
Projection Pursuit Multivariate Sampling of Parameter Uncertainty

Abstract
:1. Introduction
2. Sampling Techniques
2.1. Monte Carlo Simulation
2.2. Latin Hypercube Sampling
- Set the initial value of the minimum Euclidean distance to zero, .
- Generate a sampling design using CLHS.
- Calculate the minimum Euclidean distance from the CLHS design generated in step 2.
- If , with , set the new initial minimum Euclidean distance value as , that is, .
- Return to step 2 and repeat the steps L times.
- End.
- For each realization , calculate the Euclidean distance to other realizations and average the two smallest calculated distances.
- For the realization i, save the average distance and return step 2 until all of the average distances are calculated for all of the realizations .
- Remove the realization for which the smallest Euclidean distance is calculated in step 2.
- Return to step 2 and repeat the steps until the remaining number of realizations is equal to the number of realizations n that is selected initially, that is, .
- For variable j, , rank the n realizations and use these rankings as random permutations (or a stratum).
- Generate random numbers for the n number of strata.
- Sample the CDF of the variable j using the random numbers generated in step 7.
- Increment j, and return to step 6 until the ranking and sampling are carried out for all k variables.
- End.
2.3. Projection Pursuit Multivariate Transform
- Generate random numbers from a uniform distribution using MCS and establish these random numbers in a matrix .
- Transform the elements of matrix to the standard Gaussian values, that is, , where is the normal score transform.
- Compute the variance–covariance matrix of , that is, .
- Diagonalize∑, that is, , where denotes an orthogonal matrix of the eigenvectors and denotes the diagonal matrix of the eigenvalues.
- Sphere the elements of matrix ; that is, , where .
- Project onto k-dimensional unit length vector , that is, .
- Determine maximizing the projection index that measures the univariate non-Gaussianity.
- Transform to the standard Gaussian values so that the projection is univariate Gaussian. The steps for Gaussian transformation along a projection vector of can be found in Barnett et al. [33].
- Return to step 7 until the projection index reaches convergence. The stopping criteria for the optimization can be found in [24].
- Establish the final PPMT scores as a matrix where .
- Draw the probabilities from the standard Gaussian distribution and establish them in a matrix , where , where indicates a PPMT sampling design.
- End.
3. Case Studies
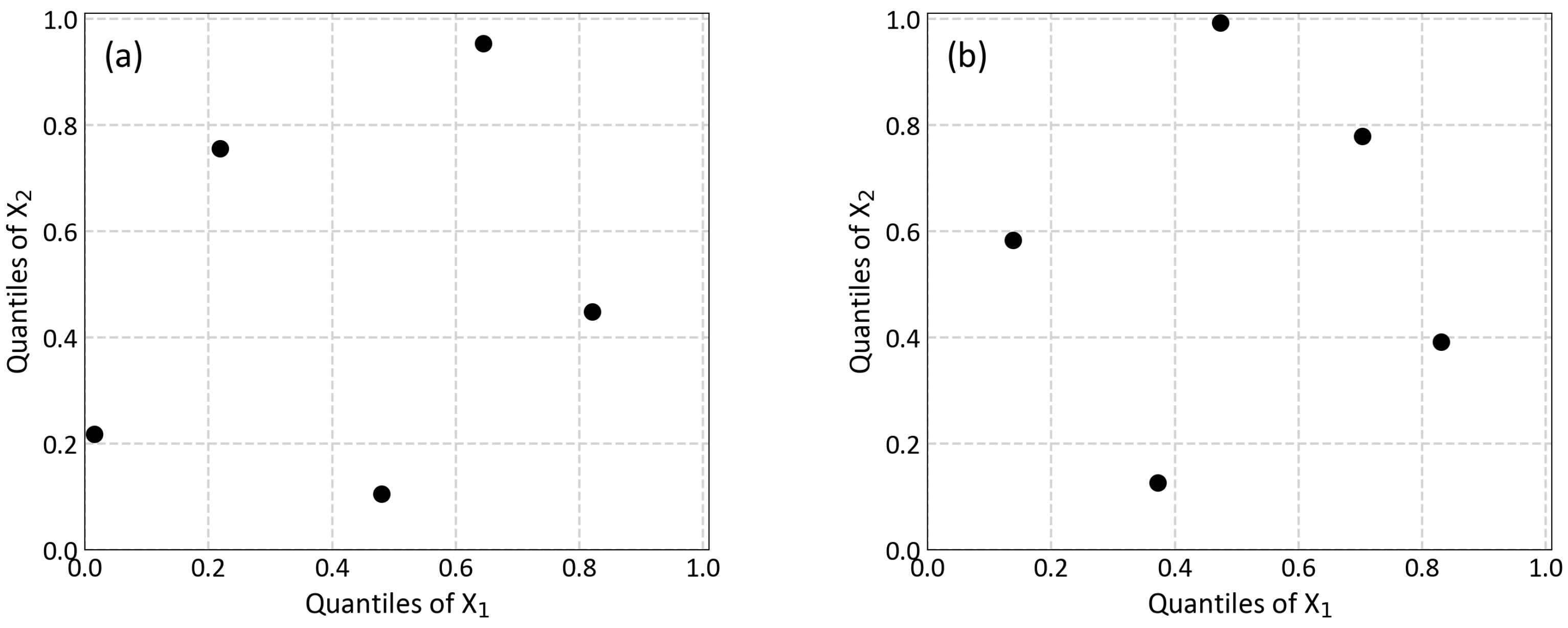
3.1. Synthetic Bivariate Case
