1. Introduction
One of the most typical deep learning algorithms is Convolutional Neural Networks (CNN). In recent decades, significant advancements in computer-aided diagnosis have been made thanks to the significant usage of CNNs in several domains of medical image analysis. A deep learning algorithm converts a problem into an improvement issue and solves the difficulty of using various optimization approaches. The improvement function is made up of a large number of hyperparameters that are defined before the learning process and influence how well the deep learning algorithm fits the model to the data. Internal CNN model parameters, such as the weights of a neural network, may be learned from the data during the model training phase, but hyperparameters are not. We want to identify a set of hyperparameter values that generate the greatest moment on the data in a fair length of time before we start the training phase. This is referred to as hyperparameter adjustment or optimization. It is critical to the accuracy of deep learning algorithms’ predictions. Furthermore, there is no apparent link between deep learning computational efficiency and hyperparameters. It is required to tweak a large number of hyperparameters on a regular basis and train various CNN models with various combinations of hyperparameters values, then compare model performance to select the optimal model. As a result, how to maximize hyperparameters in a deep learning algorithm becomes a critical topic [
1].
Manual adjustment of deep learning models is feasible, but it is extremely reliant on the user’s knowledge and understanding of the key problem. Manual tweaking may still be impossible due to variables such as time-consuming model assessments and non-linear hyperparameter correlations among dozens or even hundreds of hyperparameters in complex models. This schematic design of defining model hyperparameters has been highlighted as an issue that impedes the adoption of deep learning approaches in AI-related challenges, prompting greater research into algorithms for performing autonomous hyperparameter optimization [
1]. Furthermore, improvements in performance for certain benchmark issues have been observed not just from the introduction of brand-new, original deep learning models, but also from the discovery of superior hyperparameter combinations for existing models.
Manual search and automated search techniques are the two basic types of hyperparameter optimization approaches. Manual search is a method of manually tweaking and testing hyperparameter settings. It is based on the basic intuition and expertise of professional users who can discover the crucial elements that have a stronger influence on the outcomes and then utilize visualization tools to evaluate the link between specific hyperparameters and final outputs. Manual searching necessitates a greater sense of competence learning and technical expertise on the part of the user. It is also difficult for non-expert users to apply. Optimizing hyperparameters is a difficult task to repeat. Furthermore, as the number of hyperparameters and the list of values grows, it becomes exponentially more difficult, since individuals are not adept at dealing with high-dimensional data and are prone to misinterpreting or overlooking patterns and correlations in hyperparameters [
2].
In the search for an automated method of hyperparameter tuning, the process of picking the best hyperparameter for a deep learning model is frequently stated as a Black Box Optimization (BBO) issue. No inherent component of the deep learning model’s assessment is taken into account in this scenario. As a result, the CNN is viewed as an undetermined optimization problem that translates a collection of hyperparameters to a performance score, which is the only data in the optimization algorithm. The problem is also stated to be of a global type since the optimization problem cannot be guaranteed to be convex due to the unstable nature of the mapping. Given the possibility of several local optima, most optimization techniques for global issues in deep learning models include a mechanism for balancing the exploration of new regions in the input space against the exploitation of previously high-quality solutions.
Automatic search strategies, such as Grid Search (GS) [
3] or Cartesian product based hyperparameter search has been developed to solve the limitations of a manual search. Grid Search works on the premise of thorough searching. Grid Search educates a deep learning model on the training sample with all possible hyperparameters and its list of values and assesses its achievement on a cross-validation set using a preset measure. Finally, grid search generates hyperparameters with the best results. Although this method obtains automatic tuning and can potentially obtain the global optimal value of the optimization accusative function, it undergoes the dimensionality curse, which means that the algorithm’s efficiency declines as a large number of hyperparameters and its list of values being optimized and the scope of hyperparameter values increases.
The Random Search method [
3] was suggested to overcome the problem of high computational cost in a grid search, and it was discovered that only a few of the hyperparameters are truly relevant for most data sets. Limiting the examination to non-essential hyperparameters, the overall efficiency may be increased, and the model equation of the optimization function can be achieved. Random search tries a variety of value possibilities at random. It is more efficient in a high-dimensional space than Grid Search [
4]. Random search, on the other hand, is unsatisfactory for training some complicated CNN models, as reveals [
3].
