
Stylized Pairing for Robust Adversarial Defense
Abstract
:1. Introduction
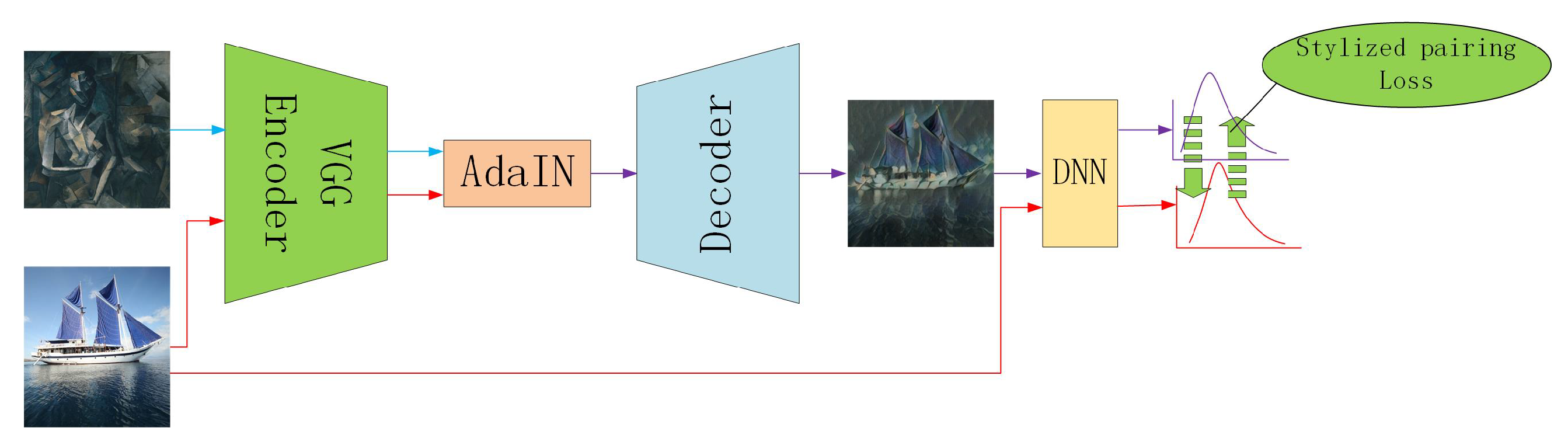
- We propose an adversarial defense method independent of adversarial perturbations, that is, stylized pairing training. By encouraging logit outputs for a pair of original image and corresponding stylized image to be similar, the proposed method increases the semantic similarity to improve models’ explainability.
- We propose an evaluation method to measure the robustness of models against adversarial examples with linear interpolation and analyze the training strategies with stylized pairings.
- Extensive experiments have been conducted, and the experimental results show that our method can efficiently extract shape-biased representation and therefore improve model robustness against adversarial examples.
2. Related Works
2.1. Style Transfer
2.2. Adversarial Defense
3. Material and Methods
3.1. Datasets
- CIFAR-10: It is a subset of the Tiny ImageNet dataset and is composed of 60,000 images. There are 10 classes including airplane, automobile, bird, cat, deer, horse, ship, and truck. All images were cropped to pixels.
- CIFAR-100: Similar to CIFAR-10, CIFAR-100 is also a subset of the Tiny ImageNet dataset and consists of 60,000 color images. In total, 100 classes are grouped into 20 super-classes. For each class, there are 600 images including the 500 training images and 100 testing images.
- ILSVRC2012: ImageNet Large Scale Visual Recognition Challenge 2012 (ILSVRC2012) is a subset of large hand-labeled ImageNet datasets, containing 1000 categories and 1.2 million images. In our experiment, we select 100 categories to conduct our experiments due to hardware limitations. We use ImageNet to denote this subset in the rest of the paper.
3.2. Model Architectures
- ResNet34: [30] contains 34 layers in total. It consists of a convolution layer and max pooling layer in its base layers, and 4 blocks convolution layers, with residual links between two consecutive layers. The channel numbers vary from 64 to 512 with the increase in layer number. Finally, the classification layer is composed of an average pooling layer and a fully connected layer.
- GoogLeNet: [31] is designed to keep a low computational budget. It contains 22 layers and is composed of convolution layers, max-pooling layers, and and convolution layers. After nine repeating inception modules, a fully connected layer is used for prediction.
