3.2. Experiment Result
This paper first conducts a single-source domain adaptation experiment to verify the effectiveness of the composite model. This paper takes the working conditions (bearing loads) as the domains, trains on 10 kinds of fault modes data under each load condition, and then tests the trained model under another load condition.
The data from each domain is divided into a training set and a test set at a ratio of 8:2. For each iteration during training, the model is first trained with the training sets from the source and target domains, and then the test set from the source and target domains are used to test the performance of the model and observe the classification accuracy of the model on the source and target domains. The number of training iterations is 100 and repeated 10 times. The classification result is the average of the optimal classification accuracy on the target domain.
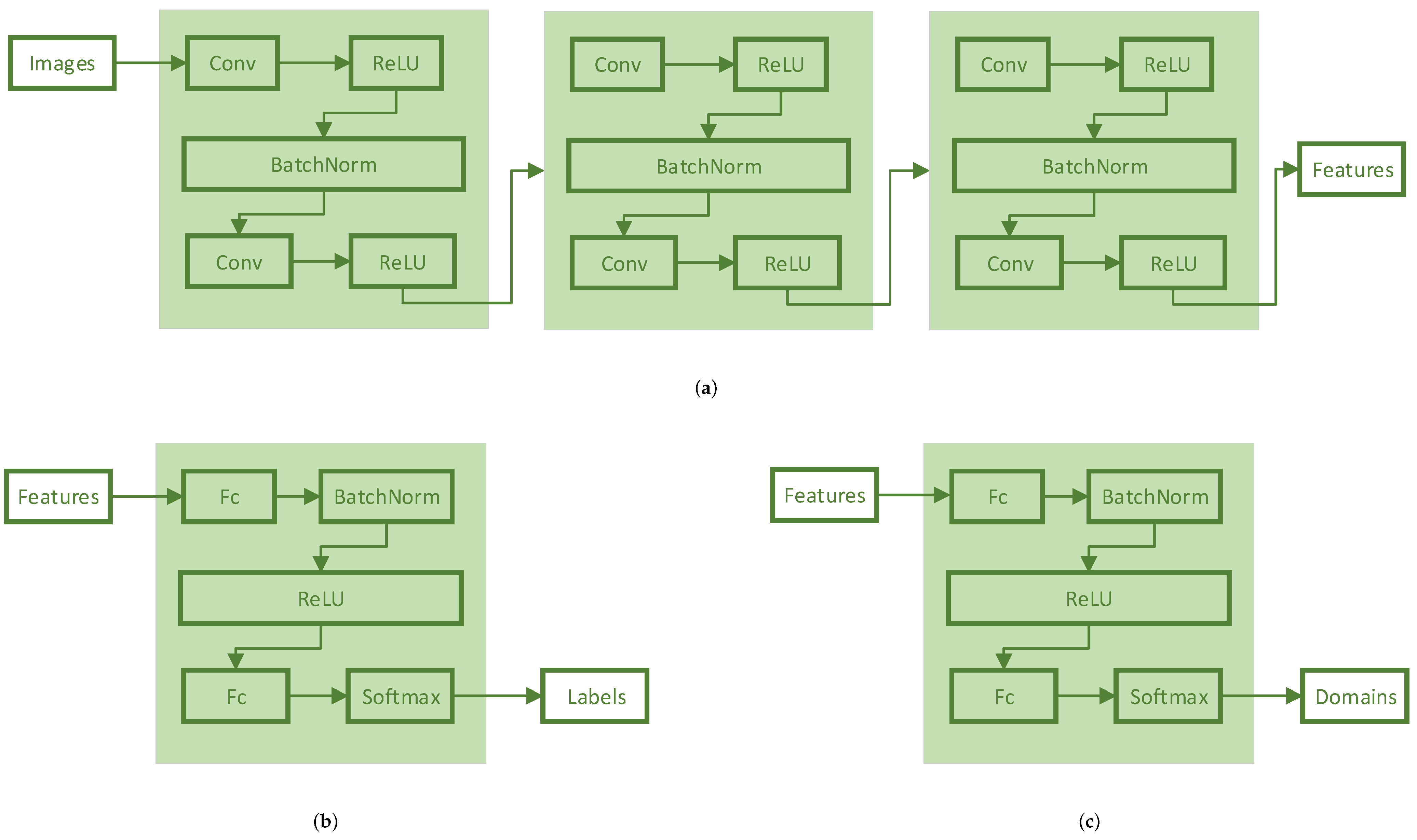
Considering the noise-resistant requirement of the model, the dataset selects the signal containing noise for experiments. The 2DCNN network as the benchmark model still has a classification accuracy of more than 99% on the noisy signal with SNR = −4, and the accuracy will decrease on the noisy signal with a lower signal-to-noise ratio. In order to ensure that the models participating in the experiment have a relatively high accuracy in the source domain so as to compare their domain adaptation capabilities, a noisy signal with SNR = −4 is selected for cross-domain experiments.
