
Study on the Technology Trend Screening Framework Using Unsupervised Learning

Abstract
:1. Introduction
2. Literature Review on Methodology
2.1. Patent Analysis on Management of Technology
2.2. Document Embedding Method—Doc2Vec
2.3. Outlier and Outlier Detection
2.4. Topic Model
- Choose
- Choose
- For each of the words
- Choose a topic
- Choose a word from , a multinomial probability conditioned on the topic
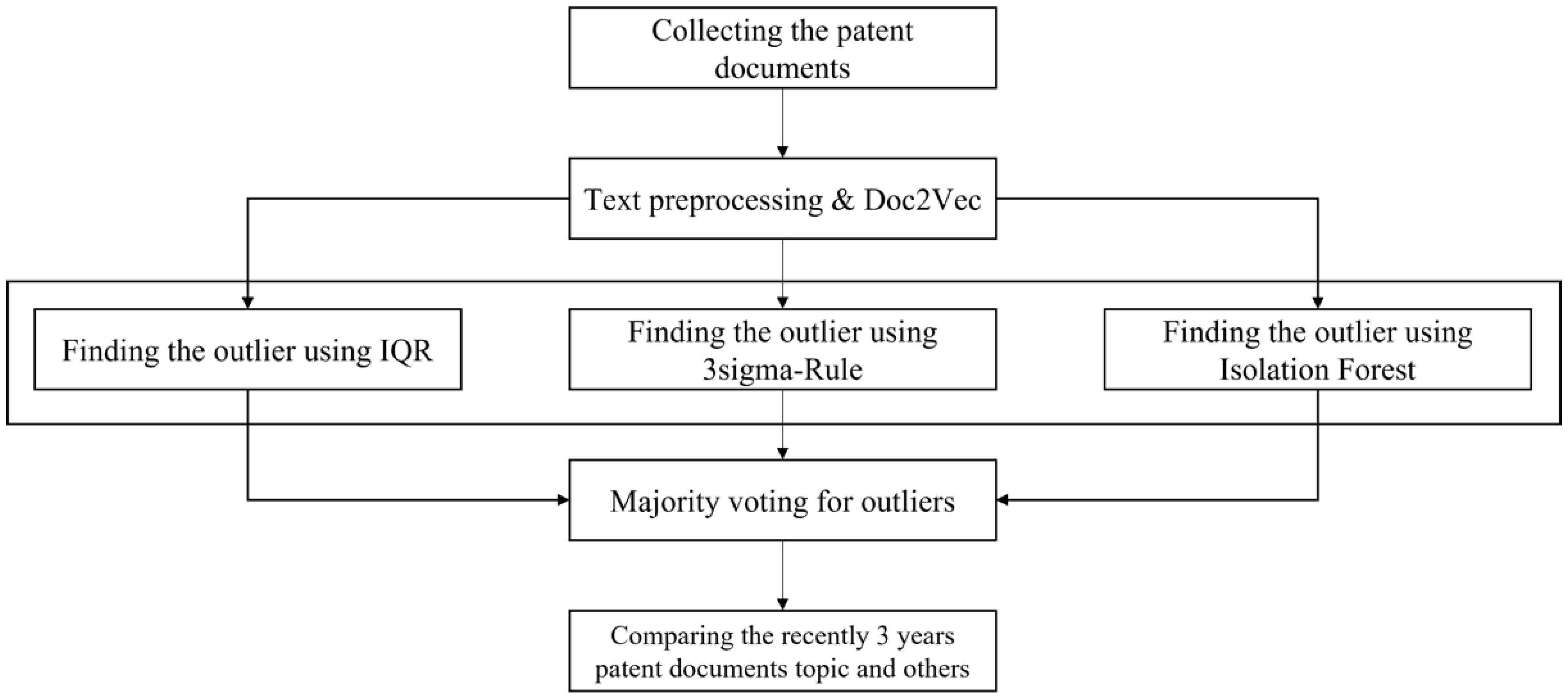
3. Proposed Methodology
3.1. Collecting the Data
3.2. Apply the Doc2Vec
3.3. Technology Trend Screening Using Outlier Detection and Topic Model
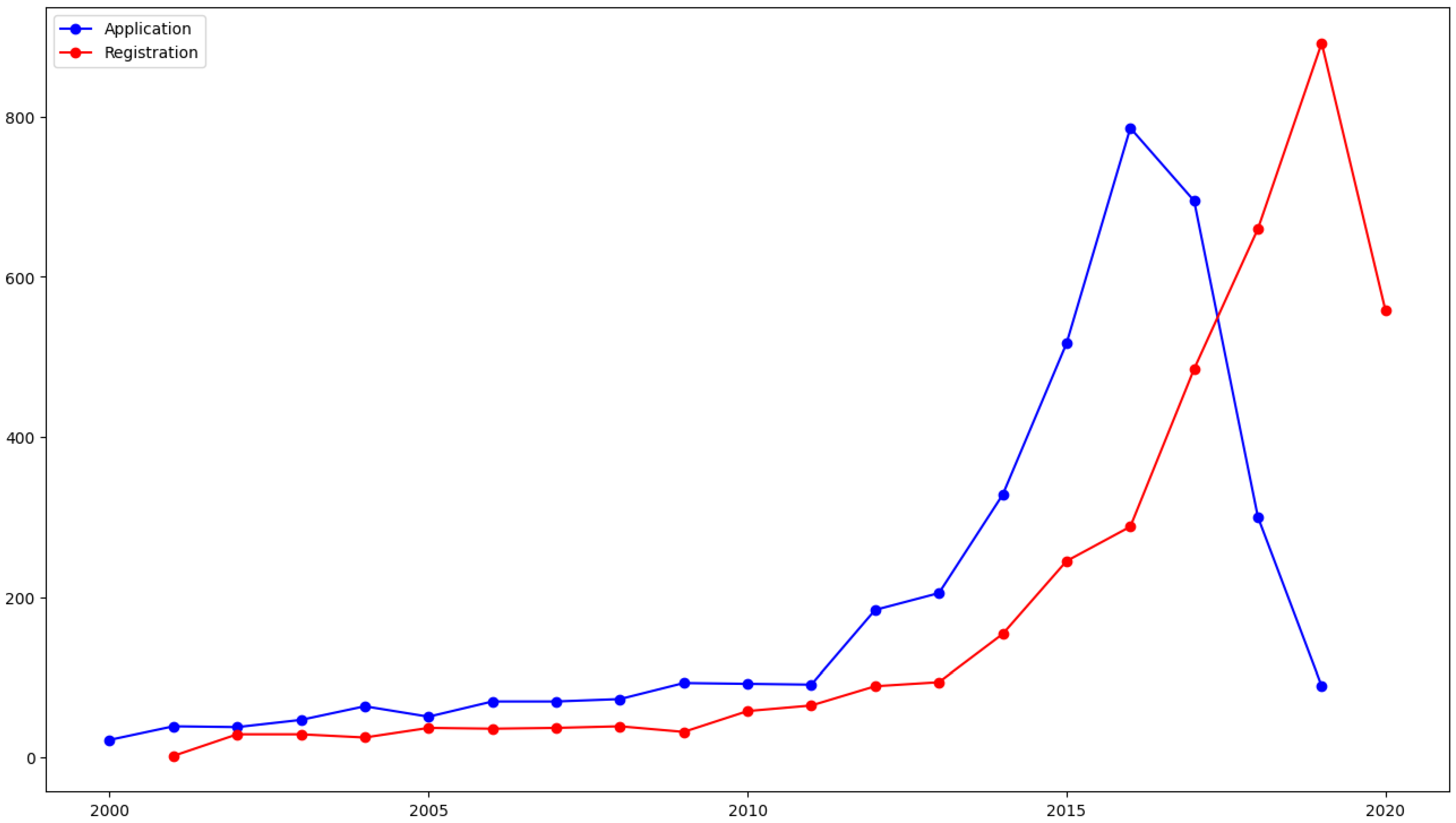
4. Experiments and Results
5. Conclusions and Future Research
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Oussous, A.; Benjelloun, F.Z.; Ait Lahcen, A.; Belfkih, S. Big Data Technologies: A Survey. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 431–448. [Google Scholar] [CrossRef]
- Monino, J.L. Data Value, Big Data Analytics, and Decision-Making. J. Knowl. Econ. 2021, 12, 256–267. [Google Scholar] [CrossRef]
- Kang, J.; Lee, J.; Jang, D.; Park, S. A Methodology of Partner Selection for Sustainable Industry-University Cooperation Based on LDA Topic Model. Sustainability 2019, 11, 3478. [Google Scholar] [CrossRef]
- Jacob, M.; Hellström, T.; Adler, N.; Norrgren, F. From Sponsorship to Partnership in Academy-industry Relations. RD Manag. 2000, 30, 255–262. [Google Scholar] [CrossRef]
- Santoro, M.D.; Betts, S.C. Making Industry-University Partnerships Work. Res. Technol. Manag. 2002, 45, 42–46. [Google Scholar] [CrossRef]
- Abbas, A.; Zhang, L.; Khan, S.U. A Literature Review on the State-of-the-Art in Patent Analysis. World Pat. Inf. 2014, 37, 3–13. [Google Scholar] [CrossRef]
- Bonino, D.; Ciaramella, A.; Corno, F. Review of the State-of-the-Art in Patent Information and Forthcoming Evolutions in Intelligent Patent Informatics. World Pat. Inf. 2010, 32, 30–38. [Google Scholar] [CrossRef]
- Abraham, B.P.; Moitra, S.D. Innovation Assessment through Patent Analysis. Technovation 2001, 21, 245–252. [Google Scholar] [CrossRef]
- Lee, C.; Lee, G. Technology Opportunity Analysis Based on Recombinant Search: Patent Landscape Analysis for Idea Generation. Scientometrics 2019, 121, 603–632. [Google Scholar] [CrossRef]
- Kim, G.; Bae, J. A Novel Approach to Forecast Promising Technology through Patent Analysis. Technol. Forecast. Soc. Chang. 2017, 117, 228–237. [Google Scholar] [CrossRef]
