1. Introduction
Road traffic safety hazards are currently a common social safety issue all over the world. In terms of vehicle type, car-related accidents account for more than two-thirds of all and are the most harmful. To improve traffic safety, the automotive industry developed airbags, anti-lock braking systems, and electronic stability systems were used in the early days. In recent years, research in the field of automotive safety has moved toward a more intelligent Advanced Driving Assistance System (ADAS). ADAS can perceive the surrounding environment and alert the driver or control the vehicle automatically when danger is present, thus reducing or avoiding the hazards of traffic accidents. It is a new generation of active safety systems [
1]. Since most accidents originate from collisions between vehicles and obstacles, obstacle avoidance is the primary task of ADAS, and accurate detection of obstacles is the basis for ADAS to take obstacle avoidance measures.
Unexpected hazards on the road (e.g., lost goods, loose stones, etc.) are an easily overlooked problem for traffic safety, and they can easily cause traffic accidents, which have a great impact on people’s property and even their lives. US traffic reports show that approximately 150 people die each year in the US due to lost goods on the road [
2]. As such, obstacles usually have small sizes and complex shapes, and achieving accurate and effective detection is a hard task for both drivers and general detection systems. Therefore, it is greatly significant to include the detection of unexpected obstacles in vehicle environment perception systems and develop an effective detection method.
There are currently two solutions in the field of automotive environment perception, namely computer vision solution and radar solution. At the current research stage, both solutions have certain advantages and disadvantages, but the computer vision solution is closer to the human driving form and has great potential for development. Vision is the most important way for humans to obtain information, and studies have shown that about 90% of the information obtained by drivers comes from vision [
3]. Computer vision takes a camera as a sensor, and the images acquired by the camera are most similar to the real world perceived by the human eyes, which contains a wealth of information that can be used for a variety of tasks in the field of environment perception. In addition, computer vision solutions are low-cost and more easily marketable.
Stereo vision and deep learning are the two main detection methods used in vision solutions. Stereo vision methods [
4,
5] mainly rely on the stereo information contained in stereo image pairs captured by binocular cameras and use the differences in the geometric structure of objects to recognize the image content. However, stereo vision techniques are strongly influenced by distance and are not effective in detecting obstacles at long distances. Deep learning methods can handle complex feature information thanks to the powerful feature extraction capabilities of convolutional neural networks. In addition, they have certain advantages over stereo vision methods in terms of detection distance and accuracy, and semantic information can be obtained. Consequently, this paper studies an unexpected obstacle detection method based on deep learning, and it mainly has the following three contributions:
A semantic segmentation method suitable for detecting unexpected obstacles on the road is proposed. Traditional supervised machine learning systems can only identify the classes of obstacles present in the training set but are powerless for unexpected obstacles. A powerful advantage of DeepLabV3+ is its ability to use the learned contextual features of the images to generalize information far beyond their training data. This paper highlights the contextual features of unexpected obstacles on the road by reasonably defining the pixel classes of the training dataset and uses DeepLabV3+ to perform semantic segmentation of images to achieve effective detection of unexpected obstacles.
An open-set recognition algorithm for unexpected road obstacles is designed. Depending on the difference in uncertainty between the known and unknown classes, it segments the unexpected obstacles by adaptive threshold. The algorithm is very different from semantic segmentation methods in terms of the principle and the image information used, so it can complement semantic segmentation methods very well.
A probabilistic fusion detection method based on the Bayesian model is proposed. The Bayesian model is a classical probabilistic prediction model, which makes the prediction results more consistent with the human brain’s judgment and decision-making process by using multivariate data for joint inference. We incorporate the detection results of the two aforementioned methods into the Bayesian model in a probabilistic form to improve the system’s ability to detect unexpected obstacles.
The rest of the paper is organized as follows. Related work is introduced in
Section 2.
Section 3 presents the core algorithms, including unexpected obstacle detection based on semantic segmentation, unexpected obstacle detection based on uncertainty, and probabilistic fusion.
Section 4 is the experiment and result analysis. The conclusions are made in
Section 5.
2. Related Work
The early machine learning methods divided the obstacle detection task into two steps: feature extraction and feature classification. The artificially designed features were input into some shallow classifiers for detection and recognition, and the detection accuracy and classification ability are limited. In recent years, deep learning techniques using deep neural networks as tools have greatly advanced the development of artificial intelligence. Among them, deep convolutional neural networks (CNNs) [
6,
7,
8] have a powerful feature extraction capability, which can learn the features of the object better and achieve higher accuracy detection. Therefore, CNNs are widely used in obstacle detection tasks [
9,
10,
11]. For example, Qi et al. [
9] first targeted obstacle regions by the maximum difference and morphological Region Of Interest (ROI) extraction method and then input the resulting ROI into CNN for obstacle recognition, thus improving the accuracy of obstacle detection and recognition. Jia et al. [
10] added the global information of a single image to the classifier while using CNN combined with Deep Belief Network (DBN) to build an obstacle detection model, which experimentally proved to have good detection capability. Levi et al. [
11] proposed an obstacle detection and road segmentation method called StixelNet, which simplified the detection task to a stixel regression problem and introduced a loss function based on a semi-discrete representation of the obstacle position probability to train the network, and achieved good results on the KITTI dataset [
12]. However, these traditional CNN-based obstacle detection methods are less flexible and cannot provide dense and accurate obstacle locations.