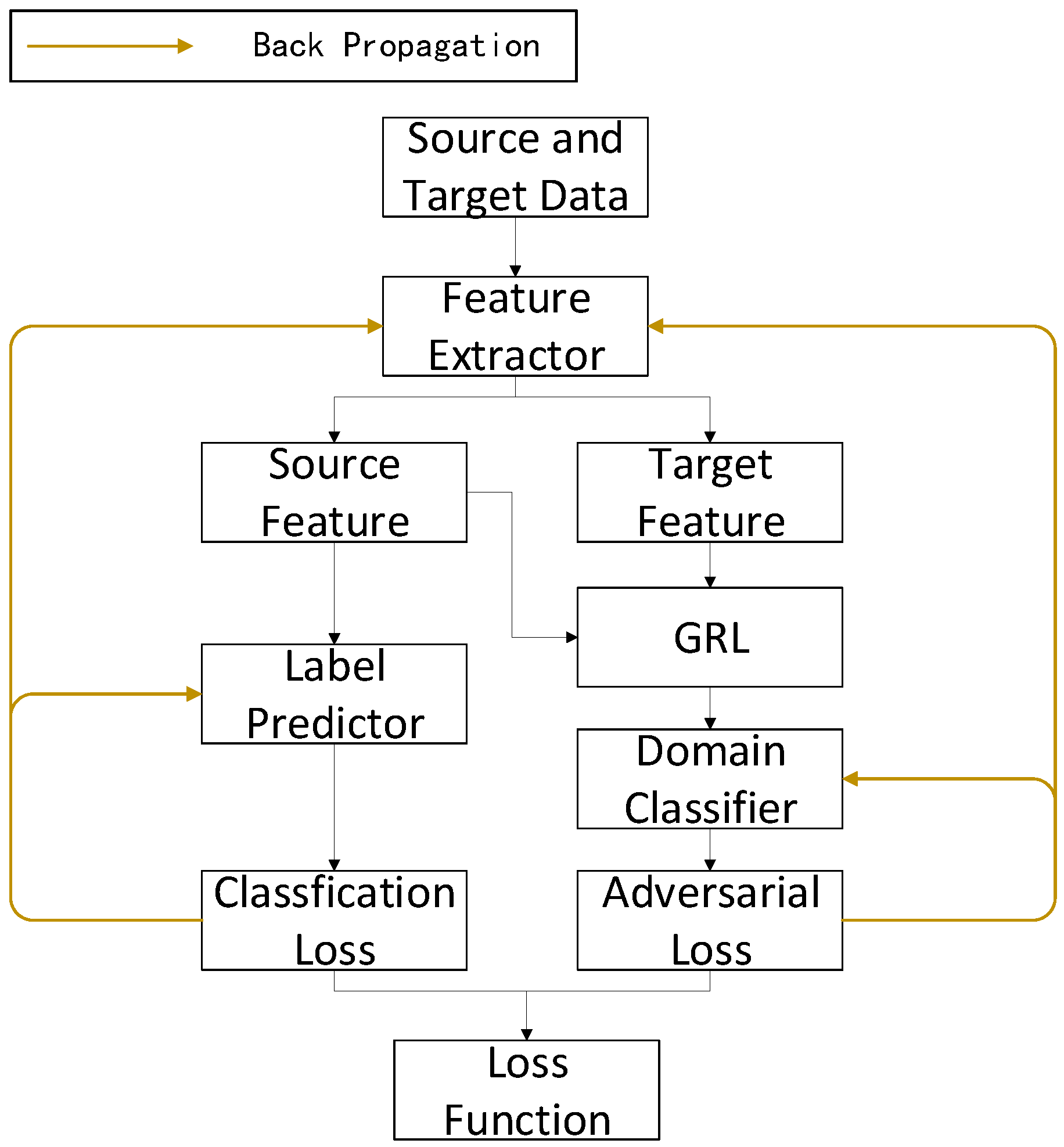
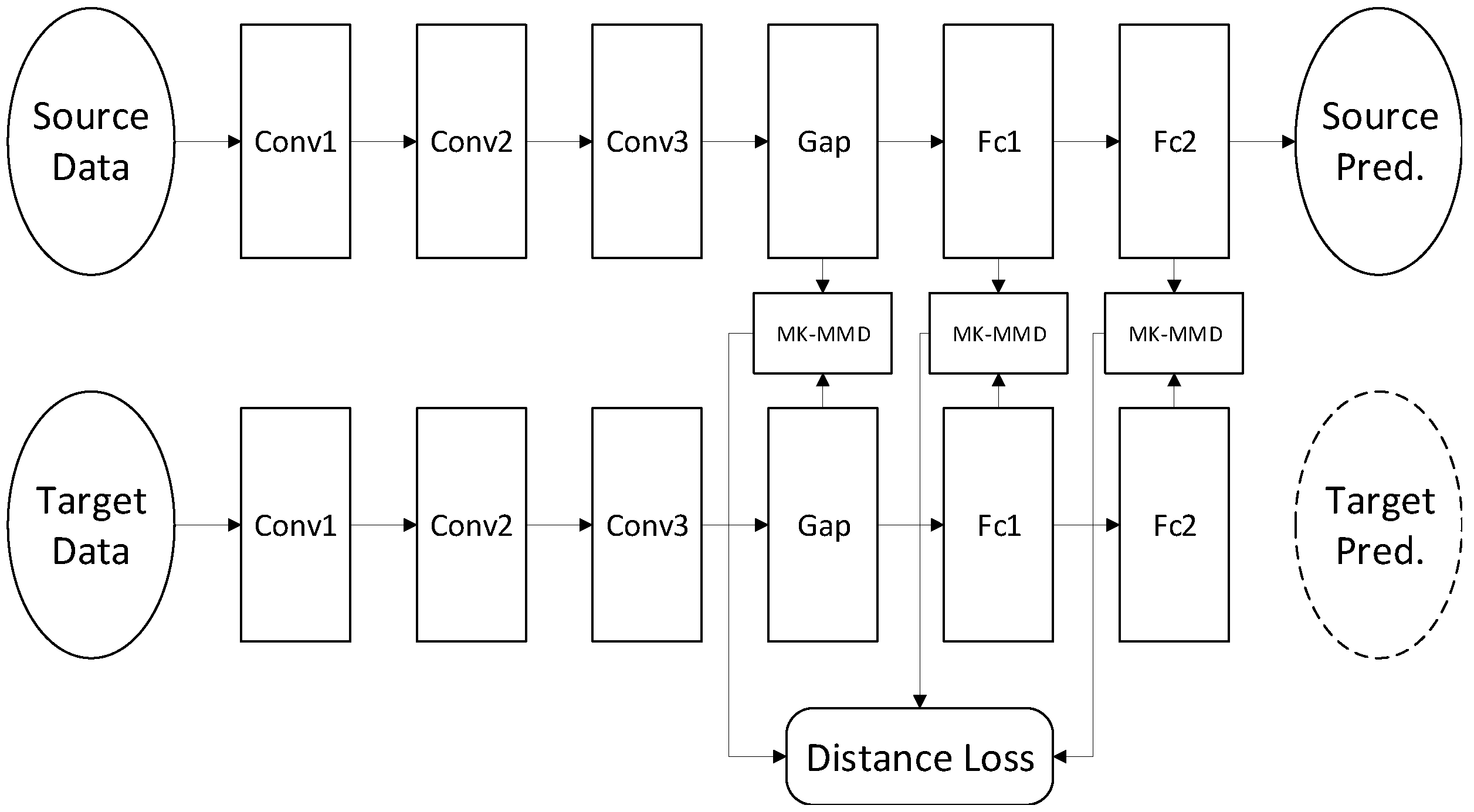
Among the methods for comparison, the classical CNN is first selected as the benchmark model to show the transfer performance of the model without any transfer method. Feature-based domain adaptation methods are then selected for comparison, represented by DAN using the MK-MMD distance and DSAN using the LMMD distance. In addition, adversarial-based domain adaptation methods are also selected for comparison, represented by DANN networks. The last is a composite model that combines the DANN and MK-MMD distance.
