
Effective Dereverberation with a Lower Complexity at Presence of the Noise
Abstract
:1. Introduction
2. Signal Model
2.1. Complex Gaussian Mixture Model
2.2. Multichannel Linear Prediction Reverberation Model
3. Proposed Dereverberation Method
3.1. Algorithm Architecture
3.2. Application of Kalman Filter
3.3. Low-Complexity Algorithm Based on the Kronecker Product
3.4. Initialization of Kalman Filtering
4. Experiments and Evaluation
4.1. Acoustic Scenario and Experimental Setup
4.2. Reference Methods
4.3. Analysis and Comparison of the Test Results
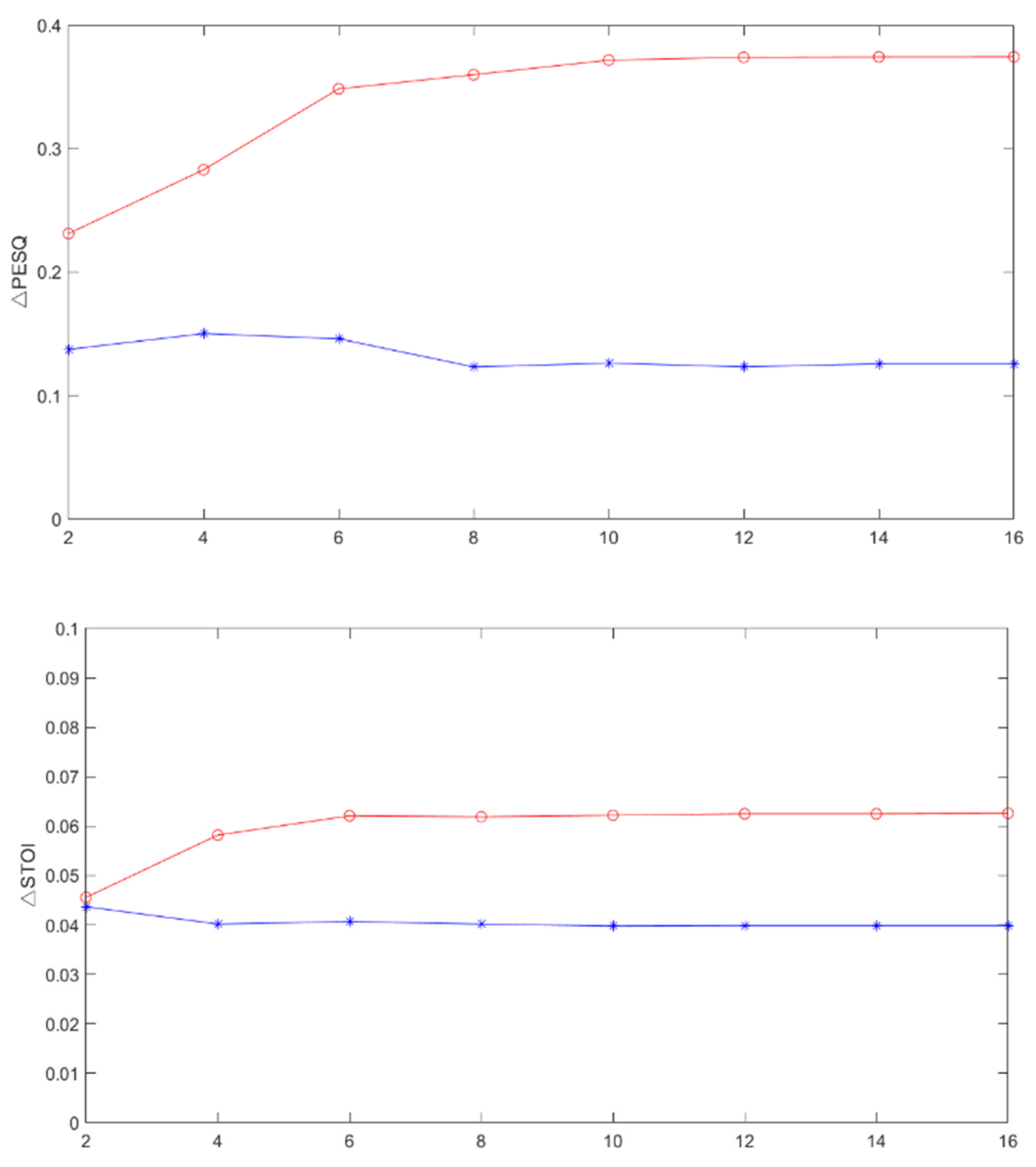
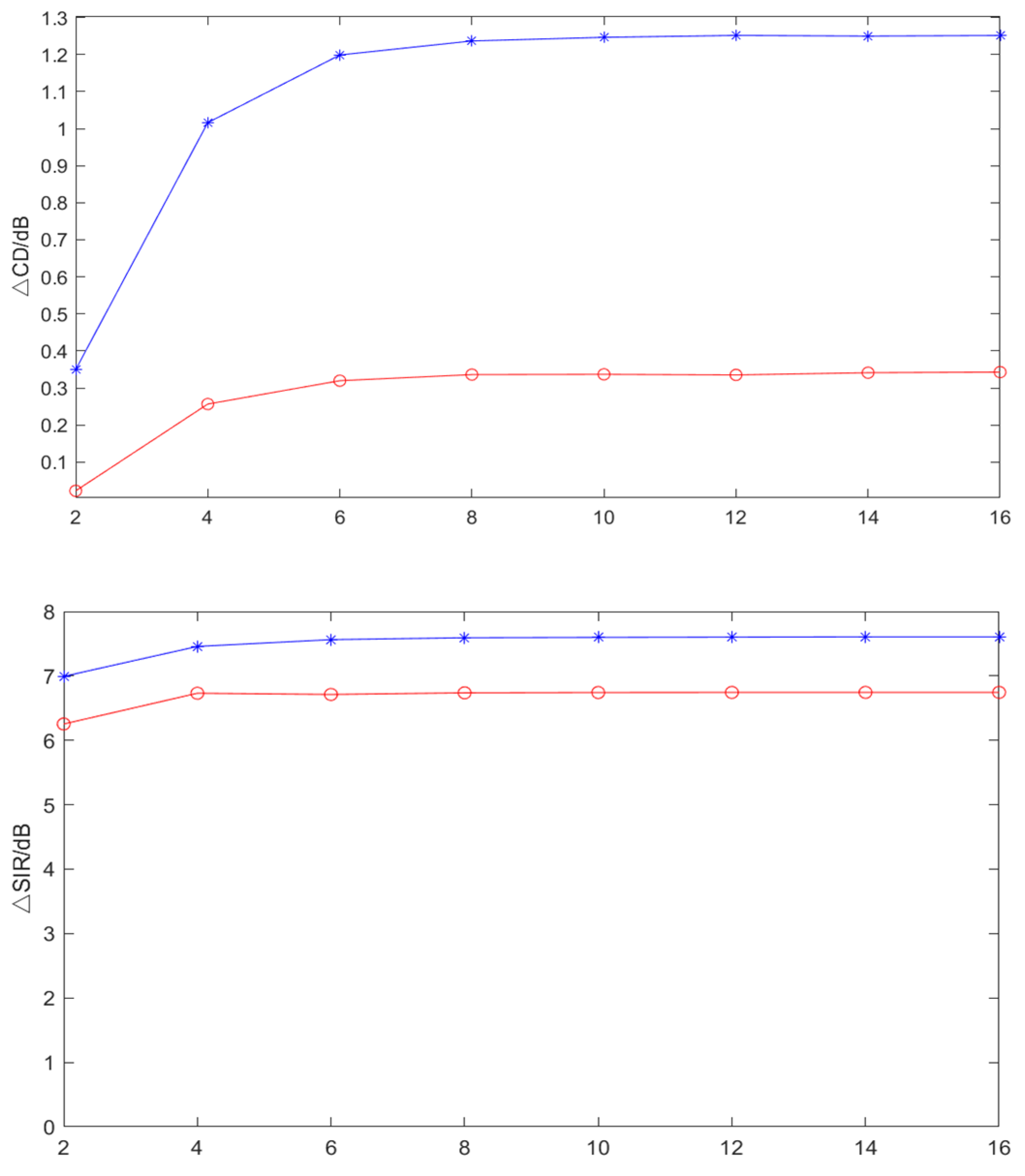
4.3.1. Effect of Filter Order
4.3.2. Effect of the PSD Initialization
4.3.3. Performance Comparison with Reference Methods
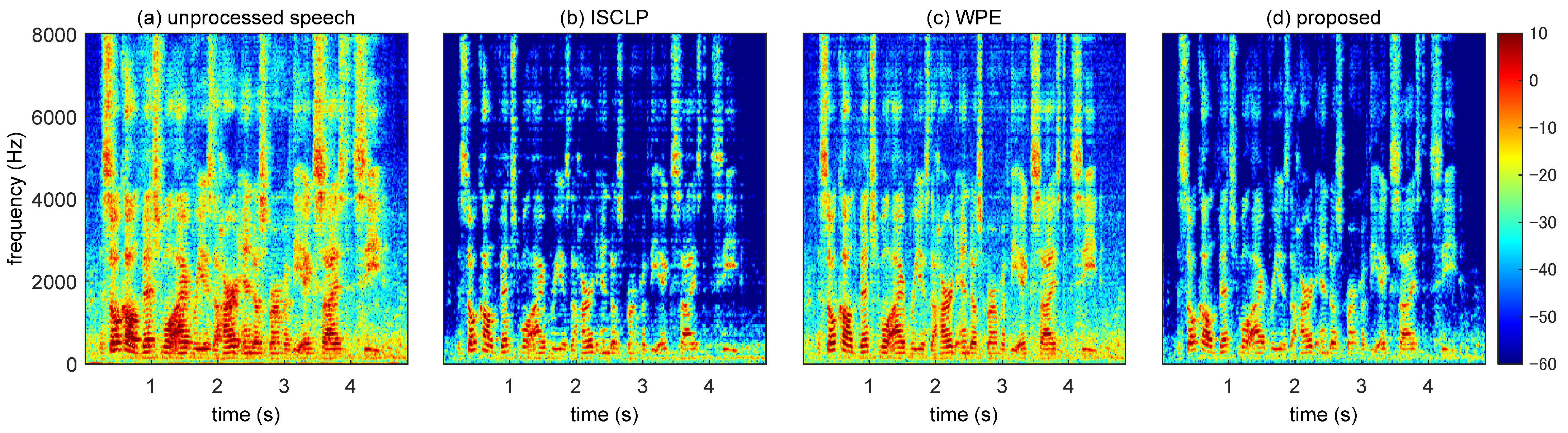
4.3.4. Comparison of the Spectrogram
4.3.5. Comparison of Computational Complexity
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Beutelmann, R.; Brand, T. Prediction of speech intelligibility in spatial noise and reverberation for normal-hearing and hearing-impaired listeners. J. Acoust. Soc. Amer. 2006, 120, 331–342. [Google Scholar] [CrossRef] [PubMed]
- Nakatani, T.; Kellermann, W.; Naylor, P.; Miyoshi, M.; Juang, B.H. Introduction to the special issue on processing reverberant speech: Methodologies and applications. IEEE/ACM Trans. Audio Speech Lang. Process. 2010, 18, 1673–1675. [Google Scholar] [CrossRef] [Green Version]
- Naylor, P.A.; Gaubitch, N.D. Speech Dereverberation; Springer: London, UK, 2010. [Google Scholar]
- van Veen, B.D.; Buckley, K.M. Beamforming: A versatile approach to spatial filtering. IEEE ASSP Mag. 1988, 5, 4–24. [Google Scholar] [CrossRef]
- Gannot, S.; Burshtein, D.; Weinstein, E. Signal enhancement using beamforming and nonstationarity with applications to speech. IEEE Trans. Signal Process. 2001, 49, 1614–1626. [Google Scholar] [CrossRef] [Green Version]
- Markovich, S.; Gannot, S.; Cohen, I. Multichannel eigenspace beamforming in a reverberant noisy environment with multiple interfering speech signals. IEEE Trans. Signal Process. 2009, 17, 1071–1086. [Google Scholar] [CrossRef]
