
Classification of Alzheimer’s Disease Using Dual-Phase 18F-Florbetaben Image with Rank-Based Feature Selection and Machine Learning


Abstract
:1. Introduction
2. Materials and Methods
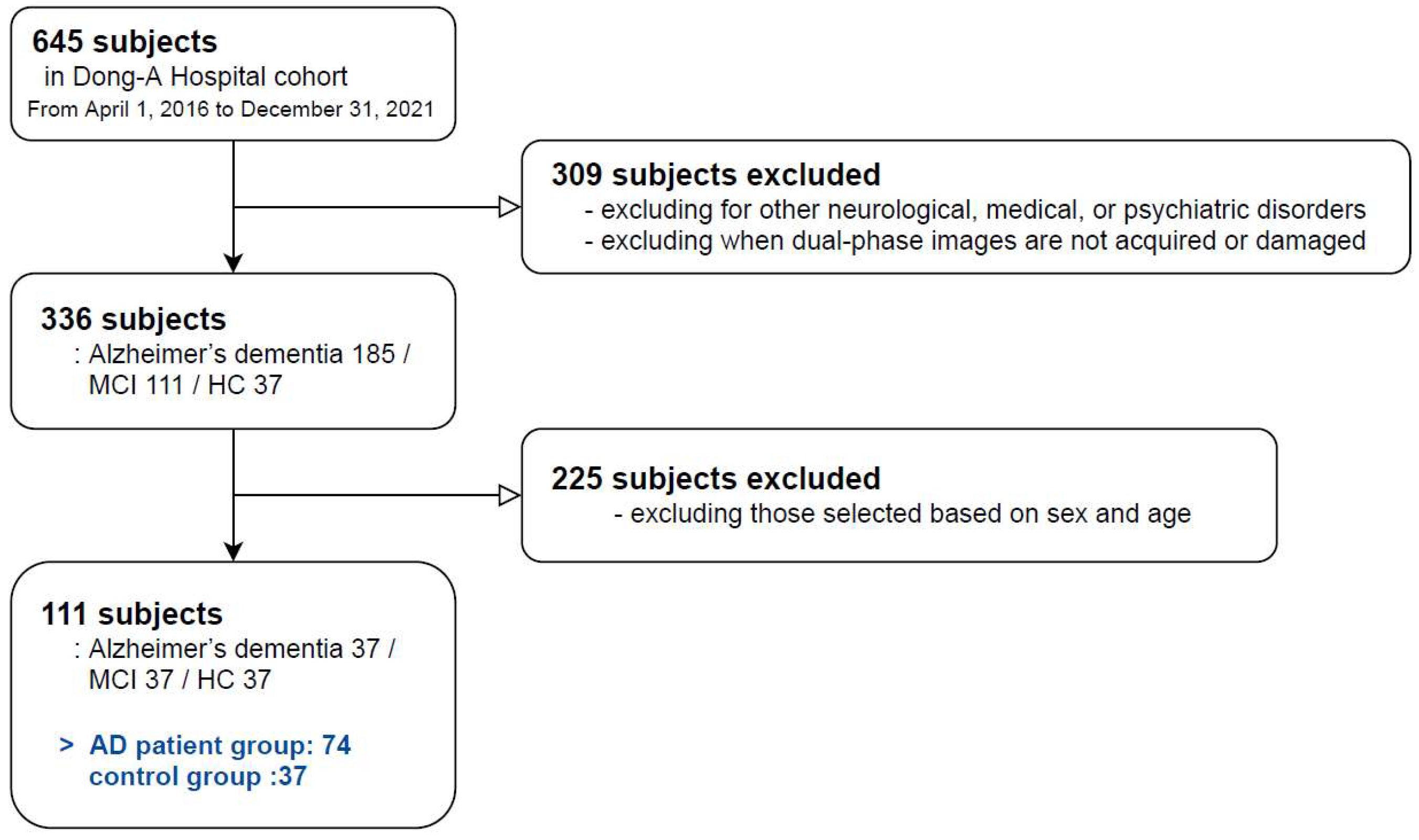
2.1. Subjects
2.2. Image Acquisition and Analysis
