
Binary Dense SIFT Flow Based Position-Information Added Two-Stream CNN for Pedestrian Action Recognition



Abstract
:1. Introduction
- Not only walking action attribute but also crossing attribute are recognized by using position-information added two stream CNN. The position-information stream increases performance of crossing attribute recognition especially.
- Multi-task learning which trains both walking and crossing attributes at once is adopted. Then performance of proposed method is compared by other single-task learning network.
- Although proposed method uses the 2D detecting and tracking algorithm than ground-truth boundary-box, the performance of behavior recognition is still high. Thus, it can be applied in a real-world environment.
2. Related Work
2.1. Human-Action Recognition between the Ground-Truth Boundary Box and Detection Algorithm
2.2. Human-Action Recognition with the Two-Stream CNN
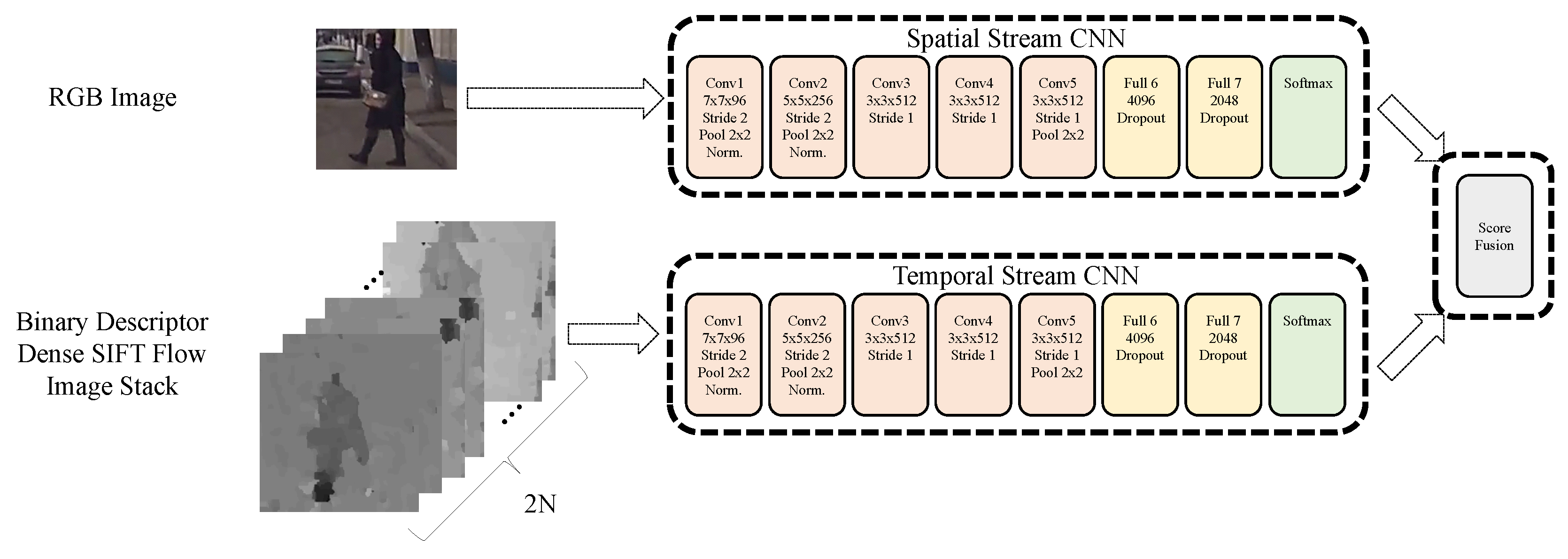
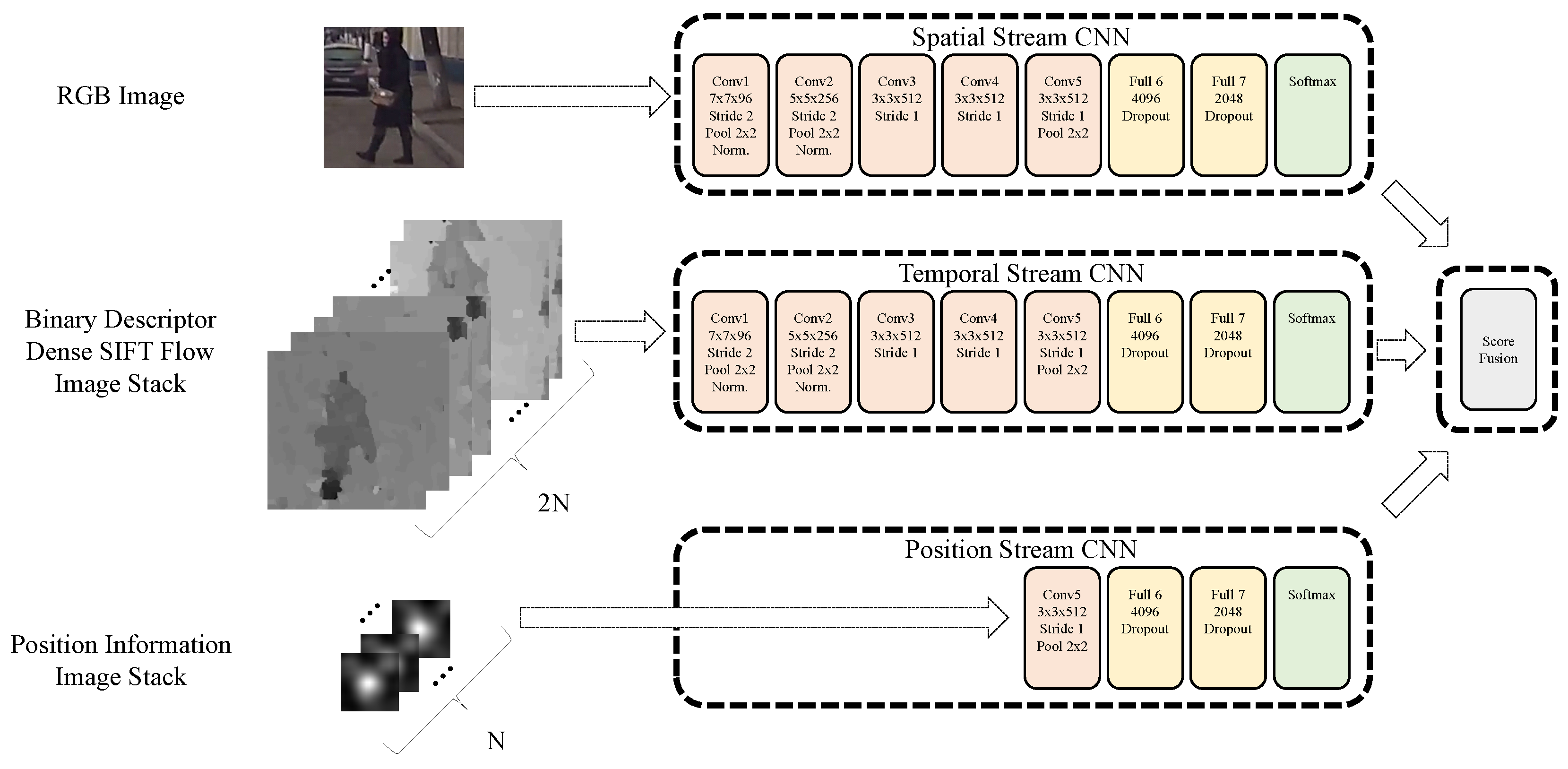
Binary Descriptor Dense SIFT Flow-Based Two-Stream CNN
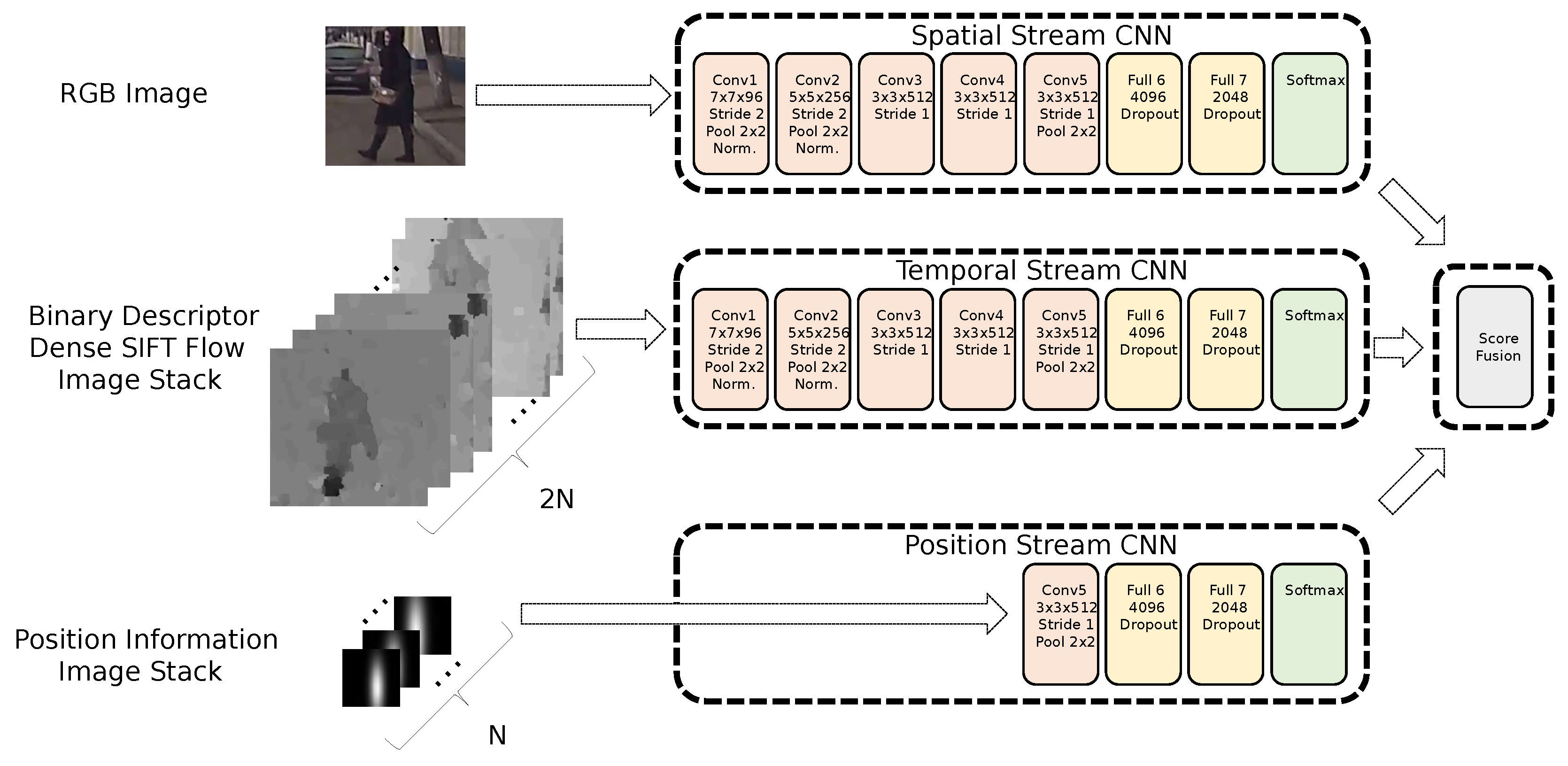
3. Position-Information Feature Added Two-Stream CNN with Pedestrian Detector and Tracker
3.1. Dense SIFT Flow-Based Two-Stream CNN for Action-Attribute Recognition
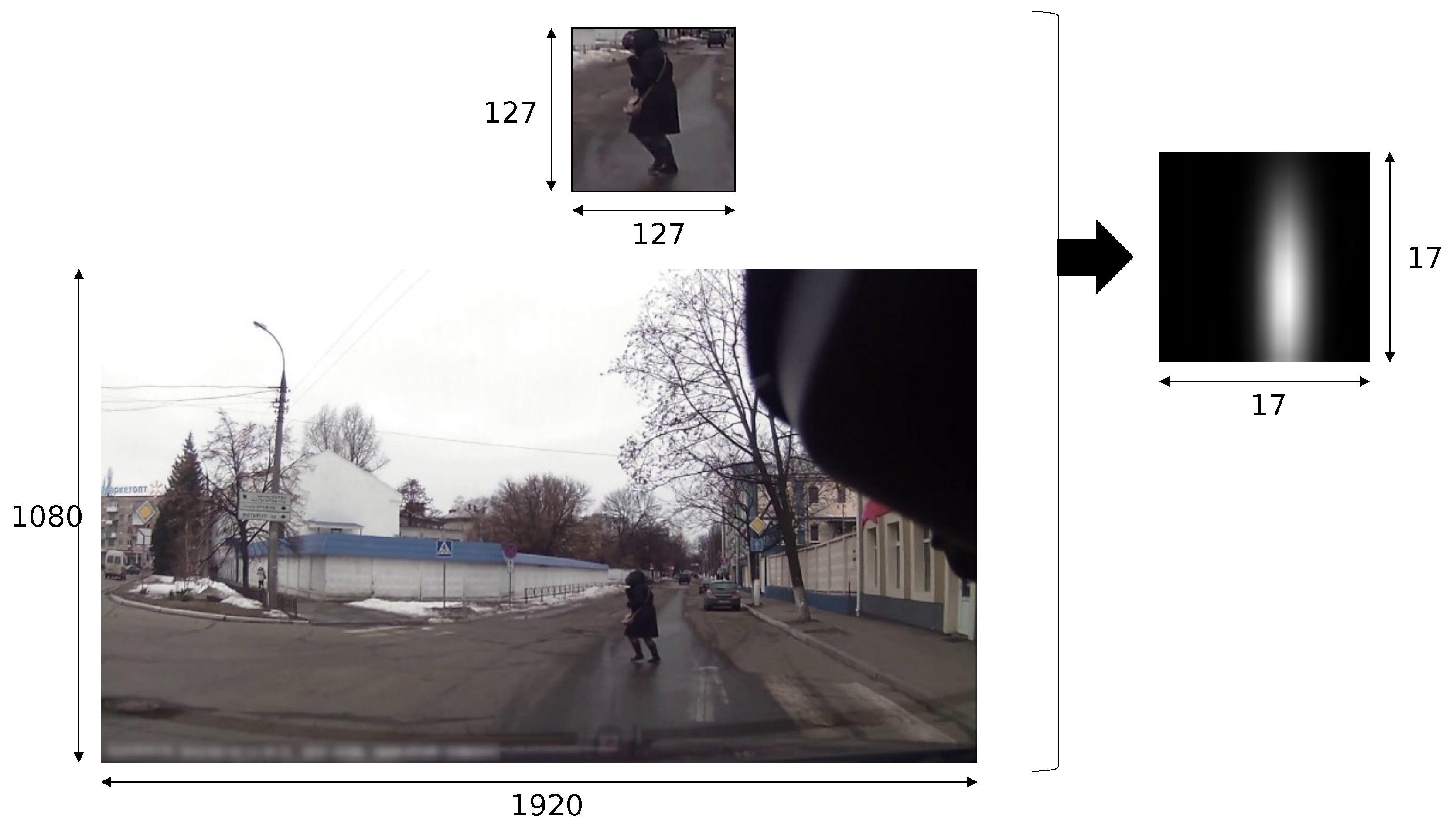
3.2. Position-Information Feature-Image Added Two-Stream CNN for Cross-Attribute Recognition
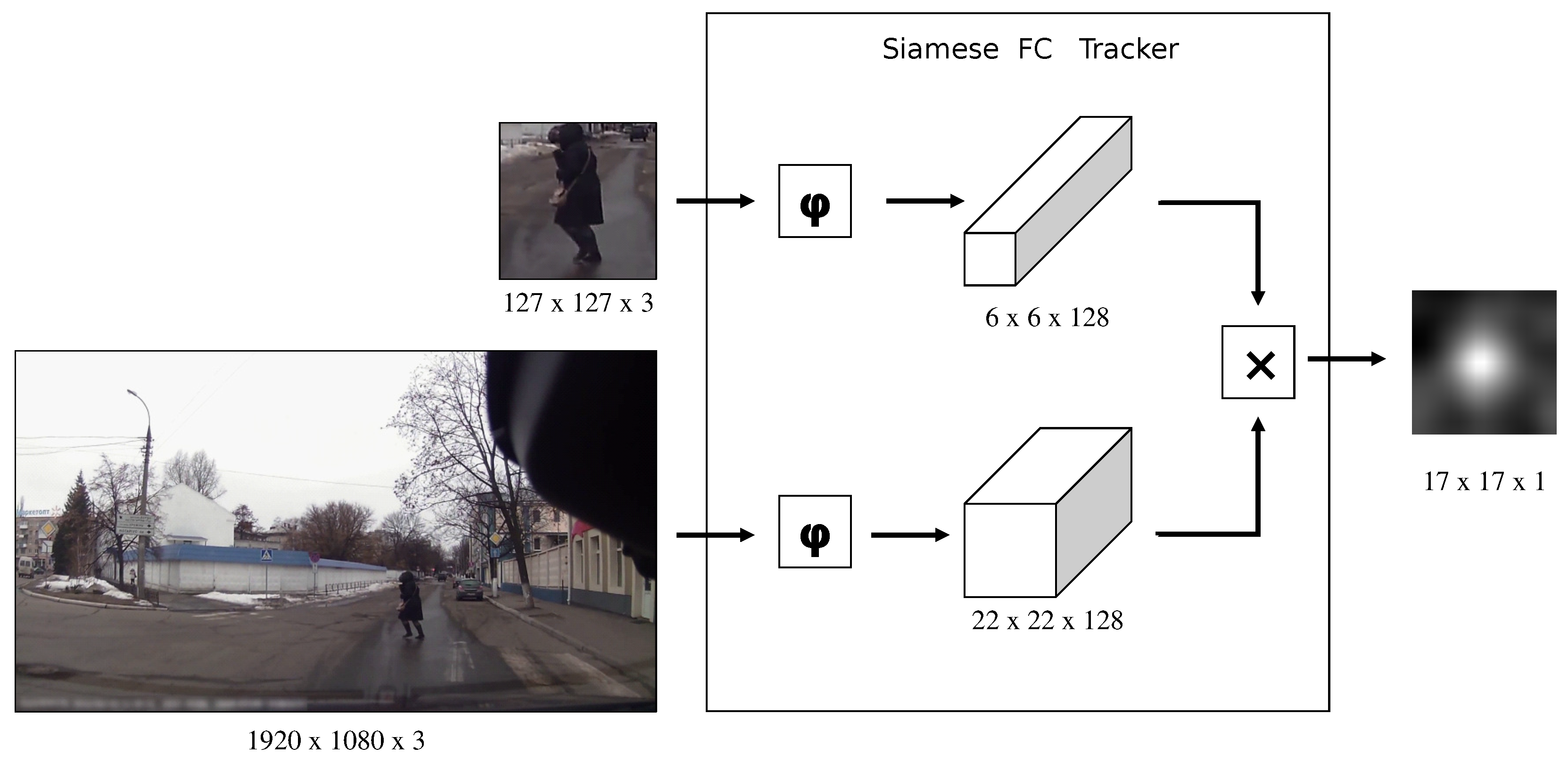
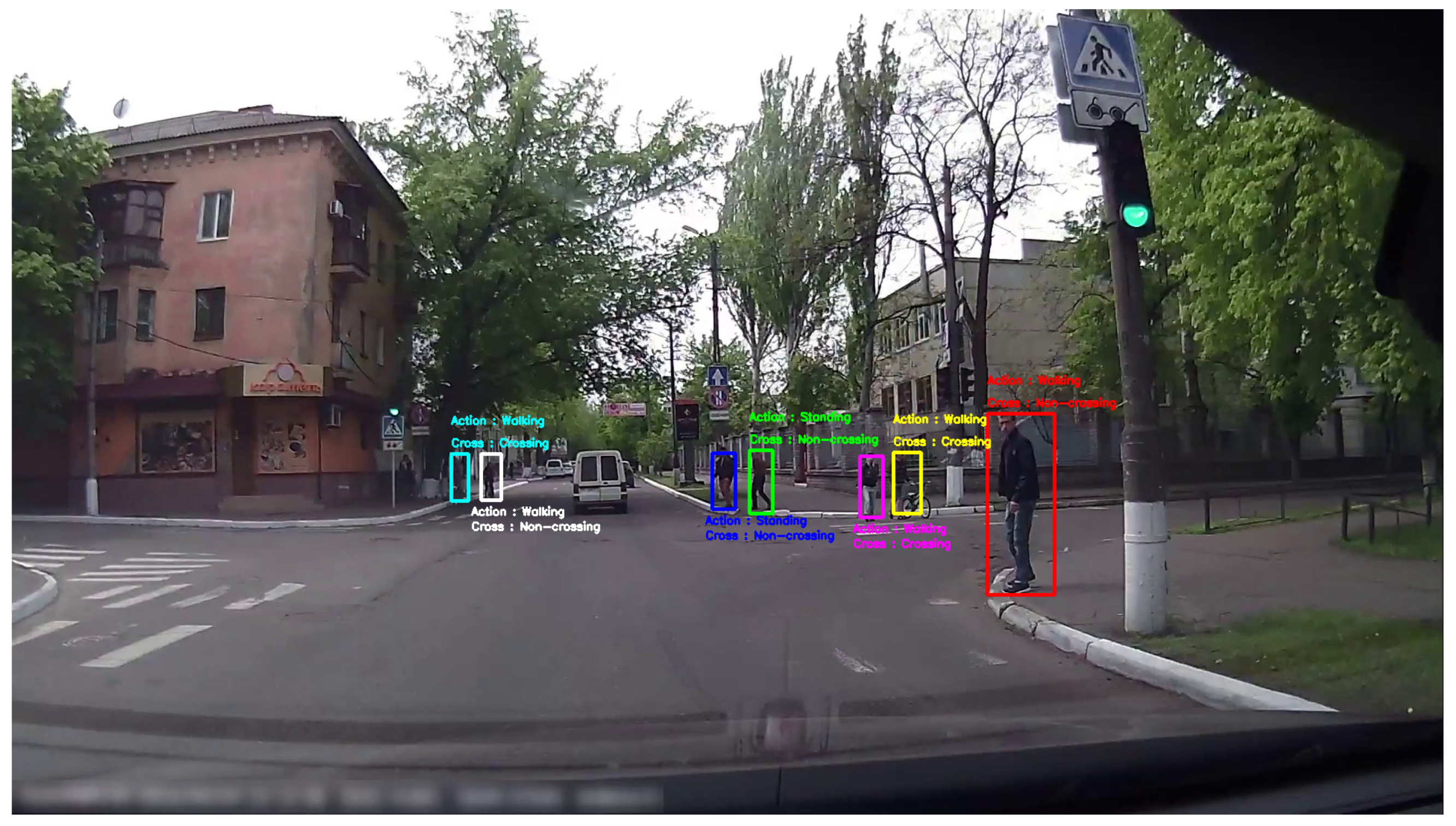
3.3. Fusion with a Detector and Tracker without a Ground-Truth Boundary Box
JAAD and PIE Datasets
4. Experimental Evaluations for Action Recognition
4.1. Experiment Environment
Implementation Detail
4.2. Ablation Analysis of Pedestrian-Action Recognition
4.2.1. Evaluation of the Binary Descriptor Dense SIFT Flow-Based Two-Stream CNN
4.2.2. Evaluation of the Position-Information Feature-Image Added Two-Stream CNN
4.2.3. Evaluation of Fusion with a Detector and Tracking without the Ground-Truth Boundary Box
