
Evaluation and Recognition of Handwritten Chinese Characters Based on Similarities
Abstract
:1. Introduction
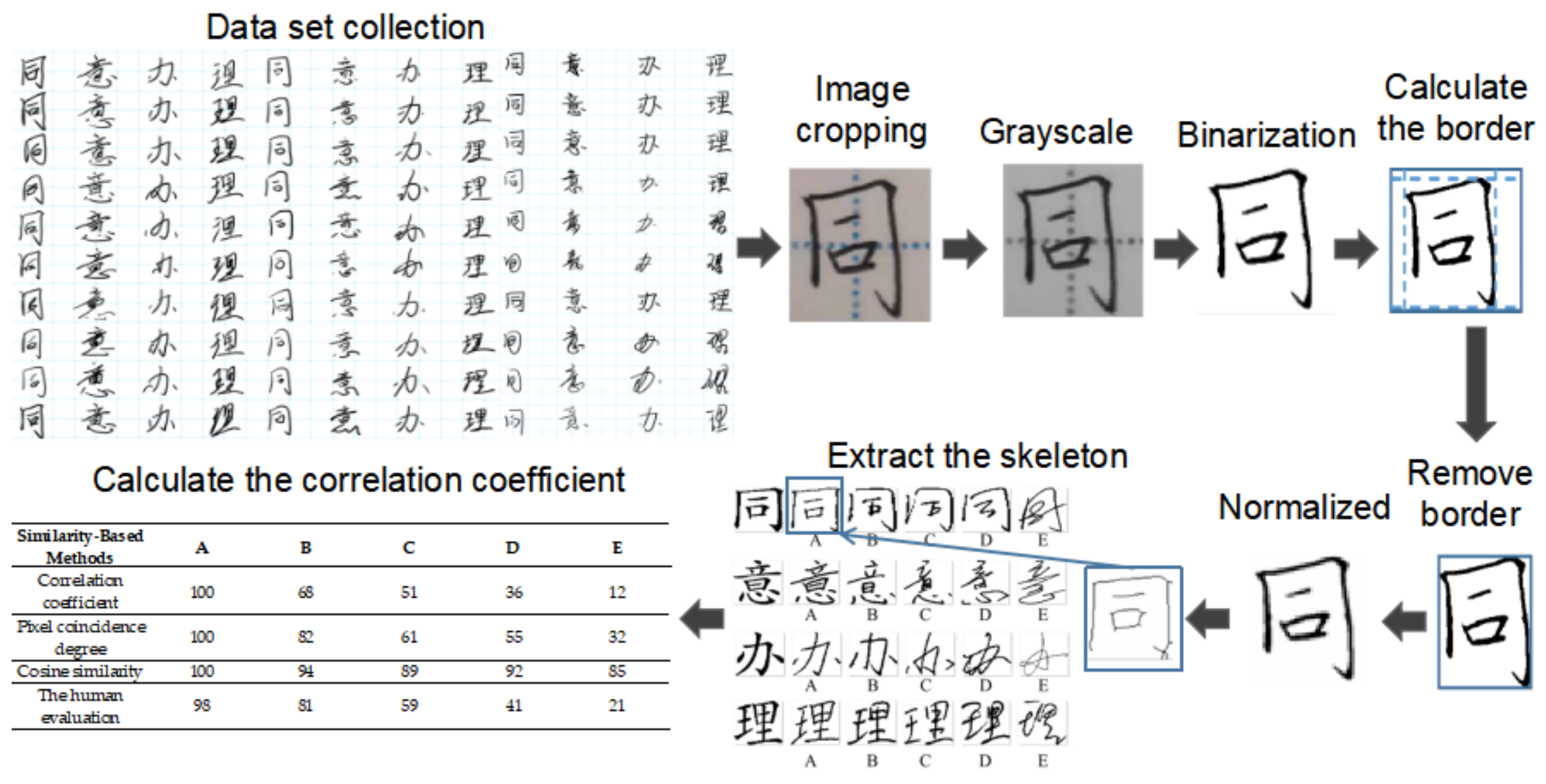
- In order to verify the accuracy of the similarity evaluation, this paper established a small “同意办理” (means “agree to proceed”) handwritten library written by 5 people as required. The library consists of 20 “同意办理” written by each person, with a total of 400 Chinese characters.
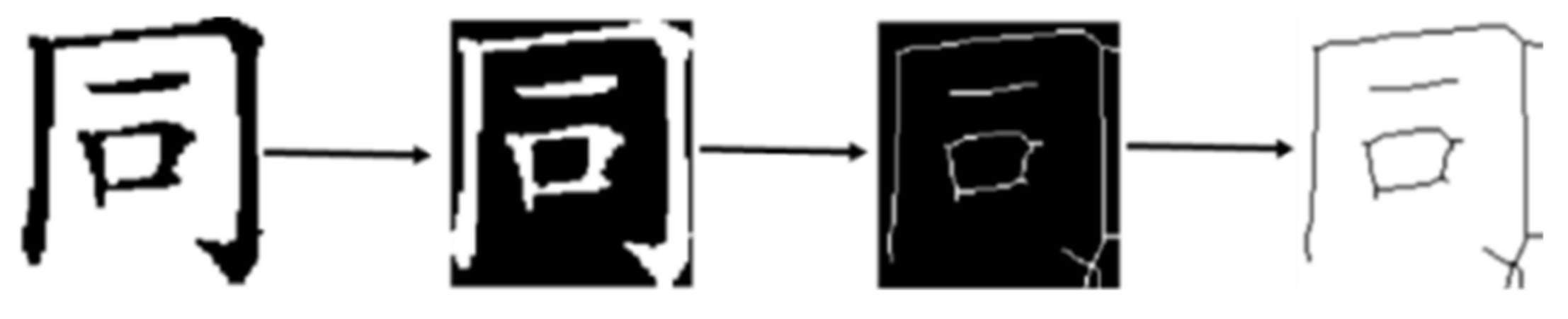
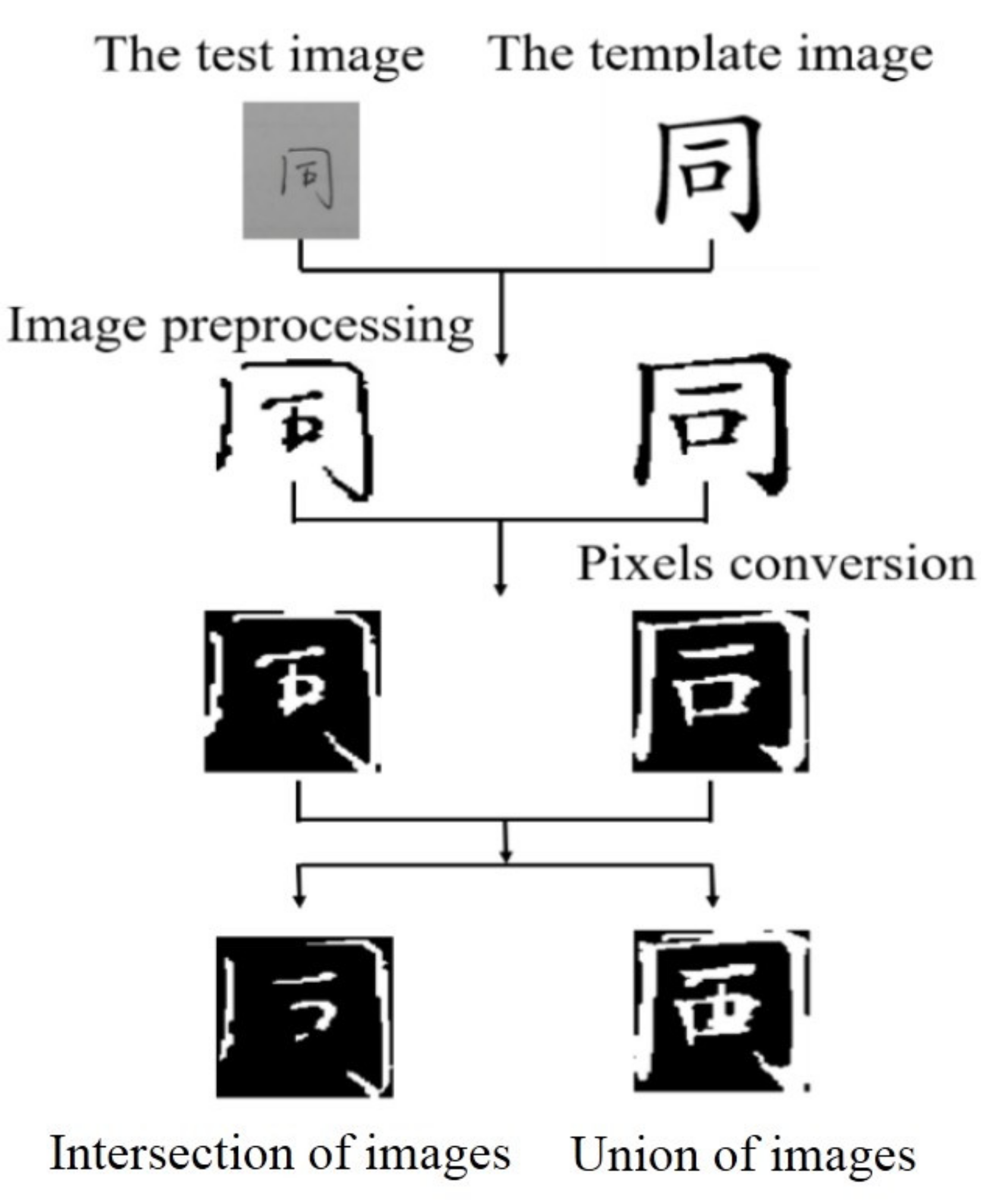
- In order to eliminate the influence of the stroke thickness of Chinese characters on the similarity calculation, this paper uses a parallel iterative Z-S skeleton extraction algorithm to extract the skeleton of the preprocessed Chinese character images. After scanning all the pixels in the binary image one by one, arithmetic and logical operations are performed on the eight neighborhoods of each pixel in order. Then, according to the result of arithmetic and logic operation, it is determined whether the pixels in the neighborhood need to be deleted. Finally, the skeleton of Chinese characters is obtained, which is beneficial to increase the diversity of similarity features.
