

Financial Fraud Detection Based on Machine Learning: A Systematic Literature Review
 , , ,
, , ,  ,
, 
Abstract
:1. Introduction
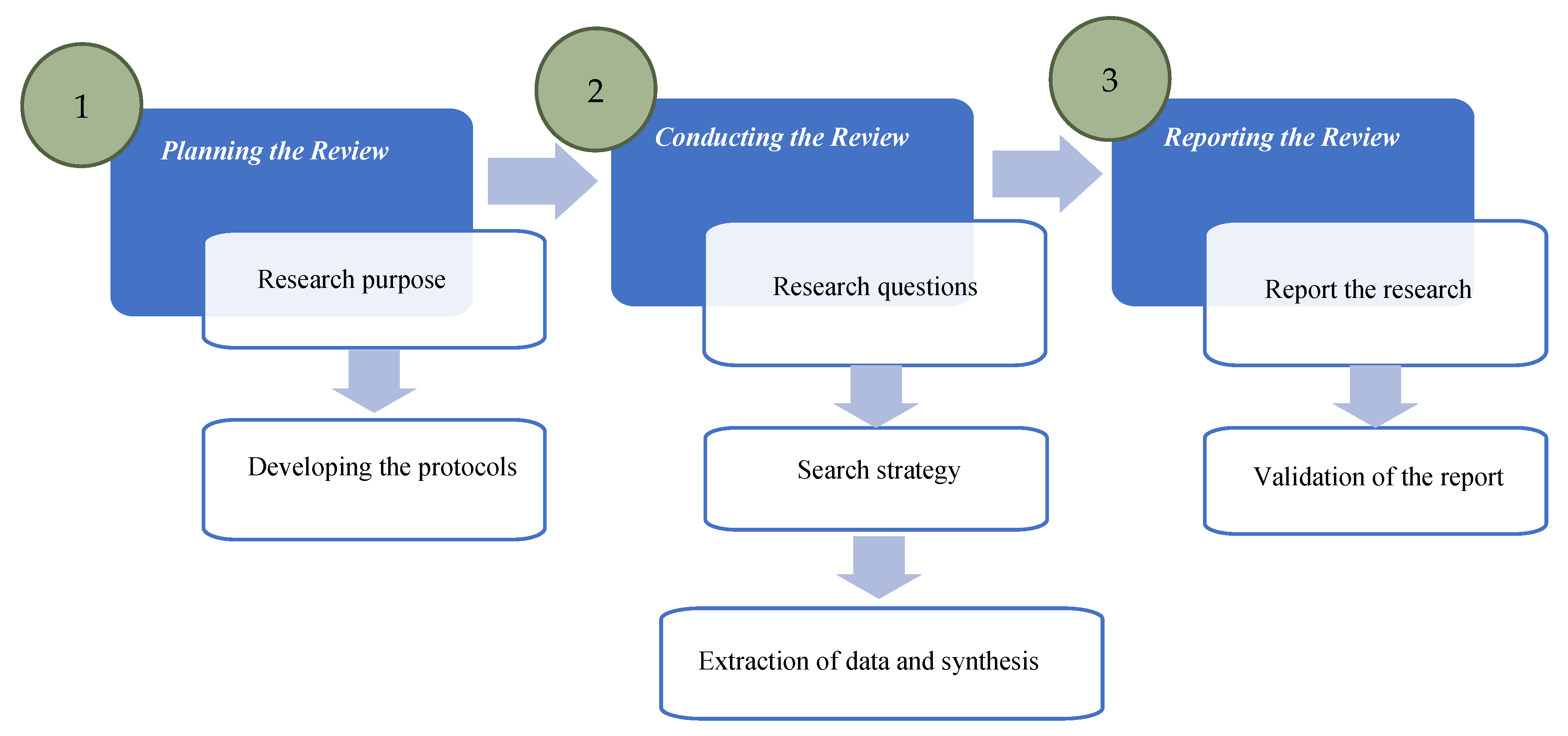
2. Research Methods
2.1. Review Planning
2.2. Conducting the Review
2.2.1. Research Questions
2.2.2. Search Strategy
2.2.3. Study Selection Criteria
2.3. Data Extraction and Synthesis
3. Search Results and Meta-Analysis
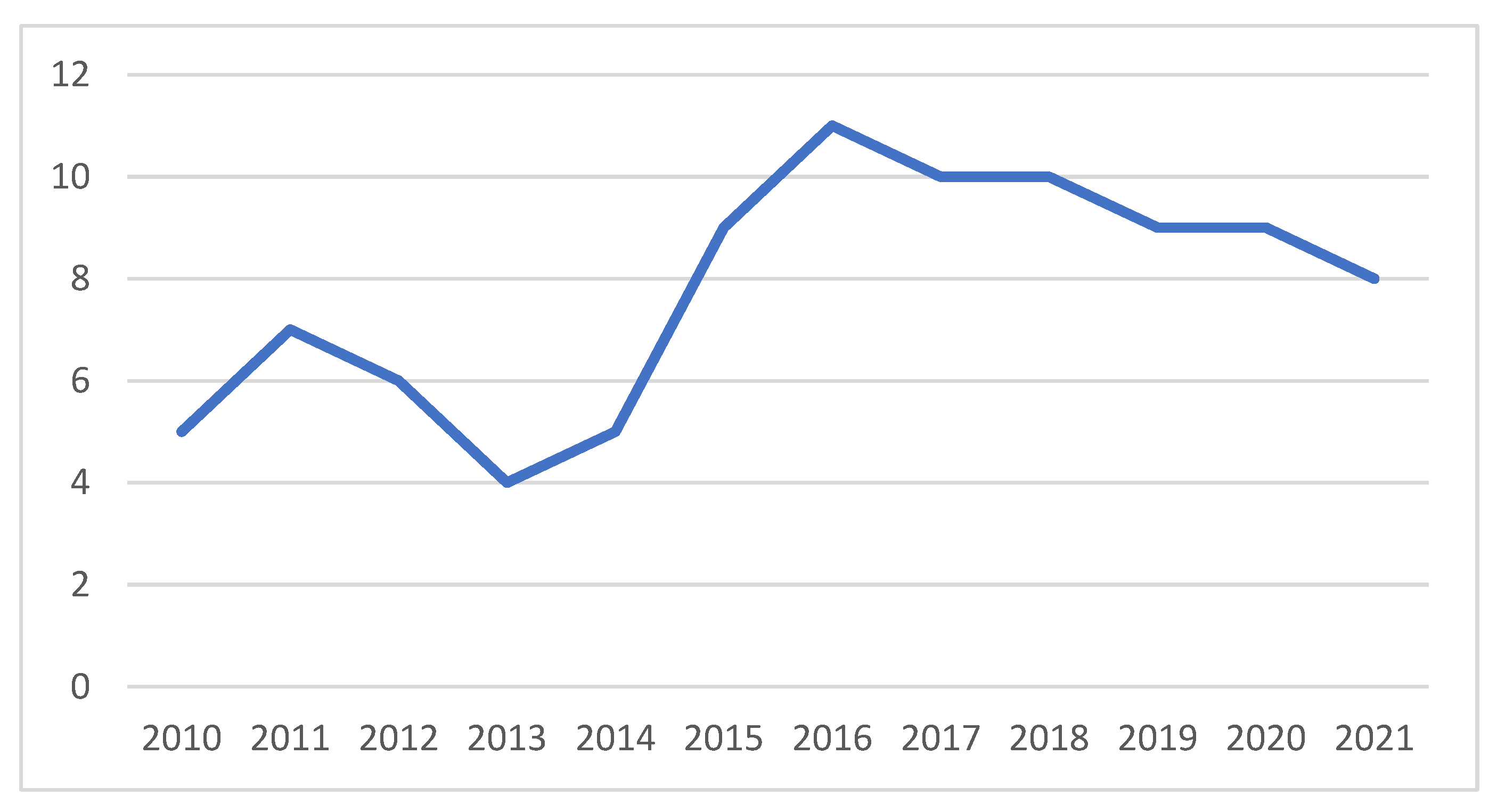
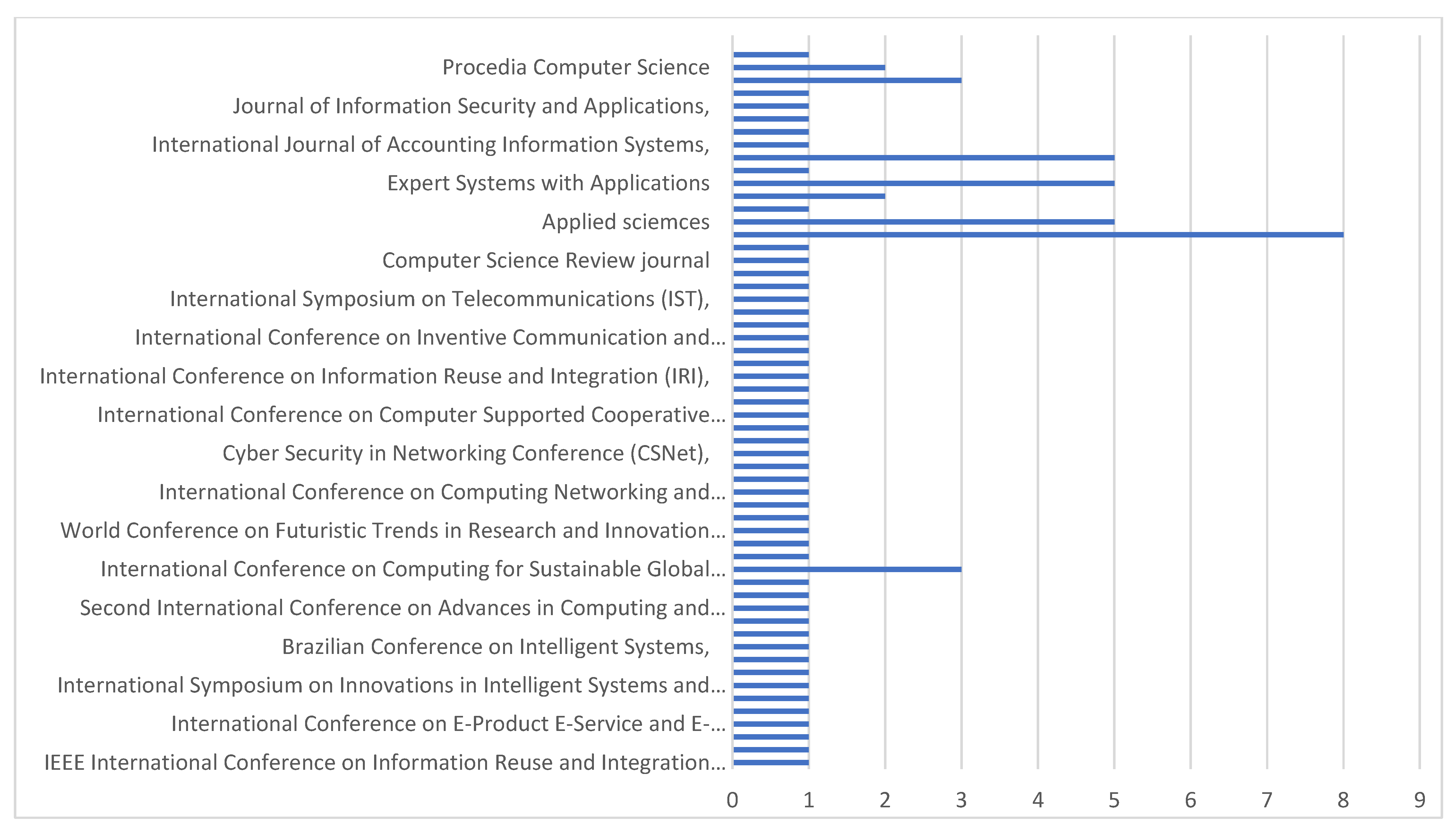
3.1. Description of Studies
3.2. Synthesis Results
3.2.1. RQ1: What Are the Different Categories of Fraudulent Activities That Are Addressed Using ML Techniques
Credit Card Fraud
Financial Statement Fraud
Insurance Fraud
Financial Cyber-Fraud
Other Financial Fraudulent Types
3.2.2. RQ2: What Are the ML-Based Techniques for Financial Fraud Detection Employed in the Literature?
Support Vector Machine (SVM)
Fuzzy-Logic-Based Method
Hidden Markov Model (HMM)
Artificial Neural Network (ANN)
KNN Algorithm
Bayesian Method
Decision Tree
Genetic Algorithm
Ensemble Methods
Clustering Based Methods
Logistic Regression
3.2.3. RQ3: What Are the Performance Evaluation Metrics Used for Financial Fraud Detection Using Machine Learning Methods
3.2.4. RQ4 What Are the Gaps and Future Research Direction in Machine-Learning-Based Fraud Detection
Imbalanced Dataset
Data Size Feature Vectors
Unstructured Data
Machine-Learning-Based Technique
4. Discussion
5. Limitation and Threat to Validity
- This SLR is only limited to conference and journal papers that discuss machine learning (ML) in the context of detecting financial fraud. By using our search approach in the early stages of the review, several non-relevant research papers were identified and excluded from this review. This ensures that the selected research papers satisfied the criteria for the study. However, it is believed that using more sources, such as additional source books, would have further enhanced this review.
- Although major databases were taken into consideration when exploring the research articles, there may be other digital libraries with relevant studies that were overlooked. We compared search terms and keywords to a well-known list of research studies to mitigate this limitation. However, some synonyms may be overlooked when searching for the keywords. The SLR protocol has been revised to address this problem by ensuring no essential terms are left out.