An effective way to use CNNs for obstacle detection is semantic segmentation. Semantic segmentation is the classification of each pixel in an image to achieve region segmentation, which is suitable for application in pixel-level scene representation and obstacle detection. In 2015, Long et al. proposed the Fully Convolutional Network (FCN) [
13], replacing fully connected layers in the traditional CNN with convolutional layers. FCN is widely used in semantic segmentation because the convolutional layer can retain a higher image resolution, which is beneficial for pixel-level task such as semantic segmentation. The evaluation results of the PASCAL VOC dataset [
14] showed that FCN-based semantic segmentation methods [
15,
16] take the lead. Badrinarayanan et al. proposed SegNet [
17] based on FCN, whose encoder part used the first 13 layers of the convolutional network of VGG-16 [
18], and each encoder layer corresponded to a decoder layer. The final output of the decoder was fed to a softmax classifier to generate a class probability for each pixel independently. To address the problem of a single scale of FCN feature extraction, the Unet [
19] proposed by Ronneberger et al. adopted the feature channel concatenation method, thus retaining more image information. In addition, its unique U-shaped network structure enabled it to have better access to the semantic information of small objects. The DeeplabV3+ model [
20] proposed by Chen et al. in 2018 incorporated an Encoder-Decoder structure and combined it with Atrous Spatial Pyramid Pooling (ASPP), which enlarged the perceptual field of the model by introducing atrous convolution and further improved the segmentation capability of the model for objects of different sizes. In recent years, some researchers have applied semantic segmentation models to the field of obstacle detection and achieved good results. For example, Shin et al. [
21] proposed a deep residual network EAR-Net for road scene segmentation on the basis of ASPP, which improved the accuracy of segmentation by utilizing depthwise separable convolution and interpolation for feature extraction and recovery. Valdez-Rodríguez et al. [
22] combined depth estimation with a semantic segmentation model and proposed a hybrid CNN network. This model can separate the foreground and background in images and achieve good segmentation results on the SYNTHIA-AL dataset [
23].
The above-mentioned semantic segmentation methods are only used to detect the types of obstacles that already exist in the training set, while unexpected obstacles (which do not exist in the training set) are not detected. Creusot et al. [
24] first explored this particular problem, and the paper used a restricted Boltzmann machine neural network to detect anomalous regions on the road. There are currently some methods for the detection of unexpected classes, such as open-set recognition, out-of-distribution detection, anomaly detection, and novelty detection, etc. However, the difference between the latter three methods and open-set recognition is that they cannot distinguish known classes in the training set [
25]. The methods to solve the open-set recognition problem are referred to as open-set recognition algorithms [
26]. Scheirer et al. [
27] conducted pioneering research on the open-set recognition problem and defined it as a constrained minimization problem. The article proposes a novel method to deal with the task of open-set recognition, which sculpts a decision space from the marginal distances of a 1-class or binary SVM with a linear kernel. Bendale et al. [
28] investigated the use of deep neural networks for open-set recognition to provide deep-learning-based recognition systems with the ability to reject unexpected class. However, the above two approaches have not carried out targeted research in the area of unexpected obstacle detection.
As a matter of fact, using a single method for obstacle detection in practical problems is very limited. If different detection methods can be integrated, the purpose of complementing each other’s advantages can be achieved, thereby improving the detection quality. In recent years, many researchers have adopted this idea. For example, Schneider et al. [
29] defined the model as an energy minimization problem and used semantics and geometry as unary data terms in it. This model can jointly infer semantic and geometric clues to achieve better detection results. Zhang et al. [
30] proposed an obstacle detection method using fusion of radar and visual data, and its data fusion methods are divided into two categories: spatial fusion and time fusion. The former can realize the unification between coordinate systems through a series of coordinate transformations, and the latter can ensure the synchronization of data fusion in time. It can be seen that the fusion method can consider a variety of data information, which effectively improves the detection quality. For fusion strategies, Bayesian is a probability-based fusion framework, which is very classic and widely used. Therefore, this paper adopts Bayesian as the fusion framework.
In fact, semantic segmentation models have inherently powerful generalization capabilities and are capable of acquiring much more information than the types of data provided in the training dataset. For example, semantic segmentation models can learn the contextual information of an image from a large amount of training data [
17,
19]. Pixels in an image are usually not isolated, and contextual information reflects some connections between a pixel and its neighboring pixels. The information generalization capability of semantic segmentation models provides powerful technical support for the detection of unexpected obstacles. In this paper, a semantic segmentation method that can highlight the contextual information of unexpected obstacles is designed for such a complex problem of unexpected obstacle detection. In addition, as the semantic method only utilizes the semantic information of the image, the detection accuracy is limited, so this paper also designs an open-set recognition algorithm based on the uncertainty. Unexpected obstacles are detected by incorporating the two methods into the Bayesian framework for joint inference.