- In order to quantitatively evaluate the roundness of handwritten Chinese characters, we applied three similarity coefficients: correlation coefficient, Tversky index, and cosine similarity. The similarity features between eight handwritten Chinese characters and template Chinese characters are extracted to distinguish characters written by different people with different normative levels, and an artificial neural network is used to identify the character content. Among them, the features required for cosine similarity calculation are extracted through concentric circle segmentation, texture features, grid features, and image projection. By comparing with the results of manual roundness evaluation, we found that the recognition accuracy rate can reach more than 90% based on the self-built handwritten Chinese character dataset.
2. Experimental Method
- Using image projection algorithm to cut out a single Chinese character from the written phrase or sentence.
- Using the weighted average method to grayscale the handwritten Chinese character image. Then, the best threshold is obtained through the peaks and troughs of the image grayscale histogram, and the Chinese character image is segmented by the global threshold segmentation method. After the binarization operation, filter processing is performed to eliminate the isolated points in the background of the Chinese character image.
- Eliminate the blank area of the Chinese character image by projection method to ensure that the position of the handwritten Chinese character image in the whole image is as consistent as possible with the position of the template Chinese character image. Then, we use the bicubic interpolation algorithm to unify the image size of Chinese characters, and scale all the handwritten Chinese characters images and template Chinese characters images after removing the borders into images with a size of 100 × 100.
- Using a parallel iterative algorithm Z-S skeleton extraction algorithm to complete the skeleton extraction of Chinese character images after preprocessing. Then, the selected template Chinese character images are processed in the same way to obtain a set of Chinese character images to be tested.
- Extract the similarity features of handwritten Chinese characters, evaluate the normative degree of handwritten Chinese characters based on the similarity features, and compare with manual evaluation.
2.1. Dataset Production
