
Identification of Content-Adaptive Image Steganography Using Convolutional Neural Network Guided by High-Pass Kernel



Abstract
:1. Introduction
- In the proposed scheme, thirty-one kernels are used; thirty are high-pass kernels and one is the neutral kernel.
- Two non-trainable convolutional layers are considered using thirty-one kernels; one layer is used at the beginning of the network and the second before the middle of the network.
- To retain a complete statistical information, down-sampling is not performed.
- The layer-specific learning rate is considered for better results.
- The clipped ReLU layer is applied with a customized cut-off value for better control on the CNN.
- Softmax classifier is the popular choice in CNN. However, several classifiers are investigated and the SVM classifier is the most suitable.
- The outcomes of the proposed scheme are equated with the popular schemes Zhu-Net, SRNet, Yedroudj-Net, and Ye-Net.
- The comprehensive outcomes are discussed for HILL, Mi-POD, S-UNIWARD, and WOW steganography schemes with 0.2, 0.3, and 0.4 bpp payloads.
2. The Proposed Scheme
3. Experimental Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
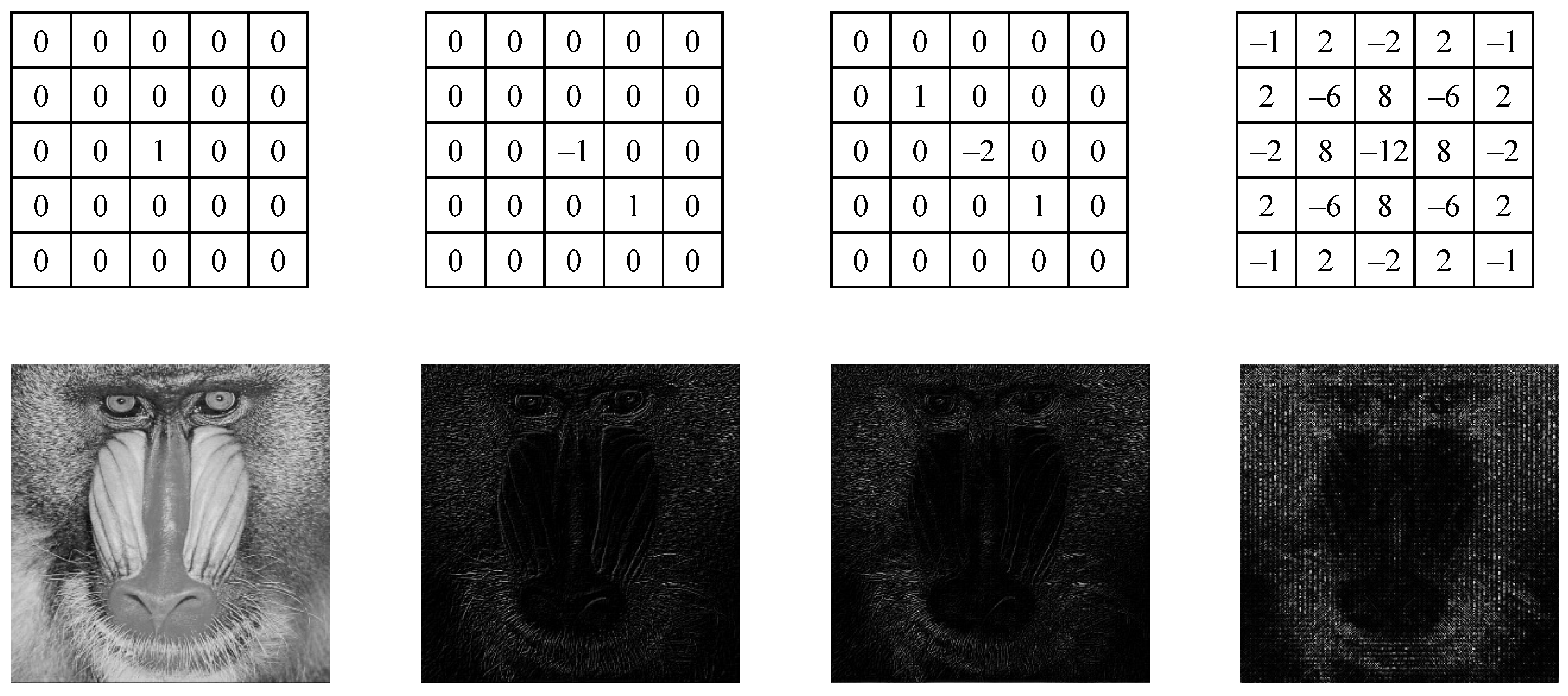{kind=link}
{kind=link}
{kind=link}
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| Thirty Non-trainable kernels | 0.3875 | 0.3242 | 0.2712 | 0.3475 | 0.2583 | 0.2378 | 0.3308 | 0.2166 | 0.1702 | 0.2523 | 0.1888 | 0.1512 |
| Thirty-one Non-trainable kernels | 0.3796 | 0.3198 | 0.2661 | 0.3414 | 0.2548 | 0.2343 | 0.3234 | 0.2132 | 0.1682 | 0.2491 | 0.1857 | 0.1484 |
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| Single Non-trainable Layer | 0.3925 | 0.3287 | 0.2739 | 0.3489 | 0.2624 | 0.2420 | 0.3337 | 0.2217 | 0.1749 | 0.2545 | 0.1905 | 0.1521 |
| Two Non-trainable Layers | 0.3796 | 0.3198 | 0.2661 | 0.3414 | 0.2548 | 0.2343 | 0.3234 | 0.2132 | 0.1682 | 0.2491 | 0.1857 | 0.1484 |
| Three Non-trainable Layers | 0.3841 | 0.3246 | 0.2696 | 0.3479 | 0.2578 | 0.2390 | 0.3289 | 0.2157 | 0.1707 | 0.2525 | 0.1894 | 0.1503 |
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| Fixed learing rate | 0.3898 | 0.3278 | 0.2715 | 0.3506 | 0.2606 | 0.2388 | 0.3289 | 0.2164 | 0.1731 | 0.2548 | 0.1898 | 0.1516 |