- Schwartz, O.; Gannot, S.; Habets, E.A.P. Nested generalized sidelobe canceller for joint dereverberation and noise reduction. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), South Brisbane, QL, Australia, 19–24 April 2015; pp. 106–110. [Google Scholar]
- Arote, S.; Deshpande, M. Multichannel speech dereverberation using generalized sidelobe canceller and post filter. In Proceedings of the IEEE 5th International Conference on Computing, Communication, Control and Automation, Pune, India, 19–21 September 2019; pp. 1–4. [Google Scholar]
- Nathwani, K.; Hegde, R.M. Speech dereverberation in multisource environment using LCMV filter. In Proceedings of the IEEE International Symposium on Signal Processing & Information Technology, Noida, India, 15–17 December 2014; pp. 404–409. [Google Scholar]
- Schwartz, O.; Gannot, S.; Habets, E.A.P. Multi-microphone speech dereverberation and noise reduction using relative early transfer functions. IEEE/ACM Trans. Audio Speech Lang. Process. 2015, 23, 240–251. [Google Scholar] [CrossRef]
- Nakatani, T.; Kinoshita, K. A unified convolutional beamformer for simultaneous denoising and dereverberation. IEEE Signal Process. Lett. 2019, 26, 903–907. [Google Scholar] [CrossRef] [Green Version]
- Dietzen, T.; Doclo, S.; Moonen, M.; van Waterschoot, T. Integrated sidelobe cancellation and linear prediction Kalman filter for joint multi-microphone speech dereverberation, interfering speech cancellation, and noise reduction. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 740–754. [Google Scholar] [CrossRef] [Green Version]
- Nakatani, T.; Yoshioka, T.; Kinoshita, K.; Miyoshi, M.; Juang, B.-H. Speech dereverberation based on variance-normalized delayed linear prediction. IEEE/ACM Trans. Audio Speech Lang. Process. 2010, 18, 1717–1731. [Google Scholar] [CrossRef]
- Hashemgeloogerdi, S.; Braun, S. Joint beamforming and reverberation cancellation using a constrained Kalman filter with multichannel linear prediction. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 481–485. [Google Scholar]