- We restricted our search to only English-language articles. Thus, this results in linguistic bias because some related papers in this field of study may exist in other languages. However, fortunately, all the gathered papers in this study were written in English. As such, we have no language bias.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hilal, W.; Gadsden, S.A.; Yawney, J. Financial Fraud: A Review of Anomaly Detection Techniques and Recent Advances. Expert Syst. Appl. 2021, 193, 116429. [Google Scholar] [CrossRef]
- Ashtiani, M.N.; Raahemi, B. Intelligent Fraud Detection in Financial Statements Using Machine Learning and Data Mining: A Systematic Literature Review. IEEE Access 2021, 10, 72504–72525. [Google Scholar] [CrossRef]
- Albashrawi, M. Detecting Financial Fraud Using Data Mining Techniques: A Decade Review from 2004 to 2015. J. Data Sci. 2016, 14, 553–570. [Google Scholar] [CrossRef]
- Choi, D.; Lee, K. An Artificial Intelligence Approach to Financial Fraud Detection under IoT Environment: A Survey and Implementation. Secur. Commun. Netw. 2018, 2018, 1–15. [Google Scholar] [CrossRef]
- Ngai, E.W.T.; Hu, Y.; Wong, Y.H.; Chen, Y.; Sun, X. The application of data mining techniques in financial fraud detection: A classification framework and an academic review of literature. Decis. Support Syst. 2011, 50, 559–569. [Google Scholar] [CrossRef]
- Ryman-Tubb, N.F.; Krause, P.; Garn, W. How Artificial Intelligence and machine learning research impacts payment card fraud detection: A survey and industry benchmark. Eng. Appl. Artif. Intell. 2018, 76, 130–157. [Google Scholar] [CrossRef]
- Al-Hashedi, K.G.; Magalingam, P. Financial fraud detection applying data mining techniques: A comprehensive review from 2009 to 2019. Comput. Sci. Rev. 2021, 40, 100402. [Google Scholar] [CrossRef]
- Chaquet-ulldemolins, J.; Moral-rubio, S.; Muñoz-romero, S. On the Black-Box Challenge for Fraud Detection Using Machine Learning (II): Nonlinear Analysis through Interpretable Autoencoders. Appl. Sci. 2022, 12, 3856. [Google Scholar] [CrossRef]
- Da’U, A.; Salim, N. Recommendation system based on deep learning methods: A systematic review and new directions. Artif. Intell. Rev. 2019, 53, 2709–2748. [Google Scholar] [CrossRef]
- Zeng, Y.; Tang, J. RLC-GNN: An Improved Deep Architecture for Spatial-Based Graph Neural Network with Application to Fraud Detection. Appl. Sci. 2021, 11, 5656. [Google Scholar] [CrossRef]
- Delamaire, L.; Hussein, A.; John, P. Credit card fraud and detection techniques: A review. Banks Bank Syst. 2009, 4, 57–68. [Google Scholar]
- Zhang, D.; Zhou, L. Discovering Golden Nuggets: Data Mining in Financial Application. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2004, 34, 513–522. [Google Scholar] [CrossRef]
- Raj, S.B.E.; Portia, A.A. Analysis on credit card fraud detection methods. In Proceedings of the 2011 International Conference on Computer, Communication and Electrical Technology (ICCCET), Tirunelveli, India, 18–19 March 2011; pp. 152–156. [Google Scholar] [CrossRef]
- Phua, C.; Lee, V.; Smith, K.; Gayler, R. A Comprehensive Survey of Data Mining-based Fraud Detection Research. arXiv 2010, arXiv:1009.6119. [Google Scholar]
- West, J.; Bhattacharya, M. Intelligent financial fraud detection: A comprehensive review. Comput. Secur. 2016, 57, 47–66. [Google Scholar] [CrossRef]
- Abdallah, A.; Maarof, M.A.; Zainal, A. Fraud detection system: A survey. J. Netw. Comput. Appl. 2016, 68, 90–113. [Google Scholar] [CrossRef]
- Popat, R.R.; Chaudhary, J. A Survey on Credit Card Fraud Detection Using Machine Learning. In Proceedings of the 2018 2nd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 11–12 May 2018; pp. 1120–1125. [Google Scholar]
- Gyamfi, N.K.; Abdulai, J. Bank Fraud Detection Using Support Vector Machine. In Proceedings of the 2018 IEEE 9th Annual Information Technology, Electronics and Mobile Communication Conference (IEMCON), Vancouver, BC, Canada, 1–3 November 2018; pp. 37–41. [Google Scholar]
- Carneiro, E.M.; Dias, L.A.V.; Da Cunha, A.M.; Mialaret, L.F.S. Cluster Analysis and Artificial Neural Networks: A Case Study in Credit Card Fraud Detection. In Proceedings of the 2015 12th International Conference on Information Technology-New Generations, Mumbai, India, 11–14 December 2011; pp. 122–126. [Google Scholar] [CrossRef]
- Iyer, D.; Mohanpurkar, A.; Janardhan, S.; Rathod, D.; Sardeshmukh, A. Credit card fraud detection using Hidden Markov Model. In Proceedings of the 2011 World Congress on Information and Communication Technologies, Mumbai, India, 11–14 December 2011; pp. 1062–1066. [Google Scholar]
- Patil, S.; Nemade, V.; Soni, P. ScienceDirect Predictive Modelling For Credit Card Fraud Detection Using Data Analytics. Procedia Comput. Sci. 2018, 132, 385–395. [Google Scholar] [CrossRef]
- Mohammadian, V.; Navimipour, N.J.; Hosseinzadeh, M.; Darwesh, A. Comprehensive and systematic study on the fault tolerance architectures in cloud computing. J. Circuits Syst. Comput. 2020, 29, 2050240. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Keele University: Keele, UK, 2007; p. 65. [Google Scholar]
- Pourhabibi, T.; Ong, K.-L.; Kam, B.H.; Boo, Y.L. Fraud detection: A systematic literature review of graph-based anomaly detection approaches. Decis. Support Syst. 2020, 133, 113303. [Google Scholar] [CrossRef]
- Marcotte, P.; Petrillo, F. Multiple Fault-tolerance Mechanisms in Cloud Systems: A Systematic Review. In Proceedings of the 2019 IEEE International Symposium on Software Reliability Engineering Workshops (ISSREW), Berlin, Germany, 28–31 October 2019; pp. 414–421. [Google Scholar]
- Isong, B.E.; Bekele, E. A systematic review of fault tolerance in mobile agents. Eng. Appl. 2013, 2, 111–124. [Google Scholar] [CrossRef]
- Nassif, A.B.; Abu Talib, M.; Nasir, Q.; Dakalbab, F.M. Machine Learning for Anomaly Detection: A Systematic Review. IEEE Access 2021, 9, 78658–78700. [Google Scholar] [CrossRef]
- Randhawa, K.; Loo, C.K.; Seera, M.; Lim, C.P.; Nandi, A.K. Credit Card Fraud Detection Using AdaBoost and Majority Voting. IEEE Access 2018, 6, 14277–14284. [Google Scholar] [CrossRef]
