
Investigating Explainability Methods in Recurrent Neural Network Architectures for Financial Time Series Data


Abstract
:1. Introduction
2. Materials and Methods
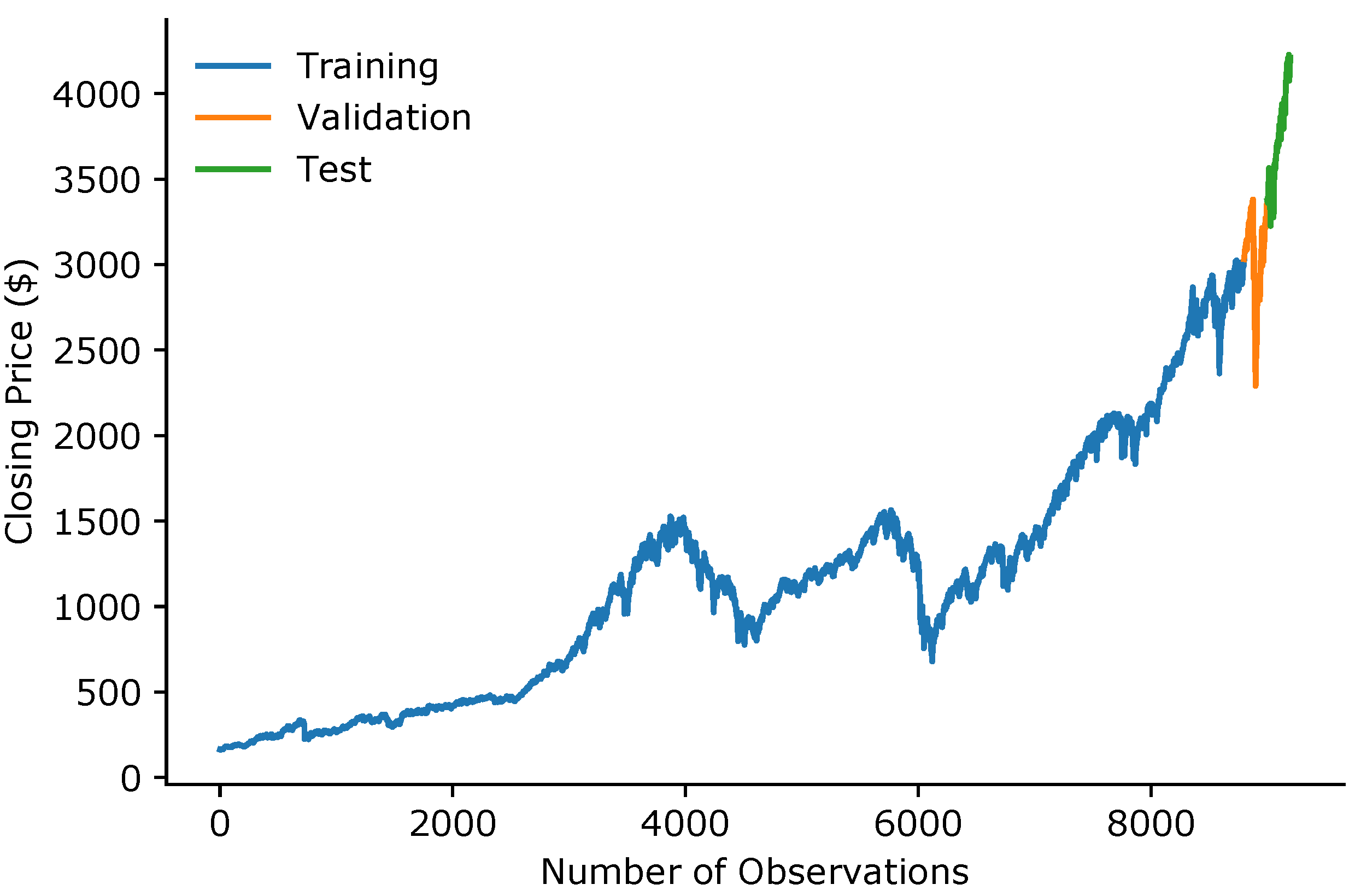
2.1. Dataset and Processing
2.2. Models
2.3. Ablation
| Algorithm 1: Ablation Algorithm. |
 |
2.4. Integrated Gradients
2.5. Added Noise
| Algorithm 2: Noise Algorithm. |
 |
2.6. Permutation
2.7. Hardware and Software
| Algorithm 3: Permutation Algorithm. |
 |
3. Results
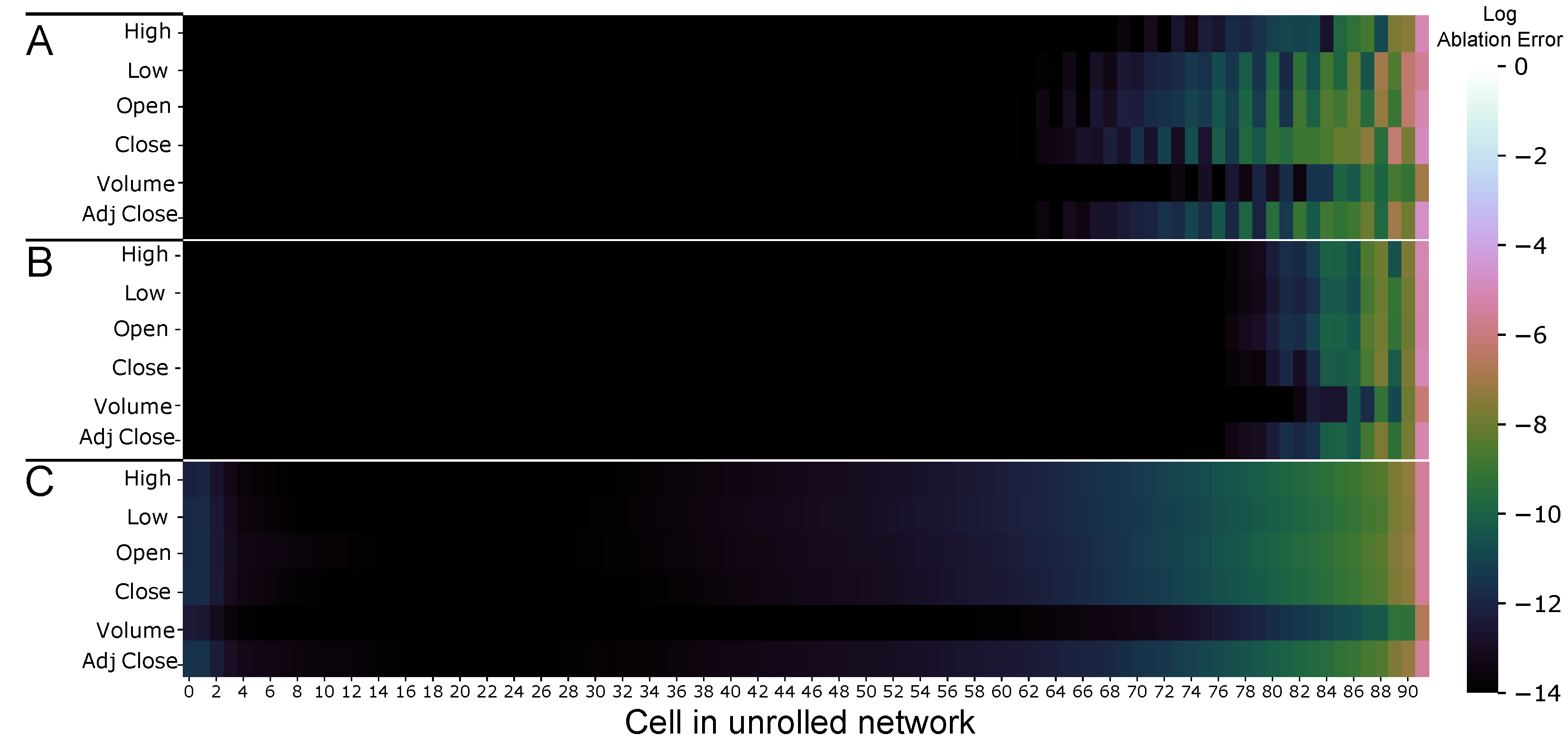
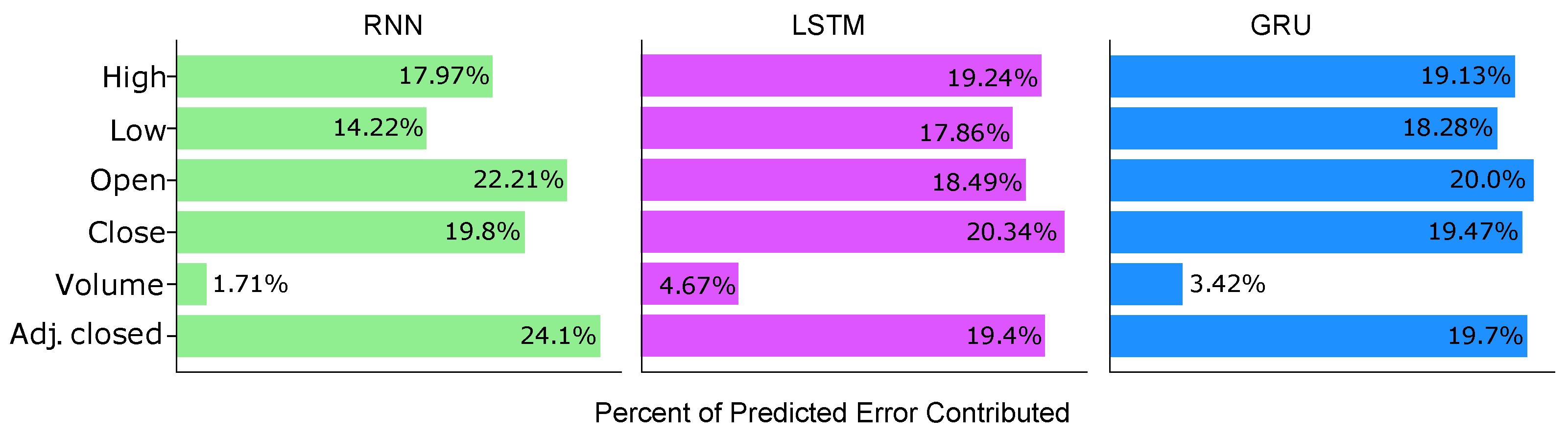
3.1. Ablation
3.2. Integrated Gradients
3.3. Added Noise
3.4. Permutation
4. Discussion
4.1. Input Importance
4.2. Feature Importance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| CNN | Convolutional neural network |
| Grad-CAM | Gradient-weighted class activation mapping |
| GRU | Gated recurrent unit |
| Lime | Local interpretable model-agnostic explanations |
| LSTM | Long short-term memory |
| RNN | Recurrent neural network |
| SMAPE | Symmetric mean absolute percentage error |
| SHAP | Shapley additive explanations |
| XAI | Explainable artificial intelligence |
References
- Tjoa, E.; Guan, C. A survey on explainable artificial intelligence (xai): Toward medical xai. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 4793–4813. [Google Scholar] [CrossRef] [PubMed]
- Rudin, C. Algorithms for interpretable machine learning. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; p. 1519. [Google Scholar]