- Braun, S.; Habets, E.A.P. Linear prediction-based online dereverberation and noise reduction using alternating Kalman filters. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1119–1129. [Google Scholar] [CrossRef]
- Cohen, A.; Stemmer, G.; Ingalsuo, S.; Markovich-Golan, S. Combined weighted prediction error and minimum variance distortionless response for dereverberation. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 446–450. [Google Scholar]
- Dietzen, T.; Spriet, A.; Tirry, W.; Doclo, S.; Moonen, M.; van Waterschoot, T. Partitioned block frequency domain Kalman filter for multi-channel linear prediction based blind speech dereverberation. In Proceedings of the IEEE International Workshop on Acoustic Signal Enhancement (IWAENC), Xi’an, China, 13–16 September 2016; pp. 1–5. [Google Scholar]
- Braun, S.; Habets, E.A.P. Online dereverberation for dynamic scenarios using a Kalman filter with an autoregressive model. IEEE Signal Process. Lett. 2016, 23, 1741–1745. [Google Scholar] [CrossRef]
- Dietzen, T.; Doclo, S.; Spriet, A.; Tirry, W.; Moonen, M.; van Waterschoot, T. Low-Complexity Kalman filter for multi-channel linear-prediction-based blind speech dereverberation. In Proceedings of the IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), New Paltz, NY, USA, 15–18 October 2017; pp. 284–288. [Google Scholar]
- Kodrasi, I.; Doclo, S. Analysis of eigenvalue decomposition-based late reverberation power spectral density estimation. IEEE/ACM Trans. Audio Speech Lang. Process. 2018, 26, 1106–1118. [Google Scholar] [CrossRef]
- Schwartz, O.; Gannot, S.; Habets, E.A.P. Joint estimation of late reverberant and speech power spectral densities in noisy environments using frobenius norm. In Proceedings of the 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 29 August–2 September 2016; pp. 1123–1127. [Google Scholar]
- Schwartz, O.; Gannot, S.; Habets, E.A.P. Joint maximum likelihood estimation of late reverberant and speech power spectral density in noisy environments. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 151–155. [Google Scholar]