- Kim, G.; Park, S.; Jang, D. Technology Analysis from Patent Data Using Latent Dirichlet Allocation. In Proceedings of the Soft Computing in Big Data Processing; Lee, K.M., Park, S.-J., Lee, J.-H., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 71–80. [Google Scholar]
- Yoon, B.; Park, Y. A Systematic Approach for Identifying Technology Opportunities: Keyword-Based Morphology Analysis. Technol. Forecast. Soc. Chang. 2005, 72, 145–160. [Google Scholar] [CrossRef]
- Kim, T.S.; Sohn, S.Y. Machine-Learning-Based Deep Semantic Analysis Approach for Forecasting New Technology Convergence. Technol. Forecast. Soc. Chang. 2020, 157, 120095. [Google Scholar] [CrossRef]
- Yoon, B.; Park, Y. A Text-Mining-Based Patent Network: Analytical Tool for High-Technology Trend. J. High Technol. Manag. Res. 2004, 15, 37–50. [Google Scholar] [CrossRef]
- Park, S.; Lee, S.J.; Jun, S. Patent Big Data Analysis Using Fuzzy Learning. Int. J. Fuzzy Syst. 2017, 19, 1158–1167. [Google Scholar] [CrossRef]
- Wang, J.; Chen, Y.J. A Novelty Detection Patent Mining Approach for Analyzing Technological Opportunities. Adv. Eng. Inform. 2019, 42, 100941. [Google Scholar] [CrossRef]
- Park, S.; Jun, S. Patent Analysis Using Bayesian Data Analysis and Network Modeling. Appl. Sci. 2022, 12, 1423. [Google Scholar] [CrossRef]
- Chandola, V.; Kumar, V. Outlier Detection: A Survey. ACM Comput. Surv. 2007, 14, 15. [Google Scholar]
- Singh, K.; Upadhyaya, S. Outlier Detection: Applications And Techniques. Int. J. Comput. Sci. Issues 2012, 9, 307–323. [Google Scholar]
- Sikder, M.N.K.; Batarseh, F.A. Outlier Detection Using AI: A Survey. arXiv 2021, arXiv:2112.00588. [Google Scholar]
- Jeon, D.; Ahn, J.M.; Kim, J.; Lee, C. A Doc2vec and Local Outlier Factor Approach to Measuring the Novelty of Patents. Technol. Forecast. Soc. Chang. 2022, 174, 121294. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient Estimation of Word Representations in Vector Space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Le, Q.V.; Mikolov, T. Distributed Representations of Sentences and Documents. arXiv 2014, arXiv:1405.4053. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014. [Google Scholar]
- Roper, A.T.; Cunningham, S.W.; Porter, A.L.; Mason, T.W.; Rossini, F.A.; Banks, J. Forecasting and Management of Technology, 2nd ed.; Wiley: Hoboken, NJ, USA, 2011; ISBN 9780470440902. [Google Scholar]