4.3. Comparison of the Experimental Results with State-of-the-Art Methods of Multitask Learning
4.4. Comparison of the Experimental Results with State-of-the-Art Methods for Single-Task Learning
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Betz, J.; Zheng, H.; Liniger, A.; Rosolia, U.; Karle, P.; Behl, M.; Krovi, V.; Mangharam, R. Autonomous vehicles on the edge: A survey on autonomous vehicle racing. IEEE Open J. Intell. Transp. Syst. 2022, 3, 458–488. [Google Scholar] [CrossRef]
- Badue, C.; Guidolini, R.; Carneiro, R.V.; Azevedo, P.; Cardoso, V.B.; Forechi, A.; Jesus, L.; Berriel, R.; Paixao, T.M.; Mutz, F.; et al. Self-driving cars: A survey. Expert Syst. Appl. 2021, 165, 113816. [Google Scholar] [CrossRef]
- Arnold, E.; Al-Jarrah, O.Y.; Dianati, M.; Fallah, S.; Oxtoby, D.; Mouzakitis, A. A survey on 3d object detection methods for autonomous driving applications. IEEE Trans. Intell. Transp. Syst. 2019, 20, 3782–3795. [Google Scholar] [CrossRef] [Green Version]
- Marzbani, H.; Khayyam, H.; To, C.N.; Quoc, D.V.; Jazar, R.N. Autonomous vehicles: Autodriver algorithm and vehicle dynamics. IEEE Trans. Veh. Technol. 2019, 68, 3201–3211. [Google Scholar] [CrossRef]
- Wang, Z.; Zhan, J.; Duan, C.; Guan, X.; Lu, P.; Yang, K. A review of vehicle detection techniques for intelligent vehicles. IEEE Trans. Neural Netw. Learn. Syst. 2022. [Google Scholar] [CrossRef] [PubMed]
- Singhal, N.; Prasad, L. Sensor based vehicle detection and classification-a systematic review. Int. J. Eng. Syst. Model. Simul. 2022, 13, 38–60. [Google Scholar] [CrossRef]
- Maity, S.; Bhattacharyya, A.; Singh, P.K.; Kumar, M.; Sarkar, R. Last Decade in Vehicle Detection and Classification: A Comprehensive Survey. Arch. Comput. Methods Eng. 2022. [Google Scholar] [CrossRef]
- Zhang, H.; Pop, D.O.; Rogozan, A.; Bensrhair, A. Accelerate High Resolution Image Pedestrian Detection with Non-Pedestrian Area Estimation. IEEE Access 2021, 9, 8625–8636. [Google Scholar] [CrossRef]
