
Adherence Improves Cooperation in Sequential Social Dilemmas

{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Preliminaries and Backgrounds
2.1. Partially Observable Markov Games
2.2. Sequential Social Dilemmas
- : mutual cooperation is preferred to mutual defection.
- : mutual cooperation is preferred to being exploited by a defector.
- : mutual cooperation is preferred to an equal probability of unilateral cooperation and defection.
- : exploiting a cooperator is preferred over mutual cooperation.
- : mutual defection is preferred over being exploited.
2.3. Multi-Agent Reinforcement Learning
3. Method
3.1. Overview
- Adherence evaluation: To cooperate better, each agent needs to understand the behavior of other agents better and judge whether it is adherent before deciding to cooperate. For knowing the adherence of other agents, it is necessary to calculate their adherence value concretely. Therefore, in Section 3.2, we illustrate how the adherence is calculated.
- Adherence evaluation model: The premise of adherence is to know each other’s behavior, but agents do not have the right to access the actions of other agents, so we set that agents need to predict the behaviors of other agents. In order to know other agents, we equip each agent with an adherence evaluation model (AEM). The model can be used not only to guide the behavior of the agent owner, but also to predict the next actions of other agents. The detailed introduction of the model is in Section 3.3.
- Reward design: Based on the above two parts, we can design the rewards for agents. In the method, the designed reward will be handed over to the agent for training, which can transform the dilemma state of SSDs into a cooperative state. The calculation of the reward is divided into two steps. The first step is to calculate the adherence value through predictions, and the second step is to reward the corresponding agent based on the adherence.
3.2. Adherence Evaluation
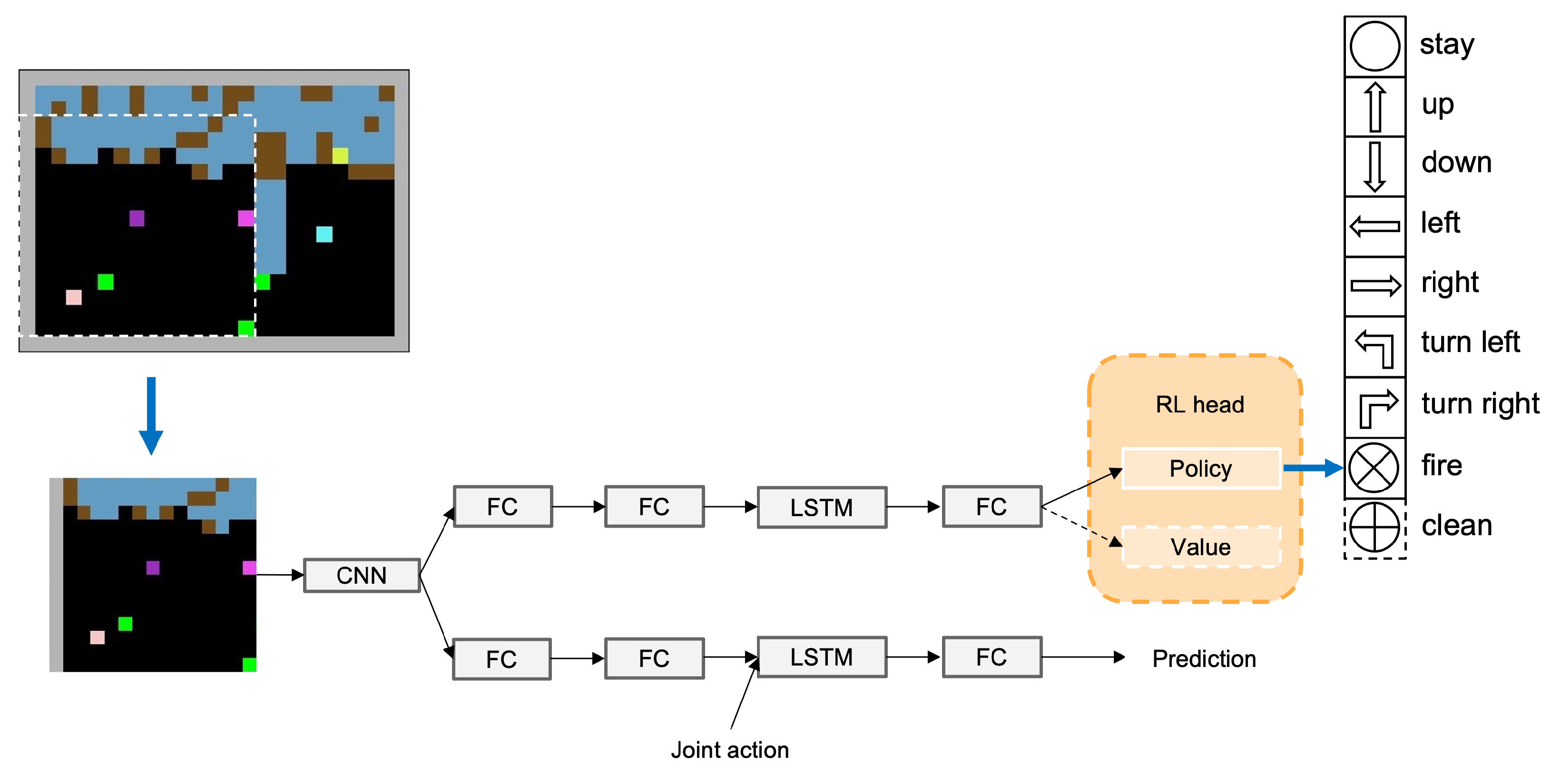
3.3. Adherence Evaluation Model
| Algorithm 1 Evaluation of j’s adherence value |
| Input:N, agent set |
