


Application of Machine Learning to Express Measurement Uncertainty
 , ,
, ,
Abstract
:1. Introduction
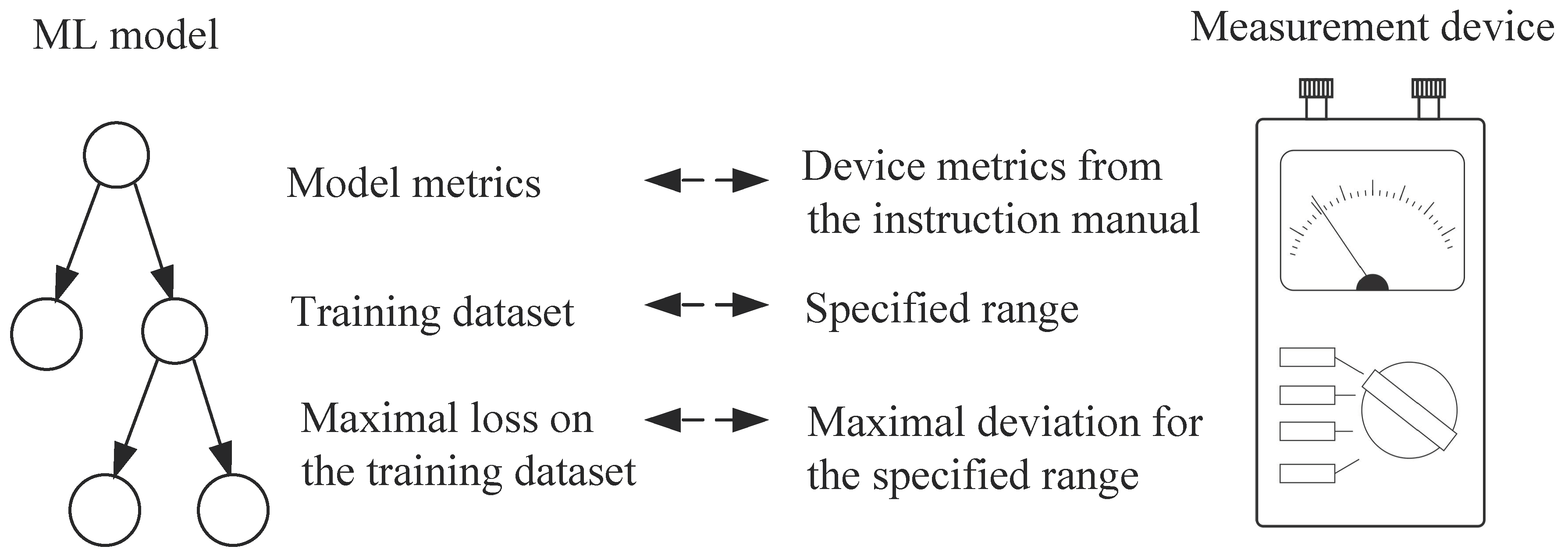
- To address the abovementioned issues, a novel “judgmental” [21] approach to evaluating the measurement uncertainty of the ML model is proposed. The method is based on the analogy of an ML model and an actual measurement device.
- It uses the procedure for expressing the type B measurement uncertainty [29] and the maximal value of the empirical absolute loss function of the ML model. Since expressing type B measurement uncertainty is based on the experience and judgment of the measurer, the approach is referred to as “judgmental [21]”.