As a result, getting the automated optimization technique to attain high precision and accuracy has always been an issue in deep learning that has not been entirely solved. A hyperparameter tweaking problem is one in which the optimization goal function is unknown or a black-box function. Conventional optimization approaches such as the Newton’s method and gradient descent are ineffective. In this type of optimization issue, Bayesian optimization is a very successful optimization approach [
5]. Using the Bayesian formula, it incorporates prior knowledge about the unknown function of the population parameters to produce posterior knowledge about the function probability. Then, using this posterior data, we can figure out where the function gets its best value. The Bayesian optimization technique beats other global optimization methods in experiments [
6]. As a result, we proposed the Adaptive Hyperparameter Tuning method based on Bayesian optimization and on the Gaussian process to adjust deep learning hyperparameters. If we assume that the optimization function follows a Gaussian distribution, we may calculate the prior distribution of hyperparameters. The Bayesian optimization approach is based on the Gaussian process will be presented in depth in the following sections. The proposed mechanism is then tested on the proposed CNN Deep-Hist [
7] and on three different pretrained deep learning models such as ResNet, DenseNet, and MobileNetV2 to see if it works.
Fourfold contributions are evaluated in this work. First, the main theme of this study is to propose Adaptive Hyperparameter Tuning (AHT) for the selection of optimized hyperparameters to classify and analyze medical images. Second, we present a unique stable CNN model for healthcare image classification that incorporates the benefits of the Separable Convolution with a residual learning framework (ResNet) to enhance the exchange of knowledge and development ease. Third, we provide CNN model settings—providing a combination of hyperparameters with fewer parameters, cheaper space and quicker classification, making them more acceptable for healthcare applications. Fourth, we show that optimization algorithms can be effectively used to create CNN categorization designs.
We used medical image datasets such as BreakHis [
8], BraTS [
9], COVID-19 X-ray [
10] and NIH X-ray [
11] utilizing freely available information and pretrained CNN models such as ResNet, DenseNet and MobileNetV2. Almost all CNN hyperparameters are automatically tuned by the proposed Adaptive Hyperparameter Tuning (AHT) algorithm. The first task is to optimize the hyperparameters of the pretrained CNN models for image classification using the medical image dataset as BreakHis [
8], BraTS, COVID-19 X-ray, and NIH X-ray. The second task involves optimizing the hyperparameters of a proposed neural network model for modeling using the medical imaging datasets. This study uses various medical imaging modalities such as BraTS for brain cancer, an X-ray of COVID19 and Histopathological images (BreakHis) of Breast Cancer. These modalities cover the most critical diseases and spread all over the world. The most recent state-of-the-artwork of Hyperparameter Optimization is reviewed in
Section 2. In
Section 3, we explain the basic preprocessing methodologies and provide the detailed thinking and implementation of the proposed Adaptive Hyperparameter Tuning (AHT) model.
Section 5 comprises the training and testing results of various hyperparameters on three different medical imaging modalities and datasets. The final
Section 6 concludes this study.
3. Proposed Methodology
The proposed algorithm depicted in
Figure 2 is based on the hyperparameter optimization algorithm Surrogate Model (SM), Acquisition Function (AF), and Tree Parzen Estimator (TPE). When resolving a complicated issue, a penalty-based boundary intersection decomposition strategy is chosen because it gives equally scattered alternatives on the perimeter areas of the Pareto Front and has a limited handful of weight vectors. This is significant in our scenario since training CNN models are strongly non-convex optimization issues, and the AHT-based learning model uses a limited amount of weight matrix to minimize computing complexity. On the other hand, the penalty-based boundary intersection technique, necessitates the determination of a compensation element to optimize the uniformity and variability of the results. On the BraTS MRI and BreakHis dataset, we used the AHT algorithms with 10 lists of hyperparameters with different ranges and with penalty component settings of 0.25, 0.5, 0.75, 1, 3, 5, 7, and 10 for the proposed Deep-Hist neural network. Component 7 was chosen since it gave a varied collection of responses that performed significantly in the optimal solutions. This penalty component has also been utilized in other experiments with positive outcomes. The intensities of the optimization methods can vary in numerous situations. A normalizing procedure is required in these circumstances to approach the optimization method’s output to a similar magnitude and reduce biases while choosing non-dominated spots. This normalization is critical in the suggested methodology since the accuracy and F1-Score yield values between [0→1], whereas the range of learnable parameters in a system might easily reach thousands.