- Kuklasiński, A.; Doclo, S.; Jensen, S.H.; Jensen, J. Maximum likelihood PSD estimation for speech enhancement in reverberation and noise. IEEE/ACM Trans. Audio Speech Lang. Process. 2016, 24, 1599–1612. [Google Scholar] [CrossRef] [Green Version]
- Higuchi, T.; Ito, N.; Yoshioka, T.; Nakatani, T. Robust MVDR beamforming using time-frequency masks for online/offline ASR in noise. In Proceedings of the IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP), Shanghai, China, 20–25 March 2016; pp. 5210–5214. [Google Scholar]
- Ito, N.; Araki, S.; Yoshioka, T.; Nakatani, T. Relaxed disjointness based clustering for joint blind source separation and dereverberation. In Proceedings of the IEEE International Workshop on Acoustic Signal Enhancement (IWAENC), Juan-les-Pins, France, 8–11 September 2014; pp. 268–272. [Google Scholar]
- Mandel, M.; Ellis, D.; Jebara, T. An EM algorithm for localizing multiple sound sources in reverberant environments. In Advances in Neural Information Processing Systems 19: Proceedings of the 2006 Conference; MIT Press: Cambridge, MA, USA, 2007; pp. 953–960. [Google Scholar]
- Pan, C.; Chen, J.; Benesty, J. Performance study of the MVDR beamformer as a function of the source incidence angle. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 67–79. [Google Scholar] [CrossRef]
- Simon, D. Optimal State Estimation: Kalman, H infinity, and Nonlinear Approaches; Wiley: Hoboken, NJ, USA, 2006. [Google Scholar]
- Kay, S.M. Fundamentals of Statistical Signal Processing: Estimation Theory, 1st ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 1993. [Google Scholar]
- Haykin, S. Adaptive Filter Theory, 4th ed.; Prentice-Hall: Englewood Cliffs, NJ, USA, 2002. [Google Scholar]
- Enzner, G.; Vary, P. Frequency-domain adaptive Kalman filter for coustic echo control in hands-free telephones. Signal Process. 2006, 86, 1140–1156. [Google Scholar] [CrossRef]
- Yang, W.; Huang, G.; Chen, J.; Benesty, J.; Cohen, I.; Kellermann, W. Robust dereverberation with kronecker product based multichannel linear prediction. IEEE Signal Process. Lett. 2021, 28, 101–105. [Google Scholar] [CrossRef]