- The Chinese characters in the database are the most frequently used business words in banking or communication business. By testing these Chinese characters, it can reflect the effectiveness of the method proposed in this paper for content recognition and authentication.
- The samples in this dataset are intended to be used to evaluate the roundness of Chinese characters through similarity feature extraction, and the number of 400 samples is sufficient to verify the accuracy and reliability of the method.
- The writing style of sample Chinese characters varies greatly, which is convenient for manual judgment of writing quality. In this paper, the evaluation results of the neatness of Chinese writing should be compared with the results of manual evaluation.
2.2. Image Capturing and Skeleton Extraction
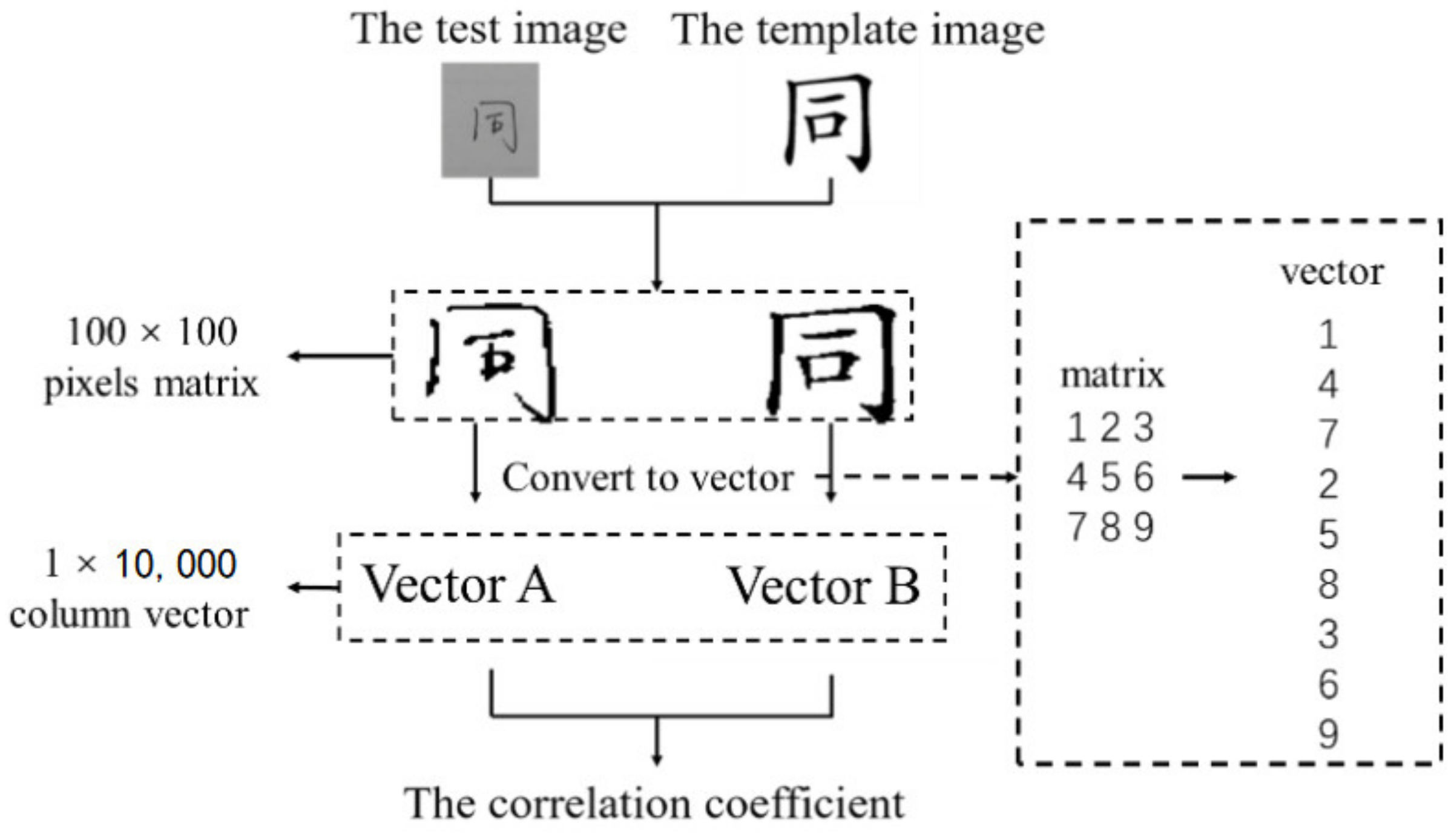
2.3. Correlation Coefficient
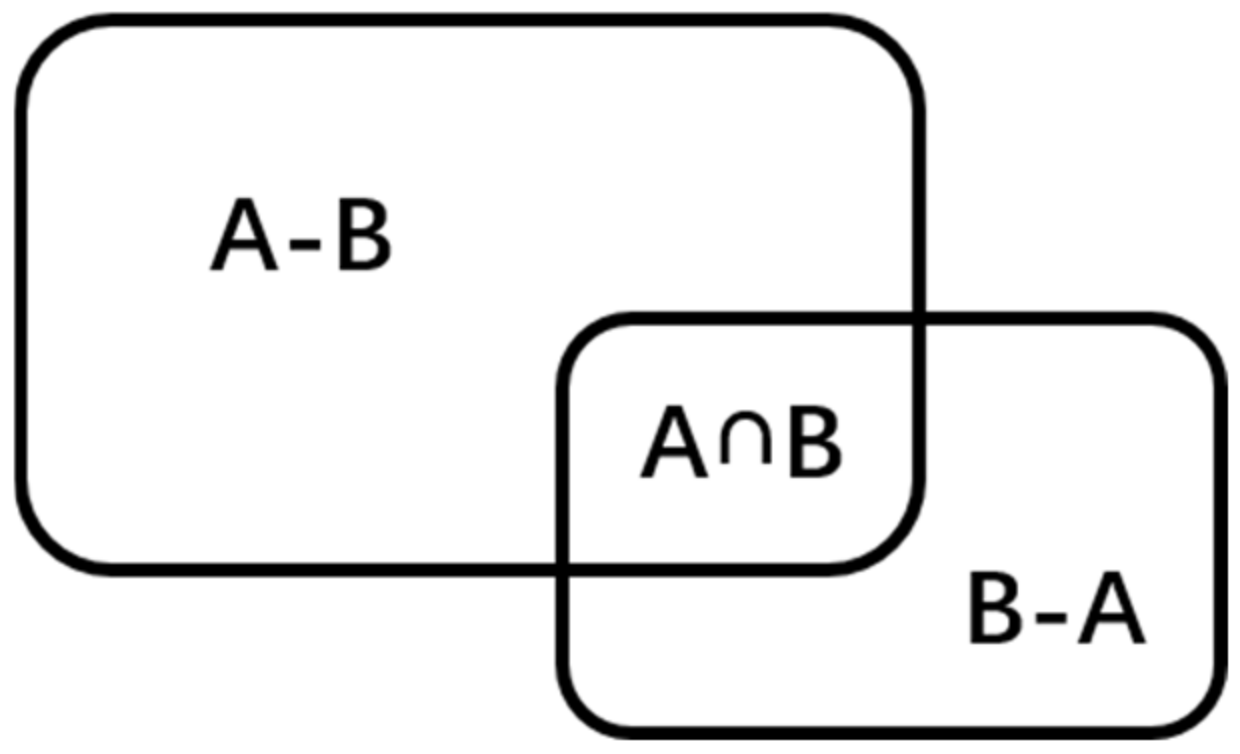
2.4. Pixel Coincidence Degree
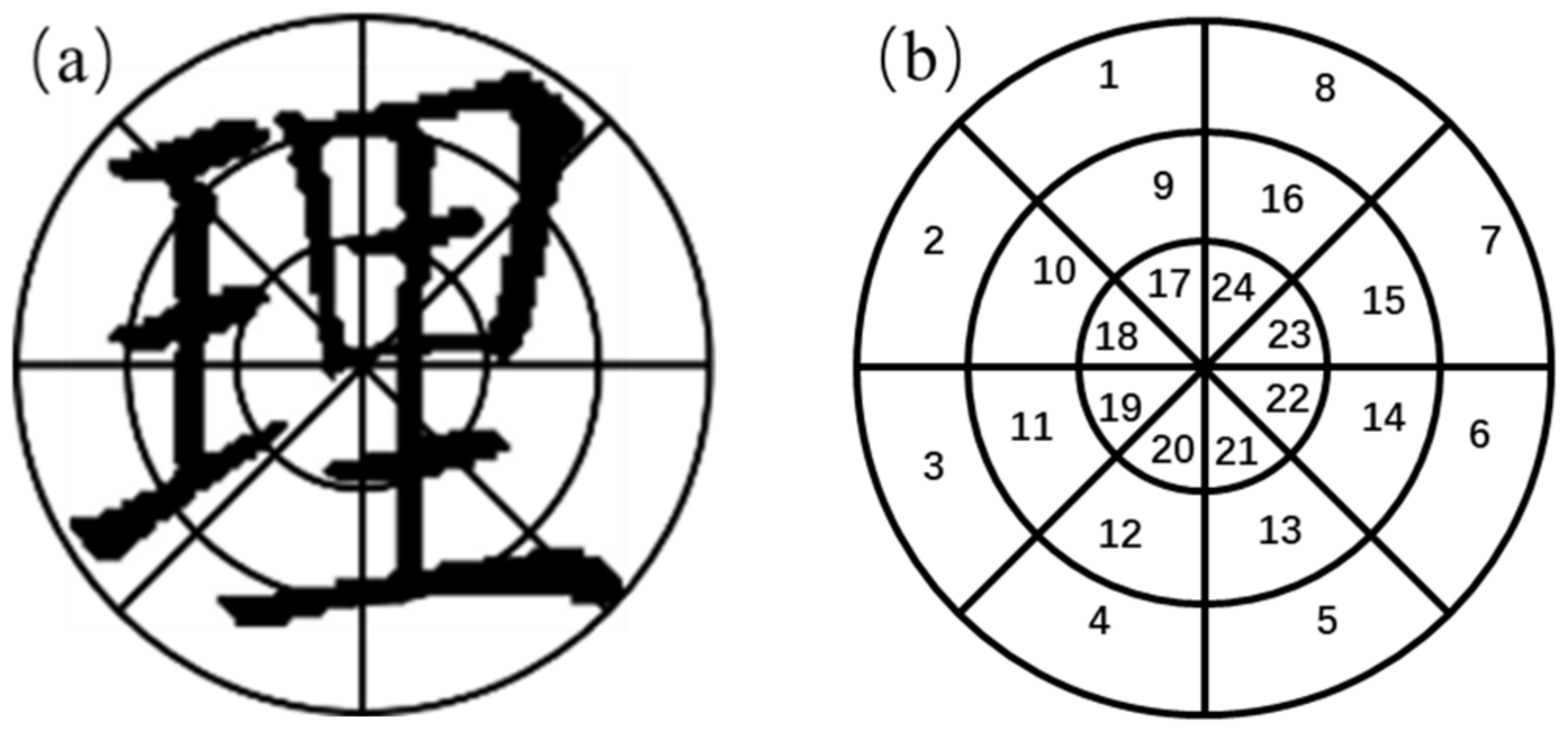
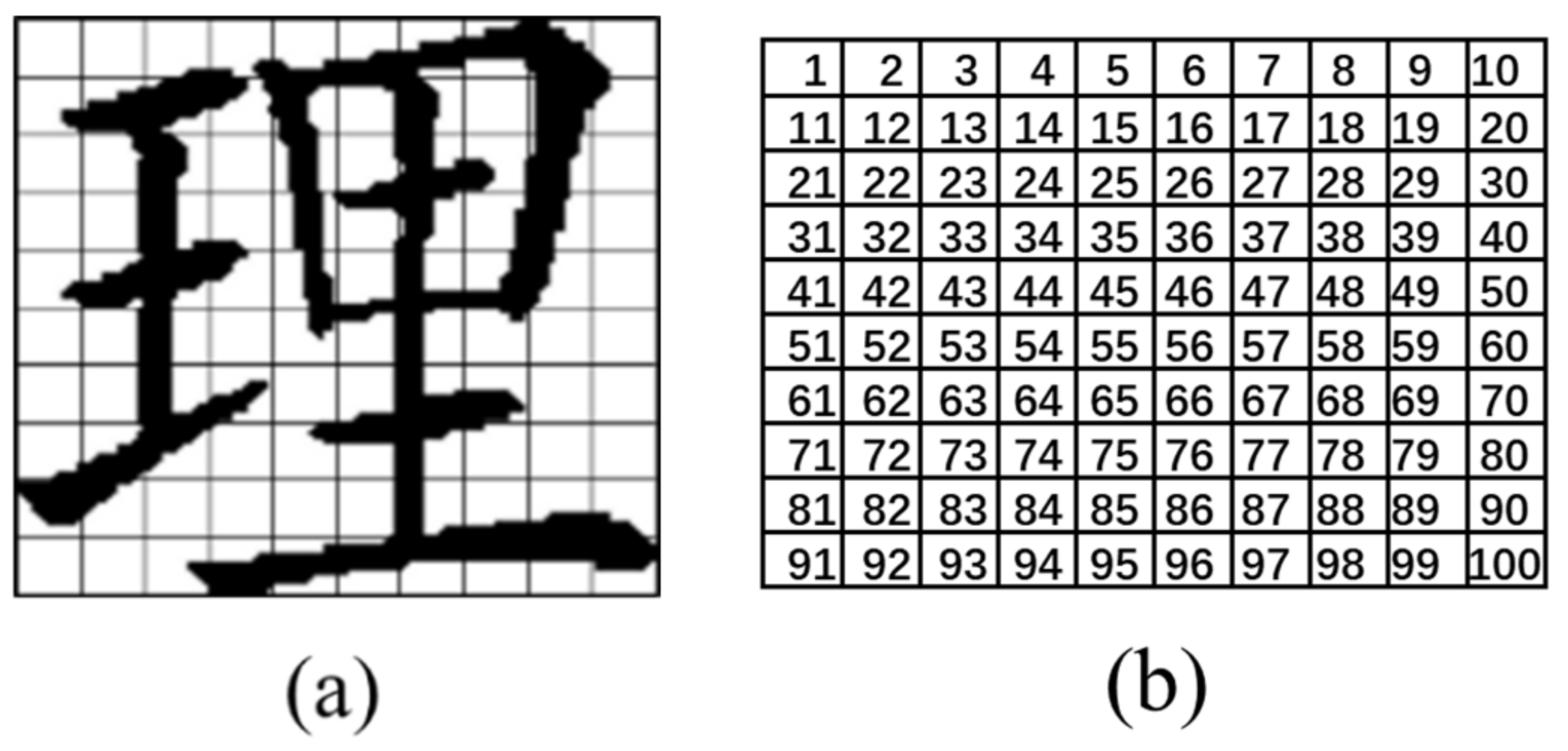
2.5. Cosine Similarity
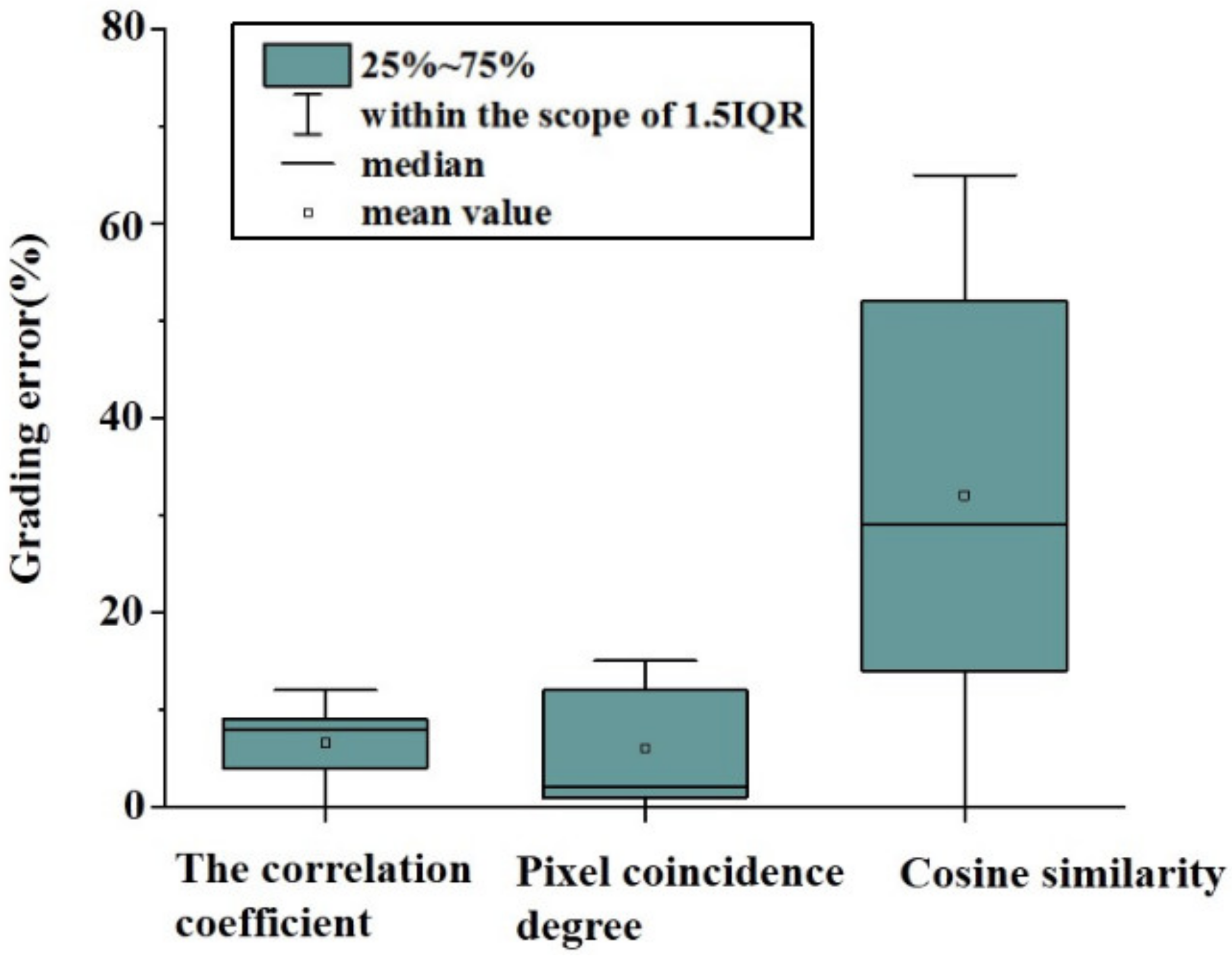
3. Results and Discussion
3.1. Correlation Coefficient Results
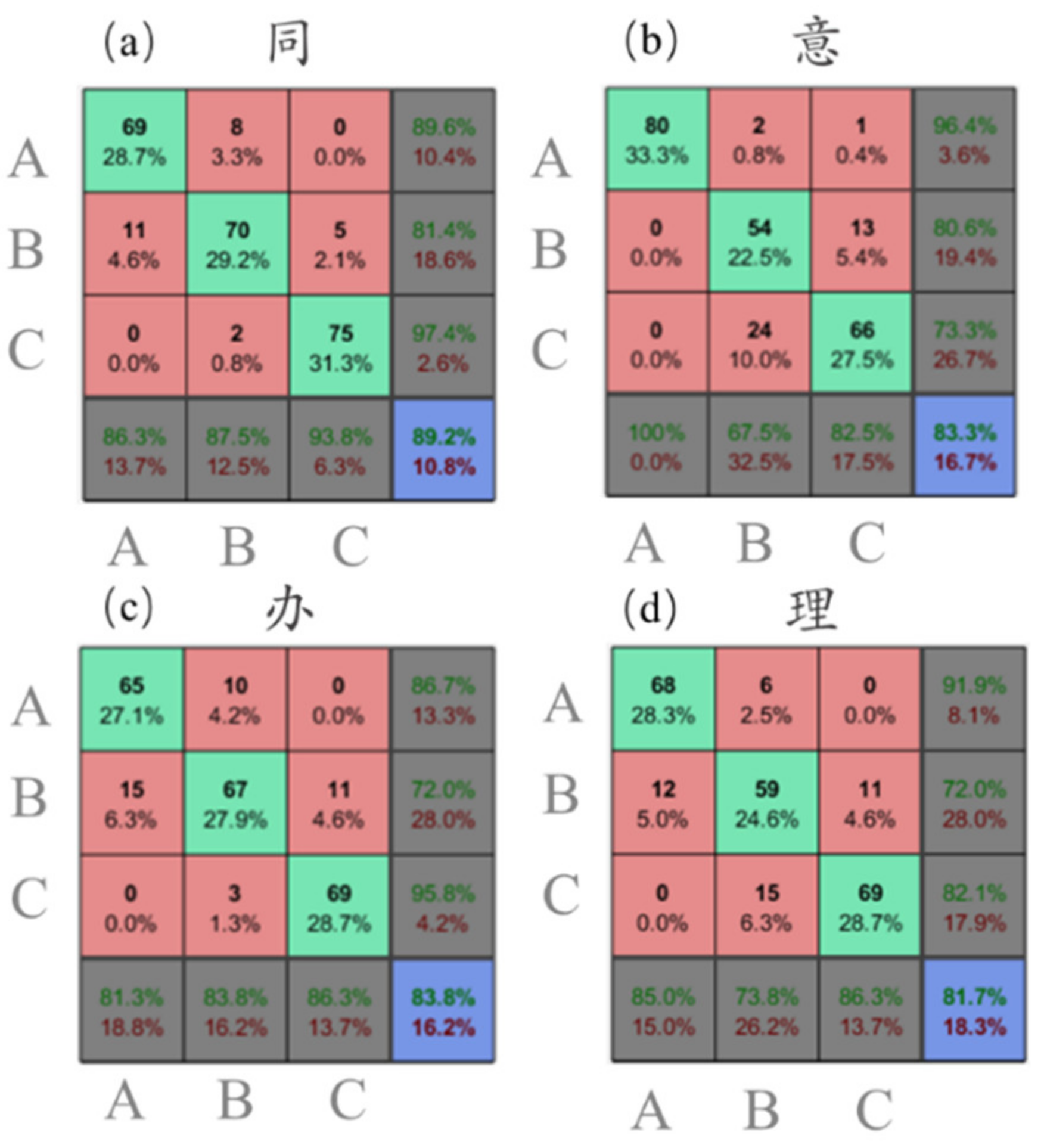
3.2. Pixel Coincidence Degree Results
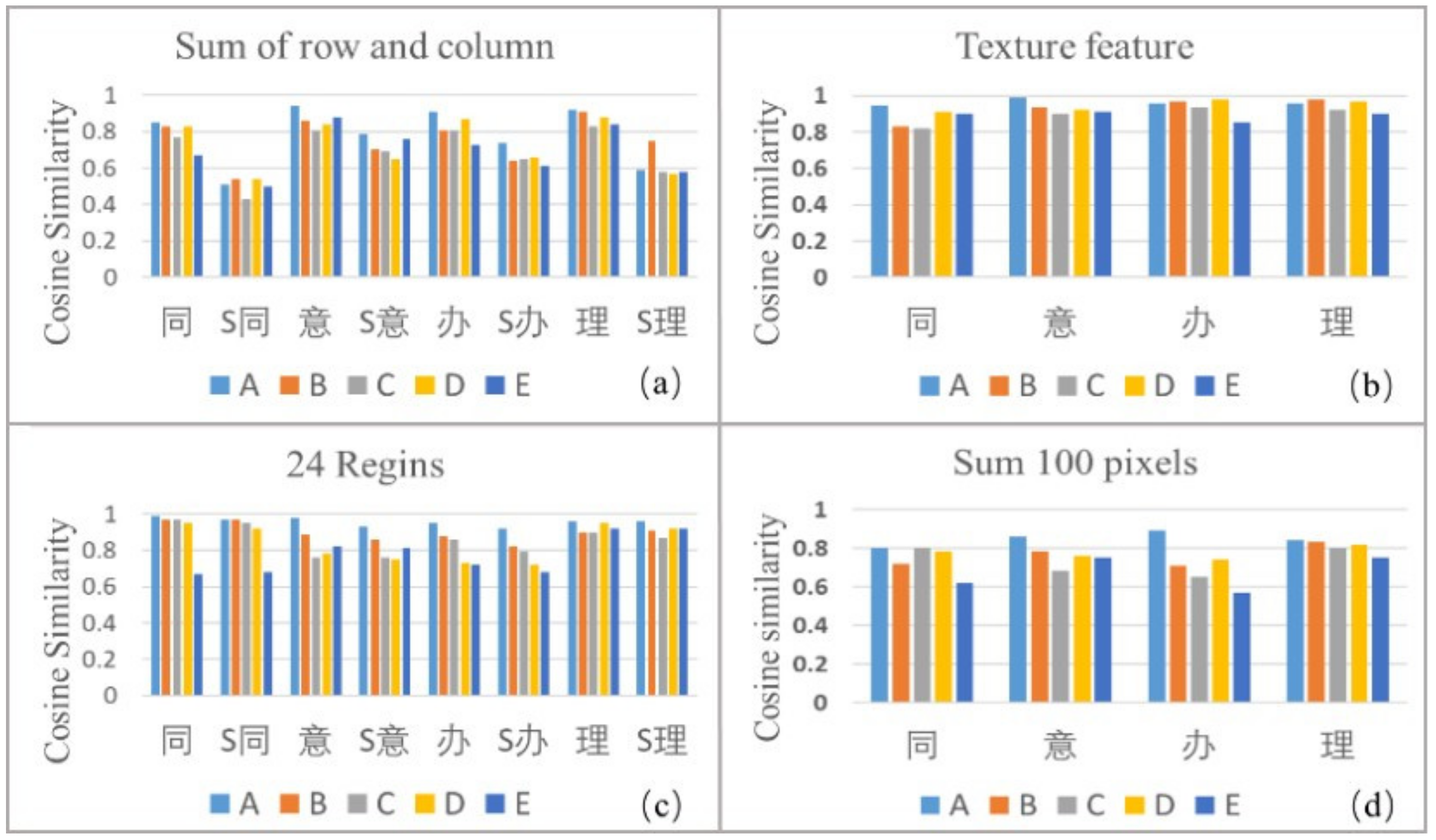
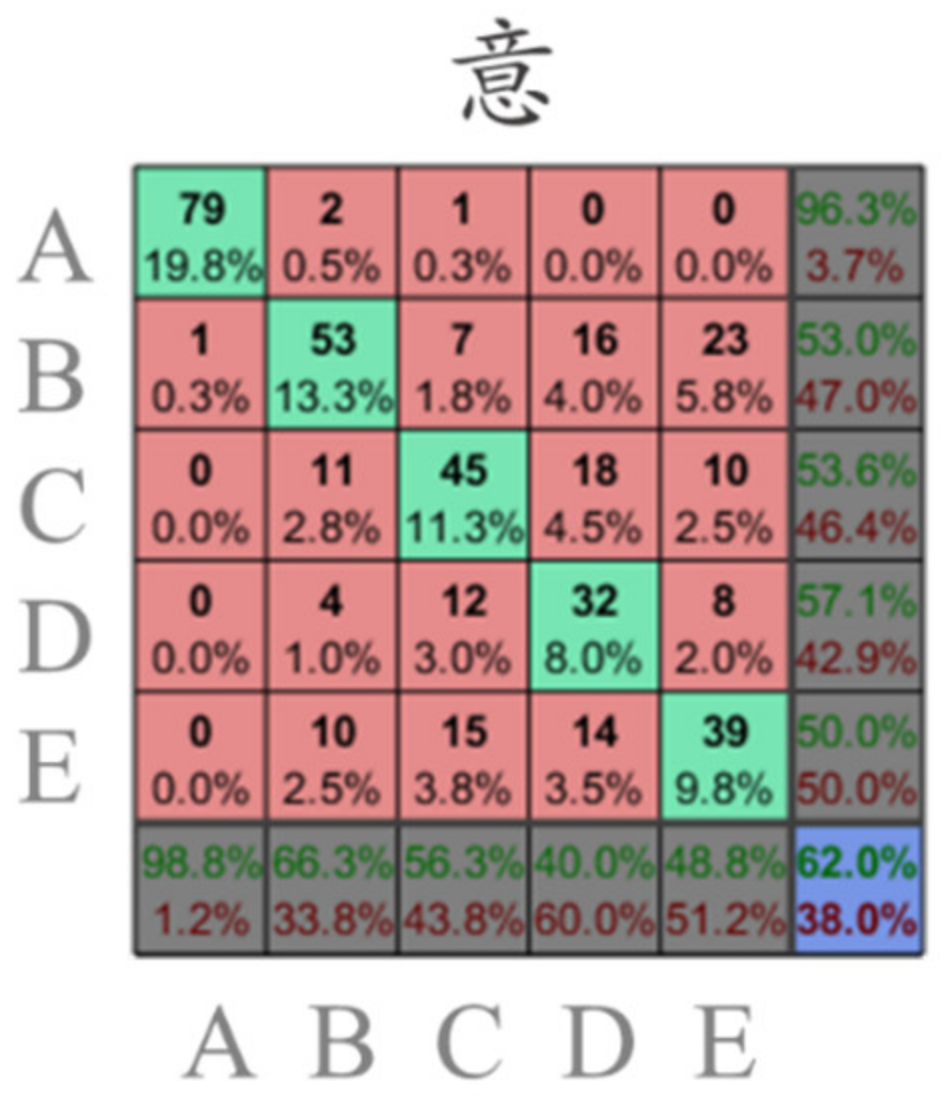
3.3. Cosine Similarity Results
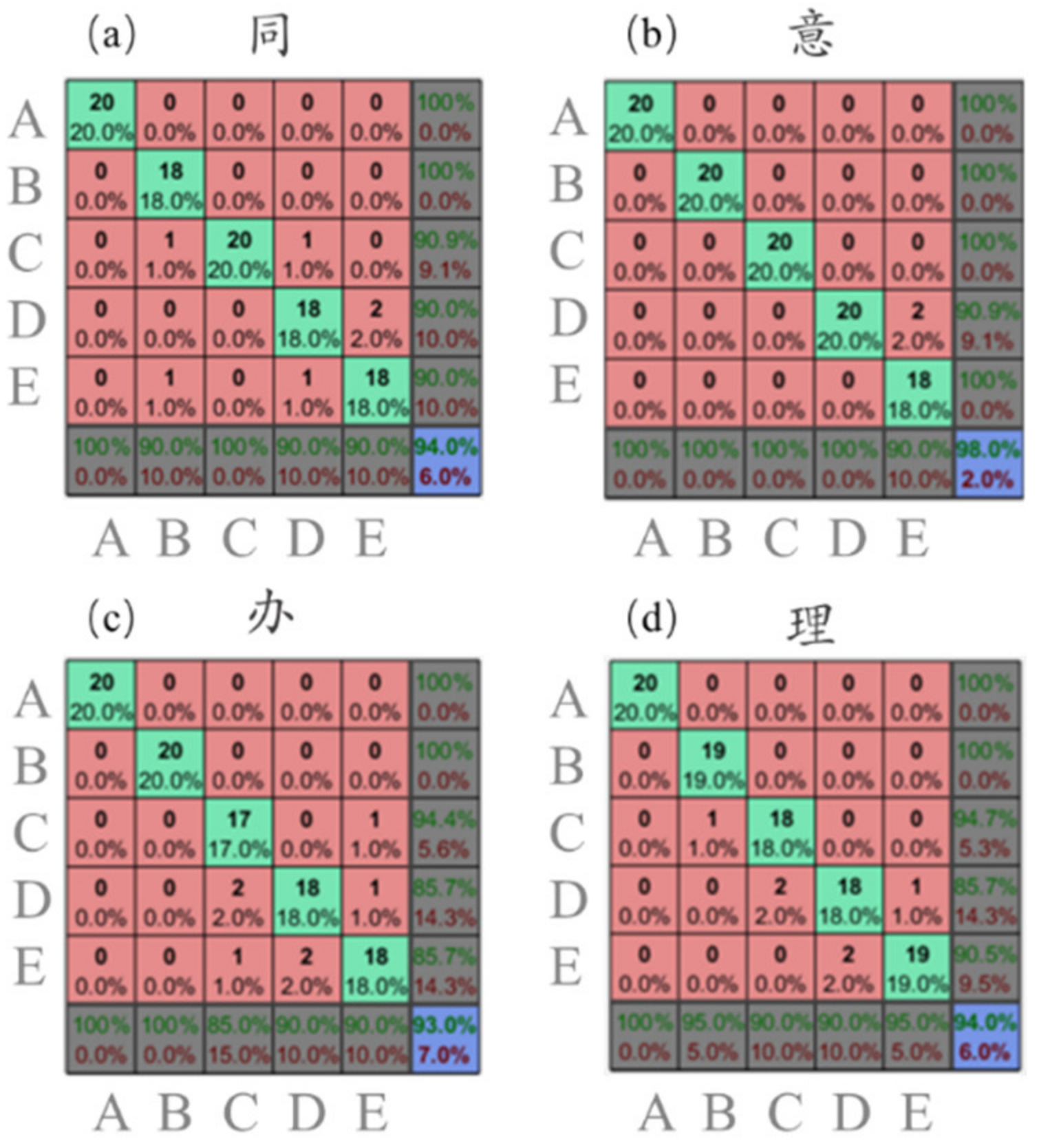
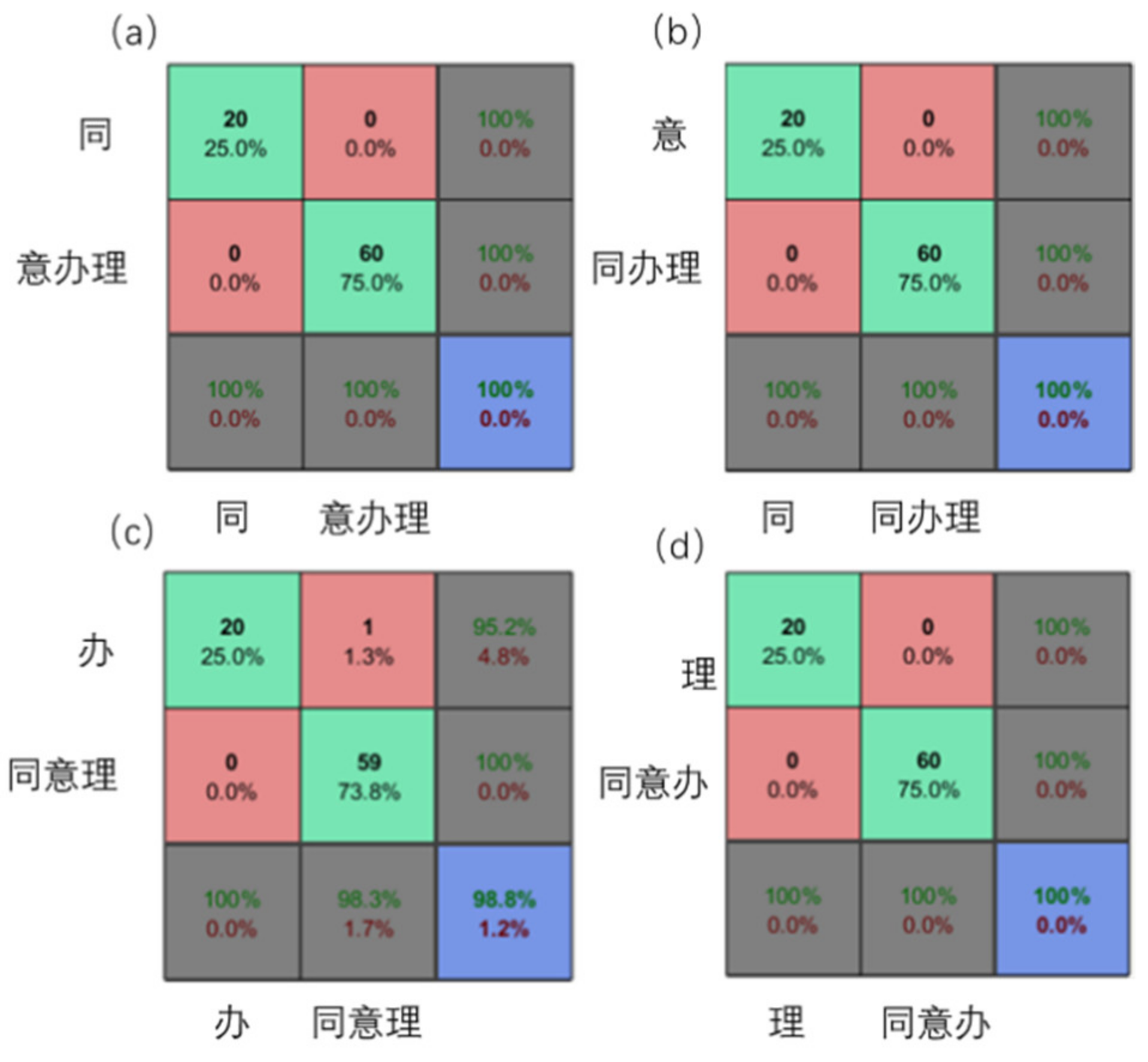
3.4. Neural Network Test Results
3.5. Comparison with Human Evaluations
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhou, M.K.; Zhang, X.Y.; Yin, F.; Liu, C.L. Discriminative Quadratic Feature Learning for Handwritten Chinese Character Recognition. Pattern Recognit. 2016, 49, 7–18. [Google Scholar] [CrossRef]
- Wang, Z.R.; Du, J. Writer Code Based Adaptation of Deep Neural Network for Offline Handwritten Chinese Text Recognition. In Proceedings of the 15th International Conference on Frontiers in Handwriting Recognition (ICFHR), Shenzhen, China, 23–26 October 2016; pp. 548–553. [Google Scholar]
- Cao, Z.; Lu, J.; Cui, S.; Zhang, C. Zero-Shot Handwritten Chinese Character Recognition with Hierarchical Decomposition Embedding. Pattern Recognit. 2020, 107, 107488. [Google Scholar] [CrossRef]
- Lin, H.; Zheng, X.; Wang, L.; Dai, L. Offline Handwritten Similar Chinese Character Recognition Based on Convolutional Neural Network and Random Elastic Transform. J. Lanzhou Inst. Technol. 2020, 27, 62–67. [Google Scholar]
- Li, Z.; Wu, Q.; Xiao, Y.; Jin, M.; Lu, H. Deep Matching Network for Handwritten Chinese Character Recognition. Pattern Recognit. 2020, 107, 107471. [Google Scholar] [CrossRef]