3.2. Synthetic Five-Variate Case
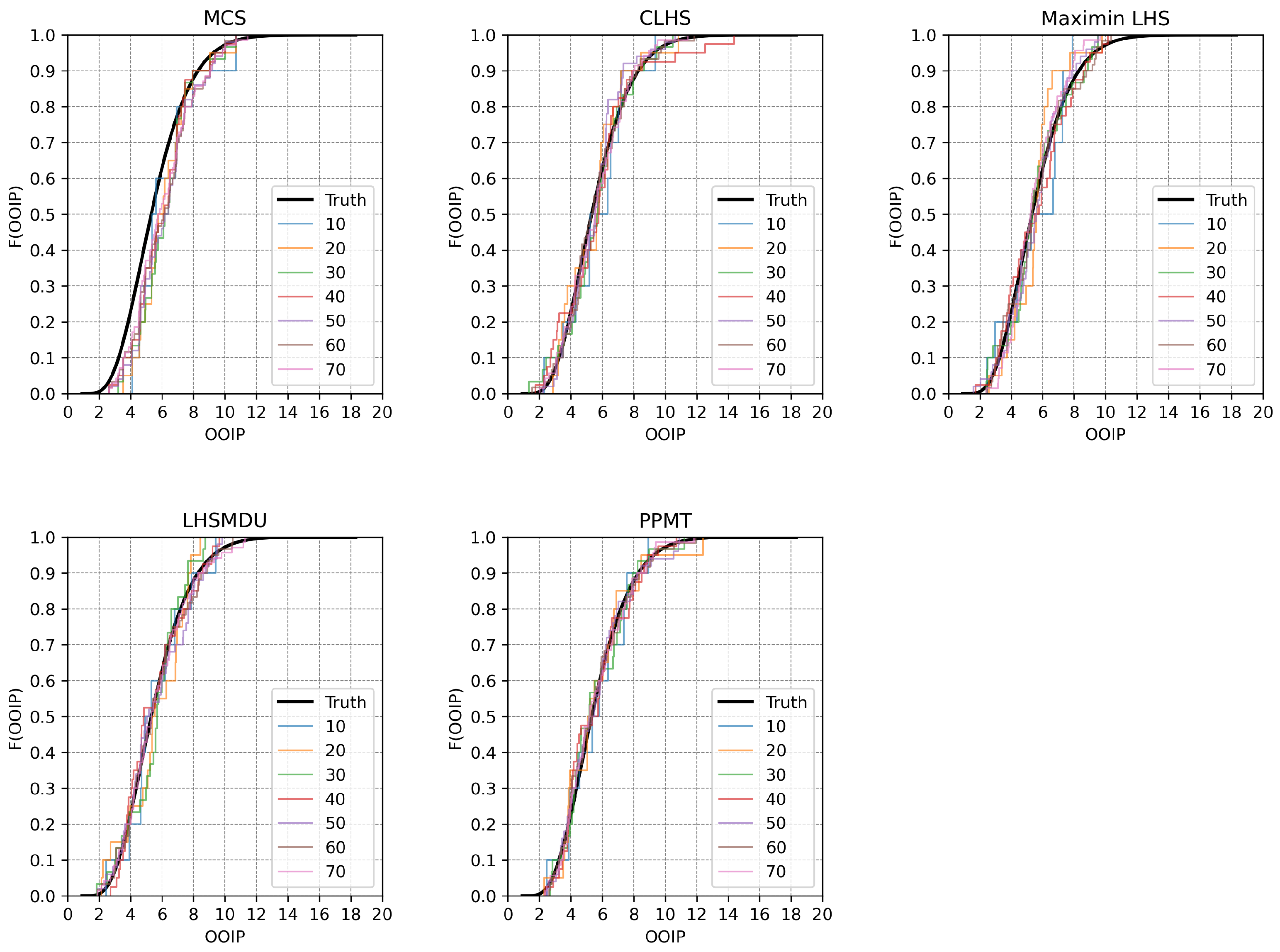
3.3. Quality Assessments of Sampling Designs
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
Abbreviations
| CDF | cumulative distribution function |
| CLHS | classic Latin hypercube sampling |
| CPU | central processing unit |
| LHS | Latin hypercube sampling |
| LHSMDU | Latin hypercube sampling with multidimensional uniformity |
| Maximin LHS | maximin Latin hypercube sampling |
| MCS | Monte Carlo simulation |
| OOIP | original oil in place |
| PPMT | projection pursuit multivariate transform |
| WL2 | Wraparound L2 |
References
- Deutsch, J.L.; Deutsch, C.V. Latin hypercube sampling with multidimensional uniformity. J. Stat. Plan. Inference 2012, 142, 763–772. [Google Scholar] [CrossRef]
- Erten, O.; Deutsch, C. Bootstrap. In Encyclopedia of Mathematical Geosciences; Daya Sagar, B., Cheng, Q., McKinley, J., Agterberg, F., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 1–5. [Google Scholar]
- James, F. Monte Carlo theory and practice. Rep. Prog. Phys. 1980, 43, 1145. [Google Scholar] [CrossRef]
- Fishman, G. Monte Carlo: Concepts, Algorithms, and Applications; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Law, A.M.; Kelton, W.D.; Kelton, W.D. Simulation Modeling and Analysis; McGraw-Hill: New York, NY, USA, 2000; Volume 3. [Google Scholar]
- Ortiz, J.C.; Deutsch, C.V. Testing pseudo-random number generators. In Third Annual Report of the Centre for Computational Geostatistics; University of Alberta: Edmonton, AB, Canada, 2001. [Google Scholar]
- Khodadadian, A.; Taghizadeh, L.; Heitzinger, C. Optimal multilevel randomized quasi-Monte-Carlo method for the stochastic drift–diffusion-Poisson system. Comput. Methods Appl. Mech. Eng. 2018, 329, 480–497. [Google Scholar] [CrossRef]
- McKay, M.D.; Beckman, R.J.; Conover, W.J. A comparison of three methods for selecting values of input variables in the analysis of output from a computer code. Technometrics 1979, 21, 239–245. [Google Scholar]
- McKay, M.D. Latin hypercube sampling as a tool in uncertainty analysis of computer models. In Proceedings of the 24th Conference on Winter Simulation, Arlington, VA, USA, 13–16 December 1992; pp. 557–564. [Google Scholar]
- Pebesma, E.J.; Heuvelink, G.B.M. Latin hypercube sampling of Gaussian random fields. Technometrics 1999, 41, 303–312. [Google Scholar] [CrossRef]
- Jin, R.; Chen, W.; Sudjianto, A. An efficient algorithm for constructing optimal design of computer experiments. J. Stat. Plan. Inference 2005, 134, 268–287. [Google Scholar] [CrossRef]
- Tang, B. Orthogonal Array-Based Latin Hypercubes. J. Am. Stat. Assoc. 1993, 88, 1392–1397. [Google Scholar] [CrossRef]
