
A Binaural MFCC-CNN Sound Quality Model of High-Speed Train


Abstract
:1. Introduction
- The most commonly used evaluation method is the A-W SPL, and psychoacoustic parameters are also used, but these parameters consider the time domain or frequency domain information individually. They cannot completely reflect the human hearing perception.
- Some studies use linear regression, traditional shallow neural networks, and other techniques to optimize the subjective evaluation, but the time and frequency information of noises have not been considered simultaneously.
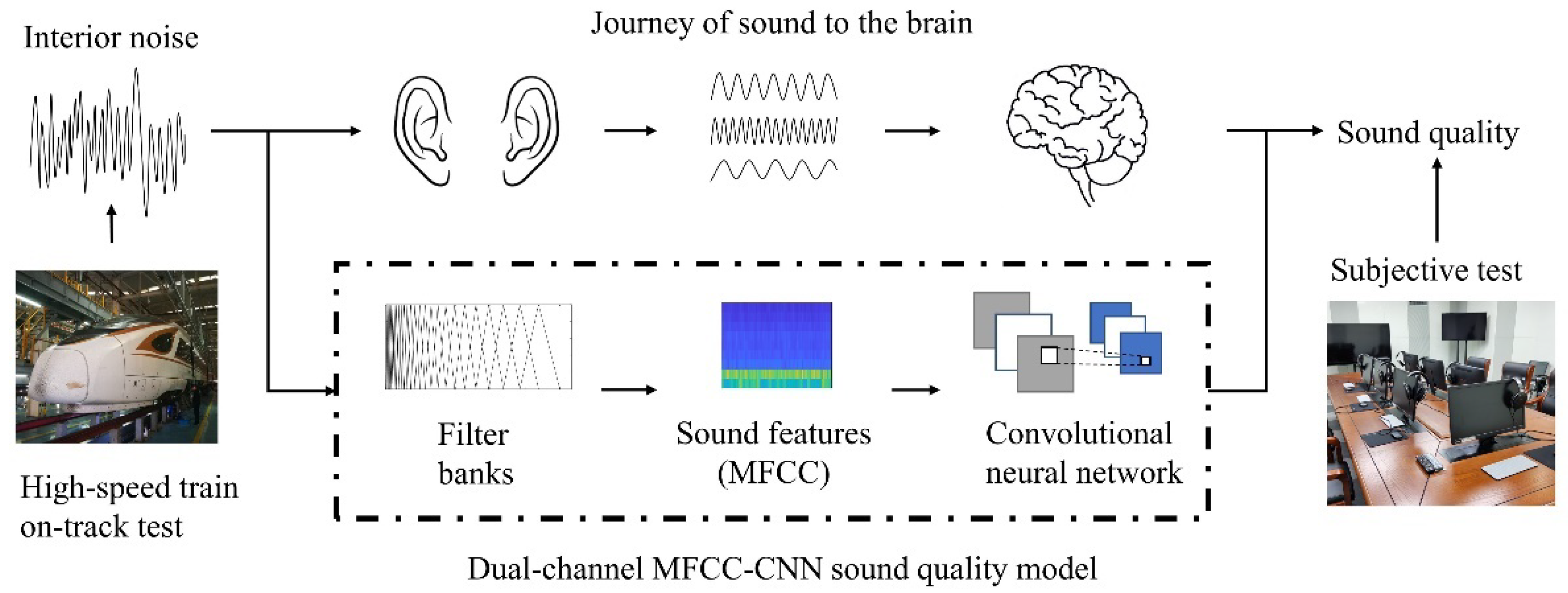
- There are many sound quality models for automotive engineering, but using these models to evaluate the sound quality of HSTs may not be effective. The reason is that the HST travels faster, and its noise is higher and more concentrated below 100 Hz [6]. Meanwhile, automobile noise is more predominant between 100 and 600 Hz [21].
- In most previous studies, the sound samples were collected by microphones, so the influence of binaural hearing could not be considered in the previous models.
- The human auditory system works like a set of filters, so the model uses Mel-scale filter banks to simulate the system. The filter banks separate the input sound signal into multiple components and attenuate the components differently. Compared to the A-W SPL, the Mel-scale filter banks provide a better resolution at low frequencies and less resolution at high frequencies, which mimics the nonlinear human perception of sound.
- The model converts noise data into MFCC features, so both time domain and frequency domain information can be used simultaneously as input parameters for the CNN. At the same time, MFCCs help find out the key information in the noise sample, especially the low-frequency characteristics, thus improving the model accuracy.