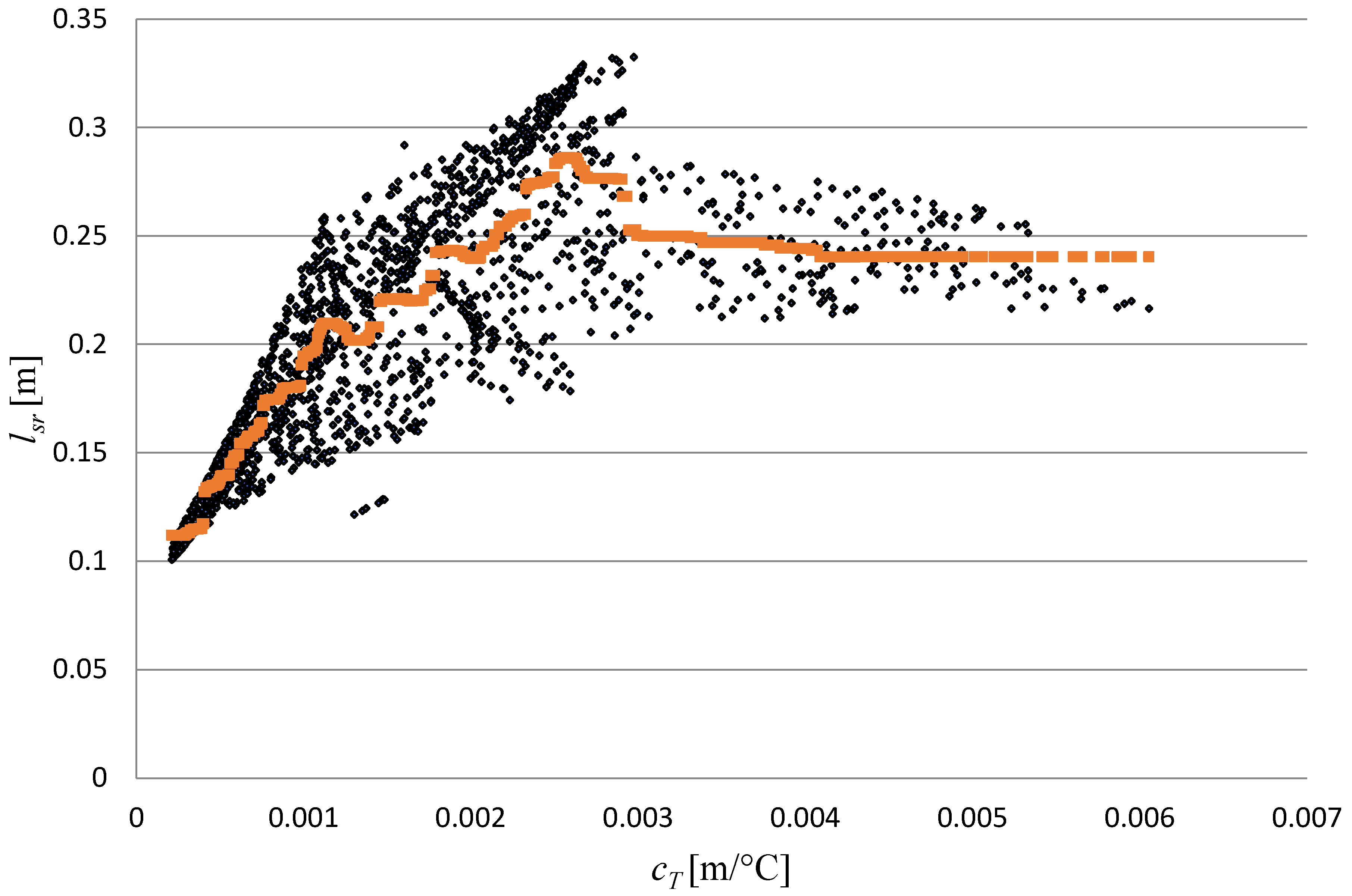
- The example uses the dataset representing the correlation of the mean distance of partial discharge and acoustic emission (AE) sensors and the temperature coefficient of sensitivity of the non-iterative algorithm [30].
- Based on the highest coefficient of determination value, the dropout additive regression trees algorithm (DART) achieved the best performance.
- The proposed estimation procedure is not limited to the presented example but can also be used in all similar regression problems, including big data analysis.