- Bhattacharyya, S.; Jha, S.; Tharakunnel, K.; Westland, J.C. Data mining for credit card fraud: A comparative study. Decis. Support Syst. 2011, 50, 602–613. [Google Scholar] [CrossRef]
- Srivastava, A.; Yadav, M.; Basu, S.; Salunkhe, S.; Shabad, M. Credit card fraud detection at merchant side using neural networks. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 667–670. [Google Scholar]
- de Sá, A.G.; Pereira, A.C.; Pappa, G.L. A customized classification algorithm for credit card fraud detection. Eng. Appl. Artif. Intell. 2018, 72, 21–29. [Google Scholar] [CrossRef]
- Robinson, W.N.; Aria, A. Sequential fraud detection for prepaid cards using hidden Markov model divergence. Expert Syst. Appl. 2018, 91, 235–251. [Google Scholar] [CrossRef]
- Hajek, P.; Henriques, R. Mining corporate annual reports for intelligent detection of financial statement fraud—A comparative study of machine learning methods. Knowl.-Based Syst. 2017, 128, 139–152. [Google Scholar] [CrossRef]
- Craja, P.; Kim, A.; Lessmann, S. Deep learning for detecting financial statement fraud. Decis. Support Syst. 2020, 139, 113421. [Google Scholar] [CrossRef]
- Ravisankar, P.; Ravi, V.; Rao, G.R.; Bose, I. Detection of fi nancial statement fraud and feature selection using data mining techniques. Decis. Support Syst. 2011, 50, 491–500. [Google Scholar] [CrossRef]
- Gao, Y.; Sun, C.; Li, R.; Li, Q.; Cui, L.; Gong, B. An Efficient Fraud Identification Method Combining Manifold Learning and Outliers Detection in Mobile Healthcare Services. IEEE Access 2018, 6, 60059–60068. [Google Scholar] [CrossRef]
- Huang, S.-Y.; Tsaih, R.-H.; Yu, F. Topological pattern discovery and feature extraction for fraudulent financial reporting. Expert Syst. Appl. 2014, 41, 4360–4372. [Google Scholar] [CrossRef]
- Peng, J.; Li, Q.; Li, H.; Liu, L.; Yan, Z.; Zhang, S. Fraud Detection of Medical Insurance Employing Outlier Analysis. In Proceedings of the 2018 IEEE 22nd International Conference on Computer Supported Cooperative Work in Design (CSCWD), Nanjing, China, 9–11 May 2018; pp. 341–346. [Google Scholar]
- van Capelleveen, G.; Poel, M.; Mueller, R.M.; Thornton, D.; van Hillegersberg, J. Outlier detection in healthcare fraud: A case study in the Medicaid dental domain. Int. J. Account. Inf. Syst. 2016, 21, 18–31. [Google Scholar] [CrossRef]
- Anbarasi, M.S.; Dhivya, S. Fraud detection using outlier predictor in health insurance data. In Proceedings of the 2017 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, India, 23–24 February 2017; pp. 1–6. [Google Scholar]
- Sundarkumar, G.G.; Ravi, V.; Siddeshwar, V. One-class support vector machine based undersampling: Application to churn prediction and insurance fraud detection. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 10–12 December 2015; pp. 1–7. [Google Scholar] [CrossRef]
- Subudhi, S.; Panigrahi, S. Effect of Class Imbalanceness in Detecting Automobile Insurance Fraud. In Proceedings of the 2018 2nd International Conference on Data Science and Business Analytics (ICDSBA), ChangSha, China, 21–23 September 2018; pp. 528–531. [Google Scholar]
- Fayyomi, M.; Eleyan, D.; Eleyan, A. A Survey Paper On Credit Card Fraud Detection Techniques. Int. J. Adv. Res. Comput. Eng. Technol. 2021, 3, 827–832. [Google Scholar]
- Wang, Y.; Xu, W. Leveraging deep learning with LDA-based text analytics to detect automobile insurance fraud. Decis. Support Syst. 2018, 105, 87–95. [Google Scholar] [CrossRef]
- Gepp, A.; Kumar, K.; Bhattacharya, S. Lifting the numbers game: Identifying key input variables and a best-performing model to detect financial statement fraud. Account. Financ. 2021, 61, 4601–4638. [Google Scholar] [CrossRef]
- Perols, L.; Lougee, B.A. The relation between earnings management and financial statement fraud. Adv. Account. 2011, 27, 39–53. [Google Scholar] [CrossRef]
- Wang, Q.; Xu, W.; Huang, X.; Yang, K. Enhancing intraday stock price manipulation detection by leveraging recurrent neural networks with ensemble learning. Neurocomputing 2019, 347, 46–58. [Google Scholar] [CrossRef]
- Islam, S.R.; Ghafoor, S.K.; Eberle, W. Mining Illegal Insider Trading of Stocks: A Proactive Approach. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 1397–1406. [Google Scholar] [CrossRef]
- Kulkarni, P.M.; Domeniconi, C. Network-based anomaly detection for insider trading. arXiv 2017, arXiv:1702.05809. [Google Scholar]
- Mirtaheri, M.; Abu-El-Haija, S.; Morstatter, F.; Steeg, G.V.; Galstyan, A. Identifying and Analyzing Cryptocurrency Manipulations in Social Media. IEEE Trans. Comput. Soc. Syst. 2021, 8, 607–617. [Google Scholar] [CrossRef]
- Monamo, P.M.; Marivate, V.; Twala, B. A Multifaceted Approach to Bitcoin Fraud Detection: Global and Local Outliers. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 188–194. [Google Scholar] [CrossRef]
- Vasek, M.; Moore, T. There’s No Free Lunch, Even Using Bitcoin: Tracking the Popularity and Profits of Virtual Currency Scams BT–Financial Cryptography and Data Security. In Proceedings of the International Conference on Financial Cryptography and Data Security, Kota Kinabalu, Malaysia, 1–5 March 2015; pp. 44–61. [Google Scholar]
- Monamo, P.; Marivate, V.; Twala, B. Unsupervised learning for robust Bitcoin fraud detection. In Proceedings of the 2016 Information Security for South Africa (ISSA), Johannesburg, South Africa, 17–18 August 2016; pp. 129–134. [Google Scholar] [CrossRef]
- Li, X.; Ying, S. Lib-SVMs Detection Model of Regulating-Profits Financial Statement Fraud Using Data of Chinese Listed Companies. In Proceedings of the 2010 International Conference on E-Product E-Service and E-Entertainment, Henan, China, 7–9 November 2010; pp. 1–4. [Google Scholar] [CrossRef]
- Throckmorton, C.S.; Mayew, W.J.; Venkatachalam, M.; Collins, L.M. Financial fraud detection using vocal, linguistic and fi nancial cues. Decis. Support Syst. 2015, 74, 78–87. [Google Scholar] [CrossRef]
- Glancy, F.H.; Yadav, S.B. A computational model for fi nancial reporting fraud detection. Decis. Support Syst. 2011, 50, 595–601. [Google Scholar] [CrossRef]
