This section provides a test of the proposed SFINet for wind power forecasting.
Section 4.1 introduces the data sets included in this study. There were five data sets utilized: two of them were the collected real wind power data and three were the published data sets.
Section 4.2 introduces detailed power prediction and other experimental settings.
Section 4.3 shows the performance and usability of the proposed method, as well as the testing results. The effectiveness of SFINet was verified by comparing it with various other methods including SCINet.
4.1. Data Set Selection
We empirically perform the test of the established models using five data sets: two of them were collected from a wind farm and the other three were selected from the published benchmark data sets.
The data collected from a wind farm represent the operation data of two independent wind turbines, each with a rated power of 1.5 MW, for one year with a sampling frequency of once per 10 min, i.e., 10 min data. The two data sets were marked as WPm1 and WPm2, respectively. The data for each sampling point include 12 variables—see
Table 1 below. These variables were most relevant to wind power generation, including the wind speed, generator output power, pitch angle, nacelle position (or yaw angle), wind direction (vane direction), etc. These variables were selected by referring to the previously published research articles for wind power forecast and through discussions with the wind farm operation manager and engineers. There were two wind turbine operation modes: Mode 1 was marked as 20 when there was power output to the grid and Mode 2 was marked as 6 when there was no power output or the wind turbine stopped running. Other values represent the wind turbine running in a transition status between the two operation modes. The value was calculated based on the time length when it was running in Mode 1 and the time length when it was running in Mode 2 in a 10 min time step. Similarly, there were two wind turbine braking modes: Under braking and no braking. When it was under braking, the variable Turbine Brake Level was assigned a value of 51, whereas it was given 0 if there was no braking. Other values assigned to this variable represent the braking is in a transition status between the two braking modes. The value was calculated based on the time length when it was in braking mode and the time length when there was no braking. Each value was calculated in average on a 10 min time step.
The ratio of the training data set to the validation set and the test set was 5:2:3. See
Table 2 for detailed information. These two data sets were used to verify the effectiveness of the proposed method in wind power forecasting.
Electricity Transformer Temperature (ETT) data were collected and used in [
55]. The ETT data cover 2 years’ data collected from two separate counties in China. They were split into two data sets marked as ETTh1 and ETTh2, respectively, with a sampling frequency of once per hour. The ETTm1 data set was 15 min data, i.e., the sampling frequency was once per 15 min. Each data point consisted of the target value of “oil temperature” (°C) and six power load features—see
Table 3 below. The ratio of the training data set to the validation set and the test set was 3:1:1. See
Table 2 for detailed information. The ETT data sets were used to demonstrate the general validity of the proposed method.
4.2. Experiment Implementation
In order to evaluate the performance of the proposed method in different aspects, a variety of tasks were defined based on the wind power data set, including prediction tasks of different horizons and univariate or multivariate predictions.
In terms of horizon, similar to ETT data, in the case of a fixed sampling time, different output sequence lengths characterized different prediction times and also showed the difficulty of the task. The prediction lengths of WPh1 and WPh2 were divided into 6, 12, 24, and 48, and the corresponding prediction times were 1 h, 2 h, 4 h, and 8 h. In terms of variables, two forms of multivariate and univariate were used for evaluation. Univariate prediction takes the value of the generated wind power per second (A1gr Gen Power for Process_1sec), and multivariate prediction takes the values from all variables.
For ETT data, the prediction lengths of ETTh1 and ETTh2 were 24, 48, 96, 288, and 720, respectively, and the corresponding prediction time lengths were 24 h, 48 h, 96 h, 288 h, and 720 h. The predicted lengths of ETTm1 were 24, 48, 96, 288, and 672, corresponding to the predicted times of 6 h, 12 h, 24 h, 72 h, and 168 h, respectively. Univariate prediction takes the value of oil temperature, and multivariate prediction takes the values from all variables.
- (1)
Evaluation index
The Mean Absolute Error (MAE) and Weighted Mean Absolute Percentage Error (WMAPE) were used as evaluation criteria. Because some variables in the task may have had negative values (the data sets in the format as
Table 1 and
Table 2), the optimized WMAPE was calculated as follows,
where τ is the total number of data points and
is the mean of the data in the sample.