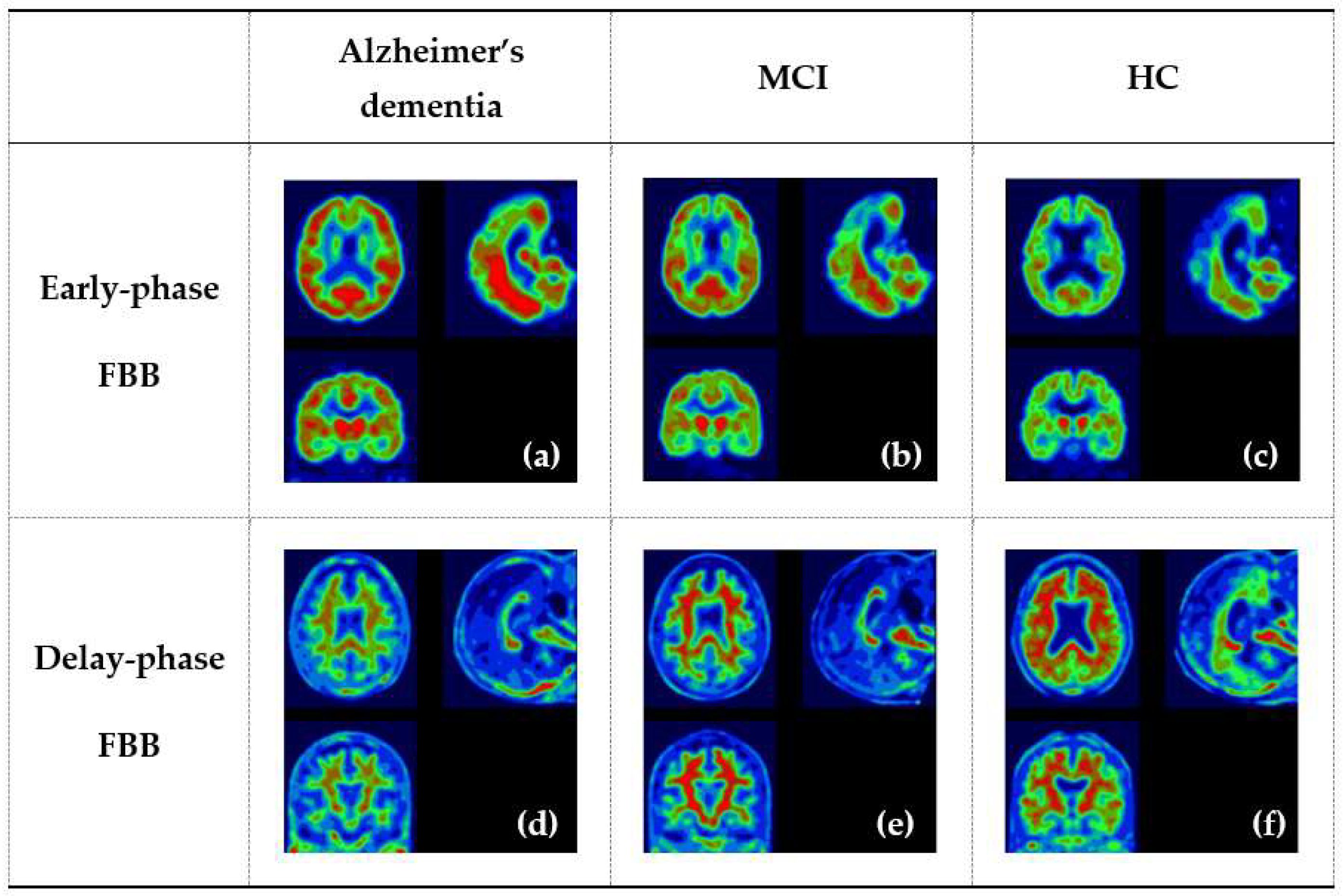
2.2.1. Image Acquisition
2.2.2. Image Preprocessing
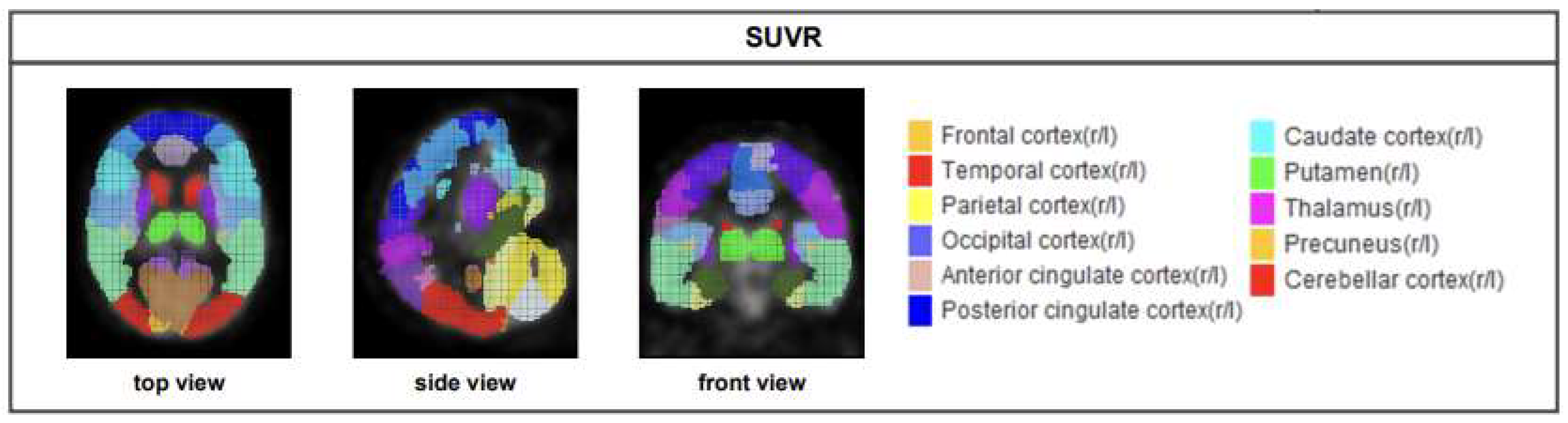
2.2.3. SUVR acquisition
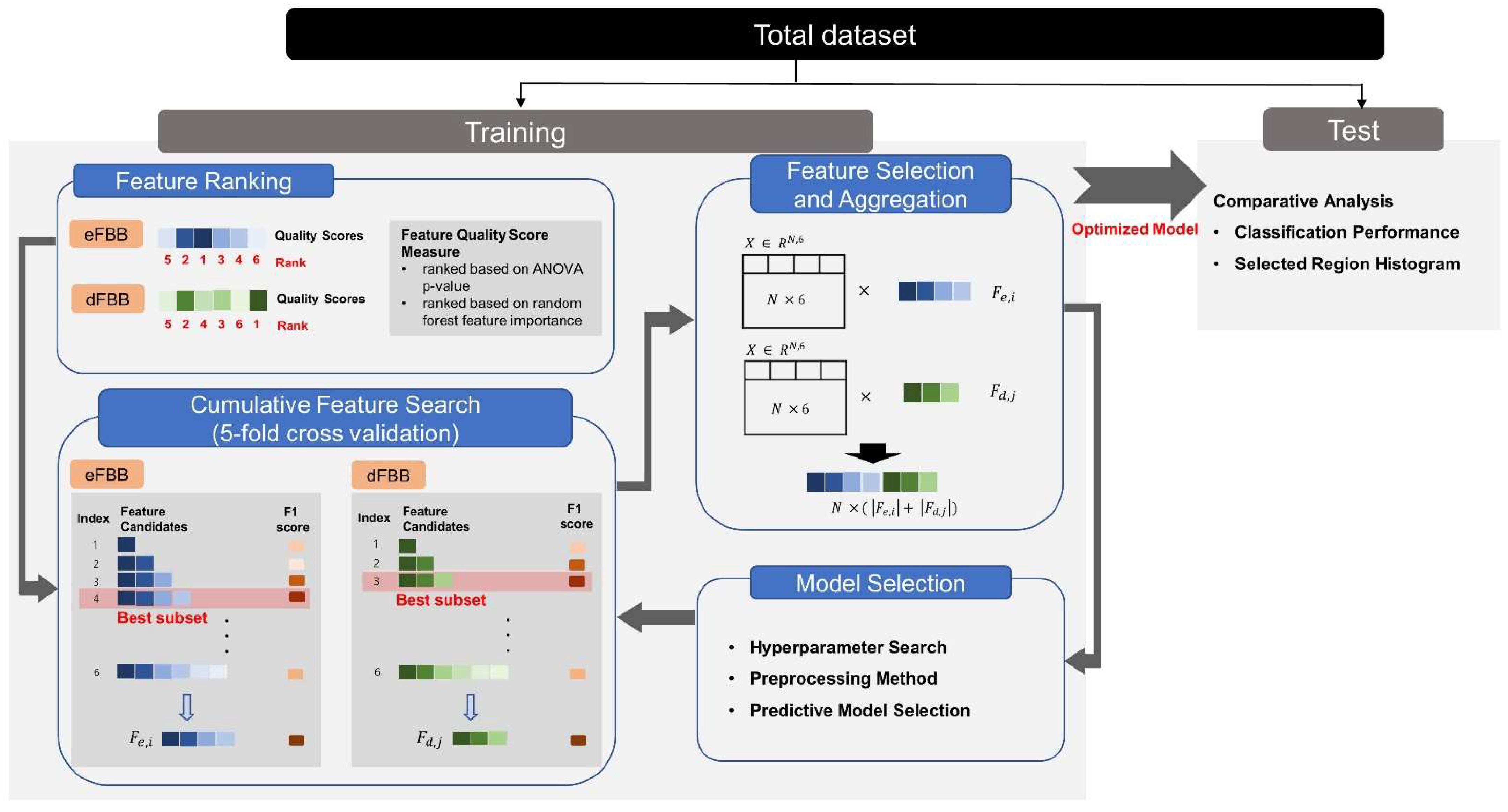
2.3. Experiment
- Feature ranking methods were applied to the preprocessed data.
- Feature subset was determined by cumulative feature search with 5-fold cross validation.
- As a series of model selection procedures, the hyperparameters, preprocessing methods, and types of predictive model were reconsidered without test set.
- The best model was tested and feature distribution observed to test our hypotheses.