- The proposed procedure is applicable even when the probability distribution of deviation of predicted values from correct values is unknown.
2. Methods
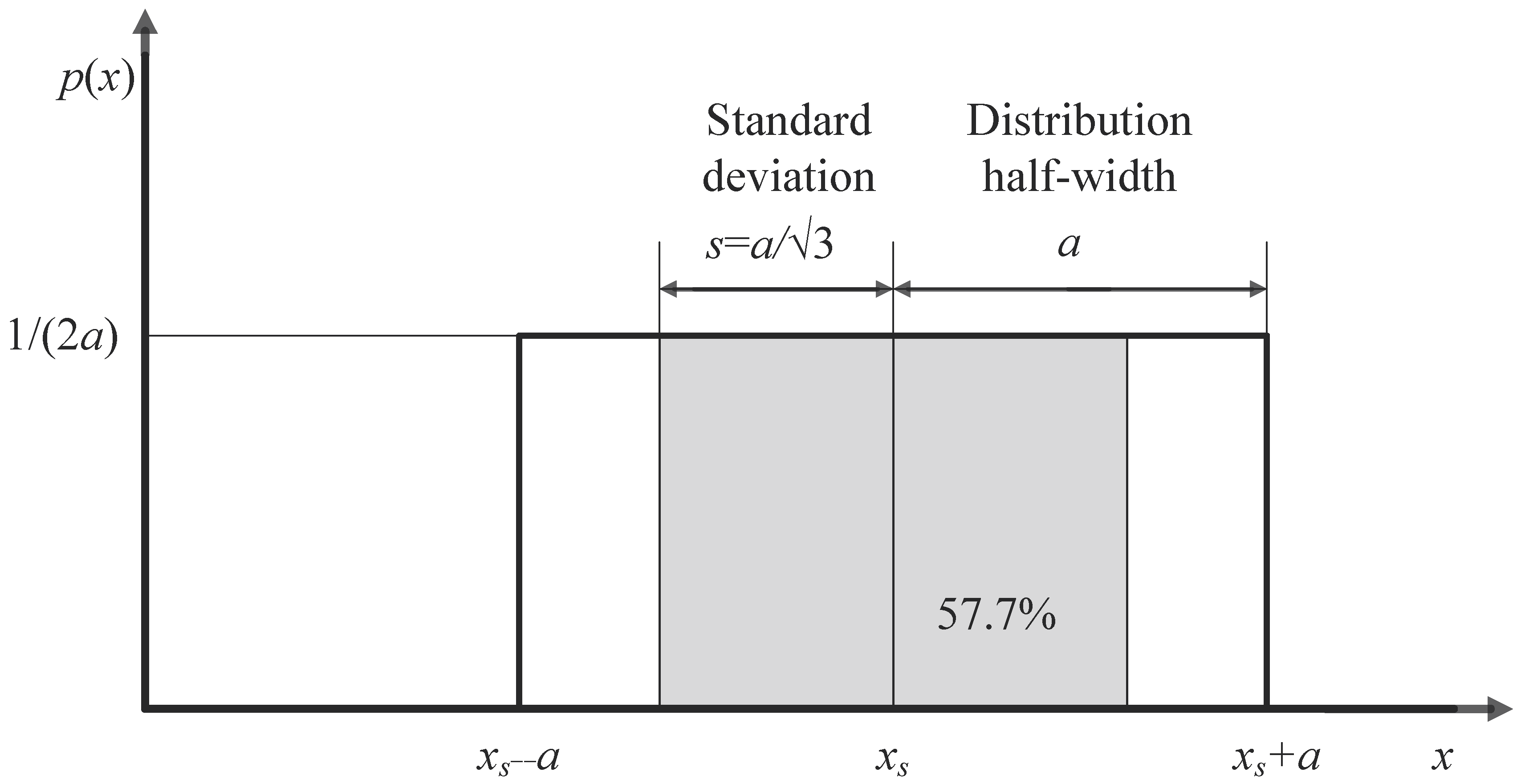
2.1. Measurement Uncertainty
2.2. Empirical Loss Function
2.3. DART Algorithm
2.4. Measurement Uncertainty of ML Model
3. Experimental Data, Comparative Analysis, and Discussion
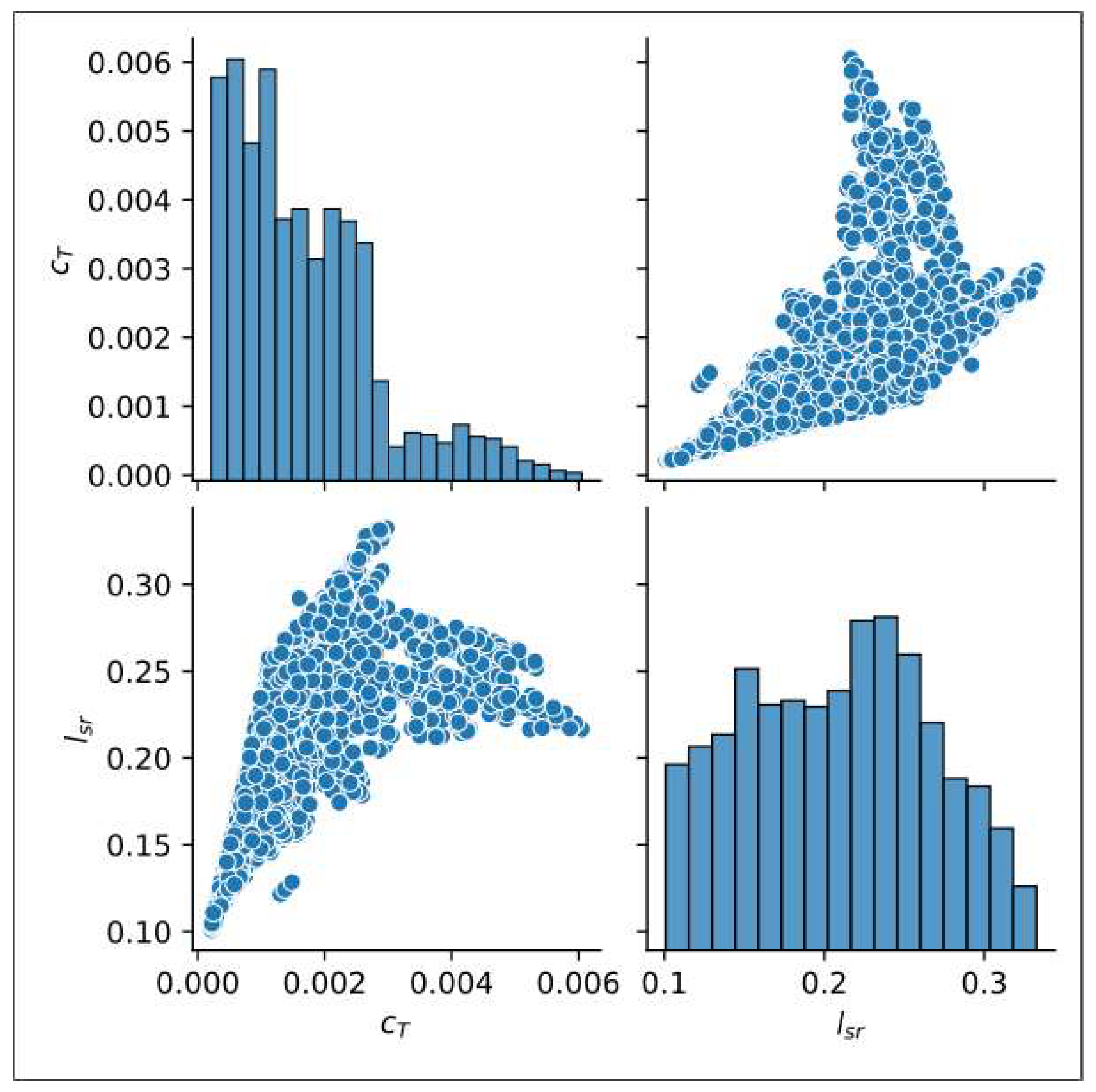
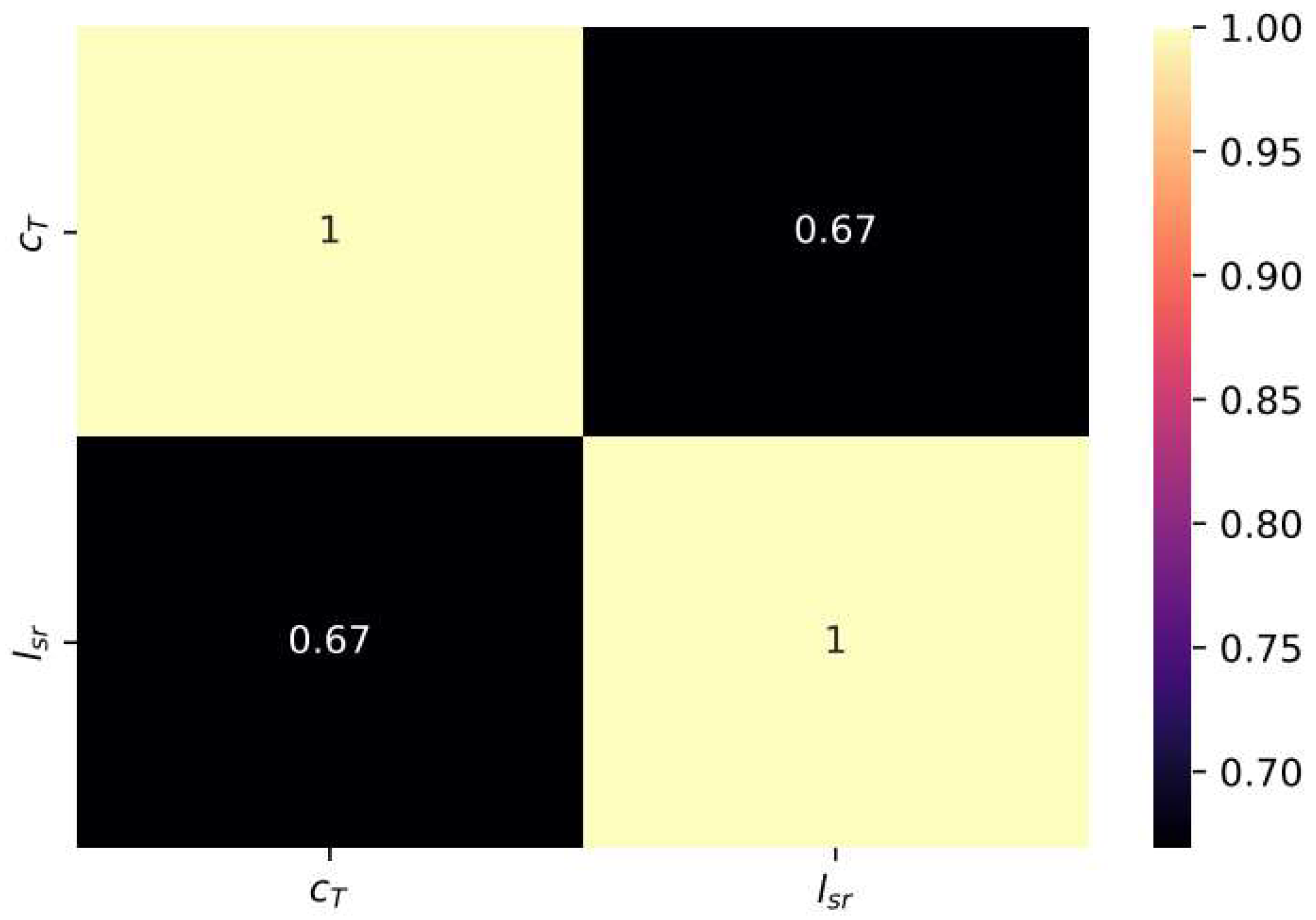
3.1. Experimental Data and Comparative Analysis
3.2. Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Prentice Hall: Hoboken, NJ, USA, 2010. [Google Scholar]
- Chellappa, R.; Theodoridis, S.; van Schaik, A. Advances in Machine Learning and Deep Neural Networks. Proc. IEEE 2021, 109, 607–611. [Google Scholar] [CrossRef]
- Yu, K.; Tan, L.; Mumtaz, S.; Al-Rubaye, S.; Al-Dulaimi, A.; Bashir, A.K.; Khan, F.A. Securing Critical Infrastructures: Deep-Learning-Based Threat Detection in IIoT. IEEE Commun. Mag. 2021, 59, 76–82. [Google Scholar] [CrossRef]
- Louridas, P.; Ebert, C. Machine Learning. IEEE Softw. 2016, 33, 110–115. [Google Scholar] [CrossRef]
- Benkhelifa, E.; Welsh, T.; Hamouda, W. A Critical Review of Practices and Challenges in Intrusion Detection Systems for IoT: Toward Universal and Resilient Systems. IEEE Commun. Surv. Tutor. 2018, 20, 3496–3509. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A Review of Machine Learning and Deep Learning Applications. In Proceedings of the 4th International Conference on Computing, Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018. [Google Scholar]