- The CNN with multiple hidden layers is used to simulate the brain’s processing of sound signals. It is considered to be more powerful than traditional neural networks because of its high accuracy in speech recognition problems. Each layer of the CNN can be used to extract sound features.
- Two input channels are applied to simulate binaural hearing so that the different sound signals can be processed separately. The time and level differences of sound signals are important factors affecting sound quality.
2. Experimental Procedures
2.1. Noise Data Collection
2.2. Subjective Test
2.2.1. Subject Selection
2.2.2. Jury Evaluation Method
2.2.3. Listening Environment and Test Delivery
3. Methods
3.1. Convolutional Neural Network (CNN)
3.1.1. Input Layer
3.1.2. Convolutional Layer
3.1.3. Pooling Layer
3.1.4. Fully Connected Layer
3.1.5. Output Layer
3.2. Mel-Scale Frequency Cepstral Coefficients (MFCC)
3.3. Binaural MFCC-CNN Sound Quality Model
4. Results and Discussions
4.1. Subjective Evaluation Results and Data Check
4.2. Training Results of the Binaural MFCC-CNN Model
4.3. Performance Comparison with Other Models
4.3.1. Shallow Neural Network Model
4.3.2. The Influence of Binaural Hearing and MFCC
5. Conclusions
- The binaural MFCC-CNN sound quality model has a similar architecture to the hearing system. It better represents the nonlinearity of human hearing and makes the model highly accurate. The model achieved an accuracy of 96.2%. Thus, the proposed model was feasible for the HST sound quality evaluation, and the CNN method was appropriate.
- The sound signals were converted into MFCC features as input parameters for the CNN, so both time domain and frequency domain information can be considered simultaneously. The proposed model considered the influence of the time-varying characteristics of the sound, which led to better performance than the traditional neural network model.
- Two input channels were applied to simulate binaural hearing. The time and the level difference between the two ears were important factors affecting the HST subjective evaluation, and such differences also affected the accuracy of the sound quality model, especially at a low annoyance level. Hence, the monaural MFCC-CNN sound quality model had lower accuracy than the binaural model.
- The MFCC features extracted from the sound signal helped capture the main characteristics of HST noise at high annoyance levels and reduced the input data dimensions. It provided frequency domain information that facilitates the distinction of various noise samples, so the proposed model outperformed the times series sound quality model.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Münzel, T.; Sørensen, M.; Daiber, A. Transportation noise pollution and cardiovascular disease. Nat. Rev. Cardiol. 2021, 18, 619–636. [Google Scholar] [CrossRef] [PubMed]
- Peng, Y.; Fan, C.; Hu, L.; Peng, S.; Xie, P.; Wu, F.; Yi, S. Tunnel driving occupational environment and hearing loss in train drivers in China. Occup. Environ. Med. 2019, 76, 97–104. [Google Scholar] [CrossRef] [PubMed]
- Qian, K.; Hou, Z.; Sun, Q.; Gao, Y.; Sun, D.; Liu, R. Evaluation and optimization of sound quality in high-speed trains. Appl. Acoust. 2021, 174, 107830. [Google Scholar] [CrossRef]
- Standard ISO 532-1:2017; Acoustics—Methods for Calculating Loudness—Part 1: Zwicker Method. International Organization for Standardization: Geneva, Switzerland, 2017.
- Standard ISO 532-2:2017; Acoustics—Methods for Calculating Loudness—Part 2: Moore-Glasberg Method. International Organization for Standardization: Geneva, Switzerland, 2017.