3. Proposed Methods
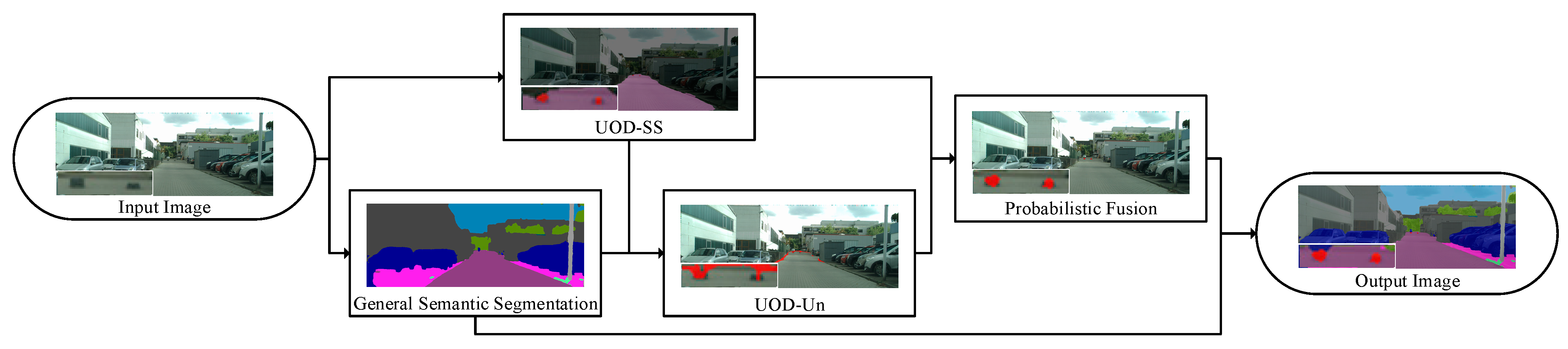
Figure 1 shows the flow chart of our method. First, the input image is fed into Unexpected Obstacles Detection Based on Semantic Segmentation (UOD-SS) and general semantic segmentation. The Unexpected Obstacles Detection Based on Uncertainty (UOD-Un) based on uncertainty degree uses the results of the above two methods. Then, the detection probabilities provided by the above two methods are fused through a Bayesian framework (Probabilistic Fusion Based on UOD-SS and UOD-Un, PF-SSUn). Finally, the output image is the superposition of general semantic segmentation and probabilistic fusion results.
3.1. Unexpected Obstacle Detection Based on Semantic Segmentation (UOD-SS)
In this paper, by reasonably defining the classes of the training dataset, the contextual features of unexpected obstacles on the road are highlighted. The powerful information generalization ability of the semantic segmentation model is used to realize the detection of unexpected obstacles; at the same time, the free space where the vehicle can travel is output. To highlight the contextual features of unexpected obstacles, traffic scenes are divided into three classes: free space, unexpected obstacles, and background, where the background class is defined as any image region except free space and unexpected obstacles on the road.
Figure 2 shows this classification method. There are two dropped cargoes in
Figure 2a, shown in the image as unexpected obstacles on the road.
Figure 2b is the scene image after segmentation according to the above classification method. The purple part represents free space, the red part represents unexpected obstacles, and the uncolored part represents the background. It can be seen from
Figure 2b that these two unexpected obstacles are particularly prominent in the free space. Due to the small number of scene classes, the network ignores the shape and other features of the obstacles and focuses on the common contextual properties of unexpected obstacles on the road. Therefore, this kind of semantic information can be learned by virtue of the semantic segmentation model to segment unexpected obstacles at different distances and appearances.