| , agent j’s observation of the state at time t |
| p, agent j’s policy |
| , agent k’s action set T |
| , agent k’s action at time t |
| Output:, the overall adherence value of all other agents |
| 1: |
| 2: for each agent do |
| 3: if k is not j then |
| 4: |
| 5: |
| 6: for each do |
| 7: Replace counterfactual action, calculate marginal policy |
| 8: end for |
| 9: Calculate j’s adherence to k |
| 10: end if |
| 11: Calculate j’s total adherence reward |
| 12: end for |
| 13: |
| 14: return |
3.4. Reward Design
3.5. Algorithm Optimization
4. Experiment
4.1. Environment
4.1.1. Cleanup
4.1.2. Harvest
4.2. Social Outcome Metrics
4.3. Results and Analysis
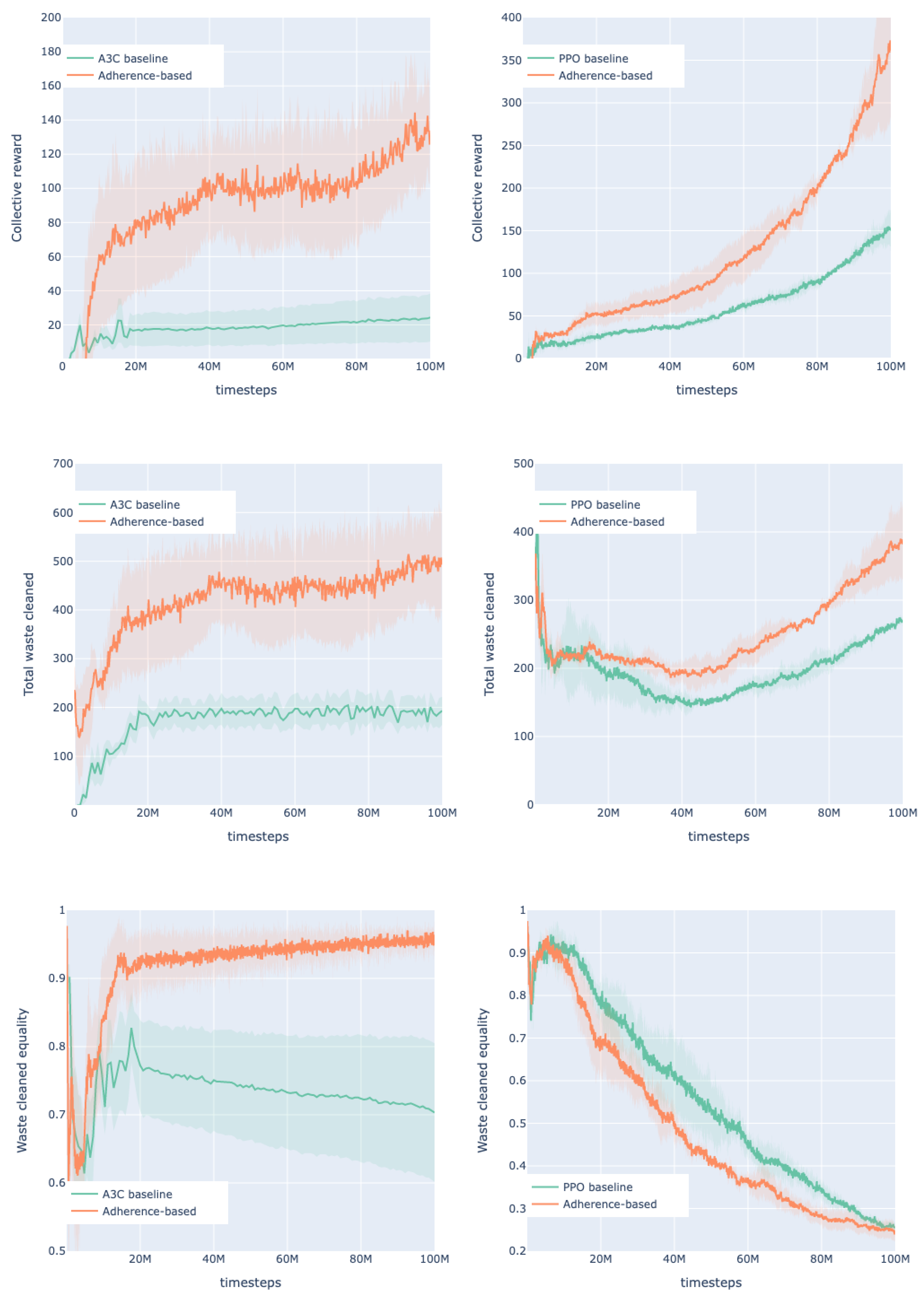
4.3.1. Cleanup
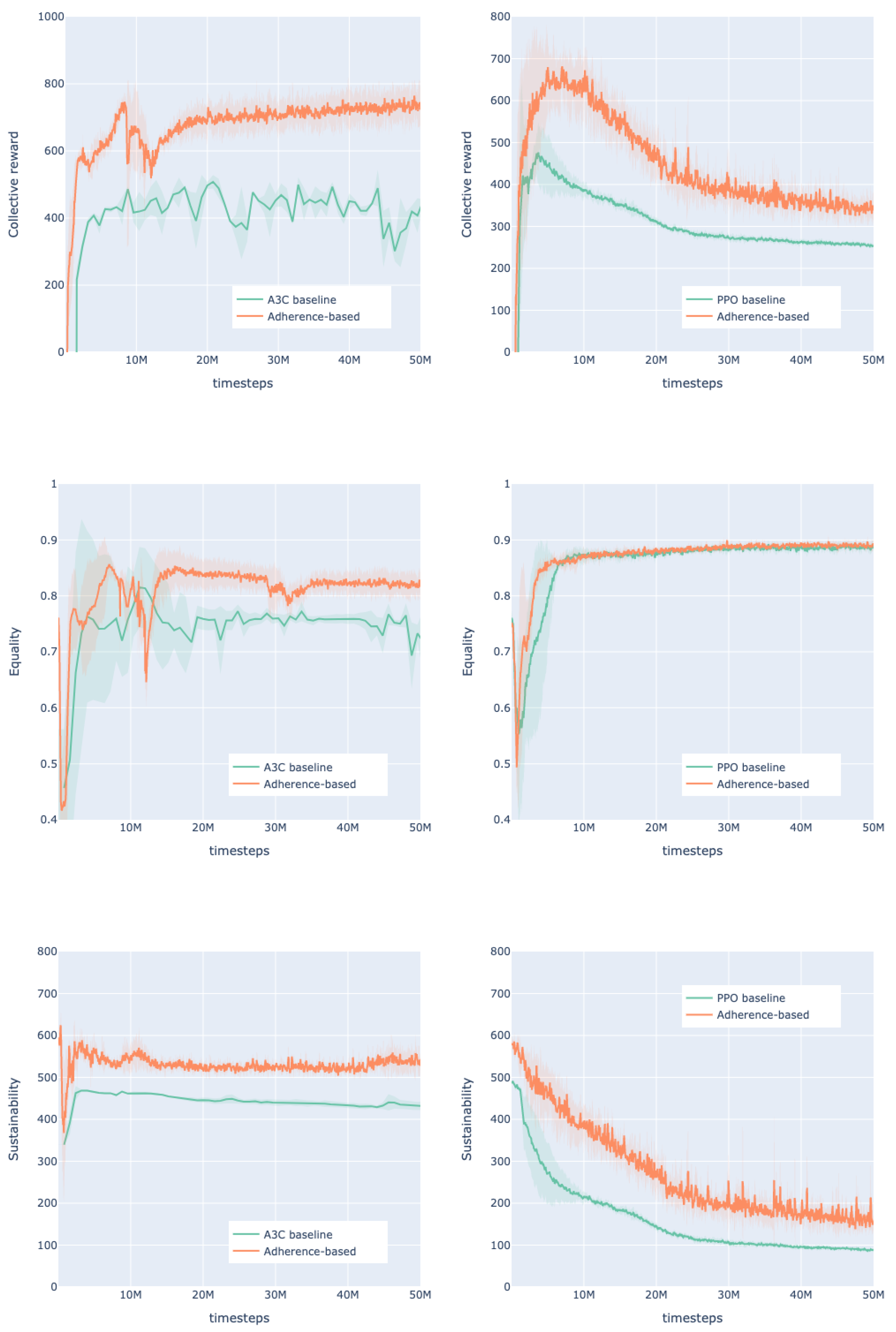
4.3.2. Harvest
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Matignon, L.; Laurent, G.J.; Le Fort-Piat, N. Independent reinforcement learners in cooperative Markov games: A survey regarding coordination problems. Knowl. Eng. Rev. 2012, 27, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Jia, D.; Weng, X. Deep reinforcement learning for autonomous driving. arXiv 2018, arXiv:1811.11329. [Google Scholar]
- Cobbe, K.; Hesse, C.; Hilton, J.; Schulman, J. Leveraging procedural generation to benchmark reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 2048–2056. [Google Scholar]
- Yang, Y.; Caluwaerts, K.; Iscen, A.; Zhang, T.; Tan, J.; Sindhwani, V. Data efficient reinforcement learning for legged robots. In Proceedings of the Conference on Robot Learning, PMLR, Virtual, 16–18 November 2020; pp. 1–10. [Google Scholar]
- Delaram, J.; Houshamand, M.; Ashtiani, F.; Valilai, O.F. A utility-based matching mechanism for stable and optimal resource allocation in cloud manufacturing platforms using deferred acceptance algorithm. J. Manuf. Syst. 2021, 60, 569–584. [Google Scholar] [CrossRef]
- Yang, Y.; Hao, J.; Chen, G.; Tang, H.; Chen, Y.; Hu, Y.; Fan, C.; Wei, Z. Q-value path decomposition for deep multiagent reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 13–18 July 2020; pp. 10706–10715. [Google Scholar]