Adaptive Hyperparameter Tuning (AHT) steps for determining the best Hyper settings are as follows:
In this approach, to find the optimal hyperparameters of deep learning algorithms that bring back the plausible performance. The representation of hyperparameter optimization is depicted in Equation (
3).
depicts the optimized hyperparameters list that predicts the lowest error,
which is an objective function to minimize the error (Root Mean Squared Error (RMSE)). In this approach, there is a surrogate function that optimizes the objective function on each iteration and selects the next hyperparameter.
The objective function () is the main evaluator that finds the optimal set of hyperparameters. Generally, It takes a simple set of hyperparameters and returns a negative score and according to the returned score, the set of hyperparameters will adjust for the next iteration.
Using the surrogate function, we can approximate the objective function by proposing parameters to the objective function. A Gaussian Process (GP) depicted in Equation (
4) is simply a specific term for a method that takes two values in the input vector,
and
, as an argument and determines how “related” they are depending on a certain idea of “connection.” Tree Parzen Estimator (TPE – depicted in Equation (
5)) and Random Forest Regression (RFR).
where
then
. The duration of the swivels is determined by the
ℓ factor. Usually, it will not be possible to estimate greater than
ℓ units from the empirical observations. Similarly, the
establishes our function’s total difference from its mean value. In short,
and
ℓ define the function’s horizontal and vertical domains.
Upper Confidence Bound (UCB) comprises explicit exploitation
and exploration
components and is perhaps as straightforward as an acquisition function can acquire (
7).
The exploitation vs. exploration decision is simple and easier to tweak with upper confidence bound via the hyperparameter . The upper confidence bound is a weighted total of the anticipated efficiency recorded by the Gaussian Process and the ambiguity represented by the gaussian process’s standard error . When is modest, AHT will favor alternatives that are likely to function well, i.e., have a large . On the opposite, when is big, AHT encourages the discovery of previously unexplored portions of the solution space.
The Surrogate Model (SM) and the Acquisition Function (AF) are critical components of an Adaptive Hyperparameter Tuning (AHT) proposed algorithm. Surrogate models are frequently Gaussian Processes (GP) that can accommodate recorded datasets while quantifying the ambiguity of unseen regions. As a result, the surrogate model is to attempt to estimate the mysterious black-box function . The AF then “reviews” the surrogate model to identify which regions of the scope of are worthy of utilizing and which regions are worth investigating. As a result, the acquisition function has a great premium in locations in which is ideal, or in regions where we have still not examined. On the opposite, the acquisition function expected score is modest in places where is unsatisfactory or where we have recently tested. We determine the next wild estimate to attempt by identifying the that maximizes the AF instead of explicitly maximizing , whose analytical version we do not know, we instead maximize the acquisition function which is considerably simpler to perform and significantly less costly.
From the above mentioned algorithms, we apply the Tree Parzen Estimator, and the output of the algorithm is forward to the selection function. In this step, three common algorithms (Probability of Improvement (PI), Lower/Upper Confidence Bound (L/UCB), and Expected Improvement (EI)) are used for calculating expected improvements. The mathematical calculation of the most commonly used algorithm is depicted in Equation (
8).
We want to maximize f(
), and the best option we have so far is
. Then we can describe “improvement,” I(
) in Equation (
8). As a result, if the incoming
we are considering has an underlying quantity f(
) that is smaller than f(
), f(
) − f(
) is negligible. Therefore, we are not getting any better, because the above calculation produces 0 because the largest amount among any negative integer and 0 is 0. If the revised number f(
) is greater than our present best guess, then f(
) − f(
) is optimistic. If we analyze f at the new location
, I(
) yields the change, which is how significantly we will enhance our existing best answer.
where CDF is the cumulative probability function,
is the average of surrogate function,
shows the optimal average of the surrogate function founds so far, and
is the standard deviation of the surrogate function.