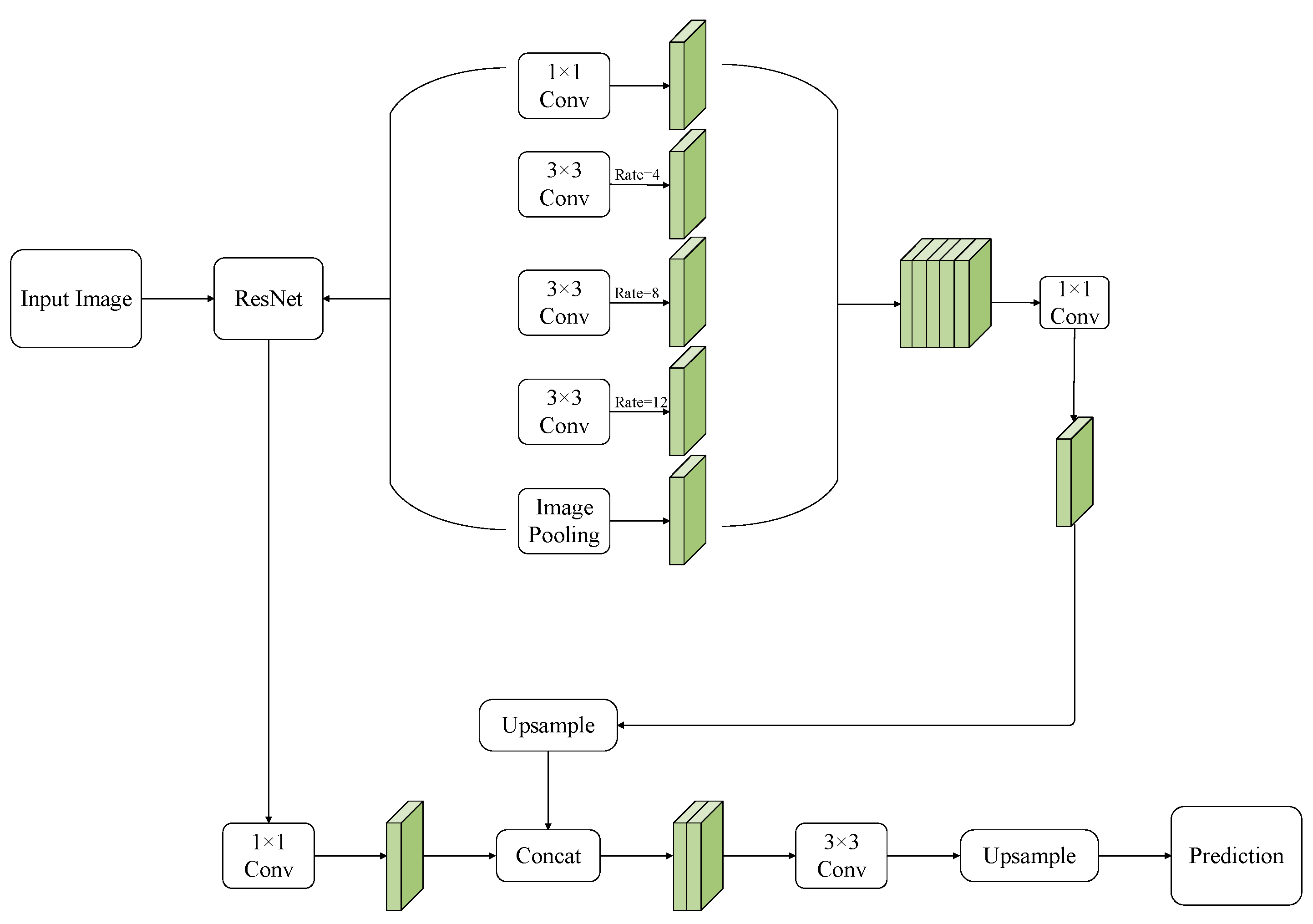
The advanced DeepLabV3+ is used as the semantic segmentation model, and ResNet-50 is adopted as the backbone feature extraction network. The model combines the encoder-decoder structure and ASPP, which can well restore the edge information of the image and learn multi-scale features. The architecture of DeepLabV3+ for the UOD-SS method is shown in
Figure 3. To solve the problem of semantic segmentation of road scenes, the model introduces atrous convolution. Compared with standard convolution, atrous convolution can increase the receptive field of the model and retain more spatial information about small objects. For unexpected obstacles of small size, atrous convolution can effectively reduce the interference of large background regions on feature extraction. At the same time, it can make the feature map in the model retain the boundary information of the object as much as possible without adding too many calculation parameters. For a two-dimensional signal such as an image, the mapping formula for the input and output of the atrous convolution is as follows:
Among them, is the index value of a single element of the feature map; is the dilation rate of the atrous convolution; is the convolution kernel of size .
Aiming at unexpected obstacles on the road, the original atrous convolution with the dilation rate of 6, 12, and 18 in DeepLabV3+ is changed to 4, 8, and 12, respectively. As the resolution of the feature maps continues to decrease, the smaller dilation rate can efficiently extract low-resolution feature maps. At the same time, the ASPP structure adopted by the model integrates multi-scale feature information and uses a convolution kernel with a larger dilation rate to segment large objects and smaller one to segment small objects, thereby enhancing the model’s ability to segment objects of different sizes.
Finally, this semantic segmentation network is trained using the Lost and Found dataset [
5], which contains road scenes with high complexity and various unexpected obstacles.
3.2. Unexpected Obstacle Detection Based on Uncertainty (UOD-Un)
In order to further improve the detection effect of unexpected obstacles, an open-set recognition algorithm UOD-Un based on uncertainty is designed in this paper. We compute the uncertainty degree from the known class probabilities obtained from general semantic segmentation. The general semantic segmentation is different from the three-class semantic segmentation in the UOD-SS method in
Section 3.1; its training set contains common objects in the traffic scene. In general, semantic segmentation, the predicted probabilities of unexpected obstacle (unknown class) are usually more dispersed among known classes, with higher uncertainty relative to known classes.