2.3.1. Feature Selection and Aggregation for Dual-Phase FBB
2.3.2. Evaluation for Classification Model and Selected Feature Distribution
2.3.3. Machine Learning Methods for Classifying AD Patient Group and Control Group
2.3.4. Experimental Machine Learning Tool
2.4. Statistical Analysis
3. Results
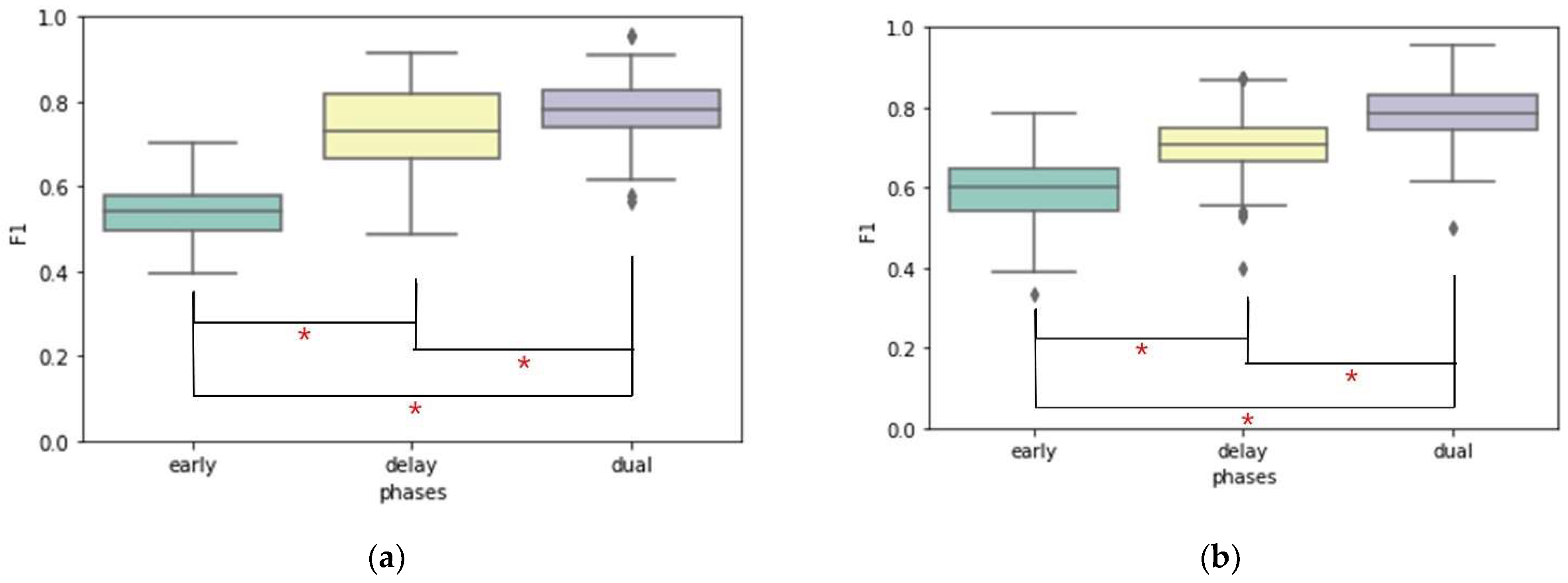
3.1. Comparison of Classification Performance for AD Patient Group and Control Group
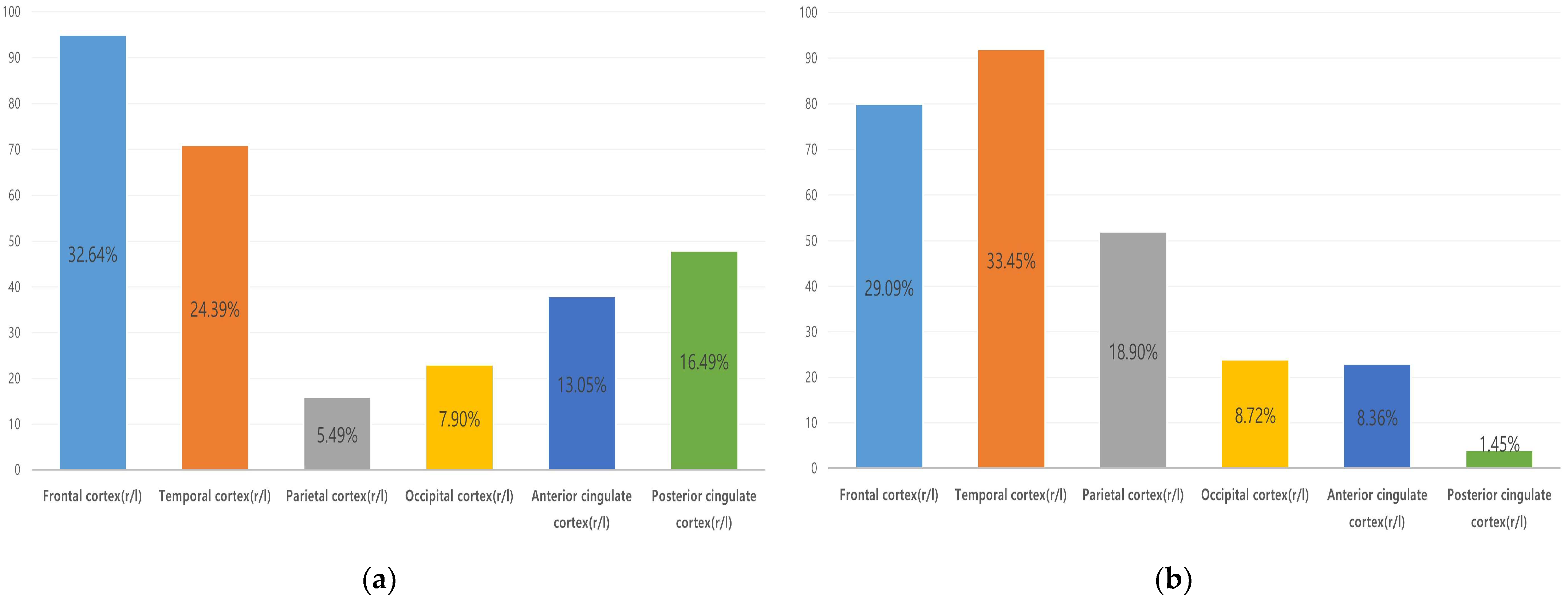
3.2. Frequency-Based Analysis for Feature Selection
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Nichols, E.; Steinmetz, J.D.; Vollset, S.E.; Fukutaki, K.; Chalek, J.; Abd-Allah, F.; Abdoli, A.; Abualhasan, A.; Abu-Gharbieh, E.; Akram, T.T.; et al. Estimation of the global prevalence of dementia in 2019 and forecasted prevalence in 2050: An analysis for the Global Burden of Disease Study 2019. Lancet Public Health 2022, 7, e105–e125. [Google Scholar] [CrossRef]
- Khan, A. An Investigative Study into Alzheimer’s Disease (AD): Development, Pathway and Progression, and Novel Treatment; University of Tennessee: Knoxville, TN, USA, 2022. [Google Scholar]
- Ponisio, M.R.; Iranpour, P.; Benzinger, T.L. Amyloid Imaging in Dementia and Neurodegenerative Disease; Hybrid PET/MR Neuroimaging; Springer: Berlin/Heidelberg, Germany, 2022; pp. 99–110. [Google Scholar]
- Zhao, X.; Li, C.; Ding, G.; Heng, Y.; Li, A.; Wang, W.; Hou, H.; Wen, J.; Zhang, Y. The Burden of Alzheimer’s Disease Mortality in the United States, 1999–2018. J. Alzheimer’s Dis. 2021, 82, 803–813. [Google Scholar] [CrossRef] [PubMed]
- Myoraku, A.; Klein, G.; Landau, S.; Tosun, D. Regional uptakes from early-frame amyloid PET and 18F-FDG PET scans are comparable independent of disease state. Eur. J. Hybrid Imaging 2022, 6, 2. [Google Scholar] [CrossRef] [PubMed]
- Albano, D.; Premi, E.; Peli, A.; Camoni, L.; Bertagna, F.; Turrone, R.; Borroni, B.; Calhoun, V.D.; Rodella, C.; Magoni, M. Correlation between brain glucose metabolism (18F-FDG) and cerebral blood flow with amyloid tracers (18F-Florbetapir) in clinical routine: Preliminary evidences. Rev. Española De Med. Nucl. E Imagen Mol. (Engl. Ed.) 2022, 41, 146–152. [Google Scholar] [CrossRef]
- Vanhoutte, M.; Landeau, B.; Sherif, S.; de la Sayette, V.; Dautricourt, S.; Abbas, A.; Manrique, A.; Chocat, A.; Chételat, G. Evaluation of the early-phase [18F] AV45 PET as an optimal surrogate of [18F] FDG PET in ageing and Alzheimer’s clinical syndrome. NeuroImage Clin. 2021, 31, 102750. [Google Scholar] [CrossRef]
- Massa, F.; Chincarini, A.; Bauckneht, M.; Raffa, S.; Peira, E.; Arnaldi, D.; Pardini, M.; Pagani, M.; Orso, B.; Donegani, M.I. Added value of semiquantitative analysis of brain FDG-PET for the differentiation between MCI-Lewy bodies and MCI due to Alzheimer’s disease. Eur. J. Nucl. Med. Mol. Imaging 2022, 49, 1263–1274. [Google Scholar] [CrossRef]
- Arafa, D.A.; Moustafa, H.E.; Ali-Eldin, A.M.; Ali, H.A. Early detection of Alzheimer’s disease based on the state-of-the-art deep learning approach: A comprehensive survey. Multimed. Tools Appl. 2022, 81, 23735–23776. [Google Scholar] [CrossRef]