- Ren, J.; Niu, C.; Han, J. An IF-RCNN Algorithm for Pedestrian Detection in Pedestrian Tunnels. IEEE Access 2020, 8, 165335–165343. [Google Scholar] [CrossRef]
- Cai, J.; Lee, F.; Yang, S.; Lin, C.; Chen, H.; Kotani, K.; Chen, Q. Pedestrian as Points: An Improved Anchor-Free Method for Center-Based Pedestrian Detection. IEEE Access 2020, 8, 179666–179677. [Google Scholar] [CrossRef]
- Wei, C.; Hui, F.; Yang, Z.; Jia, S.; Khattak, A.J. Fine-grained highway autonomous vehicle lane-changing trajectory prediction based on a heuristic attention-aided encoder-decoder model. Transp. Res. Part Emerg. Technol. 2022, 140, 103706. [Google Scholar] [CrossRef]
- Claussmann, L.; Revilloud, M.; Gruyer, D.; Glaser, S. A review of motion planning for highway autonomous driving. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1826–1848. [Google Scholar] [CrossRef] [Green Version]
- Liao, J.; Liu, T.; Tang, X.; Mu, X.; Huang, B.; Cao, D. Decision-making Strategy on Highway for Autonomous Vehicles using Deep Reinforcement Learning. IEEE Access 2020, 8, 177804–177814. [Google Scholar] [CrossRef]
- Tsotsos, J.K.; Kotseruba, I.; Rasouli, A.; Solbach, M.D. Visual attention and its intimate links to spatial cognition. Cogn. Process. 2018, 19, 121–130. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.; Ma, N.; Wang, P.; Li, J.; Wang, P.; Pang, G.; Shi, X. Survey of pedestrian action recognition techniques for autonomous driving. Tsinghua Sci. Technol. 2020, 25, 458–470. [Google Scholar] [CrossRef]
- Wang, X.; Zheng, S.; Yang, R.; Zheng, A.; Chen, Z.; Tang, J.; Luo, B. Pedestrian attribute recognition: A survey. Pattern Recognit. 2022, 121, 108220. [Google Scholar] [CrossRef]
- Brehar, R.D.; Muresan, M.P.; Mariţa, T.; Vancea, C.C.; Negru, M.; Nedevschi, S. Pedestrian street-cross action recognition in monocular far infrared sequences. IEEE Access 2021, 9, 74302–74324. [Google Scholar] [CrossRef]