- Kinoshita, K.; Delcroix, M.; Kwon, H.; Mori, T.; Nakatani, T. Neural network-based spectrum estimation for online WPE dereverberation. In Proceedings of the Interspeech, Stockholm, Sweden, 20–24 August 2017; pp. 384–388. [Google Scholar]
- Cheng, R.; Bao, C.; Cui, Z. Mass: Microphone array speech simulator in room acoustic environment for multi-channel speech coding and enhancement. Appl. Sci. 2020, 10, 1484. [Google Scholar] [CrossRef] [Green Version]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Fiscus, J.G.; Pallett, D.S. DARP: A TIMIT Acoustic-Phonetic Continous Speech Corpus CD-ROM. NIST Speech Disc 1-1.1; NASA STI/Recon Technical Report N 93, 27403; NASA: Washington, DC, USA, 1993. [Google Scholar]
- ITU-T. Perceptual Evaluation of Speech Quality (PESQ): An Objective Method for End-to-End Speech Quality Assessment of Narrowband Telephone Networks and Speech Codecs; ITU-T Recommendation P.862; International Telecommunication Union: Geneva, Switzerland, 2001. [Google Scholar]
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE/ACM Trans. Audio Speech Lang. Process. 2011, 19, 2125–2136. [Google Scholar] [CrossRef]
- Hu, Y.; Loizou, P.C. Evaluation of objective quality measures for speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2008, 16, 229–238. [Google Scholar] [CrossRef]
- Loizou, P.C. Speech Enhancement: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2007. [Google Scholar]
- Goetze, S.; Warzybok, A.; Kodrasi, I.; Jungmann, J.O.; Cauchi, B.; Rennies, J.; Habets, E.A.P.; Mertins, A.; Gerkmann, T.; Doclo, S.; et al. A study on speech quality and speech intelligibility measures for quality assessment of single-channel dereverberation algorithms. In Proceedings of the 14th International Workshop on Acoustic Signal Enhancement (IWAENC), Juan-les-Pins, France, 8–11 September 2014; pp. 233–237. [Google Scholar]
- Dietzen, T. GitHub Repository: Integrated Sidelobe Cancellation and Linear Prediction Kalman Filter for Joint Multi-microphone Speech Dereverberation, Interfering Speech Cancellation, and Noise Reduction. July 2019. Available online: https://github.com/tdietzen/ISCLP-KF (accessed on 14 January 2021).