The classification accuracy of each method under cross-working conditions is shown in
Table 2. The left side of the arrow represents the source domain, and the right side represents the target domain. The accuracy shown in the table is the classification accuracy of the model on the target domain. The accuracy on the source domain is close to 100%, so it is not shown in this table.
The results in
Table 2 show that considering the CNN without any optimization and domain adaptation methods as the benchmark, the average accuracy of the CNN model on the unlabeled target domain is 87.08%.
However, DAN and DSAN, which use the distance method for domain adaptation, both perform mediocrely. DAN only outperforms the CNN model on a few cross-domain tasks, with no advantage in average accuracy. The DSAN method is even negative optimization, which is due to the fact that the image is filled with yellow areas representing noise signals, blurring the distribution between subfields and aligning non-identical sub-fields, resulting in negative optimization, while the use of the DANN network can improve the cross-domain accuracy to a certain extent. With an improvement of 3% to 4% in various cross-domain tasks, the average accuracy rate is increased to 91.57%. This result indicates that domain-invariant features can be found through adversarial training. On the basis of conversary, the composite model combined with the MK-MMD distance can further improve the cross-domain accuracy by 1% to 5%, indicating that the composite model combining these two methods can achieve a good classification result.
Figure 8 shows the accuracy result of the baseline CNN model, the feature-based DAN model, the adversarial-based DANN model, and the composite model.
It can be seen from
Figure 8 that the composite model has high diagnosis accuracy on three cross-domain tasks of 0→1, 0→3, 2→3, all above 95%. On the cross-domain tasks of 0→2, 1→2, 1→3, The diagnosis accuracy is slightly lower, all around 90%. Compared with other methods, the composite model has the greatest improvement on the 0→3 cross-domain task, while the improvement in other cross-domain tasks is a bit smaller.
Although the composite model can improve the accuracy of diagnosis on various cross-domain tasks, the disadvantage of combining the two methods is that the model becomes bloated, and the loss function is complicated, resulting in a reduced training speed. This is where the composite model falls short.
Then this paper conducts multi-source domain adaptation experiments. The multi-source methods compared with the MCDANN method proposed in this paper fall into two categories. The first is the single-source domain optimal method. For each source domain, we use this method to operate a singe-source cross-domain test on the target domain and get the best accuracy as the benchmark accuracy. The second is the multi-source methods which are extended to single-source domain methods. Among the feature-based methods, the DAN method is selected for multi-source domain expansion, and the MK-MMD distance between each source domain and target domain is calculated and the weighted sum is performed as the domain loss function for training; Among the adversarial-based methods, the DANN method is selected for expansion, computing the adversarial loss between each source and a target domain and weighted summation as the domain loss function for training. The multi-source methods all take three source domains to participate in the training, and the comparison results of several methods are shown in
Table 3.
Table 3 indicates that among the single-source domain methods, the composite model still has the best performance. Compared with the single-source domain, the DAN method and the DANN method using multi-source extension have a considerable improvement, which proves that multiple source domains can indeed provide more information to correct the problem of accuracy drop in cross-domain.