- Yang, B.; Zhan, W.; Wang, P.; Chan, C.; Cai, Y.; Wang, N. Crossing or not? Context-based recognition of pedestrian crossing intention in the urban environment. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5338–5349. [Google Scholar] [CrossRef]
- Wang, J.; Liu, Z.; Wu, Y.; Yuan, J. Learning actionlet ensemble for 3D human action recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 914–927. [Google Scholar] [CrossRef] [PubMed]
- Devanne, M.; Wannous, H.; Berretti, S.; Pala, P.; Daoudi, M.; Del Bimbo, A. 3-d human action recognition by shape analysis of motion trajectories on riemannian manifold. IEEE Trans. Cybern. 2014, 45, 1340–1352. [Google Scholar] [CrossRef]
- Pienaar, S.W.; Malekian, R. Human activity recognition using LSTM-RNN deep neural network architecture. In Proceedings of the 2019 IEEE 2nd Wireless Africa Conference (WAC), Pretoria, South Africa, 18–20 August 2019; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Two-stream convolutional networks for action recognition in videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Zhang, B.; Wang, L.; Wang, Z.; Qiao, Y.; Wang, H. Real-time action recognition with enhanced motion vector CNNs. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2718–2726. [Google Scholar] [CrossRef]
- Zhao, Y.; Man, K.L.; Smith, J.; Siddique, K.; Guan, S.U. Improved two-stream model for human action recognition. EURASIP J. Image Video Process. 2020, 2020, 1–9. [Google Scholar] [CrossRef]
- Park, S.K.; Chung, J.H.; Kang, T.K.; Lim, M.T. Binary Dense SIFT Flow Based Two Stream CNN for Human Action Recognition. Multimed. Tools Appl. 2021, 80, 35697–35720. [Google Scholar] [CrossRef]
- Marginean, A.; Brehar, R.; Negru, M. Understanding pedestrian behaviour with pose estimation and recurrent networks. In Proceedings of the 2019 6th International Symposium on Electrical and Electronics Engineering (ISEEE), Galati, Romania, 18–20 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, Z.; Papanikolopoulos, N. Estimating pedestrian crossing states based on single 2D body pose. In Proceedings of the IEEE International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 2205–2210. [Google Scholar] [CrossRef]