Exploitation (evaluating at locations where the surrogate mean is low) and exploration (evaluating at sites where the surrogate variance is less) are trade-offs in acquisition functions. The employed acquisition function O(F) is optimized over the surrogate model to determine the next hyperparameters to assess. (In this case,
f =
and F
is the new hyperparameter value.) We add probabilistic modules in one of the most commonly utilized acquisition functions in the literature is the Probabilistic Expected Improvement Criterion. Expected Improvement (EI) is given as:
where
In the end, we leveraged the assumption that the PDF of a normally distributed is symmetrical, therefore
=
). Therefore, this equation may appear frightening, but it is not. So, whenever would EI(x) take on a bigger number and when
. That is, the Gaussian Process’s average value is large at
. When there is a bunch more ambiguity, the expected improvement increases, so when
> 1. Through the meantime, the equation above applies for
; alternatively, if
= 0 (as at the recorded data points), EI(
) = 0. While we go, there is one more thing. We can smooth the AHT algorithm’s exploitation vs. exploration by inserting a (hyper)parameter(F) into the equation for EI(x). Therefore, the complete equations are (
11) and (
12).
where f
shows the optimized hyperparameter values, and
is the posterior mean.
and
are the mean and the standard deviation of the GP posterior predictive at
, respectively.
and
are the CDF and PDF of the standard normal distribution, respectively.
The depicted
Figure 1 has list of hyperparameters
“nu” as numbers of Neurons,
“af” as Activation Functions (‘relu’, ‘sigmoid’, ‘softplus’, ‘softsign’, ‘tanh’, ‘selu’, ‘elu’, ‘exponential’, LeakyReLU, ‘relu’),
“opt” as Optimizer (‘SGD’, ‘Adam’, ‘RMSprop’, ‘Adadelta’, ‘Adagrad’, ‘Adamax’, ‘Nadam’, ‘Ftrl’, ’SGD’) “lr” as learning rate (0.01–1),
bs as Batch Size (4–256), ep as epochs (20–100), lyr as layers (1–3), norm as Normalization (0–1), drop as the drop-out rate (0–0.3) and k as Kernel (3–9).
For getting optimized hyperparameters, we used a combined dataset and evolved with a single hyperparameter (learning rate) and acquired two optimal learning rates (0.001 and 0.0001).
In this study, we analyze that Gaussian Process (GP) works inefficiently in categorical hyperparameters such as activation functions and Optimizers. When using several kernels in Gaussian Process (GP), it can be challenging to choose optimal hyperparameters. In Tree Parzen Estimators (TPE), the selection of hyperparameters is independent and there is zero correlation between hyperparameters. It starts model overfitting and increases validation error if we train our model without regularization with more epochs.
We have proposed a novel and hybrid approach for acquiring optimized both numerical and categorical hyperparameters as well. In this approach, we take a sample of the dataset (BraTS21) and forward to a neural network black box model with a list of hyperparameters and pass these hyperparameters to both Gaussian Process (GP) and Tree Parzen Estimator (TPE) and obtain the optimal values with our proposed approach to handle the categorical and create a correlation between hyperparemters and then pass the optimal values to acquisition function and reiterate the procedure.
The posterior distribution improves with each iteration, and the algorithm gets more secure in determining which portions of the parameter domain are worth examining and which are not. AHT additionally employs an acquisition function (exploration strategy or infill sampling criteria) to aid in the selection of the next location to be assessed.
5. Result and Discussion
The models (pretrained models such as ResNet, DenseNet, MobileNetV2, and our customized model Deep-Hist which is used for the diagnosis of cancer on Breast Histopathological images [
7]) were first trained with a learning rate of [0.01, 0.001, 0.0001 and 0.00001], epoch size are [20, 40, 60, 80], batch size of [8, 16, 32, 64] and kernel/filter size of [3, 5, 7, 9]. The models are trained on a variety of datasets such as COVID-19 Xray [
10], BreakHis [
8], and Brain Tumor Segmentation (BraTS) Challenge in 2020 and 2021 and obtained the maximum baseline accuracy of 95.71 percent depicted in
Table 1,
Table 2 and
Table 3.