- Bakolas, E.; Lee, Y. Decentralized game-theoretic control for dynamic task allocation problems for multi-agent systems. In Proceedings of the 2021 American Control Conference (ACC), New Orleans, LA, USA, 25–28 May 2021; pp. 3228–3233. [Google Scholar]
- Lian, F.; Chakrabortty, A.; Duel-Hallen, A. Game-theoretic multi-agent control and network cost allocation under communication constraints. IEEE J. Sel. Areas Commun. 2017, 35, 330–340. [Google Scholar] [CrossRef]
- Huang, K.; Chen, X.; Yu, Z.; Yang, C.; Gui, W. Heterogeneous cooperative belief for social dilemma in multi-agent system. Appl. Math. Comput. 2018, 320, 572–579. [Google Scholar] [CrossRef]
- Dobrowolski, Z. Internet of things and other e-solutions in supply chain management may generate threats in the energy sector—The quest for preventive measures. Energies 2021, 14, 5381. [Google Scholar] [CrossRef]
- Leibo, J.Z.; Dueñez-Guzman, E.A.; Vezhnevets, A.; Agapiou, J.P.; Sunehag, P.; Koster, R.; Matyas, J.; Beattie, C.; Mordatch, I.; Graepel, T. Scalable evaluation of multi-agent reinforcement learning with melting pot. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual, 18–24 July 2021; pp. 6187–6199. [Google Scholar]
- Izquierdo, S.S.; Izquierdo, L.R.; Gotts, N.M. Reinforcement learning dynamics in social dilemmas. J. Artif. Soc. Soc. Simul. 2008, 11, 1. [Google Scholar]
- Macy, M.W.; Flache, A. Learning dynamics in social dilemmas. Proc. Natl. Acad. Sci. USA 2002, 99, 7229–7236. [Google Scholar] [CrossRef] [Green Version]
- Van Lange, P.A.; Joireman, J.; Parks, C.D.; Van Dijk, E. The psychology of social dilemmas: A review. Organ. Behav. Hum. Decis. Process. 2013, 120, 125–141. [Google Scholar] [CrossRef]
- Sandholm, T.W.; Crites, R.H. Multiagent reinforcement learning in the iterated prisoner’s dilemma. Biosystems 1996, 37, 147–166. [Google Scholar] [CrossRef]
- Sibly, H.; Tisdell, J. Cooperation and turn taking in finitely-repeated prisoners’ dilemmas: An experimental analysis. J. Econ. Psychol. 2018, 64, 49–56. [Google Scholar] [CrossRef]
- Busoniu, L.; Babuska, R.; De Schutter, B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2008, 38, 156–172. [Google Scholar] [CrossRef] [Green Version]