- Fang, Z.; López, A.M. Intention recognition of pedestrians and cyclists by 2d pose estimation. IEEE Trans. Intell. Transp. Syst. 2019, 21, 4773–4783. [Google Scholar] [CrossRef] [Green Version]
- Black, M.J.; Anandan, P. The robust estimation of multiple motions: Parametric and piecewise-smooth flow fields. Comput. Vis. Image Underst. 1996, 63, 75–104. [Google Scholar] [CrossRef]
- Brox, T.; Bruhn, A.; Papenberg, N.; Weickert, J. High accuracy optical flow estimation based on a theory for warping. In Proceedings of the European Conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 25–36. [Google Scholar] [CrossRef]
- Mordan, T.; Cord, M.; Pérez, P.; Alahi, A. Detecting 32 Pedestrian Attributes for Autonomous Vehicles. arXiv 2020, arXiv:2012.02647. [Google Scholar] [CrossRef]
- Pop, D.O.; Rogozan, A.; Chatelain, C.; Nashashibi, F.; Bensrhair, A. Multi-task deep learning for pedestrian detection, action recognition and time to cross prediction. IEEE Access 2019, 7, 149318–149327. [Google Scholar] [CrossRef]
- Chatfield, K.; Simonyan, K.; Vedaldi, A.; Zisserman, A. Return of the devil in the details: Delving deep into convolutional nets. arXiv 2014, arXiv:1405.3531. [Google Scholar]
- Liu, C.; Yuen, J.; Torralba, A. Sift flow: Dense correspondence across scenes and its applications. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 978–994. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, J.; Li, Y.; Xu, H.; Liu, H. Probabilistic prediction of pedestrian crossing intention using roadside LiDAR data. IEEE Access 2019, 7, 93781–93790. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Luo, H.; Xie, W.; Wang, X.; Zeng, W. Detect or track: Towards cost-effective video object detection/tracking. In Proceedings of the AAAI Conference on Artificial Intelligence, Atlanta, Georgia, 8–12 October 2019; Volume 33, pp. 8803–8810. [Google Scholar] [CrossRef] [Green Version]
