
Skin Lesion Segmentation Based on Vision Transformers and Convolutional Neural Networks—A Comparative Study



Abstract
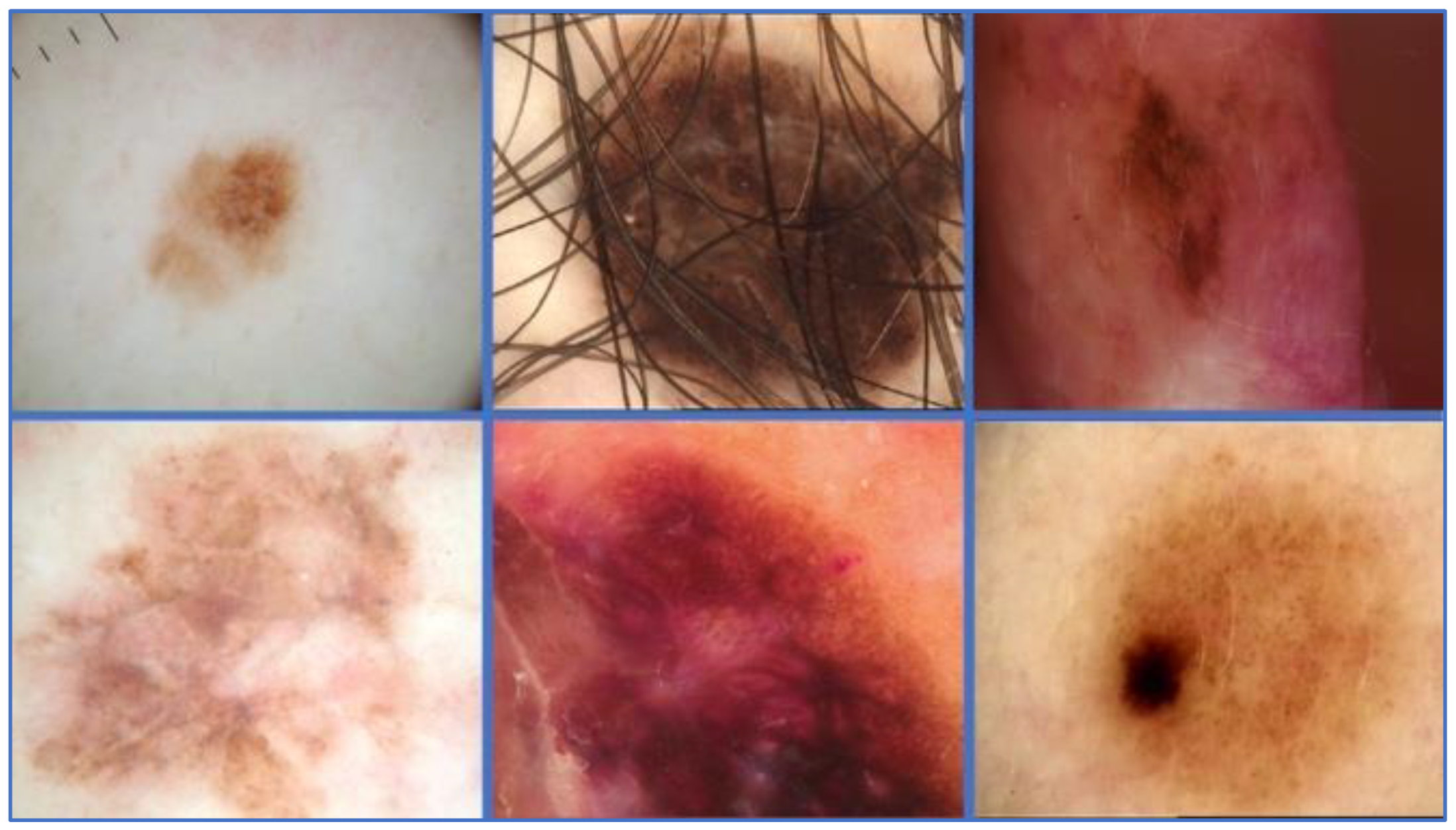
:1. Introduction
- We discuss the challenges in the skin lesion segmentation.
- We provide a detailed comparative analysis of the state-of-the-art methods for the task of skin lesion segmentation.
- We evaluate the efficacy of the state-of-the-art methods, and the experiments demonstrate the effectiveness of the U-Net and Transformer-based methods for skin lesion segmentation.
2. Related Work
3. Methods
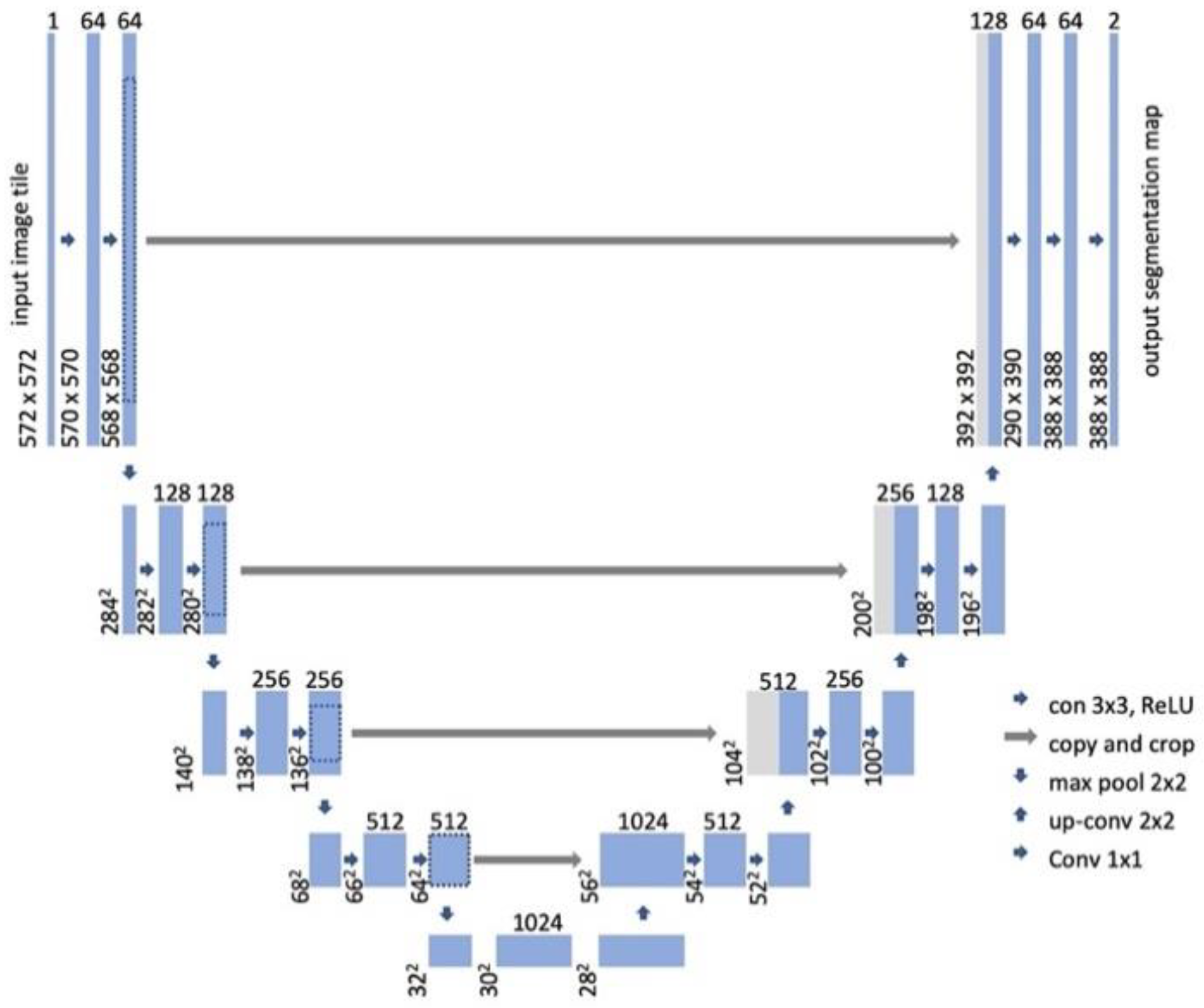
3.1. U-Net
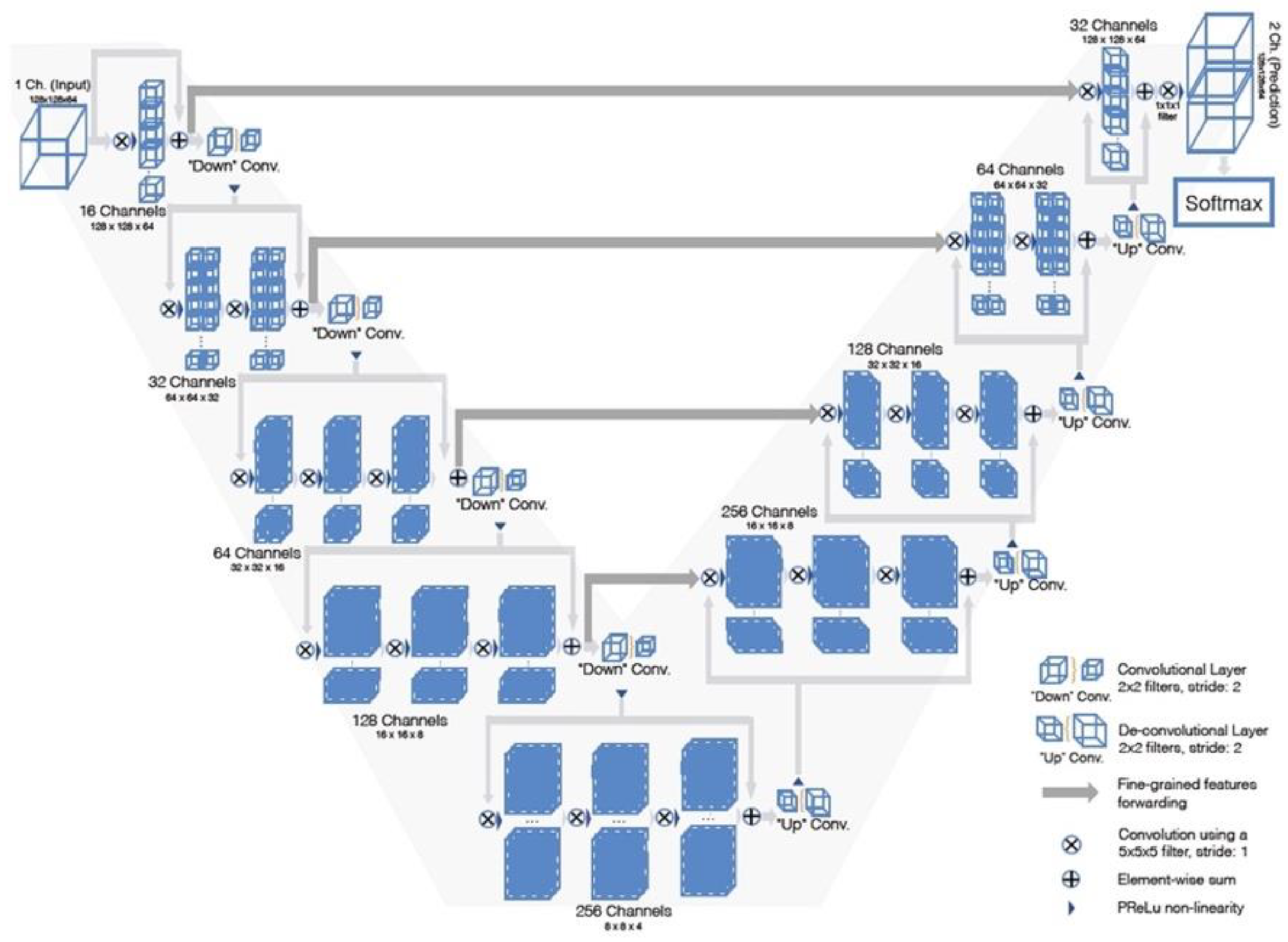
3.2. V-Net
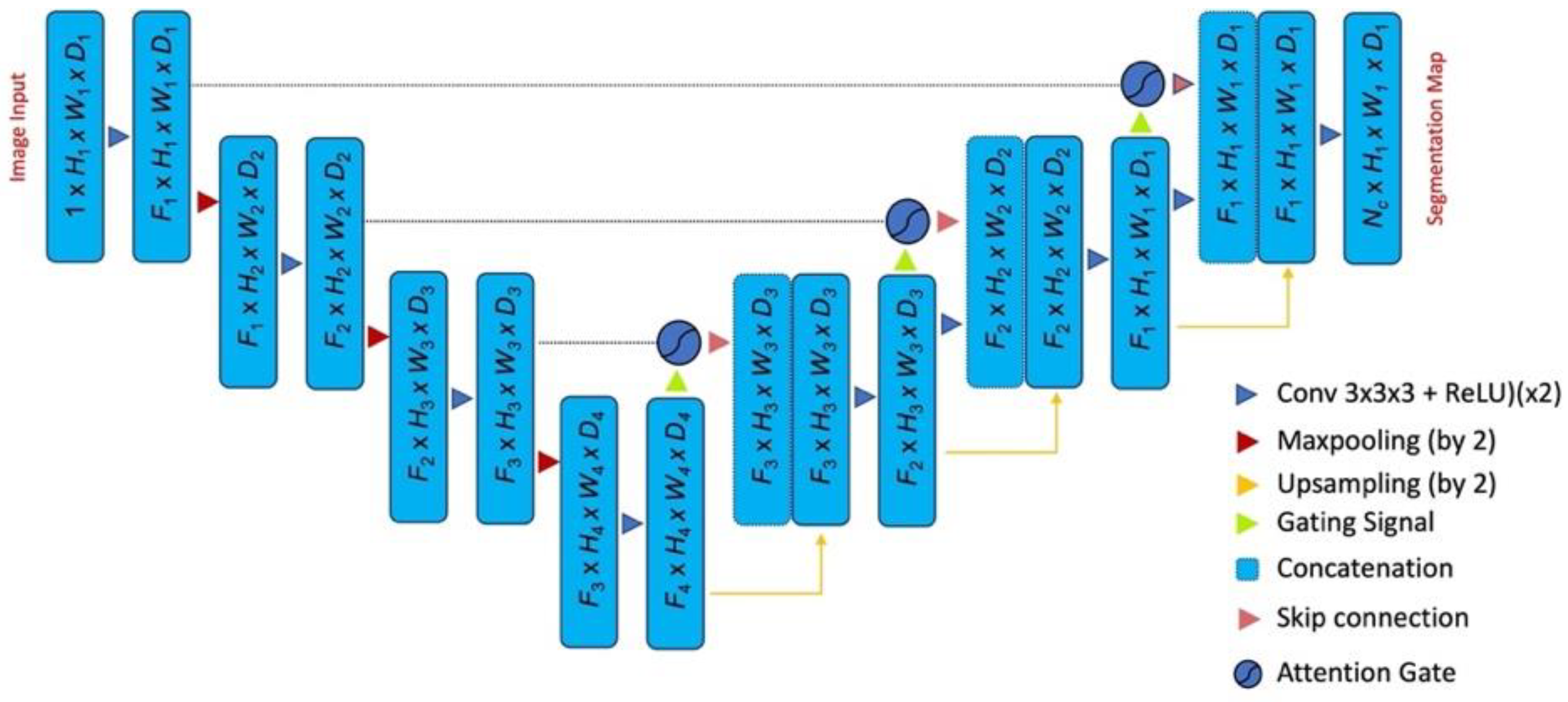
3.3. Attention U-Net
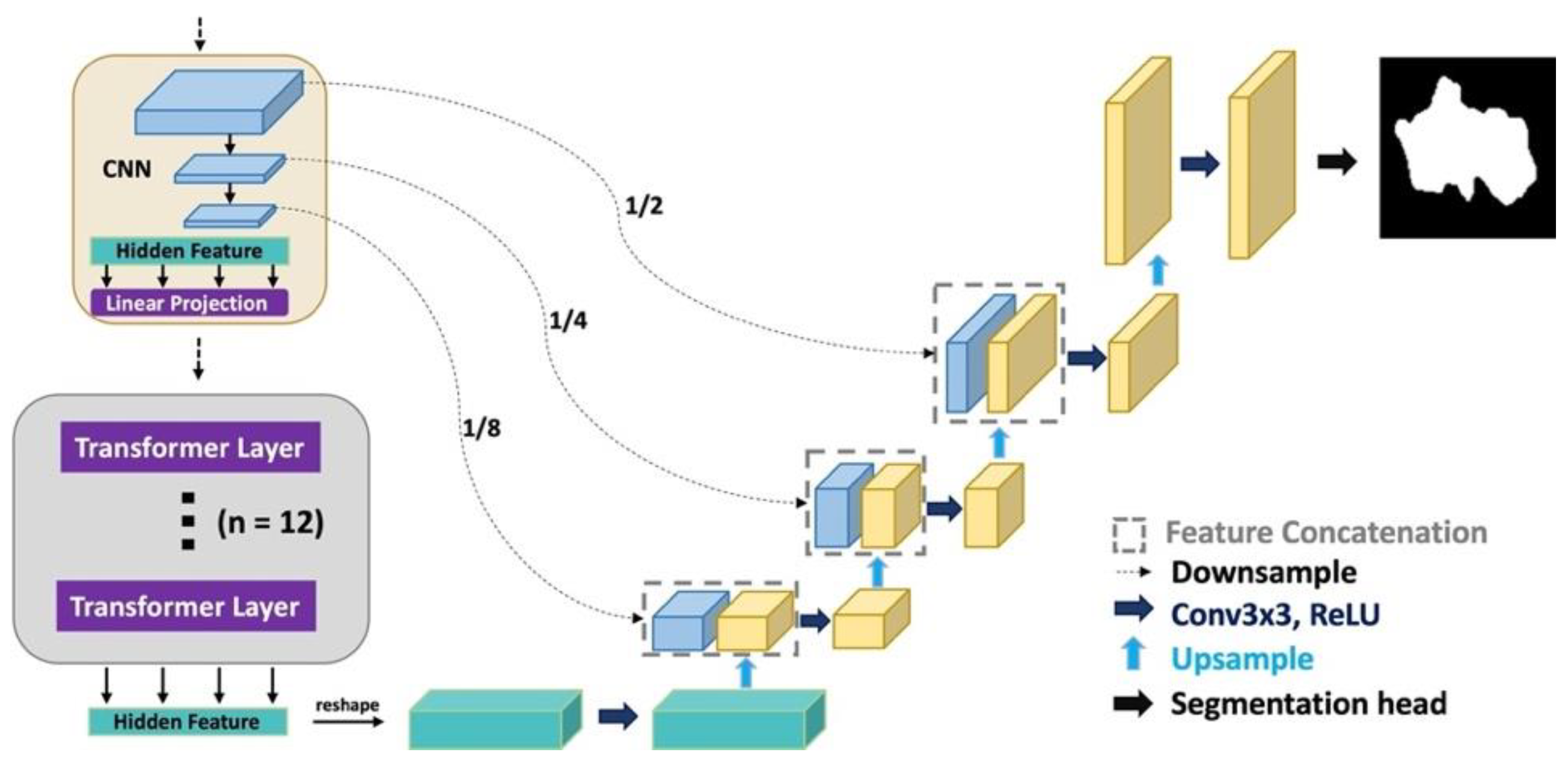
3.4. TransUNet
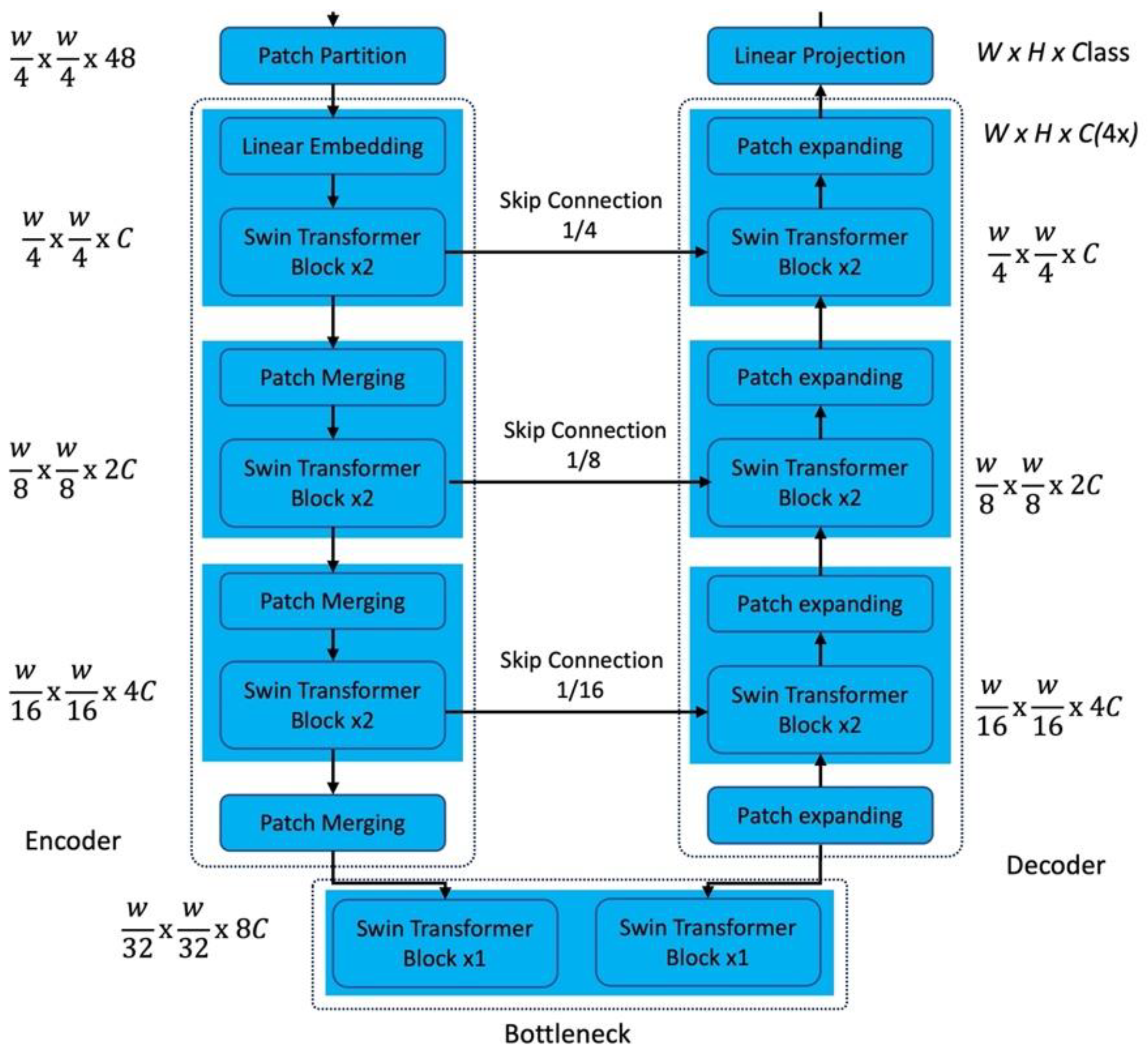
3.5. Swin-UNet
4. Experimental Results
4.1. Implementation Details
4.2. Dataset
4.3. Evaluation Metrics
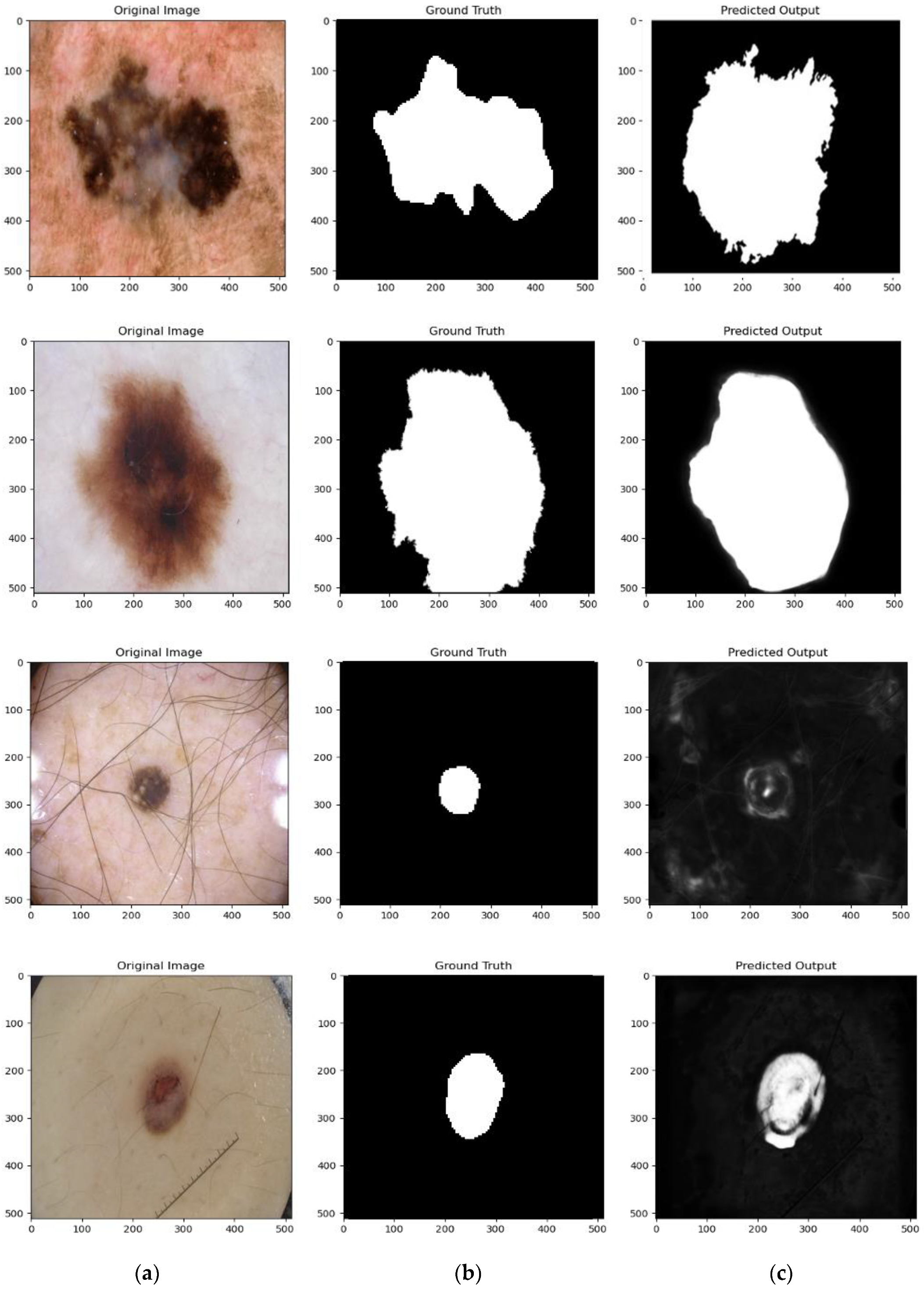
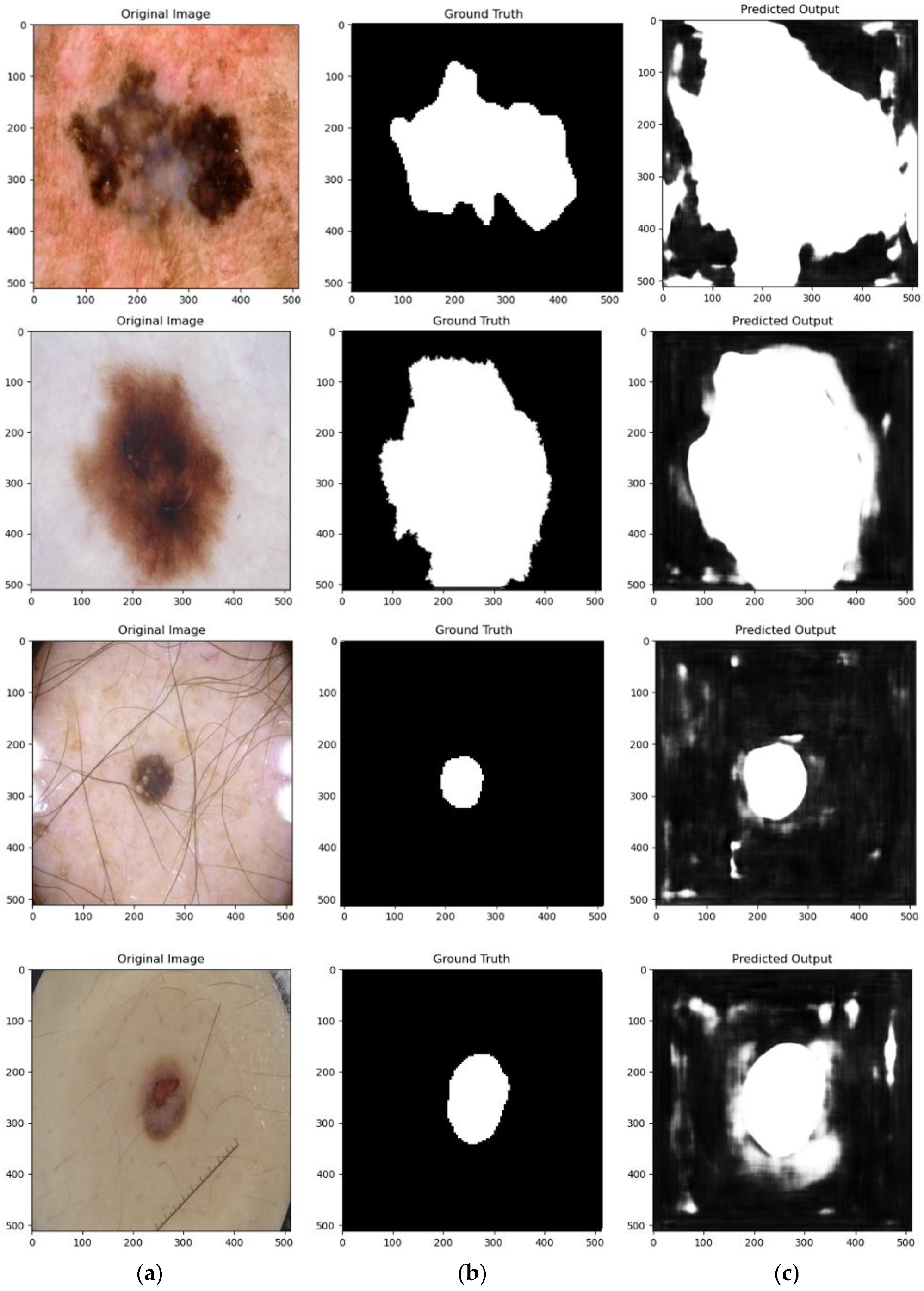
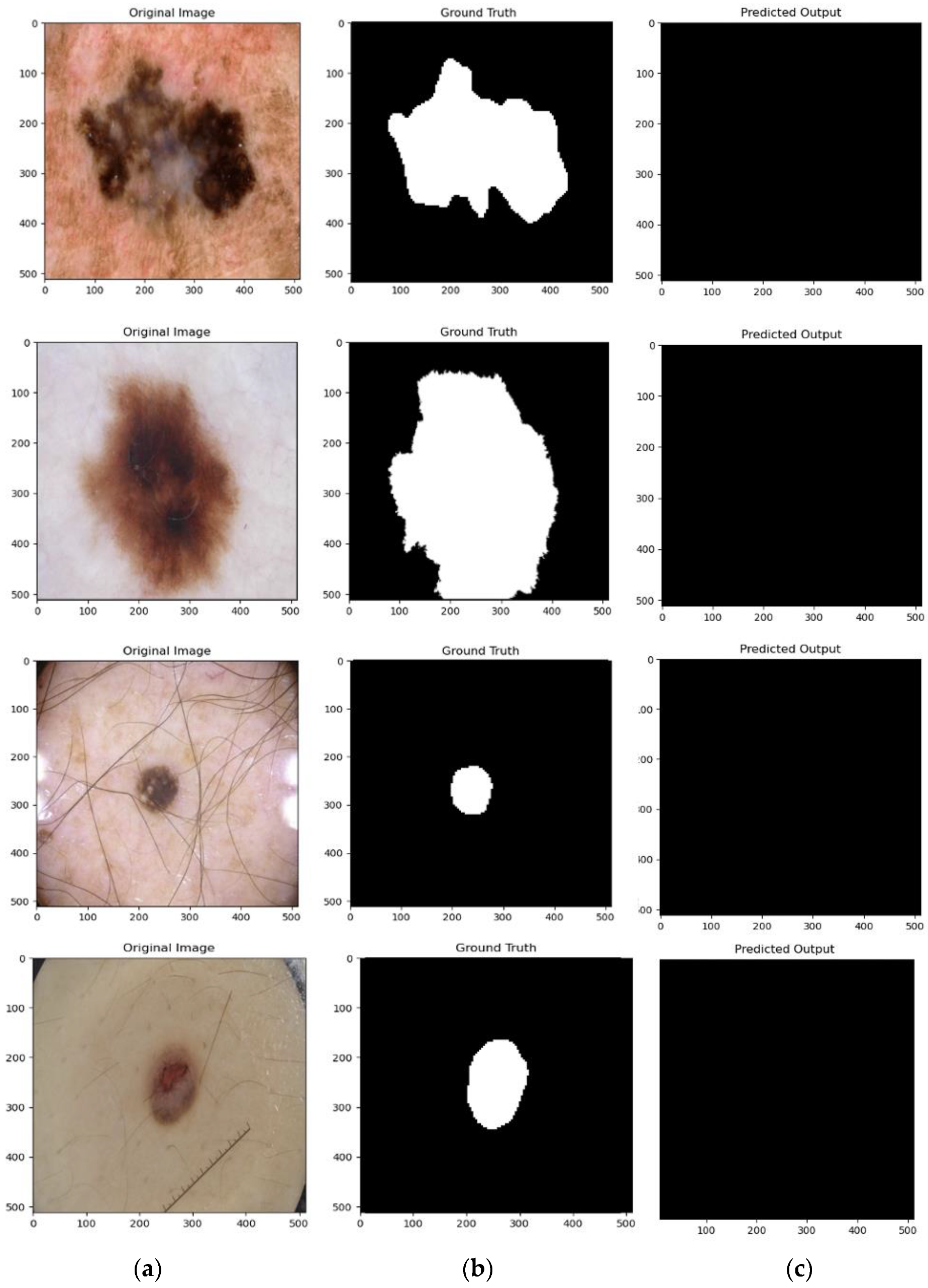
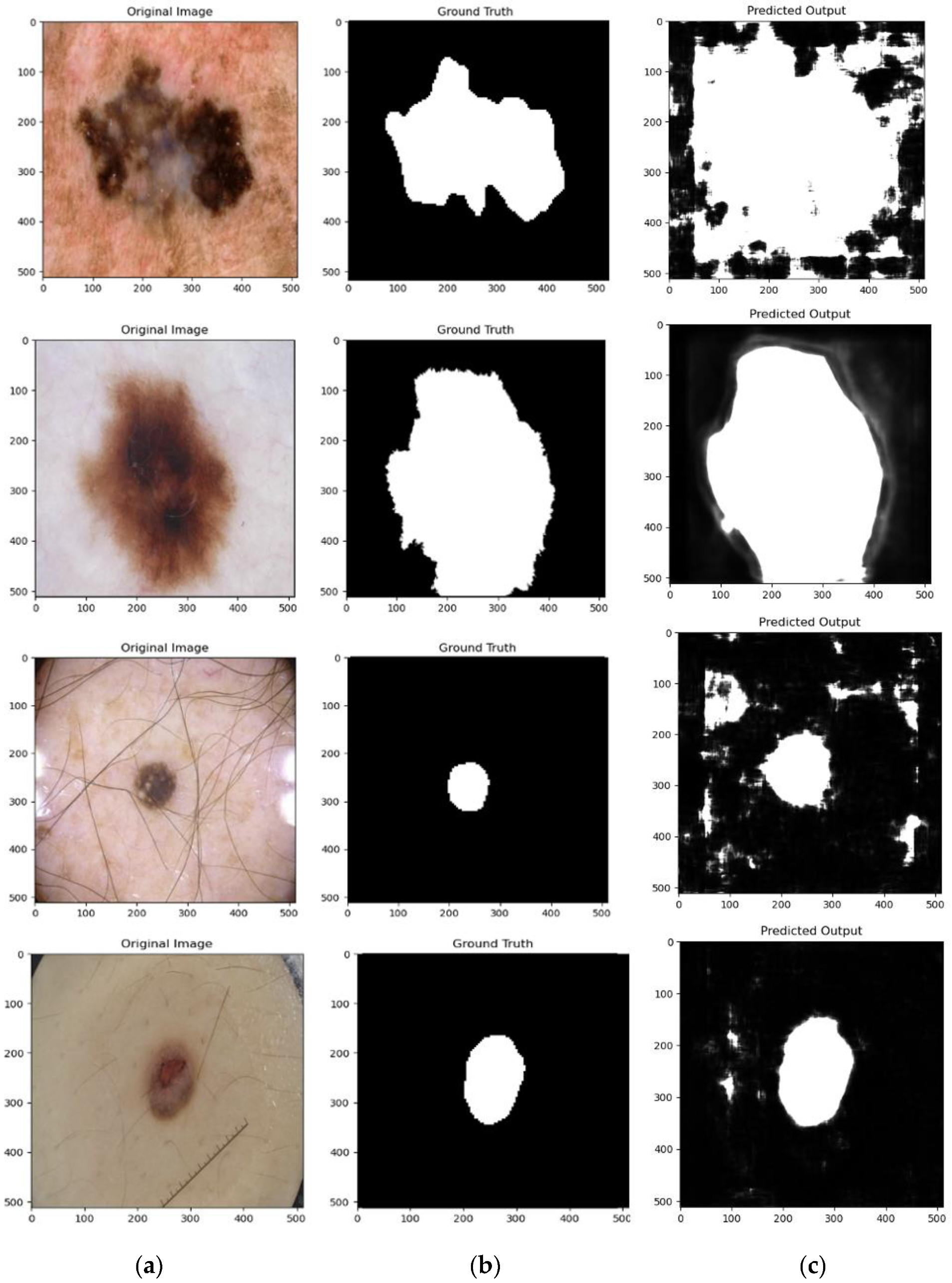
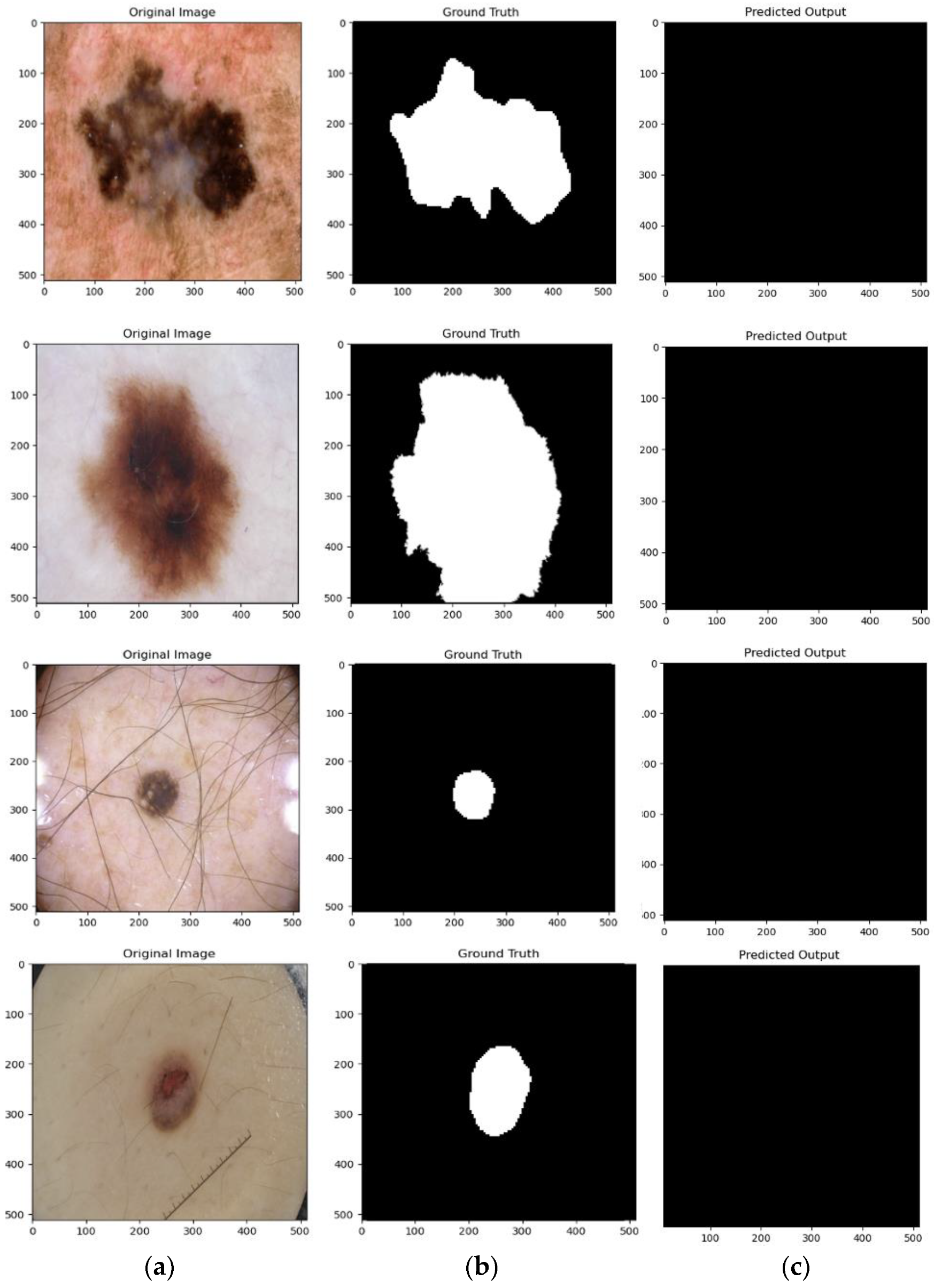
4.4. Qualitative Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. Key Facts about Cancer. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 5 April 2022).