| Layer-specific learning rate | 0.3796 | 0.3198 | 0.2661 | 0.3414 | 0.2548 | 0.2343 | 0.3234 | 0.2132 | 0.1682 | 0.2491 | 0.1857 | 0.1484 |
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| ReLU | 0.3856 | 0.3236 | 0.2720 | 0.3462 | 0.2581 | 0.2397 | 0.3302 | 0.2170 | 0.1721 | 0.2540 | 0.1900 | 0.1519 |
| Cipped ReLU | 0.3796 | 0.3198 | 0.2661 | 0.3414 | 0.2548 | 0.2343 | 0.3234 | 0.2132 | 0.1682 | 0.2491 | 0.1857 | 0.1484 |
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| Softmax Classifier | 0.3854 | 0.3262 | 0.2735 | 0.3476 | 0.2620 | 0.2422 | 0.3298 | 0.2202 | 0.1757 | 0.2553 | 0.1933 | 0.1567 |
| SVM Classifier | 0.3796 | 0.3198 | 0.2661 | 0.3414 | 0.2548 | 0.2343 | 0.3234 | 0.2132 | 0.1682 | 0.2491 | 0.1857 | 0.1484 |
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| SRNet | 0.4560 | 0.3789 | 0.3305 | 0.4221 | 0.3417 | 0.2806 | 0.3568 | 0.2686 | 0.2225 | 0.2850 | 0.2226 | 0.1783 |
| Ye-Net | 0.4672 | 0.4202 | 0.3736 | 0.4311 | 0.3733 | 0.3470 | 0.4058 | 0.3301 | 0.2706 | 0.3228 | 0.2922 | 0.2214 |
| Yedroudj-Net | 0.4710 | 0.4216 | 0.3372 | 0.4294 | 0.3798 | 0.2952 | 0.4122 | 0.3189 | 0.2757 | 0.3074 | 0.2652 | 0.2071 |
| Zhu-Net | 0.3888 | 0.3339 | 0.2878 | 0.3385 | 0.2828 | 0.2576 | 0.3167 | 0.2391 | 0.1951 | 0.2689 | 0.2339 | 0.1489 |
| Proposed Scheme | 0.3796 | 0.3198 | 0.2661 | 0.3414 | 0.2548 | 0.2343 | 0.3234 | 0.2132 | 0.1682 | 0.2491 | 0.1857 | 0.1484 |
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| SRNet | 0.4180 | 0.3468 | 0.3170 | 0.3967 | 0.3212 | 0.2638 | 0.3392 | 0.2495 | 0.2087 | 0.2505 | 0.1832 | 0.1401 |
| Ye-Net | 0.4601 | 0.3994 | 0.3527 | 0.4052 | 0.3509 | 0.3262 | 0.3864 | 0.3065 | 0.2511 | 0.3009 | 0.2402 | 0.1947 |
| Yedroudj-Net | 0.4426 | 0.3819 | 0.3257 | 0.4036 | 0.3570 | 0.2775 | 0.3835 | 0.2968 | 0.2543 | 0.2831 | 0.2130 | 0.1677 |
| Zhu-Net | 0.3718 | 0.3169 | 0.2414 | 0.3209 | 0.2658 | 0.2421 | 0.2875 | 0.2102 | 0.1695 | 0.2315 | 0.1702 | 0.1057 |
| Proposed Scheme | 0.3608 | 0.2867 | 0.2476 | 0.3109 | 0.2495 | 0.2203 | 0.2691 | 0.1922 | 0.1546 | 0.2066 | 0.1561 | 0.1011 |
| Steganography Scheme | HILL | Mi-POD | S-UNIWARD | WOW | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Payload (bpp) | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 | 0.2 | 0.3 | 0.4 |