- Luo, L.; Zheng, X.; Hao, Z.-Y.; Dai, W.-Q.; Yang, W.-Y. Sound quality evaluation of high-speed train interior noise by adaptive Moore loudness algorithm. J. Zhejiang Univ. A 2017, 18, 690–703. [Google Scholar] [CrossRef]
- Liu, Z.; Sun, Z.; Liu, S. Study on the Sound Quality Objective Evaluation of High Speed Train’s Door Closing Sound. In Proceedings of the 2015 International Forum on Energy, Environment Science and Materials, Shenzhen, China, 25–26 September 2015. [Google Scholar] [CrossRef] [Green Version]
- Chen, X.; Lin, J.; Jin, H.; Huang, Y.; Liu, Z. The psychoacoustics annoyance research based on EEG rhythms for passengers in high-speed railway. Appl. Acoust. 2021, 171, 107575. [Google Scholar] [CrossRef]
- Park, B.; Jeon, J.-Y.; Choi, S.; Park, J. Short-term noise annoyance assessment in passenger compartments of high-speed trains under sudden variation. Appl. Acoust. 2015, 97, 46–53. [Google Scholar] [CrossRef]
- Hong, J.; Cha, Y.; Jeon, J.Y. Noise in the passenger cars of high-speed trains. J. Acoust. Soc. Am. 2015, 138, 3513–3521. [Google Scholar] [CrossRef] [PubMed]
- Yoon, K.; Gwak, D.Y.; Chun, C.; Seong, Y.; Hong, J.; Lee, S. Analysis of frequency dependence on short-term annoyance of conventional railway noise using sound quality metrics in a laboratory context. Appl. Acoust. 2018, 138, 121–132. [Google Scholar] [CrossRef]
- Meng, F.; Yang, L. Sound Quality Evaluation on Interior Noise in High-speed Trains. In Proceedings of the 40th Annual German Congress on Acoustics, Oldenburg, Germany, 10–13 March 2014. [Google Scholar]
- Chen, P.; Xu, L.; Tang, Q.; Shang, L.; Liu, W. Research on prediction model of tractor sound quality based on genetic algorithm. Appl. Acoust. 2022, 185, 108411. [Google Scholar] [CrossRef]
- Xing, Y.F.; Wang, Y.S.; Shi, L.; Guo, H.; Chen, H. Sound quality recognition using optimal wavelet-packet transform and artificial neural network methods. Mech. Syst. Signal Process. 2016, 66–67, 875–892. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, J.; Guo, P.; Bi, F.; Yu, H.; Ni, G. Sound quality prediction for engine-radiated noise. Mech. Syst. Signal Process. 2015, 56–57, 277–287. [Google Scholar] [CrossRef]
- Lee, H.; Lee, J. Neural network prediction of sound quality via domain Knowledge-Based data augmentation and Bayesian approach with small data sets. Mech. Syst. Signal Process. 2021, 157, 107713. [Google Scholar] [CrossRef]
- Huang, H.B.; Wu, J.H.; Huang, X.R.; Yang, M.L.; Ding, W.P. The development of a deep neural network and its application to evaluating the interior sound quality of pure electric vehicles. Mech. Syst. Signal Process. 2019, 120, 98–116. [Google Scholar] [CrossRef]
- Liang, K.; Zhao, H. Automatic evaluation of internal combustion engine noise based on an auditory model. Shock Vib. 2019, 2019, 2898219. [Google Scholar] [CrossRef] [Green Version]
- Huang, X.; Huang, H.; Wu, J.; Yang, M.; Ding, W. Sound quality prediction and improving of vehicle interior noise based on deep convolutional neural networks. Expert Syst. Appl. 2020, 160, 113657. [Google Scholar] [CrossRef]
- Zhao, B.; Wu, C.J. Sound quality evaluation of electronic expansion valve using Gaussian restricted Boltzmann machines based DBN. Appl. Acoust. 2020, 170, 107493. [Google Scholar] [CrossRef]
- Monaragala, R.M. Knitted structures for sound absorption. In Advances in Knitting Technology; Woodhead Publishing: Sawston, UK, 2011; pp. 262–286. [Google Scholar] [CrossRef]
- Standard ISO 3381:2021; Railway applications—Acoustics—Noise Measurement Inside Railbound Vehicles. International Organization for Standardization: Geneva, Switzerland, 2021.
- Otto, N.; Amman, S.; Eaton, C.; Lake, S. Guidelines for jury evaluations of automotive sounds. SAE Tech. Pap. 1999, 108, 3015–3034. [Google Scholar] [CrossRef] [Green Version]
- Gjestland, T. Standardized general–purpose noise reaction questions. In Proceedings of the 12th ICBEN Congress, Zurich, Switzerland, 18–22 June 2017. [Google Scholar]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE Inst. Electr. Electron. Eng. 1998, 86, 2278–2324. [Google Scholar] [CrossRef]























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Annoyance Level | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| Description | Not at all | Slightly | Moderately | Very | Extremely |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruan, P.; Zheng, X.; Qiu, Y.; Hao, Z. A Binaural MFCC-CNN Sound Quality Model of High-Speed Train. Appl. Sci. 2022, 12, 12151. https://doi.org/10.3390/app122312151
Ruan P, Zheng X, Qiu Y, Hao Z. A Binaural MFCC-CNN Sound Quality Model of High-Speed Train. Applied Sciences. 2022; 12(23):12151. https://doi.org/10.3390/app122312151
Chicago/Turabian StyleRuan, Peilin, Xu Zheng, Yi Qiu, and Zhiyong Hao. 2022. "A Binaural MFCC-CNN Sound Quality Model of High-Speed Train" Applied Sciences 12, no. 23: 12151. https://doi.org/10.3390/app122312151