- Leibo, J.Z.; Zambaldi, V.; Lanctot, M.; Marecki, J.; Graepel, T. Multi-agent reinforcement learning in sequential social dilemmas. arXiv 2017, arXiv:1702.03037. [Google Scholar]
- Vinyals, O.; Ewalds, T.; Bartunov, S.; Georgiev, P.; Vezhnevets, A.S.; Yeo, M.; Makhzani, A.; Küttler, H.; Agapiou, J.; Schrittwieser, J.; et al. Starcraft ii: A new challenge for reinforcement learning. arXiv 2017, arXiv:1708.04782. [Google Scholar]
- Berner, C.; Brockman, G.; Chan, B.; Cheung, V.; Dębiak, P.; Dennison, C.; Farhi, D.; Fischer, Q.; Hashme, S.; Hesse, C.; et al. Dota 2 with large scale deep reinforcement learning. arXiv 2019, arXiv:1912.06680. [Google Scholar]
- Singh, S.; Barto, A.G.; Chentanez, N. Intrinsically Motivated Reinforcement Learning; Technical Report; Massachusetts University Amherst Dept of Computer Science: Amherst, MA, USA, 2005. [Google Scholar]
- Eccles, T.; Hughes, E.; Kramár, J.; Wheelwright, S.; Leibo, J.Z. Learning reciprocity in complex sequential social dilemmas. arXiv 2019, arXiv:1903.08082. [Google Scholar]
- Chentanez, N.; Barto, A.; Singh, S. Intrinsically motivated reinforcement learning. Adv. Neural Inf. Process. Syst. 2004, 17, 1281–1288. [Google Scholar]
- Mohamed, S.; Jimenez Rezende, D. Variational information maximisation for intrinsically motivated reinforcement learning. Adv. Neural Inf. Process. Syst. 2015, 28, 2125–2133. [Google Scholar]
- Klyubin, A.S.; Polani, D.; Nehaniv, C.L. Empowerment: A universal agent-centric measure of control. In Proceedings of the 2005 IEEE Congress on Evolutionary Computation, Edinburgh, UK, 2–4 September 2005; Volume 1, pp. 128–135. [Google Scholar]
- Pathak, D.; Agrawal, P.; Efros, A.A.; Darrell, T. Curiosity-driven exploration by self-supervised prediction. In Proceedings of the Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 16–17. [Google Scholar]
- Schmidhuber, J. Formal theory of creativity, fun, and intrinsic motivation (1990–2010). IEEE Trans. Auton. Ment. Dev. 2010, 2, 230–247. [Google Scholar] [CrossRef]
- Peysakhovich, A.; Lerer, A. Prosocial learning agents solve generalized stag hunts better than selfish ones. arXiv 2017, arXiv:1709.02865. [Google Scholar]
