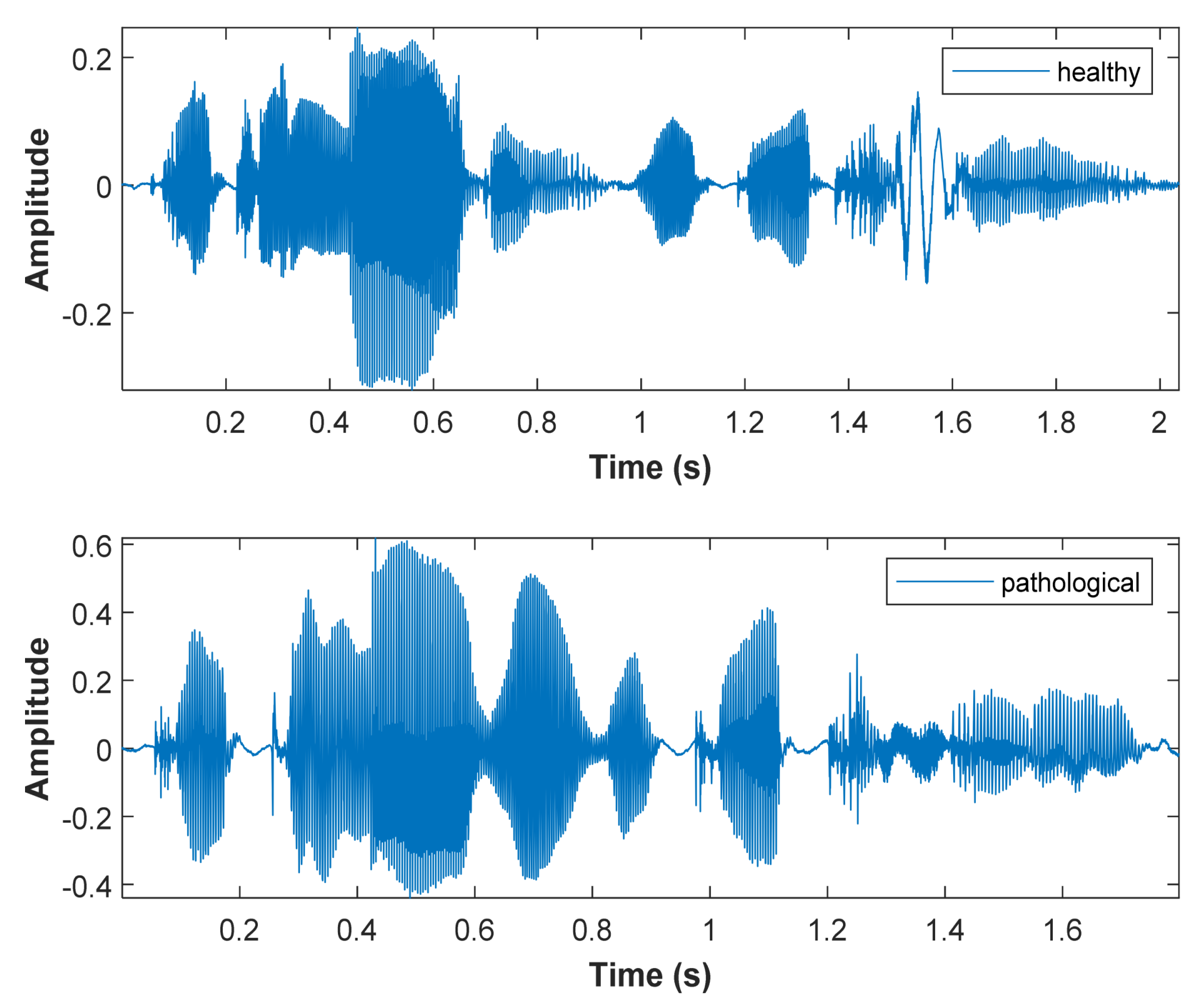
4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A
Appendix B

References
- Rabiner, L.R.; Schafer, R.W. Hearing, Auditory, and Speech Perception. In Theory and Applications of Digital Speech Processing, 1st ed.; Prentice-Hall: Upper Saddle River, NJ, USA, 2011; pp. 138–145. [Google Scholar]
- Quateri, T.E. Production and Classification of Speech Sounds. In Discrete-Time Speech Signal Processing: Principles and Practices; Prentice-Hall: Upper Saddle River, NJ, USA, 2001; pp. 72–76. [Google Scholar]
- Chittka, L.; Brockmann, A. Perception Space—The Final Frontier. PLoS Biol. 2015, 3, 564–568. [Google Scholar] [CrossRef] [Green Version]
- Reich, R.D. Instrument Identification through a Simulated Cochlear Implant Processing System. Master’s Thesis, Department of Media Arts and Sciences, Massachusetts Institute of Technology, Cambridge, MA, USA, September 2002. Available online: https://dspace.mit.edu/handle/1721.1/62373 (accessed on 13 December 2021).
