
Multipointer Coattention Recommendation with Gated Neural Fusion between ID Embedding and Reviews

Abstract
:1. Introduction
- The proposed MPCAR model first uses a review gating mechanism to extract important reviews from the input sequence (user reviews and item reviews). Then, it uses review-level coattention and a multipointer learning scheme to extract the most informative reviews and models these reviews at the word level to capture richer interactions;
- ID embedding that reveals the identity of users and items is introduced. In addition, a gated neural fusion layer is designed to effectively integrate ID embedding and review features to generate the final comprehensive representation of users (items). Finally, the final representations of users and items are fed into a factorization machine (FM) to predict users’ ratings of the target items;
- The MPCAR model was evaluated on real datasets from Amazon in ten different domains. The experimental results of the model outperformed those of existing popular methods.
2. Related Work
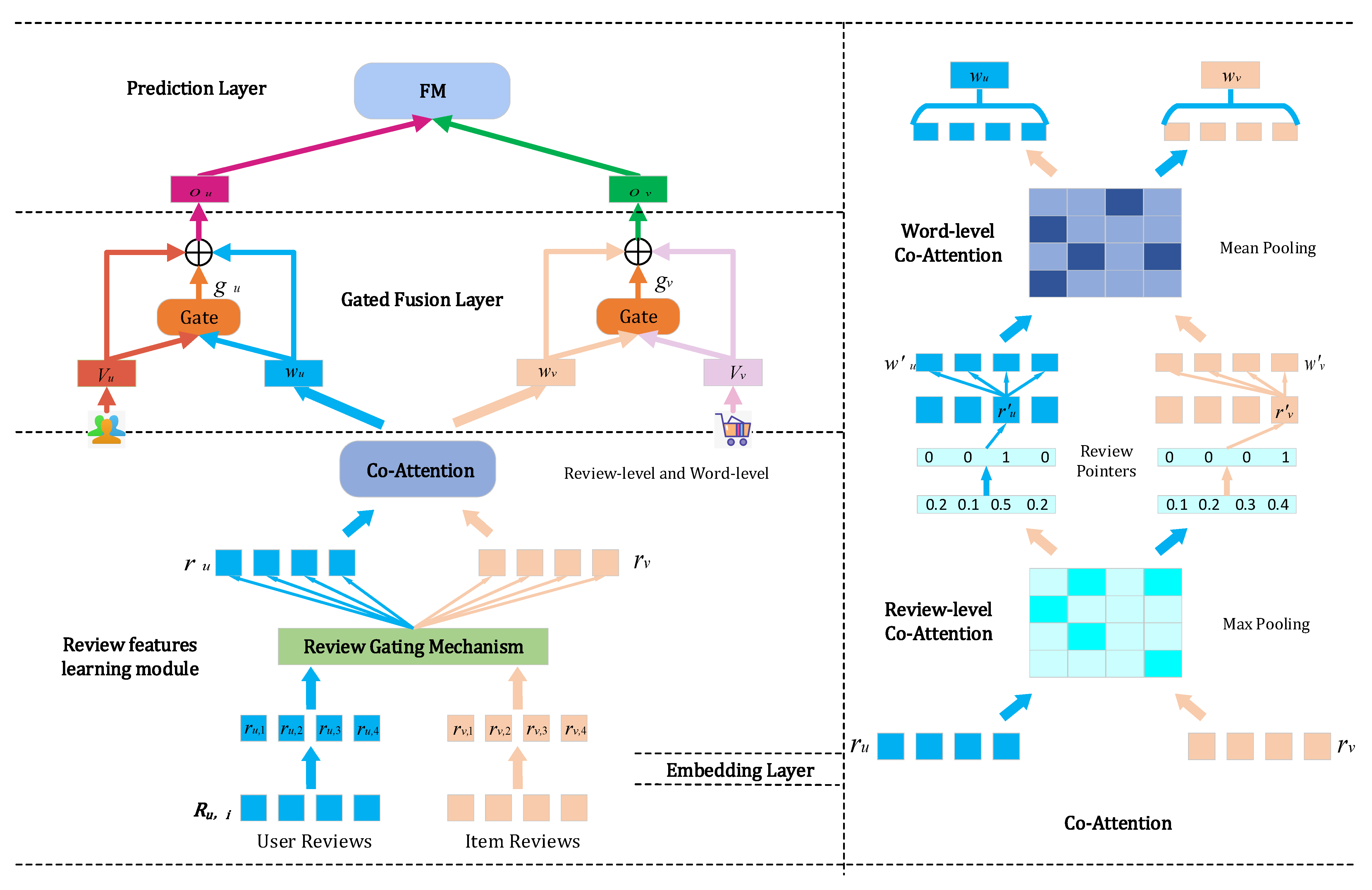
3. Model Architecture
3.1. Review Feature Learning Module
- Embedding Layer. In the embedding layer, we calculate the initial review embedding according to the embedding method in the MPCN model. Given review consisting of a series of words, these words are represented as one-hot encoding vectors. Then, all words are passed into an embedding matrix. With the embedding matrix, we retrieve a d-dimensional vector for each word and finally construct user review embeddings ,, …, and item review embeddings ,, …, according to a series of words.
