
Study on Dynamic Evaluation of Sci-tech Journals Based on Time Series Model


Abstract
:1. Introduction
- We propose a sci-tech journal evaluation task for the dynamic evaluation of scientific journals based on time series analysis.
- Based on the collection and analysis of data from sci-tech journal publishing platforms, such as WanFang and ZhiWang, we construct a time series dataset of journal metrics, which is a multivariate short-time multi-series time series dataset. Our dataset provides data support and certain challenges to the field of multi-series time series data collaborative analysis.
- We build models using nine mainstream time series data analysis methods of machine learning and deep learning to conduct various experiments on the task and dataset proposed in this study, and the results are compared and analyzed in detail.
- We confirm that these nine methods are generalizable to the task of the comprehensive dynamic evaluation of scientific journals and find the LSTM model built on our dataset produces the best performance, laying the foundation for the subsequent optimization of algorithms and serving as a directional guide for this task.
2. Related Works
2.1. Evaluation of Sci-tech Journals
2.1.1. Development of Sci-tech Journals
2.1.2. Evaluation Methods of Sci-tech Journals
2.1.3. Current Status of Studies on Sci-tech Journal Evaluation Metric Analysis
2.2. Time Series Dataset
2.2.1. Univariate Time Series Datasets
2.2.2. Multivariate Time Series Datasets
2.3. Time Series Analysis Methods
2.3.1. Traditional Methods
2.3.2. Machine Learning Methods
2.3.3. Deep Learning Methods
3. Dataset and Metrics
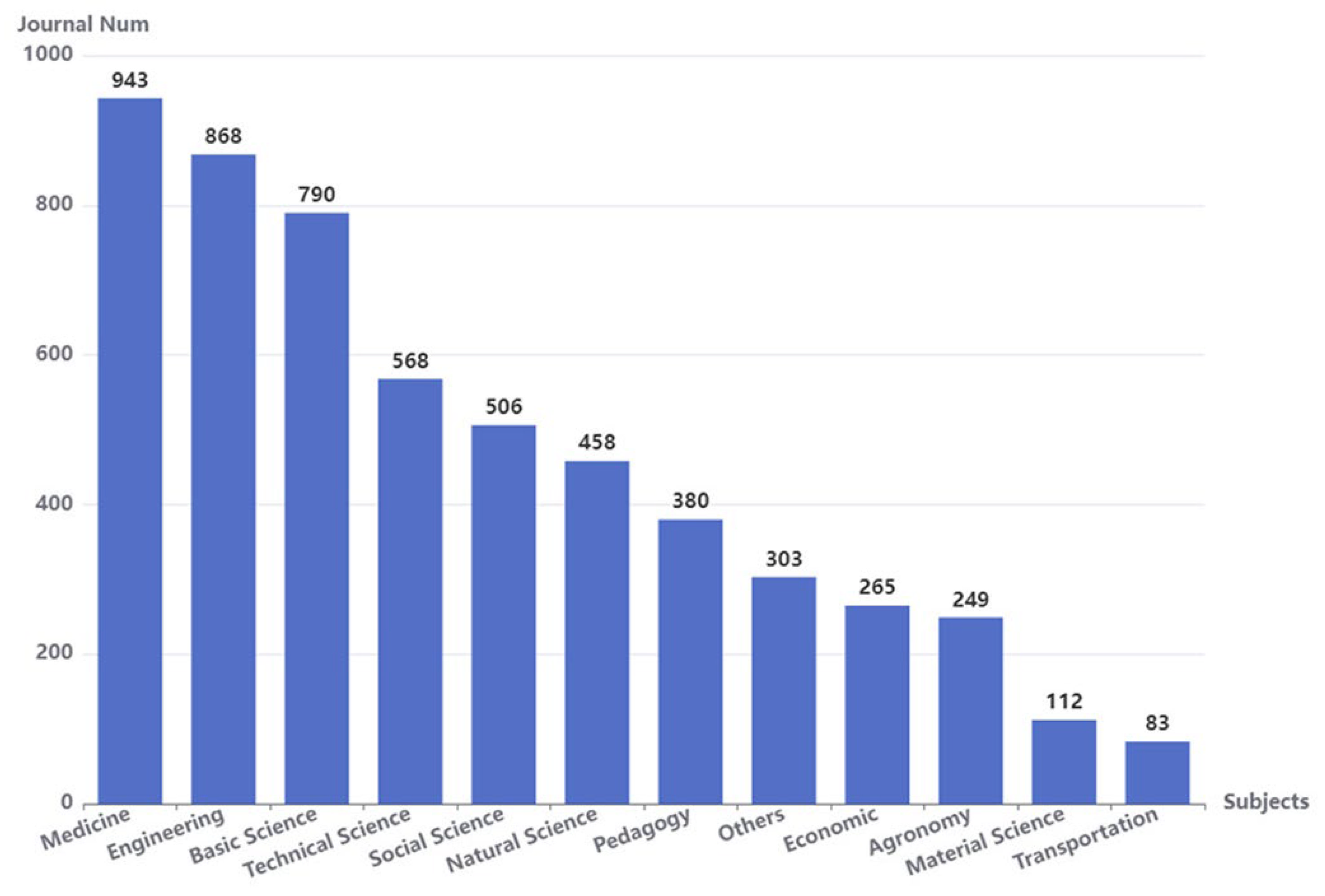
3.1. Dataset
3.2. Metrics
4. Methods
4.1. Machine Learning Methods
4.1.1. Multiple Linear Regression
4.1.2. Random Forest
4.1.3. EXtreme Gradient Boosting (XGBoost)
4.1.4. LightGBM
4.2. Deep Learning Methods
4.2.1. Artificial Neural Network (ANN)
4.2.2. Conv-1D Convolutional Neural Network (CNN)
4.2.3. WaveNet
4.2.4. Long Short-Term Memory Network (LSTM)
4.2.5. Gate Recurrent Unit (GRU)
5. Results
5.1. Training Situation Analysis
5.2. Evaluation Metrics Results
5.3. Dynamic Evaluation Analysis of Sci-tech Journals Based on LSTM
6. Discussion
6.1. Methods and Results Discussion
6.2. Theoretical and Practical Implications
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Thomas, D.R. A general inductive approach for analyzing qualitative evaluation data. Am. J. Eval. 2006, 27, 237–246. [Google Scholar] [CrossRef]
- Derek de solla Price. Little Science, Big Science; Columbia Press: New York, NY, USA, 1965; p. 53. [Google Scholar]
- Birkle, C.; Pendlebury, D.A.; Schnell, J.; Adams, J. Web of Science as a data source for research on scientific and scholarly activity. Quant. Sci. Stud. 2020, 1, 363–376. [Google Scholar] [CrossRef]
- Garfield, E. The history and meaning of the journal impact factor. Jama 2006, 295, 90–93. [Google Scholar] [CrossRef] [PubMed]