- Tang, B. Selecting Latin hypercubes using correlation criteria. Stat. Sin. 1998, 8, 965–977. [Google Scholar]
- Ye, K.Q.; Li, W.; Sudjianto, A. Algorithmic construction of optimal symmetric Latin hypercube designs. J. Stat. Plan. Inference 2000, 90, 145–159. [Google Scholar] [CrossRef]
- Morris, M.D.; Mitchell, T.J. Exploratory designs for computational experiments. J. Stat. Plan. Inference 1995, 43, 381–402. [Google Scholar] [CrossRef]
- Park, J.S. Optimal Latin-hypercube designs for computer experiments. J. Stat. Plan. Inference 1994, 39, 95–111. [Google Scholar] [CrossRef]
- Iman, R.L.; Conover, W.J. A distribution-free approach to inducing rank correlation among input variables. Commun. Stat.-Simul. Comput. 1982, 11, 311–334. [Google Scholar] [CrossRef]
- Olsson, A.M.J.; Sandberg, G.E. Latin hypercube sampling for stochastic finite element analysis. J. Eng. Mech. 2002, 128, 121–125. [Google Scholar] [CrossRef]
- Owen, A.B. Controlling correlations in Latin hypercube samples. J. Am. Stat. Assoc. 1994, 89, 1517–1522. [Google Scholar] [CrossRef]
- Stein, M. Large sample properties of simulations using Latin hypercube sampling. Technometrics 1987, 29, 143–151. [Google Scholar] [CrossRef]
- Johnson, M.E.; Moore, L.M.; Ylvisaker, D. Minimax and maximin distance designs. J. Stat. Plan. Inference 1990, 26, 131–148. [Google Scholar] [CrossRef]
- Kruskal, J.B. Toward a practical method which helps uncover the structure of a set of multivariate observations by finding the linear transformation which optimizes a new “index of condensation”. In Statistical Computation; Elsevier: Amsterdam, The Netherlands, 1969; pp. 427–440. [Google Scholar]
- Friedman, J.H.; Tukey, J.W. A projection pursuit algorithm for exploratory data analysis. IEEE Trans. Comput. 1974, 100, 881–890. [Google Scholar] [CrossRef]
- Barnett, R.M.; Manchuk, J.G.; Deutsch, C.V. Projection Pursuit Multivariate Transform. Math. Geosci. 2014, 46, 337–359. [Google Scholar] [CrossRef]
- Halton, J.H. A retrospective and prospective survey of the Monte Carlo method. Siam Rev. 1970, 12, 1–63. [Google Scholar] [CrossRef]
- Watkins, D.S. Fundamentals of Matrix Computations; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 64. [Google Scholar]
- Deutsch, C.V.; Journel, A.G. GSLIB Geostatistical Software Library and User’s Guide, 2nd ed.; Oxford University Press: New York, NY, USA, 1997; p. 369. [Google Scholar]
- Deutsch, C.; Begg, S. The use of ranking to reduce the required number of realizations. Centre for Computational Geostatistics (CCG) Annual Report. 2001. Available online: http://www.ccgalberta.com/ccgresources/report03/2001-115_value_of_ranking.pdf (accessed on 20 September 2022).