Figure 4 shows the uncertainty degree distribution of general semantic segmentation.
Figure 4a shows the result of general semantic segmentation for the scene in
Figure 2a.
Figure 4b shows the uncertainty degree distribution map of
Figure 4a, and the ROI in
Figure 4b is the free space class and unexpected obstacle class region in
Figure 2b. From
Figure 4b, it can be seen that the area of the unexpected obstacle class is red, indicating that this area has a higher uncertainty degree. Therefore, the uncertainty degree can be used to distinguish known and unknown classes so that unexpected obstacles can be detected.
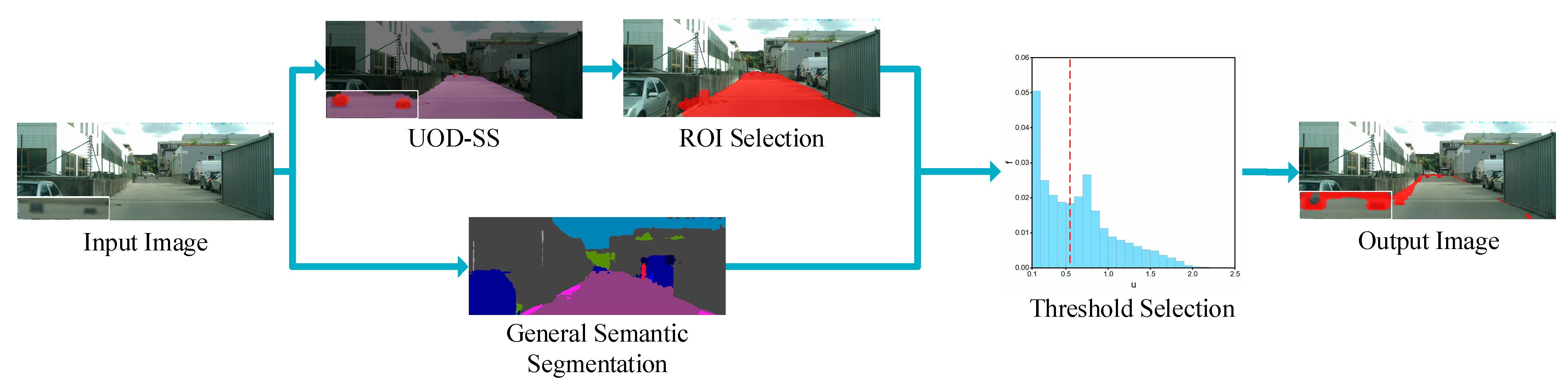
The flow of UOD-Un is shown in
Figure 5. Firstly, the general semantic segmentation is performed on the original image, and then the ROI is determined according to the detection result of UOD-SS. Finally, the uncertainty degree of the pixels in this region is calculated, and the threshold of the uncertainty degree is used to segment unexpected obstacles. When performing general semantic segmentation, we also choose the DeepLabV3+ model and use the Cityscapes dataset [
31] as the training set, which can complement the Lost and Found dataset to a certain extent.
Entropy can describe the uncertainty of each possible event of the information source, so it is used as the measurement criterion of pixel uncertainty in this paper. The uncertainty degree of the pixel
in the input image is defined as follows:
Among them, is the total number of classes; is the class index; represents the prediction probability of the class of the pixel in the image, which can be obtained by the Softmax layer of the semantic segmentation model.
There is also a high uncertainty at the class boundary of the image, and this method may mark these pixels as an unknown class, resulting in a high false-positive rate of the segmentation results. Therefore, it is necessary to filter out these points that interfere with the detection results as much as possible. Given that unexpected obstacles are generally scattered in free space, the free space class and unexpected obstacle class regions detected by UOD-SS are first selected, and then the region is expanded by 3 pixels in each of the length and width dimensions of the image. The expanded region is used as the ROI of UOD-Un, so that the selected ROI can avoid the interference of the background, thereby minimizing the occurrence of false positives.
According to the previous analysis, unexpected obstacles can be segmented by the uncertainty degree threshold, so it is very important to choose this threshold reasonably. An adaptive threshold selection method is proposed in this paper.