- Cermeno, A.P.E.; Siguenza, J.A. Simulation of Human Opinions About Calligraphy Aesthetic. In Proceedings of the 2nd International Conference on Artificial Intelligence, Modelling and Simulation (AIMS), Madrid, Spain, 18–20 November 2014; pp. 9–14. [Google Scholar]
- Kusetogullari, H.; Yavariabdi, A.; Cheddad, A.; Grahn, H.; Hall, J. ARDIS: A Swedish Historical Handwritten Digit Dataset. Neural Comput. Appl. 2020, 32, 16505–16518. [Google Scholar] [CrossRef]
- Cohen, G.; Afshar, S.; Tapson, J.; Van Schaik, A. EMNIST: Extending MNIST to Handwritten Letters. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2921–2926. [Google Scholar]
- Balaha, H.M.; Ali, H.A.; Saraya, M.; Badawy, M. A New Arabic Handwritten Character Recognition Deep Learning System (AHCR-DLS). Neural Comput. Appl. 2021, 33, 6325–6367. [Google Scholar] [CrossRef]
- Kusetogullari, H.; Yavariabdi, A.; Hall, J.; Lavesson, N. DIGITNET: A Deep Handwritten Digit Detection and Recognition Method Using a New Historical Handwritten Digit Dataset. Big Data Res. 2021, 23, 100182. [Google Scholar] [CrossRef]
- Li, F.; Shen, Q.; Li, Y.; Parthaláin, N. Mac Handwritten Chinese Character Recognition Using Fuzzy Image Alignment. Soft Comput. 2016, 20, 2939–2949. [Google Scholar] [CrossRef]
- Xu, L.; Wang, Y.; Li, X.; Pan, M. Recognition of Handwritten Chinese Characters Based on Concept Learning. IEEE Access 2019, 7, 102039–102053. [Google Scholar] [CrossRef]
- Ren, H.; Wang, W.; Liu, C. Recognizing Online Handwritten Chinese Characters Using RNNs with New Computing Architectures. Pattern Recognit. 2019, 93, 179–192. [Google Scholar] [CrossRef]
- Cai, J.; Peng, L.; Tang, Y.; Liu, C.; Li, P. TH-GAN: Generative Adversarial Network Based Transfer Learning for Historical Chinese Character Recognition. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Sydney, NSW, Australia, 20–25 September 2019; pp. 178–183. [Google Scholar]
- Lu, L.; Pei-Liang, Y.; Wei-Wei, S.; Jian-Wei, M. Similar Handwritten Chinese Character Recognition Based on CNN-SVM. ACM Int. Conf. Proc. Ser. 2017, 16–20. [Google Scholar] [CrossRef]
- Wang, Z.; Liao, M.; Maekawa, Z. A Study on Quantitative Evaluation of Calligraphy Characters. Comput. Technol. Appl. 2016, 7, 103–122. [Google Scholar]
- Xu, S.; Jiang, H.; Lau, F.C.M.; Pan, Y. Computationally Evaluating and Reproducing the Beauty of Chinese Calligraphy. IEEE Intell. Syst. 2012, 27, 63–72. [Google Scholar] [CrossRef]
- Wang, M.; Fu, Q.; Wang, X.; Wu, Z.; Zhou, M. Evaluation of Chinese Calligraphy by Using DBSC Vectorization and ICP Algorithm. Math. Probl. Eng. 2016, 2016, 4845092. [Google Scholar] [CrossRef]