- Drude, L.; Heymann, J.; Boeddeker, C.; Haeb-Umbach, R. NARA-WPE: A Python package for weighted prediction error dereverberation in Numpy and Tensorflow for online and offline processing. In Proceedings of the 13th ITG-Symposium, Speech communication, Oldenburg, Germany, 10–12 October 2018; pp. 216–220. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| T60 (ms) | 100 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|
| PESQ | ||||||
| unprocessed | 1.12 | 1.51 | 1.56 | 1.58 | 1.61 | 1.62 |
| ISCLP | 1.50 | 1.58 | 1.63 | 1.66 | 1.69 | 1.71 |
| WPE | 1.12 | 1.47 | 1.52 | 1.53 | 1.54 | 1.56 |
| proposed | 1.20 | 1.66 | 1.72 | 1.77 | 1.78 | 1.79 |
| proposed-kron | 1.19 | 1.68 | 1.75 | 1.77 | 1.78 | 1.79 |
| STOI | ||||||
| unprocessed | 0.51 | 0.58 | 0.58 | 0.58 | 0.56 | 0.56 |
| ISCLP | 0.59 | 0.57 | 0.57 | 0.57 | 0.57 | 0.57 |
| WPE | 0.50 | 0.57 | 0.57 | 0.58 | 0.59 | 0.59 |
| proposed | 0.54 | 0.61 | 0.62 | 0.62 | 0.62 | 0.62 |
| proposed-kron | 0.54 | 0.61 | 0.62 | 0.62 | 0.62 | 0.61 |
| CD (dB) | ||||||
| unprocessed | 7.04 | 5.98 | 5.92 | 5.89 | 5.89 | 5.90 |
| ISCLP | 7.93 | 7.91 | 7.87 | 7.87 | 7.87 | 7.88 |
| WPE | 7.00 | 5.98 | 5.90 | 5.86 | 5.82 | 5.80 |
| proposed | 7.60 | 7.13 | 7.06 | 7.01 | 6.96 | 6.93 |
| proposed-kron | 7.05 | 6.32 | 6.23 | 6.17 | 6.13 | 6.41 |
| SIR (dB) | ||||||
| unprocessed | 11.70 | −4.37 | −5.52 | −6.11 | −6.89 | −7.03 |
| ISCLP | 7.02 | −1.17 | −1.62 | −1.13 | −1.31 | −0.98 |
| WPE | 6.34 | −1.42 | −2.28 | −2.97 | −3.43 | −3.98 |
| proposed | −2.00 | −2.17 | −2.73 | −2.74 | −2.31 | −1.90 |
| proposed-kron | −3.14 | −3.12 | −3.33 | −3.42 | −3.11 | −2.70 |
| fwSegSNR (dB) | ||||||
| unprocessed | 0.65 | 1.93 | 2.11 | 2.22 | 2.30 | 2.35 |
| ISCLP | 1.41 | 1.67 | 1.63 | 1.57 | 1.51 | 1.46 |
| WPE | 0.83 | 2.02 | 2.17 | 2.28 | 2.35 | 2.41 |
| proposed | 3.16 | 4.03 | 4.16 | 4.24 | 4.30 | 4.34 |
| proposed-kron | 3.43 | 4.62 | 4.79 | 4.89 | 4.96 | 5.01 |
| T60 (ms) | 100 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|
| PESQ | ||||||
| unprocessed | 1.46 | 1.84 | 1.87 | 1.88 | 1.88 | 1.87 |
| ISCLP | 2.02 | 1.84 | 1.88 | 1.90 | 1.90 | 1.90 |
| WPE | 1.49 | 1.79 | 1.83 | 1.86 | 1.88 | 1.91 |
| proposed | 1.51 | 2.01 | 2.06 | 2.10 | 2.11 | 2.11 |
| proposed-kron | 1.45 | 2.06 | 2.09 | 2.10 | 2.09 | 2.08 |
| STOI | ||||||
| unprocessed | 0.62 | 0.66 | 0.65 | 0.64 | 0.64 | 0.63 |
| ISCLP | 0.71 | 0.64 | 0.64 | 0.64 | 0.63 | 0.63 |
| WPE | 0.61 | 0.67 | 0.67 | 0.67 | 0.67 | 0.67 |
| proposed | 0.63 | 0.69 | 0.70 | 0.70 | 0.69 | 0.69 |
| proposed-kron | 0.64 | 0.69 | 0.69 | 0.68 | 0.67 | 0.67 |
| CD (dB) | ||||||
| unprocessed | 6.42 | 5.27 | 5.27 | 5.30 | 5.35 | 5.40 |