- Islam, R.; Tarique, M.; Abdel-Raheem, E.A. Survey on Signal Processing Based Pathological Voice Detection Techniques. IEEE Access 2020, 8, 66749–66776. [Google Scholar] [CrossRef]
- Martins, R.H.G.; Amaral, H.A.; Tavares, E.L.M.; GarciaMartins, M.; Gonçalves, T.M.; Dias, N.H. Voice disorders: Etiology and diagnosis. J. Voice 2016, 30, 761.e1–761.e9. [Google Scholar] [CrossRef] [Green Version]
- The Voice Diagnostic: Initial Considerations, Case History, and Perceptual Evaluation. Available online: https://entokey.com/ (accessed on 13 December 2021).
- Voice Disorders. Available online: https://www.asha.org/practice-portal/clinical-topics/voice-disorders/ (accessed on 13 December 2021).
- Wood, J.M.; Athanasiadis, T.; Allen, J. Laryngitis. BMJ 2015, 349, g5827. [Google Scholar] [CrossRef]
- Kahrilas, P.J.; Shaeen, N.J.; Vaezi, M.F. American Gastroenterological Association Institute technical review on the management of gastroesophageal reflux disease. Gastroenterology 2008, 135, 1392–1413. [Google Scholar] [CrossRef]
- Collins, S.R. Direct and Indirect Laryngoscopy: Equipment and Techniques. Respir. Care 2014, 59, 850–864. [Google Scholar] [CrossRef] [Green Version]
- Mehta, D.D.; Hillman, R.E. Current role of stroboscopy in laryngeal imaging. Curr. Opin. Otolaryngol.-Head Neck Surg. 2012, 20, 429–436. [Google Scholar] [CrossRef] [Green Version]
- Heman-Ackah, Y.D.; Mandel, S.; Manon-Espaillat, R.; Abaza, M.M.; Sataloff, R.T. Laryngeal electromyography. Otolaryngol. Clin. N. Am. 2007, 40, 1003–1023. [Google Scholar] [CrossRef]
- Al-Nasheri, A.; Muhammad, G.; Alsulaiman, M.; Ali, Z.; Malki, K.H.; Mesallam, T.A.; Ibrahim, M.F. Voice Pathology Detection and Classification using Auto-correlation and entropy features in Different Frequency. IEEE Access 2017, 6, 6961–6974. [Google Scholar] [CrossRef]
- Taib, D.; Tarique, M.; Islam, R. Voice Features Analysis for Early Detection of Voice Disability in Children. In Proceedings of the IEEE International Symposium on Signal Processing and Information Technology, Louisville, KY, USA, 6–8 December 2019; pp. 12–17. [Google Scholar] [CrossRef]
- Hegde, S.; Shetty, S.; Rai, S.; Dodderi, T. A Survey on Machine Learning Approaches for Automatic Detection of Voice Disorder. J. Voice 2019, 33, 947.E11–947.E33. [Google Scholar] [CrossRef]
- Islam, R.; Tarique, M. Classifier Based Early Detection of Pathological Voice. In Proceedings of the International Symposium on Signal Processing and Information Technology, Ajman, United Arab Emirates, 10–12 December 2019. [Google Scholar] [CrossRef]
- Islam, R.; Abdel-Raheem, E.; Tarique, M. A study of using cough sounds and deep neural networks for the early detection of COVID-19. Biomed. Eng. Adv. 2022, 3, 100025. [Google Scholar] [CrossRef]
- Alhussein, M.; Muhammad, G. Voice Pathology Detection Using Deep Learning on Mobile Healthcare Framework. IEEE Access 2018, 6, 41034–41041. [Google Scholar] [CrossRef]
- Narendra, N.P.; Alku, P. Glottal Source Information for Pathological Voice Detection. IEEE Access 2020, 8, 67745–67755. [Google Scholar] [CrossRef]
- Wu, H.; Soraghan, J.; Lowit, A.; Di-Caterina, G. A Deep Learning Method for Pathological Voice Detection Using Convolutional Deep Belief Network. In Proceedings of the INTERSPPECH, Hyderabad, India, 2–9 September 2018; pp. 446–450. [Google Scholar] [CrossRef] [Green Version]