- Zhang, W.; An, W.; Huang, D. Writing Process Restoration of Chinese Calligraphy Images Based on Skeleton Extraction. IOP Conf. Ser. Mater. Sci. Eng. 2019, 569, 032060. [Google Scholar] [CrossRef]
- Marti, U.V.; Bunke, H. A Full English Sentence Database for Off-Line Handwriting Recognition. In Proceedings of the 5th International Conference on Document Analysis and Recognition. (ICDAR), Bangalore, India, 22 September 1999; pp. 709–712. [Google Scholar]
- Grosicki, E.; El-Abed, H. ICDAR 2011-French Handwriting Recognition Competition. In Proceedings of the International Conference on Document Analysis and Recognition (ICDAR), Beijing, China, 18–21 September 2011; pp. 1459–1463. [Google Scholar]
- Cheddad, A.; Kusetogullari, H.; Hilmkil, A.; Sundin, L.; Yavariabdi, A.; Aouache, M.; Hall, J. SHIBR—The Swedish Historical Birth Records: A Semi-Annotated Dataset. Neural Comput. Appl. 2021, 33, 15863–15875. [Google Scholar] [CrossRef]
- Wüthrich, M.; Liwicki, M.; Fischer, A.; Indermühle, E.; Bunke, H.; Viehhauser, G.; Stolz, M. Language Model Integration for the Recognition of Handwritten Medieval Documents. In Proceedings of the 10th International Conference on Document Analysis and Recognition (ICDAR), Barcelona, Spain, 26–29 July 2009; pp. 211–215. [Google Scholar]
- Lavrenko, V.; Rath, T.M.; Manmatha, R. Holistic Word Recognition for Handwritten Historical Documents. In Proceedings of the 1st International Workshop on Document Image Analysis for Libraries-DIAL 2004, Palo Alto, CA, USA, 23–24 January 2004; pp. 278–287. [Google Scholar]
- Serrano, N.; Castro, F.; Juan, A. The RODRIGO Database. In Proceedings of the 7th International Conference on Language Resources and Evaluation LREC 2010, Valletta, Malta, 17–23 May 2010; pp. 2709–2712. [Google Scholar]
- Fischer, A.; Frinken, V.; Fornés, A.; Bunke, H. Transcription Alignment of Latin Manuscripts Using Hidden Markov Models. ACM Int. Conf. Proc. Ser. 2011, 29–36. [Google Scholar] [CrossRef]
- Pérez, D.; Tarazón, L.; Serrano, N.; Castro, F.; Ramos Terrades, O.; Juan, A. The GERMANA Database. In Proceedings of the 10th International Conference on Document Analysis and Recognition ICDAR 2009, Barcelona, Spain, 26–29 July 2009; pp. 301–305. [Google Scholar]
- Romero, V.; Fornés, A.; Serrano, N.; Sánchez, J.A.; Toselli, A.H.; Frinken, V.; Vidal, E.; Lladós, J. The ESPOSALLES Database: An Ancient Marriage License Corpus for off-Line Handwriting Recognition. Pattern Recognit. 2013, 46, 1658–1669. [Google Scholar] [CrossRef]