- Diaconis, P.; Freedman, D. Asymptotics of graphical projection pursuit. Ann. Stat. 1984, 12, 793–815. [Google Scholar] [CrossRef]
- Cook, D.; Buja, A.; Cabrera, J.; Hurley, C. Grand tour and projection pursuit. J. Comput. Graph. Stat. 1995, 4, 155–172. [Google Scholar]
- Hall, P. On polynomial-based projection indices for exploratory projection pursuit. Ann. Stat. 1989, 17, 589–605. [Google Scholar] [CrossRef]
- Klinke, S. Exploratory Projection Pursuit: The Multivariate and Discrete Case. 1995. Available online: https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.45.4509&rep=rep1&type=pdf (accessed on 20 September 2022).
- Barnett, R.M.; Manchuk, J.G.; Deutsch, C.V. The Projection-Pursuit Multivariate Transform for Improved Continuous Variable Modeling. SPE J. 2016, 21, 2010–2026. [Google Scholar] [CrossRef]
- Hickernell, F.J. Lattice Rules: How Well Do They Measure Up? In Random and Quasi-Random Point Sets; Hellekalek, P., Larcher, G., Eds.; Springer: New York, NY, USA, 1998; pp. 109–166. [Google Scholar]
- Johnson, R.A.; Wichern, D.W. (Eds.) Applied Multivariate Statistical Analysis; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 1988. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Distribution | Parameters |
|---|---|---|
| Triangular | , , | |
| Gaussian | , | |
| Uniform | , | |
| Triangular | , , | |
| Triangular | , , |
| Coefficients | MCS | CLHS | Maximin LHS | LHSMDU | PPMT |
|---|---|---|---|---|---|
| a | 1.267 | 1.056 | 0.980 | 0.803 | 0.717 |
| b | −0.488 | −0.504 | −0.484 | −0.449 | −0.477 |
| Coefficients | MCS | CLHS | Maximin LHS | LHSMDU | PPMT |
|---|---|---|---|---|---|
| a | 1.577 | 1.297 | 1.244 | 1.118 | 1.028 |
| b | −0.504 | −0.492 | −0.513 | −0.466 | −0.497 |
| MCS Equivalent Number of Realizations | ||||||||
|---|---|---|---|---|---|---|---|---|
| Reals# | CLHS | Maximin LHS | LHSMDU | PPMT | ||||
| 10 | 20 | 24 | 22 | 25 | 26 | 30 | 30 | 32 |
| 100 | 195 | 200 | 199 | 204 | 202 | 208 | 281 | 312 |
| 1000 | 1631 | 1657 | 1690 | 1703 | 1699 | 1715 | 3398 | 3401 |
| 10,000 | 15,948 | 16,144 | 17,055 | 17,899 | 17,064 | 17,956 | 21,034 | 21,945 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Erten, O.; Pereira, F.P.L.; Deutsch, C.V. Projection Pursuit Multivariate Sampling of Parameter Uncertainty. Appl. Sci. 2022, 12, 9668. https://doi.org/10.3390/app12199668
Erten O, Pereira FPL, Deutsch CV. Projection Pursuit Multivariate Sampling of Parameter Uncertainty. Applied Sciences. 2022; 12(19):9668. https://doi.org/10.3390/app12199668
Chicago/Turabian StyleErten, Oktay, Fábio P. L. Pereira, and Clayton V. Deutsch. 2022. "Projection Pursuit Multivariate Sampling of Parameter Uncertainty" Applied Sciences 12, no. 19: 9668. https://doi.org/10.3390/app12199668