- Verma, R.; Anand, S.; Vaja, C.; Bade, R.; Shah, A.; Gaikwad, K. Metastatic Malignant Melanoma: A Case Study. Int. J. Sci. Study 2016, 4, 188–190. [Google Scholar]
- Siegel, R.L.; Miller, K.D.; Goding Sauer, A.; Fedewa, S.A.; Butterly, L.F.; Anderson, J.C.; Cercek, A.; Smith, R.A.; Jemal, A. Colorectal Cancer Statistics, 2020. CA Cancer J. Clin. 2020, 70, 145–164. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-Level Classification of Skin Cancer with Deep Neural Networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef] [PubMed]
- Kroemer, S.; Frühauf, J.; Campbell, T.M.; Massone, C.; Schwantzer, G.; Soyer, H.P.; Hofmann-Wellenhof, R. Mobile Teledermatology for Skin Tumour Screening: Diagnostic Accuracy of Clinical and Dermoscopic Image Tele-evaluation Using Cellular Phones. Br. J. Dermatol. 2011, 164, 973–979. [Google Scholar] [CrossRef] [PubMed]
- Alves, J.; Moreira, D.; Alves, P.; Rosado, L.; Vasconcelos, M.J.M. Automatic Focus Assessment on Dermoscopic Images Acquired with Smartphones. Sensors 2019, 19, 4957. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ngoo, A.; Finnane, A.; McMeniman, E.; Soyer, H.P.; Janda, M. Fighting Melanoma with Smartphones: A Snapshot of Where We Are a Decade after App Stores Opened Their Doors. Int. J. Med. Inform. 2018, 118, 99–112. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pehamberger, H.; Steiner, A.; Wolff, K. In Vivo Epiluminescence Microscopy of Pigmented Skin Lesions. I. Pattern Analysis of Pigmented Skin Lesions. J. Am. Acad. Dermatol. 1987, 17, 571–583. [Google Scholar] [CrossRef]