- Alonso, S.; Cabrerizo, F.J.; Herrera-Viedma, E.; Herrera, F. h-Index: A review focused in its variants, computation and standardization for different scientific fields. J. Informetr. 2009, 3, 273–289. [Google Scholar] [CrossRef] [Green Version]
- Abdi, H.; Williams, L.J. Principal component analysis. Wiley Interdiscip. Rev. Comput. Stat. 2010, 2, 433–459. [Google Scholar] [CrossRef]
- Zhu, Y.; Tian, D.; Yan, F. Effectiveness of entropy weight method in decision-making. Math. Probl. Eng. 2020, 2020, 3564835. [Google Scholar] [CrossRef]
- He, L.; Xingye, D. Research on intelligent evaluation for the content innovation of academic papers. Libr. Inf. Serv. 2020, 64, 93. [Google Scholar]
- Goffman, W.; Morris, T.G. Bradford’s law and library acquisitions. Nature 1970, 226, 922–923. [Google Scholar] [CrossRef]
- Clermont, M.; Krolak, J.; Tunger, D. Does the citation period have any effect on the informative value of selected citation indicators in research evaluations? Scientometrics 2021, 126, 1019–1047. [Google Scholar] [CrossRef]
- Chi, P.S. Differing disciplinary citation concentration patterns of book and journal literature? J. Informetr. 2016, 10, 814–829. [Google Scholar] [CrossRef]
- Guz, A.N.; Rushchitsky, J.J. Scopus: A system for the evaluation of scientific journals. Int. Appl. Mech. 2009, 45, 351–362. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, L. A comparative study on the relationship between article volume and impact factor of humanities and social sci-tech journals—The example of art and design and intelligence journals. J. Intell. 2019, 38, 151–157. [Google Scholar]
- Tang, K.Y.; Lu, J.; Li, H. Research on the influence of journalism and communication journals’ article volume on academic influence. Media Watch 2021, 38, 91–97. [Google Scholar]
- Li, C.; Ding, Z. Research on the relationship between the number of articles and the influence of excellence action plan journals based on the M-K trend test. Technol. Publ. 2021, 40, 78–84. [Google Scholar]
- Wu, T.; Shi, J.; Yang, Y.; Chen, C.; Sun, J. A comparative study of core indicators for citation evaluation of science and technology journals. China J. Sci. Technol. Res. 2014, 25, 1058–1062. [Google Scholar]
- Yu, L. A study on the selection of nonlinear academic evaluation methods based on neural networks. Intell. Theory Pract. 2021, 44, 63–70, 56. [Google Scholar]
- Esling, P.; Agon, C. Time-series data mining. ACM Comput. Surv. (CSUR) 2012, 45, 1–34. [Google Scholar] [CrossRef] [Green Version]
- Newbold, P. ARIMA model building and the time series analysis approach to forecasting. J. Forecast. 1983, 2, 23–35. [Google Scholar] [CrossRef]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 3146–3154. [Google Scholar]
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K. Xgboost: Extreme gradient boosting. R Package Version 0.4-2 2015, 1, 1–4. [Google Scholar]