- Mareeswari, V.; Gunasekaran, G. Prevention of credit card fraud detection based on HSVM. In Proceedings of the 2016 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, India, 25–26 February 2016; pp. 1–4. [Google Scholar]
- Humpherys, S.L.; Mof, K.C.; Burns, M.B.; Burgoon, J.K.; Felix, W.F. Identi fi cation of fraudulent fi nancial statements using linguistic credibility analysis. Decis. Support Syst. 2011, 50, 585–594. [Google Scholar] [CrossRef]
- Li, X.; Xu, W.; Tian, X. How to protect investors? A GA-based DWD approach for financial statement fraud detection. In Proceedings of the 2014 IEEE International Conference on Systems, Man, and Cybernetics (SMC), San Diego, CA, USA, 5–8 October 2014; pp. 3548–3554. [Google Scholar] [CrossRef]
- Karlos, S.; Fazakis, N.; Kotsiantis, S.; Sgarbas, K. Semi-supervised forecasting of fraudulent financial statements. In Proceedings of the 20th Pan-Hellenic Conference on Informatics, Patras, Greece, 10–12 November 2016. [Google Scholar] [CrossRef]
- Özçelik, M.H.; Duman, E.; Işik, M.; Çevik, T. Improving a credit card fraud detection system using genetic algorithm. In Proceedings of the 2010 International Conference on Networking and Information Technology, Manila, Philippines, 11–12 June 2010; pp. 436–440. [Google Scholar]
- Rizki, A.; Surjandari, I.; Wayasti, R.A. Data mining application to detect financial fraud in Indonesia’s public companies. In Proceedings of the 2017 3rd International Conference on Science in Information Technology (ICSITech), Bandung, Indonesia, 25–26 October 2017; pp. 206–211. [Google Scholar]
- Chen, S. Detection of fraudulent financial statements using the hybrid data mining approach. SpringerPlus 2016, 5, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Yao, J.; Zhang, J.; Wang, L. A financial statement fraud detection model based on hybrid data mining methods. In Proceedings of the 2018 international conference on artificial intelligence and big data (ICAIBD), Chengdu, China, 26–28 May 2018; pp. 57–61. [Google Scholar] [CrossRef]
- Rajak, I.; Mathai, K.J. Intelligent fraudulent detection system based SVM and optimized by danger theory. In Proceedings of the 2015 International Conference on Computer, Communication and Control (IC4), Indore, India, 10–12 September 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Jeragh, M.; Alsulaimi, M. Combining Auto Encoders and One Class Support Vectors Machine for Fraudulant Credit Card Transactions Detection. In Proceedings of the 2018 Second World Conference on Smart Trends in Systems, Security and Sustainability (WorldS4), London, UK, 30–31 October 2018; pp. 178–184. [Google Scholar] [CrossRef]
- Kho, J.R.D.; Vea, L.A. Credit card fraud detection based on transaction behavior. In Proceedings of the TENCON 2017-2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 1880–1884. [Google Scholar] [CrossRef]
- Behera, T.K.; Panigrahi, S. Credit Card Fraud Detection: A Hybrid Approach Using Fuzzy Clustering & Neural Network. In Proceedings of the 2015 Second International Conference on Advances in Computing and Communication Engineering, Dehradun, India, 1–2 May 2015; pp. 494–499. [Google Scholar]
- HaratiNik, M.R.; Akrami, M.; Khadivi, S.; Shajari, M. FUZZGY: A hybrid model for credit card fraud detection. In Proceedings of the 6th International Symposium on Telecommunications (IST), Tehran, Iran, 6–8 November 2012; pp. 1088–1093. [Google Scholar]
- Malini, N.; Pushpa, M. Analysis on credit card fraud identification techniques based on KNN and outlier detection. In Proceedings of the 2017 third international conference on advances in electrical, electronics, information, communication and bio-informatics (AEEICB), Chennai, India, 27–28 February 2017; pp. 255–258. [Google Scholar] [CrossRef]
- Benchaji, I.; Douzi, S.; ElOuahidi, B. Using Genetic Algorithm to Improve Classification of Imbalanced Datasets for Credit Card Fraud Detection. In Proceedings of the International Conference on Advanced Information Technology, Services and Systems, Mohammedia, Morocco, 17–18 October 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Case, B. Recognizing Debit Card Fraud Transaction Using CHAID and K-Nearest Neighbor: Indonesian Bank case. In Proceedings of the 2016 11th International Conference on Knowledge, Information and Creativity Support Systems (KICSS), Yogyakarta, Indonesia, 10–12 November 2016. [Google Scholar]
- Bhusari, V.; Patil, S. Study of Hidden Markov Model in credit card fraudulent detection. In Proceedings of the 2016 World Conference on Futuristic Trends in Research and Innovation for Social Welfare (Startup Conclave), Coimbatore, India, 29 February–1 March 2016; pp. 1–4. [Google Scholar]
- Sahin, Y.; Bulkan, S.; Duman, E. A cost-sensitive decision tree approach for fraud detection. Expert Syst. Appl. 2013, 40, 5916–5923. [Google Scholar] [CrossRef]
- Duman, E.; Ozcelik, M.H. Detecting credit card fraud by genetic algorithm and scatter search. Expert Syst. Appl. 2011, 38, 13057–13063. [Google Scholar] [CrossRef]
- Sahin, Y.; Duman, E. Detecting credit card fraud by ANN and logistic regression. In Proceedings of the 2011 International Symposium on Innovations in Intelligent Systems and Applications, Istanbul, Turkey, 15–18 June 2011; pp. 315–319. [Google Scholar]
- Ghobadi, F.; Rohani, M. Cost sensitive modeling of credit card fraud using neural network strategy. In Proceedings of the 2016 2nd International Conference of Signal Processing and Intelligent Systems (ICSPIS), Tehran, Iran, 14–15 December 2016; pp. 1–5. [Google Scholar]
- Awoyemi, J.O.; Adetunmbi, A.O.; Oluwadare, S.A. Credit card fraud detection using machine learning techniques: A comparative analysis. In Proceedings of the 2017 international conference on computing networking and informatics (ICCNI), Ota, Nigeria, 29–31 October 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Mishra, A.; Ghorpade, C. Credit Card Fraud Detection on the Skewed Data Using Various Classification and Ensemble Techniques. In Proceedings of the 2018 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 24–25 February 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Kirlidog, M.; Asuk, C. A Fraud Detection Approach with Data Mining in Health Insurance. Procedia-Soc. Behav. Sci. 2012, 62, 989–994. [Google Scholar] [CrossRef]