- Stolz, W. ABCD Rule of Dermatoscopy: A New Practical Method for Early Recognition of Malignant Melanoma. Eur. J. Dermatol. 1994, 4, 521–527. [Google Scholar]
- Argenziano, G.; Fabbrocini, G.; Carli, P.; De Giorgi, V.; Sammarco, E.; Delfino, M. Epiluminescence Microscopy for the Diagnosis of Doubtful Melanocytic Skin Lesions: Comparison of the ABCD Rule of Dermatoscopy and a New 7-Point Checklist Based on Pattern Analysis. Arch. Dermatol. 1998, 134, 1563–1570. [Google Scholar] [CrossRef] [Green Version]
- Yu, L.; Chen, H.; Dou, Q.; Qin, J.; Heng, P.-A. Automated Melanoma Recognition in Dermoscopy Images via Very Deep Residual Networks. IEEE Trans. Med. Imaging 2016, 36, 994–1004. [Google Scholar] [CrossRef]
- Liu, L.; Mou, L.; Zhu, X.X.; Mandal, M. Automatic Skin Lesion Classification Based on Mid-Level Feature Learning. Comput. Med. Imaging Graph. 2020, 84, 101765. [Google Scholar] [CrossRef]
- Codella, N.; Rotemberg, V.; Tschandl, P.; Celebi, M.E.; Dusza, S.; Gutman, D.; Helba, B.; Kalloo, A.; Liopyris, K.; Marchetti, M. Skin Lesion Analysis toward Melanoma Detection 2018: A Challenge Hosted by the International Skin Imaging Collaboration (Isic). arXiv 2019, arXiv:1902.03368. [Google Scholar]