Table 1,
Table 2 and
Table 3 depicts the AHT optimal set of hyperparameters using the surrogate model and a combination of the Gaussian process and Tree Parzen Estimator methodologies. It can be seen that the hyperparameters used with the presented AHT optimization model, such as kernel sizes and activation functions are identical. The major distinction is determined by the set of the kernel and the selection of the learning rate. Thus, the decrease in the number of learnable parameters is the significant enhancement of our method over the other Bayesian Optimization approach. The AHT optimization algorithm managed to construct a CNN model that was 79% lighter than the ResNet, 61% lighter than the DenseNet, and 44% less than the capacity of the MobileNetV2. Our proposed algorithm is offering muchly improved or comparable classification performance. The reduction in the number of learnable parameters reduces the time for training, forecasting time, and the demand for processing capacity significantly.
In this study, Algorithm 1 is initially used to optimize architectural hyperparameters. After the basic hyperparameters have been determined, Algorithm 1 is used to fine-tune the elegant adjustment hyperparameters. The proposed method is applied to the training set using a 5-fold cross-validation strategy in this suggested study. The provided datasets are divided into five sections, four of which are utilized for training and the fifth for testing. There are 23,950 images in the classification job, which are randomly divided into training, validation, and test sets in an 80:10:10 ratio.
The proposed method, in essence, assesses the optimal hyperparameter value combinations and returns the one with the highest accuracy. To obtain the best accuracy in Algorithm 1, four hyperparameters must be modified. Combining these hyperparameter values can be conducted in various ways, including 4 values of the learning rate, four values of Kernel, four values of activation function, and four of batch size. For the binary classification job, the performance of the recommended models such as ResNet, DenseNet, MobileNetV2, and Deep-Hist are evaluated using a 5-fold cross-validation technique. The combined data set is divided into five sections, with four used for training and the fifth for testing/validation. The experiments are carried out five times. After evaluating the task’s performance of the classifier for each fold, the model’s average classification demonstration is computed.
The CNN convolution layer activation may be used to see what properties CNN has learned after training. Color and borders are taught by the initial layer of the CNN framework, whereas more intricate properties like tumor/feature borders are learned by the CNN framework’s convolution layers. The features of subsequent convolution layers are produced by combining the information learned by preceding convolution layers. The early layer of CNN for the classification duty has 128 channels into 96. The forward convolution layer, which includes 96 channels, which are 2D tensors, makes up each layer of CNN. Pixels whose value is near 255 have a lot of positives, whereas pixels whose value is near 0 have negative activations in these images. In the same way, gray pixels in the input image represent weakly active channels. Without ever being asked to learn about malignancy, it is plausible to assume that CNN has discovered that malignant features are distinguishing characteristics that can be used to differentiate across binary classes. Unlike previous CNN models, which were often created to be problem-specific, this convolution neural network model may learn important properties on its own. In this article, learning to detect malignant and benign aids in the differentiation of a malignant image from a benign image.
| Algorithm 1 Proposed algorithm Adaptive Hyperparameter Tuning (AHT). |
AHT F tuning function
unified distribution of hyperparameters, = , , , …, .
Require: Evaluate the real objective cost function O(F) for random hyperparameter points
F in the hyperparameter space.
while do
if is ∈ C then
Ensure: Create a surrogate model (Tree Parzen Estimator model) to estimate the genuine
unbiased cost function using the specified hyperparameter (F) variables and recorded
events.
HyperDistance(, )
else if is ∈ R then
Ensure: Create a surrogate model (Gaussian Process model)
Ensure: Using a hybrid acquisition function (AF), we retrieve the optimal hyperparameter
value F. HyperDistance(, )
Update the statistical Acquisition Function (AF) model, + =
Train the different pretrained model and the proposed model Deep-hist using
optimized hyperparameters (). Compare the accuracy and F1-Score and re-evaluate
with the next closest hyperparameter.
We normalize the accuracy and F1-Score of the training of different training
iteration by setting [, …, ].
end if
end while
procedure HyperDistance(, )
For each vector of hyperparameter ∈ [, , …] determine the accuracy
w.r.t closest next expected hyperparameter using Euclidean Distance.