- Al-Turjman, F.; Zahmatkesh, H.; Shahroze, R. An overview of security and privacy in smart cities’ IoT communications. Trans. Emerg. Telecommun. Technol. 2022, 33, e3677. [Google Scholar] [CrossRef]
- Ahmed, M.; Cox, D.; Simpson, B.; Aloufi, A. ECU-IoFT: A Dataset for Analysing Cyber-Attacks on Internet of Flying Things. Appl. Sci. 2022, 12, 1990. [Google Scholar] [CrossRef]
- Fagbola, F.I.; Venter, H.S. Smart Digital Forensic Readiness Model for Shadow IoT Devices. Appl. Sci. 2022, 12, 730. [Google Scholar] [CrossRef]
- Ashfaq, Z.; Mumtaz, R.; Rafay, A.; Zaidi, S.M.H.; Saleem, H.; Mumtaz, S.; Shahid, A.; De Poorter, E.; Moerman, I. Embedded AI-Based Digi-Healthcare. Appl. Sci. 2022, 12, 519. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M. Applications of ML/DL in the management of smart cities and societies based on new trends in information technologies: A systematic literature review. Sustain. Cities Soc. 2022, 85, 104089. [Google Scholar] [CrossRef]
- Heidari, A.; Navimipour, N.J.; Unal, M.; Toumaj, S. The COVID-19 epidemic analysis and diagnosis using deep learning: A systematic literature review and future directions. Comput. Biol. Med. 2022, 141, 105141. [Google Scholar] [CrossRef] [PubMed]
- Ullah, Z.; Al-Turjman, F.; Mostarda, L.; Gagliardi, R. Applications of Artificial Intelligence and Machine learning in smart cities. Comput. Commun. 2020, 154, 313–323. [Google Scholar] [CrossRef]