- Althelaya, K.A.; El-Alfy ES, M.; Mohammed, S. Stock market forecast using multivariate analysis with bidirectional and stacked (LSTM, GRU). In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–7. [Google Scholar]
- Medsker, L.R.; Jain, L.C. Recurrent neural networks. Design and Applications 2001, 5, 64–67. [Google Scholar]
- Oord, A.V.D.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Harper, C.A.; Lyons, L.; Thornton, M.A.; Larson, E.C. Enhanced Automatic Modulation Classification using Deep Convolutional Latent Space Pooling. In Proceedings of the 2020 54th Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 1–4 November 2020; pp. 162–165. [Google Scholar]
- Bisong, E. Introduction to Scikit-learn. In Building Machine Learning and Deep Learning Models on Google Cloud Platform; Apress: Berkeley, CA, USA, 2019; pp. 215–229. [Google Scholar]
- Das, K.; Jiang, J.; Rao, J.N.K. Mean squared error of empirical predictor. Ann. Stat. 2004, 32, 818–840. [Google Scholar] [CrossRef] [Green Version]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]
- Karunasingha, D.S.K. Root mean square error or mean absolute error? Use their ratio as well. Inf. Sci. 2022, 585, 609–629. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef]
- Shcherbakov, M.V.; Brebels, A.; Shcherbakova, N.L.; Tyukov, A.P.; Janovsky, T.A.; Kamaev, V.A.E. A survey of forecast error measures. World Appl. Sci. J. 2013, 24, 171–176. [Google Scholar]
- Ng, K.Y.; Awang, N. Multiple linear regression and regression with time series error models in forecasting PM10 concentrations in Peninsular Malaysia. Environ. Monit. Assess. 2018, 190, 1–11. [Google Scholar] [CrossRef]
- Kane, M.J.; Price, N.; Scotch, M.; Rabinowitz, P. Comparison of ARIMA and Random Forest time series models for prediction of avian influenza H5N1 outbreaks. BMC Bioinform. 2014, 15, 1–9. [Google Scholar] [CrossRef]
- Shehadeh, A.; Alshboul, O.; Al Mamlook, R.E.; Hamedat, O. Machine learning models for predicting the residual value of heavy con-struction equipment: An evaluation of modified decision tree, LightGBM, and XGBoost regression. Autom. Construct. 2021, 129, 103827. [Google Scholar]
- Alzain, E.; Alshebami, A.S.; Aldhyani TH, H.; Alsubari, S.N. Application of Artificial Intelligence for Predicting Real Estate Prices: The Case of Saudi Arabia. Electronics 2022, 11, 3448. [Google Scholar] [CrossRef]
- Ecer, F.; Ardabili, S.; Band, S.S.; Mosavi, A. Training multilayer perceptron with genetic algorithms and particle swarm optimization for modeling stock price index prediction. Entropy 2020, 22, 1239. [Google Scholar] [CrossRef] [PubMed]
- Cai, M.; Pipattanasomporn, M.; Rahman, S. Day-ahead building-level load forecasts using deep learning vs. traditional time-series techniques. Appl. Energy 2019, 236, 1078–1088. [Google Scholar] [CrossRef]
- Borovykh, A.; Bohte, S.; Oosterlee, C.W. Conditional time series forecasting with convolutional neural networks. arXiv 2017, arXiv:1703.04691. [Google Scholar]