return
end procedure |
The quality of the recommended model is evaluated using the 5-fold cross-validation technique for binary classification. The data set is divided into five sections, four of which are used for training and the fifth for testing. The trials are repeated five times. After evaluating the task’s performance of the classifier for each fold, the CNN model’s average classification achievement is computed. Because the study contains 23,950 images, there is enough dataset to divide them into 80:10:10 training, validation, and test sets. For testing the trained model, images are chosen at random from each class’s combined dataset to test the model. After 60 iterations, the proposed CNN model for the classification task achieves 95.71 accuracies. These findings back up the CNN model’s ability to classify various types of malignant images. See
Table 4 and
Table 5 and
Figure 3 and
Figure 4 for further information on accuracy measurements such as precision, recall, specificity, accuracy, and sensitivity. As shown in
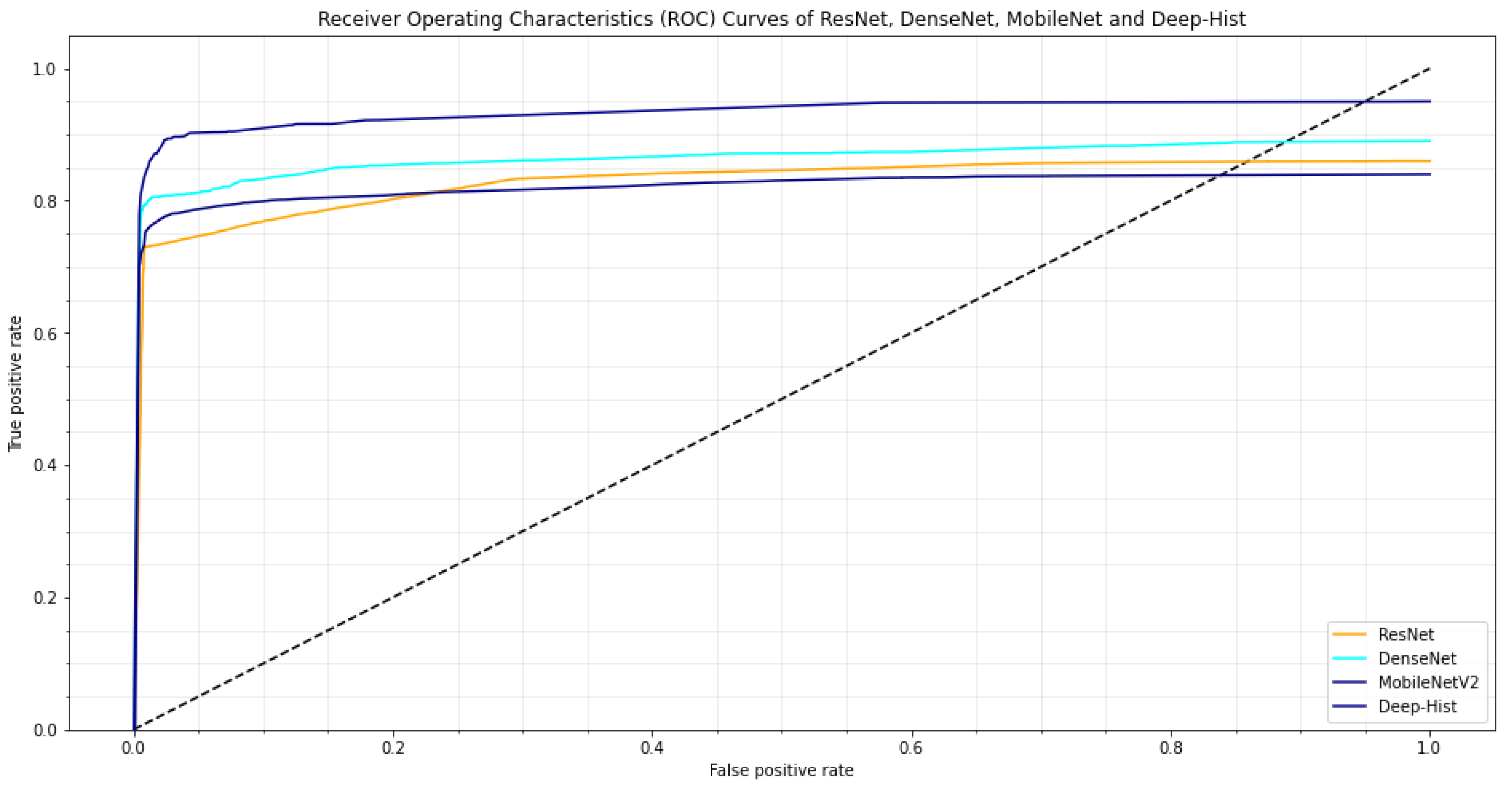
Figure 4, the AUC of the ROC curve is 0.9534 and in
Table 4, ResNet had an 87.76 accuracy rate, DenseNet had an 87.59 accuracy rate and MobileNetV2 had an 84.18 accuracy rate. Large and readily available healthcare data sets are used to obtain acceptable categorization outputs. The classification of malignant types is accurate at 95.71%. The plausible outcomes of the proposed framework are evaluated using performance assessment metrics such as ROC curve AUC, precision, specificity, accuracy, and sensitivity.