- Hariri, R.H.; Fredericks, E.M.; Bowers, K.M. Uncertainty in big data analytics: Survey, opportunities and challenges. J. Big Data 2019, 6, 44. [Google Scholar] [CrossRef]
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN Comput. Sci. 2021, 2, 160. [Google Scholar] [CrossRef]
- Shende, M.K.; Salih, S.Q.; Bokde, N.D.; Scholz, M.; Oudah, A.Y.; Yaseen, Z.M. Natural Time Series Parameters Forecasting: Validation of the Pattern-Sequence-Based Forecasting (PSF) Algorithm; A New Python Package. Appl. Sci. 2022, 12, 6194. [Google Scholar] [CrossRef]
- Siddique, T.; Mahmud, M.S.; Keesee, A.M.; Ngwira, C.M.; Connor, H. A Survey of Uncertainty Quantification in Machine Learning for Space Weather Prediction. Geosciences 2022, 12, 27. [Google Scholar] [CrossRef]
- Walker, W.E.; Harremoës, P.; Rotmans, J.; van der Sluijs, J.P.; Van Asselt, M.; Janssen, P.; Von Krauss, M.K. Defining Uncertainty: A Conceptual Basis for Uncertainty Management in Model-Based Decision Support. Integr. Assess. 2003, 4, 5–17. [Google Scholar] [CrossRef]
- Siddique, T.; Mahmud, M.S. Classification of fNIRS Data Under Uncertainty: A Bayesian Neural Network Approach. In Proceedings of the IEEE International Conference on E-health Networking, Application & Services (HEALTHCOM), Shenzhen, China, 1–2 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–4. [Google Scholar]
- Van Asselt, M.; Rotmans, J. Uncertainty in integrated assessment modelling. Clim. Chang. 2002, 54, 75–105. [Google Scholar] [CrossRef]