The relative improvement of performance (RIP) with MAE and absolute improvement of performance (AIP) with WMAPE were used for comparison. They were calculated as follows:
where MAE =
and
are obtained using other competitive methods for prediction, and MAE and WMAPE are obtained using the newly proposed method based on the SFINet model.
- (2)
Data processing
In order to evaluate the performance of our proposed algorithm in wind turbine power prediction, we conducted experiments based on the proposed WP data sets and compared the prediction results with those given by the SCINet models. At the same time, in order to further verify the general applicability of the algorithm, we also verified the performance of the algorithm using the ETT data sets and compared it with other methods, including SCINet.
Our task does not specify the look-back windows corresponding to a certain prediction sequence horizon. In the wind power forecasting task, the original wind power data have singular values. In order to eliminate the singular values shown in
Table 1, we chose to skip singular values when constructing the training, validation, and testing for different tasks. If there was a singular value in a pair, this piece of data was discarded. Therefore, in this way, for different tasks, the number of samples for training, validation, and testing were be produced, as shown in
Table 4.
Table 4 also shows the input data time length for a certain prediction length; for example, if the prediction length is for 6 h, the input data covers a time length of 128 h.
The singular value issue did not appear in the ETT data set, and these data could be used normally. In the ETT task, the settings are shown in
Table 5.
All data were normalized. In terms of the loss function and optimizer, we followed the same settings for the SCINet model given in [
23].
- (1)
Hardware platform
Training GPU: Single Nvidia 3080Ti 16 GB.
CPU Intel(R) Xeon(R) CPU E5-2650 v4 @ 2.20 GHz.
Memory: 256 G.
4.3. Prediction Experiment and Result Analysis
- (1)
Wind power forecasting
Applying SFINet to the wind power data sets, the forecasting performance obtained is shown in
Table 6. It can be seen from
Table 6 that the prediction results of the SFINet model proposed in this paper were generally better than those of the SCINet model. The evaluation criteria of MAE using the multivariate and univariate prediction results with the WPm1 data set were reduced by up to 10.07% and 6.90%, respectively; and up to 9.20 and 6.87%, respectively, for the WPm2 data set.
The forecast results evaluated using WMAPE are shown in
Table 7. From the results given in
Table 7, the superiority of the SFINet model algorithm was verified in univariate and multivariate wind turbine power prediction. The evaluation indices of WMAPE with the WPm1 data set were reduced by up to 5.79% using multivariate evaluation and 4.93% using univariate evaluation, and the WMAPE with the WPm2 data set were reduced by up to 4.86 and 4.35%, respectively. The performance improvement trend of the SFINet model under different horizon tasks was similar to the results using MAE metric.
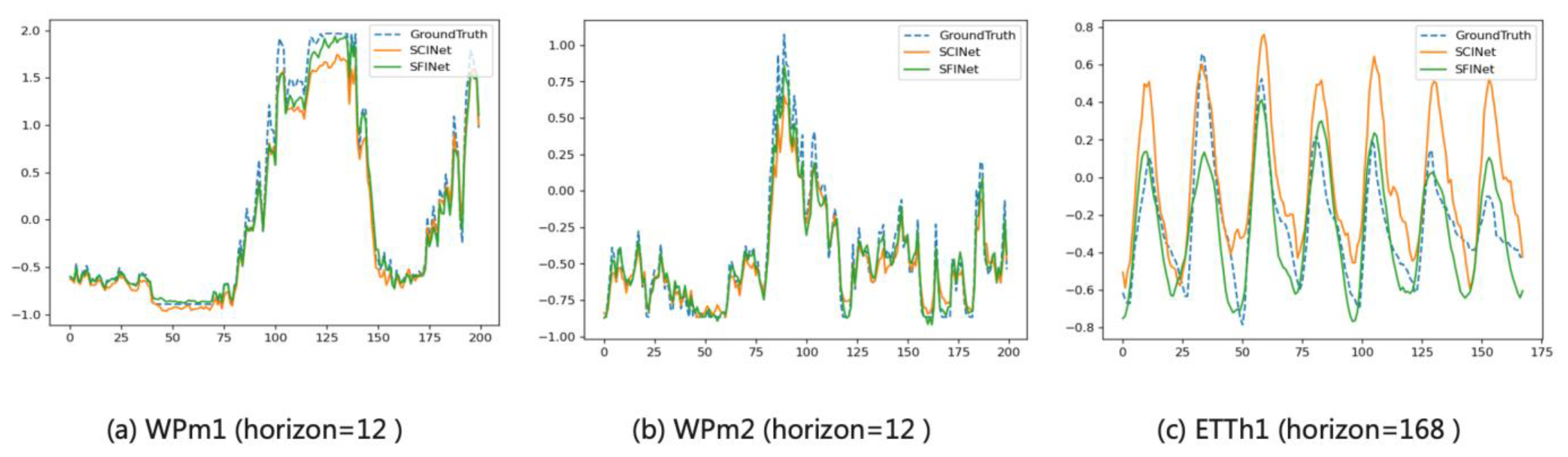
We then performed qualitative analysis of the prediction results using the wind power data set by selecting a piece of wind turbine power data for a sampling length of 200 in the WPh1 data set and WPh2 data set, as shown in