- Benesty, J.; Chen, J.; Huang, Y.; Cohen, I. Noise Reduction in Speech Processing; Springer: New York, NY, USA, 2009. [Google Scholar]
- Chang, Y.; Yang, D.; Guo, Y. Laser Ultrasonic Damage Detection in Coating-Substrate Structure via Pearson Correlation Coefficient. Surf. Coatings Technol. 2018, 353, 339–345. [Google Scholar] [CrossRef]
- Gragera, A.; Suppakitpaisarn, V. Relaxed Triangle Inequality Ratio of the Sørensen–Dice and Tversky Indexes. Theor. Comput. Sci. 2018, 718, 37–45. [Google Scholar] [CrossRef]
- Kunimoto, R.; Vogt, M.; Bajorath, J. Maximum Common Substructure-Based Tversky Index: An Asymmetric Hybrid Similarity Measure. J. Comput. Aided. Mol. Des. 2016, 30, 523–531. [Google Scholar] [CrossRef]
- Moujahid, D.; Elharrouss, O.; Tairi, H. Visual Object Tracking via the Local Soft Cosine Similarity. Pattern Recognit. Lett. 2018, 110, 79–85. [Google Scholar] [CrossRef]
- Roberti de Siqueira, F.; Robson Schwartz, W.; Pedrini, H. Multi-Scale Gray Level Co-Occurrence Matrices for Texture Description. Neurocomputing 2013, 120, 336–345. [Google Scholar] [CrossRef]
- Yang, P.; Yang, G. Feature Extraction Using Dual-Tree Complex Wavelet Transform and Gray Level Co-Occurrence Matrix. Neurocomputing 2016, 197, 212–220. [Google Scholar] [CrossRef]
- Liu, H.L.; Cao, X.W.; Xu, R.J.; Chen, N.Y. Independent Neural Network Modeling of Class Analogy for Classification Pattern Recognition and Optimization. Anal. Chim. Acta 1997, 342, 223–228. [Google Scholar] [CrossRef]
- Huang, K.; Yan, H. Off-Line Signature Verification Based on Geometric Feature Extraction and Neural Network Classification. Pattern Recognit. 1997, 30, 9–17. [Google Scholar] [CrossRef]
- Pradeep, J.; Srinivasan, E.; Himavathi, S. Diagonal Based Feature Extraction For Handwritten Character Recognition System Using Neural Network. In Proceedings of the 3rd International Conference on Electronics Computer Technology ICECT 2011, Kanyakumari, India, 8–10 April 2011; pp. 364–368. [Google Scholar]
- Wu, S.G.; Bao, F.S.; Xu, E.Y.; Wang, Y.X.; Chang, Y.F.; Xiang, Q.L. A Leaf Recognition Algorithm for Plant Classification Using Probabilistic Neural Network. In Proceedings of the 2007 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Giza, Egypt, 15–18 December 2007; pp. 11–16. [Google Scholar]
- Sun, R.; Lian, Z.; Tang, Y.; Xiao, J. Aesthetic Visual Quality Evaluation of Chinese Handwritings. In Proceedings of the 24th International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires Argentina, 25–31 July 2015; pp. 2510–2516. [Google Scholar]