The use of pretrained Convolutional Neural Network models and our proposed model Deep-Hist to categorize images has lately become popular in the diagnosis of medical analysis. The kind of malignant disease is determined using CNN models in this study. The key hurdle with CNN is figuring out which network architecture is the most successful for a specific situation. Choosing the right hyperparameters is crucial for getting good results, especially with convolutional neural networks. Adaptive Hyperparameter Tuning (AHT) is proposed in this study to construct the most effective CNN framework and to improve the hyperparameters of the CNN models. Large and readily available healthcare data sets such as BreakHis, BraTS, and NIH-Xray are used to obtain plausible classification outputs. The classification of malignant types is accurate at 95.71%. The outcomes of the proposed framework are evaluated using performance assessment metrics such as ROC curve AUC, precision, specificity, accuracy, and sensitivity depicted in
Table 4 and
Table 5.
It is fascinating to compare the outputs of the proposed CNN model Deep-Hist to those of current dominant advanced CNN models such as ResNet, DenseNet, and MobileNetV2. The same experiment is run with the same combined dataset (COVID-19, BreakHis, NIH-Xray, and BraTS), using well-known pretrained CNNs such as ResNet, DenseNet, and MobileNetV2.
Table 4 shows the outcomes of these models. The proposed CNN model Deep-Hist and many common architectures are compared in terms of accuracy and AUC obtained during the experiments.
Table 4 and
Table 5 shows that the proposed CNN model Deep-Hist outperforms other networks in the classification test. In the task of classification, the DenseNet model, which is close to the proposed CNN model, achieves an accuracy of 87.59%. Pretrained deep learning frameworks for common image classification issues are constructed and learned on generic data sets, which might explain why the proposed CNN models outperform them. On the other hand, the proposed CNN model is designed for a more specific task, namely Breast Cancer classification. In addition, the proposed model Deep-Hist is trained and evaluated using Histopathological images of Breast Cancer, NIH-Xray images of lungs, COVID-19 images of lungs X-ray, and Brain tumors of BraTS. Another factor why the proposed CNN model “Deep-Hist” surpasses the pretrained models is that the proposed CNN architecture was enhanced specifically for the categorization job and used the hyperparameters that generate the optimal results.
Figure 4 also shows that a recall of 0.5 percent denotes that the classification algorithm has a large number of false negatives, which can be caused by imbalanced classes or untuned model hyperparameters, whereas a recall of 1.0 percent demonstrates that the classifier has confidently predicted for the extracted features. Furthermore, when the Area Under the Curve (AUC) is 1 or close to 1, the classification algorithm has successfully discriminated all positive and negative class points, but when AUC is zero, the classification algorithm classified all negatives as positives and vice versa. The True Positive Rate (TPR) is shown against the False Positive Rate (FPR) at varying levels of intensity on the Receiver Operating Characteristics (ROC) Curve.
Figure 4 illustrates how classifiers with curves closer to the upper left corner perform better. In addition, when the classifier curve approaches the ROC space’s 45
diagonal, the test becomes less accurate. A probability in the range [0.0, 0.49] implies a negative result (0), whereas a probability in the range [0.5, 1.0] suggests a positive event (1). The Deep-Hist accuracy is 0.95, ResNet = 0.87, MobileNetV2 = 0.84, and DenseNet = 0.88 are closer to the top left corner in the experimental findings.
The two initial hyperparameters which as epochs and kernel/filter values steer the search toward the local maximum on the right side; however, exploration forecasts the algorithm to baffle from that topical optimum and determine the global on the left. We observe how the two hyperparameter point ideas frequently occur in high-uncertainty zones (exploration) and are not just based on the high-degree surrogate function values.