- MobileNet: [32] has been extended to multiple versions. In this paper, we adopt the MobileNetV3 (small), which based on MobileNetV1’s depth-wise separable convolutions and MobileNetV2’s linear bottleneck and invert residual structure, introduces lightweight attention modules and excitation into the bottleneck structure. For details, please refer to [32].
3.3. Stylized Pairing Training
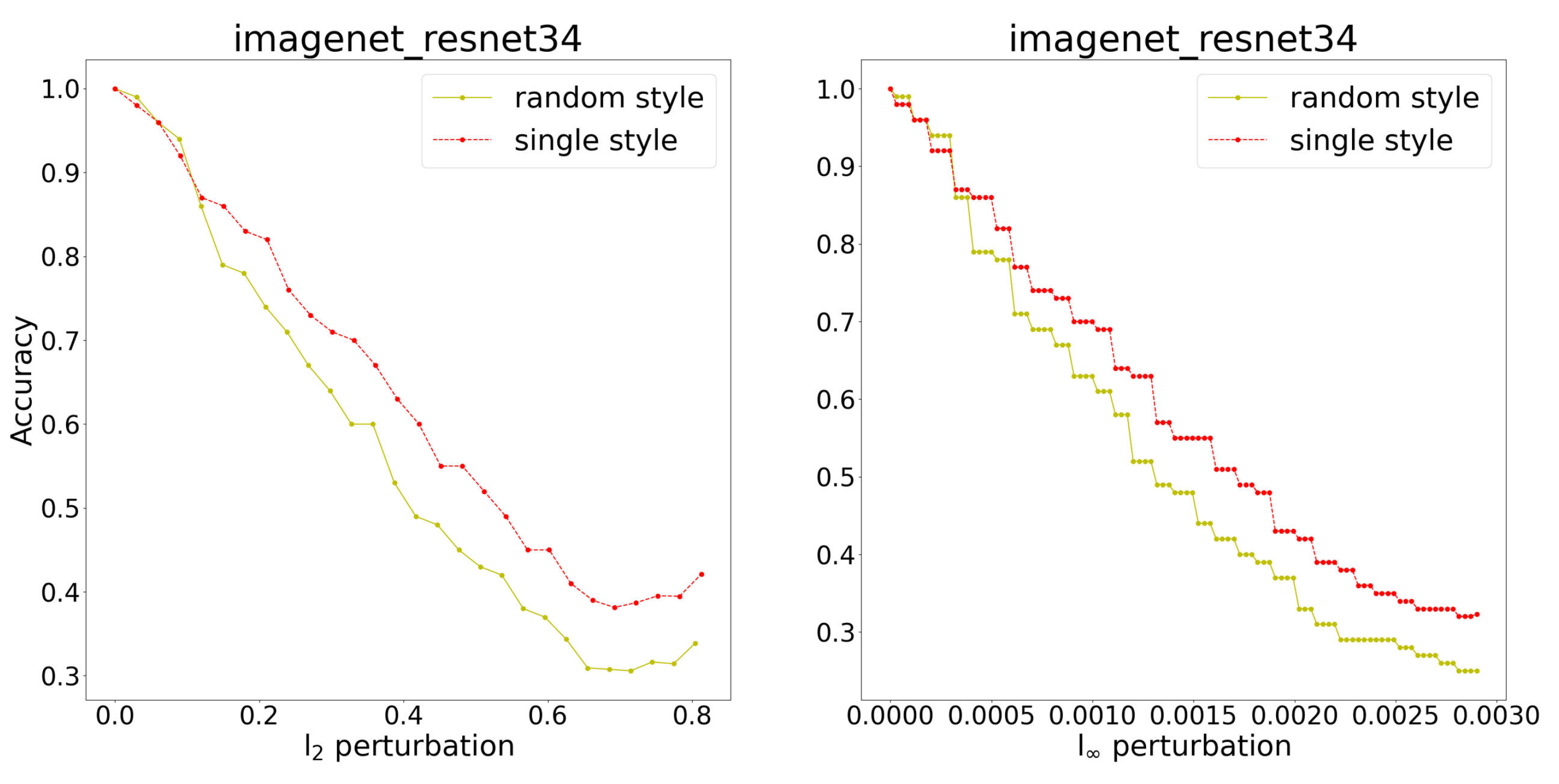
4. Results
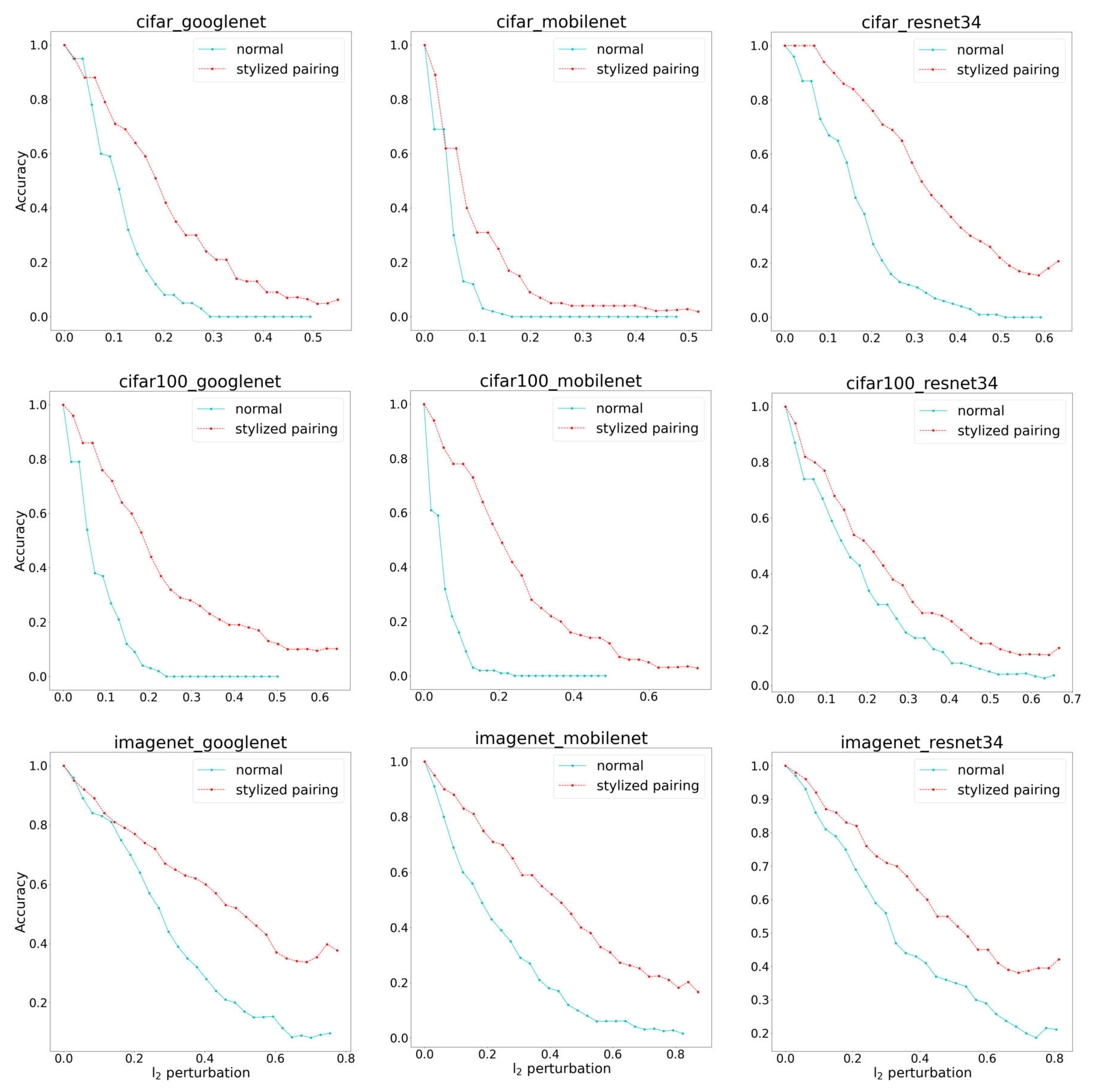
4.1. Comparisons with Normal Training
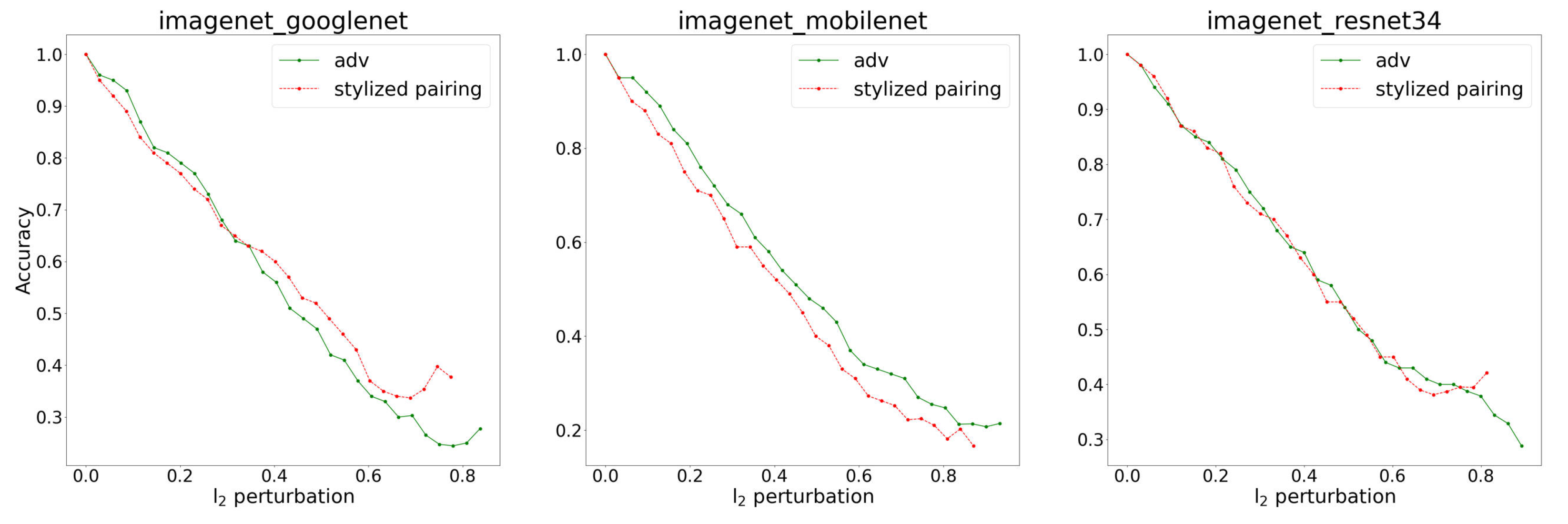
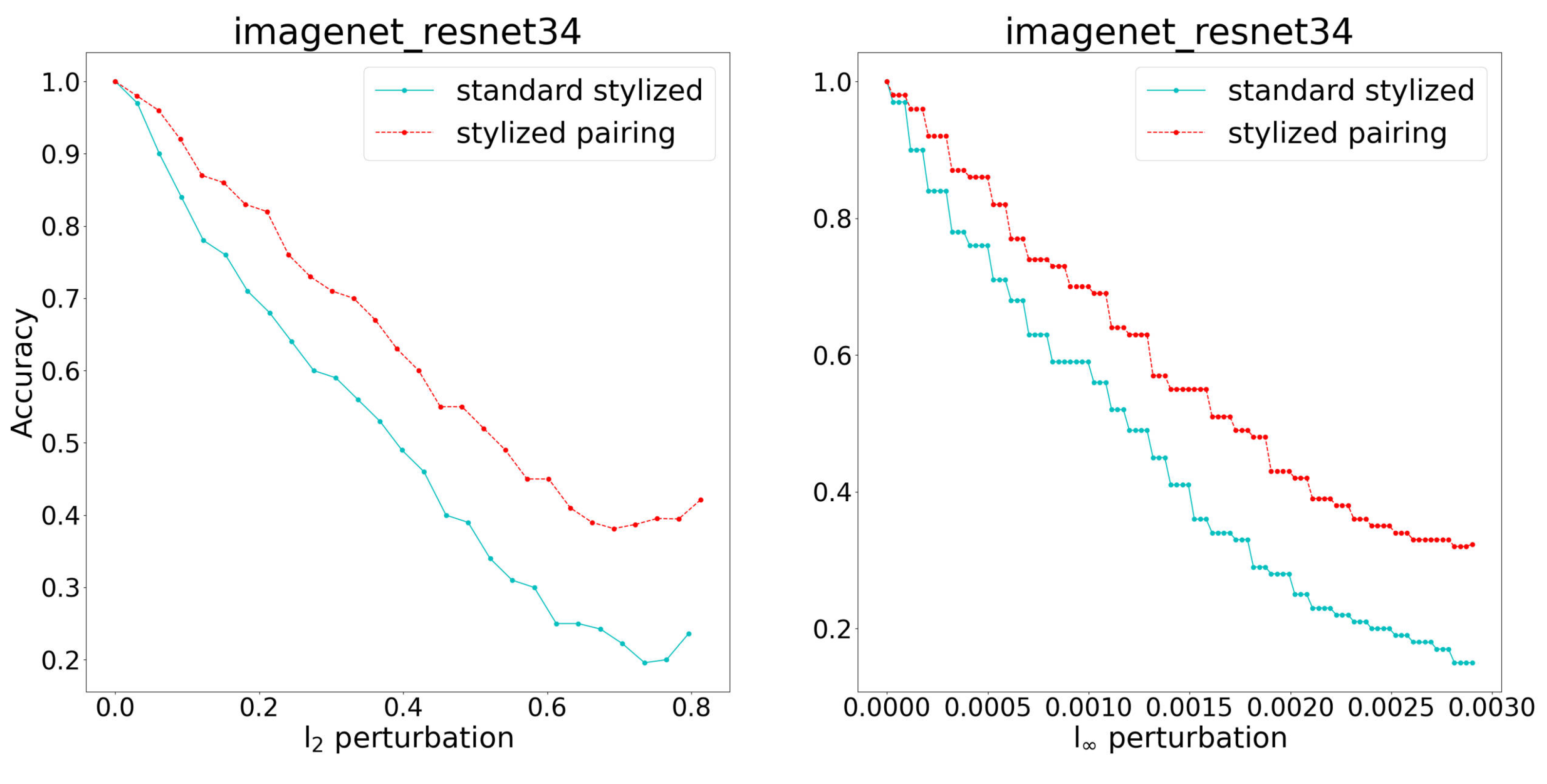
4.2. Comparisons with Adversarial Training
5. Discussions
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Yu, Z.; Zhou, Y.; Zhang, W. How Can We Deal With Adversarial Examples? In Proceedings of the 2020 12th International Conference on Advanced Computational Intelligence (ICACI), Dali, China, 14–16 March 2020; pp. 628–634. [Google Scholar]
- Peng, Y.; Zhao, W.; Cai, W.; Su, J.; Han, B.; Liu, Q. Evaluating deep learning for image classification in adversarial environment. IEICE Trans. Inf. Syst. 2020, 103, 825–837. [Google Scholar] [CrossRef]
- Geirhos, R.; Rubisch, P.; Michaelis, C.; Bethge, M.; Wichmann, F.A.; Brendel, W. ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. arXiv 2018, arXiv:1811.12231. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards deep learning models resistant to adversarial attacks. arXiv 2017, arXiv:1706.06083. [Google Scholar]