- Rajashekararadhya, S.V.; Vanaja Ranjan, P. Neural Network Based Handwritten Numeral Recognition of Kannada and Telugu Scripts. In Proceedings of the IEEE Region 10 International Conference TENCON, Hyderabad, India, 19–21 November 2008; pp. 1–5. [Google Scholar]
- Chen, P.C.; Pavlidis, T. Segmentation by Texture Using a Co-Occurrence Matrix and a Split-and-Merge Algorithm. Comput. Graph. Image Process. 1979, 10, 172–182. [Google Scholar] [CrossRef]
- Tversky, A. Features of Similarity. Psychol. Rev. 1977, 84, 327–352. [Google Scholar] [CrossRef]
- Koo, J.H.; Cho, S.W.; Baek, N.R.; Lee, Y.W.; Park, K.R. A Survey on Face and Body Based Human Recognition Robust to Image Blurring and Low Illumination. Mathematics 2022, 10, 1522. [Google Scholar] [CrossRef]
- Wang, M.; Yin, X.; Zhu, Y. Representation Learning and Pattern Recognition in Cognitive Biometrics: A Survey. Sensors 2022, 22, 5111. [Google Scholar] [CrossRef]
- Adjabi, I.; Ouahabi, A.; Benzaoui, A.; Taleb-Ahmed, A. Past, Present, and Future of Face Recognition: A Review. Electronics 2020, 9, 1188. [Google Scholar] [CrossRef]
- Liu, L.; Huang, L.; Yin, F.; Chen, Y. Offline Signature Verification Using a Region Based Deep Metric Learning Network. Pattern Recognit. 2021, 118, 108009. [Google Scholar] [CrossRef]
- Yan, W.; Guo, M.; Wang, Z.; Zhang, J. Gabor-Based Feature Extraction towards Chinese Character Writing Quality Evaluation. Comput. Technol. Dev. 2020, 30, 92–96. [Google Scholar]
- Liu, H.-Q. Aesthetic Evaluation of Poetry Translation Based on the Perspective of Xu Yuanchong’s Poetry Translation Theories with Intuitionistic Fuzzy Information. Int. J. Knowl.-Based Intell. Eng. Syst. 2019, 23, 303–309. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhao, P.; Zhao, F.; Mu, X.; Bai, K.; You, X. Survey on Abstractive Text Summarization Technologies Based on Deep Learning. Comput. Eng. 2021, 47, 11–21. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Language | Number of Samples | Application | Application Limitations |
|---|---|---|---|---|
| IAM | English | 1539 | Text content recognition | Suitable for a single style of writing. |
| RIMES | English | 12,723 | Text content recognition | It can only be used for e-mail message identification. |
| SHIBR | Swedish | 15,000 | Text content recognition | It only contains words from Swedish historical documents. |
| Parzival | Middle High German | 45 | Text content recognition | Most of the content is poetry, which is rarely seen in daily life. |