- van Zyl, T.L. Machine Learning on Geospatial Big Data. In Big Data: Techniques and Technologies in Geoinformatics; CRC Press: Boca Raton, FL, USA, 2014; p. 133. [Google Scholar]
- Angelov, P.P.; Soares, E.A.; Jiang, R.; Arnold, N.I.; Atkinson, P.M. Explainable artificial intelligence: An analytical review. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1424. [Google Scholar] [CrossRef]
- Parikh, R.B.; Teeple, S.; Navathe, A.S. Addressing bias in artificial intelligence in health care. JAMA 2019, 322, 2377–2378. [Google Scholar] [CrossRef] [PubMed]
- Caruana, R.; Lou, Y.; Gehrke, J.; Koch, P.; Sturm, M.; Elhadad, N. Intelligible models for healthcare: Predicting pneumonia risk and hospital 30-day readmission. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1721–1730. [Google Scholar]
- Goodman, B.; Flaxman, S. European Union regulations on algorithmic decision-making and a “right to explanation”. AI Mag. 2017, 38, 50–57. [Google Scholar] [CrossRef] [Green Version]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On pixel-wise explanations for non-linear classifier decisions by layer-wise relevance propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dieber, J.; Kirrane, S. Why model why? Assessing the strengths and limitations of LIME. arXiv 2020, arXiv:2012.00093. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Riberio, M.T.; Singh, S.; Guestrin, C. Why Should I Trust You? Explaining the Predictions of Any Classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Confalonieri, R.; Coba, L.; Wagner, B.; Besold, T.R. A historical perspective of explainable Artificial Intelligence. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2021, 11, e1391. [Google Scholar] [CrossRef]