- Ahmed, A.A.; Deo, R.C.; Ghahramani, A.; Raj, N.; Feng, Q.; Yin, Z.; Yang, L. LSTM integrated with Boruta-random forest optimiser for soil moisture estimation under RCP4. 5 and RCP8. 5 global warming scenarios. Stoch. Environ. Res. Risk Assess. 2021, 35, 1851–1881. [Google Scholar] [CrossRef]
- Yamak, P.T.; Yujian, L.; Gadosey, P.K. A comparison between arima, lstm, and gru for time series forecasting. In Proceedings of the 2019 2nd International Conference on Algorithms, Computing and Artificial Intelligence, Sanya, China, 20–22 December 2019; pp. 49–55. [Google Scholar]
- Uyanık, G.K.; Güler, N. A study on multiple linear regression analysis. Procedia-Soc. Behav. Sci. 2013, 106, 234–240. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.C. Artificial neural network. In Interdisciplinary Computing in Java Programming; Springer: Boston, MA, USA, 2003; pp. 81–100. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Dey, R.; Salem, F.M. Gate-variants of gated recurrent unit (GRU) neural networks. In Proceedings of the 2017 IEEE 60th international midwest symposium on circuits and systems (MWSCAS), Boston, MA, USA, 6–9 August 2017; pp. 1597–1600. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Existing Studies of Time Series Forecasting Tasks |
|---|---|
| Multiple Linear Regression | Ng K Y, Awang N use Multiple Linear Regression time series model to forecast PM10 concentrations in Peninsular Malaysia [32]. |
| Random Forest | Kane M J, Price N, Scotch M, et al. use Random Forest time series model to predict avian influenza H5N1 outbreaks [33]. |
| XGBoost | Shehadeh A, Alshboul O, Al Mamlook R E, et al. use machine learning models (XGBoost and LightGBM) to predict the residual value of heavy construction equipment [34]. |
| LightGBM | |
| ANN | Alzain E, Alshebami A S, Aldhyani T H H, et al. use ANN to predict housing prices [35]; Ecer F, Ardabili S, Band S S, et al. train ANN to predict stock price index [36]. |
| Conv-1D CNN | Cai M, Pipattanasomporn M, Rahman S. use Conv-1D CNN model in deep learning to forecast day-ahead building-level load [37]. |
| WaveNet | Borovykh A, Bohte S, Oosterlee C W. use WaveNet to forecast conditional time series [38]. |
| LSTM | Ahmed A A, Deo R C, Ghahramani A, et al. integrate LSTM and Random Forest to estimate soil moisture [39]. |
| GRU | Yamak P T, Yujian L, Gadosey P K. use GRU to forecast time series data with Bitcoin’s price dataset as their time series dataset [40]. |
| Methods | Training Time | Params | MSE | |
|---|---|---|---|---|
| Machine Learning | Multiple Linear Regression | 0.36618 s | - | 0.00044 |
| Random Forest | 134.23013 s | - | 0.00047 | |
| XGBoost | 3.37131 s | - | 0.00058 | |
| LightGBM | 2.57614 s | - | 0.00076 | |
| Deep Learning | ANN | 32.43376 s | 20,161 | 0.00047 |
| Conv-1D CNN | 51.61289 s | 67,145 | 0.00047 | |
| WaveNet | 73.93935 s | 6721 | 0.00050 | |
| LSTM | 108.72789 s | 13,851 | 0.00037 | |