- Stoleru, G.I.; Iftene, A. Prediction of Medical Conditions Using Machine Learning Approaches: Alzheimer’s Case Study. Mathematics 2022, 10, 1767. [Google Scholar] [CrossRef]
- Lin, H.; Jiang, J.; Li, Z.; Sheng, C.; Du, W.; Li, X.; Han, Y. Identification of subjective cognitive decline due to Alzheimer’s disease using multimodal MRI combining with machine learning. Cereb. Cortex 2022, bhac084. [Google Scholar] [CrossRef]
- Qiu, S.; Miller, M.I.; Joshi, P.S.; Lee, J.C.; Xue, C.; Ni, Y.; Wang, Y.; Anda-Duran, D.; Hwang, P.H.; Cramer, J.A. Multimodal deep learning for Alzheimer’s disease dementia assessment. Nat. Commun. 2022, 13, 3404. [Google Scholar] [CrossRef]
- Sharma, S.; Mandal, P.K. A Comprehensive Report on Machine Learning-based Early Detection of Alzheimer’s Disease using Multi-modal Neuroimaging Data. ACM Comput. Surv. (CSUR) 2022, 55, 43. [Google Scholar] [CrossRef]
- Yoon, H.J.; Jeong, Y.J.; Kang, D.; Kang, H.; Yeo, K.K.; Jeong, J.E.; Park, K.W.; Choi, G.E.; Ha, S. Effect of Data Augmentation of F-18-Florbetaben Positron-Emission Tomography Images by Using Deep Learning Convolutional Neural Network Architecture for Amyloid Positive Patients. J. Korean Phys. Soc. 2019, 75, 597–604. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Comput. Biol. Med. 2019, 112, 103375. [Google Scholar] [CrossRef] [PubMed]
- Ziegel, E.R.; Girden, E. Anova: Repeated Measures, 1st ed.; SAGE Publications Inc.: Newbury Park, CA, USA, 1993; pp. 10–13. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. Test 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- Vapnik, V.N. Support Vector Machine: Statistical Learning Theory, 1st ed.; John Wiley & Sons Inc.: New York, NY, USA, 1998; pp. 401–415. [Google Scholar]
- Zhang, H. The optimality of naive Bayes. In Proceedings of the Seventeenth International Florida Artificial Intelligence Research Society Conference, Miami Beach, FL, USA, 17–19 May 2004; Volume 1, p. 3. [Google Scholar]
- Fernandes, A.A.T.; Figueiredo, D.B.; Rocha, E.C.d.; Nascimento, W.d.S. Read this paper if you want to learn logistic regression. Rev. De Sociol. E Politica 2021, 28, e006. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Chakravarti, I.M.; Laha, R.G.; Roy, J. Handbook of Methods of Applied Statistics; Wiley Series in Probability and Mathematical Statistics (USA) Eng; Wiley: Hoboken, NJ, USA, 1967. [Google Scholar]
- Chételat, G.; Arbizu, J.; Barthel, H.; Garibotto, V.; Law, I.; Morbelli, S.; van de Giessen, E.; Agosta, F.; Barkhof, F.; Brooks, D.J. Amyloid-PET and 18F-FDG-PET in the diagnostic investigation of Alzheimer’s disease and other dementias. Lancet Neurol. 2020, 19, 951–962. [Google Scholar] [CrossRef]
- Wirth, M.; Villeneuve, S.; Haase, C.M.; Madison, C.M.; Oh, H.; Landau, S.M.; Rabinovici, G.D.; Jagust, W.J. Associations between Alzheimer disease biomarkers, neurodegeneration, and cognition in cognitively normal older people. JAMA Neurol. 2013, 70, 1512–1519. [Google Scholar] [CrossRef] [Green Version]