- Harar, P.; Alonso-Hernandezy, J.B.; Mekyska, J.; Galaz, Z.; Burget, R.; Smekal, Z. Voice Pathology Detection using Deep Learning: A Preliminary Study. In Proceedings of the IEEE International Conference and Workshop on Bioinspired Intelligence (IWOBI), Funchal, Portugal, 10–12 July 2017. [Google Scholar] [CrossRef] [Green Version]
- Fang, S.-H.; Tsao, Y.; Hsiao, M.-J.; Chen, J.-Y.; Lai, Y.-H.; Lin, F.-C.; Wang, C.-T. Detection of Pathological Voice Using Cepstrum Vectors: A Deep Learning Approach. J. Voice 2019, 33, 634–641. [Google Scholar] [CrossRef]
- Islam, R.; Abdel-Raheem, E.; Tarique, M. Early Detection of COVID-19 Patients using Chromagram Features of Cough Sound Recordings with Machine Learning Algorithm. In Proceedings of the International Conference on Microelectronics (ICM), New Cairo City, Egypt, 19–22 December 2022. [Google Scholar] [CrossRef]
- Cosentinio, S.; Falk, T.H.; McAlpine, D.; Marquardt, T. Cochlear Implant Filterbank Design and Optimization. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 347–353. [Google Scholar] [CrossRef]
- Katsiamis, A.G.; Drakakis, E.M.; Lyon, R.F. Practical Gammatone-Like Filters for Auditory Processing. EUROSHIP J. Audio Speech Music. Process. 2007, 2007, 63685. [Google Scholar] [CrossRef] [Green Version]
- Jun, T.J.; Kim, D. Pathological Voice Disorders Classification from Acoustic Waveform. Available online: http://mac.kaist.ac.kr/~juhan/gct634/2018/finals/pathological_voice_disorders_classification_from_acoustic_waveforms_poster.pdf (accessed on 21 March 2020).
- Srinivasan, V.; Ramalingam, V.; Arulmozli, P. Artificial Neural Network Based Pathological Voice Classification Using MFCC Features. Int. J. Sci. Environ. Technol. 2014, 3, 291–302. Available online: https://pdfs.semanticscholar.org/241b/313fd5758095d74abe8da7b8aa22e2348075.pdf (accessed on 21 March 2020).
- Wang, J.; Cheolwoo, J. Vocal fold disorder detection using pattern recognition methods. In Proceedings of the 2007 29th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Lyon, France, 23–26 August 2007; pp. 3253–3256. [Google Scholar] [CrossRef]
- Ali, A.; Ganar, S. Intelligent Pathological Voice Detection. Int. J. Innov. Res. Technol. 2018, 5, 92–95. [Google Scholar]
- Sellam, V.; Jagadeesan, J. Classification of Normal and Pathological Voice using SVM and RBFNN. J. Signal Inf. Process. 2014, 5, 42693. [Google Scholar] [CrossRef] [Green Version]
- Chopra, M.; Khieu, K.; Liu, T. Classification and Recognition of Stuttered Speech. Stanford University. 2020. Available online: http://web.stanford.edu/class/cs224s/reports/Manu_Chopra.pdf (accessed on 21 March 2020).
- Sassou, A. Automatic Identification of Pathological Voice Quality Based on the GRBAS Categorization. In Proceedings of the APSIPA Annual Summit and Conference, Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1243–1247. [Google Scholar] [CrossRef]
- Murphy, P. Development of Acoustic Analysis Techniques for Use in the Diagnosis of Vocal Pathology. Ph.D. Thesis, School of Physical Science, Dublin City University, Dublin, Ireland, 2019. Available online: http://doras.dcu.ie/19122/1/Peter_Murphy_20130620152522.pdf (accessed on 17 May 2019).