| GRU | 120.08700 s | 18,561 | 0.00046 |
| Methods | MSE | MAE | RMSE | MAPE | NRMSE | 80% | 85% | 90% | |
|---|---|---|---|---|---|---|---|---|---|
| Machine Learning | Multiple Linear Regression | 0.00044 | 0.01393 | 0.02109 | 22.143% | 0.02516 | 68.433% | 55.899% | 40.645% |
| Random Forest | 0.00047 | 0.01342 | 0.02174 | 19.921% | 0.02594 | 71.152% | 59.447% | 43.687% | |
| XGBoost | 0.00058 | 0.01456 | 0.02418 | 21.963% | 0.02884 | 68.203% | 56.359% | 39.862% | |
| LightGBM | 0.00076 | 0.01561 | 0.02764 | 27.961% | 0.03298 | 66.129% | 53.963% | 38.018% | |
| Deep Learning | ANN | 0.00047 | 0.01388 | 0.02165 | 23.472% | 0.02583 | 68.525% | 57.281% | 42.074% |
| Conv-1D CNN | 0.00047 | 0.01369 | 0.02169 | 21.560% | 0.02588 | 69.032% | 58.479% | 42.258% | |
| WaveNet | 0.00050 | 0.01401 | 0.02225 | 22.983% | 0.02655 | 67.604% | 56.866% | 41.567% | |
| LSTM | 0.00037 | 0.01238 | 0.01914 | 19.704% | 0.02283 | 72.442% | 61.521% | 46.083% | |
| GRU | 0.00046 | 0.01304 | 0.02154 | 19.972% | 0.02570 | 71.521% | 60.046% | 43.548% |
| Subject Class | MSE | MAE | RMSE | MAPE | NRMSE | 80% | 85% | 90% |
|---|---|---|---|---|---|---|---|---|
| Medicine | 0.00040 | 0.01372 | 0.01990 | 14.032% | 0.03096 | 82.656% | 72.847% | 55.622% |
| Engineering | 0.00034 | 0.01020 | 0.01844 | 20.840% | 0.04779 | 69% | 57% | 44% |
| Pedagogy | 0.00045 | 0.01311 | 0.02123 | 27.958% | 0.03149 | 71.622% | 59.459% | 44.595% |
| Technical Science | 0.00018 | 0.00902 | 0.01330 | 19.659% | 0.03335 | 69.412% | 58.235% | 44.706% |
| Economic | 0.00086 | 0.01806 | 0.02924 | 35.588% | 0.04092 | 53.947% | 43.421% | 31.579% |
| Transportation | 0.00015 | 0.00969 | 0.01237 | 17.177% | 0.07558 | 61.538% | 50% | 30.769% |
| Social Science | 0.00030 | 0.01213 | 0.01743 | 17.112% | 0.02764 | 68.868% | 53.774% | 36.792% |
| Natural Science | 0.00036 | 0.01278 | 0.01887 | 22.791% | 0.06288 | 61.667% | 52.5% | 38.333% |
| Materials Science | 0.00026 | 0.01225 | 0.01599 | 43.718% | 0.12383 | 55.263% | 47.368% | 34.211% |
| Agronomy | 0.00014 | 0.00869 | 0.01180 | 14.211% | 0.05090 | 79.310% | 63.793% | 48.276% |
| Basic Science | 0.00022 | 0.00993 | 0.01477 | 27.944% | 0.05378 | 59.483% | 48.276% | 34.914% |
| Others | 0.00077 | 0.01635 | 0.02775 | 27.026% | 0.03310 | 62.745% | 53.922% | 37.255% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Han, Y.; Chen, M.; Che, Y. Study on Dynamic Evaluation of Sci-tech Journals Based on Time Series Model. Appl. Sci. 2022, 12, 12864. https://doi.org/10.3390/app122412864
Ma Y, Han Y, Chen M, Che Y. Study on Dynamic Evaluation of Sci-tech Journals Based on Time Series Model. Applied Sciences. 2022; 12(24):12864. https://doi.org/10.3390/app122412864
Chicago/Turabian StyleMa, Yan, Yingkun Han, Mengshi Chen, and Yongqiang Che. 2022. "Study on Dynamic Evaluation of Sci-tech Journals Based on Time Series Model" Applied Sciences 12, no. 24: 12864. https://doi.org/10.3390/app122412864