- Bertinetto, L.; Valmadre, J.; Henriques, J.F.; Vedaldi, A.; Torr, P.H. Fully-convolutional siamese networks for object tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 850–865. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Adeli, E.; Cao, Z.; Lee, K.H.; Shenoi, A.; Gaidon, A.; Niebles, J.C. Spatiotemporal relationship reasoning for pedestrian intent prediction. IEEE Robot. Autom. Lett. 2020, 5, 3485–3492. [Google Scholar] [CrossRef] [Green Version]
- Rasouli, A.; Kotseruba, I.; Tsotsos, J.K. Are they going to cross? A benchmark dataset and baseline for pedestrian crosswalk behavior. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Venice, Italy, 22–29 October 2017; pp. 206–213. [Google Scholar] [CrossRef]
- Rasouli, A.; Kotseruba, I.; Kunic, T.; Tsotsos, J.K. Pie: A large-scale dataset and models for pedestrian intention estimation and trajectory prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6262–6271. [Google Scholar] [CrossRef]
- Pop, D.O. Detection of pedestrian actions based on deep learning approach. Stud. Univ. Babeş-Bolyai. Informatica. 2019, 64, 5–13. [Google Scholar] [CrossRef] [Green Version]
- Chaabane, M.; Trabelsi, A.; Blanchard, N.; Beveridge, R. Looking ahead: Anticipating pedestrians crossing with future frames prediction. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Snowmass Village, CO, USA, 1–5 March 2020; pp. 2297–2306. [Google Scholar] [CrossRef]
- Rasouli, A.; Rohani, M.; Luo, J. Pedestrian Behavior Prediction via Multitask Learning and Categorical Interaction Modeling. arXiv 2020, arXiv:2012.03298. [Google Scholar]
- Soomro, K.; Zamir, A.R.; Shah, M. UCF101: A dataset of 101 human actions classes from videos in the wild. arXiv 2012, arXiv:1212.0402. [Google Scholar]
- Singh, A.; Suddamalla, U. Multi-input fusion for practical pedestrian intention prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2304–2311. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Action | Cross | Look | Hand Gesture | Reaction | No. of Frames |