- Fauvel, K.; Lin, T.; Masson, V.; Fromont, É.; Termier, A. XCM: An Explainable Convolutional Neural Network for Multivariate Time Series Classification. Mathematics 2021, 9, 3137. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Viton, F.; Elbattah, M.; Guérin, J.L.; Dequen, G. Heatmaps for Visual Explainability of CNN-Based Predictions for Multivariate Time Series with Application to Healthcare. In Proceedings of the 2020 IEEE International Conference on Healthcare Informatics (ICHI), Oldenburg, Germany, 30 November–3 December 2020; pp. 1–8. [Google Scholar]
- Meyes, R.; Lu, M.; de Puiseau, C.W.; Meisen, T. Ablation studies in artificial neural networks. arXiv 2019, arXiv:1901.08644. [Google Scholar]
- Covert, I.; Lundberg, S.; Lee, S.I. Understanding global feature contributions with additive importance measures. arXiv 2020, arXiv:2004.00668. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the International Conference on Machine Learning, Sydney, NSW, Australia, 6–11 August 2017; pp. 3319–3328. [Google Scholar]
- Kopitar, L.; Cilar, L.; Kocbek, P.; Stiglic, G. Local vs. Global Interpretability of Machine Learning Models in Type 2 Diabetes Mellitus Screening. In Artificial Intelligence in Medicine: Knowledge Representation and Transparent and Explainable Systems; Springer: Berlin/Heidelberg, Germany, 2019; pp. 108–119. [Google Scholar]