- Knopman, D.S.; Jack, C.R.; Wiste, H.J.; Weigand, S.D.; Vemuri, P.; Lowe, V.; Kantarci, K.; Gunter, J.L.; Senjem, M.L.; Ivnik, R.J. Short-term clinical outcomes for stages of NIA-AA preclinical Alzheimer disease. Neurology 2012, 78, 1576–1582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Teipel, S.; Drzezga, A.; Grothe, M.J.; Barthel, H.; Chételat, G.; Schuff, N.; Skudlarski, P.; Cavedo, E.; Frisoni, G.B.; Hoffmann, W. Multimodal imaging in Alzheimer’s disease: Validity and usefulness for early detection. Lancet Neurol. 2015, 14, 1037–1053. [Google Scholar] [CrossRef]
- Grueso, S.; Viejo-Sobera, R. Machine learning methods for predicting progression from mild cognitive impairment to Alzheimer’s disease dementia: A systematic review. Alzheimer’s Res. Ther. 2021, 13, 162. [Google Scholar] [CrossRef]
- El-Sappagh, S.; Alonso, J.M.; Islam, S.M.; Sultan, A.M.; Kwak, K.S. A multilayer multimodal detection and prediction model based on explainable artificial intelligence for Alzheimer’s disease. Sci. Rep. 2021, 11, 2660. [Google Scholar] [CrossRef] [PubMed]
- Kumari, R.; Nigam, A.; Pushkar, S. An efficient combination of quadruple biomarkers in binary classification using ensemble machine learning technique for early onset of Alzheimer disease. Neural Comput. Appl. 2022, 34, 11865–11884. [Google Scholar] [CrossRef]
- Kim, J.P.; Kim, J.; Kim, Y.; Moon, S.H.; Park, Y.H.; Yoo, S.; Jang, H.; Kim, H.J.; Na, D.L.; Seo, S.W. Staging and quantification of florbetaben PET images using machine learning: Impact of predicted regional cortical tracer uptake and amyloid stage on clinical outcomes. Eur. J. Nucl. Med. Mol. Imaging 2020, 47, 1971–1983. [Google Scholar] [CrossRef] [Green Version]
- Thientunyakit, T.; Shiratori, S.; Ishii, K.; Gelovani, J.G. Molecular PET Imaging in Alzheimer’s Disease. J. Med. Biol. Eng. 2022, 42, 301–317. [Google Scholar] [CrossRef]
- Asghar, M.; Hinz, R.; Herholz, K.; Carter, S.F. Dual-phase [18F] florbetapir in frontotemporal dementia. Eur. J. Nucl. Med. Mol. Imaging 2019, 46, 304–311. [Google Scholar] [CrossRef] [Green Version]
- Ottoy, J.; Verhaeghe, J.; Niemantsverdriet, E.; De Roeck, E.; Ceyssens, S.; Van Broeckhoven, C.; Engelborghs, S.; Stroobants, S.; Staelens, S. 18F-FDG PET, the early phases and the delivery rate of 18F-AV45 PET as proxies of cerebral blood flow in Alzheimer’s disease: Validation against 15O-H2O PET. Alzheimer’s Dement. 2019, 15, 1172–1182. [Google Scholar] [CrossRef]
- Son, S.H.; Kang, K.; Ko, P.; Lee, H.; Lee, S.; Ahn, B.; Lee, J.; Yoon, U.; Jeong, S.Y. Early-phase 18F-florbetaben PET as an alternative modality for 18F-FDG PET. Clin. Nucl. Med. 2020, 45, e8–e14. [Google Scholar] [CrossRef]
- Cai, Q.; Wang, H.; Li, Z.; Liu, X. A survey on multimodal data-driven smart healthcare systems: Approaches and applications. IEEE Access 2019, 7, 133583–133599. [Google Scholar] [CrossRef]
- Meng, X.; Jiang, R.; Lin, D.; Bustillo, J.; Jones, T.; Chen, J.; Yu, Q.; Du, Y.; Zhang, Y.; Jiang, T. Predicting individualized clinical measures by a generalized prediction framework and multimodal fusion of MRI data. Neuroimage 2017, 145, 218–229. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shi, J.; Zheng, X.; Li, Y.; Zhang, Q.; Ying, S. Multimodal neuroimaging feature learning with multimodal stacked deep polynomial networks for diagnosis of Alzheimer’s disease. IEEE J. Biomed. Health Inform. 2017, 22, 173–183. [Google Scholar] [CrossRef]