- Verde, L.; De Pietro, G.; Alrashoud, M.; Ghoneim, A.; Al-Mutib, K.N.; Sannino, G. Dysphonia Detection Index (DDI): A New Multi-Parametric Marker to Evaluate Voice Quality. IEEE Access 2019, 7, 55689–55697. [Google Scholar] [CrossRef]
- Ding, H.; Gu, Z.; Dai, P.; Zhou, Z.; Wang, L.; Wu, X. Deep connected attention (DCA) ResNet for robust voice pathology detection and classification. Biomed. Signal Process. Control 2021, 70, 102973. [Google Scholar] [CrossRef]
- Sztaho, D.; Gabor, K.; Gabriel, T.M. Deep Learning Solution for Pathological Voice Detection using LSTM-based Autoencoder Hybrid with Multi-Task Learning. In Proceedings of the 14th International Conference on Bio-inspired Systems and Signal Processing, Vienna, Austria, 11–13 February 2021; Volume 4, pp. 135–141. [Google Scholar]
- Al-Dhief, F.T.; Latiff, N.M.A.; Malik, N.N.N.A.; Sabri, N.; Baki, M.M.; Alb, M.A.A. Voice Pathology Detection using Machine Learning Techniques. In Proceedings of the 5th International Symposium on Telecommunication Technologies (ISTT), Shah Alam, Malaysia, 9–11 November 2020. [Google Scholar] [CrossRef]
- Lee, J.-Y. Experimental Evaluation of Deep Learning Methods for an Intelligent Pathological Voice Detection System using the Saarbrucken Voice Database. Appl. Sci. 2021, 11, 7149. [Google Scholar] [CrossRef]
- Hu, H.-C.; Chang, S.-Y.; Wang, C.-H. Deep Learning Application for Vocal Fold Disease Prediction Through Voice Recognition: Preliminary Development Study. J. Med. Internet Res. 2021, 23, e25247. [Google Scholar] [CrossRef]
- Mohammed, M.A.; Abdulkareem, K.H.; Mostafa, S.A.; Ghani, M.K.A.; Maashi, M.S.; Garcia-apirain, B.; Oleagordia, I.; AlHakami, H.; Al-Dhief, F.T. Voice Pathology Detection and Classification Using Convolutional Neural Network Model. Appl. Sci. 2020, 10, 3723. [Google Scholar] [CrossRef]
- Syed, S.A.; Rashid, M.; Hussain, S.; Zahid, H. Comparative Analysis of CNN and RNN for Voice Pathology Detection. BioMed Res. Int. 2021, 2021, 6635964. [Google Scholar] [CrossRef]
- Saarbrücken Voice Database. Available online: http://stimmdb.coli.uni-saarland.de/index.php4#target (accessed on 13 December 2021).
- Huckvale, M.; Buciuleae, C. Automated Detection of Voice Disorder in the Saarbrücken Voice Database: Effects of Pathology Subset and Audio Materials. In Proceedings of the INTERSPEECH, Brno, Czech Republic, 30 August–3 September 2021; pp. 1399–1403. [Google Scholar] [CrossRef]
- Schindler, R.; Kessler, D. Preliminary results with the Clarion cochlear implant. Laryngoscope 1992, 102, 1006–1013. [Google Scholar] [CrossRef]
- Kessler, D.K. The Clarion® Multi-Strategy Cochlear Implant. Ann. Otol. Rhinol. Laryngol. 1999, 108 (Suppl. S4), 8–16. [Google Scholar] [CrossRef]
- Tyler, R.; Gantz, B.; Woodworth, G.G.; Parkinson, A.J.; Lowder, M.W.; Schum, L.K. Initial independent results with the Clarion cochlear implant. Ear Hear. 1996, 17, 528–536. [Google Scholar] [CrossRef]
- Bäckström, T. Introduction to Speech Processing: Pre-Emphasis. Available online: https://wiki.aalto.fi/display/ITSP/Pre-emphasis (accessed on 13 December 2021).