- Sen, S.; Ravindran, B.; Raghunathan, A. Empir: Ensembles of mixed precision deep networks for increased robustness against adversarial attacks. arXiv 2020, arXiv:2004.10162. [Google Scholar]
- Katz, G.; Barrett, C.; Dill, D.L.; Julian, K.; Kochenderfer, M.J. Reluplex: An efficient SMT solver for verifying deep neural networks. In Proceedings of the International Conference on Computer Aided Verification, Heidelberg, Germany, 24–28 July 2017; pp. 97–117. [Google Scholar]
- Gehr, T.; Mirman, M.; Drachsler-Cohen, D.; Tsankov, P.; Chaudhuri, S.; Vechev, M. Ai2: Safety and robustness certification of neural networks with abstract interpretation. In Proceedings of the 2018 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 21–23 May 2018; pp. 3–18. [Google Scholar]
- Zhai, R.; Dan, C.; He, D.; Zhang, H.; Gong, B.; Ravikumar, P.; Hsieh, C.J.; Wang, L. Macer: Attack-free and scalable robust training via maximizing certified radius. arXiv 2020, arXiv:2001.02378. [Google Scholar]
- Ross, A.; Doshi-Velez, F. Improving the adversarial robustness and interpretability of deep neural networks by regularizing their input gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LO, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Gu, S.; Rigazio, L. Towards deep neural network architectures robust to adversarial examples. arXiv 2014, arXiv:1412.5068. [Google Scholar]