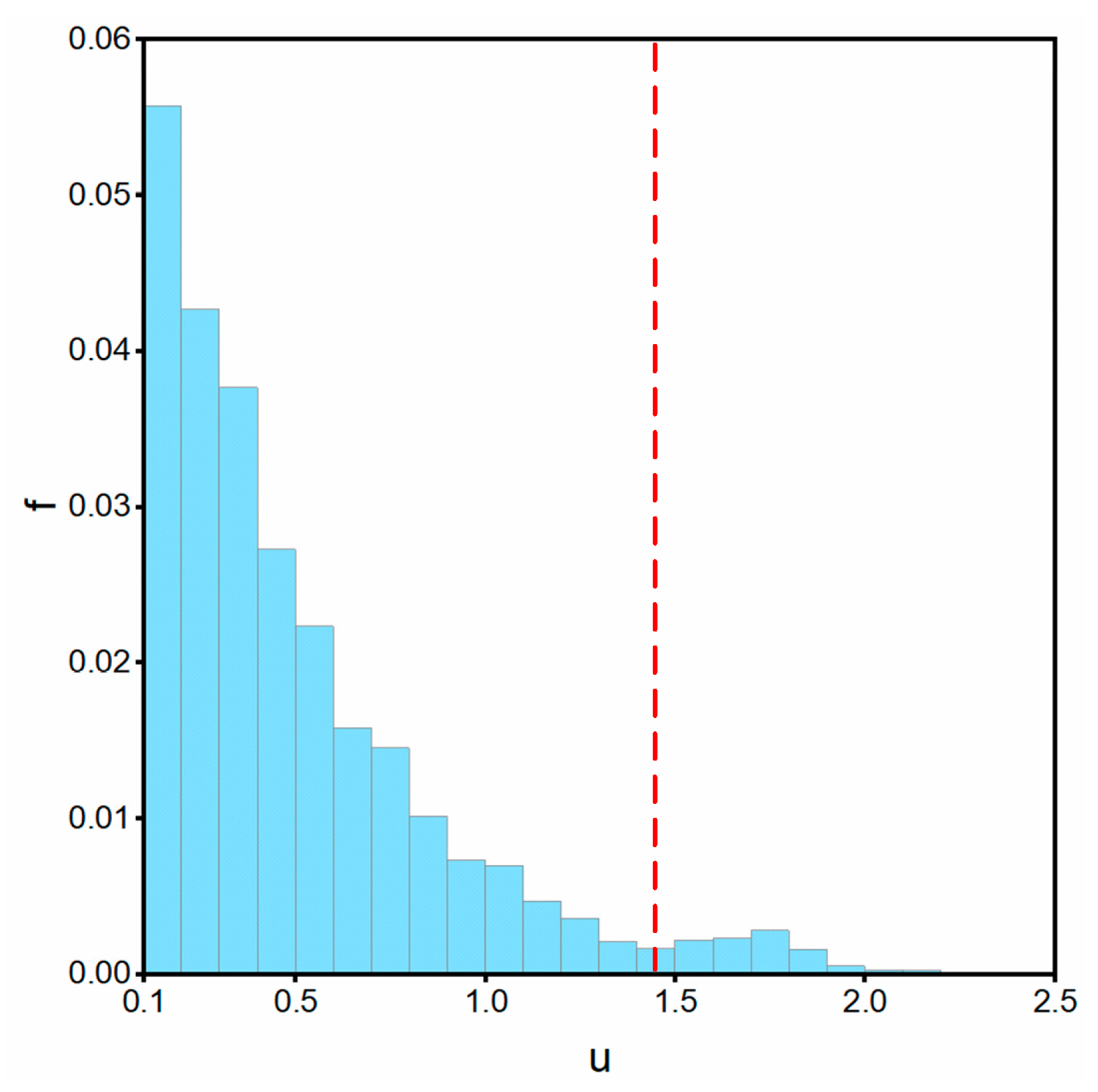
Figure 6 shows the uncertainty degree distribution histogram of an image. The horizontal axis is the uncertainty degree (u) represented by entropy, and the vertical axis is the frequency (f) of pixels with a certain uncertainty degree. The figure reflects the general distribution of uncertainty degree. Considering that the number of pixels belonging to the known classes is large and mainly distributed on the left, while the number of pixels belonging to the unknown class is small and mainly distributed on the right, if the known classes and the unknown class are regarded as two different sets, then the point with the loosest coupling between the two sets should be selected as the threshold point for segmentation. According to this threshold selection principle, first find the leftmost and rightmost frequency peak intervals in the uncertainty degree distribution histogram (to avoid chance, the count of pixels in the peak interval is required to be greater than 100), and then take the midpoint of the minimum interval between these two peaks as the threshold, as shown by the red dotted line in the figure. Finally, all the pixels whose uncertainty degree is higher than the threshold are marked as an unknown class. The selection of the threshold is shown in Algorithm 1.