- Review Gating Mechanism. Regardless of whether reviews written by users or reviews written for items are used, the information contained in these reviews is different, and not every review contains useful information. Here, we use a review gating mechanism to filter out useful review information.where ⊙ is the Hadamard product and is the sigmoid activation function. is the i-th review in sequence . , and , are the parameters of this layer.
- Review-level Coattention. We use a review gating mechanism to select informative reviews and from review libraries of user u and item v, respectively, as this layer of the input list. We first calculate the affinity matrix between them using Formula (2) and then obtain the row and column maximum values of the matrix using the max pooling function of Formula (3). We transform the maximum value into a one-hot vector (pointers ) using the Gumbel–Softmax and apply these pointers to the original review list of the users (items) to obtain the th review of user u and the th review of item , respectively. The description is as follows:where and . is a feed-forward neural network with L layers. The reason for adopting the maximum pooling function is that max pooling will select the most influential review among all the reviews of its partners. Gumbel represents the Gumbel–Softmax [35], which returns a one-hot vector, as shown in Formulas (4) and (5). Because of the nondifferentiability of argmax, it is challenging to use discrete variables in neural networks. However, the Gumbel–Softmax replaces the argmax function with a differentiable softmax function that can support the use of discrete vectors in end-to-end neural networks.
- Word-level Coattention. At the review level coattention layer, each review is compressed into a single embedding resulting in word information smoothing. To prevent word information smoothing, we extract the most informative reviews and using review pointers and then use word-level coattention to model these reviews to obtain deep-level word-level interaction information. Formula (6) computes an affinity matrix between and :where , and is the standard L-layer feed-forward neural network.
3.2. Gated Fusion Layer
3.3. Prediction Layer
4. Experimental Evaluation
4.1. Datasets and Evaluation Metric
- Regarding the dataset, we choose the Amazon 5-core version [38,39] of the Amazon review public dataset, which contains a total of 24 subcategory datasets. In the experiment, we used 10 subcategory datasets to verify our MPCAR model. These 10 subdatasets all contain real user reviews from Amazon between May 1996 and July 2014. All datasets contain users, items, and user reviews and ratings of items. Each user in the dataset has posted at least five or more reviews on the platform. The details of the dataset are shown in Table 2. We randomly divided the interactive data into training set (80%), validation set (10%), and test set (10%).
- In this paper, we use mean squared error (MSE) and mean absolute error (MAE) as the evaluation metrics for model performance. These two metrics are derived by calculating the difference between the true rating and the predicted rating to measure the accuracy of rating prediction. Smaller values of MSE and MAE indicate that the predicted value is closer to the true value and the accuracy of the model prediction result is higher. Given the predicted rating and the true rating of user u for item v, MSE and MAE are defined by the following formulas:where represents the number of samples in the testing sets.
4.2. Compared Models
- Matrix factorization (MF) [4] is a commonly used benchmark. It uses the inner product to represent user and item scores.
- The deep collaborative neural network (DeepCoNN) [5] combines a user review set and an item review set to model users and items through a CNN. It trains the convolutional representation of the user and the item and passes the cascaded embedding into the FM model.
- Dual attention CNN model (D-ATT) [32], which uses reviews to make recommendations is the latest model based on a CNN. The model is characterized by using two forms of attention (local and global). End-user (item) representations are learned by combining representations learned from local and global attention. The representation of users and items is predicted by scoring using the dot product.
- NARRE [6] uses two parallel neural networks, both of which include a convolutional layer and an attention layer, to capture the usefulness of reviews, to model users, and items.
- MPCN [7] uses a pointer network to learn the characteristics of users and target items from words and reviews and transfers the final representation of users and items to the FM model.