- Xie, C.; Wu, Y.; Maaten, L.v.d.; Yuille, A.L.; He, K. Feature denoising for improving adversarial robustness. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 501–509. [Google Scholar]
- Borji, A. Shape Defense Against Adversarial Attacks. arXiv 2020, arXiv:2008.13336. [Google Scholar]
- Addepalli, S.; BS, V.; Baburaj, A.; Sriramanan, G.; Babu, R.V. Towards achieving adversarial robustness by enforcing feature consistency across bit planes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1020–1029. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A neural algorithm of artistic style. arXiv 2015, arXiv:1508.06576. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 694–711. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. Stylebank: An explicit representation for neural image style transfer. In Proceedings of the IEEE Conference On computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1897–1906. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A learned representation for artistic style. arXiv 2016, arXiv:1610.07629. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Dziugaite, G.K.; Ghahramani, Z.; Roy, D.M. A study of the effect of jpg compression on adversarial images. arXiv 2016, arXiv:1608.00853. [Google Scholar]
- Buckman, J.; Roy, A.; Raffel, C.; Goodfellow, I. Thermometer encoding: One hot way to resist adversarial examples. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Guo, C.; Rana, M.; Cisse, M.; Van Der Maaten, L. Countering adversarial images using input transformations. arXiv 2018, arXiv:1711.00117. [Google Scholar]
- Xu, W.; Evans, D.; Qi, Y. Feature squeezing: Detecting adversarial examples in deep neural networks. arXiv 2017, arXiv:1704.01155. [Google Scholar]
- Ma, X.; Li, B.; Wang, Y.; Erfani, S.M.; Wijewickrema, S.; Schoenebeck, G.; Song, D.; Houle, M.E.; Bailey, J. Characterizing adversarial subspaces using local intrinsic dimensionality. arXiv 2018, arXiv:1801.02613. [Google Scholar]
- Somavarapu, N.; Ma, C.Y.; Kira, Z. Frustratingly simple domain generalization via image stylization. arXiv 2020, arXiv:2006.11207. [Google Scholar]
- Brochu, F. Increasing shape bias in ImageNet-trained networks using transfer learning and domain-adversarial methods. arXiv 2019, arXiv:1907.12892. [Google Scholar]
- Kannan, H.; Kurakin, A.; Goodfellow, I. Adversarial logit pairing. arXiv 2018, arXiv:1803.06373. [Google Scholar]