- Loizou, P.C.; Dorman, M.; Tu, Z. On the number of channels needed to understand speech. J. Acoust. Soc. Am. 1999, 106, 2097–2103. [Google Scholar] [CrossRef]
- Oppenheim, A.V.; Schafer, R.W. Digital Filter Design Techniques. In Digital Signal Processing; Prentice Hall: Upper Saddle River, NJ, USA, 1975; pp. 239–250. [Google Scholar]
- Carney, L.H.; Win, C.T. Temporal coding of resonances by low-frequency auditory nerve fibers: Single fiber responses and a population model. J. Neurophysiol. 1988, 60, 1653–1677. [Google Scholar] [CrossRef] [Green Version]
- de Boer, E.; de Jongh, R. On cochlear encoding: Potentialities and limitations of the reverse-correlation techniques. J. Acoust. Am. 1978, 63, 115–135. [Google Scholar] [CrossRef] [PubMed]
- Patterson, A.D.; Holdsworth, J. A functional model of neural activity patterns and auditory image. Adv. Speech Hear. Lang. Process. 2014, 3, 547–563. [Google Scholar]
- Patterson, R.D.; Holdsworth, J. Complex sounds and auditory images. In Auditory Physiology and Perception; Cazals, Y., Demany, I., Horner, K., Eds.; Pergamon: Oxford, UK, 1992; pp. 429–446. [Google Scholar]
- Unoki, M. Comparison of the roex and gammachip filters as representations of the auditory filter. J. Acoust. Soc. Am. 2006, 120, 1474–1492. [Google Scholar] [CrossRef] [PubMed]
- Schofield, D. Visualizations of the Speech Based on a Model of the Peripheral Auditory System; Report DITC 62/85; National Physical Lab.: Teddington, UK, 1985. [Google Scholar]
- Patterson, R.D.; Moore, B.C.J. Auditory filters and excitation patterns as representations of frequency resolution. In Frequency Selecting in Hearing; Moore, B.C.J., Ed.; Academic Press: London, UK, 2019; pp. 123–177. [Google Scholar]
- Darling, A.M. Properties and Implementation of Gammatone Filters: A Tutorial. Available online: https://www.phon.ucl.ac.uk/home/shl5/Darling1991-GammatoneFilter.pdf (accessed on 30 September 2021).
- Kim, P. MATLAB Deep Learning: With Machine Learning, Neural Networks and Artificial Intelligence; Academic Press: London, UK, 2017; Available online: https://link.springer.com/book/10.1007/978-1-4842-2845-6?noAccess=true (accessed on 13 December 2021).
- Du, S.; Lee, J.; Li, H.; Wang, L.; Zhai, X. Gradient Descent Finds Global Minima of Deep Neural networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 1675–1685. [Google Scholar]
- Jiaa, Y.; Du, P. Performance measures in evaluating machine learning-based bioinformatics predictors for classifications. Quant. Biol. 2016, 4, 320–330. [Google Scholar] [CrossRef] [Green Version]
- Rangayyan, M. Pattern Classification and Diagnostic Decision. In Biomedical Signal Analysis, 2nd ed.; John Wiley and Sons: Hoboken, NJ, USA, 2001; pp. 598–606. [Google Scholar]
- Lathi, B.P. Continuous-Time Signal Analysis: The Fourier Transform. In Signal Processing and Linear Systems; International Edition; Oxford University Press: New York, NY, USA, 2001; pp. 235–245. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Bandwidth, Hz | Center Frequency, Hz |
|---|---|
| 265 | 394 |
| 331 | 692 |
| 431 | 1064 |
| 516 | 1528 |
| 645 | 2109 |
| 805 | 2834 |
| 1006 | 3740 |
| 1136 | 4871 |
| Bandwidth, Hz | Center Frequency, Hz |
|---|---|
| 158 | 50 |
| 173 | 186 |
| 276 | 389 |
| 478 | 690 |
| 788 | 1139 |
| 1249 | 1807 |
| 1936 | 2802 |
| 2960 | 4282 |
| Simulation No. | Accuracy (%) | ||
|---|---|---|---|
| Training | Validation | Testing | |
| 1 | 100 | 88.00 | 79.17 |
| 2 | 100 | 85.83 | 79.17 |
| 3 | 100 | 88.83 | 75.00 |
| 4 | 100 | 85.83 | 79.17 |
| 5 | 100 | 87.83 | 83.33 |
| 6 | 100 | 88.00 | 79.17 |
| 7 | 100 | 85.83 | 75.00 |
| 8 | 100 | 83.33 | 75.00 |
| 9 | 100 | 85.33 | 79.17 |