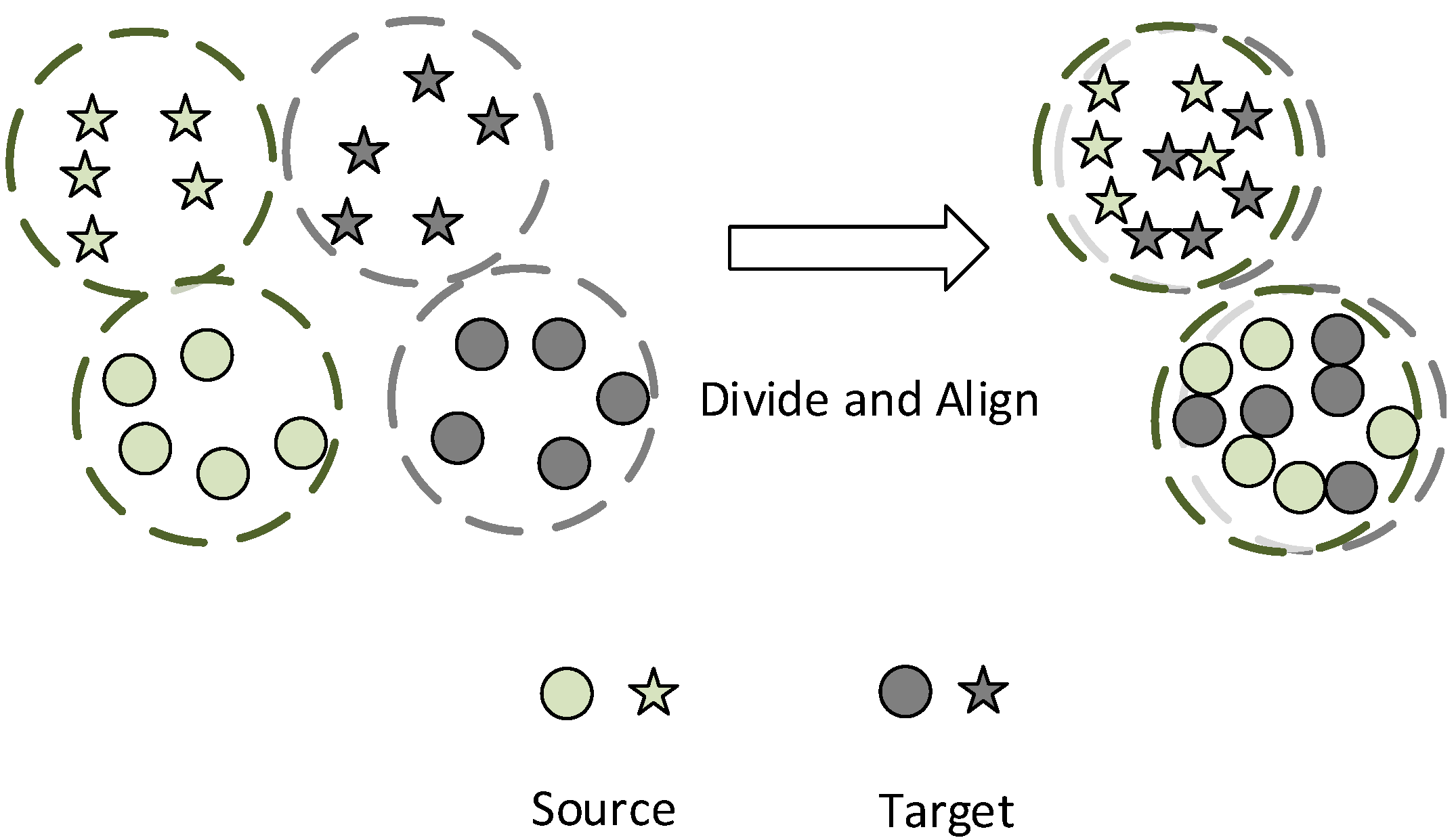
For the MCDANN method proposed in this paper, a consistency regularization loss is introduced besides the domain loss and classification loss, which improves the accuracy of the model by reducing the prediction difference on the target domain by models from several source domains. Therefore, we can get cross-domain diagnosis results in various domains with an accuracy of more than 96%, which proves its effectiveness.
However, the introduction of consistency loss also makes the loss function more complicated, thus affecting the speed of model training, making it slightly slower than other methods. This is also the disadvantage of MCDANN.