| Algorithm 1. The selection of the threshold algorithm. |
Input:: Uncertainty frequency distribution; : Intervals quantity of uncertainty frequency distribution; : The function to find local maximum of frequency; : The count of pixels in the interval; : The function to find the left endpoint of minimum interval
Output:
: Leftmost peak; : Rightmost peak; : Selected threshold |
, , ,
1. Find the leftmost peak
while
do
if
and
end if
end while
2. Find the rightmost peak
while do
if
and
end if
end while
3. Determine the threshold
|
3.3. Probabilistic Fusion (PF-SSUn)
Psychological research shows that human judgment and decision making is a combination of a variety of information and gives results in a probabilistic way. For intelligent vehicles, obstacle detection is also a judgment and decision-making process. The UOD-SS and UOD-Un methods proposed in this paper detect unexpected obstacles from the perspectives of semantic information and uncertainty information, respectively. The two methods are independent of each other, so the fusion of the obtained results can bring many new advantages. The Bayesian framework is suitable for decision inference based on multi-factor probabilistic methods, which is more in line with the human brain’s judgment and decision-making process than the methods of obstacle detection using single information. In this paper, it is used to fuse the results obtained by the above two independent methods, and the probability that a pixel is an unexpected obstacle can be expressed as:
Among them, represents the prior probability; and represent the probability that the pixel is judged as an unexpected obstacle by UOD-SS and UOD-Un, respectively. Finally, the judgment of whether the pixel is an unexpected obstacle depends on the threshold of .
can be obtained directly from the Softmax layer of the network, and the Softmax function can be expressed as:
Among them,
represents the output of the previous stage unit of the class
;
is the class index;
is the total number of classes. Therefore,
can be expressed as:
where
,
, and
represent the output of the previous stage unit of background class, free space class and unexpected obstacles class, respectively.