- Peng, H.; You, M. The Health Care Fraud Detection Using the Pharmacopoeia Spectrum Tree and Neural Network Analytic Contribution Hierarchy Process. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 2006–2011. [Google Scholar] [CrossRef]
- Bauder, R.; da Rosa, R.; Khoshgoftaar, T. Identifying Medicare Provider Fraud with Unsupervised Machine Learning. In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration (IRI), Salt Lake City, UT, USA, 7–9 July 2018; pp. 285–292. [Google Scholar]
- Bauder, R.A.; Khoshgoftaar, T.M.; Richter, A.; Herland, M. Predicting Medical Provider Specialties to Detect Anomalous Insurance Claims. In Proceedings of the 2016 IEEE 28th International Conference on Tools with Artificial Intelligence (ICTAI), San Jose, CA, USA, 6–8 November 2016; pp. 784–790. [Google Scholar]
- Badriyah, T.; Rahmaniah, L.; Syarif, I. Nearest Neighbour and Statistics Method based for Detecting Fraud in Auto Insurance. In Proceedings of the 2018 International Conference on Applied Engineering (ICAE), Batam, Indonesia, 3–4 October 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, X.; Zhang, J.; Zhang, P.; Liu, L.; Jin, H.; Jin, H. Analyzing and Detecting Money-Laundering Accounts in Online Social Networks. IEEE Netw. 2017, 32, 115–121. [Google Scholar] [CrossRef]
- Mhamane, S.S.; Lobo, L.M.R.J. Internet banking fraud detection using HMM. In Proceedings of the 2012 Third International Conference on Computing, Communication and Networking Technologies (ICCCNT’12), Karur, India, 26–28 July 2012; pp. 1–4. [Google Scholar]
- Faraji, Z.; States, U. A Review of Machine Learning Applications for Credit Card Fraud Detection with A Case study. J. Manag. 2022, 5, 49–59. [Google Scholar] [CrossRef]
- Bhavitha, B.K.; Rodrigues, A.P.; Chiplunkar, N.N. Comparative study of machine learning techniques in sentimental analysis. In Proceedings of the 2017 International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 10–11 March 2017; pp. 216–221. [Google Scholar] [CrossRef]
- Carta, S.; Fenu, G.; Recupero, D.R.; Saia, R. Fraud detection for E-commerce transactions by employing a prudential Multiple Consensus model. J. Inf. Secur. Appl. 2019, 46, 13–22. [Google Scholar] [CrossRef]
- Rb, A.; Kr, S.K. Credit card fraud detection using artificial neural network. Glob. Transit. Proc. 2021, 2, 35–41. [Google Scholar] [CrossRef]
- Pradeep, G.; Ravi, V.; Nandan, K.; Deekshatulu, B.L.; Bose, I.; Aditya, A. Fraud Detection in Financial Statements Using Evolutionary Computation Based Rule Miners. In Proceedings of the International Conference on Swarm, Evolutionary, and Memetic Computing, Hyderabad, India, 18–19 December 2015; pp. 239–250. [Google Scholar] [CrossRef]
- Hajek, P. Interpretable Fuzzy Rule-Based Systems for Detecting Financial Statement Fraud. In Proceedings of the IFIP International Conference on Artificial Intelligence Applications and Innovations, Crete, Greece, 25–27 June 2019; pp. 1–12. [Google Scholar]
- Khan, A.; Singh, T.; Sinhal, A.; Khan, A.; Singh, T. Implement credit card fraudulent detection system using observation probabilistic in hidden Markov model. In Proceedings of the 2012 Nirma University International Conference on Engineering (NUiCONE), Ahmedabad, India, 6–8 December 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, X.; Wu, H.; Yi, Z. Research on Bank Anti-Fraud Model Based on K-Means and Hidden Markov Model. In Proceedings of the 2018 IEEE 3rd International Conference on Image, Vision and Computing (ICIVC), Chongqing, China, 27–29 June 2018; pp. 780–784. [Google Scholar] [CrossRef]
- Song, R.; Huang, L.; Cui, W.; Vanthienen, J. Fraud Detection of Bulk Cargo Theft in Port Using Bayesian Network Models. Appl. Sci. 2020, 10, 1056. [Google Scholar] [CrossRef]
- Dang, T.K.; Tran, T.C.; Tuan, L.M. Machine Learning Based on Resampling Approaches and Deep Reinforcement Learning for Credit Card Fraud Detection Systems. Appl. Sci. 2021, 11, 10004. [Google Scholar] [CrossRef]
- Bouchti, E.; Chakroun, A.; Abbar, H.; Okar, C. Fraud detection in banking using deep reinforcement learning. In Proceedings of the 2017 Seventh International Conference on Innovative Computing Technology (INTECH), Luton, UK, 16–18 August 2017; pp. 58–63. [Google Scholar]
- Zouboulidis, E.; Kotsiantis, S. Forecasting fraudulent financial statements with committee of cost-sensitive decision tree classifiers. In Hellenic Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2012; pp. 57–64. [Google Scholar]
- Hassanzadeh, R. A Nomaly Detection in Online Social Networks: Using Data-Mining Techniques and Fuzzy. Ph.D. Thesis, Queensland University of Technology, Brisbane City, QLD, Australia, 2014. [Google Scholar]
- Shah, V.; Shah, P.; Shetty, H.; Mistry, K. Review of Credit Card Fraud Detection Techniques. In Proceedings of the 2019 IEEE International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 29–30 March 2019; pp. 1–7. [Google Scholar] [CrossRef]
- Deng, Q. Detection of fraudulent financial statements based on Naïve Bayes classifier. In Proceedings of the 2010 5th International Conference on Computer Science & Education, Hefei, China, 24–27 August 2010; pp. 1032–1035. [Google Scholar] [CrossRef]
- Ahmed, M.; Mahmood, A.N.; Islam, R. A survey of anomaly detection techniques in financial domain. Futur. Gener. Comput. Syst. 2016, 55, 278–288. [Google Scholar] [CrossRef]
- Uchhana, N.; Ranjan, R.; Sharma, S.; Agrawal, D.; Punde, A. Literature Review of Different Machine Learning Algorithms for Credit Card Fraud Detection. Int. J. Innov. Technol. Explor. Eng. 2021, 10, 101–108. [Google Scholar] [CrossRef]
- Abbasi, A.; Albrecht, C.; Vance, A.; Hansen, J. Metafraud: A meta-learning framework for detecting financial fraud. Mis Q. 2012, 36, 1293–1327. [Google Scholar] [CrossRef]
- Moepya, S.O.; Nelwamondo, F.V.; Twala, B. Increasing the detection of minority class instances in financial statement fraud. In Proceedings of the Asian Conference on Intelligent Information and Database Systems, Kanazawa, Japan, 3–5 April 2017; Volume 2, p. 2017. [Google Scholar]