- Kenny, E.M.; Delaney, E.D.; Greene, D.; Keane, M.T. Post-hoc explanation options for XAI in deep learning: The Insight centre for data analytics perspective. In Proceedings of the International Conference on Pattern Recognition, Virtual Event, 10–15 January 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 20–34. [Google Scholar]
- Hyndman, R.J.; Koehler, A.B.; Snyder, R.D.; Grose, S. A state space framework for automatic forecasting using exponential smoothing methods. Int. J. Forecast. 2002, 18, 439–454. [Google Scholar] [CrossRef] [Green Version]
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 27, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, T.T.; Le Nguyen, T.; Ifrim, G. A Model-Agnostic Approach to Quantifying the Informativeness of Explanation Methods for Time Series Classification. In Lecture Notes in Computer Science, Proceedings of the International Workshop on Advanced Analytics and Learning on Temporal Data, Ghent, Belgium, 18 September 2020; Springer: Cham, Switzerland, 2020; pp. 77–94. [Google Scholar]
- Delaney, E.; Greene, D.; Keane, M.T. Instance-based counterfactual explanations for time series classification. In Lecture Notes in Computer Science, Proceedings of the International Conference on Case-Based Reasoning, Salamanca, Spain, 13–16 September 2021; Springer: Cham, Switzerland, 2021; pp. 32–47. [Google Scholar]
- Bailey, D.H.; Borwein, J.; Lopez de Prado, M.; Salehipour, A.; Zhu, Q.J. Backtest overfitting in financial markets. Automated Trader 2016, 1–8. Available online: https://www.davidhbailey.com/dhbpapers/overfit-tools-at.pdf (accessed on 10 December 2021).