can be obtained according to the degree of deviation between the uncertainty degree of each pixel and the threshold. Assuming that the probability at the threshold is 50%, it can be expressed as:
Among them, represents the value of the uncertainty degree at the threshold; represents the uncertainty degree of pixel .
5. Conclusions
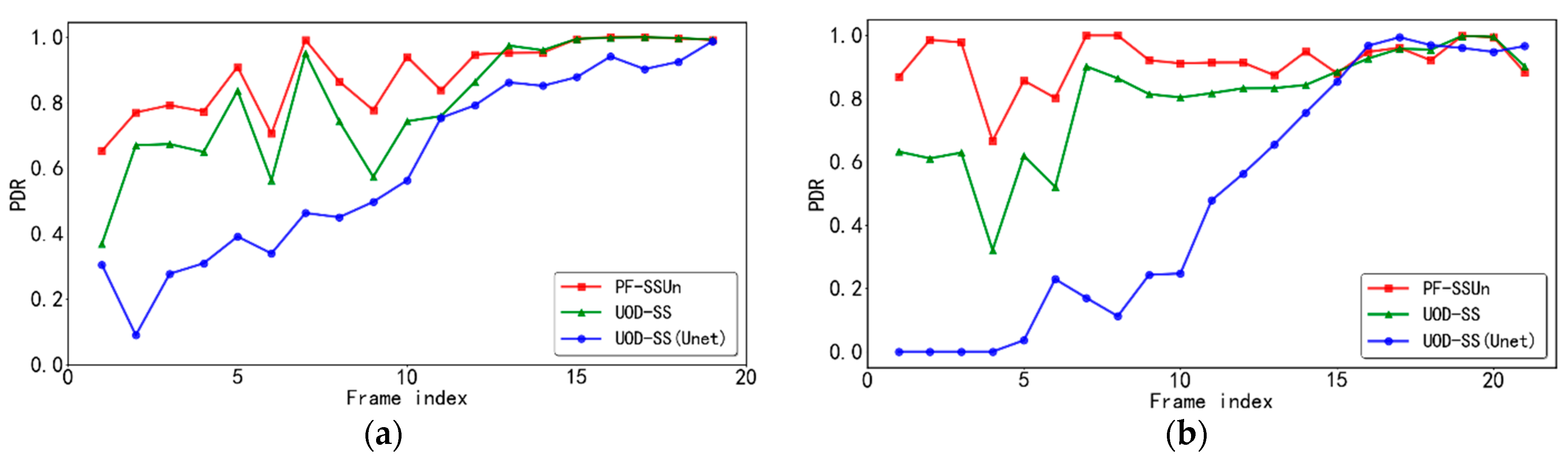
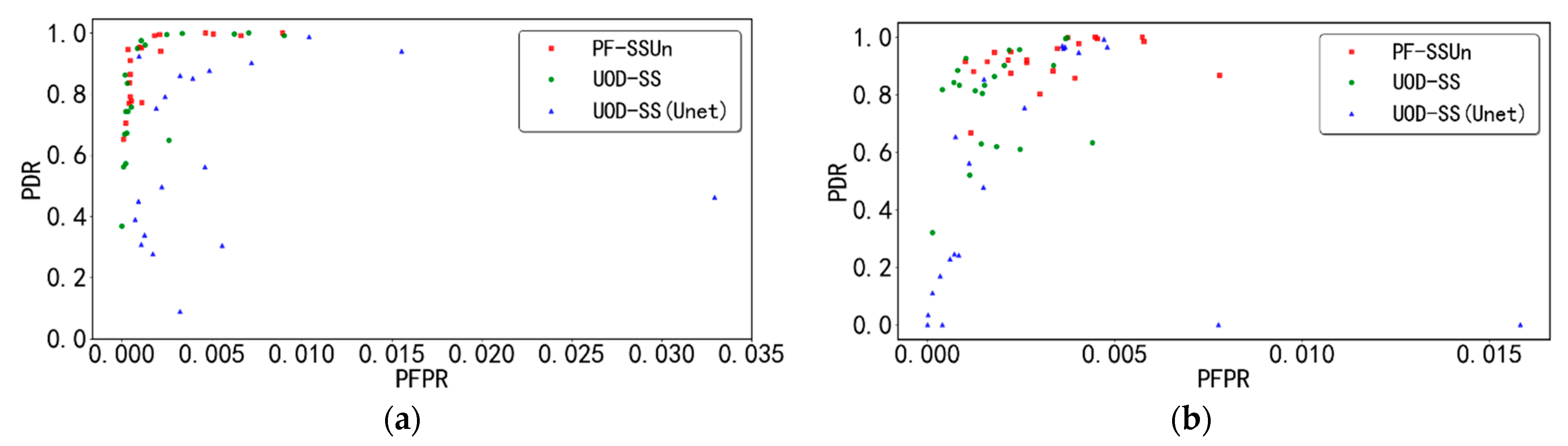
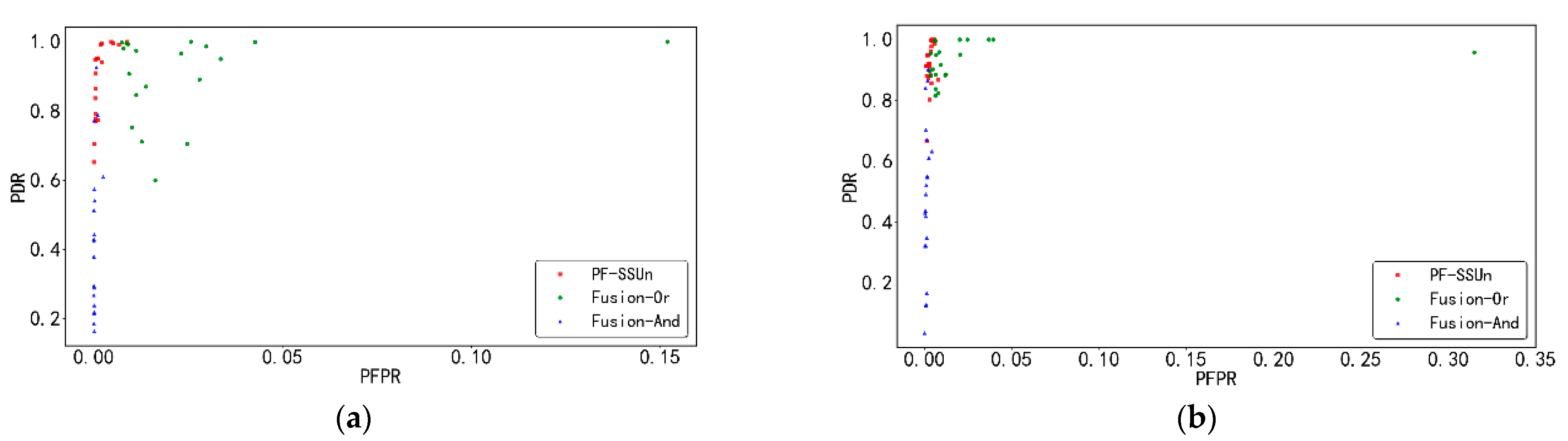
In order to improve the environment perception ability of ADAS, this paper proposes an unexpected obstacle detection method based on Bayesian probabilistic fusion. Firstly, an unexpected obstacle detection method based on semantic segmentation (UOD-SS) is proposed. This method highlights the contextual information of unexpected obstacles by reasonably dividing the scene classes so that the semantic segmentation model can more easily identify unexpected obstacles. Furthermore, we propose an uncertainty-based unexpected obstacle detection method (UOD-Un), which uses an adaptive threshold to segment known and unknown classes. Finally, the detection probabilities provided by the above two methods are fused through the Bayesian framework, and the obtained result reflects the joint decision making based on various information. Experiments implemented on the public dataset Lost and Found show that the pixel-level detection rate and false-positive rate of our method are 92.33 and 0.37%, respectively. Even in the detection of long-distance and small-size unexpected obstacles, our method has achieved good detection results. It can be seen from the experimental results that there are many false-positive pixels in the detection results of UOD-Un. Although the fusion method can remove some of them, the remaining pixels still have a certain effect on the final false-positive rate. Therefore, our future work is to study how to reduce the false-positive rate of UOD-Un. In addition, since the core of this paper is two unexpected obstacle detection methods and their fusion, the existing DeepLabV3+ network is selected for semantic segmentation. If a more powerful semantic segmentation network can be designed, it may improve the detection effect. This is also our future work.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}