- Chen, S.; Goo, Y.-J.J.; Shen, Z.-D. A Hybrid Approach of Stepwise Regression, Logistic Regression, Support Vector Machine, and Decision Tree for Forecasting Fraudulent Financial Statements. Sci. World J. 2014, 2014, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Patel, H.; Parikh, S.; Patel, A.; Parikh, A. An Application of Ensemble Random Forest Classifier for Detecting Financial Statement Manipulation of Indian Listed Companies. In Recent Developments in Machine Learning and Data Analytics; Springer: Singapore, 2019. [Google Scholar]
- Hobson, L.; Mayew, W.J. Analyzing Speech to Detect Financial Misreporting Analyzing Speech to Detect Financial Misreporting. J. Account. Res. 2010, 2, 349–392. [Google Scholar]
- Li, Y.; Yan, C.; Liu, W.; Li, M. Research and application of random forest model in mining automobile insurance fraud. In Proceedings of the 2016 12th International Conference on Natural Computation, Fuzzy Systems and Knowledge Discovery (ICNC-FSKD), Changsha, China, 13–15 August 2016; pp. 1756–1761. [Google Scholar] [CrossRef]
- Kowshalya, G.; Nandhini, M. Predicting Fraudulent Claims in Automobile Insurance. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 1338–1343. [Google Scholar]
- Bauder, R.; Khoshgoftaar, T. Medicare Fraud Detection Using Random Forest with Class Imbalanced Big Data. In Proceedings of the 2018 IEEE International Conference on Information Reuse and Integration (IRI), Salt Lake City, UT, USA, 7–9 July 2018; pp. 80–87. [Google Scholar]
- Li, S.-H.; Yen, D.C.; Lu, W.-H.; Wang, C. Identifying the signs of fraudulent accounts using data mining techniques. Comput. Hum. Behav. 2012, 28, 1002–1013. [Google Scholar] [CrossRef]
- Bartoletti, M.; Pes, B.; Serusi, S. Data Mining for Detecting Bitcoin Ponzi Schemes. In Proceedings of the 2018 Crypto Valley Conference on Blockchain Technology (CVCBT), Zug, Switzerland, 20–22 June 2018; pp. 75–84. [Google Scholar] [CrossRef]
- Zhang, W.; He, X. An Anomaly Detection Method for Medicare Fraud Detection. In Proceedings of the 2017 IEEE International Conference on Big Knowledge (ICBK), Hefei, China, 9–10 August 2017; pp. 309–314. [Google Scholar]
- Deng, Q.; Mei, G. Combining self-organizing map and K-means clustering for detecting fraudulent financial statements. In Proceedings of the 2009 IEEE International Conference on Granular Computing, Nanchang, China, 17–19 August 2009; pp. 126–131. [Google Scholar] [CrossRef]
- Sael, N.; Benabbou, F. ScienceDirect ScienceDirect Performance of machine learning techniques in the detection of Performance of machine learning techniques in the detection of financial frauds financial frauds. Procedia Comput. Sci. 2018, 148, 45–54. [Google Scholar]
- Liang, J.; Lv, W. Research on detecting technique of financial statement fraud based on Fuzzy Genetic Algorithms BPN. In Proceedings of the 2009 International Conference on Management Science and Engineering, Nanchang, China, 17–19 August 2009; pp. 1462–1468. [Google Scholar] [CrossRef]
- Xiaoyun, W.; Danyue, L. Hybrid outlier mining algorithm based evaluation of client moral risk in insurance company. In Proceedings of the 2010 2nd IEEE International Conference on Information Management and Engineering, Chongqing, China, 17–19 September 2010; pp. 585–589. [Google Scholar] [CrossRef]
- Bauder, R.A.; Khoshgoftaar, T.M. Medicare Fraud Detection Using Machine Learning Methods. In Proceedings of the 2017 16th IEEE International Conference on Machine Learning and Applications (ICMLA), Cancun, Mexico, 18–21 December 2017; pp. 858–865. [Google Scholar]
- Pejic-bach, M. Invited Paper: Profiling Intelligent Systems Applications in Fraud Detection and Prevention: Survey of Research Articles Profiling intelligent systems applications in fraud detection and prevention: Survey of research articles. In Proceedings of the 2010 International Conference on Intelligent Systems, Modelling and Simulation, Liverpool, UK, 27–29 January 2010. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- D’Addio, R.M.; Manzato, M.G. A Collaborative Filtering Approach Based on User’s Reviews. In Proceedings of the 2014 Brazilian Conference on Intelligent Systems, Washington, DC, USA, 18–22 October 2014; pp. 204–209. [Google Scholar] [CrossRef]
- Paruchuri, H. Credit Card Fraud Detection using Machine Learning: A Systematic Literature Review. ABC J. Adv. Res. 2017, 6, 113–120. [Google Scholar] [CrossRef]
- Silva, B.; Marques, N.; Panosso, G. Applying neural networks for concept drift detection in financial markets. CEUR Workshop Proc. 2012, 960, 43–47. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S/N | RQ | Motivation |
|---|---|---|
| 1 | What popular financial frauds that are addressed based on the ML approaches? | Identify the popular types of financial frauds that are detected based on the ML methods. |
| 2 | What popular ML-based approaches employed for financial fraud detection? | Identify the popular categories of the ML methods used for financial fraud detection. |
| 3 | What are the evaluation metrics employed to detect financial frauds? | Identify the evaluation metrics used for financial fraud detection. |
| 4 | What are the research gaps, trends, and future directions of the research area? | Identify the research gaps, the trends, and future directions in fraud detection research in online transactions. |
| S/N | Exclusion | Inclusion |
|---|---|---|
| 1 | Articles that do not focus on financial fraudulent transactions. | |
| 2 | Articles that are in the form of abstracts, short papers, posters, and book chapters. | The articles that are conducted from 2010 to 2021. |
| 3 | Articles that do not pertain to the use of ML/data mining methods. | Articles that focus on financial fraud detection and applied ML methods |
| 4 | Studies that do not mention their performance evaluation metrics | A peer-reviewed research article. |
| 5 | Studies that were not published in the English language. | Studies were conducted in English only. |
| ID | Quality Assessment |