- Cox, M.; O’Hagan, A. Meaningful expression of uncertainty in measurement. Accredit. Qual. Assur. 2022, 27, 19–37. [Google Scholar] [CrossRef]
- Yu, D.; Wu, J.; Wang, W.; Gu, B. Optimal performance of hybrid energy system in the presence of electrical and heat storage systems under uncertainties using stochastic p-robust optimization technique. Sustain. Cities Soc. 2022, 83, 103935. [Google Scholar] [CrossRef]
- Fangjie, G.; Jianwei, G.; Yi, Z.; Ningbo, H.; Haoyu, W. Community decision-makers’ choice of multi-objective scheduling strategy for integrated energy considering multiple uncertainties and demand response. Sustain. Cities Soc. 2022, 83, 103945. [Google Scholar] [CrossRef]
- Yan, Q.; Lin, H.; Li, J.; Ai, X.; Shi, M.; Zhang, M.; Gejirifu, D. Many-objective charging optimization for electric vehicles considering demand response and multi-uncertainties based on Markov chain and information gap decision theory. Sustain. Cities Soc. 2022, 78, 103652. [Google Scholar] [CrossRef]
- Volodina, V.; Challenor, P. The importance of uncertainty quantification in model reproducibility. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2021, 379, 20200071. [Google Scholar] [CrossRef]
- Levi, D.; Gispan, L.; Giladi, N.; Fetaya, E. Evaluating and Calibrating Uncertainty Prediction in Regression Tasks. Sensors 2022, 22, 5540. [Google Scholar] [CrossRef] [PubMed]