| SRNet | 0.3739 | 0.3135 | 0.2920 | 0.3095 | 0.2505 | 0.2058 | 0.2930 | 0.2136 | 0.1807 | 0.2226 | 0.1592 | 0.1185 |
| Ye-Net | 0.4324 | 0.3682 | 0.3220 | 0.3161 | 0.2737 | 0.2544 | 0.3599 | 0.2761 | 0.2135 | 0.2847 | 0.2175 | 0.1697 |
| Yedroudj-Net | 0.4093 | 0.3456 | 0.3140 | 0.3148 | 0.2785 | 0.2165 | 0.3479 | 0.2673 | 0.2292 | 0.2608 | 0.1774 | 0.1381 |
| Zhu-Net | 0.3469 | 0.2981 | 0.2291 | 0.2703 | 0.2073 | 0.1889 | 0.2312 | 0.1936 | 0.1400 | 0.1932 | 0.1413 | 0.0795 |
| Proposed Scheme | 0.3166 | 0.2655 | 0.2114 | 0.2482 | 0.1868 | 0.1718 | 0.2129 | 0.1859 | 0.1286 | 0.1765 | 0.1296 | 0.0718 |
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, B.; Wang, M.; Huang, J.; Li, X. A new cost function for spatial image steganography. In Proceedings of the 2014 IEEE International Conference on Image Processing, ICIP 2014, Paris, France, 27–30 October 2014; pp. 4206–4210. [Google Scholar] [CrossRef]
- Sedighi, V.; Cogranne, R.; Fridrich, J. Content-Adaptive Steganography by Minimizing Statistical Detectability. IEEE Trans. Inf. Forensics Secur. 2016, 11, 221–234. [Google Scholar] [CrossRef] [Green Version]
- Holub, V.; Fridrich, J.; Denemark, T. Universal distortion function for steganography in an arbitrary domain. EURASIP J. Inf. Secur. 2014, 2014, 1. [Google Scholar] [CrossRef] [Green Version]
- Holub, V.; Fridrich, J. Designing steganographic distortion using directional filters. In Proceedings of the WIFS 2012—Proceedings of the 2012 IEEE International Workshop on Information Forensics and Security, Costa Adeje, Spain, 2–5 December 2012; pp. 234–239. [Google Scholar] [CrossRef] [Green Version]
- Weber, A.G. The USC-SIPI Image Database: Version 5. USC-SIPI Rep. 2006, 315, 1–24. [Google Scholar]
- Lyu, S.; Farid, H. Steganalysis Using Higher-Order Image Statistics. IEEE Trans. Inf. Forensics Secur. 2006, 1, 111–119. [Google Scholar] [CrossRef]
- Westfeld, A. F5—A Steganographic Algorithm. In International Workshop on Information Hiding; Springer: Berlin/Heidelberg, Germany, 2001; pp. 289–302. [Google Scholar]
- Provos, N.; Honeyman, P. Detecting Steganographic Content on the Internet. 2001. Available online: http://niels.xtdnet.nl/papers/detecting.pdf/ (accessed on 21 January 2022).