- Jun, S.; Park, S. Examining Technological Competition between BMW and Hyundai in the Korean Car Market. Technol. Anal. Strateg. Manag. 2016, 28, 156–175. [Google Scholar] [CrossRef]
- Lee, J.; Kang, J.H.; Jun, S.; Lim, H.; Jang, D.; Park, S. Ensemble Modeling for Sustainable Technology Transfer. Sustainability 2018, 10, 2278. [Google Scholar] [CrossRef]
- Chalapathy, R.; Chawla, S. Deep Learning for Anomaly Detection: A Survey. arXiv 2019, arXiv:1901.03407. [Google Scholar]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Liu, F.T.; Ting, K.M.; Zhou, Z.H. Isolation-Based Anomaly Detection. ACM Trans. Knowl. Discov. Data 2012, 6, 1–39. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technical Field | Number of Avg. Words in Document | Number of Documents | Period |
|---|---|---|---|
| Drone | 636 | 3854 | January 2000–December 2019 |
| Hyperparameter | Candidates |
|---|---|
| Vector size | 2 |
| Window | 10 |
| Minimum count | 2 |
| Epoch | 30 |
| Hyperparameter | Candidates |
|---|---|
| Inference Algorithm | Gibbs Sampling |
| The Number of K | From 1 to 10 |
| Parameter |
| 2000–2016 | 2017–2019 | |
|---|---|---|
| Number of documents | 2770 | 1084 |
| X-Axis | Y-Axis | |
|---|---|---|
| IQR | 1.241 | 2.600 |
| −1.045 | −5.834 | |
| 3.918 | 4.567 |
| Mean | Std. | Outlier (Left) | Outlier (Right) | |
|---|---|---|---|---|
| X-axis | 1.541 | 1.081 | −1.702 | 4.784 |
| Y-axis | −0.745 | 1.864 | −6.338 | 4.848 |
| Document No. | IQR | 3 Sigma-Rule | iForest |
|---|---|---|---|
| US 10000285 | √ | ✕ | √ |
| US 10029790 | √ | √ | √ |
| … | … | … | … |
| US 9310207 | ✕ | ✕ | √ |
| US 9989378 | √ | ✕ | √ |
| Technology Area | Topic No. | Topic Description | Keyword |
|---|---|---|---|
| Inner in Training set | 1 | Navigation & sensor technology | data, determin, flight, base, devic, sensor, inform, processor, method, compris |
| 2 | Drone network technology | drone, signal, commun, receiv, system, object, configure, modul, data, network | |
| 3 | HMI(Human Machine Interface) technology | control, system, flight, oper, mode, command, configur, unit, signa, devic | |
| 4 | Thrust technology | wing, rotat, rotor, motor, drive, propel, fuselag, axi, blade, propuls | |
| 5 | Payload technology | captur, portion, configur, compris, assembl, posit, surfac, coupl, member, arm | |