- Pires, C.; Barandas, M.; Fernandes, L.; Folgado, D.; Gamboa, H. Towards Knowledge Uncertainty Estimation for Open Set Recognition. Mach. Learn. Knowl. Extr. 2020, 2, 505–532. [Google Scholar] [CrossRef]
- Fotis, G.; Vita, V.; Ekonomou, L. Machine Learning Techniques for the Prediction of the Magnetic and Electric Field of Electrostatic Discharges. Electronics 2022, 11, 1858. [Google Scholar] [CrossRef]
- Fotis, G.; Vita, V.; Maris, T.I. Rise Time and Peak Current Measurement of ESD Current from Air Discharges with Uncertainty Calculation. Electronics 2022, 11, 2507. [Google Scholar] [CrossRef]
- Polužanski, V.; Kartalović, N.; Nikolić, B. Impact of Power Transformer Oil-Temperature on the Measurement Uncertainty of All-Acoustic Non-Iterative Partial Discharge Location. Materials 2021, 14, 1385. [Google Scholar] [CrossRef]
- Besharatifard, H.; Hasanzadeh, S.; Heydarian-Forushani, E.; Alhelou, H.H.; Siano, P. Detection and Analysis of Partial Discharges in Oil-Immersed Power Transformers Using Low-Cost Acoustic Sensors. Appl. Sci. 2022, 12, 3010. [Google Scholar] [CrossRef]
- ISO. Guide to the Expression of Uncertainty in Measuremen; ISO: Geneva, Switzerland, 2008. [Google Scholar]
- European Accreditation. EA-4/02 M (2013): Evaluation of the Uncertainty of Measurement in Calibration; European Accreditation: Geneva, Switzerland, 2013. [Google Scholar]
- Singapore Accreditation Council. Guidance Notes EL 001: Guidelines on the Evaluation and Expression of Measurement Uncertainty for Electrical Testing Field; Singapore Accreditation Council: Singapore, 2019.