- Wu, L.; Oviatt, S.L.; Cohen, P.R. Multimodal integration-a statistical view. IEEE Trans. Multimed. 1999, 1, 334–341. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Lundberg, S.M.; Lee, S. A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Syst. 2017, 30, 4768–4777. [Google Scholar]
- Jo, T.; Nho, K.; Saykin, A.J. Deep learning in Alzheimer’s disease: Diagnostic classification and prognostic prediction using neuroimaging data. Front. Aging Neurosci. 2019, 11, 220. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Li, M.; Luo, Y.; Yang, S.; Li, W.; Bi, Y. Alzheimer’s disease detection using depthwise separable convolutional neural networks. Comput. Methods Programs Biomed. 2021, 203, 106032. [Google Scholar] [CrossRef]
- López-Sanz, D.; Bruña, R.; Delgado-Losada, M.L.; López-Higes, R.; Marcos-Dolado, A.; Maestú, F.; Walter, S. Electrophysiological brain signatures for the classification of subjective cognitive decline: Towards an individual detection in the preclinical stages of dementia. Alzheimer’s Res. Ther. 2019, 11, 49. [Google Scholar] [CrossRef]
- Zhang, L.; Xie, D.; Li, Y.; Camargo, A.; Song, D.; Lu, T.; Jeudy, J.; Dreizin, D.; Melhem, E.R.; Wang, Z. Improving Sensitivity of Arterial Spin Labeling Perfusion MRI in Alzheimer’s Disease Using Transfer Learning of Deep Learning-Based ASL Denoising. J. Magn. Reson. Imaging 2022, 55, 1710–1722. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AD Patient Group | Control Group | ||
|---|---|---|---|
| Alzheimer’s Dementia | MCI | HC | |
| Subjects | 37 | 37 | 37 |
| M/F | 14/23 | 14/23 | 14/23 |
| Average Age (range) | 66.59 (51–81) | 66.43 (44–83) | 66.32 (37–80) |
| BAPL 1/2/3 | 9/7/21 | 21/4/12 | 35/2/0 |
| Amyloid +/− | 28/9 | 16/21 | 2/35 |
| eFBB | dFBB | Dual FBB | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Accuracy | F1 Score | AUC | Accuracy | F1 Score | AUC | Accuracy | F1 Score | AUC | |
| Composite SUVR performance | |||||||||
| SVM | 67.04 | 53.83% | 0.5423 | 66.78% | 54.10% | 0.7080 | 70.65% | 64.97% | 0.8415 |
| RF | 58.39% | 53.98% | 0.6444 | 73.56% | 73.23% | 0.8336 | 78.21% | 78.06% | 0.8724 |
| LR | 66.91% | 55.87% | 0.7351 | 67.91% | 56.31% | 0.7809 | 72.91% | 65.56% | 0.8478 |
| NB | 66.52% | 63.27% | 0.7164 | 71.34% | 71.96% | 0.7350 | 76.08% | 76.52% | 0.8469 |
| Regional SUVR performance | |||||||||
| SVM (A.p) | 66.47% | 53.76% | 0.5701 | 66.47% | 61.80% | 0.7874 | 71.17% | 70.21% | 0.8223 |
| SVM (F.i) | 65.91% | 53.57% | 0.5475 | 66.60% | 61.83% | 0.7892 | 70.86% | 69.55% | 0.8223 |
| RF (A.p) | 61.52% | 59.51% | 0.6592 | 71.00% | 71.24% | 0.8040 | 78.52% | 78.54% | 0.8456 |
| RF (F.i) | 59.95% | 57.92% | 0.6582 | 69.82% | 70.10% | 0.7861 | 76.82% | 76.76% | 0.8440 |
| LR (A.p) | 65.39% | 56.95% | 0.7015 | 64.91% | 62.04% | 0.7865 | 72.60% | 70.73% | 0.8399 |
| LR (F.i) | 65.60% | 56.61% | 0.7124 | 64.86% | 61.57% | 0.7909 | 72.65% | 70.74% | 0.8383 |
| NB (A.p) | 63.34% | 63.43% | 0.6811 | 71.95% | 72.47% | 0.7944 | 76.13% | 76.58% | 0.8486 |
| NB (F.i) | 64.69% | 65.10% | 0.6958 | 72.56% | 73.07% | 0.7927 | 76.13% | 76.58% | 0.8476 |
| Min | Median | Mean | Max | SD | |
|---|---|---|---|---|---|
| eFBB | 33.66% | 60.19% | 59.51% | 78.63% | 8.4251 |