| ISCLP | 7.16 | 7.46 | 7.42 | 7.43 | 7.55 | 7.68 |
| WPE | 6.30 | 5.16 | 5.10 | 5.06 | 5.04 | 5.13 |
| Proposed | 6.97 | 6.28 | 6.32 | 6.34 | 6.35 | 6.37 |
| proposed-kron | 6.40 | 5.38 | 5.47 | 5.56 | 5.66 | 5.75 |
| SIR (dB) | ||||||
| unprocessed | 13.41 | −3.80 | −4.80 | −5.59 | −6.11 | −6.51 |
| ISCLP | 8.81 | −0.11 | −0.15 | −0.38 | −0.41 | −0.58 |
| WPE | 6.69 | −0.16 | −1.51 | −2.34 | −2.94 | −3.51 |
| proposed | −2.21 | −1.99 | −1.15 | −1.34 | −1.11 | −1.18 |
| proposed-kron | −3.34 | −2.08 | −2.12 | −2.26 | −2.12 | −2.25 |
| fwSegSNR (dB) | ||||||
| unprocessed | 1.89 | 3.33 | 3.43 | 3.47 | 3.47 | 3.46 |
| ISCLP | 3.56 | 2.80 | 2.65 | 2.50 | 2.40 | 2.30 |
| WPE | 2.15 | 3.56 | 3.70 | 3.79 | 3.84 | 3.88 |
| proposed | 4.56 | 5.23 | 5.31 | 5.33 | 5.37 | 5.37 |
| proposed-kron | 4.91 | 5.87 | 5.96 | 6.00 | 6.02 | 6.01 |
| T60 (ms) | 100 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|
| PESQ | ||||||
| unprocessed | 1.85 | 2.08 | 2.06 | 2.03 | 2.00 | 1.97 |
| ISCLP | 2.41 | 2.41 | 2.38 | 2.34 | 2.30 | 2.26 |
| WPE | 1.90 | 2.17 | 2.20 | 2.23 | 2.24 | 2.25 |
| proposed | 2.15 | 2.38 | 2.39 | 2.37 | 2.34 | 2.31 |
| proposed-kron | 2.14 | 2.37 | 2.35 | 2.31 | 2.28 | 2.23 |
| STOI | ||||||
| unprocessed | 0.73 | 0.72 | 0.71 | 0.69 | 0.68 | 0.66 |
| ISCLP | 0.79 | 0.76 | 0.75 | 0.75 | 0.74 | 0.73 |
| WPE | 0.72 | 0.75 | 0.75 | 0.75 | 0.75 | 0.75 |
| proposed | 0.75 | 0.76 | 0.75 | 0.75 | 0.74 | 0.74 |
| proposed-kron | 0.75 | 0.75 | 0.74 | 0.73 | 0.72 | 0.71 |
| CD (dB) | ||||||
| unprocessed | 5.57 | 5.22 | 5.33 | 5.45 | 5.57 | 5.68 |
| ISCLP | 6.42 | 7.07 | 7.15 | 7.21 | 7.28 | 7.34 |
| WPE | 5.39 | 4.87 | 4.82 | 4.80 | 4.79 | 4.78 |
| proposed | 6.39 | 6.74 | 6.68 | 6.64 | 6.60 | 6.59 |
| proposed-kron | 5.59 | 6.01 | 6.00 | 6.00 | 6.00 | 6.02 |
| SIR (dB) | ||||||
| unprocessed | 14.13 | −5.48 | −6.53 | −7.26 | −7.80 | −8.21 |
| ISCLP | 9.38 | −1.02 | −1.62 | −2.03 | −2.29 | −2.49 |
| WPE | 6.76 | −1.85 | −2.92 | −3.75 | −4.44 | −5.02 |
| proposed | −2.19 | −6.82 | −6.83 | −6.69 | −6.57 | −6.41 |
| proposed-kron | −3.32 | −8.03 | −8.06 | −7.94 | −7.87 | −7.71 |
| fwSegSNR (dB) | ||||||
| unprocessed | 3.83 | 4.71 | 4.68 | 4.59 | 4.49 | 4.39 |
| ISCLP | 5.63 | 3.85 | 3.34 | 3.16 | 3.02 | 2.88 |
| WPE | 4.13 | 5.14 | 5.24 | 5.29 | 5.31 | 5.32 |
| proposed | 4.12 | 4.25 | 4.24 | 4.23 | 4.20 | 4.14 |
| proposed-kron | 4.63 | 4.94 | 4.94 | 4.90 | 4.84 | 4.76 |
| T60 (ms) | 100 | 400 | 500 | 600 | 700 | 800 |
|---|---|---|---|---|---|---|
| PESQ | ||||||
| unprocessed | 2.24 | 2.32 | 2.24 | 2.18 | 2.12 | 1.97 |
| ISCLP | 2.73 | 2.59 | 2.53 | 2.47 | 2.42 | 2.36 |