- Li, Y.; Shen, L. Skin Lesion Analysis towards Melanoma Detection Using Deep Learning Network. Sensors 2018, 18, 556. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Singh, V.K.; Abdel-Nasser, M.; Rashwan, H.A.; Akram, F.; Pandey, N.; Lalande, A.; Presles, B.; Romani, S.; Puig, D. FCA-Net: Adversarial Learning for Skin Lesion Segmentation Based on Multi-Scale Features and Factorized Channel Attention. IEEE Access 2019, 7, 130552–130565. [Google Scholar] [CrossRef]
- Yang, X.; Zeng, Z.; Yeo, S.Y.; Tan, C.; Tey, H.L.; Su, Y. A Novel Multi-Task Deep Learning Model for Skin Lesion Segmentation and Classification. arXiv 2017, arXiv:1703.01025. [Google Scholar]
- Xie, Y.; Zhang, J.; Xia, Y.; Shen, C. A Mutual Bootstrapping Model for Automated Skin Lesion Segmentation and Classification. IEEE Trans. Med. Imaging 2020, 39, 2482–2493. [Google Scholar] [CrossRef] [Green Version]
- Liu, L.; Tsui, Y.Y.; Mandal, M. Skin Lesion Segmentation Using Deep Learning with Auxiliary Task. J. Imaging 2021, 7, 67. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Berseth, M. ISIC 2017-Skin Lesion Analysis towards Melanoma Detection. arXiv 2017, arXiv:1703.00523. [Google Scholar]
- Chang, H. Skin Cancer Reorganization and Classification with Deep Neural Network. arXiv 2017, arXiv:1703.00534. [Google Scholar]