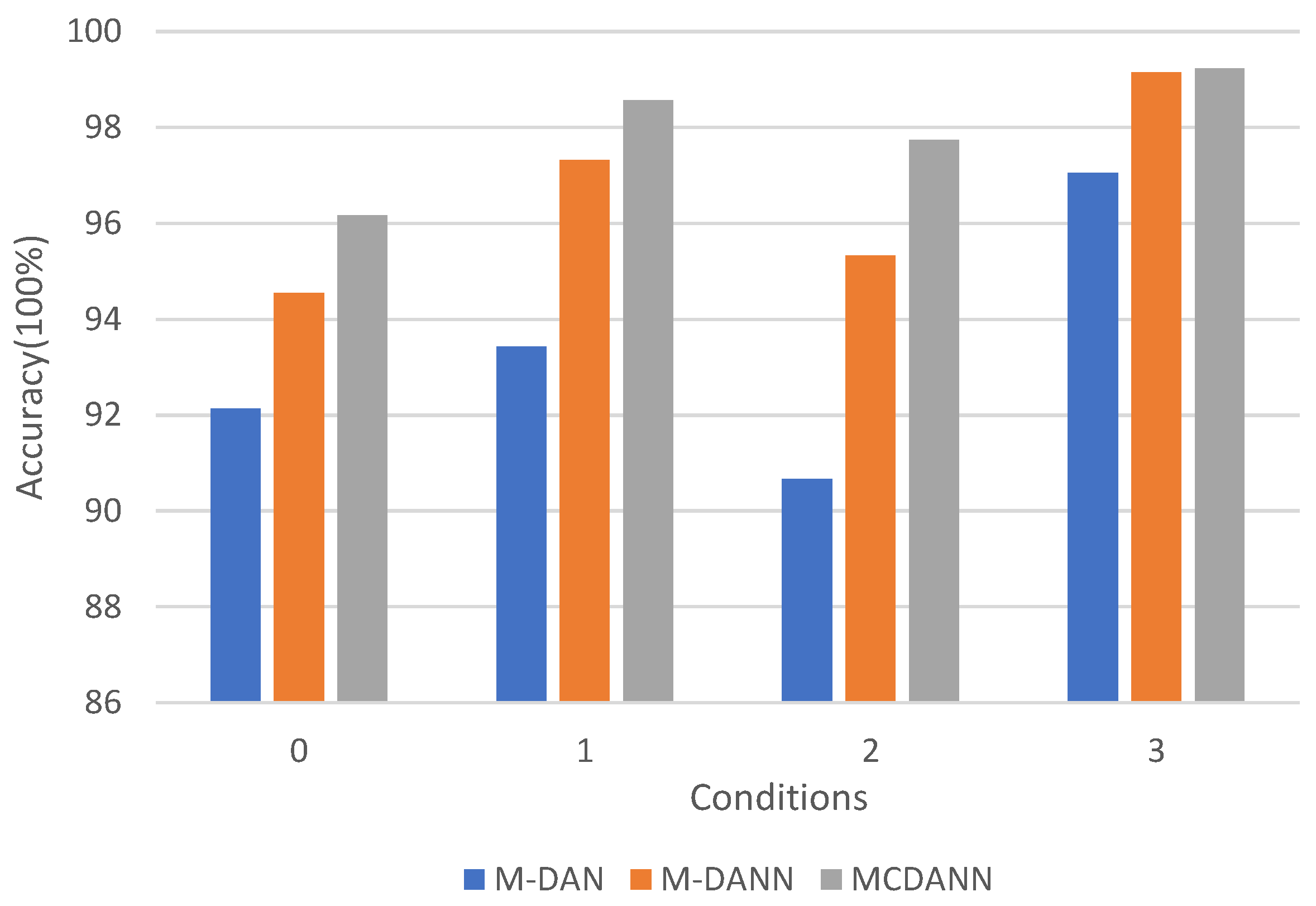
Figure 9 shows the accuracy comparison of several methods using multi-source domains under different working conditions. As can be seen from the figure, under the four unknown working conditions, the MCDANN method proposed in this paper has achieved the best accuracy. All these methods have lower accuracy on working conditions 0 and 2 and higher accuracy on 1 and 3. On working condition 3, since other methods have already achieved high diagnostic accuracy, the improvement of MCDANN is not large. On working condition 2, the MCDANN has the largest relative improvement.