Figure 5a,b. It can be seen that the forecasted wind power had the characteristics of large variation, violent fluctuations and no obvious laws to follow. The prediction result of the SFINet model could better fit the actual power curve. At the same time, at the peak and valley points of the power change, the prediction result of the SFINet model was generally better than that of the SCINet model (see also
Figure 5c) by using the published data set.
- (2)
Generalization study
The ETT data set given in [
55] were used to evaluate the performance of a time series forecasting task e.g., [
23,
55]. In this paper, we used the same dataset to evaluate the performance of time series forecasting by different approaches, and the results of multivariate and univariate prediction are shown in
Table 8 and
Table 9.
As shown in
Table 8, in multivariate prediction, the prediction effects of Transformer-based methods other than Reformer [
56], such as LogTrans [
52] and Informer [
55], outperformed the RNN-based methods, such as LSTMa [
5]; the performance of TCN [
22] further outperformed Transformer-based methods; compared with these methods, SCINet model achieved better performance, because the downsample–convolve–interact architecture enabled multi-resolution analysis, which facilitated extracting temporal relation features with enhanced predictability. Overall, in this paper, as shown in all subtasks with ETT data, the prediction performance using SFINet was all better than that using SCINet—see the relative performance improvement given by RIP as shown in green color.
By comparison with the multivariate prediction, the performance of these methods in discussion for univariate prediction was gradually improved. N-Beats [
57] outperforms the above methods, and it is observed that SCINet is superior to other baseline methods. However, the performance of SFINet in time series forecasting is even better than that of SCINet.
Specifically, for the two different tasks using the ETTh1 data set, the evaluation criterion of MAE was improved by 6.33% and 0.76% or more, respectively, while using the ETTh2 and ETTm1 data sets, the prediction performance was improved by 6.94% and 1.76%, and 3.06% and 1.14% or more, respectively. When increasing the horizon, the improvement in MAE showed an increasing trend. The results further confirmed the effectiveness and universality of the algorithm proposed in this paper.
In order to make further comparison between SFINet and SCINet in time series forecasting, we performed the prediction using the ETT data set and the prediction performance was evaluated using the metric of WMAPE—see
Table 9. SFINet also achieved better performance than SCINet. More specifically, in the multivariate task and univariate task on the ETTh1 data set, the WMAPE was improved by at least 2.88% and 1.04%, respectively, while, on the ETTh2 and ETTm1 data sets, the above-mentioned performance was improved by 1.11% and 1.47%, and 1.13% and 0.43% or more, respectively.
Finally, the prediction results using ETTh1 data set for a horizon of 168 are shown in
Figure 5c as an illustration example. The predicted results could very well fit the actual values, and the degree of fitting was better than that of the SCINet model.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}