4.3. Experimental Setting
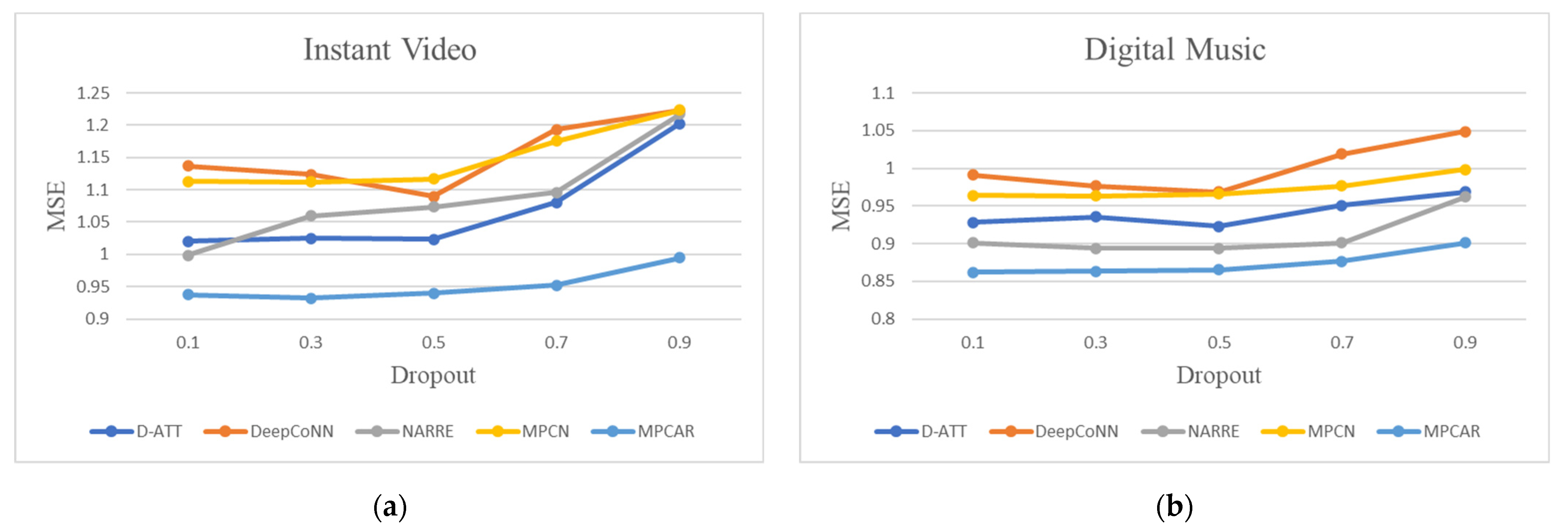
4.4. Performance Evaluation (RQ1)
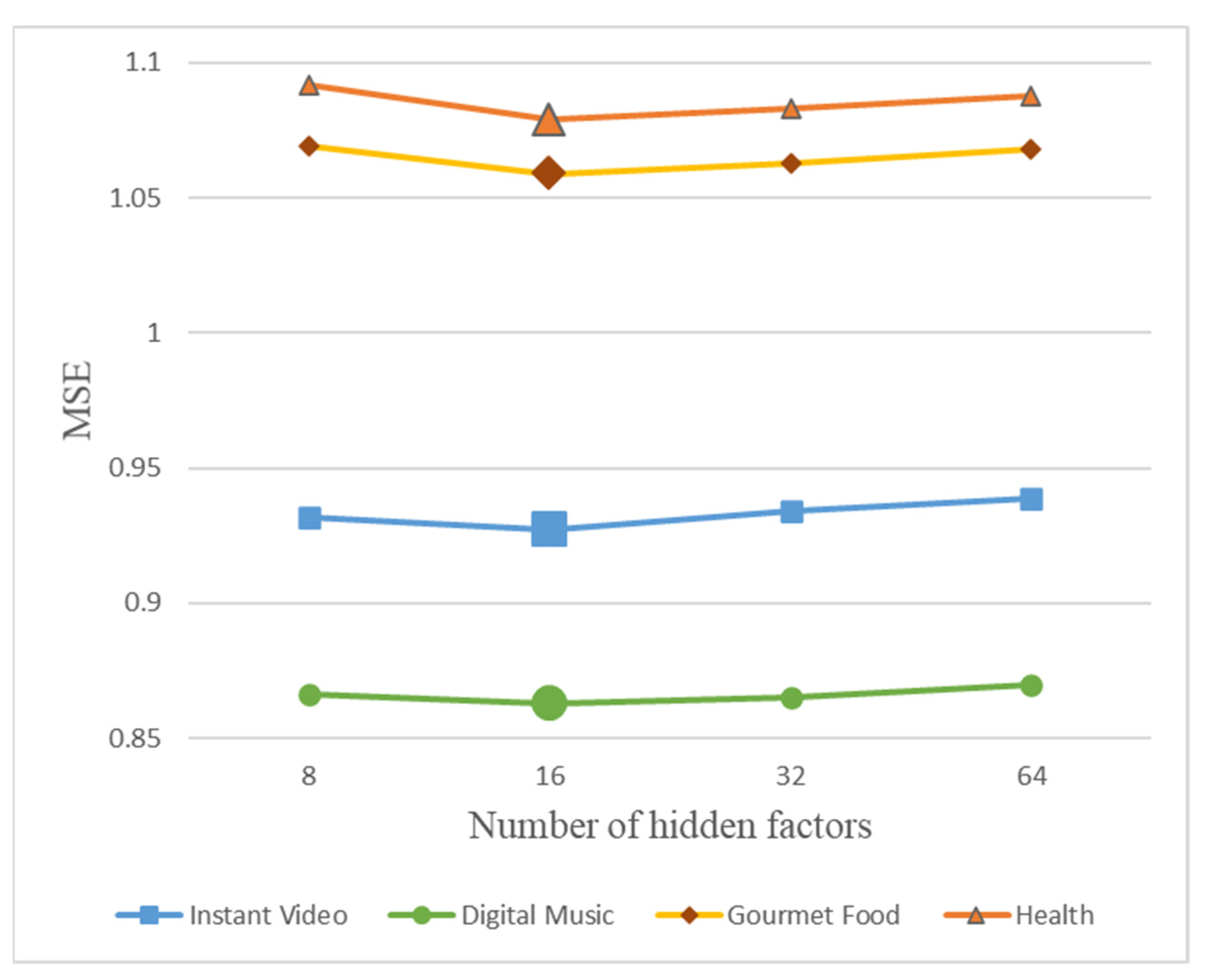
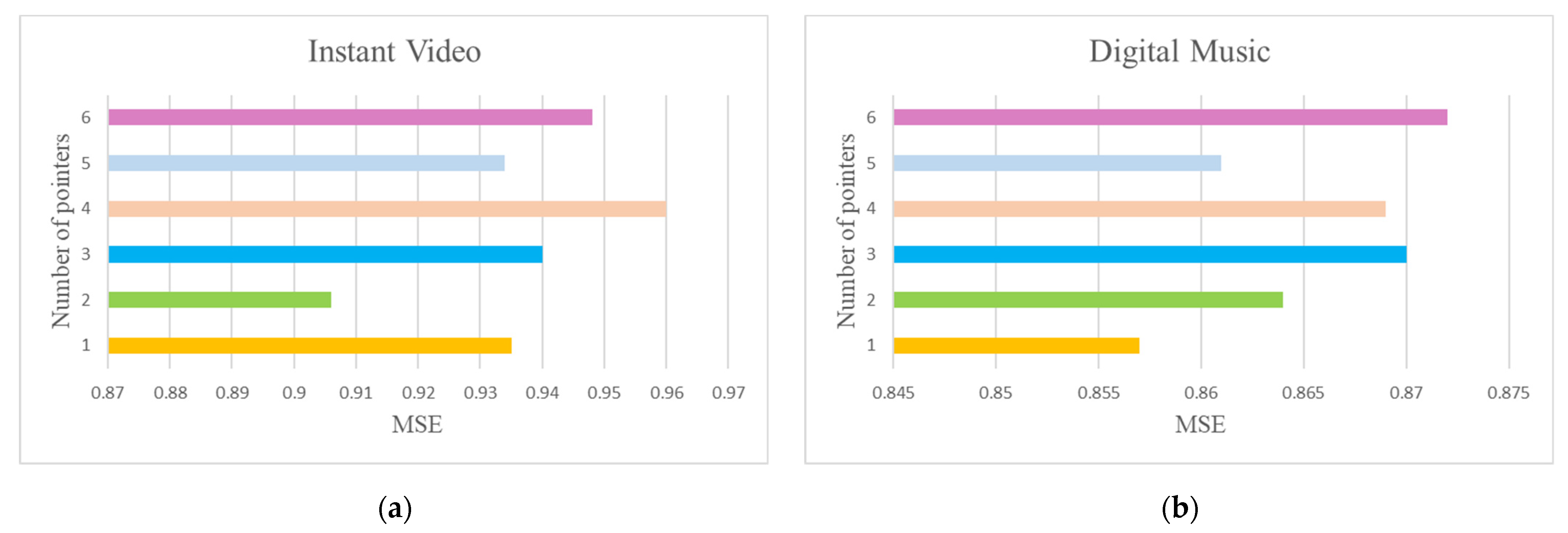
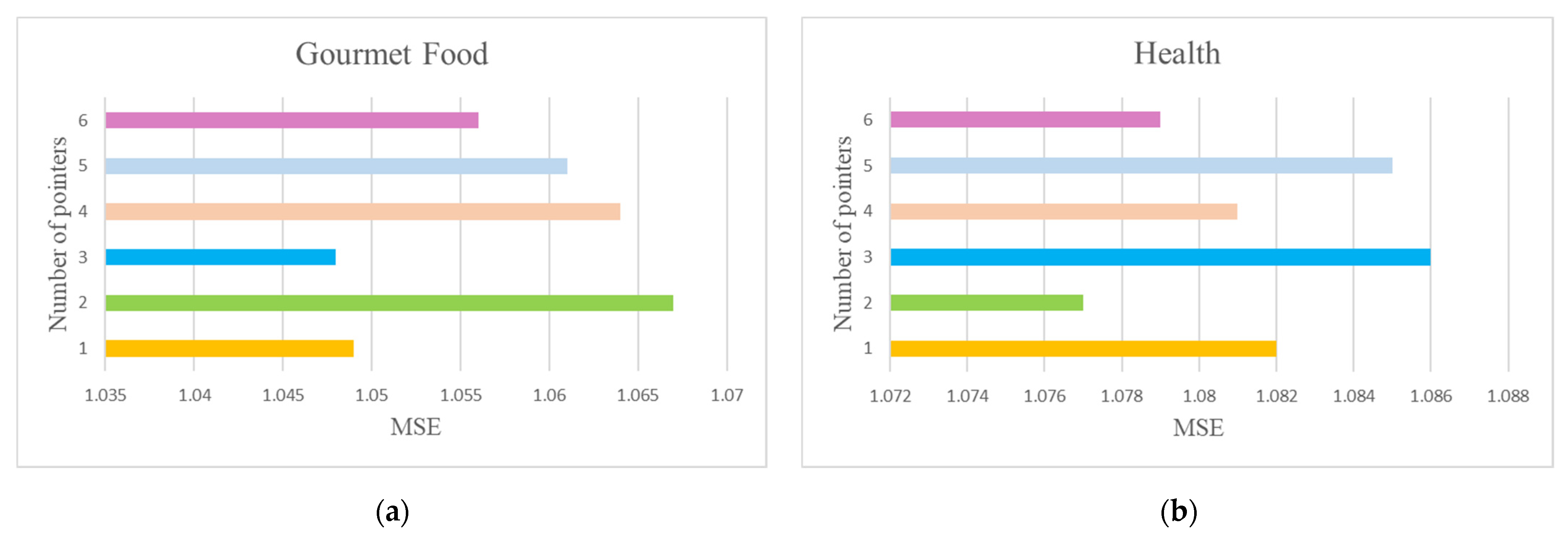