|---|---|
| 1 | Is the purpose of the study clear? |
| 2 | Are the techniques clearly stated and explained? |
| 3 | Are the proposed techniques clearly presented and implemented? |
| 4 | Is the experimental procedure clearly described? |
| 5 | Does the study make contributions to the SLR? |
| 6 | Are empirical experiments clearly stated? |
| 7 | Are the performance measures clearly stated? |
| 8 | Are the conclusion and future direction clearly stated? |
| Search Method | Information Extracted | Purpose of the Extraction |
|---|---|---|
| Manual Search | The category of financial fraud addressed in the study | RQ1 |
| The technique used for the fraud detection | RQ2 | |
| The objective of the study | RQ1, RQ2 | |
| The evaluation metrics used to address which technique | RQ3 | |
| Future direction, trends, and gaps in the study | RQ4 | |
| Conclusion of the study | RQ1, RQ2, and RQ4 | |
| Automatic Search | Title of the study | Study Description and Meta-Analysis |
| Publication year | ||
| Names of the author | ||
| Publication type (conference proceeding or journal article) | ||
| The conference or journal names |
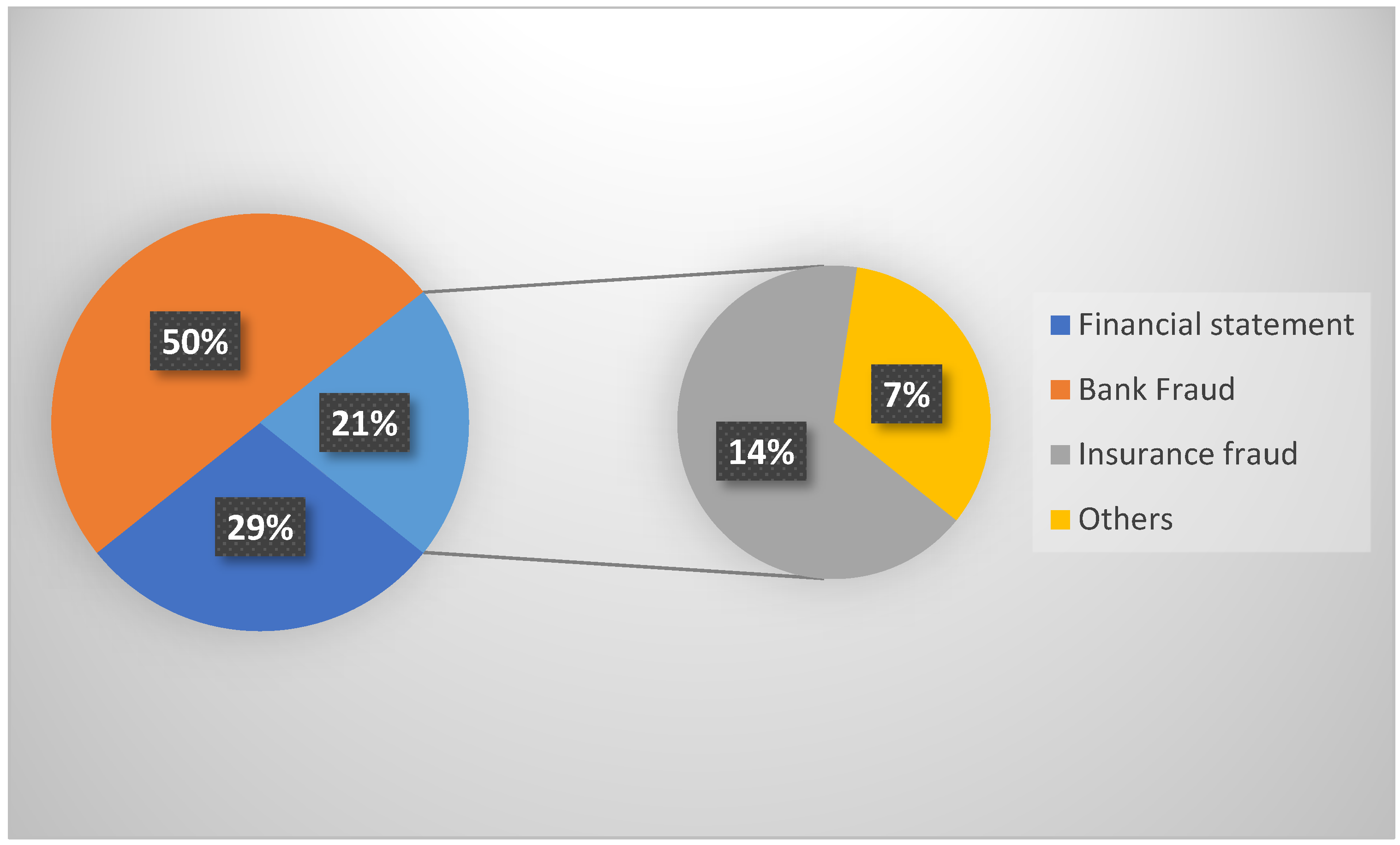
| Fraud Type | Description | Technique Used | References | No. of Reference |
|---|---|---|---|---|
| Financial Statement Fraud | This is a corporate fraud such that the financial statements are illegitimately modified to allow the organizations to look more beneficial. | Support Vector Machine | [33,54,55,56] | 20 |
| Clustering based method | [37,56] | |||
| Decision Tree | [33,57,58,59,60] | |||
| Logistic Regression | [35] | |||
| Naïve Bayes | [33,61] | |||
| Artificial Neural Network | [33,40,62,62,63,64] | |||
| Credit Card Fraud | Illegitimate use of the card without proper owners’ authorization | Support Vector Machine | [18,57,65,66,67] | 32 |
| Fuzzy logic | [68,69] | |||
| Clustering based method, | [70,71] | |||
| Artificial Neural Network | [70,72] | |||
| Hidden Markov model | [20,32,73] | |||
| Decision Tree | [16,21,74] | |||
| Genetic Algorithm | [75,19] | |||
| Artificial Neural Network | [30,61,76,77] | |||
| Naïve Bayes | [5,28,69,78] | |||
| Logistic Regression | [78] | |||
| Random Forest | [29,69,79], | |||
| Health Insurance Fraud | Fraudulent claims by individuals or organizations to support the relevant expenses of theft or accidental damages. | Support Vector Machine | [80] | 5 |
| Artificial Neural Network | [81] | |||
| K Nearest Neighbors | [82] | |||
| Naïve Bayes | [83], | |||
| Clustering-based method, | [40] | |||
| Auto Insurance Fraud | Fraudulent claims by an individual to get health insurance profits. | Support Vector Machine | [41,42], | 3 |
| K Nearest Neighbors | [84] | |||
| Cyber Financial fraud | Financial fraudulent activities through cyber space | Artificial Neural Network | [47,48,49,50] | 3 |
| SVM | [50,85] | 2 | ||
| Others | Other frauds that are faced in the financial domains include commodities and securities fraud [32], mortgage fraud, corporate fraud, and money laundering. | Support Vector Machine | [42] | 5 |
| Decision Tree | [42] | |||
| Fuzzy logic | [69] | |||
| Clustering-based method, | [51] | |||
| Hidden Markov model | [86] |
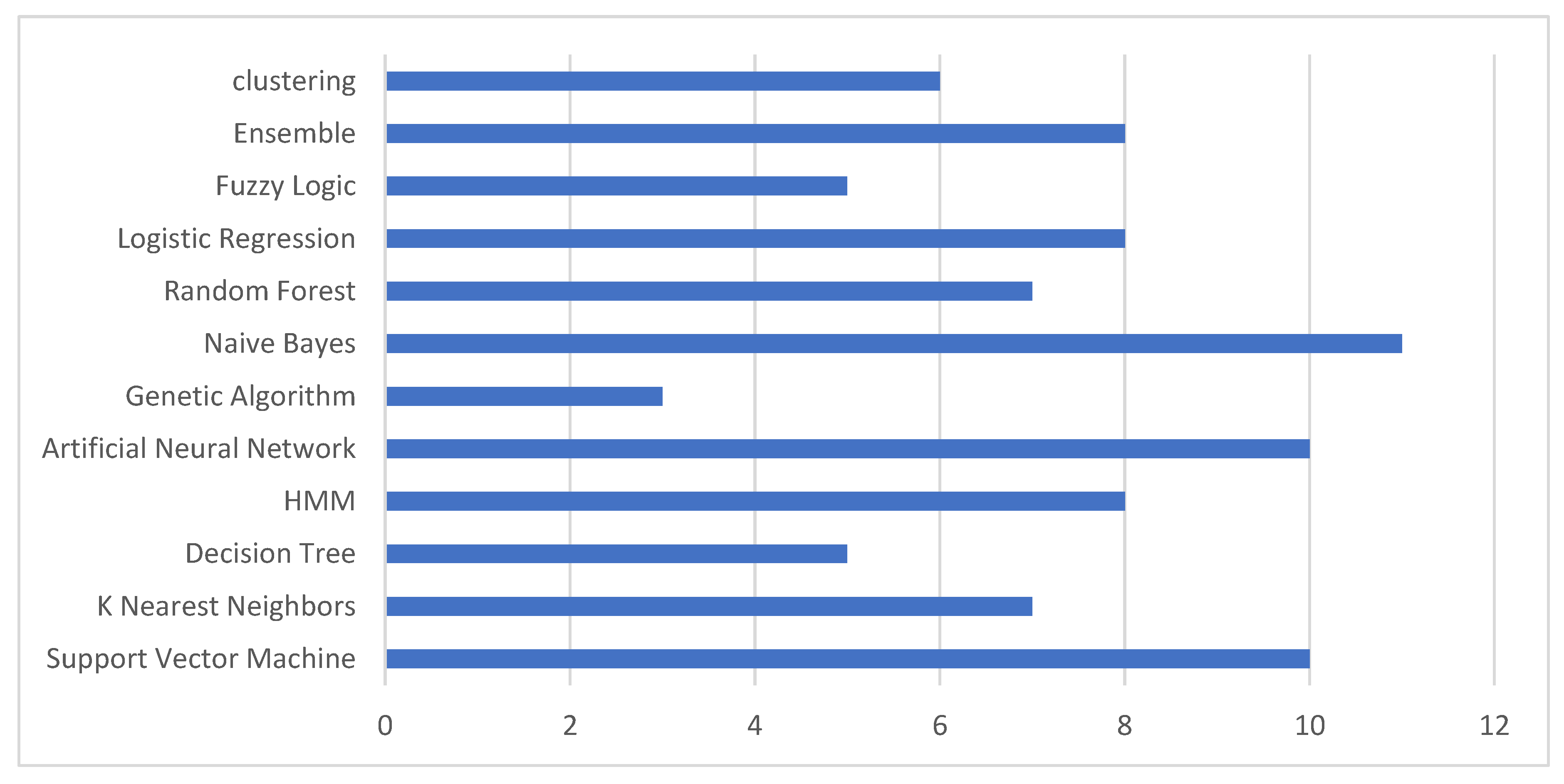
| Techniques | Short Description | No. of Articles | References |
|---|---|---|---|
| SVM | A classification method used in linear classification | 10 | [18,41,42,54,57,65,66,66,80,80] |
| HMM | A dual embedded random process used to provide more complex random processes | 8 | [19,20,73,74,86,89,94,103] |
| ANN | Amulti-layer network that works similar to human thought | 10 | [28,30,33,61,62,75,76,77,81,97] |
| Fuzzy Logic | A logic that indicates that methods of thinking are estimated and not accurate. | 5 | [68,69,91,92] |
| KNN | It classifies data according to their similar and closest classes. | 7 | [60,70,72,78,84,98,99] |
| Decision Tree | A regression tree and classification method that is used for decision support | 5 | [29,44,54,57,67] |
| Genetic Algorithm | It searches for the best way to solve problems concerning the suggested solutions | 3 | [35,61,71] |
| Ensemble | Meta algorithms that combined manifold intelligent technique into one predictive technique | 8 | [2,29,33,64,69,79,98,105], |
| Logistic Regression | They are mainly applied in binary and multi-class classification problems. | 8 | [35,78,81,104,106,107,108] |
| Clustering | Unsupervised learning method which involve grouping identical instances into the same sets | 6 | [5,18,56,102,103] |
| Random Forest | Classification methods that operate by combining a multitude of decision trees | 7 | [21,29,67,79,109,110,111] |
| Naïve Bayes | A classification algorithm that can predict group membership | 11 | [5,28,31,33,61,67,78,83,101,101,112] |
| Metrics | Formula | References |
|---|---|---|
| Accuracy | [18,21,29,33,38,40,41,42,62,66,69,72,78,82,83,84,110,113,114,115,116,117] | |
| Precision | [21,39,40,67,69,77,78,94,113,118] | |
| Recall/Sensibility/TPR) | [21,39,40,67,69,77,94,113,118] | |
| F-measure(F1) | [21,31,33,65,84,113] | |
| Specificity (TNR) | [42,70,77,78,82,94,113] | |
| AUC | AUC = the area under ROC curve | [35,113] |
| Others | [65,66,67,74,119] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, A.; Abd Razak, S.; Othman, S.H.; Eisa, T.A.E.; Al-Dhaqm, A.; Nasser, M.; Elhassan, T.; Elshafie, H.; Saif, A. Financial Fraud Detection Based on Machine Learning: A Systematic Literature Review. Appl. Sci. 2022, 12, 9637. https://doi.org/10.3390/app12199637
Ali A, Abd Razak S, Othman SH, Eisa TAE, Al-Dhaqm A, Nasser M, Elhassan T, Elshafie H, Saif A. Financial Fraud Detection Based on Machine Learning: A Systematic Literature Review. Applied Sciences. 2022; 12(19):9637. https://doi.org/10.3390/app12199637
Chicago/Turabian StyleAli, Abdulalem, Shukor Abd Razak, Siti Hajar Othman, Taiseer Abdalla Elfadil Eisa, Arafat Al-Dhaqm, Maged Nasser, Tusneem Elhassan, Hashim Elshafie, and Abdu Saif. 2022. "Financial Fraud Detection Based on Machine Learning: A Systematic Literature Review" Applied Sciences 12, no. 19: 9637. https://doi.org/10.3390/app12199637