- Hughes, E.; Leibo, J.Z.; Phillips, M.; Tuyls, K.; Dueñez-Guzman, E.; Castañeda, A.G.; Dunning, I.; Zhu, T.; McKee, K.; Koster, R.; et al. Inequity aversion improves cooperation in intertemporal social dilemmas. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 3326–3336. [Google Scholar]
- Wang, J.X.; Hughes, E.; Fernando, C.; Czarnecki, W.M.; Duéñez-Guzmán, E.A.; Leibo, J.Z. Evolving intrinsic motivations for altruistic behavior. arXiv 2018, arXiv:1811.05931. [Google Scholar]
- Jaques, N.; Lazaridou, A.; Hughes, E.; Gulcehre, C.; Ortega, P.; Strouse, D.; Leibo, J.Z.; De Freitas, N. Social influence as intrinsic motivation for multi-agent deep reinforcement learning. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 3040–3049. [Google Scholar]
- Yuan, Y.; Zhao, P.; Guo, T.; Jiang, H. Counterfactual-Based Action Evaluation Algorithm in Multi-Agent Reinforcement Learning. Appl. Sci. 2022, 12, 3439. [Google Scholar] [CrossRef]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual multi-agent policy gradients. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Devlin, S.; Yliniemi, L.; Kudenko, D.; Tumer, K. Potential-based difference rewards for multiagent reinforcement learning. In Proceedings of the 2014 International Conference on Autonomous Agents and Multi-Agent Systems, Paris, France, 5–9 May 2014; pp. 165–172. [Google Scholar]
- Shapley, L.S. Stochastic games. Proc. Natl. Acad. Sci. USA 1953, 39, 1095–1100. [Google Scholar] [CrossRef] [Green Version]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Machine Learning Proceedings 1994; Elsevier: Berlin/Heidelberg, Germany, 1994; pp. 157–163. [Google Scholar]
- Kollock, P. Social dilemmas: The anatomy of cooperation. Annu. Rev. Sociol. 1998, 24, 183–214. [Google Scholar] [CrossRef]
- Conybeare, J.A. Public goods, prisoners’ dilemmas and the international political economy. Int. Stud. Q. 1984, 28, 5–22. [Google Scholar] [CrossRef]
- Shankar, A.; Pavitt, C. Resource and public goods dilemmas: A new issue for communication research. Rev. Commun. 2002, 2, 251–272. [Google Scholar]