| 6 | Perception technology | uav, vehicl, aerial, unman, imag, locat, area, camera, may, sensor | |
| 7 | Energy management technology | power, deliveri, air, electr, packag, system, batteri, energi, transport, sourc | |
| 8 | Technology for mission capable | cell, platform, mobil, robot, light, beam, tower, array, plural, extern | |
| 9 | Drone landing technology | aircraft, land, posit, ground, point, zone, method, featur, speed, later | |
| Outlier in Training set | 1 | UAS(unmanned aircraft system) Tech. | control, vehicl, system, uav, compris, imag, flight, devic, aircraft, data |
| Inner in Testing set | 1 | Payload technology | motor, portion, propel, payload, configur, plural, support, packag, compris, arm |
| 2 | Drone structure technology | rotor, assembl, wing, propuls, rotat, axi, vertic, surfac, bodi, lift | |
| 3 | Location estimation technology | data, drone, determin, locat, base, plural, sensor, method, processor, devic | |
| 4 | Network infra technology | signal, commun, wireless, system, devic, receiv, mobil, network, modul, antenna | |
| 5 | Fuel cell technology | batteri, configur, posit, coupl, deploy, unit, include, member, connect, compris | |
| 6 | Communication control technology | vehicl, uav, aerial, unman, system, control, configur, compris, may, commun | |
| 7 | Perception technology | imag, object, captur, camera, light, detect, virtual, len, plural, design | |
| 8 | Charging technology | power, electr, station, main, state, subsystem, connect, protect, left, adapt | |
| 9 | Thrust control & landing technology | control, aircraft, flight, oper, system, mode, command, signal, thrust, gener | |
| Outlier in Testing set | 1 | Flight control technology | vehicl, aerial, system, drone, control, unman, flight, compris, posit, configur |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Park, S.; Lee, J. Study on the Technology Trend Screening Framework Using Unsupervised Learning. Appl. Sci. 2022, 12, 8920. https://doi.org/10.3390/app12178920
Lee J, Park S, Lee J. Study on the Technology Trend Screening Framework Using Unsupervised Learning. Applied Sciences. 2022; 12(17):8920. https://doi.org/10.3390/app12178920
Chicago/Turabian StyleLee, Junseok, Sangsung Park, and Juhyun Lee. 2022. "Study on the Technology Trend Screening Framework Using Unsupervised Learning" Applied Sciences 12, no. 17: 8920. https://doi.org/10.3390/app12178920