| WPE | 2.30 | 2.51 | 2.54 | 2.55 | 2.56 | 2.55 |
| proposed | 2.54 | 2.61 | 2.58 | 2.53 | 2.48 | 2.45 |
| proposed-kron | 2.51 | 2.58 | 2.52 | 2.45 | 2.39 | 2.34 |
| STOI | ||||||
| unprocessed | 0.82 | 0.76 | 0.74 | 0.72 | 0.70 | 0.69 |
| ISCLP | 0.85 | 0.79 | 0.78 | 0.77 | 0.76 | 0.75 |
| WPE | 0.81 | 0.80 | 0.80 | 0.80 | 0.80 | 0.80 |
| proposed | 0.81 | 0.79 | 0.79 | 0.78 | 0.77 | 0.77 |
| proposed-kron | 0.81 | 0.78 | 0.77 | 0.76 | 0.74 | 0.73 |
| CD (dB) | ||||||
| unprocessed | 4.64 | 4.78 | 5.00 | 5.21 | 5.38 | 5.53 |
| ISCLP | 5.80 | 6.73 | 6.84 | 6.94 | 7.02 | 7.10 |
| WPE | 4.41 | 4.20 | 4.19 | 4.20 | 4.21 | 4.21 |
| proposed | 5.64 | 6.29 | 6.27 | 6.26 | 6.25 | 6.24 |
| proposed-kron | 5.32 | 5.71 | 5.75 | 5.79 | 5.82 | 5.85 |
| SIR (dB) | ||||||
| unprocessed | 14.19 | −5.53 | −6.67 | −7.32 | −7.81 | −8.62 |
| ISCLP | 9.55 | −0.98 | −1.57 | −1.96 | −2.21 | −2.42 |
| WPE | 6.78 | −1.90 | −2.99 | −3.84 | −4.54 | −5.13 |
| proposed | −1.91 | −6.79 | −6.80 | −6.67 | −6.49 | −6.38 |
| proposed-kron | −3.03 | −8.05 | −8.09 | −7.92 | −7.82 | −7.73 |
| fwSegSNR (dB) | ||||||
| unprocessed | 6.39 | 5.86 | 5.65 | 5.43 | 5.22 | 5.04 |
| ISCLP | 7.33 | 4.14 | 3.84 | 3.63 | 3.45 | 3.28 |
| WPE | 6.55 | 6.53 | 6.56 | 6.55 | 6.54 | 6.51 |
| proposed | 5.86 | 5.24 | 5.13 | 5.04 | 4.94 | 4.86 |
| proposed-kron | 6.27 | 5.76 | 5.64 | 5.53 | 5.40 | 5.27 |
| Proposed-Kron | |||
|---|---|---|---|
| Step | (×) | (+) | (÷) |
| 1 | (2L − 1) (L − 1)2 | 2(L − 1)3 − (L − 1) | —— |
| 2 | M (L − 1)2 (M + 1) + 2 (L − 1)2 + 2 (L − 1) | (M2 + 2) (L − 1)2 − M (L − 1) | L − 1 |
| 3 | (L − 1) + (L − 1)2 + (L − 1)3 | (L − 1)3 + (L − 1) | —— |
| Proposed | |||
| Step | (×) | (+) | (÷) |
| 1 | 2 M3 (L − 1)3 + M2 (L − 1)2 | 2 M3(L − 1)3 − M(L − 1) | —— |
| 2 | 2 M2 (L − 1)2 + 2 M (L − 1) | 2 M2(L − 1)2 | M (L − 1) |
| 3 | M (L − 1) + M2 (L − 1)2 + M3 (L − 1)3 | M (L − 1)3 + (L − 1) | —— |
| Complexity Reduction Factor | |||
| Step | λ (×) ≈ | λ (+) ≈ | λ (÷) ≈ |
| 1 | 1/M3 | 1/M3 | —— |
| 2 | 1/2 + 1/2 M | 1/2 + 1/M2 | 1/M |
| 3 | 1/M3 | 1/M | —— |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, F.; Bao, C.; Zhou, J. Effective Dereverberation with a Lower Complexity at Presence of the Noise. Appl. Sci. 2022, 12, 11819. https://doi.org/10.3390/app122211819
Tan F, Bao C, Zhou J. Effective Dereverberation with a Lower Complexity at Presence of the Noise. Applied Sciences. 2022; 12(22):11819. https://doi.org/10.3390/app122211819
Chicago/Turabian StyleTan, Fengqi, Changchun Bao, and Jing Zhou. 2022. "Effective Dereverberation with a Lower Complexity at Presence of the Noise" Applied Sciences 12, no. 22: 11819. https://doi.org/10.3390/app122211819