- Shalev-Shwartz, S.; Wexler, Y. Minimizing the Maximal Loss: How and Why? arXiv 2016, arXiv:1602.01690. [Google Scholar]
- Wang, Q.; Ma, Y.; Zhao, K.; Tian, Y. A Comprehensive Survey of Loss Functions in Machine Learning. Ann. Data Sci. 2022, 9, 187–212. [Google Scholar] [CrossRef]
- Chicco, D.; Warrens, M.J.; Jurman, G. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Comput. Sci. 2021, 7, e623. [Google Scholar] [CrossRef] [PubMed]
- Friedman, J.H.; Meulman, J.J. Multiple additive regression trees with application in epidemiology. Stat. Med. 2003, 22, 1365–1381. [Google Scholar] [CrossRef] [PubMed]
- Rashmi, K.V.; Gilad-Bachrach, R. DART: Dropouts meet Multiple Additive Regression Trees. arXiv 2015, arXiv:1505.01866. [Google Scholar]
- Ahmed, Z.; Amizadeh, S.; Bilenko, M.; Carr, R.; Chin, W.-S.; Dekel, Y.; Dupre, X.; Eskarveskiy, V.; Filipi, S.; Finley, T.; et al. Machine learning at microsoft with ML.Net. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Count | 1799 | 1799 |
|---|---|---|
| cT[m/°C] | lsr[m] | |
| Average value | 0.001691 | 0.2083 |
| Standard deviation | 0.001168 | 0.0580 |
| Minimum | 0.000213 | 0.1008 |
| 25% | 0.000778 | 0.1594 |
| 50% | 0.001450 | 0.2132 |
| 75% | 0.002324 | 0.2516 |
| Maximum | 0.006055 | 0.3325 |
| Quantity | Estimate | Standard Uncertainty | Probability Distribution | Sensitivity Coefficient | Uncertainty Contribution |
| lsr | Predicted value by the ML model | 0.06 m | Uniform | 1.0 | 0.06 m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Polužanski, V.; Kovacevic, U.; Bacanin, N.; Rashid, T.A.; Stojanovic, S.; Nikolic, B. Application of Machine Learning to Express Measurement Uncertainty. Appl. Sci. 2022, 12, 8581. https://doi.org/10.3390/app12178581
Polužanski V, Kovacevic U, Bacanin N, Rashid TA, Stojanovic S, Nikolic B. Application of Machine Learning to Express Measurement Uncertainty. Applied Sciences. 2022; 12(17):8581. https://doi.org/10.3390/app12178581
Chicago/Turabian StylePolužanski, Vladimir, Uros Kovacevic, Nebojsa Bacanin, Tarik A. Rashid, Sasa Stojanovic, and Bosko Nikolic. 2022. "Application of Machine Learning to Express Measurement Uncertainty" Applied Sciences 12, no. 17: 8581. https://doi.org/10.3390/app12178581