- Liu, L.; Mou, L.; Zhu, X.X.; Mandal, M. Skin Lesion Segmentation Based on Improved U-Net. In Proceedings of the 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE), Edmonton, AB, Canada, 5–8 May 2019; pp. 1–4. [Google Scholar]
- Abhishek, K.; Hamarneh, G.; Drew, M.S. Illumination-Based Transformations Improve Skin Lesion Segmentation in Dermoscopic Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 728–729. [Google Scholar]
- Nasir, M.; Attique Khan, M.; Sharif, M.; Lali, I.U.; Saba, T.; Iqbal, T. An Improved Strategy for Skin Lesion Detection and Classification Using Uniform Segmentation and Feature Selection Based Approach. Microsc. Res. Tech. 2018, 81, 528–543. [Google Scholar] [CrossRef] [PubMed]
- Afza, F.; Khan, M.A.; Sharif, M.; Rehman, A. Microscopic Skin Laceration Segmentation and Classification: A Framework of Statistical Normal Distribution and Optimal Feature Selection. Microsc. Res. Tech. 2019, 82, 1471–1488. [Google Scholar] [CrossRef] [PubMed]
- Damian, F.A.; Moldovanu, S.; Dey, N.; Ashour, A.S.; Moraru, L. Feature Selection of Non-Dermoscopic Skin Lesion Images for Nevus and Melanoma Classification. Computation 2020, 8, 41. [Google Scholar] [CrossRef]