4.5. Parameter Sensitivity Analysis (Q2)
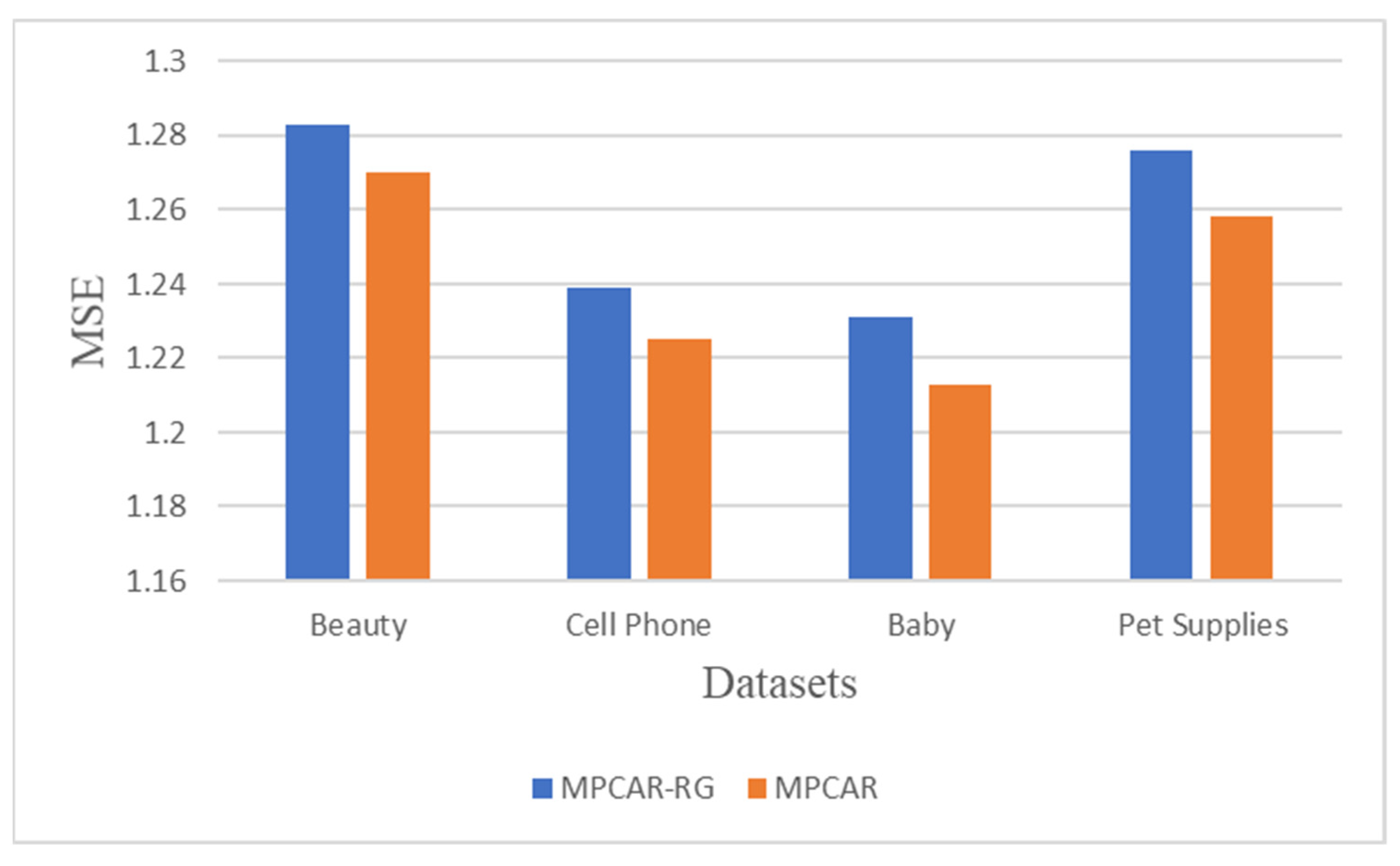
4.6. Gated Neural Network Ablation Analysis (Q3)
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Dropout can be used as a trick choice for training neural networks. In each training batch, ignoring a certain number of neurons with a certain probability can significantly reduce overfitting. In our approach, we set the dropout parameter to 0.2 to prevent the model from overfitting.