- Li, B.; Huang, J.; Shi, Y.Q. Textural features based universal steganalysis. In Proceedings of the Security, Forensics, Steganography, and Watermarking of Multimedia Contents X, San Jose, CA, USA, 27–31 January 2008; p. 681912. [Google Scholar] [CrossRef]
- Pevný, T.; Filler, T.; Bas, P. Using High-Dimensional Image Models to Perform Highly Undetectable Steganography. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2010; Volume 6387, pp. 161–177. [Google Scholar]
- Fridrich, J.; Kodovsky, J. Rich Models for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef] [Green Version]
- Pevny, T.; Bas, P.; Fridrich, J. Steganalysis by Subtractive Pixel Adjacency Matrix. IEEE Trans. Inf. Forensics Secur. 2010, 5, 215–224. [Google Scholar] [CrossRef] [Green Version]
- Denemark, T.; Sedighi, V.; Holub, V.; Cogranne, R.; Fridrich, J. Selection-channel-aware rich model for Steganalysis of digital images. In Proceedings of the 2014 IEEE International Workshop on Information Forensics and Security, WIFS 2014, Atlanta, GA, USA, 3–5 December 2015; pp. 48–53. [Google Scholar] [CrossRef]
- Tang, W.; Li, H.; Luo, W.; Huang, J. Adaptive steganalysis against WOW embedding algorithm. In Proceedings of the 2nd ACM workshop on Information hiding and multimedia security—IH&MMSec ’14, Salzburg, Austria, 11–13 June 2014; pp. 91–96. [Google Scholar] [CrossRef]
- Xu, X.; Dong, J.; Wang, W.; Tan, T. Local correlation pattern for image steganalysis. In Proceedings of the 2015 IEEE China Summit and International Conference on Signal and Information Processing (ChinaSIP), Chengdu, China, 12–15 July 2015; pp. 468–472. [Google Scholar] [CrossRef]
- Mielikainen, J. LSB matching revisited. IEEE Signal Process. Lett. 2006, 13, 285–287. [Google Scholar] [CrossRef]
- Li, F.; Zhang, X.; Cheng, H.; Yu, J. Digital image steganalysis based on local textural features and double dimensionality reduction. Secur. Commun. Netw. 2016, 9, 729–736. [Google Scholar] [CrossRef]
- Li, B.; Li, Z.; Zhou, S.; Tan, S.; Zhang, X. New Steganalytic Features for Spatial Image Steganography Based on Derivative Filters and Threshold LBP Operator. IEEE Trans. Inf. Forensics Secur. 2018, 13, 1242–1257. [Google Scholar] [CrossRef]
- Wang, P.; Liu, F.; Yang, C. Towards feature representation for steganalysis of spatial steganography. Signal Process. 2020, 169, 107422. [Google Scholar] [CrossRef]
- Ge, H.; Hu, D.; Xu, H.; Li, M.; Zheng, S. New Steganalytic Features for Spatial Image Steganography Based on Non-negative Matrix Factorization. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2020; Volume 12022, pp. 337–351. [Google Scholar]
- Li, B.; Wang, M.; Li, X.; Tan, S.; Huang, J. A Strategy of Clustering Modification Directions in Spatial Image Steganography. IEEE Trans. Inf. Forensics Secur. 2015, 10, 1905–1917. [Google Scholar] [CrossRef]
- Qian, Y.; Dong, J.; Wang, W.; Tan, T. Deep learning for steganalysis via convolutional neural networks. Media Watermarking Secur. Forensics 2015, 2015, 94090J. [Google Scholar] [CrossRef]
- Qian, Y.; Dong, J.; Wang, W.; Tan, T. Learning and transferring representations for image steganalysis using convolutional neural network. In Proceedings of the International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar] [CrossRef]
- Xu, G.; Wu, H.-Z.; Shi, Y.-Q. Structural Design of Convolutional Neural Networks for Steganalysis. IEEE Signal Process. Lett. 2016, 23, 708–712. [Google Scholar] [CrossRef]
- Wu, S.; Zhong, S.H.; Liu, Y. Steganalysis via deep residual network. In Proceedings of the International Conference on Parallel and Distributed Systems—ICPADS, Wuhan, China, 13–16 December 2016; pp. 1233–1236. [Google Scholar] [CrossRef]
- Wu, S.; Zhong, S.; Liu, Y. Deep residual learning for image steganalysis. Multimed. Tools Appl. 2017, 77, 10437–10453. [Google Scholar] [CrossRef]
- Ye, J.; Ni, J.; Yi, Y. Deep Learning Hierarchical Representations for Image Steganalysis. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2545–2557. [Google Scholar] [CrossRef]