| George Washington | English | 20 | Text content recognition | The number of samples in the dataset is too small. |
| Saint Gall | Carolingian | 60 | Text content recognition | 21.54% of the words in the dataset are abbreviations, and hyphens and punctuation marks cannot be recognized. |
| Germana | Spanish | 764 | Text content recognition | Scribbled content is not recognizable. |
| Esposalles | Spanish | 173 | Text content recognition | It is mainly used for the study of social relations and is not good for character recognition. |
| Rodrigo | Spanish | 853 | Text content recognition | It is mainly used for the study of local social relations. |
| This Paper | Chinese | 400 | Text content recognition, authorized signature recognition | It is only suitable for the processing of Chinese bank communication business. |
| Correlation Coefficient | A | B | C | D | E |
|---|---|---|---|---|---|
| 同 | 0.44 | 0.36 | 0.29 | 0.23 | 0.01 |
| 意 | 0.32 | 0.19 | 0.16 | 0.12 | 0.08 |
| 办 | 0.47 | 0.24 | 0.18 | 0.09 | 0.03 |
| 理 | 0.39 | 0.34 | 0.20 | 0.17 | 0.08 |
| Correlation Coefficient | A | B | C | D | E |
|---|---|---|---|---|---|
| 同 | 0.36 | 0.34 | 0.26 | 0.24 | 0.10 |
| 意 | 0.31 | 0.20 | 0.17 | 0.15 | 0.14 |
| 办 | 0.35 | 0.22 | 0.17 | 0.15 | 0.05 |
| 理 | 0.35 | 0.34 | 0.25 | 0.24 | 0.15 |
| Methods of Classification | Accuracy (%) | |||
|---|---|---|---|---|
| 同 | 意 | 办 | 理 | |
| BP | 94 | 98 | 93 | 94 |
| SVM | 69 | 72 | 76 | 69 |
| K-NN | 65 | 68 | 74 | 62 |
| CNN | 98.6 | 92.9 | 91.4 | 98.6 |
| Similarity-Based Methods | A | B | C | D | E |
|---|---|---|---|---|---|
| Correlation coefficient | 100 | 68 | 51 | 36 | 12 |
| Pixel coincidence degree | 100 | 82 | 61 | 55 | 32 |
| Cosine similarity | 100 | 94 | 89 | 92 | 85 |
| The human evaluation | 98 | 81 | 59 | 41 | 21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Zhang, X.; Fu, B.; Zhan, Z.; Sun, H.; Li, L.; Zhang, G. Evaluation and Recognition of Handwritten Chinese Characters Based on Similarities. Appl. Sci. 2022, 12, 8521. https://doi.org/10.3390/app12178521
Zhao Y, Zhang X, Fu B, Zhan Z, Sun H, Li L, Zhang G. Evaluation and Recognition of Handwritten Chinese Characters Based on Similarities. Applied Sciences. 2022; 12(17):8521. https://doi.org/10.3390/app12178521
Chicago/Turabian StyleZhao, Yuliang, Xinyue Zhang, Boya Fu, Zhikun Zhan, Hui Sun, Lianjiang Li, and Guanglie Zhang. 2022. "Evaluation and Recognition of Handwritten Chinese Characters Based on Similarities" Applied Sciences 12, no. 17: 8521. https://doi.org/10.3390/app12178521