- We use L2 regularization to reduce the complexity of the MPCAR model. L2 regularization reduces the complexity of the neural network by reducing the size of the parameter value and prevents the model from overfitting to a certain extent.
- The optimal result of the model depends on whether the appropriate number of hidden factors is selected. Too many hidden factors may cause the model to overfit. According to previous work, we determine the range of the number of hidden factors as (8, 16, 32, 64), and find the optimal number of hidden factors in this range.
References
- Sharma, L.; Gera, A. A survey of recommendation system: Research challenges. Int. J. Eng. Trends Technol. 2013, 4, 1989–1992. [Google Scholar]
- Shah, L.; Gaudani, H.; Balani, P. Survey on recommendation system. Int. J. Comput. Appl. 2016, 137, 43–49. [Google Scholar] [CrossRef]
- Kanwal, S.; Nawaz, S.; Malik, M.K.; Nawaz, Z. A Review of Text-Based Recommendation Systems. IEEE Access 2021, 9, 31638–31661. [Google Scholar] [CrossRef]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Zheng, L.; Noroozi, V.; Yu, P.S. Joint deep modeling of users and items using reviews for recommendation. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining, Cambridge, UK, 6–10 February 2017; pp. 425–434. [Google Scholar]
- Chen, C.; Zhang, M.; Liu, Y.; Ma, S. Neural attentional rating regression with review-level explanations. In Proceedings of the 2018 World Wide Web Conference, Lyon, France, 23–27 April 2018; pp. 1583–1592. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C. Multi-pointer co-attention networks for recommendation. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; pp. 2309–2318. [Google Scholar]
- Ma, H.; King, I.; Lyu, M.R. Effective missing data prediction for collaborative filtering. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Amsterdam, The Netherlands, 23–27 July 2007; pp. 39–46. [Google Scholar]
- Zhang, Z.; Guo, X. Optimized collaborative filtering recommendation algorithm based on item rating prediction. Appl. Res. Comput. 2008, 9, 2658–2660. [Google Scholar]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International Conference on World Wide Web, Hong Kong, China, 1–5 May 2001; pp. 285–295. [Google Scholar]
- Herlocker, J.L.; Konstan, J.A.; Riedl, J. Explaining collaborative filtering recommendations. In Proceedings of the 2000 ACM Conference on Computer Supported Cooperative Work, Philadelphia, PA, USA, 2–6 December 2000; pp. 241–250. [Google Scholar]
- Wei, J.; He, J.; Chen, K.; Zhou, Y.; Tang, Z. Collaborative filtering and deep learning based recommendation system for cold start items. Expert Syst. Appl. 2017, 69, 29–39. [Google Scholar] [CrossRef] [Green Version]
- Mnih, A.; Salakhutdinov, R. Probabilistic matrix factorization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2008; pp. 1257–1264. [Google Scholar]
- Junliang, L.; Xiaoguang, L. Technical progress of personalized recommendation system. Comput. Sci. 2020, 47, 47–55. [Google Scholar]
- Cao, L. Coupling learning of complex interactions. Inf. Process. Manag. 2015, 51, 167–186. [Google Scholar] [CrossRef]
- Cao, L. Non-iid recommender systems: A review and framework of recommendation paradigm shifting. Engineering 2016, 2, 212–224. [Google Scholar] [CrossRef] [Green Version]
- He, X.; Chua, T.-S. Neural factorization machines for sparse predictive analytics. In Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 355–364. [Google Scholar]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.-S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Catherine, R.; Cohen, W. Transnets: Learning to transform for recommendation. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 288–296. [Google Scholar]
- Wu, L.; Quan, C.; Li, C.; Wang, Q.; Zheng, B.; Luo, X. A context-aware user-item representation learning for item recommendation. ACM Trans. Inf. Syst. 2019, 37, 1–29. [Google Scholar] [CrossRef] [Green Version]