- Sezer, O.B.; Gudelek, M.U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. 2020, 90, 106181. [Google Scholar] [CrossRef] [Green Version]
- Laher, S.; Paskaramoorthy, A.; Van Zyl, T.L. Deep Learning for Financial Time Series Forecast Fusion and Optimal Portfolio Rebalancing. In Proceedings of the 2021 IEEE 24th International Conference on Information Fusion (FUSION), Sun City, South Africa, 1–4 November 2021; pp. 1–8. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Mathonsi, T.; van Zyl, T.L. Prediction Interval Construction for Multivariate Point Forecasts Using Deep Learning. In Proceedings of the 2020 7th International Conference on Soft Computing & Machine Intelligence (ISCMI), Stockholm, Sweden, 14–15 November 2020; pp. 88–95. [Google Scholar]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M5 accuracy competition: Results, findings and conclusions. Int. J. Forecast. 2020, 32, 8026–8037. [Google Scholar] [CrossRef]
- Mathonsi, T.; van Zyl, T.L. A Statistics and Deep Learning Hybrid Method for Multivariate Time Series Forecasting and Mortality Modeling. Forecasting 2022, 4, 1–25. [Google Scholar] [CrossRef]
- Said, S.E.; Dickey, D.A. Testing for unit roots in autoregressive-moving average models of unknown order. Biometrika 1984, 71, 599–607. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. Adv. Neural Inf. Process. Syst. 2019, 32, 8026–8037. [Google Scholar]
- Seabold, S.; Perktold, J. Statsmodels: Econometric and statistical modeling with python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Volume 57, p. 61. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental algorithms for scientific computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kokhlikyan, N.; Miglani, V.; Martin, M.; Wang, E.; Alsallakh, B.; Reynolds, J.; Melnikov, A.; Kliushkina, N.; Araya, C.; Yan, S.; et al. Captum: A unified and generic model interpretability library for pytorch. arXiv 2020, arXiv:2009.07896. [Google Scholar]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M.L. Seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Gers, F.A.; Schmidhuber, E. LSTM recurrent networks learn simple context-free and context-sensitive languages. IEEE Trans. Neural Netw. 2001, 12, 1333–1340. [Google Scholar] [CrossRef] [Green Version]
- Trinh, T.; Dai, A.; Luong, T.; Le, Q. Learning longer-term dependencies in rnns with auxiliary losses. In Proceedings of the International Conference on Machine Learning, Vancouver, BC, Canada, 30 April–3 May 2018; pp. 4965–4974. [Google Scholar]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555. [Google Scholar]
- Hoseinzade, E.; Haratizadeh, S. CNNpred: CNN-based stock market prediction using a diverse set of variables. Expert Syst. Appl. 2019, 129, 273–285. [Google Scholar] [CrossRef]
- Livieris, I.E.; Pintelas, E.; Pintelas, P. A CNN–LSTM model for gold price time-series forecasting. Neural Comput. Appl. 2020, 32, 17351–17360. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Hidden States | Layers (# Cells) | Dropout | Alpha | Test Accuracy (SMAPE) |
|---|---|---|---|---|---|
| RNN | 64 | 1 | 0.000 | 0.005 | 1.83 |
| GRU | 128 | 2 | 0.065 | 0.010 | 1.81 |
| LSTM | 128 | 2 | 0.050 | 0.008 | 1.81 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Freeborough, W.; van Zyl, T. Investigating Explainability Methods in Recurrent Neural Network Architectures for Financial Time Series Data. Appl. Sci. 2022, 12, 1427. https://doi.org/10.3390/app12031427
Freeborough W, van Zyl T. Investigating Explainability Methods in Recurrent Neural Network Architectures for Financial Time Series Data. Applied Sciences. 2022; 12(3):1427. https://doi.org/10.3390/app12031427
Chicago/Turabian StyleFreeborough, Warren, and Terence van Zyl. 2022. "Investigating Explainability Methods in Recurrent Neural Network Architectures for Financial Time Series Data" Applied Sciences 12, no. 3: 1427. https://doi.org/10.3390/app12031427