| 10 | 100 | 80.83 | 75.00 |
| Average | 100 | 85.96 | 77.91 |
| Simulation No. | TPF (%) | TNF (%) | FPF (%) | FNF (%) |
|---|---|---|---|---|
| 1 | 83.33 | 75.00 | 25.00 | 16.67 |
| 2 | 83.33 | 75.00 | 25.00 | 16.67 |
| 3 | 75.00 | 75.00 | 25.00 | 25.00 |
| 4 | 75.00 | 83.33 | 16.67 | 25.00 |
| 5 | 75.00 | 91.67 | 8.33 | 25.00 |
| 6 | 75.00 | 83.33 | 16.67 | 25.00 |
| 7 | 66.67 | 83.33 | 16.67 | 33.33 |
| 8 | 75.00 | 75.00 | 25.00 | 25.00 |
| 9 | 83.33 | 75.00 | 25.00 | 16.67 |
| 10 | 75.00 | 75.00 | 25.00 | 25.00 |
| Average | 76.67 | 79.17 | 20.83 | 23.33 |
| Prediction (%) | ||
|---|---|---|
| Actual | Control | Pathology |
| Control | 20.83 (FPF) | |
| Pathology | 23.33 (FNF) | |
| Simulation No. | Accuracy (%) | ||
|---|---|---|---|
| Training | Validation | Testing | |
| 1 | 100 | 85.00 | 75.00 |
| 2 | 100 | 75.83 | 75.00 |
| 3 | 100 | 87.83 | 79.17 |
| 4 | 100 | 80.83 | 79.17 |
| 5 | 100 | 77.83 | 79.17 |
| 6 | 100 | 85.00 | 79.17 |
| 7 | 100 | 80.83 | 75.00 |
| 8 | 100 | 83.33 | 75.00 |
| 9 | 100 | 85.00 | 75.00 |
| 10 | 100 | 78.83 | 83.33 |
| Average | 100 | 81.98 | 77.50 |
| Simulation No. | TPF (%) | TNF (%) | FPF (%) | FNF (%) |
|---|---|---|---|---|
| 1 | 83.33 | 66.67 | 33.33 | 16.67 |
| 2 | 83.33 | 66.67 | 33.33 | 16.67 |
| 3 | 83.33 | 66.67 | 33.33 | 16.67 |
| 4 | 83.33 | 75.00 | 25.00 | 16.67 |
| 5 | 83.33 | 75.00 | 25.00 | 16.67 |
| 6 | 83.33 | 75.00 | 25.00 | 16.67 |
| 7 | 83.00 | 75.00 | 25.00 | 16.67 |
| 8 | 75.00 | 75.00 | 25.00 | 25.00 |
| 9 | 91.67 | 75.00 | 25.00 | 8.33 |
| 10 | 83.33 | 66.67 | 33.33 | 16.67 |
| Average | 83.30 | 71.67 | 28.33 | 16.67 |
| Prediction (%) | ||
|---|---|---|
| Actual | Control | Pathology |
| Control | ||
| Pathology | ||
| System Model | ||
|---|---|---|
| Measures | Bandpass Filters | Gammatone Filters |
| Accuracy | ||
| Precision | ||
| Recall/Sensitivity | ||
| F1 score | ||
| NPV | ||
| Research Works | Phonemes | Pathological Condition | Features | Tools | Accuracy/ F1 Score |
|---|---|---|---|---|---|
| Tae Jun [27] | Vowels | Neoplasm, phono-trauma, vocal palsy | Mel Spectrogram | Dense-net | Accuracy: 71% |
| V. Sellam [31] | Tamil phrases | Multiple voice disorders | Signal energy, pitch, formant frequencies, mean square residual signal, reflection coefficients, jitter and shimmer | SVM RBFNN | Accuracy: 91% (RBFNN) 83% (SVM) for children subgroup |
| A. Sassou [33] | Japanese Vowel | Roughness, breathiness, asthenia, and strain | Higher-Order Local Autocorrelation (HLAC) | FFNN, AR-HMM | F-measure: 87.25% for speaker-based identification. |
| H. Wu [21] | Vowels | Reinke’s edema, laryngitis, leukoplakia, recurrent laryngeal, nerve paralysis, vocal fold carcinoma, vocal fold paralysis | Spectrogram | CNN, CDBN | Accuracy: 71%, |
| Proposed Method | Speech | Laryngitis | Cochlear Simulation Model-1, Cochlear Simulation Model-2 | Cochlear implant processing system and CNN | F1 score: 77.6%, 78.7% Accuracy: 77.9%, 77.5% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Islam, R.; Abdel-Raheem, E.; Tarique, M. A Novel Pathological Voice Identification Technique through Simulated Cochlear Implant Processing Systems. Appl. Sci. 2022, 12, 2398. https://doi.org/10.3390/app12052398
Islam R, Abdel-Raheem E, Tarique M. A Novel Pathological Voice Identification Technique through Simulated Cochlear Implant Processing Systems. Applied Sciences. 2022; 12(5):2398. https://doi.org/10.3390/app12052398
Chicago/Turabian StyleIslam, Rumana, Esam Abdel-Raheem, and Mohammed Tarique. 2022. "A Novel Pathological Voice Identification Technique through Simulated Cochlear Implant Processing Systems" Applied Sciences 12, no. 5: 2398. https://doi.org/10.3390/app12052398