- Boroumand, M.; Chen, M.; Fridrich, J. Deep Residual Network for Steganalysis of Digital Images. IEEE Trans. Inf. Secur. 2019, 14, 1181–1193. [Google Scholar] [CrossRef]
- Guo, L.; Ni, J.; Shi, Y.Q. Uniform Embedding for Efficient JPEG Steganography. IEEE Trans. Inf. Forensics Secur. 2014, 9, 814–825. [Google Scholar] [CrossRef]
- Yedroudj, M.; Comby, F.; Chaumont, M. Yedroudj-Net: An Efficient CNN for Spatial Steganalysis. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2092–2096. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Zhong, S.; Liu, Y. A Novel Convolutional Neural Network for Image Steganalysis with Shared Normalization. IEEE Trans. Multimed. 2020, 22, 256–270. [Google Scholar] [CrossRef] [Green Version]
- Zhang, R.; Zhu, F.; Liu, J.; Liu, G. Depth-Wise Separable Convolutions and Multi-Level Pooling for an Efficient Spatial CNN-Based Steganalysis. IEEE Trans. Inf. Forensics Secur. 2020, 15, 1138–1150. [Google Scholar] [CrossRef]
- Xiang, Z.; Sang, J.; Zhang, Q.; Cai, B.; Xia, X.; Wu, W. A New Convolutional Neural Network-Based Steganalysis Method for Content-Adaptive Image Steganography in the Spatial Domain. IEEE Access 2020, 8, 47013–47020. [Google Scholar] [CrossRef]
- Wang, Z.; Chen, M.; Yang, Y.; Lei, M.; Dong, Z. Joint multi-domain feature learning for image steganalysis based on CNN. EURASIP J. Image Video Process. 2020, 2020, 28. [Google Scholar] [CrossRef]
- Bas, P.; Furon, T. Break Our Watermarking System. 2008. Available online: http://bows2.ec-lille.fr/ (accessed on 21 January 2022).
- Bas, P.; Filler, T.; Pevný, T. “Break Our Steganographic System”: The Ins and Outs of Organizing BOSS. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2011; Volume 6958, pp. 59–70. [Google Scholar]
- Glorot, Y.B.X. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the thirteenth international conference on artificial intelligence and statistics, Sardinia, Italy, 13–15 May 2010; pp. 249–256. [Google Scholar]
- Hannun, A.; Case, C.; Casper, J.; Catanzaro, B.; Diamos, G.; Elsen, E.; Prenger, R.; Satheesh, S.; Sengupta, S.; Coates, A.; et al. Deep Speech: Scaling up end-to-end speech recognition. arXiv 2014, arXiv:1412.5567. [Google Scholar]
- Singh, B.; De, S.; Zhang, Y.; Goldstein, T.; Taylor, G. Layer-Specific Adaptive Learning Rates for Deep Networks. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 364–368. [Google Scholar] [CrossRef]
- Hermessi, H.; Mourali, O.; Zagrouba, E. Deep feature learning for soft tissue sarcoma classification in MR images via transfer learning. Expert Syst. Appl. 2019, 120, 116–127. [Google Scholar] [CrossRef]
- Alarifi, J.S.; Goyal, M.; Davison, A.K.; Dancey, D.; Khan, R.; Yap, M.H. Facial Skin Classification Using Convolutional Neural Networks. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2017; Volume 10317, pp. 479–485. [Google Scholar]
- Xu, G. Deep convolutional neural network to detect J-UNIWARD. In Proceedings of the 5th ACM Workshop on Information Hiding and Multimedia Security, Philadelphia, PA, USA, 20–22 June 2017. [Google Scholar] [CrossRef]
- Tang, Y. Deep Learning Using Linear Support Vector Machines. arXiv 2013, arXiv:1306.0239. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agarwal, S.; Jung, K.-H. Identification of Content-Adaptive Image Steganography Using Convolutional Neural Network Guided by High-Pass Kernel. Appl. Sci. 2022, 12, 11869. https://doi.org/10.3390/app122211869
Agarwal S, Jung K-H. Identification of Content-Adaptive Image Steganography Using Convolutional Neural Network Guided by High-Pass Kernel. Applied Sciences. 2022; 12(22):11869. https://doi.org/10.3390/app122211869
Chicago/Turabian StyleAgarwal, Saurabh, and Ki-Hyun Jung. 2022. "Identification of Content-Adaptive Image Steganography Using Convolutional Neural Network Guided by High-Pass Kernel" Applied Sciences 12, no. 22: 11869. https://doi.org/10.3390/app122211869