In addition to the CWRU dataset, we also tested our model on DIRG bearing dataset. DIRG dataset is an open source dataset acquired on the rolling bearing test rig of the Dynamic and Identification Research Group (DIRG) from the Department of Mechanical and Aerospace Engineering at Politecnico di Torino [
38]. This dataset includes a variety of speed and static load conditions, each with 6 failure modes, including two fault locations, inner ring or roller, each location includes 3 sizes of indentations, 450 um, 250 um, and 150 um. Due to the lack of some data, we decide to set the static load to 1000 N, and the rotational speed to 100 Hz, 200 Hz, 300 Hz, and 400 Hz as the four working conditions of No. 0~3 to carry out multi-source domain adaptive experiments. Except for the rotation speed as the working condition and these 6 fault modes as labels, other details are the same as the multi-source domain adaptation experiments on CWRU. The experimental results are shown as follows:
Table 4 and
Figure 10 show that our model achieved the best accuracy on most cross-domain conditions except one when tested on the DIRG dataset without fine-tuning, indicating that it is not by chance that our model can achieve a good result, proving the effectiveness of our method.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
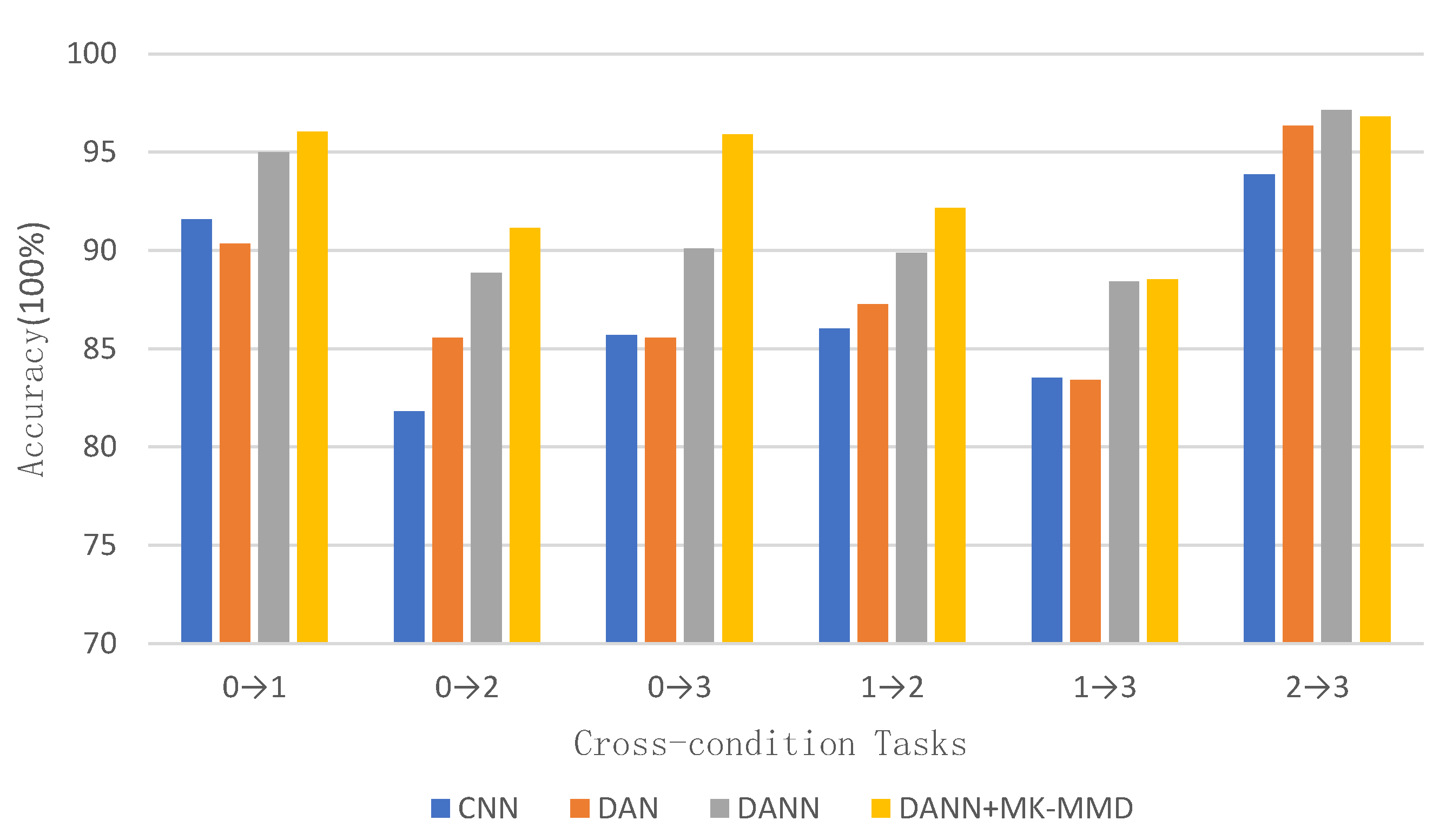{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}