- Khan, S.A.; Gulzar, Y.; Turaev, S.; Peng, Y.S. A Modified HSIFT Descriptor for Medical Image Classification of Anatomy Objects. Symmetry 2021, 13, 1987. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Maninis, K.-K.; Caelles, S.; Pont-Tuset, J.; Van Gool, L. Deep Extreme Cut: From Extreme Points to Object Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 616–625. [Google Scholar]
- Javed Awan, M.; Mohd Rahim, M.S.; Salim, N.; Mohammed, M.A.; Garcia-Zapirain, B.; Abdulkareem, K.H. Efficient Detection of Knee Anterior Cruciate Ligament from Magnetic Resonance Imaging Using Deep Learning Approach. Diagnostics 2021, 11, 105. [Google Scholar] [CrossRef]
- Jafari, M.H.; Karimi, N.; Nasr-Esfahani, E.; Samavi, S.; Soroushmehr, S.M.R.; Ward, K.; Najarian, K. Skin Lesion Segmentation in Clinical Images Using Deep Learning. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), IEEE, Cancun, Mexico, 4–8 December 2016; pp. 337–342. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Guided Image Filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 1397–1409. [Google Scholar] [CrossRef]
- Yuan, Y. Automatic Skin Lesion Segmentation with Fully Convolutional-Deconvolutional Networks. arXiv 2017, arXiv:1703.05165. [Google Scholar]
- Al-Masni, M.A.; Al-Antari, M.A.; Choi, M.-T.; Han, S.-M.; Kim, T.-S. Skin Lesion Segmentation in Dermoscopy Images via Deep Full Resolution Convolutional Networks. Comput. Methods Programs Biomed. 2018, 162, 221–231. [Google Scholar] [CrossRef]