| dFBB | 40.05% | 70.92% | 71.24% | 87.26% | 7.9509 |
| dual FBB | 49.89% | 78.52% | 78.54% | 95.70% | 7.6105 |
| Frontal | Temporal | Parietal | Occipital | Anterior Cingulate | Posterior Cingulate | ||
|---|---|---|---|---|---|---|---|
| eFBB | Number of features | 95 | 71 | 16 | 23 | 38 | 48 |
| Ratio (%) | 32.64% | 24.39% | 5.49% | 7.90% | 13.05% | 16.49% | |
| dFBB | Number of features | 80 | 92 | 52 | 24 | 23 | 4 |
| Ratio (%) | 29.09% | 33.45% | 18.90% | 8.72% | 8.36% | 1.45% | |
| Features | 1 | 2 | 3 | 4 | 5 | 6 | All | |
|---|---|---|---|---|---|---|---|---|
| Region | ||||||||
| Frequency distribution by the number of featuresof eFBB | ||||||||
| Frontal | 18 | 29 | 13 | 18 | 8 | 9 | 95 | |
| Temporal | 0 | 25 | 10 | 19 | 8 | 9 | 71 | |
| Parietal | 0 | 2 | 1 | 1 | 3 | 9 | 16 | |
| Occipital | 0 | 0 | 2 | 5 | 7 | 9 | 23 | |
| Anterior cingulate | 1 | 2 | 4 | 15 | 7 | 9 | 38 | |
| Posterior cingulate | 1 | 4 | 9 | 18 | 7 | 9 | 48 | |
| Frequency distribution by the number of features of dFBB | ||||||||
| Frontal | 7 | 18 | 27 | 16 | 8 | 4 | 80 | |
| Temporal | 16 | 21 | 27 | 16 | 8 | 4 | 92 | |
| Parietal | 0 | 3 | 21 | 16 | 8 | 4 | 52 | |
| Occipital | 0 | 0 | 1 | 11 | 8 | 4 | 24 | |
| Anterior cingulate | 1 | 0 | 5 | 5 | 8 | 4 | 23 | |
| Posterior cingulate | 0 | 0 | 0 | 0 | 0 | 4 | 4 | |
| Features | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | All | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Region | ||||||||||||
| Frequency distribution by the number of features of eFBB | ||||||||||||
| Frontal | 2 | 11 | 15 | 20 | 18 | 12 | 7 | 5 | 4 | 1 | 95 | |
| Temporal | 0 | 7 | 6 | 15 | 15 | 11 | 7 | 5 | 4 | 1 | 71 | |
| Parietal | 0 | 0 | 8 | 0 | 2 | 3 | 3 | 3 | 3 | 0 | 16 | |
| Occipital | 0 | 0 | 8 | 1 | 3 | 5 | 4 | 3 | 4 | 1 | 23 | |
| Anterior cingulate | 0 | 0 | 4 | 7 | 7 | 6 | 6 | 3 | 4 | 1 | 38 | |
| Posterior cingulate | 0 | 2 | 3 | 7 | 11 | 10 | 6 | 4 | 4 | 1 | 48 | |
| Frequency distribution by the number of features of dFBB | ||||||||||||
| Frontal | 1 | 6 | 13 | 17 | 17 | 10 | 6 | 5 | 4 | 1 | 80 | |
| Temporal | 1 | 7 | 16 | 21 | 17 | 13 | 7 | 5 | 4 | 1 | 92 | |
| Parietal | 0 | 0 | 6 | 12 | 10 | 9 | 5 | 5 | 4 | 1 | 52 | |
| Occipital | 0 | 0 | 1 | 3 | 6 | 4 | 3 | 4 | 2 | 1 | 24 | |
| Anterior cingulate | 0 | 0 | 0 | 7 | 2 | 6 | 1 | 3 | 3 | 1 | 23 | |
| Posterior cingulate | 0 | 0 | 0 | 0 | 0 | 2 | 1 | 0 | 0 | 1 | 4 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, H.-J.; Yoon, H.; Kim, S.; Kang, D.-Y. Classification of Alzheimer’s Disease Using Dual-Phase 18F-Florbetaben Image with Rank-Based Feature Selection and Machine Learning. Appl. Sci. 2022, 12, 7355. https://doi.org/10.3390/app12157355
Shin H-J, Yoon H, Kim S, Kang D-Y. Classification of Alzheimer’s Disease Using Dual-Phase 18F-Florbetaben Image with Rank-Based Feature Selection and Machine Learning. Applied Sciences. 2022; 12(15):7355. https://doi.org/10.3390/app12157355
Chicago/Turabian StyleShin, Hyun-Ji, Hyemin Yoon, Sangjin Kim, and Do-Young Kang. 2022. "Classification of Alzheimer’s Disease Using Dual-Phase 18F-Florbetaben Image with Rank-Based Feature Selection and Machine Learning" Applied Sciences 12, no. 15: 7355. https://doi.org/10.3390/app12157355