- Naseer, M.; Khan, S.; Hayat, M.; Khan, F.S.; Porikli, F. Stylized adversarial defense. arXiv 2020, arXiv:2007.14672. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. Pytorch: An imperative style, high-performance deep learning library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Raghunathan, A.; Xie, S.M.; Yang, F.; Duchi, J.C.; Liang, P. Adversarial training can hurt generalization. arXiv 2019, arXiv:1906.06032. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CIFAR-10 | CIFAR-100 | |||||
|---|---|---|---|---|---|---|
| GoogLetNet | MobileNet | Resnet34 | GoogLetNet | MobileNet | Resnet34 | |
| Stylized | 94.05% | 92.00% | 94.92% | 78.72% | 75.44% | 78.65% |
| Normal | 95.01% | 93.29% | 95.59% | 78.25% | 74.80% | 80.14% |
| ImageNet | |||
|---|---|---|---|
| GoogLetNet | MobileNet | Resnet34 | |
| Stylized | 77.74% | 73.24% | 77.54% |
| Normal | 79.12% | 74.80% | 79.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guan, D.; Zhao, W.; Liu, X. Stylized Pairing for Robust Adversarial Defense. Appl. Sci. 2022, 12, 9357. https://doi.org/10.3390/app12189357
Guan D, Zhao W, Liu X. Stylized Pairing for Robust Adversarial Defense. Applied Sciences. 2022; 12(18):9357. https://doi.org/10.3390/app12189357
Chicago/Turabian StyleGuan, Dejian, Wentao Zhao, and Xiao Liu. 2022. "Stylized Pairing for Robust Adversarial Defense" Applied Sciences 12, no. 18: 9357. https://doi.org/10.3390/app12189357