- Chin, J.Y.; Zhao, K.; Joty, S.; Cong, G. ANR: Aspect-based neural recommender. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, Torino, Italy, 22–26 October 2018; pp. 147–156. [Google Scholar]
- Liu, D.; Li, J.; Du, B.; Chang, J.; Gao, R. Daml: Dual attention mutual learning between ratings and reviews for item recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 344–352. [Google Scholar]
- Hyun, D.; Park, C.; Yang, M.-C.; Song, I.; Lee, J.-T.; Yu, H. Review sentiment-guided scalable deep recommender system. In Proceedings of the 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, Ann Arbor, MI, USA, 8–12 July 2018; pp. 965–968. [Google Scholar]
- Liu, H.; Wu, F.; Wang, W.; Wang, X.; Jiao, P.; Wu, C.; Xie, X. NRPA: Neural recommendation with personalized attention. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 1233–1236. [Google Scholar]
- Wu, C.; Wu, F.; Liu, J.; Huang, Y. Hierarchical user and item representation with three-tier attention for recommendation. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Long and Short Papers. Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; Volume 1, pp. 1818–1826. [Google Scholar]
- Dong, X.; Ni, J.; Cheng, W.; Chen, Z.; Zong, B.; Song, D.; Liu, Y.; Chen, H.; De Melo, G. Asymmetrical hierarchical networks with attentive interactions for interpretable review-based recommendation. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2020; pp. 7667–7674. [Google Scholar]
- Huang, J.; Rogers, S.; Joo, E. Improving restaurants by extracting subtopics from yelp reviews. In Proceedings of the iConference 2014 (Social Media Expo), Berlin, Germany, 4–7 April 2014; iSchools: Grandville, MI, USA, 2014; pp. 1–5. [Google Scholar]
- Bao, Y.; Fang, H.; Zhang, J. Topicmf: Simultaneously exploiting ratings and reviews for recommendation. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.; Wang, L.; Peng, Z.; Guo, W. based hierarchical attention cooperative neural networks for recommendation. Neurocomputing 2021, 447, 38–47. [Google Scholar] [CrossRef]
- Kim, D.; Park, C.; Oh, J.; Lee, S.; Yu, H. Convolutional matrix factorization for document context-aware recommendation. In Proceedings of the 10th ACM Conference on Recommender Systems, Boston, MA, USA, 15–19 September 2016; pp. 233–240. [Google Scholar]
- Seo, S.; Huang, J.; Yang, H.; Liu, Y. Interpretable convolutional neural networks with dual local and global attention for review rating prediction. In Proceedings of the Eleventh ACM Conference on Recommender Systems, Como, Italy, 27–31 August 2017; pp. 297–305. [Google Scholar]
- Wu, H.; Zhang, Z.; Yue, K.; Zhang, B.; He, J.; Sun, L. Dual-regularized matrix factorization with deep neural networks for recommender systems. Knowl. Based Syst. 2018, 145, 46–58. [Google Scholar] [CrossRef]
- Rendle, S. Factorization machines. In Proceedings of the 2010 IEEE International Conference on Data Mining, Washington, DC, USA, 13–17 December 2010; pp. 995–1000. [Google Scholar]
- Jang, E.; Gu, S.; Poole, B. Categorical reparameterization with gumbel-softmax. arXiv 2016, arXiv:1611.01144. [Google Scholar]
- Ling, G.; Lyu, M.R.; King, I. Ratings meet reviews, a combined approach to recommend. In Proceedings of the 8th ACM Conference on Recommender Systems, Silicon Valley, CA, USA, 6–10 October 2014; pp. 105–112. [Google Scholar]
- McAuley, J.; Leskovec, J. Hidden factors and hidden topics: Understanding rating dimensions with review text. In Proceedings of the 7th ACM conference on Recommender Systems, Hong Kong, China, 12–16 October 2013; pp. 165–172. [Google Scholar]
- He, R.; McAuley, J. Ups and downs: Modeling the visual evolution of fashion trends with one-class collaborative filtering. In Proceedings of the 25th International Conference on World Wide Web, Montréal, QC, Canada, 11–15 April 2016; pp. 507–517. [Google Scholar]