- Bi, L.; Kim, J.; Ahn, E.; Kumar, A.; Feng, D.; Fulham, M. Step-Wise Integration of Deep Class-Specific Learning for Dermoscopic Image Segmentation. Pattern Recognit. 2019, 85, 78–89. [Google Scholar]
- Sarker, M.; Kamal, M.; Rashwan, H.A.; Akram, F.; Banu, S.F.; Saleh, A.; Singh, V.K.; Chowdhury, F.U.H.; Abdulwahab, S.; Romani, S. SLSDeep: Skin Lesion Segmentation Based on Dilated Residual and Pyramid Pooling Networks. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Granada, Spain, 16–20 September 2018; Springer: Cham, Switzerland, 2018; pp. 21–29. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 4th International Conference on 3D Vision, 3DV 2016, Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Oktay, O.; Schlemper, J.; le Folgoc, L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B. Attention U-Net: Learning Where to Look for the Pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Chen, J.; Lu, Y.; Yu, Q.; Luo, X.; Adeli, E.; Wang, Y.; Lu, L.; Yuille, A.L.; Zhou, Y. Transunet: Transformers Make Strong Encoders for Medical Image Segmentation. arXiv 2021, arXiv:2102.04306. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. arXiv 2021, arXiv:2105.05537. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | IoU | Dice Coeff | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| U-Net [20] | 80.93 | 82.18 | 86.27 | 98.40 | 87.64 |