|---|---|---|---|---|---|---|
| JAAD [40] | O | O | O | O | O | 82,032 |
| PIE [41] | O | O | O | O | X | 909,480 |
| STIP [39] | X | O | X | X | X | 1,108,176 |
| Classes | Training Dataset (No. of Samples) | Testing Dataset (No. of Samples) | |
|---|---|---|---|
| Action | Standing | 529 | 339 |
| Walking | 1211 | 1071 | |
| Cross | Not crossing | 988 | 794 |
| Crossing | 752 | 616 | |
| Irrelevant | 0 | 0 | |
| Hand gesture | Undefined | 1729 | 1405 |
| Greet | 0 | 0 | |
| Yield | 0 | 0 | |
| Right of way | 0 | 0 | |
| Other | 11 | 5 | |
| Reaction | undefined | 1655 | 1321 |
| Clear path | 24 | 29 | |
| Speed up | 33 | 33 | |
| Slow down | 28 | 27 | |
| Look | Not looking | 1460 | 1176 |
| Looking | 280 | 234 | |
| Action | Cross | ||||
|---|---|---|---|---|---|
| Walking | Standing | Crossing | Not Crossing | ||
| Training Dataset | JAAD | 529 | 1211 | 988 | 752 |
| JAAD and PIE | 30,255 | 27,317 | 12,490 | 45,082 | |
| Testing Dataset | JAAD | 3796 | 561 | 2541 | 1816 |
| Walking Accuracy | Standing Accuracy | Average Accuracy | |
|---|---|---|---|
| JAAD | 92.44% | 52.80% | 82.91% |
| JAAD and PIE | 91.01% | 72.38% | 88.70% |
| Crossing Accuracy | Not Crossing Accuracy | Average Accuracy | |
|---|---|---|---|
| JAAD | 80.64% | 60.68% | 71.16% |
| JAAD and PIE | 86.12% | 65.64% | 76.44% |
| Action | Cross | |||||
|---|---|---|---|---|---|---|
| Walking | Standing | Average | Cross | Not Cross | Average | |
| Optical Flow | 86.90% | 61.59% | 84.68% | 75.73% | 63.22% | 71.69% |
| Binary Descriptor Dense SIFT Flow | 91.01% | 72.38% | 88.70% | 86.12% | 65.64% | 76.44% |
| Action Attribute | Cross Attribute | |||||
|---|---|---|---|---|---|---|
| Walking | Standing | Average | Cross | Not Cross | Average | |
| Two-Stream CNN | 91.01% | 72.38% | 88.70% | 86.12% | 65.64% | 76.44% |
| Two-Stream CNN with Position stream | 91.49% | 72.35% | 88.75% | 86.43% | 71.04% | 79.13% |
| Action Attribute | Cross Attribute | |||||
|---|---|---|---|---|---|---|