- McAuley, J.; Targett, C.; Shi, Q.; Van Den Hengel, A. Image-based recommendations on styles and substitutes. In Proceedings of the 38th International ACM SIGIR Conference on Research and Development in Information Retrieval, Santiago, Chile, 9–13 August 2015; pp. 43–52. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Definitions |
|---|---|
| User reviews and item reviews | |
| The i-th review of user u | |
| The j-th review of item v | |
| and | Informative reviews from review libraries of user u and item v |
| TThe affinity matrix between and | |
| and | The most informative reviews from user u and item v |
| and | One-hot vector (pointers) |
| The affinity matrix between and | |
| and | The word-level representations of user u and user v |
| and | Combinations of multiple word-level representations of user u and user v |
| and | The ID embedding of user u and user v |
| and | The interaction information between ID embedding and review features |
| and | The final representations of user u and item v |
| Datasets | Number of Users | Number of Items | Number of Reviews |
|---|---|---|---|
| Instant Video | 5130 | 1685 | 37,126 |
| Instruments | 1429 | 900 | 10,261 |
| Beauty | 22,363 | 12,101 | 198,475 |
| Cellphone | 27,879 | 10,429 | 194,340 |
| Gourmet Food | 14,681 | 8713 | 151,232 |
| Health | 38,609 | 18,534 | 346,307 |
| Office Products | 4905 | 2420 | 53,237 |
| Baby | 19,445 | 7050 | 160,732 |
| Digital Music | 5541 | 3568 | 64,705 |
| Pet Supplies | 19,856 | 8510 | 157,683 |
| Methods | ID Embedding | Document | Review | Deep Learning |
|---|---|---|---|---|
| MF | × | × | × | × |
| DeepCoNN | × | √ | × | √ |
| D-ATT | × | √ | × | √ |
| NARRE | √ | × | √ | √ |
| MPCN | × | × | √ | √ |
| MPCAR | √ | × | √ | √ |
| Baseline Approaches | Our Approach | Improvement (%) | ||||||
|---|---|---|---|---|---|---|---|---|
| Metrics | Datasets | MF [4] | D-ATT [32] | DeepCoNN [5] | NARRE [6] | MPCN [7] | MPCAR | ∆MN |
| MSE | Instant Video | 2.769 | 1.004 | 1.285 | 1.096 | 0.997 | 0.906 | 10 |
| Instruments | 6.720 | 0.964 | 1.483 | 0.951 | 0.923 | 0.858 | 7.6 | |
| Beauty | 1.950 | 1.409 | 1.453 | 1.396 | 1.387 | 1.270 | 9.2 | |
| Cellphone | 1.972 | 1.452 | 1.524 | 1.429 | 1.413 | 1.225 | 15.3 | |
| Gourmet Food | 1.537 | 1.143 | 1.199 | 1.106 | 1.125 | 1.054 | 6.7 | |
| Health | 1.882 | 1.269 | 1.299 | 1.246 | 1.238 | 1.077 | 14.9 | |
| Office Products | 1.143 | 0.805 | 0.909 | 0.817 | 0.779 | 0.682 | 14.2 | |
| Baby | 1.755 | 1.325 | 1.440 | 1.318 | 1.304 | 1.213 | 7.5 | |
| Digital Music | 1.956 | 1.000 | 1.202 | 0.965 | 0.970 | 0.857 | 13.1 | |
| Pet Supplies | 1.736 | 1.337 | 1.447 | 1.316 | 1.328 | 1.258 | 5.6 | |
| MAE | Instant Video | 1.467 | 0.770 | 0.839 | 0.768 | 0.781 | 0.715 | 9.2 |
| Instruments | 2.38 | 0.689 | 0.751 | 0.718 | 0.697 | 0.670 | 4 | |
| Beauty | 1.381 | 0.837 | 0.922 | 0.828 | 0.894 | 0.813 | 10 | |
| Cellphone | 1.494 | 0.871 | 0.893 | 0.874 | 0.867 | 0.797 | 8.7 | |
| Gourmet Food | 1.206 | 0.731 | 0.718 | 0.731 | 0.704 | 0.693 | 1.6 | |
| Health | 1.27 | 0.725 | 0.739 | 0.727 | 0.712 | 0.703 | 1.3 | |
| Office Products | 0.996 | 0.754 | 0.707 | 0.720 | 0.670 | 0.615 | 8.9 | |
| Baby | 1.32 | 0.845 | 0.873 | 0.851 | 0.858 | 0.803 | 6.8 | |
| Digital Music | 1.204 | 0.697 | 0.722 | 0.686 | 0.729 | 0.660 | 10.4 | |
| Pet Supplies | 1.375 | 0.823 | 0.850 | 0.826 | 0.822 | 0.809 | 1.6 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shao, J.; Qin, J.; Zeng, W.; Zheng, J. Multipointer Coattention Recommendation with Gated Neural Fusion between ID Embedding and Reviews. Appl. Sci. 2022, 12, 594. https://doi.org/10.3390/app12020594
Shao J, Qin J, Zeng W, Zheng J. Multipointer Coattention Recommendation with Gated Neural Fusion between ID Embedding and Reviews. Applied Sciences. 2022; 12(2):594. https://doi.org/10.3390/app12020594
Chicago/Turabian StyleShao, Jianjie, Jiwei Qin, Wei Zeng, and Jiong Zheng. 2022. "Multipointer Coattention Recommendation with Gated Neural Fusion between ID Embedding and Reviews" Applied Sciences 12, no. 2: 594. https://doi.org/10.3390/app12020594