| V-Net [39] | 15.95 | 17.31 | 21.52 | 52.04 | 28.02 |
| Attention U-Net [40] | 81.21 | 83.27 | 86.75 | 98.71 | 88.74 |
| TransUNet [41] | 86.72 | 89.13 | 89.44 | 99.02 | 91.02 |
| Swin-UNet [42] | 13.25 | 17.12 | 14.32 | 21.20 | 14.58 |
| Method | IoU | Dice Coeff | Precision | Recall | Accuracy |
|---|---|---|---|---|---|
| U-Net [20] | 83.77 | 84.12 | 86.31 | 98.61 | 87.93 |
| V-Net [39] | 16.75 | 18.13 | 23.00 | 53.32 | 39.24 |
| Attention U-Net [40] | 82.01 | 84.16 | 87.46 | 98.17 | 89.02 |
| TransUNet [41] | 87.96 | 89.84 | 89.93 | 99.38 | 92.11 |
| Swin-UNet [42] | 13.23 | 16.98 | 14.35 | 21.22 | 12.21 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gulzar, Y.; Khan, S.A. Skin Lesion Segmentation Based on Vision Transformers and Convolutional Neural Networks—A Comparative Study. Appl. Sci. 2022, 12, 5990. https://doi.org/10.3390/app12125990
Gulzar Y, Khan SA. Skin Lesion Segmentation Based on Vision Transformers and Convolutional Neural Networks—A Comparative Study. Applied Sciences. 2022; 12(12):5990. https://doi.org/10.3390/app12125990
Chicago/Turabian StyleGulzar, Yonis, and Sumeer Ahmad Khan. 2022. "Skin Lesion Segmentation Based on Vision Transformers and Convolutional Neural Networks—A Comparative Study" Applied Sciences 12, no. 12: 5990. https://doi.org/10.3390/app12125990