| Walking | Standing | Average | Cross | Not Cross | Average | |
| Proposed Method with Ground-Truth Boundary Box | 91.49% | 72.35% | 88.75% | 86.43% | 71.04% | 79.13% |
| Proposed Method with Detecting and Tracking alogorithm | 90.87% | 72.23% | 88.47% | 74.50% | 70.63% | 72.90% |
| Method | Ground-Truth Boundary Box | Action | Cross |
|---|---|---|---|
| Mordan [31] | X | 29.90% | 60.20% |
| Two-stream CNN (Park [25]) | O | 88.70% | 76.44% |
| Proposed Method | O | 88.75% | 79.13% |
| Proposed Method with Detecting and Tracking alogorithm | X | 88.47% | 72.90% |
| Name | Ground-Truth Boundary Box | Action Accuracy |
|---|---|---|
| Marginean [26] | O | 79.73% |
| Two-Stream CNN (Park [25]) | O | 88.70% |
| Proposed Method | O | 88.75% |
| Proposed Method with Detecting and Tracking alogorithm | X | 88.47% |
| Name | Ground-Truth Boundary Box | Cross Accuracy |
|---|---|---|
| Pop [42] | O | 61.31% |
| Liu [39] | O | 79.28% |
| Marginean [26] | O | 81.00% |
| Wang [27] | O | 81.23% |
| Chaabane [43] | O | 86.70% |
| Fang [28] | O | 88.00% |
| Singh [46] | O | 84.89% |
| Two-Stream CNN (Park [25]) | O | 76.44% |
| Proposed Method | O | 79.13% |
| Proposed Method with Detecting and Tracking alogorithm | X | 72.90% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Park, S.K.; Chung, J.H.; Pae, D.S.; Lim, M.T. Binary Dense SIFT Flow Based Position-Information Added Two-Stream CNN for Pedestrian Action Recognition. Appl. Sci. 2022, 12, 10445. https://doi.org/10.3390/app122010445
Park SK, Chung JH, Pae DS, Lim MT. Binary Dense SIFT Flow Based Position-Information Added Two-Stream CNN for Pedestrian Action Recognition. Applied Sciences. 2022; 12(20):10445. https://doi.org/10.3390/app122010445
Chicago/Turabian StylePark, Sang Kyoo, Jun Ho Chung, Dong Sung Pae, and Myo Taeg Lim. 2022. "Binary Dense SIFT Flow Based Position-Information Added Two-Stream CNN for Pedestrian Action Recognition" Applied Sciences 12, no. 20: 10445. https://doi.org/10.3390/app122010445