The experimental results and statistical analysis present that while a Random Search (RS) may be effective for a small dataset, it is insufficient for a medium-scale dataset. Due to the intrinsic unpredictability of the acquisition procedure, RS surpasses Grid Search (GS) and Bayesian Optimization (BO) in some circumstances. In comparison, the proposed hyperparameter optimization technique (AHT) is disciplined, with a model-based approach and theoretically sound hyperparameter adjustment. As a result, it is a good choice for large-sized datasets and complicated patterns. The empirical results and statistical analysis further show that the number of hyperparameters to be adjusted, the size of the dataset, and the Imbalance ratio all influence the choice of the HPO method for CNN models. The findings of this study’s trials show that, when compared to Grid Search and Random Search, AHT has the ability to improve classifier demonstration in many circumstances since AHT picks the next hyperparameters with care. As a result, for many of the datasets utilized in this work, it is a superior choice for non-trivial hyperparameter search spaces.
Experiments demonstrate that the Deep-Hist CNN architecture along with the proposed AHT optimization algorithm (Deep-Hist-AHT) may efficiently respond to BreakHis, BraTS, and Covid-19 datasets. Furthermore, the Deep-Hist demonstrates great classification accuracy and F1-Score with acceptable spatial characterization on different pairs of healthcare datasets and outperforms the ResNet, DenseNet, and MobileNetV2 in terms of accuracy, Specificity, Sensitivity, and especially in learnable parameters. The variety in findings shows that simply adjusting the learning rate, activation function and dropout could not be enough to tailor a CNN architecture to different datasets. Furthermore, the collection of optimal hyperparameters we chose for CNN learning framework to adapt and enables the proposed model to suit fresh datasets efficiently. The findings of the Deep-Hist with AHT optimization algorithm and the other pretrained models such as ResNet, DenseNet, and MobileNetV2 with BO approaches indicate that our methodology outperforms the well-known Multi-Objective Bayesian hyperparameter optimization method while delivering significantly smaller structures. Furthermore, it illustrates that using the proposed AHT optimization algorithm to tweak the hyperparameters in the CNN architectures greatly increases the F1-Score, Specificity, and Sensitivity of healthcare datasets.
6. Conclusions
As a response to the rise of deep learning, machine learning research studies have switched from feature engineering to architecture engineering. This work uses CNN models to explain the binary categorization of malignant and benign for the first diagnosis, practically all of which are autonomously adjusted using the Adaptive Hyperparameter Tuning algorithm. A powerful CNN model for identifying malignancy in images is defined using publicly available medical image datasets. The proposed paradigm for classifying medical images into binary classes is 95.71%. The proposed CNN model is trained and assessed on a large enough amount of medical images. The results obtained by the proposed CNN model, as well as comparisons with well-known techniques, demonstrate the CNN model’s utility when developed with the supplied optimization framework. Clinicians and medical practitioners can utilize the CNN model developed in this study to confirm their first screening for malignant and benign binary classification.
The number of repetitions required to estimate the optimized hyperparameters is the suggested AHT optimization algorithm’s shortcoming in comparison to the other proven Bayesian optimization method. Distributed parallelization the learning of potential CNN architectures in each iteration and employing a surrogate-assisted adaptive strategy to decrease the number of architectures taught is workable alternatives to this challenge.
The Deep-Hist model has a fundamental fixed architecture which is a constraint. However, it should be noted that constructing a CNN model entails a large number of optimized hyperparameters that constitute a vast activity effort. To maintain the task numerically and manageably, various hyperparameters must be fine-tuned early. After a complete evaluation of effective CNN models for healthcare image classification, the Deep-Hist constant CNN architecture was established in this study, and it is the strategy that permits the approach to optimize for classification error and model complexity. Furthermore, considering the model’s demonstrated capacity to adjust new healthcare datasets, we feel the unbound collection of hyperparameters offers adequate flexibility.
The approach provided here intends to tackle the prevailing restrictions of adjusting a CNN model to unknown healthcare datasets and user-generated models in medical and clinical situations. In the future, we intend to accelerate the proposed optimization algorithm with other learning frameworks by employing parallel computing methodologies with federated learning and extending the CNN models to dynamically classify and segment 3D/2D healthcare images.








{kind=link}
{kind=link}
{kind=link}
{kind=link}