- Hardin, G. The Tragedy of the Commons. Science 1968, 162, 124–1248. [Google Scholar] [CrossRef] [Green Version]
- Dawes, R.M.; McTavish, J.; Shaklee, H. Behavior, communication, and assumptions about other people’s behavior in a commons dilemma situation. J. Personal. Soc. Psychol. 1977, 35, 1. [Google Scholar] [CrossRef]
- Perolat, J.; Leibo, J.Z.; Zambaldi, V.; Beattie, C.; Tuyls, K.; Graepel, T. A multi-agent reinforcement learning model of common-pool resource appropriation. arXiv 2017, arXiv:1707.06600. [Google Scholar]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, PMLR, New York, NY, USA, 20–22 June 2016; pp. 1928–1937. [Google Scholar]
- Gers, F.A.; Schmidhuber, J.; Cummins, F. Learning to forget: Continual prediction with LSTM. Neural Comput. 2000, 12, 2451–2471. [Google Scholar] [CrossRef]
- Ferguson, H.J.; Scheepers, C.; Sanford, A.J. Expectations in counterfactual and theory of mind reasoning. Lang. Cogn. Process. 2010, 25, 297–346. [Google Scholar] [CrossRef] [Green Version]
- Tomasello, M. Why We Cooperate; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Oliver, P. Rewards and punishments as selective incentives for collective action: Theoretical investigations. Am. J. Sociol. 1980, 85, 1356–1375. [Google Scholar] [CrossRef]
- O’Gorman, R.; Henrich, J.; Van Vugt, M. Constraining free riding in public goods games: Designated solitary punishers can sustain human cooperation. Proc. R. Soc. B Biol. Sci. 2009, 276, 323–329. [Google Scholar] [CrossRef] [PubMed] [Green Version]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, Y.; Guo, T.; Zhao, P.; Jiang, H. Adherence Improves Cooperation in Sequential Social Dilemmas. Appl. Sci. 2022, 12, 8004. https://doi.org/10.3390/app12168004
Yuan Y, Guo T, Zhao P, Jiang H. Adherence Improves Cooperation in Sequential Social Dilemmas. Applied Sciences. 2022; 12(16):8004. https://doi.org/10.3390/app12168004
Chicago/Turabian StyleYuan, Yuyu, Ting Guo, Pengqian Zhao, and Hongpu Jiang. 2022. "Adherence Improves Cooperation in Sequential Social Dilemmas" Applied Sciences 12, no. 16: 8004. https://doi.org/10.3390/app12168004